Nehalem: mérföldkő vagy sem?

Ha a nemrégiben bemutatott Intel Atomra gondolunk, akkor a kis gépekbe szánt megoldások jutnak eszünkbe. Pedig a most bejelentett Intel Nehalem is lehetett volna "atom", csak más kontextusba helyezve: atomcsapás az AMD fejére. Mert bár ez első pillantásra talán nem látszik, az Intel ismét nagyot durrantott, és ez a megállapítás nem csak magára a processzorra érvényes, hanem a köré épülő rendszerekre is. Nehalem kódnév alatt egy olyan processzorarchitektúrát fogunk megismerni, ami a mobilprocesszoroktól kezdve a high-end szerverekig mindenhol megpróbál majd az AMD nyakára rálépni.
Az Intel tikk-takk névre keresztelt taktikája mindenki számára ismert: a Pentiumok csúfos bukása után az Intel felsővezetése elhatározta, hogy többé nem kíván a másodhegedűs szerepében tetszelegni a piacon sem az eladások, sem a teljesítmény tekintetében. A páros években bemutatkozik egy új architektúra (ez a takk), a páratlan években pedig megjelenik a piacon ennek az alacsonyabb csíkszélességen gyártott változata (ez a tikk). Amikor elindult a tikk-takk "program", 2006-ban az Intel előhozakodott a Core architektúrával (Merom). 2007-ben bemutatta a Core 45 nm csíkszélességen gyártott változatát, a Penrynt. 2008-at írunk, tehát itt az idő valami újra, ez pedig a Nehalem. A Nehalem tehát nem szimplán egy geometriai "frissítés", hanem egy új fejlesztés. Azt persze az Intel sem tagadja, hogy az új generáció alapja a Core architektúra, amely – mint tudjuk – a Pentium M-ből fejlődött ki, ennek elődje pedig a Pentium 3 lehetne, ami az 1995-ös Pentium Pro jelentős átalakuláson keresztülment változata, tehát a Nehalem belsőleg igen messzire nyúlik vissza. Létező gyökerek ezek, ám igencsak távoliak.
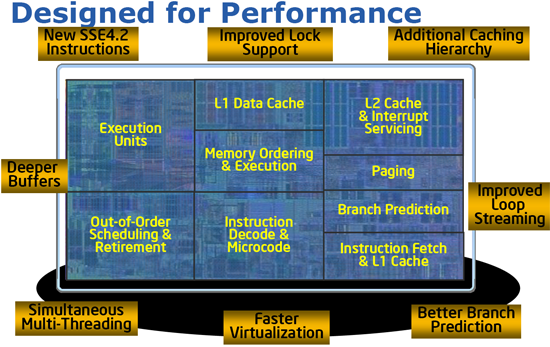
A Core architektúra, illetve ennek 45 nm-es variánsa, a Penryn korábban már bemutatásra került, ezért a most következő felsorolásban szereplő újítások megértéséhez érdemes ezeket a korábban íródott cikkeket újra átnézni. A kérdés egyszerű: mit változtattak meg a Core-on? Azon a Core-on, ami sokak számára, ha nem is tökéletes, de gyakorlatilag bőven megfelel a mindennapi igények kielégítésére. A lista hosszú, de röviden össze lehet foglalni az alapkoncepciót: szokás szerint növelték az adott mennyiségű fogyasztásra vetített órajelenként elérhető teljesítményt. Konkrétabban, címszavakban:
- modulárisan felépülő architektúra, ahol a komponensekből könnyedén "legózható" össze egy-egy erősebb-gyengébb CPU,
- az egyes rendszerkomponensek összekötéséért felelős adatbuszok leváltásra kerültek, mostantól nincs már FSB,
- integrált memóriavezérlő,
- alaposan megváltozott a cache-hierarchia, megjelent a harmadszintű gyorsítótár,
- újra köreinkben üdvözölhetjük az SMT-t, azaz a Hyper-Threading technológiát, amit a Pentium 4 így mégsem vitt magával a sírba,
- dinamikusan kezelt processzormagok, programszálak, gyorsítótárak, interfészek és fogyasztás,
- a SIMD-utasításkészletek kibővítése,
Csapjunk a közepébe, először is lássuk a futószalagot, a teljesítményt befolyásoló újításokat a front-endtől a back-endig! Az utasítások előbehívásáért felelős terület némileg megváltozott. Az előbehívó továbbra is 16 byte széles, de az elágazásbecslő javult; egyrészt az L2 elágazásbecslő színre lépése miatt (másodszintű BTB, azaz Branch Target Buffer), másrészt az RSB (Return Stack Buffer) továbbfejlesztésének köszönhetően. Ezekkel az újításokkal nem csak magának a becslésnek a pontosságán javítottak, hanem a rosszul megjósolt elágazásokból fakadó cikluskiesésekből is sikerült lefaragni; az Intel szerint ez egyszerűen a legjobb elágazásbecslő logika, ami létezik (mi mást mondanának). A macro-op fúzió is jobb lett, mint volt, ez már a JL/JNGE, JGE/JNL, JLE/JNG és JG/JNLE utasításpárokat is képes összefűzni, ráadásul működőképes 64-bites üzemmódban. (Ami zavarbaejtő, ugyanis az előbehívó szélessége változatlan, márpedig a Core 2 esetében azért vetették el a használatát, mert a prefixek miatt az előbehívó nem képes optimálisan működni.) A Core 2-ben az előbehívó után és a dekódoló előtt található a 18 utasítás tárolására képes Loop Stream Detector (végülis egy mini-cache), ami a tizennyolc x86-os utasításnál (macro-op) rövidebb (és külső szubrutinra nem mutató) ciklusok tárolásával és újravégrehajtásával gyorsítja a futást. A Nehalemben található LSD már a dekódolók után helyezkedik el, és 28 micro-op tárolására lett felkészítve (különböző mérések szerint ez kb. 20-23 x86-os utasításnak felel meg). Az a tény, hogy az LSD immár az x86-os utasítások (macro-opok) helyett a belsőleg használt RISC-szerű utasításokat (micro-op) tárolja lehetőséget ad a futószalagon előtte elhelyezkedő részegységek (elágazásbecslés, előbehívás, dekódolás) lekapcsolására, ráadásul a dekódolás lépésének kihagyásával közvetlenül áll összeköttetésben az OoO-motorral, ami szintén gyorsulást hoz magával. A Dedicated Stack Manager és a dekódolás nem változott semmit, három szimpla és egy komplex dekóder végzi a munkát (arról nem szól a fáma, hogy a szimpla dekóderek okosabbak lettek-e).
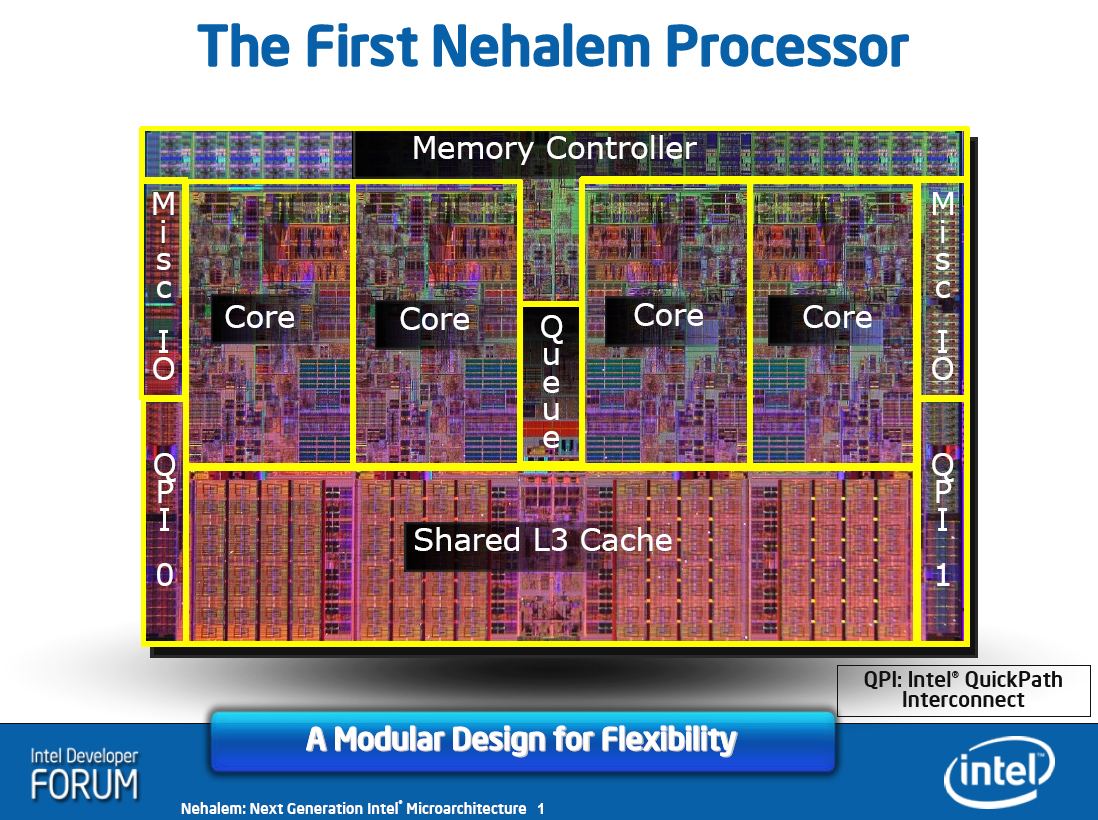
A Nehalem felépítése [+]
A dekódolást követően az utasítások (az LSD után) a ReOrder Bufferbe (ROB) kerülnek. A Nehalemben található ROB-ot 96-ról 128 bejegyzés szélességűre bővítették. Erre a Nehalemnek szüksége is van a Hyper-Threading-technológia miatt, amiről később még szó esik. A függőségek kivizsgálása után, miután elérhetővé válnak az operandusok, az utasítások a Reservation Stationbe (ütemező) kerülnek, ami szintén szélesedett, 32 helyett 36 bejegyzés tárolására képes. Az ütemező az utasításokat/operandusokat a végrehajtó egységek felé továbbítja, ezek száma változatlan a Core 2-höz képest, összesen 3 porton keresztül áramlanak át az adatok (Port 0/1/5) a három lebegőpontos, két egészszámos, illetve három SSE végrehajtó felé. Az ötös porton található végrehajtó kiegészült egy-egy lebegőpontos és integer biteltolást végző blokkal, de ezt leszámítva a végrehajtók nem változtak semmit.

A Reservation Station összesen hat porttal rendelkezik, a fentebb tárgyalt három porton felül további három (Port 2/3/4) szolgál az utasításbeolvasásra vagy kiírásra (Load, Store Address, Store Data). A parancsok végrehajtása után a végeredmény a gyorsítótárak felé veszi az irányt, az itt "feltorlódó" utasítások először a load és store gyorstárakba kerülnek, melyek szintén kiszélesítésre kerültek jórészt a Hyper-Threading-technológia bevezetése miatt: a load puffer 32-ről 48, a store puffer 20-ról 32 bejegyzés szélességűre bővült. Ami magát a futószalagot illeti, ezek a főbb újítások, de még van pár dolog, amiről említést kell tennünk.
A cikk még nem ért véget, kérlek, lapozz!





