Hirdetés
A Cayman felépítése

Most már biztos, hogy az AMD Radeon HD 6000-es sorozata egészen érdekes generáció lesz. A termékcsalád kódneve egységesen Northern Islands lett, ám az architektúra közel sem egységes. A nemrég megjelent Barts lapka esetében sokan nem értettek egyet az elnevezéssel, de a vállalatnak nyomós indoka volt a HD 6800-as jelzés mellett. Most, hogy megjelent a generáció leggyorsabb GPU-ja, megérthetjük, hogy mi áll az eltolt számozás mögött. A Cayman a Barts nevű fejlesztéssel ellentétben teljesen új architektúrára épül, amiről a HD 6900-as jelzés informálná a felhasználót. Valószínűleg a legtöbb vásárló ezt nem fogja átlátni, hiszen a fejlesztésekkel kapcsolatban nem sokan követik az eseményeket, de az AMD mindenképpen ki akarta hangsúlyozni, hogy az új GPU technikailag az aktuális generáció legfejlettebb megoldása lesz.
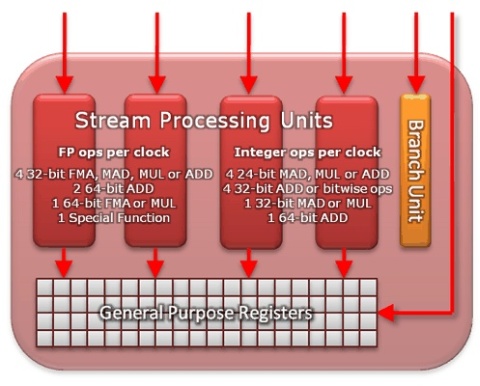
A 40 nm-es gyártástechnológián készülő Cayman lapkával hatalmasat lépett előre az AMD, mivel a többéves R600 architektúra utolsó, és egyben legfontosabb részeleme történelem lett. Korábban már említettük, hogy a vállalat hosszú távú projektként tekintett az R600-ra, és ez be is igazolódott, hiszen a rendszer kisebb-nagyobb módosításokkal ugyan, de öt generáción át megfelelt az igényeknek. Semmi sem tarthat azonban örökké, így lassan újra kellett gondolni az alapokat, hiszen ez a fejlődés velejárója. Az előző generációs Radeonok sarkalatos pontja volt a 4 darab skalár és 1 darab speciális végrehajtó egységgel működő szuperskalár shader processzorok alkalmazása. Ez az elgondolás úgynevezett 1+1+1+1+1 co-issue képességű, aminek köszönhetően az egység egy órajel alatt öt egymástól nem függő utasítást képes végrehajtani. A függőség kezelése persze fontos szempont, hiszen két olyan utasítás nem hajtható végre párhuzamosan, amiből az egyik az előző instrukció eredményére alapoz. Az AMD a futtatásra kerülő shader kódokban lévő függőségek kezelését a driver fordítójára bízta. A meghajtó az egymás után következő utasításokból optimalizált végrehajtási sorrend felállítása után hosszú és komplex, főleg 5 matematikai és 1 vezérlő utasításból álló VLIW mintákat hoz létre. Ezen utasításszavakkal történik szuperskalár shader processzorok táplálása. Azonnal észrevehető, hogy a hardver már eleve nagymértékben párhuzamos munkavégzésre optimalizált kódot dolgoz fel, így a chip működésének hatékonysága főleg a driver fordítómodulját író rendszerprogramozóktól függ. A felépítés előnye, hogy az ütemezés tulajdonképpen a VLIW minták generálásával statikusan van megoldva, vagyis erre nem kell tranzisztort költeni, így a hardver pusztán a minták végrehajtásának sorrendjéről dönt. Az Evergreen generáció esetében további okosságokat fundáltak ki a mérnökök, mivel a HD 5000-es Radeonok szuperskalár shader processzora még akkor is képes egyszerre futtatni egy MUL és egy ADD utasítást, ha az utóbbi számítás az előbbi eredményétől függ. A cél természetesen mindig a hatékonyabb feldolgozás biztosítása a lehető legkevesebb tranzisztor felhasználása mellett. A Cayman esetében is ezen az úton haladt a fejlesztés, ami újszerű szuperskalár shader processzorokat eredményezett. A rendszerből eltűnt a dedikált speciális végrehajtó, aminek a kihasználására ugyan nagyon törekedett a shader fordító, de sokszor ez nem volt lehetséges. Az új feldolgozó tehát a 4 darab skalár egységből áll. Ezek technikailag ugyanolyan képességűek, támogatják a bitszintű utasításokat és az IEEE754-2008-as lebegőpontos szabványt, továbbá a komplexebb feladatok erejéig össze is tudnak kapcsolódni egymással. A lebegőpontos számláló utasítások tekintetében az új szuperskalár shader processzor négy darab 32 bites FMA, MAD, MUL vagy ADD utasításra képes, dupla pontosság mellett pedig két darab 64 bites ADD és egy-egy 64 bites FMA vagy MUL instrukció hajtható végre. A speciális, azaz a trigonometrikus és a transzcendens (EXP, LOG, RCP, RSQ, SIN, COS) utasítások mostantól három vagy négy skalár egység összevonásával lehetségesek, míg a fixpontos számítások közül négy darab 24 bites MAD, MUL vagy ADD, szintén négy 32 bites ADD vagy bitszintű logikai művelet, egy 32 bites MAD vagy MUL, illetve egy 64 bites ADD instrukció alkalmazható.
[+]
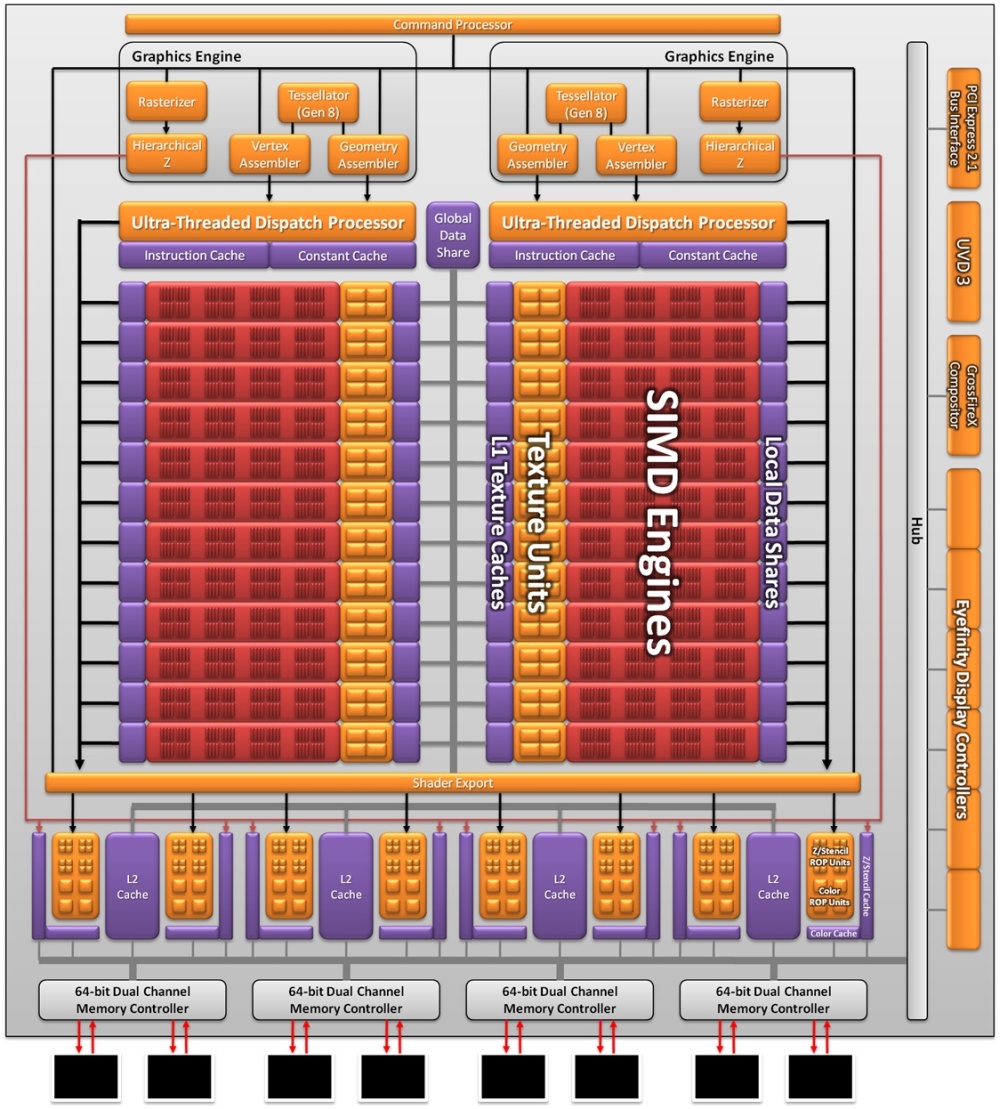
A rendszer továbbra is nagyon függ majd a shader-fordítótól, amit a változások miatt komolyan át kell alakítani. Az AMD itt nem áll a helyzet magaslatán, ám a következő driverekben további optimalizációkat kap majd a Cayman. A változások hatására összességében nő a rendszer általános kihasználtsága, miközben az új szuperskalár shader processzor egységnyi helyigényhez viszonyított teljesítménye 10%-kal nőtt az előző generációhoz képest. A dedikált speciális végrehajtó eldobásával az ütemezés és a regiszterkezelés is egyszerűbb lett, mivel a skalár egységek képességei megegyeznek. Az általános felépítés tekintetében a Cayman egy shader tömbben 16 darab szuperskalár shader processzort rejt el, melyhez 32 kB-os Local Data Share, valamint egy 8 kB-os, csak olvasható gyorsítótárral rendelkező textúrázó blokk tartozik. Utóbbi egyébként négy darab Gather4-kompatibilis csatornát alkalmaz, melyek csak szűrt mintákkal térnek vissza. Az interpoláció a HD 5000-es sorozathoz hasonlóan emulált, ám a Barts lapka esetében bemutatkozó optimalizációk jelen vannak, így relatíve kevés erőforrás szükséges az interpolálás végrehajtásához. Az új GPU-ban összesen 24 darab shader tömb van, amelyek két blokkra vannak szétosztva. A két darab shader blokk nemcsak különálló Ultra-Threading Dispatch Processzorra támaszkodik, hanem a setup motorjuk is független. A tömbök közötti adatmegosztást továbbra is egy nagysebességű, 64 kB-os (Global Data Share) tárterület biztosítja.

[+]
A blokkdiagramon látható, hogy a legnagyobb változás a setup motort érte, ugyanis az új GPU két darab teljesen elkülönülő egységgel dolgozik. Ennek köszönhetően a rendszer órajelenként két háromszöget dolgoz fel. A feldolgozó motoronként elhelyezett tesszellációs egység a Barts kódnevű lapkában bemutatkozó megoldás izmosabb verziója. A fix funkciós egység kiegészült egy új technikával is, ami lehetővé teszi, hogy a magas tesszellációs faktorral rendelkező felületeket lementse a fedélzeti memóriába, így azokat a következő képkockák számítása alatt elég betölteni, amivel megspórolható a felbontással eltöltött idő. Ez a megvalósítás csak akkor hatékony, ha a memória nem túl gyors elérése még mindig gyorsabb megoldás a háromszögek felbontásánál. Persze érdemes észben tartani, hogy egy méretesebb felület rengeteg helyet foglal, vagyis óvatosan kell bánni az opcióval. Az AMD ezt a driverből fogja koordinálni, megkeresve a programban azokat a jeleneteket, ahol előnyös lehet a felületek kimentése. Az erre fenntartott memóriaterület is szabályozható, így a rendszer lényegében a program igényeihez igazítható. A raszter motor órajelenként 16 képpontot dolgoz fel, ami a teljes lapkára nézve 32 pixelt jelent, a renderelés pedig 2 x 2 pixeles tömbökön zajlik. További újítás a tile-based load balancing, ami a hierarchikus Z algoritmus túlterhelését akadályozza meg. A rendszer a raszterizálást hierarchikus Z nélkül hajtja végre a teljes képkockát több egyenlő méretű, viszonylag kicsi mozaikra osztva. Természetesen itt számos szabályt be kell tartani biztosítva a renderelés sorrendjét. A hierarchikus Z algoritmus a mozaikokon lesz lefuttatva, amelyeket tovább lehet küldeni, vagy éppen el lehet dobni, ha nem tartalmaznak látható információt. Hasonló elvet alkalmaz az NVIDIA is a Fermi architektúránál. Az elgondolás a teljesítmény tekintetében messze nem a legjobb, de még mindig jobb bevállalni ezt, minthogy a hierarchikus Z motor túlterhelődjön, ami összességében sokkal nagyobb problémát jelent.
A cikk még nem ért véget, kérlek, lapozz!