- Igencsak szerény méretekkel rendelkezik az Aetina Xe HPG architektúrás VGA-ja
- Miniképernyős, VIA-s Epomaker billentyűzet jött a kábelmentes szegmensbe
- Különösen rendezett beltér hozható össze a Cooler Master új házában
- A középkorra és a pokolra is gondolt az új AMD Software
- Új gyártástechnológiai útitervvel állt elő a TSMC
Hirdetés
-


Lenovo Essential Wireless Combo
lo Lehet-e egy billentyűzet karcsú, elegáns és különleges? A Lenovo bebizonyította, hogy igen, de bosszantó is :)
-


A Video AI lehet a One UI 6.1.1 ütőkártyája
ma Vagy hogy fogja a mesterséges intelligencia manipulálni a mozgóképeket?
-


Konzolokra is megjelenik a Deathbound
gp A PC-s verzió mellett megkapjuk a teljes kiadást PlayStation és Xbox platformokra is.






Új hozzászólás Aktív témák
-
#5301
 Petykemano
veterán
S_x96x_S
#5299
Petykemano
veterán
S_x96x_S
#5299
Petykemano
veterán
válasz
 S_x96x_S
#5299
üzenetére
S_x96x_S
#5299
üzenetére
aZ x86 dekóder limitációról:
"For a while we thought variable-length instructions were really hard to decode. But we keep figuring out how to do that. You basically predict where all the instructions are in tables, and once you have good predictors, you can predict that stuff well enough. So fixed-length instructions seem really nice when you're building little baby computers, but if you're building a really big computer, to predict or to figure out where all the instructions are, it isn't dominating the die. So it doesn't matter that much."
Találgatunk, aztán majd úgyis kiderül..
-
#5302
Petykemano
veterán
S_x96x_S
#5297
Petykemano
veterán
válasz
S_x96x_S
#5297
üzenetére
Kétféle véleményt láttam megjelenni:
1) "Báháháhá, az SMT letiltásával nyert egyszálas teljesítmény x86 utolsó halálhörgés kísérte próbálkozása, mielőtt az Arm végleg letaszítaná a trónról egyszálas teljesítményben különösen ha figyelembe vesszük a perf/W mutatót is."
2) Az elmúlt években a legnagyobb igyekezet ellenére is több SMT-vel kapcsolatba hozható sebezhetőség felbukkant. A szálak között megoszott erőforrások, cache-ek, bufferek, stb olyan sebezhetőséget rejtenek - most vagy akár a jövőben -, hogy bölcsebb és biztonságosabb már élből tiltani virtualizált környezetben, ahol nem biztosítható, hogy ugyanaz a mag biztosan ne kerülhessen kiosztásra két különböző szervezet vagy projekt számáraÉrdekes egyébként a megoldás.
a GCP-ben vCPU-t bérelsz, ami gyakorlatilag ez hardveres szálat jelent.
Állítólag az Amazonnál hardveres magot bérelsz, az SMT-t ingyen adják.Találgatunk, aztán majd úgyis kiderül..
-
#5303
 HSM
félisten
Petykemano
#5288
HSM
félisten
Petykemano
#5288
HSM
félisten
válasz
 Petykemano
#5288
üzenetére
Petykemano
#5288
üzenetére
"ez utóbbi tulajdonképpen miben különbözik attól, mintha mondjuk egy mag áramtalanítaná az AVX512 vagy egyéb részeit (regisztereket, cache-t, ALU-kat stb), amit épp nem használ"
Abban, hogy ami ott van, azt nem tudod áramtalanítással olyanná tenni, mintha nem lenne ott. Pl. a mag többi részét is hozzá kell igazítani, a jelutakat is hosszabbítja, így kikapcsolva is indirekten növeli a többi rész fogyasztását.Ez az OS tudta nélküli kis mag használat viszont hasznos lehet áramfogyasztás csökkentő célokra, az Arm-féle megvalósításnak is volt ilyen működési módja [link] . Ebben kevesebb elvérzési lehetőséget látok, mint a konkurens elképzelésben. Bár a leghasznosabb egy kapcsolható megoldás lenne, ha működhetne automatikus átkapcsolással, de ha olyan a munkafolyamat, mondjuk egy reboot árán átkapcsolhatnád, hogy elérhető legyen minden magod külön külön a takarékos mag utasításkészletével.
Egyébként vicces valahol (miközben mérnöki szempontból tökéletesen érthető és szükségszerű), hogy a mai napig előfordulnak ilyen problémák a nem heterogén felépítés miatt. Egy CCX itt, egy CCX ott, egy erős mag itt, egy gyengébb mag ott... És ezek még viszonylag hasonló képességű holmik voltak mondjuk egy tervezett 8+16-os Alder Lake utódhoz képest...
 Lesz itt felfordulás még emiatt szvsz.
Lesz itt felfordulás még emiatt szvsz. 
#5289 Petykemano : A CMT koncepciója szvsz jó volt. A Bulldozer piaci szerepléséhez más, szerencsétlen körülmények is hozzájárultak. Egyébként logikusnak tűnik az osztott FPU az AVX512-re. Kérdés, ezzel nem-e dobjuk kukába a használatának előnyeit. Illetve az első generációs Zen fele szélességű FPU-ja sem bizonyult rossz kompromisszumnak, lehet lenne értelme az AVX512-nél is bevetni, elkerülendő a mag túlzott "kiszélesedését".
-
#5304
 S_x96x_S
őstag
Petykemano
#5301
S_x96x_S
őstag
Petykemano
#5301
S_x96x_S
őstag
válasz
Petykemano
#5301
üzenetére
> aZ x86 dekóder limitációról:
> "For a while we thought variable-length instructions
> were really hard to decode. But we keep figuring out how to do that.azért nem könnyű :-)
A probléma igazából az, hogy azt a trükköt amit az X86 -nál kitalálnak, az ARM dekodolásánál is fel lehet használni .. vagyis az előny megmarad. ( az én laikus - naiv és leegyszerűsített nézőpontom szerint)
az én laikus - naiv és leegyszerűsített nézőpontom szerint)a ZEN3 akár 6 dekodólt utasítást is végre tudna hajtani órajelenként,
de csak 4-et tud dekódolni ..
Ha megvan a micro-op cache-ben, akkor jó .. ha nem, akkor meg vár a dekodolóra."The throughput of the Zen 3 is now as high as six instructions per clock cycle. This may be six integer instructions or six floating point/vector instructions, or any mix of these. This is a record so far. It can do three memory operations per clock. The clock frequency is 3.8 GHz with boosts up to almost 5 GHz.
A serious bottleneck is a decoding rate of 4 instructions or 16 bytes per clock. To compensate for this, the Zen 3 has a micro-op cache with 4096 entries after the decoder.The bottleneck in the decoder appears to be difficult to overcome. This is a consequence of the messy x86 code structure where instructions can have any length from 1 to 15 bytes, and it is complicated to determine the length of each instruction. Intel processors have the same bottleneck and the same decoding rate. The programmer must make sure the critical part of a program fits into this micro-op cache if you want to get the maximum throughput. It is important to avoid loop unrolling where possible in order to economize the use of the micro-op cache. (The Clang compiler often makes excessive loop unrolling).
The AMD Zen 3 has a higher instruction-per-clock throughput and a bigger micro-op cache than the best current Intel processors. This makes the Zen 3 the best choice for many applications. The Zen 3 does not support the AVX512 instruction set, however. Therefore, Intel processors are likely to be faster for software that can utilize the 512-bit vector instructions. AMD have focused on higher throughput where Intel have focused on larger vectors.
"
https://www.agner.org/forum/viewtopic.php?t=56Kérdés, hogy a ZEN4-nek milyen széles lesz a dekódere.
még ha meg is duplázzák 8-ra - mint az M1-nél ..
az ARM-et mindig sokkal egyszerűbb lesz skálázni dekodolás szempontjából.Mottó: "A verseny jó!"
-
#5305
S_x96x_S
őstag
Petykemano
#5302
S_x96x_S
őstag
válasz
Petykemano
#5302
üzenetére
> ARM .. X86 ... SMT
igen .. a célpiac kulcs
más a piac -> más az optimális kiépítés.
Az ARM Server chipek (jelenleg) tisztán Cloud fókuszúak ..
Ezért itt az egyszállúság előny.
Az X86 piaca vegyes .. itt az SMT2 a sweet spot .. ( céges belső szerverek vs cloud )Az IBM-es POWER chipek tisztán belső céges gépek ( van valami minimális cloud, de nem jellemző )
itt már --> SMT2, SMT4, SMT8Mottó: "A verseny jó!"
-
S_x96x_S
őstag
AMD vs Intel Market Share ( benchmark alapon )
https://www.cpubenchmark.net/market_share.html
https://news.ycombinator.com/item?id=27553451Mottó: "A verseny jó!"
-
#5307
Petykemano
veterán
S_x96x_S
#5306
Petykemano
veterán
válasz
S_x96x_S
#5306
üzenetére
Figyelemre méltó ugrás a notebookok terén - még ha ez csupán benchmarkokat jelent is, akkor is arra utal, hogy több az AMD noti, többet tesztelnek, talán több van a polcokon is és többen veszik meg kipróbálni, hogy milyen. A benchmarkból persze mindenképp csak az enthusiast réteg látszik.
Találgatunk, aztán majd úgyis kiderül..
-
#5308
S_x96x_S
őstag
Petykemano
#5307
S_x96x_S
őstag
válasz
Petykemano
#5307
üzenetére
> notebookok terén
a DigiTimes szerint az Intel notebook-os tortáját (~piaci részesedését) nem csak az AMD - hanem az Apple is eszegeti.
"Intel is expected to lose nearly 50% of its orders from Apple in 2021 and will eventually obtain no orders from the client. Losing Apple's 10% market share and seeing AMD staying firmly with another 10%, Intel's share in the notebook market is likely to slip below 80% in 2023, the sources noted." ( fizetős DigiTimes alapján - macroumors szemlézte)
Most az Intelre már nagyobb fenyegetést jelent az ARM (Apple silicon)
mint az AMD, azon egyszerű ok miatt, hogy az AMD-től sokkal egyszerűbb visszaszerezni a piacot a szoftver kompatibilitás miatt.De ha CPU ISA-t is váltanak az ügyfelek,
akkor onnan nehezen váltanak vissza Intelre. ( X86-ra)Mottó: "A verseny jó!"
-
S_x96x_S
őstag
32 magos szerver CPU-k .. (1 socket )
STH: Intel Xeon Gold 6314U v AMD EPYC 7543P the 1S 32-core Optionsa fekete az AMD ..
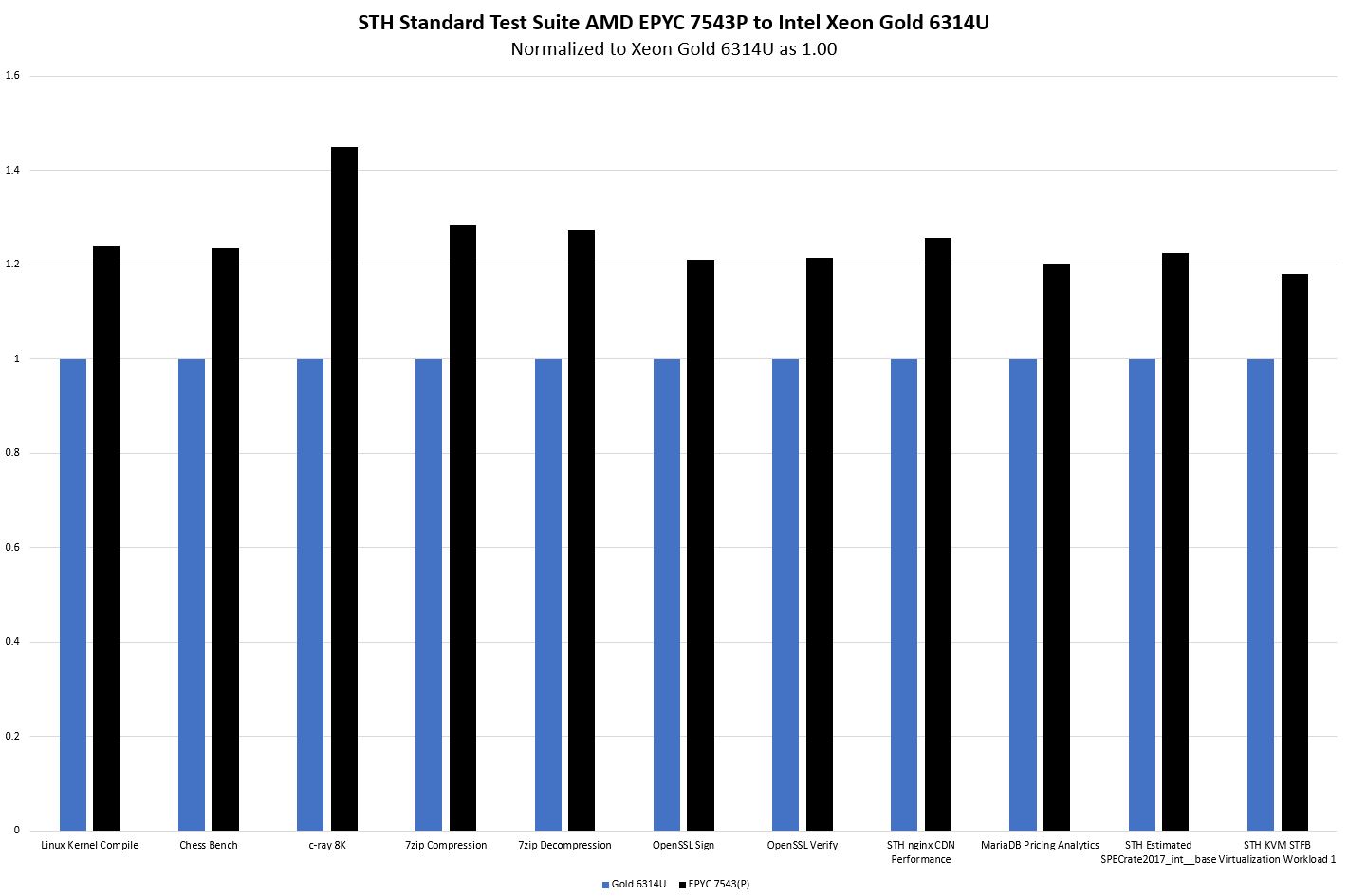
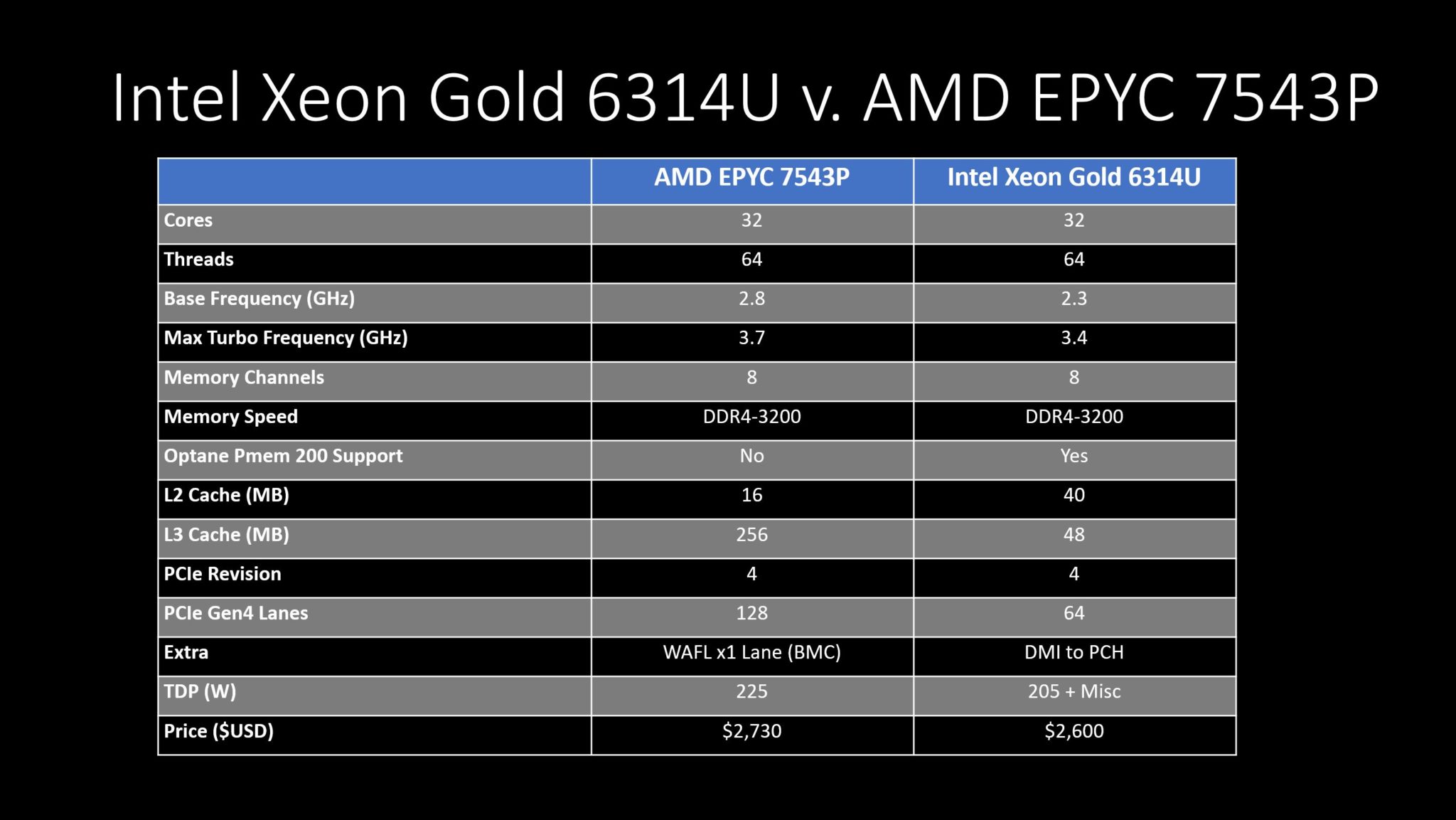
"Overall, Intel can claim a lower price by almost 5%. AMD can, however, claim that it has 20-33% better performance as well as additional PCIe Gen4 connectivity. Intel has its newer instructions and Optane PMem 200 support. Still, for the majority of buyers, it seems fairly clear that at list price, AMD has a better value proposition here."
"Overall, Intel made a lot of headway in this generation. At list pricing, we would probably recommend that the majority of our readers look at the AMD EPYC 7543P over the Intel Xeon Gold 6314U. AMD has more performance with the same core count, thus more performance per core. In other segments, having an AMD EPYC platform means more PCIe Gen4 connectivity. Still, there are many single-socket servers that have 0-1 expansion cards and 1-4 drives where Intel is now very competitive."A verseny jó
Mottó: "A verseny jó!"
-
#5310
Petykemano
veterán
Petykemano
veterán
érdekes olvasmány arról, hogy miért döntött az AMD interposer helyett az IFOP megoldás mellett
Talán azt is magyarázza kicsit, hogy miért nincs L4$ és az AMD miért inkább az L3$-t növelgeti. az IFOP késleltetése viszonylag magas és linkenként csak 55GB/s a sávszélessége. Azt gyanítom, hogy nagyon kevés hatása lett volna, ha erre az alapra építenek rá egy az IOD-ban található L4$-t. Nem lett volna elég alacsony a késleltetés és a sávszélesség is szűk lett volna.
Olvastam a hétvégén egy cikket az EMIB-ről is. Az tulajdonképpen egy embedded interposer, ami a chipek széleit köti össze, ellentétben a hagyományos interposerrel, amire az összes lapkát rá kell ültetni - és emiatt az EPYC-nél túlságosan nagy interposert kellett volna alkalmazni.
Én azt gondolom, hogy 1000mm2-es interposert ezután se fognak használni.
Szerintem a következő lépcső a TSMC LSI nevezetű technológiájáa, ami megfelel az intel EMIB-nek.Az IFOP megoldás késleltetése és energiafogyasztása magas. A megnövelt méretű L3$ célja éppenséggel lehet az, hogy minél kevesebb adatot kell mozgatni az IFOP-on (CCD<->IOD<->DDR) keresztül.
Az LSI használata csökkentené a késleltetést és lehetővé tenné a CCD és az IOD közötti szélessávú kapcsolatot. Nem tudom mennyit, de olyasfélét, mint amit egy HBM igényel. (Természetesen az LSI használata lehetővé tenné azt is, hogy a CCD-k egyenként HBM-et kapjanak)
Azt viszont nem tudom, hogy ilyen szélessávú hidak használata - azon kívül, hogy lehetővé tenne egy L4$ kialakítását az IOD táján - vajon mire adna lehetőséget, vajon mit lehetne kezdeni vele?
Az AVX-ről (AVX512-ről) mondják, hogy nagyon cache és memóriaintenzív. Ami nem meglepő, hiszen sok adaton elvégzett vektorművelet. Ez valószínűleg egy dimenzióval fokozódik, ha mátrixműveletekről is beszélünk.
Lehetséges volna, hogy a zen4-be kerüli AVX512 támogatás magával hozza a IFOP cseréjét LSI-re?
Találgatunk, aztán majd úgyis kiderül..
-
#5311
 paprobert
senior tag
Petykemano
#5310
paprobert
senior tag
Petykemano
#5310
paprobert
senior tag
válasz
Petykemano
#5310
üzenetére
Az IF törvényszerűen követi az egységnyi idő alatt egy vezetéken átküldhető adatmennyiség rekordját, tisztes távolságból. Ha ebben fejlődés van, minden interconnect képes gyorsulni.
"Lehetséges volna, hogy a zen4-be kerüli AVX512 támogatás magával hozza a IFOP cseréjét LSI-re?"
Szerintem az AMD meg akarja úszni hogy TSMC-only technológiára építse fel az egész portfólióját, annak ellenére hogy egyébként szimbiózisban vannak jelenleg. A 3D cache egy viszonylag kockázatmentes projekt ehhez képest.
Az új foglalattal lesz új tracing topológia is, azaz ha nagyobb sávszélességgel terveznek, a lehetőség meglesz a kiépítésére házon belül is.[ Szerkesztve ]
640 KB mindenre elég. - Steve Jobs
-
S_x96x_S
őstag
Linux: "Pass-Through DMA controller for EPYC processors"
AMD Continues Working To Mainline Their PTDMA Driver For Linux
https://www.phoronix.com/scan.php?page=news_item&px=AMD-PTDMA-Linux-Driver-v10"The PTDMA hardware allows for high bandwidth memory-to-memory and I/O copy operations. Now mid-way through 2021 that AMD PTDMA Linux driver remains in the works and is up to its tenth driver revision while waiting to see if it's now ready for mainline or further changes are still deemed necessary.
This AMD PTDMA controller and driver is optimized for use with AMD Non-Transparent Bridge (NTB) devices and not general purpose DMA. NTB is used for in connecting multiple separate memory systems to the same PCI Express fabric. The PTDMA driver supports the 0x1498 (PCI device ID) controller found within EPYC processors since 7002 "Rome"."
Mottó: "A verseny jó!"
-
#5313
Petykemano
veterán
paprobert
#5311
Petykemano
veterán
válasz
 paprobert
#5311
üzenetére
paprobert
#5311
üzenetére
"Az IF törvényszerűen követi az egységnyi idő alatt egy vezetéken átküldhető adatmennyiség rekordját, tisztes távolságból. Ha ebben fejlődés van, minden interconnect képes gyorsulni."
Nem teljesen értem ezt a megjegyzést. De ez nem biztos, hogy Te hibád, lehet, hogy én vagyok alul- vagy félretájékozott. Távol van tőlem, hogy magamat ezeknek a technológiáknak a beható ismerőjének tüntessem fel, épp csak morzsákat csipegetek.Tudomásom szerint az Infinity Fabric egy linkje egy 32bit széles busz viszonylag magas frekvencián. Tehát persze, ahogy ezt a frekvenciát tudják növelni, úgy nőhet a sávszélesség is és persze a magas frekvencia biztosan segít a viszonylag nagy távolságban levő chipek közötti késleltetés letornászásában.
Ez a megoldás költséghatékony, mivel nincs gigantikus interposer.
Viszont - tudomásom szerint a magas frekvencia miatt - az adattovábbítás költsége (áramfelvétel és hő) magas (2pJ/bit)Felfogásom szerint a régi jó interposer azt tette lehetővé, hogy
- vékony busz helyett széles buszt lehessen használni, ami adja a sávszélességet
- magas helyett alacsony frekvencián lehessen használni, ami jelentősen csökkenti az energiaigényt
- a chipek egymáshoz közel való ültetése pedig javít a késleltetésenUgyanezt teszi lehetővé az EMIB és az LSI is, úgy, hogy nem teszi szükségessé a 1000mm2-es interposer használatát egy EPYC esetén.
"Szerintem az AMD meg akarja úszni hogy TSMC-only technológiára építse fel az egész portfólióját, annak ellenére hogy egyébként szimbiózisban vannak jelenleg. A 3D cache egy viszonylag kockázatmentes projekt ehhez képest. Az új foglalattal lesz új tracing topológia is, azaz ha nagyobb sávszélességgel terveznek, a lehetőség meglesz a kiépítésére házon belül is."
Nem tudom, ezt ma még meg lehet úszni?
A célt érteni vélem, hogy ne legyen teljes függőség. De ezzel arra utalsz, hogy az AMD nem fogja használni a TSMC packaging technológiát, hanem sajátot fejleszt?Találgatunk, aztán majd úgyis kiderül..
-
#5314
paprobert
senior tag
Petykemano
#5313
paprobert
senior tag
válasz
Petykemano
#5313
üzenetére
A moduláció típusa, a vezeték két végén lévő en- és decoder karakterisztikája, ill a vezetékek száma adott esetben, mind tud fejlődni. Networkingnél látjuk, ami ennek az élvonalában halad, hogy rengeteget volt a fejlődés azonos fizikai médiumon keresztüli adatátvitelben az elmúlt években, azaz van tér a fejlődésre.
Vagy másik példa erre a PCIe, amely alatt az összes cég, ill. konzorcium próbálja propagálni a saját zárt(abb) szoftverrétegét.
Vagy pl. kis csúsztatással a GDDR6X is emiatt gyorsult."De ezzel arra utalsz, hogy az AMD nem fogja használni a TSMC packaging technológiát, hanem sajátot fejleszt?"
Csak arra utalok, hogy az AMD akkor fogja használni a TSMC polcról levehető, pénzbe kerülő technológiáját, ha kikerülhetetlen falba ütközik a további skálázásban a saját rendelkezésre álló eszközeivel.
640 KB mindenre elég. - Steve Jobs
-
#5315
Petykemano
veterán
paprobert
#5314
Petykemano
veterán
válasz
paprobert
#5314
üzenetére
"Csak arra utalok, hogy az AMD akkor fogja használni a TSMC polcról levehető, pénzbe kerülő technológiáját, ha kikerülhetetlen falba ütközik a további skálázásban a saját rendelkezésre álló eszközeivel."
Értem és ezzel egyet is értek. Én magam is felvetettem azt a kérdést, hogy tök jó, hogy nagyon magas sávszélesség állna rendelkezésre a CCD és az IOD között és az L4$ is papíron jól hangzik, de vajon ténylegesen mennyit profitálna belőle a cpu?Szerintem egyébként az energiafogyasztás terén szorít a cipő.
Egyrészt a 2pJ/bit sok, ehhez képest kísérleti jelleggel votl már 0.56pJ/W is TSMC+ARm alapon
Másrészt a milan Epyc Idle fogyasztása 100-110W. [link]De ha ezt megoldja csak az IOD alacsonyabb csíkszélessége és/vagy a nagyobb L3$, az is jó lehet.
Találgatunk, aztán majd úgyis kiderül..
-
#5316
Petykemano
veterán
Petykemano
veterán
AMD Ryzen Embedded - V3000
Zen 3 (6 nm) - FP7r2
- up to 8 Cores / 16 Threads
- 20x PCIe 4.0 lanes (8x dGPU)
- 4x DDR5-4800 (ECC)
- two 10G ethernet PHYs
- 2x USB 4.0
- 15-30 W and 35-54 W models
- up to 12 CUs (RDNA2)(~Rembrandt)
[link]Találgatunk, aztán majd úgyis kiderül..
-
S_x96x_S
őstag
AM4 - igéretes otthoni gép ..
sajnos csak Gen3-as M.2 -e van ( nem Gen4 ) de minden másban majdnem tökéletes.
( viszont 4 DDR RAM! és egy mini PCIe Kártyahely )"DeskMini Max is a 9L desktop PC equipped with an ASRock X300-ITX motherboard that supports a wide range of AM4 Ryzen processors from 2000 up to 5000 series (maximum 105W). It is worth noting that this is not a standard Mini-ITX motherboard, but a custom extended version that packs four full-sized memory modules as well as a full-length PCIe interface."
https://videocardz.com/newz/asrock-deskmini-max-features-mysterious-amd-radeon-p120-itx-graphics-card



Mottó: "A verseny jó!"
-
#5318
 awexco
őstag
Petykemano
#5316
awexco
őstag
Petykemano
#5316
awexco
őstag
-
#5320
awexco
őstag
Petykemano
#5319
awexco
őstag
válasz
Petykemano
#5319
üzenetére
Ha nem lesz nagyon kiherélve az igp elég frankó laposok lesznek belőle .
Bár fura , h nem 5nm-en jön ... Jövőre gyárt ott az amd is úgyrémlik.I5-6600K + rx5700xt + LG 24GM77
-
#5321
 -=MrLF=-
senior tag
Petykemano
#5316
-=MrLF=-
senior tag
Petykemano
#5316
-=MrLF=-
senior tag
válasz
Petykemano
#5316
üzenetére
tegnap jött cikk is: [link]
protonmail.com Secure Email Based in Switzerland . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . startpage.com The world's most private search engine from Netherland
-
#5322
Petykemano
veterán
-=MrLF=-
#5321
-
#5323
Petykemano
veterán
Petykemano
veterán
-
#5324
S_x96x_S
őstag
Petykemano
#5323
S_x96x_S
őstag
válasz
Petykemano
#5323
üzenetére
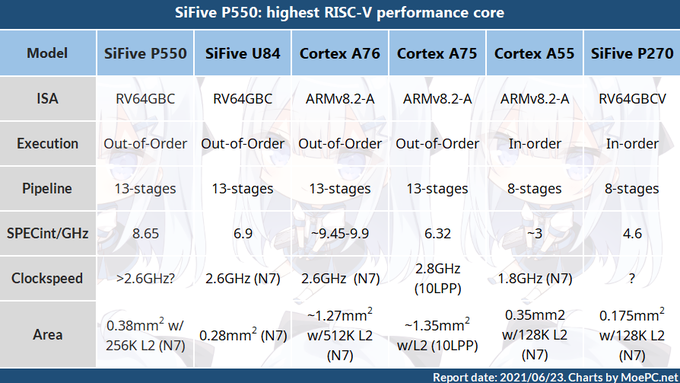
hát igen ... keményen jön fel a RISC-V is.
Ráadásul a SiFive nem csak az Intel 7nm-en nyomul
hanem TSMC (5nm! )
és a Samsung-al is együtt dolgozik.persze ha az Intel megveszi .. ki tudja mi lesz a Samsung és a TSMC-s együttműködéssel.
Ráadásul az Intel 2022 -re igéri a 7nm-en , a saját chipjét 7nm-en meg 2023-ra.
"The time scale for this platform coming to market is quite interesting. Despite Intel recently committed to bringing its 7nm to market in 2023 with the compute tile for its Meteor Lake processor as its first 7nm product, we’re being told that Horse Creek silicon will be ready in 2022, which would make Horse Creek its first 7nm product. For what it is worth, it’s unlikely that the Intel RISC-V solution is tile-based, but it might be easy enough to bring a small RISC-V chip development platform to market around then. The chip is likely to be small, so that might work in favor of its costs as well. A question does remain as to whether Intel’s involvement here is purely in the hardware, or whether there will be an Intel-based software stack to go along with it."
Mottó: "A verseny jó!"
-

Cathulhu
addikt
-
#5326
S_x96x_S
őstag
Petykemano
#5322
S_x96x_S
őstag
válasz
Petykemano
#5322
üzenetére
> .. hogy 65-95W-os TDP keretben az IGP frekvencia tudna-e feljebb
> menni? Mondjuk esetleg 2.5-2.7Ghz-re.talán ..
valami okosabb chip-en belüli smartshift / GPUturbo kell ..
a PS5-ben ( ~ AMD Design )
jelenleg 2.23 Ghz a beállított "tető" .. és az N7-es technológia
Hátha az N6-os egy picivel jobb lesz. 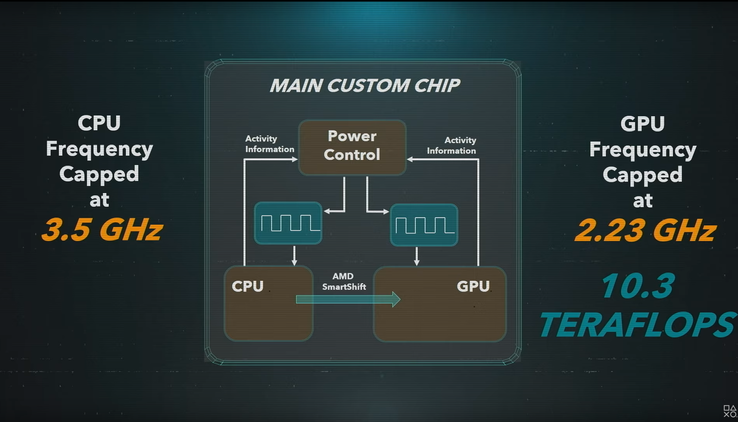
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
válasz
 Cathulhu
#5325
üzenetére
Cathulhu
#5325
üzenetére
> SiFive-nak van nem open source ipje?
az én értelmezésem szerint
A RISC-V IP ( referencia design és ISA ) Open Source -os ..de mintha a SiFive -nek egy egyedi Apple Silicon hoz hasonló
megoldása IS lenne
( custom design - ami a publikus "szabad" ISA-t implementálja )
és a legújabb design nem találod meg a repojukban
https://github.com/sifive
( vagy csak én nem találom a "Performance P550 core"-t, mert béna vagyok. )
Vagyis csak egy része open-source-os , pont annyira, hogy a saját ügyfeleik életét megkönnyítsék.
https://github.com/sifive/freedom-e-sdkHa teljesen "szabad licenszű kell " akkor ott van még a Rocket-Chip
https://github.com/chipsalliance/rocket-chipMottó: "A verseny jó!"
-
#5328
Petykemano
veterán
S_x96x_S
#5326
Petykemano
veterán
válasz
S_x96x_S
#5326
üzenetére
> jelenleg 2.23 Ghz a beállított "tető" .. és az N7-es technológia
A Navi23 azon már rég túl van. [link]
2684 a táblázatban levő legmagasabb turbo frekvencia.Persze az még játszhat, hogy APU formában nem HPC könyvtárral, hanem HD-vel szedik rakják a tranzisztorokat.
Találgatunk, aztán majd úgyis kiderül..
-
#5329
S_x96x_S
őstag
Petykemano
#5328
S_x96x_S
őstag
válasz
Petykemano
#5328
üzenetére
> 2684 a táblázatban levő legmagasabb turbo frekvencia.
az külső GPU .. saját hűtéssel .. nem APU
szerintem:A ZEN3 -as chip (~Package W) minimum 10W-ot fogyaszt üresben is [1]
ha meg adagolja az adatokat a iGPU-nak, akkor lehet, hogy 15-20W
emiatt nem lehet a teljes fogyasztási keretet az iGPU-ra áttenni.
vagyis a 2684 * 0,75 ~ 2Ghz
( de én 2.3Ghz felett APU-t nem igen várnék az N6-sal se .. )
Ettől még örülnék, ha neked lenne igazad és én tévednék.
az okoskodásomat arra építem, hogy
valami üresjárati fogyasztást a CPU-ra is allokálni kell ..
Legalább 3-5-10 W -ot. ami beleszámít a közös hő-keretbe.
Az AMD Ryzen Embedded - V3000 -ben benne van szinte
minden .. vagyis a hálózatra, az USB , a SATA kezelésre is kell allokálni valami fogyasztást.
[1]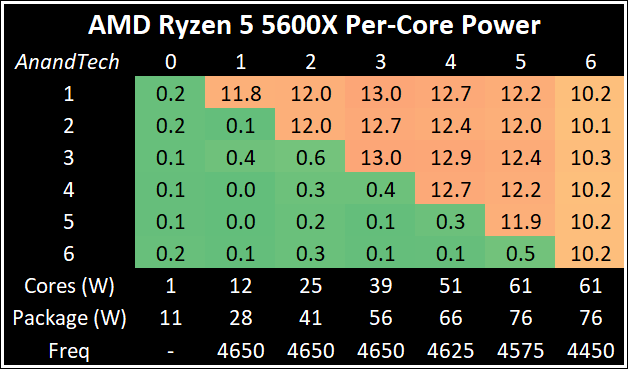
[link]Mottó: "A verseny jó!"
-
S_x96x_S
őstag
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
Labilis (Intel/AMD) CPU-k
![;]](//cdn.rios.hu/dl/s/v1.gif) , Corruption Execution Errors (CEEs); “mercurial” cores, szívás+++
, Corruption Execution Errors (CEEs); “mercurial” cores, szívás+++
már kb 1 hónapos hír, de érdekes lehet,
video: https://www.youtube.com/watch?v=QMF3rqhjYuM
"HotOS 2021: Cores That Don’t Count (Fun Hardware)"
aminek a lényege,
hogy egyes CPU-k furcsa - nehezen detektálható ( "csendes" ) hibákat generálnak. Hasonló mint az ECC memória problémaköre, csak ez CPU-ra.- kb 1/1000 CPU érintett
- egyes CPU-k, bizonyos esetekben elég labilis eredményeket kalkulálnak
- extrém következmények is lehetnek .. pl. ha valaki ilyen CPU-n titkosít akkor nem biztos, hogy vissza tudja kódolni az anyagát ..
pár link:
Google kutatásról: http://muratbuffalo.blogspot.com/2021/06/cores-that-dont-count.html
Facebook kutatásról: http://muratbuffalo.blogspot.com/2021/06/silent-data-corruptions-at-scale.html
https://www.theregister.com/2021/06/04/google_chip_flaws/https://www.extremetech.com/computing/323476-cpu-manufacturers-are-pushing-the-boundaries-of-cmos-and-starting-to-pay-for-it
"The idea that CPUs would become less reliable as transistor density increased is a topic people like Bob Colwell, the lead designer on Intel’s 1995 Pentium Pro, were talking about 20 years ago. This is the first report I’ve ever seen in that time suggesting that CPUs from both AMD and Intel could now suffer from various silent errors that may otherwise go undetected in the moment and that the problem is industry-wide.
This incident has some similarities to the old Pentium FDIV bug, but only nominally. The FDIV flaw was silent in most cases, but the issue affected every Pentium Intel had built, and it affected them immediately. According to Google, some chips don’t show evidence of flaws until they’re at a certain age. Google is actively working on writing software to detect CEEs and it calls on both Intel and AMD to test CPUs more effectively before shipping them."Mottó: "A verseny jó!"
-
S_x96x_S
őstag
versenytárs - Ajjjajjjj ..
Az Intel csendben letiltja a TSX -et
egyes Skylake és Coffee Lake prociknál ...
Intel To Disable TSX By Default On More CPUs With New Microcode"Intel is going to be disabling Transactional Synchronization Extensions (TSX) by default for various Skylake through Coffee Lake processors with forthcoming microcode updates. Yes, this does mean performance implications for workloads benefiting from TSX. This change has seemingly not been talked about much at all publicly and I just happened to become aware of it when looking through new kernel patches."
Mottó: "A verseny jó!"
-
#5333
Petykemano
veterán
Petykemano
veterán
16GB DDR5
Elég szellős.
Tudom, persze az elején mindig nagyon drága, de erre nagyon hamar fel fog szerintem kerülni egy másik 4-es pakk és ha két modult veszel, akkor az már 64GB.
A kép alapján úgy tűnik, rá fog férni - még mindig egy oldalra - annak kétszerese is a felső sorban. 2 modullal az már 128GBVan egy olyan érzésem, hogy a memória kapacitás jelentősen meg fog nőni a következő néhány évben.
2-3 év múlva lehet, hogy már 64GB-os gépeket fogunk venni (vagy csak nézni)Találgatunk, aztán majd úgyis kiderül..
-
#5334
 poci76
aktív tag
Petykemano
#5333
poci76
aktív tag
Petykemano
#5333
poci76
aktív tag
válasz
Petykemano
#5333
üzenetére
Ennek az lenne a feltétele, hogy a memóriaárak jelentősen csökkenjenek.
-
#5335
S_x96x_S
őstag
Petykemano
#5333
S_x96x_S
őstag
válasz
Petykemano
#5333
üzenetére
> Tudom, persze az elején mindig nagyon drága,
szerintem
az "alap" 4000Mhz körüli DDR5 -ösök
olcsóbban fognak kijönni mint a 4000Mhz-es DDR4-esek.a DDR4 -ből a 4000Mhz körüli/felettiek már a prémiumos termékek
nehezebb gyártani is .. a TOP30 % -ban vannakDDR5 -ből meg a 4000Mhz-es még mindig a bottom 30% -ban.
Nem melegszenek annyira, nem a válogatott chipek kerülnek ide.Ráadásul most a memóriagyártók már csak DDR5-ös gyárakat csinálnak vagy állítják át a gyárakat DDR5-re.
Vagyis a DDR4-es keresletre - sokkal kisebb DDR4-es kinálat jut.
Vagyis az is lehet, hogy a DDR5 - az év végi DDR4-es árakhoz képest már relative olcsóó lesz .. ( ugyanakkora teljesítményt értve )
DDR4 memory is becoming more expensive ahead of the DDR5 era
By Paul Lilly April 21, 2021
A market research firm says PC DRAM prices could jump by as much as 28 percent this quarter.
https://www.pcgamer.com/ddr4-memory-is-becoming-more-expensive-ahead-of-the-ddr5-era/Mottó: "A verseny jó!"
-
#5336
S_x96x_S
őstag
Petykemano
#5333
S_x96x_S
őstag
válasz
Petykemano
#5333
üzenetére
> 16GB DDR5
The first 32GB DDR5 RAM kit lands at retail for $311 and it’s already sold out
https://www.pcgamer.com/the-first-32gb-kit-of-ddr5-4800-ram-lands-at-retail-for-dollar311-and-its-already-sold-out/"What about pricing? A couple of weeks ago, TeamGroup said its 32GB DDR5-4800 memory kit would be available to purchase by the end of the month for $400. It's actually a bit cheaper—Amazon and Newegg both had it listed for $311 before the kit sold out."
---
DDR4 4600 -as Newegg - Bestselling árak ( 2x16Gb )
kb 350$ - körül vannak.
persze latency meg sok más dolog is bele játszik ..
de még a DD4-4000-res árak is nagyon szórnak 180$ - 420$ látok mindenfélét ..de majd meglátjuk ...
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
Versenytárs:
Az Intel Sapphire Rapids -ban 2 újdonság is van1.) Advanced Matrix Extensions (AMX),
(ezzel szerintem az Intel az nVidiás CUDA-ra is válaszolni akar)
Kérdés, hogy melyik ZEN-be kerülhet be ..2.) Data Streaming Accelerator (DSA).
"a high-performance data copy and transformation accelerator for streaming data from storage and memory or to other parts of the system through a DMA remapping hardware unit/IOMMU."
ez meg talán a DirectStorage koncepció Szerveres változatának néz ki felületesen. ( jól jön a HBM2e - DDR5 - OptaneDisk közötti adatmozgatásoknál )persze ezek papiron nagyon jól néznek ki.
és kb 6 hónapos előny garantált az Intelnek a bevezetésnél.Az AMD ( aki bár általában óvatos és keveset igér - ami jó )
de ettől függetlenül - valamit meg kell mutatnia 2021H2-ben
hogy az ügyfeleiben tartsa a lelket.
- én pl. HBM -et várok EPYC-re integrálva.az AMD-nek se Optane-ja, se AMX-e nem lesz ... de valami meglepit csak fel tud mutatni .. amire még az Inteles-es Raja is csettint egyet ..
Mottó: "A verseny jó!"
-

hokuszpk
nagyúr
válasz
S_x96x_S
#5332
üzenetére
nemastam magam bele, de tippre a TSX az ilyen in-memory adatbazisoknal jatszana, es ha igazam van, akkor az Intel megint bealdozza a biztonsagot a sebessegert, de ez csak addig lesz oke, amig meg nem jonnek az elso hirek az inkonzisztenssé / korrupttá váló adatbazisokrol.
Első AMD-m - a 65-ös - a seregben volt...
-
S_x96x_S
őstag
Phoronix: AMD EPYC Milan Performance Across 11 Different 2021 Linux Distributions
Az Inteles - ClearLinux a legjobb az EPYC-re
Az UBUNTU a végén ..Mottó: "A verseny jó!"
-
S_x96x_S
őstag
válasz
 hokuszpk
#5338
üzenetére
hokuszpk
#5338
üzenetére
> es ha igazam van, akkor az Intel megint bealdozza a biztonsagot a
> sebessegert,nem pont fordítva ?
most isszák a levét a régi dolgoknak
és mivel nincs már más
kénytelenek a biztonságos-és-lassú utat választani.> de ez csak addig lesz oke, amig meg nem jonnek az elso
> hirek az inkonzisztenssé / korrupttá váló adatbazisokrol.éppen a TSX- inkonzisztens ;
nem tudják mikrokóddal se megjavítani - ezért kell kikapcsolni.
2.5 évet tököltek rajta .. és ha lett volna jobb megoldás,
akkor nem ezt választják ...muszály kikapcsolni .. (mert tényleg az lesz,
hogy az Intel az inkonzisztencia szinonimája lesz )Ennél az is jobb, hogyha lassan/hagyományosan és biztonságosan - szoftveresen oldják meg tranzakció kezelést.
"A memory ordering issue is what is reportedly leading Intel to now deprecate TSX on various processors. There is this Intel whitepaper updated this month that outlines the problem at length. As noted in the revision history, the memory ordering issue has been known to Intel since at least before October 2018 but only now in June 2021 are they pushing out microcode updates to disable TSX by default."
Mottó: "A verseny jó!"
-
#5342
Petykemano
veterán
Petykemano
veterán
MLiD videója szerint a 128 magos zen4 kódneve: Bergamo
[link]Hozzáteszem: a videóban többször hangsúlyozza, hogy ez nem 100%.
Csak azért jegyzetelem le, hogy legyen nyoma, ha kódnevekre keresnénk.Elég valószínű, hogy a 128 magos zen4 létezik.
Persze lehet az AMD részéről csupán egy backup plan, ha az egyik Arm gyártó (esetleg az intel) előállna valami ütős termékkel.
Ebből a szempontból az intel nem tűnik versenytársnak (mármint minden szempontból). Az AdoredTV által bemutatott Sapphire rapids infók alapján az 56 mag elég nagy lapkákból áll össze (~1500mm2) annak ellenére, hogy már 10nm-es. Viszont a fentebb említett speckó utasításokkal (AMX, AVX512, stb) bizonyos specializált részterületeken előremutató lehet és persze ugye az is igaz lehet továbbra is, amit Abu mondott, hogy az eladási volumen nagy része alacsonyabb magszámú termékekből áll.Szóval lehet, hogy csak backup plan az AMD részéről egy potenciális ARM versenytárssal szemben. De az is lehet, hogy végül lesz belőle termék.
Említésre került, hogy a 128 mag cloud szolgáltatóknak menne.
Az nem teljesen világos, hogy csak a magok száma miatt miért kéne külön platformot csinálni? Tehát valami trükközés a magszámon kívül kell legyen még. Még annak se feltétlenül kellene különálló platformot jelentenie, ha - a GCP-ben elhelyezett Milanhoz hasonlóan - le van tiltva az SMT.
Például:
- más az IOD, több memóriacsatornát tud kezelni.
- Esetleg tartalmaz valamilyen olyan módosítást, ami SMT nélkül mégiscsak magasabb egyszálas teljesítményt ad.
- v-cache
- LSI (~EMIB) használata (Nyilván minél több a mag, annál több a inter-chiplet kommunikáció is, amiben éppenséggel gyengélkedik már a Milan is)
- HBM2 (hát talán ez a legkevésbé valószínű)Lehetne olyan prózai is az ok, hogy a 96 mag elfér ugyanakkora helyen, mint az eddigi kialakítások, de a 128 mag már nem.
Mindenesetre az sajnálatos kicsit, hogy az Executablefix által renderelt képek alapján nem látszik változás arra vonatkozóan, hogy miként huzalozzák össze a chipleteket (LSI) Ami arra utal, hogy az egzotikus AM5 kupak alatt sincs semmi érdekes.
[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#5343
hokuszpk
nagyúr
Petykemano
#5342
hokuszpk
nagyúr
válasz
Petykemano
#5342
üzenetére
"128 magos zen4 kódneve: Bergamo"
hat az Atalantanak most nagyon megy, de megse egy Roma, Juve vagy Milan

Első AMD-m - a 65-ös - a seregben volt...
-
#5344
Petykemano
veterán
Petykemano
veterán
Backporting - erre vártunk.
Monet
4 magos pici apu.
Zen3 magokkal
GF 12LP+ gyártástechnológán készítve./pletyka/
Találgatunk, aztán majd úgyis kiderül..
-
#5345
hokuszpk
nagyúr
Petykemano
#5342
hokuszpk
nagyúr
válasz
Petykemano
#5342
üzenetére
"AMD Monet: Zen3 on 12nm node"
nocsak. valahol mondtam, hogy fogunk latni 12nm -re visszaportolt csodakat, de valami sima kisebb Navira ment el a tipp.
Első AMD-m - a 65-ös - a seregben volt...
-
#5346
hokuszpk
nagyúr
Petykemano
#5344
hokuszpk
nagyúr
válasz
Petykemano
#5344
üzenetére
mekkoria meglepi lesz, ha kiderul, hogy mar a Zen3+ mag van backportolva
Első AMD-m - a 65-ös - a seregben volt...
-
#5347
Petykemano
veterán
Petykemano
veterán
AMD Daytona vs Gigabyte
MilanEddig ez elerülte a figyelmemet. Az AT újratesztelte a Milan-t egy másik alaplapban (GB) és eltűnt a korábban tapasztalt magasabb Idle power
Találgatunk, aztán majd úgyis kiderül..
-
#5348
S_x96x_S
őstag
Petykemano
#5342
S_x96x_S
őstag
válasz
Petykemano
#5342
üzenetére
Lassan már a 128 mag is kevés lesz ..
de legalább a "verseny" kihozza a maximumot a designokból - mindkét oldalon.
 ( videokardz -os linkből linkelve )
( videokardz -os linkből linkelve )Mottó: "A verseny jó!"
-
S_x96x_S
őstag
Charlie: ( 3 kiemelés a 16 -ból .. )
"Genoa delayed to mid-22 vs the formerly assumed (by Charlie) early 2022. It's a delay for technical reasons, not for marketing ones - Charlie doesn't know the details but expects it to be a bug. Could be anything really, but doesn't think it's a major issue at all."
Intel: "Launch BIOSes for SPR are scheduled to arrive in late Q2, so expect volume to come afterwards. "Q3 launch wouldn't surprise". Similar situation to ICL-SP - "launch" in March, but no availability until May."
Intel: "Realistically there's very little on the roadmaps right now that will stop AMD".Mottó: "A verseny jó!"
-
S_x96x_S
őstag
piac/versenytárs/
új főnöke van a Qualcomm-nak ;
és mind a mobil(Notebook)mind a szerver piacon nyomulnának.Nem tudom kinek licenszelnék a Nuvia magokat,
lehet, hogy az AWS cserélné le a Gravitont?Qualcomm to Challenge Intel With Nuvia-Designed Notebook Chips
"It also plans to license Nuvia cores for third-party datacenter SoCs."
"Nuvia was originally co-founded by ex-Apple engineers in a bid to build Arm-based system-on-chips (SoCs) for servers. Based on the company's own simulations, its Phoenix core could deliver at least 50% higher peak performance than AMD’s Zen 2 and Intel’s Sunny Cove cores at 1/3 of power (4.50W vs. 14.80W) in Geekbench 5, which looked very competitive. The Phoenix core could also outperform Apple's A13 Lightning cores, which essentially means that the company claimed the core was considerably better than Arm's generic Cortex A-series cores that are widely used in smartphones, tablets, and some PC-oriented SoCs. "
https://www.tomshardware.com/news/qualcomm-promises-nuvia-socs-for-pcs-in-2023magabiztos .. lenyomnák az Apple-t is.
Qualcomm CEO Says They Can Beat Apple M1 With Nuvia Team Driving Laptop Chip DesignMottó: "A verseny jó!"




 Lesz itt felfordulás még emiatt szvsz.
Lesz itt felfordulás még emiatt szvsz. 

 az én laikus - naiv és leegyszerűsített nézőpontom szerint)
az én laikus - naiv és leegyszerűsített nézőpontom szerint)







![;]](http://cdn.rios.hu/dl/s/v1.gif) , Corruption Execution Errors (CEEs); “mercurial” cores, szívás+++
, Corruption Execution Errors (CEEs); “mercurial” cores, szívás+++





