Az Intel Atom
Az Intel hivatalosan 2008 áprilisában indította útjára a korábban csak Silverthorne kódnevű, majd később Atom névre keresztelt processzorcsaládját. A korábbi fejlesztésekkel ellentétben az Atom célja a következő számítási teljesítmény rekord felállítás helyett sokkal inkább egy új kategória megteremtése volt, mely remekül passzol a MID-ek (Mobile Internet Devices) és az UMPC-k (Ultra-Mobile PC) világába. Ebből kifolyólag az architektúra tervezésénél az alacsony fogyasztás és a gyártási költségek minimalizálása játszotta a főszerepet.

A kitűzött célokat végül sikerült is elérni, hisz az első sorozat legtöbb tagjának TDP-je mindössze 2 watt volt, de az ultraalacsony fogyasztású Menlow platform alapját képző Z500 személyében egy olyan modell is napvilágot látott, mely 0,65 wattal is beérte. Mindemellett a 45 nanométeres gyártástechnológiával készült egymagos lapka területe nem volt több mint 25 mm², ami rendkívül kicsinek számít az x86-os processzorok világában. Természetesen emellett még fontos, hogy a CPU mellé szükséges infrastruktúra gyártási költsége mekkorára rúg.

Balra a Poulsbo, jobbra a Silverthorne chip
Kézenfekvő, hogy a Silverthorne mellé mindképpen kellett valamilyen chipset is, amely a grafikai magot, a memóriavezérlőt, valamint a meghajtó, USB és a többi vezérlést tartalmazta. Az egyik ilyen (SCH - System Controller Hub) a Poulsbo volt, amely a DirectX 9 képes GMA 500 nevű grafikus részt foglalta magában, amely valójában a Imagination Technologies PowerVR SGX 535 elnevezésű GPU magját és PowerVR VXD névre hallgató dekóderét takarja. Ez utóbbi segítségével a H.264/MPEG-4 AVC kódolású anyagok lejátszása is támogatottá vált. A 130 nanométeres technológiával legyártott megoldás mérete 86 mm² lett, amely több mint háromszorosa a Silverthorne lapkáénak. Érdekesség, hogy az egyetlen chipes dizájn SATA vezérlő helyett csak egyetlen PATA portot kapott, és a memóriavezérlő mindössze 1 GB DDR2-533 szabványú memóriát volt képes kezelni. Ebből is következik, hogy 2,3 wattos TPD-vel rendelkező Poulsbo elsősorban a beágyazott rendszereket célozta meg.
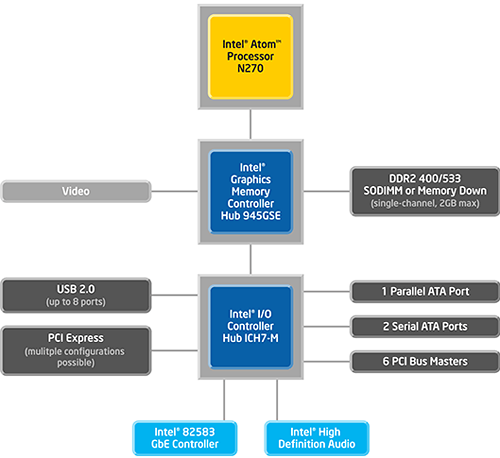
A fentiekből kifolyólag született egy valamelyest klasszikusabb megoldás is, mely a korábbi kétchipes, északi plusz déli híd konfigurációt követte. Az északi híd szerepét a 90 nanométeres technológiával gyártott 945GSE/945GC páros valamelyike kaphatta meg, melyekben immáron a DirectX 9 képes GMA 950 elnevezésű grafikus rész kapott helyet, amiből a H.264/MPEG-4 AVC anyagok hardveres gyorsításának támogatása már sajnos kimaradt. Emellé párosult az ICH7-M déli híd, mely a szokásos feladatokat ellátva, elsősorban a meghajtó és az USB vezérlésért lett felelős. Ezenkívül a chip négy PCI Express sávot is kapott, valamint akár hat sima PCI slot kezelésére is alkalmas lett. A processzorral egyetemben ez már három chipet jelentett az alaplapon, ami a kialakítással járó gyártási költségek, valamint a fogyasztás szempontjából sem volt nevezhető ideálisnak.
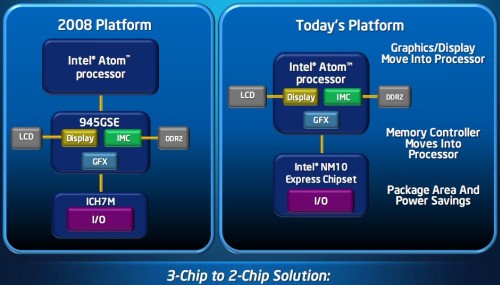
Minderre a 2009 legvégén debütált Pine Trail platform jelentett megoldást, amellyel az Intel beköltöztette a CPU lapkájába a teljes északi hidat. Az egycsatornás memóriavezérlő által támogatott memóriatípus elsődlegesen továbbra is a DDR2 maradt (667 és 800 MHz-en), de bizonyos modellek mellé már a DDR3-800 szabványú modulok is párosíthatóvá váltak. A processzormaghoz, azaz az architektúrához nem nyúlt az Intel. A korábbi déli híd szerepét a 2,1 wattos, NM10 Express névre keresztelt megoldás kapta meg. A chip tartalmazza a HD hangkodeket, továbbá négy darab PCI Express csatornáról, valamint a SATA 3 Gbps, illetve a 2.0-s verziójú USB portokról is gondoskodik. Az integrált grafikus mag itt már a GMA 3150 elnevezést kapta, de a számozásbeli nagy ugrással szemben a teljesítményét tekintve már csekélyebb az előrelépés. Egyrészt az megoldás csak az MPEG-2 kódolású anyagokat képes hardveresen gyorsítani, azaz H.264 és VC-1 továbbra sem lett támogatott, másrészt hiába nőtt a grafikai teljesítmény néhol 20-30%-kal is, még összességében így is igencsak harmatos maradt a GPU rész.

Egy szem egymagos Pineview Atom
Mindenesetre a kitűzött célt ismét sikerült elérni, hisz a platformhoz szükséges lapkák előállítási költsége és a fogyasztás is csökkent. Az egymagos, immáron egy teljes északi hidat is tartalmazó Pineview Atom mérete 66 mm² lett, míg kétmagos rokonáé 87 mm². (Érdekességképpen, ez utóbbi méret szinte pontosan megegyezik a korábbi Poulsbo vezérlőjével.) Ezzel az alaplapokhoz is már csak 4 rétegű nyák lett szükséges, ami egy komplett termék legyártásának költségeire volt jó hatással.
Az Atom mikroarchitektúrája
Az Atom mikroarchitektúra minden szempontból ellentéte az Intel 1995-ben a Pentium Próval megkezdett stratégiájának, miszerint az x86(/x64)-es programok végrehajtásának legcélravezetőbb módja azok egyszerű, RISC műveletekké bontása és ezek out-of-order végrehajtása. Ahogy már utaltunk is rá, az Atom a minél nagyobb teljesítmény hajszolása helyett egy teljesen más stratégiát választott: minél kevesebb tranzisztor felhasználásával alkotni mikroprocesszort úgy, hogy annak kihasználtsága a lehető legnagyobb legyen. Természetesen meghúztak egy teljesítményszintet, amit el kell érni a lapkával, de a lécet nem tették túl magasra. Nézzük meg közelebbről a megvalósítás részleteit!
Először is kihagyták az összes soron kívüli végrehajtáshoz szükséges logikát a processzorból, így az az utasításokat a programsorrendnek megfelelően (in-order) hajtja végre. Az x86/x64 utasítások sematikusan a következőképpen kerülnek végrehajtásra:
- betöltik forrásadataikat, amelyek közül legfeljebb 1 lehet egy memóriacímen, a többi regiszterben található;
- végrehajtják a számítási műveletet, ha ilyen van az utasításban;
- az eredményt tárolják regiszterben és/vagy egy memóriacímre írják.
Ez a séma minden utasításra ráhúzható, legyen az valós számítási művelet vagy csak egyszerű adatbetöltés a memóriából, illetve adattárolás a memóriába. A modern processzorok tipikusan a felsorolt 3 egyszerű, uop-nak nevezett RISC-műveletre bontják az utasításokat, és ezeket hajtják végre soron kívül, minden uop-típusnak külön végrehajtó egységeket dedikálva.
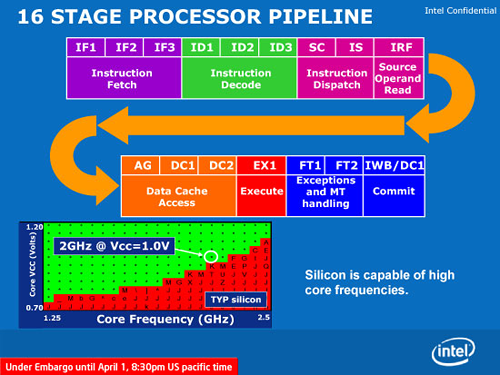
Létezik viszont egy másik megoldási mód is, amikor egyetlen olyan futószalagot hozunk létre a processzorban, amelynek lépcsőit a fenn felsoroltak alkotják: minden utasítás végigmegy minden lépcsőn, közben elvégezve a betöltést, a számítást és a tárolást. Optimális esetben minden lépcsőfokon tartózkodik egy-egy utasítás, és órajelenként továbblép a következőre. Az Atom pontosan ezt valósítja meg, csakúgy, mint a Pentium és az azt megelőző x86 processzorok. Ennek természetesen jó és rossz következményei is vannak: az utasítások dekódolása redukálódik azok elejének és végének megkeresésére, valamint a komplex, mikrokódot igénylő műveletek kiszűrésére; viszont mivel a futószalag úgy épül fel, hogy a lehető legtöbbféle utasítást ki tudja szolgálni, eléggé megnyúlik, soklépcsős lesz: az Atom futószalagja 16 állomásból áll, ami hosszabb, mint pl. a Core 2-é. Továbbá számolniuk kell a tervezőknek azzal, hogy egy-egy hosszabb művelet (például ha a beolvasandó adat nincs az L1 cache-ben, akkor annak betöltése az L2-ből vagy a memóriából) hosszabb-rövidebb időre megállíthatja a futószalagot, tehát egyetlen utasítás miatt nem tud továbblépni a többi sem. Ezt többféle módon kezelték:
- Két pipeline-t tettek egymás mellé, ez - bár az utasítások nem előzhetik meg egymást, – lehetővé teszi, hogy sok esetben 2 egymást közvetlenül követő utasítás végrehajtása egyszerre történjen, ha azok függetlenek egymástól; ezt utasításpárosításnak hívják.
- Mivel hosszú a pipeline, ezért hatékony elágazásbecslő logikát is beépítettek, hogy az utasításbetöltésnek ne kelljen megvárnia az ugró utasítások kiszámítását.
- Újra alkalmazták a Hyper-Threading technológiát, így a két pipeline-t két programszál etetheti: a két szál utasításai biztosan függetlenek egymástól, az esetek nagy részében végrehajtható mindkettőből 1-1 utasítás párhuzamosan. Ha az egyik szál végrehajtása megáll például egy L1-tévesztés miatt, akkor a kért adat megérkezéséig a másik szál teljesen kisajátíthatja mindkét futószalagot.
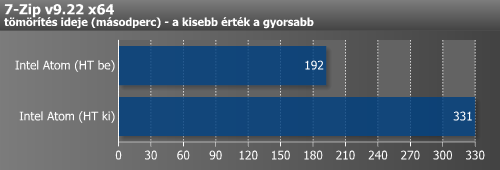

Ha belegondolunk, ilyen megállások esetén nincs meg a processzornak az a választási lehetősége, hogy addig is az adott programszál későbbi utasításait hajtsa végre, mint az out-of-order felépítésnél: egy szál futtatásakor kénytelen megvárni az adatot, két szál futtatásakor pedig szükségszerűen a másik szál utasításait kell végrehajtania. Így meg is magyaráztuk, hogy miért látunk Atomnál a fenti méréseink által is alátámasztott, kétszálas végrehajtásnál akár 70-80%-os gyorsulást az egyszálas futtatáshoz képest, míg a többi Hyper-Threadinggel ellátott CPU-nál ez csak 20-25% körül tetőzik.
Az így összerakott komplett felépítést ábrázolja az alábbi ábra:
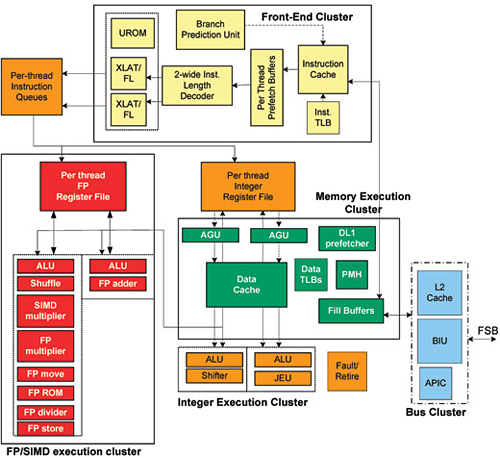
Az előre meghatározott teljesítményszint mellett a tranzisztorszám és a fogyasztás minél alacsonyabban tartásához néhány további trükkhöz folyamodott a tervezőgárda:
- Az L1 cache-eket 6T helyett 8T cellákból építették fel, amelyek ugyan így több tranzisztort emésztenek fel – ezért 32 kB helyett csak 24 kB méretű adatcache-t építettek be –, viszont előnye, hogy alacsonyabb feszültség mellett is stabil működést mutat, így ki lehetett hagyni az L1 adatcache-hez tartozó ECC hibadetektáló és -javító logikát, valamint a szükséges magfeszültség is csökkenthető.
- Két egyszerű adat-előbetöltő (prefetch) logikát alkalmaztak; az egyik a memóriából az L2 cache-be tölt be, a másik az L2-ből az L1-be, így csökkentve a cache-tévesztések miatti futószalag-megállások számát.
- Az utasítások dekódolása eléggé lassú (3 órajel/utasítás), viszont a dekóder feljegyzi az utasítások határait és komplexitását az L1 utasításcache-be, így ha újra találkozik a már egyszer feldolgozott utasításokkal pl. ciklusok esetében, akkor órajelenként 2 utasítást tud küldeni végrehajtásra.
- A processzor az SSE4 kivételével támogatja az összes SIMD-utasításkészletet, amit a 65 nm-es Core 2 is, ezek az MMX, SSE, SSE2, SSE3, SSSE3, viszont csak az egyszerű SIMD-integer műveletek és a 32 bites Single Precision lebegőpontos összeadások kaptak 128 bites végrehajtó egységet, a többi műveletet két 64 bites lépcsőben hajtja végre. Ezáltal a két pipeline SIMD és lebegőpontos része specializált, ezen műveletek meghatározottan csak egyik vagy csak másik pipeline-ban kerülhetnek végrehajtásra (természetesen akár párosítva egy másik, megfelelő utasítással).
- Ugyancsak specializált a memóriakezelés szempontjából is a két pipeline, ugyanis a memória-alrendszerhez csak az egyiknek van hozzáférése, ezáltal minden memóriaparaméteres utasítás erre a futószalagra kerül. Így nincs szükség a hozzáférések költséges összehangolására, bizonyosan mindegyik a megfelelő sorrendben kerül végrehajtásra.
- Bár sok változatában le van tiltva, alapvetően támogatja az x64 végrehajtási környezetet, viszont 32 bites programok végrehajtása közben lekapcsolja a +32 bithez szükséges regiszter-területeket és műveletvégző egységeket.
VIA Nano: a számkivetett
A VIA mint gyártó hallatán talán a legtöbb embernek a chipkészletek és a különböző vezérlők (USB, FireWire, Ethernet, Audio) ugranak be elsőre. Egészen 1998-ig csak hasonló chipek tervezésével foglalkozott a tajvani cég, amikor felvásárolták a Cyrixet, majd egy évvel később az IDT (Integrated Device Technology) Centaur Technology nevű divízióját is, mely szintén x86-os processzorok tervezésével foglalkozott. Ezen felvásárlások közvetlen gyermekei lettek a VIA Cyrix III, C3 és C7 processzorok. 2001-ben a grafikus processzorokat tervező S3-at is bekebelezte a cég (amin egyébiránt épp a közelmúltban adott túl), amivel jóformán minden meglett, ami egy platformhoz szükséges.
![]()
A C7 után a cég úgy döntött, hogy következő, Isaiah kódnevű architektúra építését a nulláról kezdik el. A cél egy hatékony, az általános alkalmazásokban jó teljesítményt nyújtó architektúra összerakása volt. Kézzelfogható termék végül csak 2008 közepén vált a fejlesztésből. A Fujitsu 65 nm-es gyártósorain készült egymagos, 63 mm²-es, Nano névre keresztelt processzorokból 1,8 GHz-es lett a legmagasabb órajelű, mely mellé 25 wattos TDP társult, míg a legkisebb 1 GHz-es U2300 beérte 5 wattal is.

A rendszer infrastruktúra hasonló volt, mint a legelső Atom esetében. A VIA CN896-os északi híd a DDR2-667 szabványú memóriákat vezérlő egység mellett egy beépített DirectX 9 kompatibilis Chrome9 grafikus processzort kapott, ami mellé még 16 PCI Express sáv is befért. Ezt bizonyos koncepciókon egy teljes hosszúságú slot formájában kivezetésre is került. A VT8237S modellszámú déli híd egy PATA és két SATA-300 interfészt volt képes kezelni 8 db USB 2.0 port mellett.

A VIA VB8001 alaplapja
Az Isaiah mikroarchitektúra
Az Atom architektúrájával szemben a VIA Nano processzor teljesen más kategóriát képvisel: noha tervezési szempontjai között ugyancsak az elsők közt szerepelt az alacsony fogyasztás és a gazdaságos előállítás, mégis egy teljes, 3 utasítás széles out-of-order felépítésű processzorral állunk szemben.

A CPU a 64 kB-os, 16 utas csoportasszociatív L1 utasításcache-ből órajelenként 16 bájtot betöltve 3 db x86 vagy x64 utasítás dekódolására képes, ezek bármilyen komplexitásúak lehetnek. Az Intel processzorokban megismert micro-fusionhoz hasonlóan a lefordított, összetartozó (pl. betöltő és számítási) primitív RISC-műveleteket egyesítve küldi a végrehajtó egységek felé, legfejlebb hármat órajelenként. Képes továbbá az egymást követő összehasonlító és elágazási utasítások egyesítésére (macro-fusion).

A végrehajtó egységekből szám szerint 7 van a processzorban, melyek out-of-order módon kapják meg a műveleteket, amint azok bemenő adatai rendelkezésre állnak:
- Két, I1 és I2 névvel ellátott, egész számokon dolgozó egység, amelyek a szorzásokon és osztásokon minden integer műveletet végrehajtanak egy órajel alatt.
- Az LD nevű címszámító a memóriaolvasásokhoz; a vele kapcsolatban álló Memory Ordering Buffer (MOB) képes az olvasásokat out-of-order módon átrendezni, akár az írási utasításokhoz képest is.
- Egy-egy egység a memóriaírási műveletek címeihez (SA) és adataihoz (ST)
- Az MA (Media A) kezeli az osztó, lebegőpontos négyzetgyök és integer SIMD műveleteket; továbbá ennek terepe az összes lebegőpontos összeadás, amelyeket 2 órajel alatt képes végrehajtani, amivel maga mögé utasítja az összes konkurens AMD és Intel processzort.
- Az MB (Media B) egység a szorzó utasításokat kapja, amelyek közül a 32 bites Single Precision szorzásokat 3, a többit 4 órajel alatt hajtja végre, így ezen a területen is a többi gyártó megoldásai előtt, illetve velük fej-fej mellett van. Érdekesség továbbá, hogy képes a lebegőpontos FMA-számítások kezelésére; mivel azonban tervezése idején még nem álltak készen az ezt kihasználó utasításkészletek, így ezt a képességét csak a nagy bonyolultságú x87-utasítások (szinusz, koszinusz stb.). számolására szolgáló belső mikrokód-algoritmusok használják ki. A összes Media A és B által kezelt lebegőpontos SIMD művelet végrehajtása 128 bites, ahogyan az integer SIMD műveletek is 128 bites végrehajtókat kaptak. Támogatott utasításkészletei az MMX, SSE, SSE2, SSE3, valamint tartalmazza az Intel-féle virtualizációs megoldást és az x64 végrehajtási környezet támogatását is.
Külön érdemes megemlíteni az L1 utasításcache olvasásánál alkalmazott elágazásbecslő logikákat: nem véletlen a többes szám, mivel a tervezőgárda nem kevesebb mint 8 ilyen egységet épített be a processzorba, amelyek különféle szempontok szerint értékelik az aktuális szituációt, és egyfajta "szavazásos" módszerrel döntik el mindig, hogy a következő órajelben a CPU mely címről kiindulva folytassa az utasítások végrehajtását.
A processzort 64 kB méretű, 16 utas csoportasszociatív L1 adatcache-sel látták el, valamint 1 MB méretű, ugyancsak 16-utas L2 másodszintű tárral. Ezek exkluzív felépítésűek, azaz ugyanazt az adatok csak egyikük tartalmazza. Rendhagyó módon kezeli a Nano az adat-előbetöltéseket: a nagy valószínűséggel használt adatokat közvetlenül az L1D-be tölti be, viszont a nagyobb bizonytalansággal rendelkező spekulációknak egy külön 64 x 64 byte-os Data Prefetch cache-t tart fenn, így nem írja felül a cache-ekben tárolt "értékes" adatokat.

A fenti képen jól látható, hogy az out-of-order végrehajtásért felelős részek (MOB, Scheduler, ROB, Retire) mekkora területet foglalnak el.
Megszokhattuk a VIA-tól, hogy sokszor olyan, jövőbe mutató tulajdonságokat halmoz fel processzoraiban, amelyek a konkurenseknél csak később jelennek meg: ilyen pl. volt az AES (titkosítás) korai támogatása, illetve a Nanokban már megtalálható hardveres véletlenszám-generátor. Teljesítményben viszont jóformán mindig az Intel és az AMD mögött jártak.
Az AMD Bobcat
Az AMD az alacsony fogyasztású processzorok párharcába csak idén januárban, meglehetősen nagy késéssel tudott beszállni. A direkt erre a célra tervezett Bobcat kódnevű dizájnt körülbelül akkor kezdték el tervezni, amikor az Atom és a Nano megjelent. Ezzel meglehetősen nagy hátrányt kellett ledolgozniuk, bár jóformán már minden kéznél volt egy megfelelő mikroarchitektúra összeállításához.

A fejlesztés immáron a Fusion irányvonal égisze alatt zajlott, mely gyakorlatilag a CPU- és GPU-funkciók egyetlen szilíciumlapkán való egyesítését rejti a név mögött. Ez egyben azt jelenti, hogy itt egy APU-ról (Accelerated Processing Unit) beszélhetünk. Az ilyen processzoroknál az alapötlet olyan processzorok megalkotása volt, amelyek heterogén módon programozhatóak, azaz egyszerre lehet kihasználni az x86-os CPU-mag/magok és a GPU számítási kapacitását.

A fenti képen jól látható, hogy egyetlen mag 512 kB méretű másodszintű gyorsítótárával durván a teljes, 75 mm²-es lapkának csak egy nyolcadát teszi ki. Ez is azt mutatja, hogy a koncepció tervezésénél nem az x86-os magokra helyezték a fő hangsúlyt. A GPU összesen 80 shader egységet foglal magában, valamint ezek mellett integrálásra került egy egycsatornás DDR3 memóriavezérlő és négy opcionálisan felhasználható PCI Express sáv. A grafikus szekciónak köszönhetően a rendszer támogatja a DirectX 11, OpenGL 4.1, OpenCL 1.1, OpenGL ES 2.0, valamint a DirectCompute 5.0-s API-t is. Továbbá az UVD 3.0 motor kezeli a H.264/AVC, az MPEG-2/4, a VC-1, a DivX és az XviD videók gyorsítását egészen Full HD felbontásig. Az APU-hoz közvetlenül csatlakozik az egyetlen vezérlőhíd (FCH). A Hudson M1 (A50) névre hallgató chip hat darab SATA 6 Gbps és 16 USB portot képes vezérelni. Ezenkívül a processzorban található PCIe sávok mellé itt még további négy társul.

[+]
A Bobcat architektúra alkalmazásával egyelőre csak a fenti, TSMC által gyártott 40 nm-en kétmagos lapka született. Ebből jelenleg az E-450 típusjelzésű Zacate kódnevű a leggyorsabb, mely két x86-os magot tartalmaz 1,65 GHz-es órajelekkel. Ez utóbbi TDP-je 18 watt, amely természetesen magában foglalja a grafikus mag, valamint a többi integrált részegység és vezérlő energiaigényét is. A Zacate mellett egy kisebb fogyasztású, Ontario kódnevű verzió is piacra került. Ebből jelenleg a C-50 a legismertebb, mely szintén két x86-os magot vonultat fel, de azok órajele csak 1 GHz, viszont ezzel együtt a TDP is csak 9 watt. A fent említett E-450-nel párhuzamosan debütált a C-50 utódja a C-60, amely a Turbo Core technológiával, a korábbi 9 wattos fogyasztási keret figyelembevétele mellett, szükség esetén képes a magok órajelét 1,33 GHz-re emelni. Az első Zacate és Ontario még csak a DDR3-1066 szabványú memóriamodulokat kezelt, azonban a közelmúltban megjelent frissítést követően az új modelleknél ez már DDR3-1333 MHz-re ugrott. Ebből leginkább a beépített grafikus vezérlő képes szignifikánsan profitálni.

Az E-350
A Bobcat mikroarchitektúra
Az AMD Bobcat nevű fejlesztése a kettes szám és az out-of-order végrehajtás jegyében fogant. Felépítése ugyan nagyon hasonlít a K8 processzorokéhoz, viszont míg az 3 utasítás széles mikroarchitektúra, addig a Bobcat minden összetevője órajelenként 2 művelet kezelésére képes.

[+]
Mint a fenti kép is elárulja, 32 kB méretű L1 utasításcache-éből egy kisméretű elágazásbecslő egységgel karöltve órajelenként 2 utasítást tud dekódolni (és a nagy testvér K8-hoz hasonlóan az összetartozó belső RISC-műveleteket macro-oppá egyesíteni), majd továbbküldeni a megfelelő ütemezők (schedulerek) felé, amelyből hármat találunk a processzorban:
- Az integer ütemező a 2, szinte teljesen megegyező integer végrehajtót (I pipe) látja el műveletekkel, melyek a szorzások és osztások kivételével bármilyen, egész számokon végzett számítási művelettel megbirkóznak, azaz általánosak.
- A címszámítási ütemező a beolvasandó memóriacímeket kiszámító Load Pipe-nak és a tárolási címeket kalkuláló Store Pipe-nak küldi az utasításokat, együttműködve az integer résszel, mivel azzal közös fizikai regiszter fájlon osztoznak. A kiszámított címek utáni memóriahozzáférések – melyek teljes mértékben átrendezhetők egymás között – a 32 kB-os L1 adatcache-hez kerülnek feldolgozásra; ennek késleltetése 3 órajel, feldolgozási kapacitása órajelenként egy 64 bites olvasás + egy 64 bites írás. Ha az elsődleges gyorstárban nem található a keresett adat, akkor a kérés a 512 kB-os L2 tárhoz kerül, amely a fogyasztás további leszorításának érdekében a mindenkori magórajel felén üzemel; ennek megfelelően nem túl gyorsan, 17 órajel alatt tudja szolgáltatni a kért adatot.
- Az FP ütemező a 2 SIMD- és lebegőpontos végrehajtót vezérli, melyek 64 bites lépcsőkben dolgozzák fel a 128 bites utasításokat, és saját, 64 bit elemméretű regiszter fájllal rendelkeznek. A végrehajtók szinte teljes mértékben specializáltak: az A(dd) Pipe kapja a lebegőpontos összeadás jellegű (összeadás, kivonás, összehasonlítás stb.), valamint az egész számokon végzett szorzási műveleteket, míg az M(ul) Pipe a lebegőpontos szorzásokat, gyökvonásokat illetve az összes osztást. Az egyszerű SIMD integer összeadási és logikai műveletek kiszámítására azonban mindkettő képes.
Ahogy már utaltunk rá, az AMD hagyományainak megfelelően helyet kapott a lapkán egy integrált memóriavezérlő is, amely egycsatornás, azaz 64 bites üzemmódban képes működni, és üzemi órajele minden esetben a rendszermemória effektív órajelének pontosan a fele.

[+]
A Bobcat egyfajta arany középútnak is tekinthető az Intel Atomja és a VIA Nanója között: bármelyik részegységét is tekintjük, az 2 műveletet hajt végre órajelenként, viszont ezt, ahol csak lehetősége van rá, out-of-order módon teszi. Csak a legkevesebb tranzisztort és energiát kívánó részét, az egész számok feldolgozóit duplázták meg, a többi egysége erősen specializált és minimális méretű, így például még véletlenül sem találkozunk 128 bites végrehajtással sehol (a fogyasztási keretet lazábban kezelő processzorokban a 128 bites végrehajtást a tradicionális 64 bites egységek megkétszerezésével érik el). Utasításkészleteiben sem marad el a másik két, korábban vizsgált mikroarchitektúrától, mivel az MMX, SSE, SSE2, SSE3, SSSE3 mellett támogatja a x64-et, a virtualizációt és az AMD-specifikus SSE4A-t is, viszont 3DNow!-támogatással már nem rendelkezik.

[+]
Specifikációk, tesztrendszer, fogyasztás
Ahogy a bevezetőben is utaltunk rá, jelen tesztünkben arra voltunk kíváncsiak, hogy az x86-os számításokat igénylő feladatokban mire mennek egymás ellen a résztvevők. Korábbi tesztünkben már összevetettük a platformok grafikus képességit, de akkor tisztán a CPU részről nem sok szó esett. Véleményünk szerint ebben a kategóriában még egy teljesen átlagfelhasználó számára is fontos a CPU sebessége, hisz bizonyos esetekben arról dönthet mindez, hogy érzünk-e feltűnően, már-már zavaróan lassú programindítást vagy -végrehajtást. Ezzel szemben a közép- és csúcskategóriában olykor fel sem tűnhet néhány másodpercnyi különbség. Bárhonnan is nézzük, még döntő fontosságú lehet mindez, hisz megfelelő mennyiségű és minőségű, a grafikus mag számítási teljesítményét kiaknázni képes alkalmazás nélkül a programok tisztán csak az x86-os CPU részre támaszkodhatnak.
Jelenleg ott tartunk, hogy a grafikus szekció a 3D-s megjelenítéseken kívül elsősorban a különféle videóanyagok lejátszását képes gyorsítani, azaz levenni a terhet az x86-os mag(ok) válláról. Erre a Pineview Atom csak részben, az MPEG-2 kódolású tartalmak gyorsításával képes, ahogy a Nano melletti VIA Chrome9 HC is. Az NVIDIA ION segítségével már egészen más a helyzet, amelyre imént említett, tavaszi tesztünkben ki is tértünk. Az AMD megoldása szinte bármilyen tartalommal megbirkózik, egyes Flash és webes formátumok gyorsítását is ideértve. Ez utóbbinál az OpenCL, DirectCompute, valamint az ATI/AMD Stream támogatásának jóvoltából a GPU-ban rejlő teljesítmény általános számításokra is felhasználható. A különféle videokódoló szoftvereket kivéve egyelőre nincs túl sok alkalmazás, ami profitálni tud ebből.
| CPU Megnevezése | Intel Atom D410 | AMD E-350 | VIA Nano L2200 |
|---|---|---|---|
| Kódnév | Pineview | Zacate | Isaiah |
| Architektúra | Lincroft | Bobcat | Isaiah |
| Tokozás (érintkezők) | micro-FCBGA8 (559) | FT1 BGA (413) | NanoBGA2 (400) |
| Gyártástechnológia | 45 nm bulk HKMG | 40 nm bulk | 65 nm bulk |
| Stepping | B0 | B0 | CNA2 |
| Magok / szálak | 1 / 2 | 2 / 2* | 1 / 1 |
| Magórajel | 1666 MHz | 1600 MHz | 1600 MHz |
| Szorzó és ref. órajel | 10 x 166 MHz | 16 x 100 MHz | 8 x 200 MHz |
| L1 D-cache / mag | 24 kB (6 utas) | 32 kB (8 utas) | 64 kB (16 utas) |
| L1 I-cache / mag | 32 kB (8 utas) | 32 kB (2 utas) | 64 kB (16 utas) |
| L2 cache / mag | 512 kB (8 utas) | 512 kB (16 utas) | 1024 kB (16 utas) |
| Utasításkészletek | MMX, SSE, SSE2, SSE3, EM64T | MMX, SSE, SSE2, SSE3, SSE4a, x86-64, AMD-V | MMX, SSE, SSE2, SSE3, x86-64 |
| Rendszerbusz | 667 MHz FSB | 2500 MT/s UMI Link | 800 MHz FSB |
| Támogatott RAM | DDR2-800 | DDR3-1066 | DDR2-667 |
| CPU feszültség | 1,15 V | 1,30 V | 1,10 V |
| TDP | max. 10 W | max. 18 W | max. 17 W |
| Tranzisztorok száma Mag mérete |
123 millió 66 mm2 |
380 millió 75 mm2 |
94 millió 63 mm2 |
| * a tesztekhez az egyik magot letiltottuk | |||
Azonos órajelre és magszámra törekedtünk, mivel most és itt arra voltunk kíváncsiak, hogy ilyen felállásban mit tud egymás ellen a két mikroarchitektúra. Ehhez az AMD E-350 egyik magját letiltottuk, amivel egy E-240 közeli CPU-t sikerült létrehozni. Azért csak közelit, mert az E-240 egyetlen magja 1500 MHz-en ketyeg, itt pedig 1600 MHz maradt az órajel. Az Atom D410 1666 MHz-es, amivel nem nagyon tudtunk mit kezdeni, így az Intel versenyzője durván 4%-os órajelelőnnyel indult. Mivel ez utóbbi processzor/mikroarchitektúra szerves része a Hyper-threading, valamint ez a funkció kivétel nélkül az összes Atom processzorban aktív, ezért ehhez nem nyúltuk, azaz a tesztek alatt be volt kapcsolva. Ezzel gyakorlatilag egy teljes értékű egymagos Atom és egy teljes értékű egymagos Bobcat küzdhetett egymás ellen.
Bármennyire is szerettük volna, sajnos VIA Nano alapú rendszert nem sikerült szereznünk tesztünkhöz. Ennek okán ezt a megoldást csak az AIDA64 által mért szintetikus eredményekben tudtuk összevetni. Érdekes lett volna látni, hogy mire képes a másik két megoldáshoz viszonyítva a Nano, de mivel gyakorlatilag csak nagyítóval (sőt azzal is nehezen) lehet találni erre épülő terméket, ezért annyira nem is lett volna releváns, mint az Intel és az AMD processzorai.

[+]
| AMD tesztplatform | AMD E-350 (1,6 GHz, 1 mag letiltva) ASRock E350M1 alaplap (A50M chipset, BIOS: 1.40) 1 x 2 GB CSX DDR3-1600; 1066 MHz-en 8-8-8-20-1T időzítésekkel |
|---|---|
| Intel tesztplatform | Intel Atom D410 (1,66 GHz) Intel Desktop Board D410PT alaplap (Intel NM10 chipset, BIOS: 0542) 2 x 1 GB Corsair DDR2-800; 800 MHz-en 5-5-5-18-2T időzítésekkel |
| IGP-k | AMD Radeon HD 6310 (AMD E-350 IGP) Intel GMA 3150 (Intel Atom D410 IGP) |
| Háttértárak | Intel SSD 510 250 GB SSDSC2MH250A2 (SATA 6 Gbps) Kingston SSDNow M Series 80 GB SNM225-S2/80 GB (Intel X25-M G2) Seagate Barracuda 7200.12 500 GB (SATA, 7200 rpm, 16 MB cache) |
| Tápegység | 120 wattos ATX paneltáp + 90 wattos hálózati adapter |
| Monitor | Samsung Syncmaster 305T Plus (30") |
| Operációs rendszer |
Windows 7 Ultimate 64 bit |

[+]
Hallgatva olvasóink tanácsaira, mostantól az alacsony fogyasztású rendszerekhez paneltápot használunk. Ez amellett, hogy teljesen passzív (zajtalan), ebben a viszonylag alacsony, 100 watt alatti zónában jobb hatékonysággal dolgozik. Elsősorban utóbbinak vesszük hasznát, mert pontosabb és reálisabb fogyasztási adatokat tudunk szolgáltatni olvasóink felé. Ennek oka, hogy a nagy, 500-600 wattos tápok ilyen kis terhelésnél meglehetősen rossz hatásfokkal dolgoznak. Tételezzük fel, hogy a tápegység, amit használunk, 50 watt környékén csak 70%-os hatékonysággal képes működni. Amennyiben erre a tápra kötött konfiguráció 40 wattot vesz fel, akkor az a 230 voltos hálózat felől már 57 wattot jelent, és ezzel mi is ezt az értéket látjuk viszont a fogyasztásmérőn. Az 57 és 40 watt közötti különbség hőenergia formájában gyakorlatilag kárba vész. Ugyanez a felállás 90%-os hatékonyság esetén már csak kb. 44 wattot kérne magának az elektromos hálózatból, ami kevesebb mint negyedét jelenti a feleslegesen elfűtött energiának a 70%-os gyengébb értékkel szemben.
Akkor mindezek ismeretében következzen is a fogyasztás! Ennek mérését egy konnektorba dugható, digitális VOLTCRAFT Energy Check 3000 készülékkel végeztük, és ahogy minden esetben, úgy most is a teljes konfiguráció értékeit vizsgáltuk.

Túl sokat nem lehet hozzáfűzni a fenti grafikonhoz. Terheletlenül az AMD szerepel jobban, míg terhelve az Intel. Ez valószínűleg annak köszönhető, hogy a Bobcat-alapú megoldás hatékonyabban képes lekapcsolni az éppen nem szükséges részegységeket.
Szintetikus eredmények: memória-alrendszer
Első körben szintetikus méréseket végeztünk a különböző processzorokkal és platformokkal. Ehhez az AIDA64 nevű programot hívtuk segítségül. Először az L1D cache sebességét néztük meg.

Az Atom órajelenként egy 128 bites adat olvasására vagy írására képes, a Bobcat órajelenként egy 64 bites adatot tud olvasni és egy másikat írni. A VIA Nano, bár 128 bites hozzáférése van az L1 cache-hez, órajelenkénti egy olvasási vagy egy írási képességgel, csak másolásban tudja hozni az elvárt szintet.

A másodszintű gyorsítótár esetében összességében továbbra is az Atom van elöl. Olvasásban a Bobcat ugyan egy lehelettel jobb, de írásnál és másolásnál elmarad az Inteltől.

Az elsőszintű gyorsítótárak késleltetésénél az Intel és az AMD szinte azonos eredményt produkál, míg a második szinten gyorsabb a Bobcat. A VIA Nano itt mindkét esetben lemarad, de az L2-nél különösen, bár a két konkurenssel szemben ő kétszer akkora, 1 MB-os másodszintű gyorsítótárral rendelkezik.

A memória-sávszélesség tekintetében ismét az Atom van az élen. Írásban a Bobcat eléggé elmarad még a Nanóhoz képest is.

A memória-késleltetést vizsgálva az L2-nél látottakhoz hasonló képet kaptunk. Ez talán annyira nem is meglepő, hisz a mérésbe beleszámít a másodszintű gyorsítótár sebessége is.
Szintetikus eredmények: utasítás-végrehajtás
Ezt követően az AIDA64 CPU és FPU benchmark moduljai felé vettük az irányt, melyekből összesen kilenc különféle teszttel mértük meg a processzorokat. Az egyik ilyen a CPU Queen, mely egy egyszerű, egész számokkal dolgozó benchmark, amely a processzorok elágazásbecslési képességeire fókuszál, és a „nyolc királynő egy sakktáblán” feladványra épül (10 x 10-es sakktáblán). A teszt MMX-, SSE2- és SSSE3-optimalizált, és kevesebb mint 1 MB memóriát foglal le. Ebben a tesztben az elágazáskezelés képességei határozzák meg a pontszámot. Nemcsak a branch prediction táblák és a becslés pontossága, a return stack mérete, hanem az is, hogy az utasításkészlet támogatja-e valamilyen módon maguknak az elágazásoknak az elkerülését (van-e CMOV vagy PABSB utasítás), illetve képes-e egyszerre párhuzamosan több bábu helyzetével számolni. Ezen felül a memóriaelérés sebessége is tükröződik az eredményekben.

Itt az Atom szépen elhúz, ami szerintünk a magasabb memória-sávszélességnek és a kétszálas végrehajtásnak köszönhető.
A következő integer teszt a CPU Photoworxx, amely különböző digitális fotófeldolgozási műveleteket hajtat végre a processzorral (kitöltés, forgatás, random stb.). Ez a teszt főleg a processzorok integer számolási végrehajtási egységeit dolgoztatja meg a memória-alrendszerrel egyetemben. A teszt csak alap x86-os utasításokat használ. A Photoworxx a legösszetettebb teszt, többféle méretű képpel dolgozik, sok minden számít benne, de leginkább az átlagos memóriaelérés ideje a döntő. Sokat jelentenek a jobb prefetcherek, és itt számít a legtöbbet a memória és a cache-ek hatása.

Ebben a tesztben nagyjából 20%-kal kapott több pontot az Atom. Úgy gondoljuk, hogy ez itt is elsősorban a Hyper-Threadingnek és a magasabb memóriaírási sebesség kettősének tudható be.
A harmadik teszt a CPU ZLib szintén egy integer benchmark, amely a publikusan elérhető ZLib fájltömörítési algoritmussal méri le a processzor és a memória-alrendszer teljesítményét, ez a teszt is csak alap x86-os utasításokat használ. Itt elsősorban a CPU sebessége, illetve képességei számítanak (dekódolás szélessége, out-of-order load támogatása, ugrásbecslés, reordering ablak mérete).

Az Atom ebben a tesztben is az élen végzett a Bobcat és a Nano előtt.
A CPU AES is egy integer benchmark, amely az AES (azaz Rijndael) adattitkosító algoritmust használja. A teszt Vincent Rijmen, Antoon Bosselaers és Paulo Barreto publikusan elérhető C kódját használja ECB módban. A benchmark alap x86-os utasításokat, és összesen 48 MB memóriát használ. Itt is inkább a CPU sebessége a fontos, illetve kiugróan az out-of-order load képesség számít (a hardveres AES támogatást leszámítva persze).

A VIA Nano a hardveres AES támogatása miatt itt egyszerűen tarol. Az ennek hiányában érkező Bobcat és Atom a második és harmadik helyet foglalta el.
A CPU Hash a negyedik integer benchmark a sorban. Ez az NSA által 1995-ben kifejlesztett SHA1 biztonságos hash algoritmus segítségével végez mérést. Az SHA1 egy igen népszerű, talán az egyik leggyakrabban használt algoritmus, amelyet 'hash'-ek, vagyis az olyan egyedi kódsorok létrehozására használnak, amelyek alkalmasak a digitális aláírások titkosítására és megfejtésére. Az SHA1-et olyan ismertebb internetes biztonsági protokollok is alkalmazzák, mint például az SSL (Secure Sockets Layer) és a PGP (Pretty Good Privacy). A benchmark mögötti kód Assemblyben készült, és az MMX, MMX+/SSE, SSE2, SSSE3, és AVX utasításkészleteket is kihasználja, emellett a VIA C7 és Nano processzorokban található VIA PadLock Security Engine-t is képes munkára fogni. Ebben a tesztben minden szál egy különálló 8 kilobájtos adatblokkon dolgozik, és az MMX, SSE2 and SSSE3 utasításkészletekre írt számítási rutinok tartalmazzák az Intel által publikált SHA1 végrehajtás gyorsítására készült vektorizálásos optimalizációt is.

A Nano hardveres támogatása itt is szépen kijön. A VIA-t az Intel és az AMD közel azonos eredménnyel követi.
A következő, immáron lebegőpontos FPU VP8 teszt a Google VP8-as kodekjével tömörít egy 1280x720 pixel felbontású, 8192 kbps bitrátájú videót a legjobb minőségi beállítások mellett. A tömörítendő képkockákat az FPU Julia fraktál modulja állítja elő. A SIMD-utasításkészletek közül ez az MMX, SSE2 és SSSE3 kiterjesztésekből képes profitálni.

Az Atom és a Nano kart karba öltve van elől, majd némi lemaradással érkezik a Bobcat.
Az FPU Julia a processzorok 32 bites (egyszeres pontosságú) lebegőpontos teljesítményét méri le a „Julia” fraktál segítségével. A benchmark kódja Assemblyben íródott, és extrém mértékben használja ki az egyes AMD és Intel SIMD-utasításkészleteket (x87, 3DNow!, 3DNow!+, SSE, AVX). A teszt 4 megabájt memóriával dolgozik szálanként.

Itt ismét a Nano keveredett az élre. Őt egy nagyobb lemaradással követ az Atom, amely mögött hasonló távolságra található a Bobcat.
A következő benchmark az FPU Mandel, ami már a 64 bites (kétszeres pontosságú) lebegőpontos teljesítményt méri le a „Mandelbrot” fraktál egyes frame-jeinek kiszámolása révén. Ez a benchmark is Assemblyben íródott, és kihasználja az egyes SIMD-utasításkészleteket (x87, SSE2, AVX).

Ebben a tesztben megint csak a Nano van elől. Őt a Bobcat, azt pedig az Atom követi szorosan.
Az FPU SinJulia a 80 bites (kiterjesztett pontosságú) lebegőpontos teljesítményt méri le a „Julia” fraktál módosított változatának kiszámolásával. A kód erősen kihasználja a trigonometrikus és exponenciális x87-es utasításokat. Míg a Juliánál a raw 32 bites lebegőpontos MUL/ADD/MOV képességek számítanak, addig a SinJuliánál a legpontosabb 80 bites mód kihajtása a lényeg, és a transzcendens utasítások (sin, cos, ex) megvalósítása. Teljes végrehajtási idő szempontjából a sin, cos, ex sebessége a döntő, amiben egyébként a P6 leszármazottai hagyományosan gyorsabbak.

Itt már fordult a kocka, és a Bobcat lépett az első helyre, ami után Atom és Nano formában érkeznek a követők.
Röviden összefoglalva és a VIA hardveres gyorsítása altal elért eredményeket leszámítva, az AIDA64 szintetikus tesztjeiben az Atom szerepelt a legjobban. A következőkben megpróbálunk fényt deríteni arra, hogy mindez tükröződik-e a különböző alkalmazásokban, illetve ha igen, akkor milyen mértékben.
Videóvágás, szerkesztés


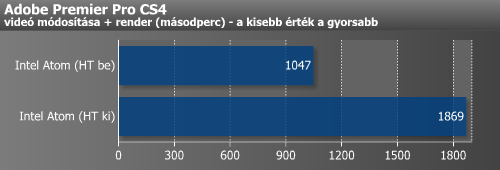
Az Adobe Premier Pro az Intel megoldásának fekszik inkább, aminek eredménye a 6%-os előny, de ne feledjük az Atom 4%-os órajelbeli előnyét. A Sorenson Squeeze-es mérésben szinte fej-fej mellett végzett a két architektúra.


A Powerdirector és a Cockos Reaper tesztek eredményeinél szinte ugyanazt tapasztaltuk, mint a Premier Pro és a Sorenson Squeeze esetében.
Videókódolás, renderelés



A DivX és XviD tömörítéseknél a Bobcat győzött. Ez utóbbinál ráadásul igen nagy előnnyel, ami annak tudható be, hogy az XviD mindössze egyetlen szálat használ, így itt a Hyper-Threading jóformán semmit sem képes segíteni. A jól párhuzamosított x264-es tömörítésnél ismételten csak kéz a kézben jár a két architektúra.



A jól párhuzamosított rendereléses tesztjeinkben a Hyper-Threading ellenére is kiütéses vereséget szenvedett az Atom.
Tömörítés, egyéb


A két tömörítésben fordult a kocka, itt a Bobcat került nagy hátrányba. Ebben a két tesztben erősen kijött a Hyper-Threading hatása.



A Photoshop az Atom-nak feküdt jobban, bár az előny itt nem nagy. Ez az Apache esetében már nem mondható el, azaz itt elhúz az Intel. Az vírusvizsgálattal viszont mát a Bobcat végzett gyorsabban, igaz, neki is fél óra kellett mindehhez az egyetlen maggal. Pusztán érdekességképpen: egy Phenom II X4 955 a négy magjával három perc alatt volt képes ugyanerre.
Utolsó tesztünk a félszintetikusnak nevezhető Peacekeeper, amely alapvetően a különféle böngészők sebességének összevetésére jött létre, de össze lehet vele mérni különböző processzorokat is. Ehhez egy fórumozónk tanácsára mi az Opera 11.5-ös verzióját vettük elő, mivel ez nem támogatja a GPU-s gyorsítást, azaz jóformán csak a CPU-ra támaszkodik.

Nem tudtunk rájönni, hogy mitől jött ki ekkora különbség a Bobcat javára, pedig a feladatkezelő alapján az Atom mindkét szála dolgozott. Később eltávolítottuk a AMD-s rendszerről a Catalyst meghajtócsomagot is, hogy biztosan semmiféle GPU-s gyorsítás ne lehessen, de az eredmény nem változott.
Összesítés és végszó
Mivel nem vagyunk maradéktalanul meggyőződve, hogy a Peacekeeper eredménye a mindennapos szörfözés közben is visszatükröződik, ezért két grafikont készítettünk.


Érdekes eredmény jött ki összesítésünkben. Jóformán azonos magszámot tekintve és (szinte) azonos órajelen az általunk tesztelt alkalmazásokat összegezve az Atom és a Bobcat jóformán ugyanazt hozta. Egy olyan alkalmazásnál, ami csak egy szálat képes kihasználni, ott szinte biztos, hogy a Bobcat gyorsabb. Ugyanez igaz lehet egy két Bobcat és két Atom magot (négy szálat) tartalmazó rendszer esetében, ha az adott alkalmazás csak két szálat/magot képes kihasználni. Négyszálas végrehajtás esetében egyezhet a felállás az előző oldalakon látottakkal. Az is jól megfigyelhető, hogy az AIDA64 szintetikus méréseinek eredményei nem tükröződnek maradéktalanul az alkalmazásokban látottakkal.

A fogyasztás vizsgálata során az jött ki, hogy kerek 2 wattal fogyaszt többet a Bobcat, ami 8%-kal magasabb az Atom esetében mért értéknél. Főképp ennek köszönhető, hogy az Atom fogyasztás per teljesítmény mutatója 9,7%-kal kedvezőbb.
Végszó
Mind az Atom, mind pedig a Bobcat architektúrára épülő platform meglehetősen népszerű. Sokaknak elégséges teljesítményt nyújtanak ezek a rendszerek, és lássuk be, hogy jó néhány szerepkörre nem is kell ennél több. Mindemellett elég energiatakarékos megoldásokról van szó, ami már rendszeres, napi többórás használat esetén a havi számlán is meglátszik. Az első generációs Atom és a Bobcat, mint CPU, összességében eléggé hasonló teljesítményt mutat, és fogyasztásuk sem tér el egymástól jelentősen. A különbség leginkább a CPU melletti grafikus megoldásnál ütközik ki, ahol az AMD megoldása lényegesen jobb, így akinek ez fontos (például egy HTPC esetében), és mégis az Atom mellé szeretné letenni a voksát, annak csak egy NVIDIA ION chipkészlettel megtámogatott megoldás jöhet szóba.

[+]
Na de mit hoz a jövő? Év végén kell érkeznie a frissített atomos Cedar Trail platformnak. Az x86-os CPU-magokhoz még most sem nyúl az Intel, azaz azonos órajelen nem fog többet tudni a CPU rész a most látottaknál. Ezzel szemben bő 3 év után változik a gyártástechnológia, és az egész megoldást átviszik a 32 nanométeres gyártósorokra. Ez a fogyasztásra és az órajelekre lehet majd jó hatással, amivel ez utóbbi az asztali megoldások esetében 2,13 GHz is lehet. A legfontosabb változás a grafikai rész érinti, ahol a cikkünk legelején említett Poulsbo vezérlőhídhoz hasonlóan az Imagination Technologies megoldása került licencelésre. Ennek jóvoltából az Atom DirectX 10.1 támogatást kap, valamint képes lesz a HD képi anyagok és flashvideók hardveres gyorsítására is.
Természetesen kérdés, hogy ez a fenti mire és meddig lesz elég, mivel az AMD sem ül a babérjain. A Brazos platform utódja, a Deccan ugyanis jó néhány frissítéssel érkezik valamikor 2012 második negyedévében. Egyrészt a gyártástechnológia már 28 nanométeres lesz, aminek köszönhetően a magszám is nőhet, és nő is. Két x86-os mag helyett immáron négy darabot fog tartalmazni a Witchita kódnevű csúcsmodell. Ezen felül a Bobcat architektúrához is hozzányúlnak valamelyest, s bár eget rengető változtatásokra nem lehet számítani, de már az is jó néhány százalék pluszt eredményezne, ha az L2 cache magórajelen járna, erre pedig 28 nm-en már van esély. Várhatóan a grafikus mag is bővülni fog, de talán ami a legérdekesebb, hogy ezen Witchita és Krishna kódnevű processzorok mellé már semmilyen plusz vezérlőhíd nem lesz szükséges, mivel már ez is beköltözik a központi processzorba.
Természetesen amint lehetőségünk lesz rá, alaposan meg fogjuk vizsgálni ezeket a megoldásokat is.
Oliverda
Az Intel Desktop Board D410PT és az ASRock E350M1 alaplapot a Ramiris Europe Kft.-től kaptuk kölcsön.







