Az új architektúra dilemmái
Az AMD hosszú utat járt be, mióta felvásárolták az ATI-t. A vállalat már saját néven adta ki a Radeon HD 2900XT jelzésű VGA-t, mely bevezette a mindmáig használt VLIW-alapú architektúrát. Ez ugyan az évek során sokat változott, de az alapokat tekintve a rendszer működése ma már nem éppen ideális. A VLIW-alapú termékek az évek során kaptak hideget-meleget. Az első generációról nem lehetett túl sok jót mondani, azon kívül, hogy az architektúra tényleg átgondolt alapokra épített, hiszen nem csak formálisan volt unified shader rendszer, hanem valóban kiegyensúlyozottan viselkedett a pixel, a vertex vagy éppen a geometry shaderrel tarkított terhelésnél is.
Persze akkoriban az utóbbi két kódtípust nagyon kevés fejlesztő használta, ami részben a DirectX 9 öröksége is volt, de kétségtelen, hogy a GeForce felépítése előnyösebbnek bizonyult az akkori játékok alatt. Ez két generációval később, a Radeon HD 4000-es sorozatnál változott meg, amikor az AMD kigyomlálta a rendszer gyenge pontjait, és a fejlesztők is több vertex, illetve geometry shader kódot kezdtek el alkalmazni. A rendkívül sikeres Radeon HD 5000-es sorozat ezután meghozta a felemelkedést is, amire az NVIDIA nagyon későn válaszolt a Fermi architektúrával, mely már a korábbi GPU-k gyengébb kihasználhatóságát is korrigálta a vertex, illetve főleg a geometry shader kódoknál.
Az aktuálisan elérhető Radeon HD 6000-es és a GeForce 500-as generáció meglehetősen kiegyenlített versenyt hozott, hiszen az AMD és az NVIDIA ugyanolyan árszinten közel azonos képességekkel rendelkező VGA-kat kínál, ami a VGA-piac részesedésén is meglátszik. Az egyetlen különbség a chipek méretében rejlik. Az AMD általánosan kisebb lapkákkal nevez ugyanabba a kategóriába, míg az NVIDIA valamivel drágábban gyártható, nagyobb kiterjedésű GPU-kra kényszerül. Ez azonban annak köszönhető, hogy az AMD a HPC-piacot nem igazán támadja, így termékeiket inkább a grafikai számításokra hegyezték ki, szemben az NVIDIA-val, ahol tervezésnél fontosabb szempontot képviselnek a szuperszámítógépek. A piacok igényei azonban változnak, így azokra reagálni kell. Manapság még nem elterjedt, hogy egy GPU-t a fejlesztők általánosabb feladatokra használnak, az irány azonban viszonylag egyértelmű, hiszen a DiRT 3 című játék DirectCompute 5.0-s felületen a GPU-val gyorsítja a fizikai számításokat a vízfelület és a zászlók mozgatásánál. Ez ugyan nem befolyásolja a játékmenetet, de jól néz ki. Az új generációs fejlesztéseknél tehát egyre jobban előtérbe kerül a GPU-k általános számításokban való szereplése, így a fejlesztéseket is ebbe az irányba érdemes vinni.
Szintén nem elhanyagolható tényező a HPC-piac. A GPU-k alkalmazása a szuperszámítógépekben egyelőre csak lassan terjed, és az igazán nagy áttörést a heterogén módon programozható lapkák, vagy ismertebb elnevezéssel élve APU-k szolgáltatják majd ezen a piacon, de nem nehéz kitalálni, hogy a GPU-k jelentik a megoldást az energiával kapcsolatos problémákra, hiszen masszív számítási teljesítményükkel messze hatékonyabbak bármely központi processzornál.
A cGPU dilemmája
Az AMD az új GCN, azaz Graphics Core Next névre keresztelt architektúrát röviddel az ATI felvásárlása után kezdte el fejleszteni, vagyis több mint öt éve készül. Komoly dilemmát jelenthetett azonban összeegyeztetni a fejlesztést a VGA-piacon rendkívül sikeres Sweet Spot stratégiával. Ennek a lényege, hogy az AMD – ha a körülmények engedik – nem tervez nagyméretűnek mondható lapkát, így minden generáció csúcstermékénél próbálnak a 400 mm²-es lélektani határ alatt maradni. Ez – főleg csíkszélességváltásnál – megkönnyíti az új termék gyártását, továbbá a fejlesztés is jóval egyszerűbb, azaz a lapka hamarabb kerülhet piacra.

[+]
Problémát jelent azonban az általános programozhatóság erősítése. Az eddigi fejlesztéseknél a grafikus feladatokban való szereplés volt a fő szempont, így a Sweet Spot stratégia alatt csak olyan változások kerültek az új generációs rendszerekbe, amit a fejlesztők a chip piacon mért élettartama alatt ki is tudnak használni. A jövőben esedékes igényeket felmérve azonban úgynevezett cGPU-ra (computational GPU) van szükség, vagyis az AMD szembekerül azzal a problémával, amivel az NVIDIA a Fermi architektúránál. Nevezetesen arról van szó, hogy a rendszert egyre inkább az általános számításokra kell kigyúrni, ami sajnos mindenképpen rossz hatással lesz a lapka méretére.
A GCN architektúra fejlesztése tehát a legkevésbé sem volt irigylésre méltó munka az elmúlt öt évben, hiszen a fejlesztés célkitűzése egy olyan rendszer elkészítése, mely alkalmazható a Fusion projekt során, illetve kiemelt szempont, hogy az általános számítások esetében is magas teljesítményt adjon le, továbbá támogassa a magasszintű programozási nyelveket, amivel a fejlesztők munkája megkönnyíthető. Mindezt még tetézi az, hogy a VGA-piacon meg kell felelni a Sweet Spot stratégiának, vagyis a rendszer hatékonyságát is az egekbe kellett tolni, mindemellett még a játékokban leadott teljesítmény növelését is figyelembe kellett venni.
Ebből világosan látszik, hogy nem lehetett csak úgy két kézzel szórni a tranzisztorok millióit a különböző egységekre, így sokkal inkább trükkös megoldásokra voltak kényszerítve a mérnökök. A Southern Island termékcsalád részeként megszületett Tahiti kódnevű cGPU-n ez a szemlélet nagyon is meglátszik, hiszen ahol lehetett, ott bizony spórolt az AMD, ráadásul a GCN architektúra felépítése is elképesztően moduláris, mi több, még a rendszer skálázhatósága is példátlan.
AMD Tahiti
Egy új architektúra bevezetésénél nagyon nehéz megfelelni minden szempontnak, ugyanis ami elméletben működik, az nem biztos, hogy a gyakorlatban is fog. A fejlesztés végletekben megszabott célkitűzéseivel az AMD óriási kockázatot is vállalt, hiszen radikális újításokat kellett bevezetni. A Tahiti kódnevű termék végül megfelel a Sweet Spot stratégiának, hiszen a TSMC 28 nm-es gyártástechnológiájával készülő lapka kiterjedése 365 mm², és ebbe a méretbe 4,31 milliárd tranzisztort sikerült bepasszírozni.

A Tahiti cGPU blokkdiagrammja [+]
A rendszer alapja CU, azaz a Compute Unit lesz; lényegében ez váltja a jelenlegi, VLIW utasításokkal dolgozó shader tömböket. Mindegyik CU tartalmaz egy skalár feldolgozót, és négy darab, egymástól teljesen független, 16 utas, azaz 512 bites, multiprecíziós SIMD motort. Ezzel a felépítéssel a jelenlegi, VLIW-alapú rendszert sújtó függőség problémája teljesen kiküszöbölhető, mivel az adatok mostantól komponens folyamonként érkeznek. Egy CU órajelenként négy utasítást képes végrehajtani 16 elemen, melyek négy különböző munkafolyamatból kerülhetnek ki. A Cayman GPU-ban alkalmazott megvalósítás jóval bonyolultabban működött, mivel egy shader tömbön belül 16 darab szuperskalár shader processzor volt, melyek órajelenként négy utasítást hajthattak végre négy elemen, ám ezek nem, illetve csak nagyon speciális esetben függhettek egymástól. Az új architektúrában bevezetett változások a hatékonyságot helyezik előtérbe, így a rendszer jobban kihasználható, és egyszerűbb is rá programozni, vagyis a driverek fejlesztésével, valamint a valós idejű shader fordító optimalizálásával is jóval könnyebb dolga lesz az AMD-nek.

[+]
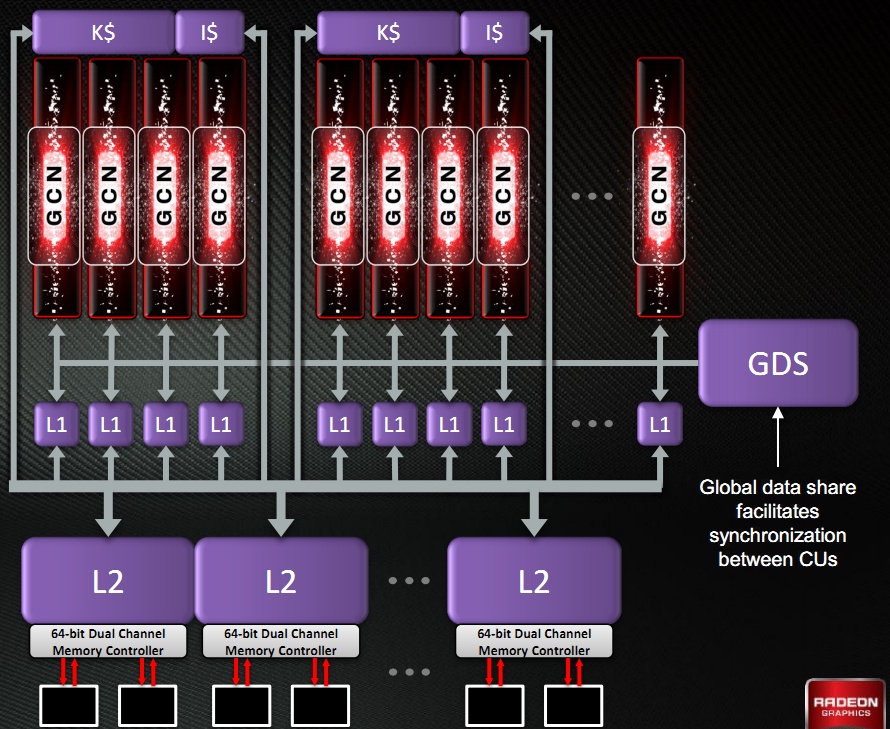
Egy CU-n belül 64 kB-os Local Data Share (LDS) található, melyeken a négy darab, egyenként 64 kB-os regiszterterülettel rendelkező SIMD motor osztozik. Az LDS-sel egyébként az AMD túlteljesíti a DirectCompute 32 kB-os követelményét, ami valószínűleg azért történt így, mert az architektúrát jelentősen az általános számításokra tervezték. Az LDS mellett egy 16 kB-os adat gyorsítótár is elérhető, melyet a CU írhat és olvashat is. A fentebb már említett skalárfeldolgozó némileg különc a CU-n belül. Ez lényegében egy integer ALU, mely 8 kB-os dedikált regiszterterületet kapott. A textúrázást CU-nként egy blokk oldja meg, mely négy darab, csak szűrt mintákkal visszatérő Gather4-kompatibilis textúrázó csatornát rejt. A rendszeren belül a CU-k négyes tömbökbe rendeződnek, és ezekhez tartozik egy 16 kB-os skalár és egy 32 kB-os utasítás gyorsítótár. Előbbit csak a skalárfeldolgozó éri el, és csak olvasható tárról van szó, ám utóbbi írható is, és a CU összes feldolgozója hasznosíthatja. A Tahiti cGPU-ban egyébként 32 darab CU található, melyekhez kapcsolódik egy Global Data Share (GDS) memória is, amivel a CU-k nagyon gyorsan oszthatnak meg adatokat egymással.

A Compute Unit felépítese [+]
A vezérlés dilemmája
Nem túl nehéz megállapítani, hogy egy cGPU-nál a hatékony működés kulcsa a hatékony vezérlés, így erre a területre az AMD-nek is rá kellett feküdni, azonban figyelembe kellett venni a skálázhatóságot. Példaként érdemes felhozni a Fermi architektúra lapkáit az NVIDIA termékskálájáról. A GF110-es és a GF114-es lapkák úgy-ahogy versenyképesek a chip kiterjedéséhez mért egységnyi sebesség tekintetében, de a kisebb GeForce-okon már meglátszik, hogy a bonyolult vezérlés rengeteg tranzisztort emészt fel. A GF116-os GPU például közel akkora, mint az AMD Barts lapkája, de a GeForce GTX 550 Ti még csak megközelíteni sem tudja a Radeon HD 6870 teljesítményét. Ez persze a termékek árazásában is megnyilvánul az NVIDIA-nál, de a probléma jelen van, és így a rendszer skálázhatósága egy bizonyos szint alatt nagyon nem hatékony.
Lényegében ezen a ponton kellett az AMD mérnökeinek a legtöbb problémával megküzdeni, és úgy döntöttek, hogy egy teljesen moduláris vezérlést vezetnek be, így az úgynevezett Asynchronous Compute Engine (ACE) felel majd a CU-k etetésért. Ez az egység a parancsprocesszorhoz szorosan kapcsolódik, és akármennyi beépíthető az adott lapkába, sőt, akár mellőzhető is. Utóbbi opció azonban nem ajánlott, mivel az ACE a rendszer magas hatékonyságú kihasználásához alapvetően szükséges, ugyanis ez a motor dönt az erőforrás-allokációjával, a kontextusváltással és a feladat prioritásával kapcsolatban. Ráadásul az ACE out of order logikát alkalmaz az erőforrások mielőbbi felszabadítása érdekében. Bár maguk a CU-k in order elven működnek, vagyis az utasításfolyamokat a beérkezés sorrendjében hajtják végre, de alapvetően az ACE eteti a CU-kat, így képes meghatározni a feldolgozás sorrendjét.
A Tahiti cGPU-ba két ACE került. Arról sajnos az AMD nem közölt információkat, hogy két motor mennyire hatékonyan képes kezelni 32 darab CU-t, de az architektúráról kiderült, hogy félelmetesen jól skálázható, így a jövőben annyi ACE-t lehet beépíteni, amennyit az AMD jónak lát.
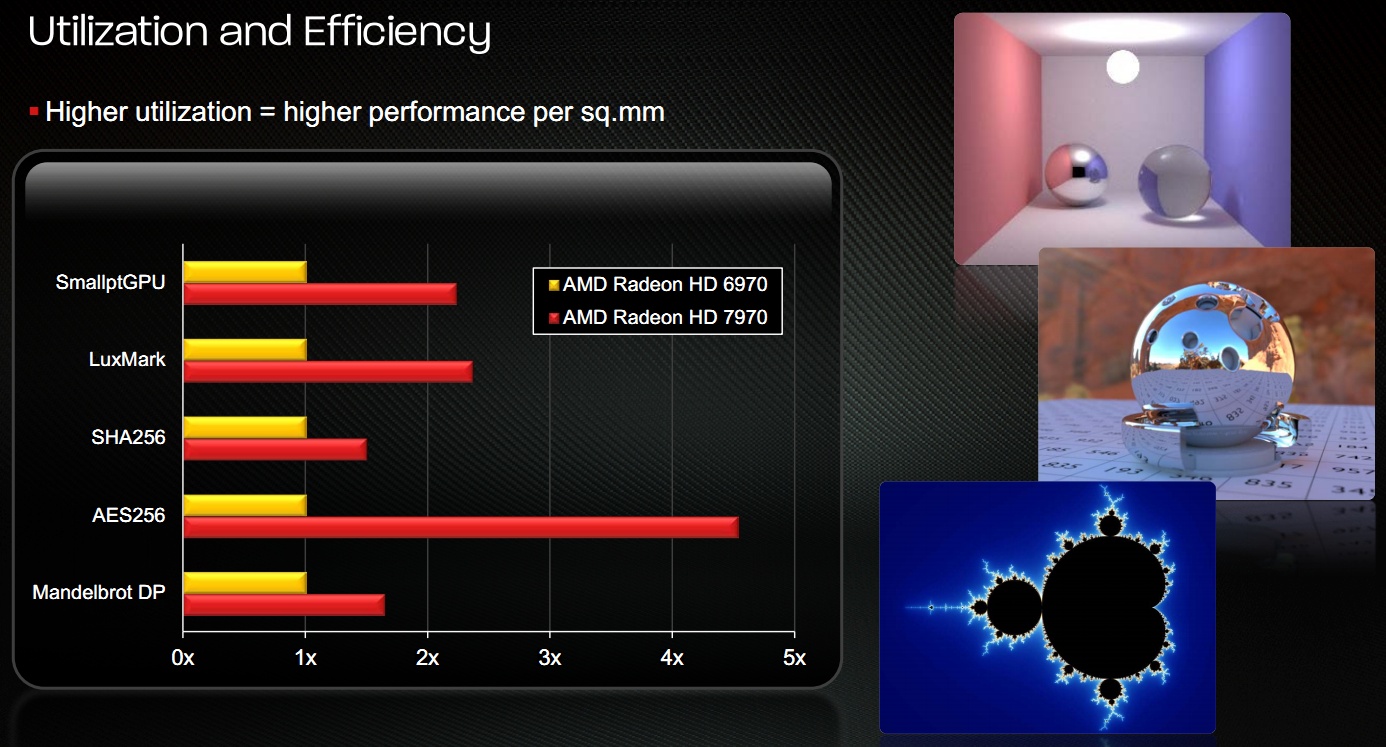
[+]
A gyakorlatban a változások az AMD mérései szerint jól sültek el, mivel a Cayman és a Tahiti lapkák kiterjedése nagyon hasonló, de az utóbbi termék 50-60%-kal nagyobb elméleti számítási teljesítmény mellett több helyen is jobb teljesítményre tett szert. A Cayman architektúrájának tipikusan feküdt az SHA256-os kódolás, mivel ez egy gyorsításra szélsőségesen érzékeny algoritmus. Itt a Tahiti lényegében annyit gyorsult, amennyire a magasabb számítási teljesítményből számítani lehetett, ám a SmallptGPU és a LuxMark esetében jóval nagyobb az előrelépés. A hatékonyság kiugró növekedésével lehet számolni az AES256-os kódolás esetében, ami az algoritmus jellegzetességeiből adódóan jól mutatja, hogy az ACE nagyon jó munkát végez a rendszer vezérlése során. Az AMD dupla pontosság mellett tesztelt Mandelbrot fraktállal is, amit szintén gyorsan dolgozott fel már a Cayman is, így az előrelépés nagyjából a valós gyorsulással egyezik meg. A Tahiti cGPU egyébként az elméleti számítási teljesítmény negyedével képes dolgozni dupla pontosság mellett.
A Tahiti és a grafika
Eddig a rendszert az általános számítások szempontjából vizsgáltuk, így ideje rátérni a grafikai részre is, ami valószínűleg jobban érdekli az olvasókat. A rendszer setup része a Cayman GPU-ban bevezetett utat követi, vagyis a Tahiti két darab teljesen elkülönülő egységgel dolgozik. Ennek köszönhetően a rendszer órajelenként két háromszöget dolgoz fel. A feldolgozó motoronként elhelyezett, kilencedik generációs tesszellációs egység azonban egy rendkívül izmos megoldás lesz.
Az AMD úgy gondolja, hogy a fix funkciós tesszellátor esetében sokkal jobb döntés az extrém mértékű skálázás helyett az egység teljesítményét növelni, illetve különböző trükkökkel gyorsítani a tesszellálást. Itt tulajdonképpen látható, hogy az NVIDIA és az AMD nem ért egyet megvalósítás szempontjából. Az előbbi vállalat a Fermi architektúrában egy úgymond brute force megvalósítás híve volt, vagyis tranzisztorok tízmillióit áldozva ide egy teljesen szétválasztott setup részt alkalmazott. Ennek az elgondolásnak az összesített hatékonysága a gyakorlatban nem volt a legjobb az elméletben elérhető maximumhoz viszonyítva, de annyira túl volt méretezve a rendszer, hogy ez bőven korrigálva lett.
Az AMD technikailag felkészítette a GCN architektúrát akármennyi setup motor kezelésére, de a vállalat szerint nagyon meg kell gondolni, hogy mennyi tranzisztor legyen felhasználva itt, mivel a tesszelláció a DirectX 11-ben a nem éppen hatékony NoSplit megvalósításra épül. Korábban írtunk már ennek hibáiról, illetve a lehetséges alternatívákról. Az világosan látszik, hogy a linkelt hírben az aktuális megoldások közül az úgynevezett DiagSplit elv kínálja a legjobb működést, de ez nem mutatkozik majd be a DirectX 11.1-es API-ban, így a fejlesztők továbbra is a NoSplit algoritmusra vannak kényszerítve.
Nem elhanyagolható szempont az sem, hogy a tesszellálás legnagyobb rákfenéje a raszterizálás hatékonysága. Ez korábban nem jelentett problémát, de az apró háromszögek alkalmazásával erősen meg lehet közelíteni egy olyan határt, ami egyszerűen túlterheli az összes kártyát ebből a szempontból. Egy korábbi cikkben részletesen elemeztük a helyzetet, miszerint a mai GPU-kra egységesen jellemző, hogy a raszterizálást négyes pixelblokkokon hajtják végre, ami annak köszönhető, hogy ez a feldolgozási elv a párhuzamos munkavégzés mellett nagyon hatékony.
Az elsődleges gond akkor merül fel, ha egy háromszög kisebb, mint négy pixel. Ilyen esetben a négyes blokk nem azonos háromszögön dolgozik, vagyis a másik háromszögre is ki kell számolni a teljes blokkot, ami lényegében az erőforrás nagymértékű pazarlása. Ennél sokkal rosszabb, ha egy háromszög egy pixel nagyságú, mivel számítás az egyik háromszöggel kezdődik az egyik pixelen, ami mellé további három képpont tartozik a blokkosított feldolgozás miatt. Ez már önmagában azt jelenti, hogy egyetlen apró háromszögért négy pixelt kell ellenőrizni, ám a poligon kicsi, így jó eséllyel mellette lesz a társa, ami további ellenőrzéseket jelent. A gyakorlatban ez a jelenség még rosszabb, ugyanis a háromszögek nem fedik tökéletesen a pixelt, vagyis legrosszabb esetben 12 pixel ellenőrzését is végre kell hajtani ahhoz, hogy egyetlen képpont raszterizálva legyen.
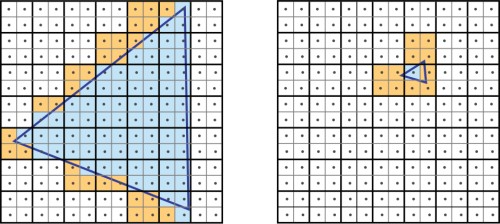
A tesszellátor a tranzisztor szintjén alapvetően nem drága, így ezen a ponton sok lehetőségük volt a mérnököknek, de a kapcsolódó raszter motor már nagyon is költséges. Az AMD a tranzisztorszám kímélése miatt úgy döntött, hogy a rendkívül pazarló, de mégis gyors brute force elv helyett inkább okos trükkökkel operálnak a teljesítmény növelésénél. A raszter motorokkal alapvetően a Cayman esetében sem volt gond, mivel ebből a szempontból az előző generációs Radeon a piac legfejlettebb és leggyorsabb megoldásának számított. Éppen ezért itt az AMD apróbb optimalizálásokkal élt, de az egység többnyire ugyanarra képes, mint az előd, azaz órajelenként 16 képpontot dolgoz fel, ami a teljes lapkára nézve 32 pixelt jelent, a renderelés pedig 2 x 2 pixeles tömbökön zajlik. Természetesen megmaradt a tile-based load balancing, ami a hierarchikus Z algoritmus túlterhelését akadályozza meg. Ezzel a rendszer a raszterizálást hierarchikus Z nélkül hajtja végre, a teljes képkockát több egyenlő méretű, viszonylag kicsi mozaikra osztva. Itt nyilván számos szabályt be kell tartani biztosítandó a renderelés sorrendjét. A hierarchikus Z algoritmus a mozaikokon lesz lefuttatva, amelyeket tovább lehet küldeni, vagy éppen el lehet dobni, ha nem tartalmaznak látható információt. Tulajdonképpen az elgondolás a teljesítmény tekintetében messze nem a legjobb, de összességében még mindig jobb bevállalni ezt, minthogy a hierarchikus Z motor túlterhelődjön, ami sokkal nagyobb problémát jelent. Hasonló megoldást alkalmaz az NVIDIA a Ferminél is, ám a zöldek raszter motorjának teljesítménye órajelenként csak 8 képpont.
A nagy változások tehát alapvetően a tesszellációs egységeket érték. Az új megoldások az előző generációs rendszerhez képest, magas tesszellációs faktor mellett átlagosan három és félszer gyorsabban dolgoznak, sőt a manapság alkalmazott kritikus faktorszint mellett négyszer tempósabban bontják fel a háromszögeket. A kilencedik generációs egység ráadásul írhat az összesen 768 kB-os L2 gyorsítótárba. Alapvetően már a Cayman GPU-ban alkalmazott motor is lehetővé tette, hogy a magas tesszellációs faktorral rendelkező felületeket lementse a rendszer a fedélzeti memóriába, így azokat a következő képkockák számítása alatt elég betölteni, amivel megspórolható a felbontással eltöltött idő. Ez a megvalósítás azonban csak akkor volt hatékony, ha a memória nem túl gyors elérése még mindig gyorsabb volt a háromszögek felbontásánál. Ez nagyon ritkán előfordulhatott, de az esetek többségében jobb opció volt számolni, mint trükközni. Az írható másodlagos gyorsítótár elérése azonban jóval gyorsabb, így az ACE elemzi a felületek felbontásával töltött időt, és ha azt túl soknak ítéli, akkor a parancsprocesszornak jelzi, hogy le kell menteni az adott részletet a gyorsítótárba. A következő képkocka számításánál a raszter motor már csak egy parancsot kap, hogy az előzőleg kiszámolt felületet töltse be a cache-ből.
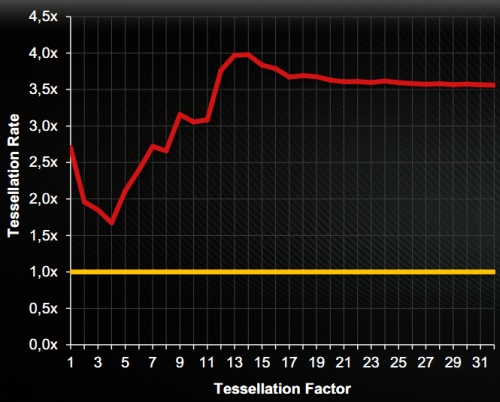
Természetesen egy méretesebb felület rengeteg helyet foglal, vagyis elsősorban a kritikus részek lementését érdemes megfontolni. Az AMD ezt persze driverből is koordinálhatja, figyelembe véve az adott program igényeit. Maga a rendszer tehát nagyon trükkös, és abszolút tranzisztorkímélő. A driverekből való rásegítés azonban valószínűleg sok támadást fog kapni a konkurens gyártótól. Bár a felületek lementése és visszatöltése a képminőségen egyáltalán nem változtat, az adott alkalmazásra szabva viszont elképesztő sebességelőnyt hozhat, így a tesszellálásra kihegyezett tesztprogramokban nem biztos, hogy a valós erőviszony köszön majd vissza. A népszerű Unigine Heaven például rengeteg, extrém mértékben tesszellált felületet használ, így ebben a programban az AMD elgondolása komoly előny lehet. Persze figyelembe kell venni, hogy mindez a játékokban is alkalmazható, így az AMD valószínűleg kihasználja a Catalyst meghajtókban régóta tengődő optimalizált tesszelláció opciót, melyre eddig még egyetlen profil sem született.
Gyorsítótárak, ROP blokkok, memória és az új VGA
Lévén, hogy az AMD cGPU-ban gondolkodott, a gyorsítótárak tekintetében is komoly előrelépésre volt szükség. A rendszer hierarchiája nem éppen egyszerű, de a hatékony működés alapja ez. Két oldallal korábban már részleteztük a CU-khoz kapcsolódó adat gyorsítótárat (L1), a négyes CU tömbökhöz használt, megosztott skalár (K$) és utasítás (I$) gyorsítótár, valamint a Global Data Share (GDS) memóriát. Ezek mindegyike kapcsolódik az összesen 768 kB-os L2 gyorsítótárhoz, mely olvasható és írható is. Az L2 gyorsítótárat hat partícióra osztotta az AMD, így a 384 bites memóriabusz egy-egy csatornája kap egy-egy 128 kB-os szeletet. Az L1 tárak és az L2 cache partíciói magórajelen üzemelnek és órajelenként 64 bájt adatot mozgatnak, vagyis elég tempós lett ebből a szempontból a rendszer. Emellett fontos újítás még, hogy az L2 cache koherens, vagyis mindegyik CU azonos memóriaképet lát.
[+]
A memóriavezérlő alapjait nem érte sok változás, így az AMD továbbra is az RV770-ben megismert Control Hub mellett tette le a voksát, ami a Tahiti cGPU-ban hat darab 64 bites csatornát üzemeltet. Túl nagy meglepetést nem okozott, hogy a mérnökök nem változtattak ezen az elvi felépítésen, hiszen a Control Hub rendkívül hatékonyan bánik a lapkához kapcsolt fedélzeti memóriával, így itt nincs lehetőség sok újításra. Változás érte azonban a ROP blokkok szervezését. Az előző generációs termékekben a blokkok a memóriacsatornákhoz kapcsolódtak. Ez alapvetően nem rossz megvalósítás, de az egyes ROP blokkok csak a hozzájuk kapcsolt memóriapartíciót használhatják, ami limitálja a hatékonyságot. A GCN architektúrában az AMD ezt a modellt megelégelte, így a ROP blokkok mostantól teljesen függetlenek a memóriacsatornáktól. Ez azt jelenti, hogy a méretes L2 gyorsítótárhoz csatlakozik az összes blokk, és így elérik a teljes fedélzeti memóriát, vagyis bármelyik partíciót használhatják.
A ROP blokkok száma egyébként nem változott az előző generációs Caymanhez viszonyítva, így továbbra is nyolc darab van belőlük, ami összesen 32 blending és 128 Z mintavételező egységet eredményez. A ROP blokkokon belül csak apróbb finomításokkal élt az AMD, így lényegében közel ugyanolyan teljesítményre képesek az egységek, mint amilyenre a Cayman megoldási.
Szintén újítás, hogy a Tahiti a fedélzeti memóriák esetében bevezeti az ECC támogatást. Az AMD ugyanazt az elgondolást használja, amit az NVIDIA a Fermi architektúránál, így az ECC működése sebességvesztést okoz, éppen ezért az asztali piacra szánt VGA-knál ez a funkció nem működik. Arról az AMD még nem nyilatkozott, hogy később aktiválható lesz-e a driverben. Technikailag megoldható, de valószínűbb, hogy a vállalat – a konkurenshez hasonlóan – inkább mellőzi az ECC-t, hiszen ennek a funkciónak nincs jelentősége a Radeon által megcélzott piacokon.
De milyen is lesz a Radeon HD 7970?
Az új GCN architektúra és a Tahiti cGPU felületes ismertetése után elegendő információ áll rendelkezésre, hogy szemügyre vegyük a Radeon HD 7970 konkrét paramétereit. Az új VGA x16-os PCI Express 3.0-s interfészbe illeszthető. Ez a csatoló elméletben kétszer nagyobb adatátviteli teljesítményt jelent az x16-os PCI Express 2.0-s porthoz viszonyítva, de a programokban ennek nem biztos, hogy azonnal látni lehet az eredményét, mivel a fejlesztők manapság arra törekszenek, hogy a PCI Express busz csak minimális igénybevételnek legyen kitéve. Számos teszt lelhető fel a weben, melyek alapján kijelenthető, hogy egy mai csúcs VGA-nak az x8-as PCI Express sem korlátozza a teljesítményét, így a PCI Express 3.0 előnyeit biztos nem lehet majd azonnal kihasználni.
Ez sokak számára valószínűleg nem hat meglepetésként, hiszen ugyanezt eddig minden új PCI Express szabvány bevezetésénél el lehetett mondani. Ennek ellenére a PCI Express 3.0 mögött jelenleg óriási reklámkampány húzódik, ám a gyártók sosem mutatják be, hogy az elméletben elérhető extra sebességnek milyen gyakorlati hatásai vannak. Ennek nyilván az az oka, hogy most még az új interfész gyakorlatban mérhető előnye nem mutatható ki.

A Radeon HD 7970 természetesen az eddig ismertetett Tahiti cGPU-ra épül, és azon belül is aktiválva lesz az összes egység. Ennek megfelelően a lapka 2048 shader részelemet kínál 128 darab Gather4-kompatibilis textúrázó csatornával. A rendszerben két ACE és két setup motor lesz összesen 32 blending és 128 Z mintavételező mellett. A magórajel esetében az AMD mérnökei 925 MHz-et állítottak be, így a Tahiti elméletben 3,78 TFLOPS-os teljesítményre képes szimpla pontosság mellett. A 384 bites memóriavezérlőre 3 GB GDDR5 szabványú fedélzeti memória kapcsolódik, mely 5,5 GHz-es effektív frekvencián ketyeg. Ennek megfelelően a memória-sávszélesség eléri a 264 GB/s-os paramétert.
Az új VGA támogatja a Cayman esetében bevezetett PowerTune technológiát, így a maximális energiaigényt a felhasználó a Catalyst Overdrive menüjében képes szabályozni pozitív, illetve negatív irányban. A Radeon HD 7970 alapértelmezett beállítások mellett 250 wattos limittel rendelkezik, de a nyomtatott áramköri lap 300 wattra is fel van készítve, ami a tuningosok számára jól jöhet. A terheléstől mentes időszakokban a kártya természetesen visszafogja magát, és a fogyasztás ilyenkor kicsivel 20 watt alá esik.

[+]
Új technológia azonban a ZeroCore Power szolgáltatás, mely akkor lép érvénybe, ha a számítógépen az operációs rendszer készenlétbe kapcsolja a monitort. Ilyen esetben az előző generációs VGA-k továbbra is elfogyasztották az úgynevezett idle energiát, ám a Radeon HD 7970 már beéri 3 wattal is. A VGA-n a GPU szinte teljesen lekapcsol, így egyedül a PCI Express vezérlő marad aktív, hogy fogadhassa a felébresztéshez szükséges jelet. Természetesen a memóriákat sem lehet teljesen inaktiválni, így azokat továbbra is frissíteni kell, de a ventilátor teljesen kikapcsol, mivel azt a 3 wattos hőmennyiséget a hőkamrás hűtőborda is elvezeti.

[+]
A ZeroCore Power a CrossFireX konfigurációknál is jól jöhet, mivel ilyenkor csak az elsődleges VGA-nak kell 20 watt körül fogyasztania, a többi kártya lekapcsolható. Az AMD korábban is alkalmazott egyfajta hibernálást a CrossFireX a rendszerekre, de ez nem 3 wattra redukálta a fogyasztást, hanem 10 watt körüli értékre, ami még mindig elég sok volt.
A megcélzott piac igényeit figyelembe véve az AMD két BIOS-t épít a termékre, mivel ezen a szinten a legtöbb felhasználó sok finomhangolást hajt végre. Ha az elsődleges rendszer egy félresikerült frissítés következtében használhatatlanná válna, akkor egy kapcsoló átállításával könnyen aktiválható a másodlagos BIOS, ami helyrehozza a problémát.
Az extrák és a képminőség
A Tahiti a reformoknak hála még számos meglepetést tartogat. Az AMD nem titkolja, hogy a rendszert a Fusion projekt igényire szabta, így az újítások egy része még nem kihasználható, de az integráció csak idő kérdése. A GCN architektúra például kezeli a C++ programnyelvet, így támogatja a virtuális funkciókat, a kivételkezelést, a rekurziót, valamint a pointereket. Sőt, utóbbi esetben a rendszer ugyanazokat a 64 bites pointereket használja, amelyeket az AMD64 utasításkészletű processzorok. Ez a legérdekesebb része a fejlesztésnek, ugyanis a CPU és cGPU egységes címtartományt kap, így a GCN architektúra képes címfordításra az AMD64-es címtartományon belül, mindemellett támogatja a virtuális memóriát az AMD IOMMU technológián keresztül, így a cGPU képes lesz kezelni a laphibákat. Ezek jó része platformszolgáltatás, vagyis csak a jövőben megjelenő Fusion APU-kon lesz kihasználható. A virtuális memória támogatása természetesen az aktuális operációs rendszerek szintjén is nehézségekbe ütközik, így az új architektúra jelenleg félkarú óriás, de az AMD pár extrát azért megpróbál hasznosítani kisebb-nagyobb trükkök bevetésével.
Partially Resident Textures
Az új architektúra egyik legérdekesebb újítása a Partially Resident Textures (PRT) eljárás, mely lehetővé teszi a hardveres virtuális textúrázást (ismertebb néven megatextúrázást) és a hardveres textúra streaming algoritmusok kreálását, valamint jelentősen több adat kezelése oldható meg segítségével. Az AMD trükközéssel próbálja hasznosítani a cGPU virtuális memória támogatását, így az új funkció az OpenGL API-hoz lesz elérhető egy specifikus kiterjesztés formájában. A PRT segítségével a VRAM egyfajta hardveresen menedzselhető gyorsítótárrá válik, így tökéletesen alkalmas lesz a textúra adatok streamelésére. A Tahiti cGPU nem kevesebb mint 32 terabájtos tömörítetlen textúrát támogat a PRT kiterjesztésen keresztül.

[+]
Az AMD a PRT képességeit egy technológiai demonstrációs program formájában fogja bemutatni, mivel manapság csak a Rage című játék és az ID Tech 5 nevű motor igényli a PRT alkalmazását. Az előbb említett játékról az AMD nem beszélt, de John Carmacket nagyon sok támadás éri a megatextúrázás minősége kapcsán, így elképzelhető, hogy egy érkező patchben az AMD PRT kiterjesztését is beveti, amivel a Rage végre olyan formát ölthet PC-n, amilyet a fejlesztők eredetileg megálmodtak. Az AMD elmondta, hogy a virtuális textúrázás vagy megatextúrázás nagy jövő előtt áll, és arra számítanak, hogy számos új generációs motor épít majd a technológiára. A vállalat szerint a PRT legnagyobb előnye a szoftveres alapokra helyezett virtuális textúrázással szemben, hogy könnyebb az implementáció, emellett a hardveres megvalósítás tökéletesen támogatja a teljes sebességű anizotropikus szűrést, amire például a Rage-ben csak limitált formában van lehetőség.
Feljavított képminőség
A Tahiti cGPU nemcsak a sebesség, hanem a képminőség terén is előrelépést jelent. A mai GPU-k esetében a textúrák szűrése jelenti a legkényesebb pontot a virtuális világ képminősége kapcsán. Az AMD és az NVIDIA már nagyon jó minőségű anizotropikus szűrést alkalmaz, és ebből a szempontból alig van különbség a két vállalat technológiája között. Az persze igaz, hogy az AMD teljesen szögfüggetlen eljárást használ, de valós körülmények között ez szinte észrevehetetlen eltérést eredményez az NVIDIA enyhén szögfüggő algoritmusához viszonyítva. Máig probléma azonban a shimmering néven ismert jelenség, mely a magas minőségű textúrák esetében egyfajta rezgést okoz a texeleken, ami mozgás közben illúzióromboló. Ez az állóképeken nem látható, mivel csak mozgás közben jelentkező pillanatnyi elváltozásokról van szó.
A shimmering a szűréshez használt algoritmus, valamint a mintavételezés minőségétől függ. A jelenséget nem lehet teljesen elfedni, mivel ez a technológia velejárója, de lehet csökkenteni a mértékét. Sajnos a Microsoft a referencia raszterizálóhoz viszonyított képminőség tekintetében ebből a szempontból egyáltalán nem vizsgálja a GPU-k képességeit, így a WHQL tesztek során alapvetően a magas minőségű szűrés vezet értékelhető eredményhez. Az AMD az előző generációs termékek képminőségét is e tesztekhez igazítja, az NVIDIA azonban nem, és inkább vállalják a WHQL teszteken a gyengébb eredményt. Azt ugyanis a Microsoft is elismeri, hogy a shimmering létező jelenség, és lehet tenni ellene, éppen ezért tökéletesen megértik az NVIDIA indokait.
Az egyik megoldás a shimmering visszafogására a szűrés minőségének csökkentése, ami nagyon enyhén életlenebb textúrákat eredményez, de cserébe redukálja a problémás jelenséget. Ezt nagyon jól össze lehet hasonlítani a Trackmania Nations című játékban, ahol tipikusan megfigyelhető a shimmering jelensége és a textúrák szűrésének minősége is. A legtöbb játék persze nem ilyen, így jóval kevésbé észrevehetők ezek az eltérések a gyártók megoldásai között. Konkrétan nagyítóval is nehéz kimutatni a különbségeket.


A textúrák minősége az AMD és az NVIDIA szűrésével [+]
Az AMD ugyanakkor rájött, hogy a felhasználókat általában jobban zavarja a shimmering, és még a textúrák minőségéből is engednek, hogy ezt a jelenséget eltüntessék, így a Catalyst 11.2-es meghajtóban megváltoztak a textúraszűréssel kapcsolatos beállítások. A legjobb minőségű és az alapértelmezett opció továbbra is olyan szűrést használ, mely megfelelő a WHQL tesztek szempontjából, de a legalacsonyabb performance beállítás a shimmering jelenség eltüntetésére törekszik, így a Geforce driverekhez hasonlóan csökkenti a szűrés minőségét. Ez valóban hatásos megoldás volt, és észrevehetően redukálta a shimmeringet, de nem annyira, amennyire az NVIDIA algoritmusa teszi. Mindenesetre az AMD-nek továbbra is fontos volt, hogy a driverek 100%-os minősítéssel végezzenek a WHQL teszten, így kompromisszumot kellett kötni az alkalmazott rutinok szempontjából.

[+]
A Tahiti esetében a mérnökök kidolgoztak egy teljesen új szűrési algoritmust, amely a textúrák enyhe elmosása nélkül is képes jelentősen redukálni a shimmering jelenségét. Az AMD szerint az algoritmus átmegy a Microsoft szigorú tesztjein is, így mindenki elégedett lesz az eredménnyel. Sőt, az új Radeon generáció nagyjából olyan képminőséget képvisel, amilyet a 3DCenter Filter Tester alkalmazásának ALU rendering szintje, ami valóban komoly előrelépés.
Eyefinity 2.0 és a multimédia
Az AMD az Eyefinity funkciót is erősíti, így bemutatkozik a 2.0-s verzió, melynek legnagyobb újítása a Discrete Digital Multi-Point (DDM) Audio szolgáltatás. Az aktuális megoldás esetében rá lehet kötni több monitort a termékekre, de csak egyetlen nyolccsatornás hangfolyam biztosítása lehetséges. Az új Eyefinity mindegyik csatlakoztatott kijelzőhöz külön nyolccsatornás hangfolyamot képes rendelni. Ez új szintre emelheti a videokonferenciák minőségét, ugyanis az egyes kijelzőkhöz rendelt személy az adott megjelenítő hangszóróján szólal meg. A fejlesztésnek alapvetően ez is volt a legfőbb célja. A DDM Audio szolgáltatás egyébként teljesen automatikus, vagyis amint egy programhoz kapcsolódó ablak átkerül egyik kijelzőről a másikra, akkor azt a hangfolyam is követi.

[+]
A DDM Audio azonban otthon is hasznos lehet. A felhozott példa ugyan nagyon sarkított, de a Radeon HD 7970 összesen hat kijelzőt támogat DDM Audio móddal, és mindegyik kijelzőn képes lejátszani egy Blu-ray videót a hozzá rendelt független nyolccsatornás hangfolyammal. Ez valószínűleg nem tömeges igény, de az Eyefinity 2.0 képességeit jól reprezentálja. A kártyára még további három kijelző köthető, melyeken dolgozni vagy akár játszani is lehet, párhuzamosan a másik három kijelzőn futó filmek mellett.
Természetesen az Eyefinity szoftveres szempontból is fejlődik, így az év első két driverében számos extra kerül elő, melyek nagy többsége az aktuális termékeken is kihasználhatók. Ilyen például az egyéni felbontások kreálásának lehetősége, illetve a tálca tetszőleges pozicionálása. Utóbbi végre a középső monitorra helyezhető, úgy, hogy az elsődleges kijelző virtuális pozícióján nem kell változtatni, ami jóval kedvezőbb megoldás, mint a driverben látható logikai megjelenítők helyezgetésével való játszadozás.
A HD3D is továbbfejlődik, mivel a Radeon HD 7970 az első olyan VGA, melyen 3 GHz-es HDMI interfész kapott helyet. Ez lehetőséget biztosít 60 darab sztereó 3D-s, Full HD felbontású képkocka továbbítására projektív módban. Emellett szintén nagy újítás, hogy az új grafikus kártyán a sztereó 3D már DisplayPort bemenettel felszerelt kijelzőkkel is működik hárommonitoros Eyefinity módban.

[+]
Kimenetek tekintetében a Radeon HD 7970 egy dual-link DVI, egy 3 GHz-es HDMI 1.4a, illetve két mini DisplayPort 1.2 HBR2 portot kapott. Az új verziójú HDMI és DisplayPort interfészek segítségével az újdonság egy kimenetről is képes kiszolgálni a 4096x2160-as felbontású monitorokat, ami az aktuális termékeknek legalább kettő interfész befogásával sikerül.
Bemutatkozik a Video Codec Engine
Az AMD a multimédiás feldolgozás szempontjából élen járó UVD 3.0-s motort nem cserélte le, így ebből a szempontból a Tahiti nem szolgál újdonsággal. Bemutatkozik azonban a Video Codec Engine (VCE), mely a H.264-es videók transzkódolását gyorsítja fel. A VCE hasonló céllal született meg, mint az Intel Sandy Bridge termékekben megismert Quick Sync Video motor, ám az AMD két módot is beépített a rendszerbe, így a felhasználó egyénileg dönthet a működésről.


VCE full és hibrid mód [+]
Az úgynevezett full mód a teljes VCE-t használja, vagyis a videó transzkódolásának folyamata egy fix funkciós futószalagon zajlik, így a minőségi szint is meg van szabva. Az Intel Quick Sync Video is így működik, ami egyrészt jó, mert borzalmasan alacsony fogyasztás mellett oldható meg az adott tartalom átkódolása, ám nem biztos, hogy a keletkező anyag minősége mindenkinek megfelelő lesz. Valószínű, hogy a legtöbb felhasználó nem fog panaszkodni, de ki kell szolgálni az igényesebb réteget is, így a VCE támogat egy hibrid módot is. Ilyenkor a rendszernek csak az úgynevezett entropy encoding egysége működik, a többi számítást a CU-k végzik. Az AMD szerint a transzkódolás tipikusan jól párhuzamosítható folyamat, ám az entropy encoding algoritmus ez alól kivétel, így ezt megéri egy célhardverre bízni. Természetesen a VCE full módban alig hat a rendszer teljesítményére, így akár játszani is lehet mellette, ám hibrid módban ez az állítás nem igaz, mivel a CU-k aktívan dolgoznak.
Új multimédiás utasítások
Az AMD a Cypress kódnevű GPU megjelenésével vezette be a SAD (Sum of Absolute Differences) utasítást, amelyet főleg multimédiás alkalmazásoknál lehet használni. Erre épül a vállalat Steady Video szolgáltatása, amely most megkapja a 2.0-s verziószámot, mivel az új generációs architektúra ebből a szempontból is fejlődött. A funkció lényege, hogy megszünteti az egyes videókban a kamera rázkódását, és az új verzió sem változtat ezen a sémán, ám a QSAD utasításnak köszönhetően jelentősen jobb munkát végez, mivel négyszer több adatot dolgoz fel egy órajel alatt, mint az eredeti SAD instrukció. Szintén újítás az MQSAD utasítás, mellyel gyorsabban elkülöníthetők a videóban mozgó objektumok, így a feldolgozás még gyorsabb és precízebb lehet.
DirectX 11.1 és a szoftverek
Eddig nem került szóba, de az új GCN architektúra támogatja a Microsoft DirectX 11.1-es API-ját, mely majd a Windows 8 megjelenésével mutatkozhat be. Ez azt jelenti, hogy a Tahiti ezen képessége jelenleg nem használható ki, de később opció lehet. A DirectX 11.1 egyébként alapvetően optimalizációkat tartalmaz, melyek jó része a mai DirectX 11-es hardvereken is megoldható. Ami új hardvert követel, az a logikai operációk támogatása a render targeteken, illetve a kényszerített mintaszámítás lehetősége a raszterizáló státusz készítésénél. Esetenként értékes újítások lehetnek, de alapvetően nem beszélhetünk forradalmi változtatásokról.
Mindenestre a DirectX 11.1 komoly előrelépés lehet, mivel bevezeti a specifikus kiterjesztéseket. Ezzel a gyártók egyéni funkciókat adhatnak hozzá az API-hoz. Ez egyrészt jó, mert így az AMD elkészítheti a Partially Resident Textures eljárás DirectX-es verzióját, másrészt rossz, mert azt a kiterjesztést csak az új generációs architektúrára épülő Radeonok fogják támogatni. Ez óhatatlanul szegmentálódáshoz vezet, ami nem tesz jót a PC-s játékpiacnak.
A specifikus kiterjesztésekkel egyébként szerencsére nem tér vissza a DirectX 9-ig alkalmazott erőforrás-ellenőrzés, így a DirectX 11.1-es kódok esetében az erőforrást a program futtatásának megkezdésénél kell érvényesíteni, és ilyenkor kell leellenőrizni a specifikus kiterjesztések meglétét is.
Mi lesz a szoftverekkel?
Tekintve az új termék temérdek újítását, felmerül a kérdés, hogy lesznek-e szoftverek, melyek kihasználják ezeket. Az AMD elmondta, hogy a VCE támogatása iránt nagy az érdeklődés, ami alapvetően nem csoda, mivel a multimédiás szoftverek fejlesztői eddig is nagyon nyitottak voltak az újításokra. Ezen a piacon óriási a verseny, így egy-egy extra döntő lehet az adott szoftver vásárlásánál. Az AMD elsősorban az ArcSofttal működik együtt az új multimédiás extrák implementálásánál, de nyilvánvalóan a többi partnertől sem tagadják meg a segítséget.
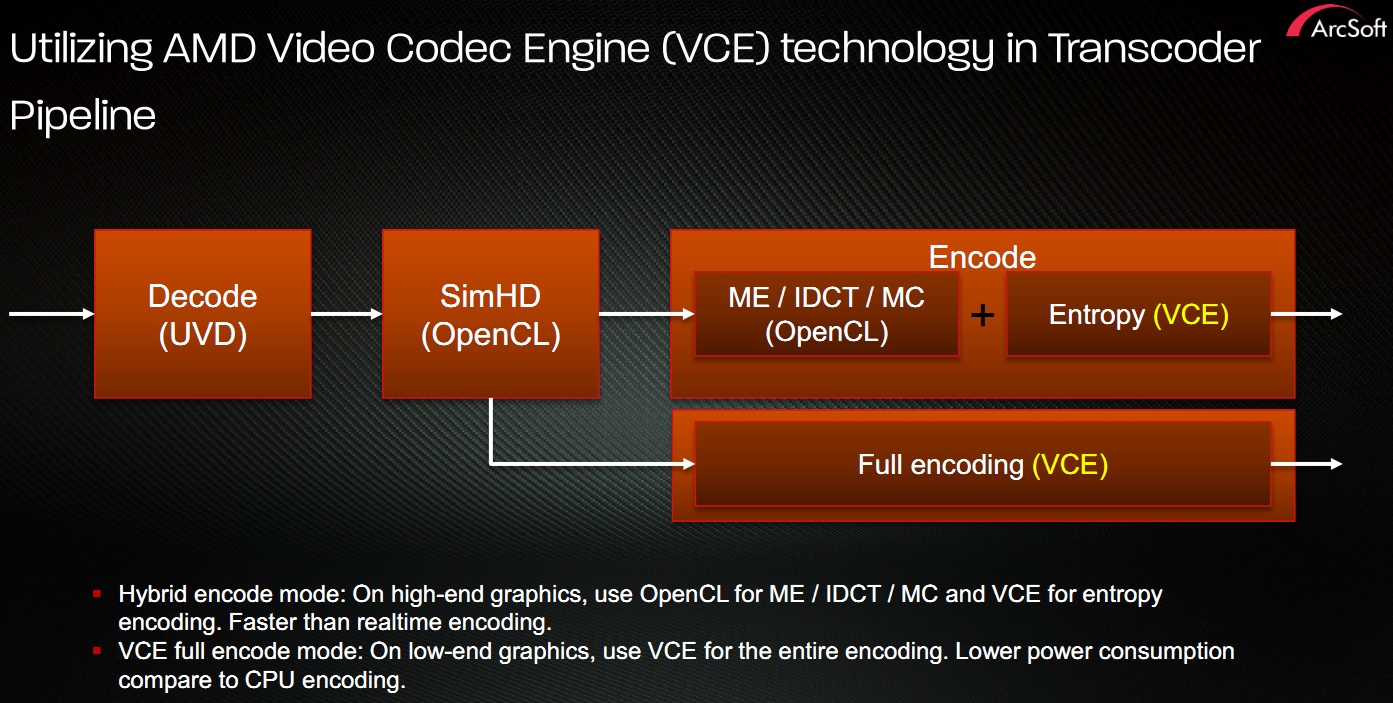
[+]
Komoly hír azonban, hogy készül a Corel WinZip 16.5, mely a fájlok tömörítését bízza majd a GPU erejére. Az érintett vállalatok az OpenCL felülettel gyorsítják a WinZip motorját, és a rendszer számos konfiguráció mellett fog működni, a Fusion APU-k pedig kiemelt optimalizálást kapnak a hatékonyabb működés érdekében.

[+]
Konklúzió
Ennyi adat után nehéz értékelés nélkül befejezni az elemzést. Az világosan látszik, hogy az AMD az új architektúra fejlesztésénél mindent beleadott. A legtöbb helyre kompromisszummentes megoldásokat kerestek, amellett, hogy a cGPU fejlesztésénél nagyon spórolni kellett a tranzisztorokkal, így több helyen lehet találkozni okos trükkökkel. A technikai képességekre, illetve az újításokra biztos nem lehet panasz, így a Radeon HD 7970 jelenleg a piac legokosabb terméke igazán innovatív technológiákkal és szolgáltatásokkal. A teljesítmény elemzése nélkül azonban hivatalosan nem értékelnénk a rendszert, így később egy teszttel is jelentkezünk, melyben a gyakorlati működést vizsgáljuk. Addig is csak annyit tudunk mondani, hogy az új architektúra nagyon tetszetős képet fest magáról.
Abu85



