- AMD Ryzen 9 / 7 / 5 / 3 5***(X) "Zen 3" (AM4)
- AMD Navi Radeon™ RX 7xxx sorozat
- Alacsony fogyasztású, 128 GB-os szervermemóriát kínál a Micron
- Kormányok / autós szimulátorok topicja
- Mini PC
- Milyen belső merevlemezt vegyek?
- Fujifilm X
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- NVIDIA GeForce RTX 4060 / 4070 S/Ti/TiS (AD104/103)
- Alapértelmezett konfiguráción sok Core CPU-nak lehet stabilitási gondja
Hirdetés
-


Letartóztatták a bitcoin-Jézust
it Amerikai adókerülés vádjával, Spanyolországban tartóztatták le a bitcoin-Jézusként ismert Roger Vert.
-


Egyre nagyobb a balhé a Helldivers II körül
gp Úgy tűnik, hogy egyre több sötét felhő kezd gyűlni a játék körül a Sony döntése miatt.
-


iPaden is vége az App Store monopóliumának
ma Ősztől lehet alternatív alkalmazásboltból telepíteni az EU tagállamaiban.






Új hozzászólás Aktív témák
-
#4351
 Cathulhu
addikt
Petykemano
#4350
Cathulhu
addikt
Petykemano
#4350
Cathulhu
addikt
válasz
 Petykemano
#4350
üzenetére
Petykemano
#4350
üzenetére
Itt most nem arrol van szo, hogy beleposzint lesz e X ev utan vagy sem, mert nyilvan az lesz, ahogyan egy mai 2 magos CPU is porig alazza az akkori 8 magosakat. De itt egyesek szerint a frissen megjelent Zen3 gyorsabban fog avulni, mint az akkori mondjuk 2500k, es alkalmatlan lesz 30 FPS-nel tobbet kitolni magabol par ev mulva. Holott a konzolokban levo Zen2 es egy friss 5GHz kozeleben jaro Zen3 kozott mar most meg van az az 50%+ single thread kulonbseg, es magokbol is lehet +50-100% (12 es 16 mag) kapni, szoval semmi se indokolja miert avulna a jelenlegi generacio gyorsabban mint az elozo. Sotmitobb, mivel eleve a konzolok fogjak meghatarozni a szintet evekig, erre semmi eselyt se latok.
[ Szerkesztve ]
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
válasz
 paprobert
#4347
üzenetére
paprobert
#4347
üzenetére
pusztán az érveléseddel van baj, világosan látszik, hogy még az általános iskolás szint is problémát jelent jelen esetben, csak éppen neked...
 De ahogy BiP írta. elengedem, pedig 1 órája szerkesztgetem a hozzászolást neked, de kb annyi értelme lett volna elküldeni, mint estimesét felolvasni a hintalónak...
De ahogy BiP írta. elengedem, pedig 1 órája szerkesztgetem a hozzászolást neked, de kb annyi értelme lett volna elküldeni, mint estimesét felolvasni a hintalónak...Tényleg nem sértés, nem tehetsz róla, ez egy nyilvános fórum, ahova sajnos azok is beírkálhatnak, akiknek nem hogy erről, de kb semmiről sincs halvány lila fingjuk se...


![;]](//cdn.rios.hu/dl/s/v1.gif) Thx mégegyszer BiP! ( megmentettél 1 hónap kényszerpihenőtől )
Thx mégegyszer BiP! ( megmentettél 1 hónap kényszerpihenőtől ) Nézd meg a hirdetéseim. Finomságok!!!
-
#4353
 paprobert
senior tag
Petykemano
#4350
paprobert
senior tag
Petykemano
#4350
paprobert
senior tag
válasz
Petykemano
#4350
üzenetére
Köszönöm hogy mutattál forrást. Igen, nagyjából erről van szó.
Pusztán a multicore teljesítmény alapján a 16 magos 5950X tud valamivel több mint kétszeres throughput-ot, azaz elméletben ott van esély 60 fps-re, amikor a konzol már csak 30-at tud. Ehhez kell jól skálázódó motor is.
Egy szálon viszont nem tud kitolni dupla annyi frémet, így ha a szál-limitált motor 30-at teljesít konzolon, és nem skálázódik, akkor sub 60 lesz az eredmény PC-n.
A ma kapható 6, 8 magosak sem single, sem multithread-ben nem tudnak kétszeres teljesítményt szolgáltatni.Az elavulás üteme, és az hogy mennyi ideig tudnak garantálni a mostani PC-s hardverek 60 képkocka feletti futást, csak azon múlik, hogy milyen gyorsan váltanak a fejlesztők.
Rossz kimondani, de vásárlóként a fejlesztők markában vagy, a hardverek számai le vannak mérve, látjuk hogy mit tudnak.[ Szerkesztve ]
640 KB mindenre elég. - Steve Jobs
-
#4354
 Petykemano
veterán
Petykemano
veterán
Petykemano
veterán
Találgatunk, aztán majd úgyis kiderül..
-
#4355
 awexco
őstag
Petykemano
#4354
awexco
őstag
Petykemano
#4354
awexco
őstag
válasz
Petykemano
#4354
üzenetére
A core-okban l1 il l2-t össze tudod hasonlítani , h menyi adat menyi helyet foglal . Csak hogy más képességekre vannak optimalizálva .
I5-6600K + rx5700xt + LG 24GM77
-
#4356
 -FreaK-
veterán
Petykemano
#4354
-FreaK-
veterán
Petykemano
#4354
-FreaK-
veterán
válasz
Petykemano
#4354
üzenetére
Szóval akkor ebből kiderül, hogy nincs külön 6magos ccx, hanem 8 magos van csak és abban van letiltva 2 mag. Vagy ez csak nekem újdonság itt?

#4357 Petykemano ez egy nagyon szép, diplomatikus válasz volt
 amúgy ez így nekem tényleg kimaradt, pedig követem a Ryzenes híreket/pletykákat is rendszeresen
amúgy ez így nekem tényleg kimaradt, pedig követem a Ryzenes híreket/pletykákat is rendszeresen 
[ Szerkesztve ]
-

Mumee
őstag
-
#4360
Petykemano
veterán
Mumee
#4359
Petykemano
veterán
És lesz félidős refresh is.
Bár nem nevezte Warholnak. És a matisse 2-t sem nevezték annak hivatalosan.Nem fura, hogy még szinte meg se jelent és már erről beszélnek? Nem félnek az Osborne hatástól? Épp most üzenik: nem életbevágó a zen3/RDNA2-be beugrani, nyugodtan várd meg a következőt, az még jobb lesz.
[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#4361
Petykemano
veterán
Mumee
#4359
Petykemano
veterán
/konkurencia/
M1
bár az AT deepdive többet mond.
Az apple 2-3x-szoros teljesítménynövekedésről beszél.
Persze várjuk meg a 3rd party méréseket
Meg nyilván persze saját OS-sel könnyű jót csinálni. Meg ott van az NPU is, amire szintén a saját OS meg az egyféle környezet sokat segít, hogy ki legyen használva
Meg 5nm.Na de mégis. Most egy pillanatra tegyük föl, hogy tényleg 2-3x gyorsabb, mint a 2018-as Coffee lake-kel szerelt elődje, pedig azért az is 4 magos i3 volt
Így mérték:
"A tesztelést az Apple 2020 októberében végezte a Mac mini Apple M1 chippel szerelt prototípusain, valamint 3,6 GHz-es, négymagos Intel Core i3 processzorral szerelt sorozatgyártott modelljein. A teszteléshez használt mindegyik modellben 16 GB memória és 2 TB-os SSD-tároló volt. A tesztelés a Final Cut Pro 10.5 kiadás előtti verziójával, egy 55 másodperces, 4096 x 2160 képpontos felbontású, 59,94 képkocka/másodperces sebességű 4K-s Apple ProRes RAW multimédiás anyagot alkalmazó projekt Apple ProRes 422 formátumra való átkódolásával történt. A teljesítménymérések adott számítógépes rendszerek használatával történtek, és a Mac mini hozzávetőleges teljesítményét tükrözik."
[link]
Jó, tehát 2x annyi mag, de azért a maradék az IPC-ből jön. Ráadásul ez csak 3Ghz-es, nem is 3.6.menjünk bele

Ez csak blokk diagram.
De itt látszik:
192KB L1i
128KB L1dEz a zen3 32KB/32KB-jához képest elképesztően sok
12MB L2$ a 4 magnak. Még ha ez az L2$ nem is éri el azt a késleltetést, mint a zen3 512KB L2$-e, viszont a zen2 16MB-os L3$-énél és egészen bizonyosan a zen3 L3$-nél is alacsonyabb a késleltetése. És a magok osztoztak rajta.Ezzel az Apple a leggyorsabb mag címét vindikálja magának.
De még a hatékonyságra optimalizált magok is
128KB L1i
64KB L1D
4MB shared L2$
paraméterekkel rendelkeznek.What really defines Apple’s Firestorm CPU core from other designs in the industry is just the sheer width of the microarchitecture. Featuring an 8-wide decode block, Apple’s Firestorm is by far the current widest commercialised design in the industry. IBM’s upcoming P10 Core in the POWER10 is the only other official design that’s expected to come to market with such a wide decoder design, following Samsung’s cancellation of their own M6 core which also was described as being design with such a wide design.
Other contemporary designs such as AMD’s Zen(1 through 3) and Intel’s µarch’s, x86 CPUs today still only feature a 4-wide decoder designs that is seemingly limited from going wider at this point in time due to the ISA’s inherent variable instruction length nature, making designing decoders that are able to deal with aspect of the architecture more difficult compared to the ARM ISA’s fixed-length instructions. On the ARM side of things, Samsung’s designs had been 6-wide from the M3 onwards, whilst Arm’s own Cortex cores had been steadily going wider with each generation, currently 4-wide in currently available silicon, and expected to see an increase to a 5-wide design in upcoming Cortex-X1 cores.
[link]"A +-630 deep ROB is an immensely huge out-of-order window for Apple’s new core, as it vastly outclasses any other design in the industry. Intel’s Sunny Cove and Willow Cove cores are the second-most “deep” OOO designs out there with a 352 ROB structure, while AMD’s newest Zen3 core makes due with 256 entries, and recent Arm designs such as the Cortex-X1 feature a 224 structure."
[link]"The four 128-bit NEON pipelines thus on paper match the current throughput capabilities of desktop cores from AMD and Intel, albeit with smaller vectors. Floating-point operations throughput here is 1:1 with the pipeline count, meaning Firestorm can do 4 FADDs and 4 FMULs per cycle with respectively 3 and 4 cycles latency. That’s quadruple the per-cycle throughput of Intel CPUs and previous AMD CPUs, and still double that of the recent Zen3, of course, still running at lower frequency."
[link]"We’re measuring up to around 148-154 outstanding loads and around 106 outstanding stores, which should be the equivalent figures of the load-queues and store-queues of the memory subsystem. To not surprise, this is also again deeper than any other microarchitecture on the market. Interesting comparisons are AMD’s Zen3 at 44/64 loads & stores, and Intel’s Sunny Cove at 128/72."
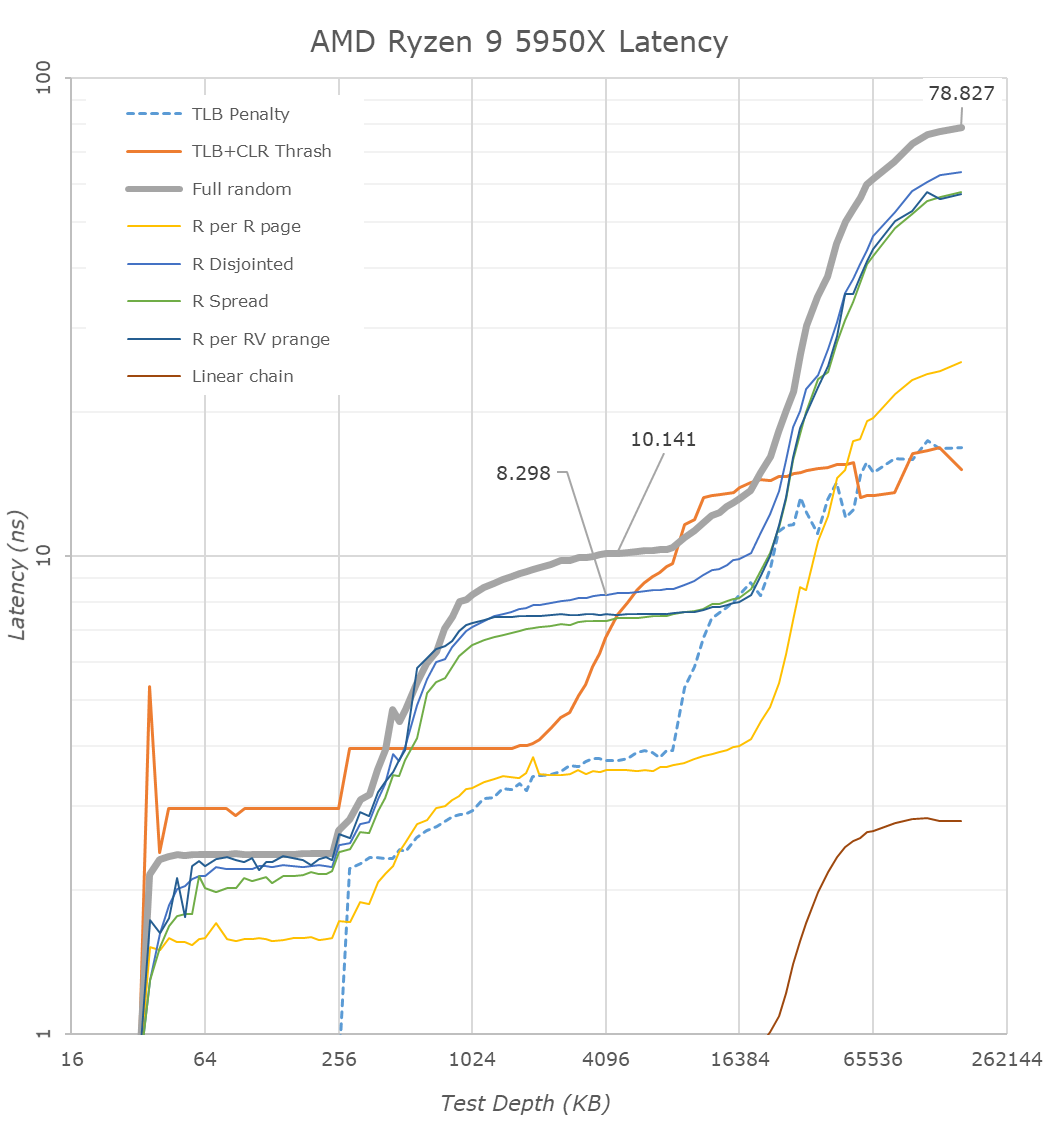
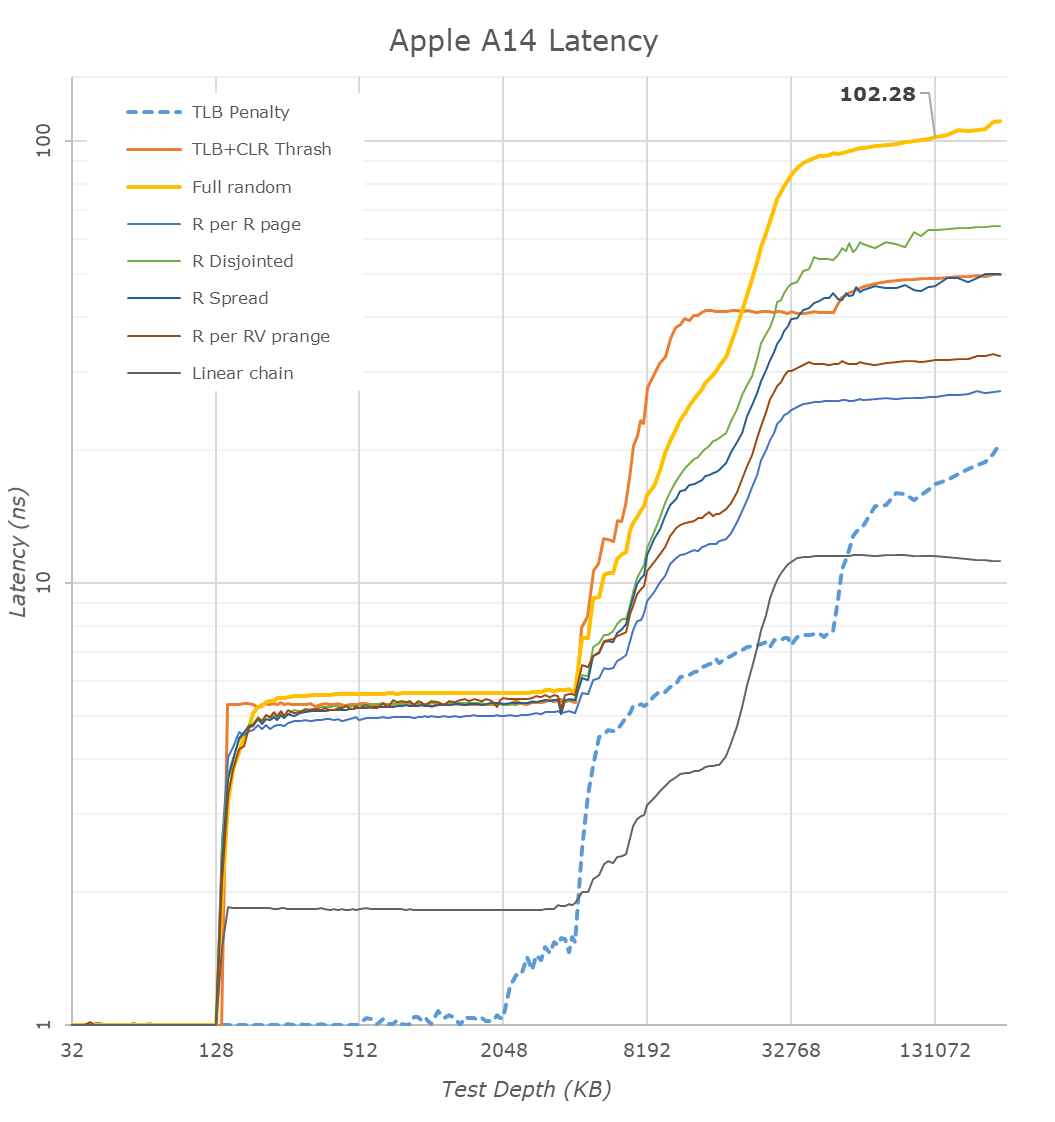
Késleltetések: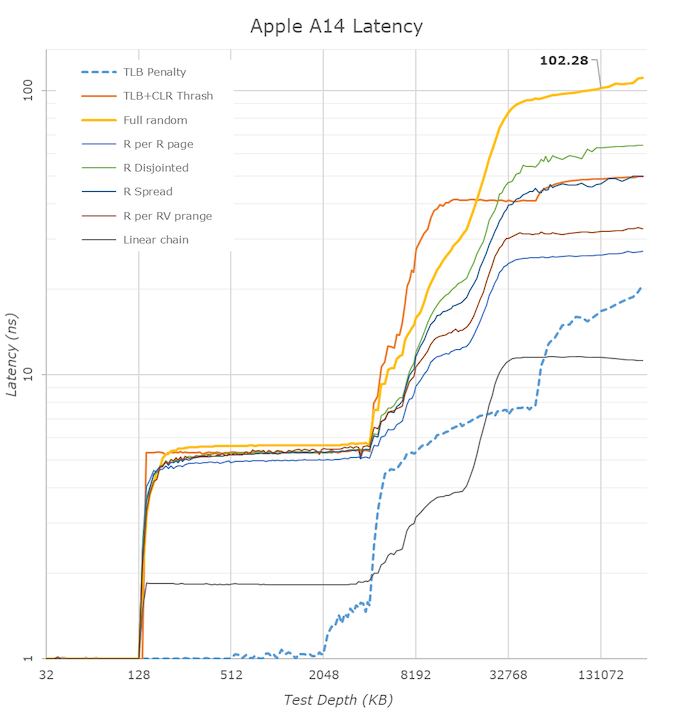
5950X:
A késeltetés az Apple M1 esetén 128KB-ig 1ns
Ugyanez az zen3-nál felugrik 32KB-nál 2-3-ra és ez 256KB-ig kitart. Tehát már a második szelet 256KB L2$ picit lassabb, mint az első. (mivelhogy összesen 512KB van a fedélzeten)Az apple-nél 128KB-től 4MB-ig végig 5ns. Világos, hogy ez a 4MB-os L2$ késleltetése.
A zen3-nál a 256KB-től 1024-ig fokozatosan emelkedik a késleltetés 8ns-ra, onnan 4MB-ig lassabban emelkedve 10ns-ra.
Az tökre világosan látszik, hogy 4MB-ig összességében jobb késleltetéseket nyújt az apple. A zen3 csak a 128KB és 512KB adatméret között ad jobb késleltetést.mindezt úgy, hogy ez csak 3Ghz-es, a zen3 meg 5ghz-es.
A hetekben asszem talán pinkyvel volt egy eszmefuttatásunk, amelyben ő kifejtette, hogy a magszám emelésnek a desktop vonalon semmi értelme és szervereknél is a magszám alapú szoftver licenc árazás eléggé betett annak az elképzelésnek, hogy majd kisfogyasztású, és kis helyigényű, de erős és sok maggal fogjuk megváltani a compute világot. Helyette az IPC növelés tűnik annak az útnak, amivel eladásokat lehet generálni.
Szóval itt van az apple példája. 3Ghz, remek késleltetések. Ha a magszámmal nem lehet nyerni, akkor a mag területigényét el kell engedni.
Jó, persze 5nm
Meg az Apple M1 nem szerverchip, hanem csak egy notebook-minipc. Igazi jó összevetés majd inkább a Cezanne-nal lehet.Nem állítom, hogy csak a hardver vonatkozásában jaj AMD/intel is dooomed. Az Apple most úgy gurított szépet, hogy rajta kívül még senki nem használ 5nm-es gyártástechnológiát. Ez mindenképp előnyt jelent persze. És ha az apple bevásárolja magát a 4 és 3nm-be is, akkor pont ugyanennyi előnyt meg is tarthat a későbbiekben is.
De az biztos, hogy az AMD nem ér rá totojázni a zen4-gyel, hogy humihumi, hát még ráérünk, hát hol az intel. Ilyen imac minit $699-ért bárki vehet, remekül helytállna bármilyen otthoni gépként, amivel történetesen játszani nem akarnak. Apropó, nem tudom, hogy áll az apple a nagyobb gpu-kkal, de mi akadályozná meg abban, hogy ugyanerre a lapkára (esetleg duplaekkára) ne csak munkára használható Mac Prokat készítsen, hanem kifejezetten játékosoknak szánt új termékvonalat?
Nyilván az MSI, meg az Acer, meg a HP nem fognak holnap előhúzni a kalapból egy ARm designt és nem tudnak Apple készüléket sem forgalmazni. És az is igaz, hogy az Apple-ön kívül nem biztos, hogy bárki más tudna 5nm-en gyártatni.
De szerintem azért kell iparkodni!És akkor még nem is beszéltünk a zárt ökoszisztéma előnyeiről. Tehát az AMD-nek és az intelnek extra/ingyen szilikont kellene áldozni arra, hogy rápakoljanak a procijaikra minimum gpu-t, de akár FPGA-t, vagy NPU-t is. Az apple ezzel élni fog nyilván. X86-on meg semmi elterjedtsége nincs.
Találgatunk, aztán majd úgyis kiderül..
-
#4362
 Devid_81
nagyúr
Petykemano
#4361
Devid_81
nagyúr
Petykemano
#4361
Devid_81
nagyúr
válasz
Petykemano
#4361
üzenetére
Te ezen a hozzaszolason aztan dolgoztal rendesen!

Egy komplett cikk!...
-

Ueda
senior tag
válasz
 Devid_81
#4362
üzenetére
Devid_81
#4362
üzenetére
Az Sg.hu -n az írják, hogy figyelik a piacot és szükség esetén
(a beépített kémek LOL)gyorsan tudnak reagálni (a cikk végén, utolsó sorokban). https://sg.hu/cikkek/it-tech/143274/evekig-tart-majd-az-intel-felzarkozasa (Pletykemano-nak ment volna #4361-re)[ Szerkesztve ]
OS : EndeavourOS KDE . . . . . . Parancs menü : https://pastebin.com/u/txt444
-
#4364
Petykemano
veterán
Ueda
#4363
Petykemano
veterán
A big.LITTLE, vagy hibrid multithreading szerintem nem elsősorban a magszám növelhetőségét célozza.
Szerintem arról van szó, hogy
1) vannak olyan szoftverek, amik 1 szálon, vagy legalábbis kevés szálon tudnak tudnak csak működni. Viszonylag kevés az olyan szoftver, ami sok magra egyenletesen skálázódik. A játékok egy olyan köztes terület, ahol ügyködnek a több magra való skálázódáson, de mindmáig meghatározó az, hogy a 1-2-3 szálon mennyire erős egy processzor.
2) az IPC növelése jelentős fogyasztás és területigénnyel rendelkezik. (valószínűleg a frekvencia növelése is)És a lényeg: ahhoz, hogy azoknál a programoknál teljesítménynövekedést érjenek el, amik rosszul skálázódnak, az IPC-t kell növelni. De azoknál a programoknál, amik jól skálázódnak a magok számával, nem feltétlenül szükséges az összes szál kezeléséhez magas IPC-jű mag. Azokhoz a programokhoz, amelyek jól skálázódnak, előnyösebb lehet 1 magas IPC-jű mag helyett 2-3 olyan, aminek az IPC-je 30%-kal alacsonyabb, de negyedakkora helyet foglal és negyedannyit fogyaszt.
Tehát a kényszer nem a magszám növelésének irányából jön, hanem az IPC növelés tranzisztor és energia költségeiből, amit azokban az esetekben, amikor több magot ki tud használni egy applikáció, hatékonyságra optimalizált magokkal kompenzálnak.
Nekem úgy tűnik, hogy az intel ezt az utat választotta. Nem állítom, hogy ez a helyes.
Találgatunk, aztán majd úgyis kiderül..
-
#4365
Mumee
őstag
Petykemano
#4361
Mumee
őstag
válasz
Petykemano
#4361
üzenetére
-
Mumee
őstag
Javítva.
[ Szerkesztve ]
-
#4370
Petykemano
veterán
Petykemano
veterán
Egy érdekes szöveg jelent meg a redditen: [link]
mondom a Redditen...zen4 desktop:
- 2022Q3
- 4 x 8c
- DDR5
- L4$ az IOD-ban
- 3300Mhz FCLK (Infinity Fabric 2.0)
- +30-40% IPCAmi érdekessé teszi az ez a mondat:
"[infinity fabric 2:] What it actually is is the culmination of all of our efforts since Zen 1 in architecting a solution to instruction starvation."
" As of now, our total IPC improvement is a staggering 30% - About 4% of this is minor core optimizations and the rest is entirely the result of the IF and memory overhaul."
Mindez a redditen van, úgyhogy senki ne úgy olvassa, mintha Lisa Su kinyilatkoztatása lenne.Viszont 2 év távlatában 5nm-en a 30-40%-os IPC növekedést nem tudok kizárni.
Ugyanakkor nem tudnám az egészet csak egy L4$ számlájára írni, vagy a 2000-ről 3300Mhz-re emelkedő IF órajelre.
Ehhez én azt tartanám szükségesnek, hogy vastagítsák az L1 és L2 cache méreteket is.Találgatunk, aztán majd úgyis kiderül..
-
#4371
 BiP
nagyúr
Petykemano
#4370
BiP
nagyúr
Petykemano
#4370
BiP
nagyúr
válasz
Petykemano
#4370
üzenetére
OFF: Cache-re a $ mennyire általánosan használt rövidítés?
Elsőre nehéz volt értelmezni, aztán csak leesett.
(Nem vagyok programozó, így simán el tudom képzelni, de eddig ezt csak tőled láttam.)[ Szerkesztve ]
-
#4373
BiP
nagyúr
Petykemano
#4372
BiP
nagyúr
válasz
Petykemano
#4372
üzenetére
A szójáték része adja magát, csak nem tudtam, hogy ez saját találmány-e (mivel soha nem láttam még máshol) vagy általánosan használt rövidítés.
A ph meg messze nem szövekorlátos környezet, ahol indokolt lenne
Lehet, hogy pont ezért nem találkoztam vele, twittert meg csak ritkán olvasok, SMS-ben nem ilyenekről értekezem[ Szerkesztve ]
-
#4375
 RECSKA
veterán
Petykemano
#4370
RECSKA
veterán
Petykemano
#4370
válasz
Petykemano
#4370
üzenetére
Azert a fabric majd megduplazasa biztos hoz valamennyit...
Amugy is cserelni kell a ramot, majd megnezzuk ddr5ben mit dob a micron
Nézd meg a hirdetéseim. Finomságok!!!
-
#4376
-vitya-
őstag
Petykemano
#4370
-vitya-
őstag
válasz
Petykemano
#4370
üzenetére
fene tudja... elolvastam az eredeti bejegyzést, és érzéseim:
- most komolyan, előléptetés elmaradása miatti hisztinek egy ilyen poszt lenne a kimenete?
- nagy része már tudott volt, és kis része lehet érdekes info
- ilyen a pcie4 használata 2022-ben, pcie5 helyett? nemtom, én 5-öt használnék
- ilyen a 7nm IO rész, ddr5 support hynix közös meló, 6600-7000MHz - lehet még racionálisan is levezethető ilyesmi, még el is tudnám hinni
- 4 thread hiánya - még el is hiszem
- óriás L4 cache? na ez amire kíváncsi lennék, hogy vajon mennyi igazság van benne
- megjelenés 2022q3? az jóóóó sokára van, miért? Lesz egy frissítés 2021-ben 5x00XT néven?-=Витя=-
-
#4378
 TESCO-Zsömle
félisten
Busterftw
#4377
TESCO-Zsömle
félisten
Busterftw
#4377
TESCO-Zsömle
félisten
válasz
 Busterftw
#4377
üzenetére
Busterftw
#4377
üzenetére
Tuti lesz refresh, egy generációban lépni architektúrát és gyártás-tech-et egyszerre mindig riziküós, ha belefér, jövőre jöhet 5nm-es ZEN3. Időbe belefér, és akkor az a 30-40% az 2x15-20% lesz. Intel se fog szundikálni a következő 2 évben. Ettől eltekintve a 2022Q3 teljesen reális.
[ Szerkesztve ]
Sub-Dungeoneer lvl -57
-
#4379
Petykemano
veterán
Petykemano
veterán
EPYC Milan 2021Q1
Találgatunk, aztán majd úgyis kiderül..
-
#4380
Cathulhu
addikt
TESCO-Zsömle
#4378
Cathulhu
addikt
válasz
 TESCO-Zsömle
#4378
üzenetére
TESCO-Zsömle
#4378
üzenetére
yep, egy pipe cleaner siman belefer jovore.
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#4390
Petykemano
veterán
Petykemano
veterán
L2$ compression
(zen4?)Találgatunk, aztán majd úgyis kiderül..
-
#4391
Cathulhu
addikt
Petykemano
#4390
Cathulhu
addikt
válasz
Petykemano
#4390
üzenetére
haaat nem vagyok benne 100%-ig biztos, hogy az extra latency level2-n ezt megeri. L3-on esetleg, de en inkabb meg mindig egy hatalmas kozos L4-ert lobbizok az IO lapkaban, oda tokeletes lenne. Kar hogy az en lobbim itt ph-n az AMD szemeben fabatkat sem er
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
-
#4393
Petykemano
veterán
Cathulhu
#4391
Petykemano
veterán
válasz
 Cathulhu
#4391
üzenetére
Cathulhu
#4391
üzenetére
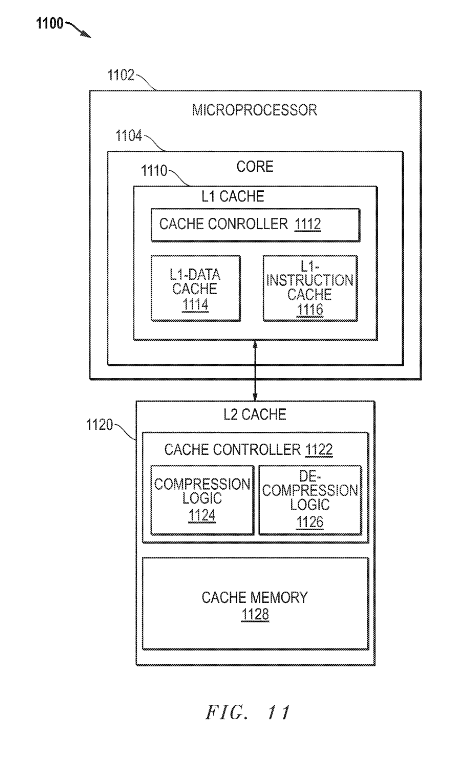
Szerintem az ábra ellenére ez csak egy koncepció, amit bármelyik szinten be lehet vetni.
Azt nem tudom, hogy érdemes-e csak egy közbülső szinten bevetni? Csak L2 esetén, de L1és L3 esetén nem.De a koncepció azért érdekes, mert a késleltetés romlása elkerülhetetlen.
A zen esetén már az L2 esetén látható, hogy a második szelet 256KB késleltetése rosszabb. Ugyanez igaz a legtávolabbi L3 szeletre.A cache kapacitását növelni kell. Eldöntheted:
1) a cache méretét növeled? Ennek valószínűleg lineárishoz közeli lesz tranzisztor- és fogyasztásköltsége és minél nagyobb/távolabbi a cache szelet, annál inkább romlik a késleltetés.
2) beépítesz egy fixfunkciós tömörítő egységet. Ennek is lesz tranzisztorköltsége és fogyasztásköltsége is és bizonyosan rátesz valamekkora késleltetést is.Tehát mindenképpen lesz tranzisztorköltség, fogyasztás és késleltetés. Az a kérdés, hogy vajon melyik megoldással mennyi a nyereség és mennyi a költség?
Az L4$-ről:
Egyetértek. Ugyanakkor most elgondolkodtam.
A zen3 nagy újítása az, hogy 2db 4magos CCX-et egyesített 1db 8magos CCX-ben ezzel megduplázva az 1 mag számára elérhető L3$ méretét és eliminálva azt a kényszert, hogy 1 CCD-n belül elhelyezkedő CCX-ben levő magok az IOD-on, vagy leginkább a memórián keresztül legyenek kénytelenek adatot megosztani. Ez az elmélet.Egyébként az anandtechnek erre vonatkozóan voltak is mérései:
https://www.anandtech.com/show/16214/amd-zen-3-ryzen-deep-dive-review-5950x-5900x-5800x-and-5700x-tested/53950X vs 5950X
Nagyon szépen látszik, hogy már nem csak 4, hanem 8 mag között zöld a késleltetés.
De ami még érdekesebb, a zöld már nem 30ns-ot, hanem 17ns-on jelent két egy CCX-be tartozó mag között. Ez óriási előrelépés!És akkor a kérdés:
Rendben van, hogy ha ez az óriási előrelépést jelentene egy 6-8 magos generációváltás esetében. De Ha a játékokban tapasztalt intelhez képest gyengébb teljesítményt az inter-CCX kommunikáció okozta (ami ugye a 6-8 magos Vermeer lapkákon megszűnik), akkor miért nem tapasztaljuk ugyanezt a teljesítmény-regressziót az 5900X/5950X esetén, ahol továbbra is van CCX-CCX kommunikáció?Ha innen nézem, nem is biztos, hogy olyan sokmindent megoldana egy hatalmas L4$ az IO lapkán
Találgatunk, aztán majd úgyis kiderül..
-
#4394
 Mumukuki
aktív tag
Petykemano
#4390
Mumukuki
aktív tag
Petykemano
#4390
Mumukuki
aktív tag
válasz
Petykemano
#4390
üzenetére
itt se volt benne dollar jel
-
#4395
Cathulhu
addikt
Petykemano
#4393
Cathulhu
addikt
válasz
Petykemano
#4393
üzenetére
L4 szerintem nem is a magok meg a CCX-ek kozotti kommunikacio miatt lenne fontos, sot meg csak nem is a CCD-k kozott, hanem az IMC es a magok kozott. Az IO es a CCD-k kozott igy is van az IF miatt egy jo adag kesleltetes, minden egyes memoria eleresnek a CCD->IO->RAM->IO->CCD utat kell ugye bejarnia, de egy jo nagy L4-el ez CCD->IO->CCD-re lehet optimalis esetben szukiteni. De mivel az L3 igy is marha nagy es tovabbi duplazast varok 5 nanon, L4-nek is csak akkor van ertelme, ha szignifikansan tobbet tud nyujtani mint az L3. Lehet tenyleg csak Epyc eseten lenne ertelme, 1-2 CCD-s asztaliknal nem, franc se tudja.
Arra mondjuk tokeletes lenne hogy az IMC es az IF koze ekelodve koztes bufferkent szepen el le lehetne valasztani az IF frekvenciat az IMC frekvenciatol.Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#4396
 HSM
félisten
Petykemano
#4393
HSM
félisten
Petykemano
#4393
HSM
félisten
válasz
Petykemano
#4393
üzenetére
Ebben a latency dologban az a rendkívül érdekes, hogy korábban CCX-en belül ugyanúgy 17ns körül mértek a 3950X-en, a távoli CCD-n belül viszont lényegesen magasabb volt, mint amit linkeltél: [link]
Valamint volt egy gyorsabb és egy lassabb CCD. Valamelyik AGESA kódban úgy tűnik stratégiát váltottak, ami a CCX-ek szinkronban tartását illeti.
Tehát ezt az "óriási előrelépést" én azért így nem jelenteném ki. Azért a pontos okokra igen kíváncsi lennék. #4395 Pinky Demon :
"De mivel az L3 igy is marha nagy es tovabbi duplazast varok 5 nanon, L4-nek is csak akkor van ertelme, ha szignifikansan tobbet tud nyujtani mint az L3"
Nem helyettesítik egymást. Egy IOD-be rakott L4 éppen a CCD-k közötti szinkronizációt gyorsíthatná, ha ehhez nem kellene a ramig elmenni. A nagyobb L3 pedig a CCD-n belüli teljesítményt tudná javítani, ami egyébként jelenleg is elég jó, de ettől semmivel sem gyorsul a CCD-k közötti kommunikáció. -

S_x96x_S
őstag
úgy néz ki, hogy az Inteles oneAPI-ra szoftveres oldalon is meglesz a válasz ( lásd lejjebb )
És egyre inkább a jövő a CPU+GPU+FPGA ( + Szoftver ) mélyebb integrációjában van.
hogy mit lehet itt elérni arra szép példa az Apple M1-es proci ( habár abban nincs FPGA )
A következő pár évben a technikai fejlődés felgyorsul ...
"AMD ROCm Open-Source Stack Coming To Xilinx FPGAs"
https://www.phoronix.com/scan.php?page=news_item&px=AMD-ROCm-XilinxMottó: "A verseny jó!"
-
S_x96x_S
őstag
"AMD Ryzen 7 5700U and Ryzen 5 5500U (Lucienne) spotted at Geekbench"
https://videocardz.com/newz/amd-ryzen-7-5700u-and-ryzen-5-5500u-lucienne-spotted-at-geekbenchMottó: "A verseny jó!"
-
#4400
Petykemano
veterán
Petykemano
veterán
"AMD today announced that it will bring a technology that should make this processor a lot easier. AMD Precision Boost Overdrive 2 will have a new curve optimizer undervolting that will come with the AGESA 1180 firmware update for AMD 400-series and 500-series motherboards. This tool will allow users to track and adjust voltages for their CPUs. It will opportunistically reduce voltage where possible under heavy load, but also during low use. Instead of relying on a fixed offset for the whole range, it will read the data from internal sensors, such as temperature or socket limits to adapt the voltage when required. This should happen in the frequency of each millisecond."
Azt hiszem én ezt vártam eddig az AVFS-től.
Találgatunk, aztán majd úgyis kiderül..




 De ahogy BiP írta. elengedem, pedig 1 órája szerkesztgetem a hozzászolást neked, de kb annyi értelme lett volna elküldeni, mint estimesét felolvasni a hintalónak...
De ahogy BiP írta. elengedem, pedig 1 órája szerkesztgetem a hozzászolást neked, de kb annyi értelme lett volna elküldeni, mint estimesét felolvasni a hintalónak...

![;]](http://cdn.rios.hu/dl/s/v1.gif) Thx mégegyszer BiP! ( megmentettél 1 hónap kényszerpihenőtől )
Thx mégegyszer BiP! ( megmentettél 1 hónap kényszerpihenőtől ) 





 amúgy ez így nekem tényleg kimaradt, pedig követem a Ryzenes híreket/pletykákat is rendszeresen
amúgy ez így nekem tényleg kimaradt, pedig követem a Ryzenes híreket/pletykákat is rendszeresen 



























Új hozzászólás Aktív témák

- Ryzen 5 3600x, GTX 1070 ti 8gb, 32gb ddr4 ram
- Hugo Boss The Scent Elixir Him Eau de Parfum
- Garis félkonfig! Ryzen 7 5800x,AsusTuf B550 gaming plus, Fury 2x16 3600 cl 16 - GARIS -
- HP Elitebook 850 G8 15.6" FHD IPS Core i5 1135G7 16/512GB HP GAR
- Dell 15,6" notebookok E6540, E5540, i5 - számla, garancia
Állásajánlatok

Cég: Ozeki Kft.
Város: Debrecen

Cég: Promenade Publishing House Kft.
Város: Budapest