

A Zen 3 mélylélektana
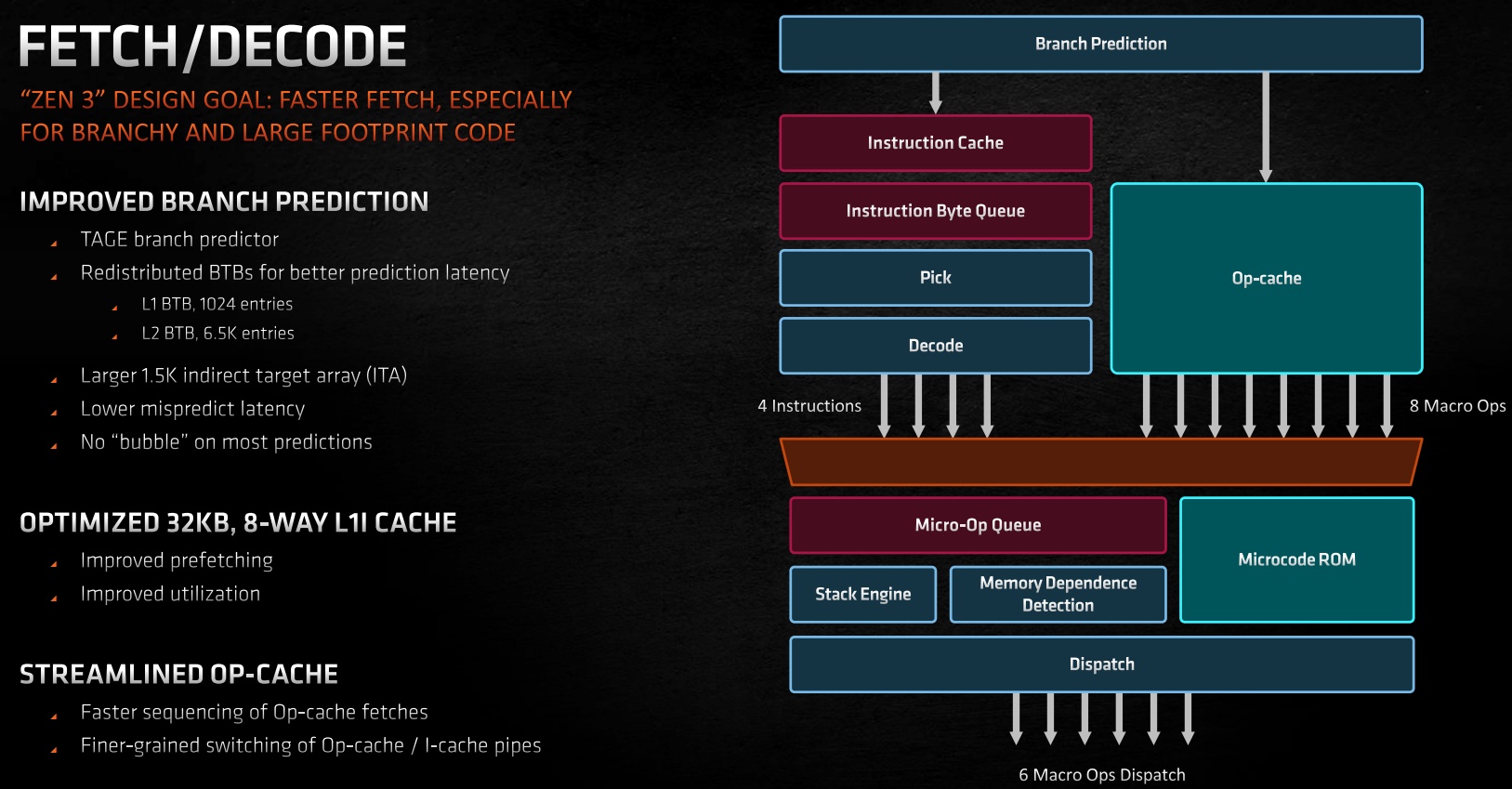
A Zen 3 mag az eredeti Zen radikális továbbfejlesztésének számít, és megörökölt majdnem minden képességet a párhuzamosan tervezett Zen 2-ből is. Utóbbihoz viszonyítva az egyik kritikus változás az elágazásbecslőt érte. A rendszer elvi működését tekintve nem változott, azaz maradt a TAGE (Tagged Geometry) megoldás, ami kiegészíti a hash perceptront az elágazások esetében. Utóbbi ellenőrzi az L1-et, míg előbbi az L2 branch target buffert (BTB). Ezek mérete ugyanakkor módosult, rendre 1024 és nagyjából 6500 bejegyzésre.
Hirdetés
Az L2 branch target buffer esetében, a korábbi cikkek alapján feltűnhet, hogy a Zen 2-höz viszonyítva kevesebb bejegyzést tud tárolni a Zen 3, de ez az AMD szerint így is elég jó, mert közben a késleltetés javult. A közvetett elágazás detektálását továbbra is az ITA, vagyis az Indirect Target Array végzi, ennek nagyjából 1500 bejegyzési helyének egyikére kerül az elágazás. A Zen 3 az elágazásbecslés hatékonysága szempontjából hasonló értékeket tud felmutatni, mint a Zen 2, ami már így is elég jó volt, a mostani fejlesztések fő célját az adta, hogy az egész sokkal gyorsabban működjön, vagyis a becsléseknek jóval hamarabb legyen eredménye. Ezt az AMD "No Bubble" megoldásnak nevezi.
[+]
Az utasításbetöltés és dekódolás tekintetében a Zen 3 továbbra is egy 32 kB-os, nyolcutas, csoportasszociatív utasítás gyorsítótárat használ, de a Zen 2-höz viszonyítva javult a kihasználhatósága. Mindemellett az op-cache lényegesen hatékonyabban működik: gyorsabb szekvenálást kínál a betöltésekhez, illetve finomszemcsés váltást biztosít az op-cache és I-cache futószalagokon.
A Zen 3 mag a valós végrehajtás tekintetében továbbra is egy integer és egy lebegőpontos blokkra oszlik, de igen jelentősek a változások a korábbi fejlesztésekhez képest. A fő cél az volt, hogy csökkenjen a késleltetés, illetve javuljon az utasításszintű párhuzamosság.

[+]
Az integer rész alapját négy darab, egyenként 24 bejegyzéses ütemező adja, vagyis mostantól nem kap minden feldolgozó saját ütemezőt, csak a négy darab ALU (aritmetikai-logikai egység), és ezek mellé lesz párosítva egy-egy másik egység, ami lehet AGU (címgeneráló egység) vagy BRU (Branch Unit). Az új Zenben összességében egy BRU-val kombinált ALU, egy-egy St-data ALU és AGU, két-két normál ALU és AGU, valamint egy dedikált BRU található, miközben az LSU (Load/Store Unit) három loadot, illetve kettő store-t képes elvégezni ciklusonként. Ez a Zen 2-höz viszonyítva igencsak szálkásított rendszer, így a re-order buffer (ROB) és a fizikai regiszterek esetében 256, illetve 192 bejegyzésre kellett növelni a méretet, hogy az új konfiguráció hatékonyan működtethető legyen.

[+]
A lebegőpontos részt valamivel kevesebb változás éri, de az ütemezés itt is hatékonyabb lett. Természetesen megmarad a két darab 256 bites FMAC vektormotor, amelyek egy-egy 256 bites FMA operációt vagy egységenként egy 256 bites ADD és egy 256 bites MUL operációt tudnak elvégezni. Ami előrelépés, hogy egy órajelciklussal gyorsabb lett az FMAC operációk elvégzése, illetve az AMD két különálló, adatmozgásokat kezelő részegységet is beépített, ezekkel a valós feldolgozók némileg tehermentesíthetők.

[+]
A load/store képességek tekintetében a store 48-ról 64 bejegyzésre hízott, míg az L2 DTLB nagyjából 2000 bejegyzést tud tárolni. Az L1 adat gyorsítótár maradt 32 kB-os nyolcutas, csoportasszociatív.

 [+]
[+]
A Zen 3 a Zen 2-höz viszonyítva új utasításokat, illetve funkciót is bevezet. Egyrészt a VAES és a VPCLMULQD utasítások kiegészülnek az AVX2 támogatásával, így 256 bites operációkkal is alkalmazhatók, másrészt újdonság az MPK, amit szoftveres szinten támogatva biztonságosabbá tehetők a felhasználói adatokhoz való hozzáférések. Mindezeken túl lényeges még a CET, vagyis a Control-flow Enforcement Technology bevezetése, ami biztonsági mechanizmust kínál a ROP (Return Oriented Programming) támadások megakadályozására.

[+]
A fenti változásokkal az AMD jelentősen javított az IPC-n, vagyis az egy órajelciklus alatt elvégzett műveletek számán a Zen 2-höz viszonyítva, illetve az új gyorsítótárstruktúrával még a többszálú munkavégzés is hatékonyabb. A vállalat szerint az átlagos előrelépés 19%, de a változásokat a cég számos alkalmazásban kimérte, és 9-39% közötti tempónövekedés látható az egy évvel korábbi fejlesztéshez képest, méghozzá azonos órajelen.

[+]
A cikk még nem ért véget, kérlek, lapozz!












