
Az Apple a tegnapi napon mutatta be az első ARM-os Maceket, amelyekről az alábbi hírben írtunk, és már akkor megígértük, hogy bővebben ránézünk az M1 nevű rendszerchipre. Ezt most meg is tesszük, hiszen lényeges fejlesztésről van szó, ami komoly hatással lehet az almás cég jövőjére.
Azt már nyár óta lehet tudni, hogy a cég az ARM-os útra lép, tehát az irány egyáltalán nem számít meglepetésnek, a kivitelezés viszont máig kérdéses volt. Azért az ősszel leleplezett A14-es SoC alapján lehetett sejteni, hogy mit kapnak majd a Macek, és ez be is jött, hiszen az M1 ennek a szálkásított verziója. Az alapot tehát a TSMC 5 nm-es eljárása adja, amire az Apple egy 16 milliárd tranzisztorból álló lapkát tervezett.

Apple M1 [+]
A processzorrész tekintetében nyolcmagos dizájnnal állunk szemben, négy erősebb és négy gyengébb magra lebontva. Előbbi csoport nyilván többet fogyaszt, de gyorsabb is, míg utóbbi inkább az energiatakarékos működésre van szabva.
A tempós mag kódneve Firestorm, és ez egy nagyon széles, nyolcutas dekódolóblokkot alkalmazó fejlesztés, ami ultramobil szinten meglepő, hiszen ennyire izmos rendszert még az ARM sem tervez házon belül. Mindemellett az OOO (sorrendtől független végrehajtás) logika működési ablaka is rendkívül mély, a 600-nál több bejegyzést is tároló ROB-nak (re-order buffer) köszönhetően. Az integer és lebegőpontos rész is egészen erősnek tűnik a mobil szintre. Előbbiben két komplex és négy szimpla ALU található, míg utóbbi négy darab 128 bites NEON SIMD-et kínál, és ennyi feldolgozó bizony még asztali szinten is megsüvegelendő. A fentiekhez mérten a gyorsítótárak tekintetében is el van eresztve a fejlesztés: az L1 utasítás- és adatgyorsítótár rendre 192 és 128 kB, míg a megosztott L2 cache 12 MB.
Hirdetés

 [+]
[+]
A kisebb mag az Icestorm kódnevet viseli, és azért láthatóan visszafogták a teljesítményét, bár bizonyos területeken azért ez is el van eresztve, elvégre az L1 utasítás- és adatgyorsítótár rendre 128 és 64 kB, a megosztott L2 cache pedig 4 MB.
Az órajeleket az Apple nem adta meg, de a Firestorm magok elméletben képesek 3 GHz környékére, míg az Icestorm esetében a 2 GHz könnyen elérhetőnek látszik. A pontos paraméterek hiányában azonban a teljesítmény nehezen behatárolható, de a ultramobil szinten biztosan nagyon erős lesz.
Az IGP tekintetében az Apple csak nyolcmagos GPU-ként hirdeti a beépített rendszert, amire 2,6 TFLOPS-os számítási teljesítményt adtak meg, maximum 24576 konkurens szál kezelésével. Ezek azonban önmagukban nem sokat jelentenek. Egyrészt a számítási tempó tekintetében nem tudni, hogy a vállalat szimpla pontosságra gondolt-e, vagy felezett pontosságra. Ultramobil szinten ugyanis inkább az utóbbit szokás megadni, és az Imagination korábban licencelt, Apple által azóta is módosítgatott dizájnja is ebben igazán erős. A konkurens szálak maximális száma sem ad semmilyen támpontot, hiszen ez nagyrészt egy elméleti adat, a valóságban azért komplex shaderekkel fog találkozni az M1 IGP-je, ahol azért eléggé ritkán futhat az elméletben kezelhető összes konkurens szál.

[+]
Sajnos nagyon részletes adatok az IGP-ről nincsenek, de azért itt az Apple hatalmas kockázatot is vállal. Valószínű, hogy az ultramobil szintre tervezett, A14-es rendszerchipbe épített dizájnjukat hozzák át a Macbe, gyakorlatilag négyről nyolcra növelve a multiprocesszorok számát. Ez a skálázás tekintetében belefér, és minden bizonnyal az alkalmazott, de részletesen nem taglalt, egyedi tervezésű DDR4-es memóriakonfiguráció is megadja hozzá a szükséges memória-sávszélességet. Azt azonban nem nagyon tudni, hogy a multiprocesszorokon belül mi van, az Apple leírása szerint 16 darab feldolgozóegység, de sűrű homály fedi ezek milyen felépítésűek.
Ami viszont általános szokott lenni, hogy az ultramobil dizájnokat másképp tervezik, mint a normál, mondhatni PC-be szánt rendszereket. Feldolgozókkal ezek is meg vannak pakolva, emiatt is tudnak jó számítási teljesítményt felmutatni, de ahol szűkre vannak szabva, azok a regiszterek, illetve a LDS (helyi adatmegosztás). Ennek a legfőbb oka az, hogy ultramobil szinten messze nincsenek olyan komplex shaderek az alkalmazásokban, mint például PC-n. Emiatt ezek úgynevezett regiszter- és LDS-nyomása jóval kisebb, amivel a statikus erőforrás-allokáció után kellő mennyiségű szálcsoport futtatható egymással párhuzamosan. A gondok akkor jönnek, amikor kap valami komplexebb shadert a multiprocesszor, ott azért megnő a regiszter- és LDS-nyomás, akár annyira, hogy nem is lehet több konkurens szálcsoportot egymás mellett elindítani, vagyis nem fogja semmi sem átlapolni az adatelérésből adódó késleltetést.
Mivel az Apple M1 a Maceken belül PC-re tervezett programokkal is bőven fog találkozni, ez a koncepció okozhat még furcsa eredményeket, annak ellenére is, hogy a beépített IGP a számítási teljesítményben bőven jól áll. Különösen nehéz helyzetben lesznek majd a professzionális alkalmazások fejlesztői, hiszen ott keletkeznek talán az igazán komplex feladatok a grafikus vezérlő számára, és egyáltalán nem véletlen, hogy a professzionális VGA-k piacára szánt modern GPU-kat olyan durván megtömik a gyártók regiszterekkel és helyi adatmegosztásra szánt memóriával. Ez ugyan nagymértékben akadályozza, hogy ultramobil szintre optimálisan leskálázhatók legyenek, de jelentősen javít a komplex feladatok hatékony végrehajtásában. A nagy TFLOPS előtti érték tehát nem minden, ahogy a konkurens szálak maximális száma sem az. Marketing szintjén lehet velük villogni, de nagyrészt nem ezek határozzák meg a teljesítményt.
Mindezeken túl némi hátrány, hogy az M1-es rendszerchippel szerelt Mac gépek nem támogatják a eGPU-t, vagyis nem lehet hozzájuk külsőleg csatlakoztatni dedikált grafikus vezérlőt. Ennek valószínűleg szoftveres oka van, az Apple által támogatott Radeon VGA-khoz el kellene előbb készíteni az ARM-ra optimalizált meghajtót, enélkül nem fog működni egy ilyen rendszer.
[+]
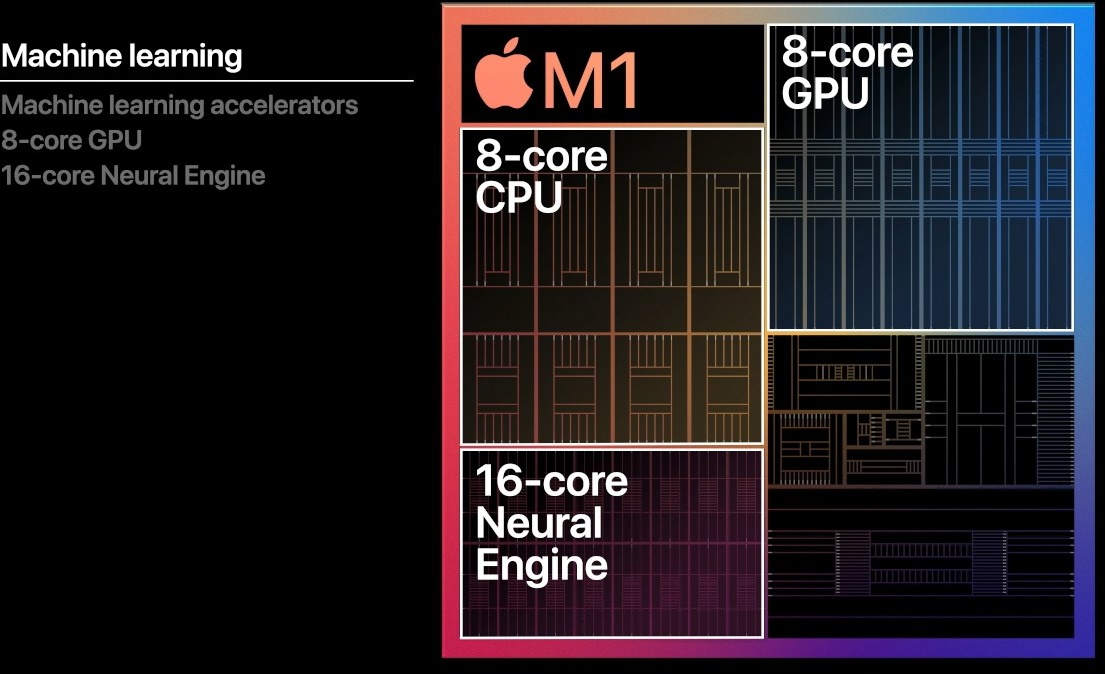
Az M1 SoC további képessége még a 16-magos Neural Engine, ami egy gépi tanulás dedukció szakaszához tervezett neuronháló gyorsító. Újdonságnak ez nem számít, egyre több rendszerchip rendelkezik ilyen, AI számításokra dedikált feldolgozóval.
Összességében az Apple M1 egy érdekes irány. Átlagos felhasználásra még megfontolandó is, mivel a teljesítménye eléggé nagy, a tipikus igényeket biztosan kiszolgálja, és teszi ezt igen jó fogyasztás mellett, amivel egy mobil eszköz üzemideje nagyon kellemes lehet. Professzionális felhasználás tekintetében azonban érdemes óvatosan közelíteni, főleg azoknál az alkalmazásoknál, amelyek a grafikus vezérlőt használják. Ha ugyanis az nem tudja megütni a mércét, akkor nincs hozzá eGPU opció, nem lehet venni az M1-es Macekhez egy külső házba egy Radeon VGA-t. Ilyen formában együtt kell majd élni az IGP limitációival, amíg nem érkezik a ARM-os meghajtó a Radeonokhoz, és jelen pillanatban még találgatni sem lehet arról, hogy ez mikortól érkezik, ha egyáltalán készül.








