Hirdetés
-


Lőn világosság: megérkezett új fénymérőnk
ma A márka és a metódus maradt, gyorsan pótoltuk a Honor 200 Pro méréseit.
-


Retro Kocka Kuckó 2024
lo Megint eltelt egy esztendő, ezért mögyünk retrokockulni Vásárhelyre! Gyere velünk gyereknapon!
-


Kíváncsi az EU, milyen online védelmet adnak a pornóplatformok a kiskorúaknak
it Az EB felkereste a nagy pornóplatformokat, hogy megtudja, milyen intézkedéseket tettek.






-

PROHARDVER!
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#17888
 Abu85
HÁZIGAZDA
FollowTheORI
#17887
Abu85
HÁZIGAZDA
FollowTheORI
#17887
Abu85
HÁZIGAZDA
válasz
 FollowTheORI
#17887
üzenetére
FollowTheORI
#17887
üzenetére
Nem lehet. Minimum szükség van a Volta L1 struktúrájára. [link]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Dyingsoul
#17906
üzenetére
Dyingsoul
#17906
üzenetére
Nem. De olyat hozhatnak, mint a Kaby Lake-G. Az NV már egy ideje nagyon ostromolja a Microsoftot, hogy dobják ki a Win32 API-t a Windowsból, és az MS is hajlik efelé, hiszen az Azure felhő megoldaná a régi alkalmazások kompatibilitását. Ha ezt elérik, akkor gyakorlatilag akárki jöhet az ARM-os csapatból. Az AMD és az Intel viszont pont, hogy ragaszkodik a Win32 lokális elérhetőségéhez. Szóval most van egy kis érdekellentét.
(#17908) b. : Tokozottat hoz. Professional, HPC és gaming.
(#17910) carl18: A Cannon Lake hozott volna sokat, de egyszerűen nem működik. Csak éppen nem igazán tudni, hogy a hardverrel van-e a baj, vagy az Intel tudta, hogy úgyis kuka a Cannon Lake, így a driverét sem fejlesztette le.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ha azt kérdezed, hogy a sajtólevélben meg van-e említve a GeForce 11/20, akkor nincs. Csak a GeForce GTX 10 Series és a G-Sync. Ettől persze bármi lehet, csak nincs külön kiemelve az új generáció.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Ren Hoek
#17916
üzenetére
Ren Hoek
#17916
üzenetére
Nézd, annyi ragadt bent, hogy úgyis le kell majd írni valamennyit. Nem egy tajvani, GeForce-okat gyártó cég a bevétel 80%-át elvesztette, amikor bezuhant a bányászat tavasszal. Egyszerűen a kínai bányák már nem vesznek VGA-t, és nagyrészt ugye GeForce-ot vettek, főleg az Európai bányák vásároltak Radeont. Persze igyekeznek majd eladni a cuccokat, hogy azért kevés leírásuk legyen a végén, de ezt innen nem lehet megúszni, főleg azért, mert sok a headless kártya.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Dare2Live
#17919
üzenetére
Dare2Live
#17919
üzenetére
Ugye az úgy van, hogy a headless VGA-k után nincs kompenzáció. Tehát ha kijelzőkimenet nélküli VGA ragad be egy partnernek, akkor azt 100%-ban a partner írja le. A kijelzőkimenettel rendelkező VGA-knál a partnernek külön szerződése van arra, hogy mekkora készlet leírását fedezi az NV. Ezután egy negyedévben összesítik és leírják. De később még értékesíthetik, ami egy nem várt eladási tételként fog szerepelni. A szerződés által nem fedezett készletet pedig a partner írja le, lényegében ugyanígy.
Valószínűbb egyébként, hogy nem nagyon akarnak itt a leírásokkal bíbelődni. A headless mindenképpen bukó, tehát ott vagy azt csinálja az NV, hogy a körülmények miatt mégis átvállalják a leírást, és akkor a partnereknek az kedvezőbb, vagy megoldják, hogy az OEM-eknek eladják, és akkor szétszedik a kártyákat, majd raknak rá kijelzőkimenetet, mert a kivezetés az megvan a NYÁK-on, csak nincs befejezve. Ezután pedig jó magasra árazzák az új szériát, hogy a régi is menjen probléma nélkül. Amúgy is fel kell készülni a 7 nm-re, ami messze a legdrágább node lesz, amivel valaha találkozhatott a piac. Ergo egy bő 50%-os emelést mindenképpen be kell iktatni, mert az ugyanakkora méretű, 7 nm-es lapkák ára háromszor több lesz, mint a 12 nm-eseké, ezen majd az EUV-s 7 nm segíthet valamennyit, de ott is minimum kétszeres lesz a különbség, tehát ugyanabba az árba feleakkora lapka fér csak bele. Plusz ott a memória problémája, mert abból is sok kell, hiszen az NV nem tud átállni a lapalapú menedzsmentre. Szóval a komponensek ilyen mértékű drágulása mellett esélytelen, hogy ezt a jelenlegi árakon folytassák.
Az Intel és az AMD nem véletlen gondolkodik a CPU tokozására helyezett GPU-ban. Ott is drága a 7 nm (Intelnek majd a 10), de annyi komponenst le tudsz vágni belőle, hogy amennyivel megdrágul az egész, annyit spórolsz is a bonyolult NYÁK, az azon lévő komponensek, illetve a GDDRx elhagyásával.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Dare2Live
#17935
üzenetére
A mostani 12 nm-en jön. De a következő már 7 nm-en.
Igen, csak ha nem rakják bele a méretcsökkenés által megengedett tranzisztorokat, akkor a fejlődés sem lesz akkora.
Az NV már rég megmondta, hogy a 28 nm volt az utolsó ingyen ebéd. Azóta a gyártástechnológia csak drágább. És a 7 nm-es node mind közül a legnagyobb áremelkedést hozza egy generációs ugrásnál. Ennek nyilván köze van ahhoz, hogy a bérgyártóknak le kellett cserélni egy csomó berendezést, de bizonyos node esetében, ahol még nem cseréltek, ott is a gyártási folyamat rendkívül költséges lett a levilágítás bonyolultsága miatt. Ezzel senki sem tud mit kezdeni az iparban, mert a fizika törvényei határozzák meg a változást, vagyis el kell fogadni, hogy innentől kezdve a chipgyártás drága mulatság lesz. Ezért is merült fel az AMD-féle "superglue" EPYC koncepció a GPU-knál, mert azzal ugyan a gyártás továbbra is drága lesz, de arányaiban olcsóbb kettő vagy négy kisebb lapkát felhasználni a tokozáson, mintha egy nagy lenne helyettük.
Persze szerintem a GPU-knál ez nem így lesz, hanem inkább a TSMC-féle tükrözött 3D-s tokozás lesz bevezetve, aminél két ugyanolyan, csak éppen egymáshoz viszonyítva tükrözött lapka egymásra lesz rakva. Ez aránylag olcsó, és gyakorlatilag egy dizájnt kell tervezni, onnan azt már fizikailag le tudod úgy tervezni, hogy az egyik eszközszintű kialakítás a másik tükörképe legyen, és akkor a routing sem probléma, ami egyébként majd egy újabb kellemetlenség lesz a 3D-s tokozások bevezetésével.Szóval jelen pillanatban olyan irányba tartunk, ahol a mostani VGA-árak megőrzése egyszerűen nem megoldható. Bármennyire is fáj, gyakorlatilag minden drágul, és pusztán jótékonyságból nem éri meg egy üzletet fenntartani. Az Intel és az AMD el fog menni a tokozott GPU-k felé, mert azok azért lényegesen olcsóbbak lehetnek a VGA-khoz képest, hiszen az alaplapgyártó viseli a komponensek költségeit, amelyik alaplapot a proci mellé úgyis megveszed, ráadásul a CPU-kon nagyságrendekkel nagyobb haszon van, mint a GPU-kon, tehát van miből engedni is, ha stratégiailag ez fontos szempont lenne.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ez nem stratégiai kérdés. Ezt kínálják a bérgyártók és a memóriagyártók. A másik lehetőség, hogy vegyenek fel úgy 150 milliárd dollár hitelt, és építsenek saját gyárakat, fejlesszenek saját gyártástechnológiát, amin legyártják maguknak a lapkát, illetve a memóriákat, amiket szintén megterveznek maguknak. Utóbbi nem realitás. Nem csak az NV-nek, kb. senkinek sem. Emiatt keresnek olyan jól a bérgyártók és a memóriagyártók. Az ajánlatuk is eléggé általános a teljes iparágon belül, vagyis senki sem kínál a másiknál sokkal jobbat, és ha az nem tetszik, akkor elküldenek a picsába, mert tudják, hogy képtelenség saját lábra állnia egy tervezőcégnek. Előbb-utóbb úgyis kopogtatni fog, hogy "oké, megvesszük annyiért a wafert".
Az NV is dolgozik ilyen tokozott megoldáson. Elég régóta rágják a Microsoft fölét, hogy dobják ki a Windows-ból a Win32 API-t. Az Azure felhőbe akarják átrakatni, és akkor a saját ARM-os lapkájuk is ugyanúgy a felhőből futtatná a Win32 alkalmazásokat, mint az Intelé és az AMD-é. Az Intel és az AMD viszont ragaszkodik a lokális futtathatóság megőrzéséhez.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A tokozott az olyan, mint a Kaby Lake-G. Persze technikailag megoldható az is, hogy ne legyen ráforrasztva az alaplapra, ez csak formalitás. Emellett a Microsoft érkező újításai miatt valószínűleg nem a PCI Express marad az összeköttetés alapja, hanem az Intelnél az UPI, míg az AMD-nél a GMI. És igen, ha a GPU-t cseréled, akkor cseréled a CPU-t is, illetve fordítva. Cserébe egy rakás komponensköltségtől megszabadulnak, hiszen a memória nagy része az alaplapi DIMM-ekben lesz, a többi komponens pedig az alaplapon.
(#17952) Jack@l: Valószínűleg igen. Az NV-nek az elsődleges problémája ma a Win32. Ha a Microsoft attól megválna, illetve a kompatibilitást átrakná az Azure felhőbe, amire egyébként már van kész koncepció, akkor az NV és minden más ARM-ban utazó cég teljes értékű versenytársa tudna lenni az Intelnek és az AMD-nek. Ezért is ragaszkodik az utóbbi két vállalat a Win32 API lokális megőrzéséhez, hiszen tudják ők is, hogy ez az előnyük.
 Amíg ez ott van a Windowsban, addig az ARM-os megoldások igen szűk piacon versenyképesek csak.
Amíg ez ott van a Windowsban, addig az ARM-os megoldások igen szűk piacon versenyképesek csak.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 carl18
#17972
üzenetére
carl18
#17972
üzenetére
Ja. Ráadásul a Volta eléggé mining monster a Pascalhoz viszonyítva. Egyedül a Cryptonight nem megy neki, de az a Vegán kívül nem megy semminek, de a Vegát is veri benne az új 32-magos Threadripper.
(#17974) b. : Az a baj, hogy nem érdekli a bányászokat a gari. Ha megpusztult, hát megpusztult. A legtöbb bányászfarm eleve olyan szerződésben veszi a bányászatra a hardvert, hogy minimum garit kérnek, cserébe az olcsóságért. Ez jó a gyártónak, mert nincs vele többet gond, és jó a bányászfarmnak, mert gyorsabban visszatermeli az árát. Onnantól kezdve pedig minden profit, ha megdöglik, hát megdöglik.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Jack@l
#18009
üzenetére
Jack@l
#18009
üzenetére
Attól függ, hogy milyen magot használsz. Egy Cortex-A76, már erősen az AMD és az Intel friss magjai környékén van. Persze ennek a hátránya, hogy a fogyasztása is jelentősen megnő, de nyilván a teljesítmény nincs ingyen. És ebbe már lehet valamekkora SVE-t is rakni, mert ARMv8.2a az ISA.
Az ARM host processzor mindenképpen segítene az NV-nek egy lapalapú memóriamenedzsmentet biztosítani PC-re, mert tudnák támogatni a GPU-ból az ARM memóriamodelljét. A többi annyira még nem fontos, de mondjuk a Microsoft-féle Tiled Resources Tier_4-re már NVLink kell nekik is, azt pedig nem fogja támogatni az AMD és az Intel, tehát muszáj maguknak gondoskodni róla. Az AMD és az Intel arra fog törekedni, hogy a saját GPU-juk legyen ott a CPU mellett a tokozáson, a saját memóriakoherens összeköttetéseikkel (GMI és UPI ugye).
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az alkalmazások többnyire bináris formában vannak szállítva, tehát oké, hogy magában az OS-en belül az UWP és az alatta futó komponensek megfelelnek annak, hogy az ARM-on működjenek, a forráskódot így is le kell fordítani ARM-ra. Mondjuk persze ez a legkevesebb, csak meg kell tenni.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#18014
üzenetére
A memóriakoherencia hiánya a gond. Az NVLink, a GMI és az UPI nem véletlenül memóriakoherens. Önmagában nem lenne ebből baj, ha megegyeznének a gyártók egy szabványban. Például a CCIX tökéletes lenne a PCI Express helyére, de valamiért egyik gyártó sem érdekelt abban, hogy a jövőben a hardvereiket keverhetővé tegyék. Emiatt mindenki csinált magának saját interfészt, és cserébe a másikét nem is támogatják.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#18018
üzenetére
Az ARM már nagyon közel van. Mondom, hogy a Cortex-A76 egy AMD/Intel csúcsmagjait megközelítő fejlesztés. Ezzel már az AVX-re is lehet reagálni, ami az ARM-nál az SVE. Csak ugye a korábbi magokba ezt nem lehetett beépíteni. És az SVE az olyan, amitől eléggé fosik az Intel és az AMD is, mert a kialakítása miatt csúnyán körbe tudja húgyozni az AVX-et. Szóval az az 5 év jó lesz 5 hónapnak. Majd a Fujitsu Post-K projektje fogja megmutatni, hogy milyen bivalyerős az ARM koncepciója. Szimplán CPU-ból kitolják 2020 után az exaflops-ot. A többiek ehhez gyorsítózni fognak.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
válasz
 Oliverda
#18027
üzenetére
Oliverda
#18027
üzenetére
És a laptopokban található magok honnan származnak az Intel és az AMD palettáján belül?
(#18028) Dare2Live: Az nem tisztán fogyasztás, hanem egy hatékonysági tényező. Ha tisztán fogyasztás lenne, akkor power consumption lenne odaírva.
A Cortex-A76 elsődlegesen egy szerverekbe szánt megoldás, amit persze lehet bárhova rakni, de a teljesítménykarakterisztikája, illetve az SVE-re vonatkozó támogatása a célt egyértelművé teszi. A mobil azért kérdéses, mert az ARM nagyon gyorsan fejleszt, és mire eljut egy cég oda, hogy a Cortex-A76 ideális lesz a fogyasztás szempontjából mobilba, addig már lesz egy még jobb mag ide. Ugyanez volt a Cortex-A55-tel is, nagy váltás, szerverekhez tervezett dizájn, és nem is nagyon alkalmazták mobilba, mert gyorsan jött a helyére jobb.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Oliverda
#18047
üzenetére
Pontosan. Az AMD és az Intel nagyobb magjai sem igazán PC-hez készültek, hanem a szerverbe. Mi csak megkapjuk ezeket. Az ARM sem igazán a PC-re szabja ezeket, hanem a szerverbe.
(#18044) Dare2Live: A Cortex-A57 jött nem sokkal utána.
(#18046) carl18: Ők továbbra is csak processzortervezők. Az Intel és az AMD versenytársa leginkább a Qualcomm és az NVIDIA lehet. A Qualcomm már az, és ezekre az alapokra simán építhet az NVIDIA. A Microsoft a szoftveres hátteret úgy építette fel, hogy az ARM-ra fókuszáljon, vagyis jöhet annyi versenyző, amennyi akar. Az 5G-t érdemes itt kihasználni. Ugyan ilyen modeme az NV-nek nincs, de a Qualcommnak igen, és bár az integráltság nekik mindenképpen előny, az NV lehet üzlettárs, ha fizetnek, akkor ugyanúgy kapnak modemet, ahogy az AMD, mert ugye ők is a Qualcommtól fogják venni. Erre a lehetőségekre nyugodtan rá lehet repülni az NV-nek. Ez egy soha vissza nem térő alkalom. Meglepődnék, ha kihagynák.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#18049
üzenetére
A PCI Express nem fog eltűnni. Egy rakás komponens erre van bekötve. A probléma az vele, hogy teljesítményben marhára kevés lesz egy GPU-nak, nem véletlen, hogy iszonyatosan megindította a tempóboostot a PCI-SIG, illetve nem memóriakoherens az interfész. Ezek miatt a hiányosságok miatt már az NV, az Intel és az AMD is rendelkezik saját alternatívával, amelyek ráadásul nem csak gyorsabbak, de memóriakoherensek is.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#18051
üzenetére
Azért elhanyagolható a különbség, mert a fejlesztők nem túráztatják a PCI Express buszt a teljesítménylimitációk miatt, de ha mondjuk elnézel a GDC-re, akkor elég sokan mondják már a gyártók közül is, hogy a fejlesztők panaszkodnak, hogy bizonyos újításokat nem tudnak bevetni a PCI Express sebessége miatt. Ezek léteznek a stúdióknál, csak áll bennük a pénz, mert valós környezetben még nem kihasználhatók. Ugyanakkor mégis fejlesztik őket, mert látják, hogy az Intel, az AMD és az NV is rendelkezik saját megoldássokkal a PCI Express helyére.
Memóriakoherencia bizonyos IGP-knél van, ezekre fejlesztik a fenti újításokat, csak itt meg a teljesítmény hiányzik, tehát ebből a szempontból is meg vannak lőve. De mondjuk egy Kaby Lake-G elég lenne, ha a CPU és a GPU memóriakoherens interfészen lenne összekötve. Na és ki fejleszt bevallottan pont ilyet? Csak nem az Intel? Nyilván mindegyik cég látja ezt, és reagálni fognak rá a megfelelő hardverekkel. Már minden komponens megvan hozzá házon belül. A Microsoft is fedi le az API-ban a problémát a Tiled Resources Tier4-gyel.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Dare2Live
#18068
üzenetére
Nem lenne nagy ötlet az LDS-pressure növekedése miatt. [link] - a Volta pont ebben javít. Tényleg eléggé számít ez, főleg úgy, hogy az übershaderek egyre bonyolultabbak.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Olyan már van a Voltában is, de kell hozzá a címfordító a multiprocesszorokba, ami az NV-nél Power9-es host CPU-hoz idomul. Ezért nem működik a Titan V-ben, mert PC-ben x86/AMD64 a host CPU.
(#18259) Petykemano: A kellene, illetve az RAM-árak ennyit engednek az két különböző dolog.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Annyit hozzátennék, hogy egyrészt jól leírtad, hogy az explicit API-k a skálázás szempontjából elkerülhetetlenek, illetve mindenkinek a Vulkan tetszik igazán
![;]](//cdn.rios.hu/dl/s/v1.gif) , de nem biztos, hogy pont maga az API a hiba oka, ha egy program mondjuk lassul DX11-ről DX12-re váltásnál.
, de nem biztos, hogy pont maga az API a hiba oka, ha egy program mondjuk lassul DX11-ről DX12-re váltásnál.
Ahogy észrevettem a legnagyobb limit (van még pár, de most a legfőbb bűnösről beszéljünk) a memóriamenedzsment. Ezt ugye explicit API mellett a program oldaláról kell meghatározni, és az tök jó, hogy a Vulkan és a DX12 szépen specifikál memóriatípusokat, memóriahalmazokat, bizonyos flageket, amelyekkel meghatározhatók az egyes memóriatípusok képességei, stb. Ugyanakkor ezek mellett nem feltétlenül találják a fejlesztők azt az optimális procedúrát, amivel jó lehet a memóriamenedzsment. És az alábbi három kép eléggé jól megmutatja, hogy ez miért baj: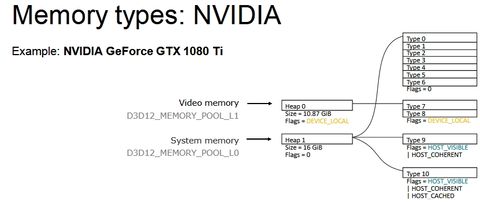

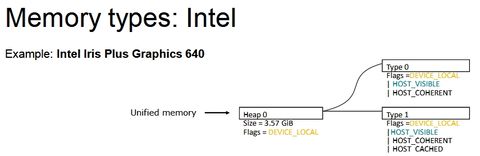
Na most tehát egy olyan menedzsmentet kell írni, ami a fenti három IHV strukturális memóriakezelését jól lefedi. És hát ez a memóriakezelés marhára különböző, már ránézésre is, tehát nem egyszerű ez a feladat.
Na most a probléma kétirányú. A memóriatípusokra vonatkozóan káosz van. Minden IHV-nek van két típusa erre. Az Intelnek egy host által látható és koherens, illetve egy még gyorsítótárazható is. Az AMD-nek van egy normál és egy host által látható és koherens, míg az NV-nek van két normál. Tehát effektíve nincs közös nevező. A memóriatípus szerinti menedzsment ezzel kizárható, ugyanakkor mégis ez a legegyszerűbb mód, tehát annak ellenére, hogy minden IHV mást támogat, sokszor erre erőszakolnak rá valamit a fejlesztők. És innentől kezdve már a strukturális implementáció hatékonysága lesz a döntő. Ez a legfőbb oka annak, amiért egy DX12 mód lassabb lehet egy DX11 módnál az egyes hardvereken.
A használhatóbb koncepció a nagy blokkos menedzsment. Mondjuk 256 MB-os blokkokkal, és ezeken a blokkokon belül lehet kisebb allokációkat létrehozni az erőforrásoknak. A halmazok esetében optimális felosztás az eszközlokális halmazok kapacitásának a tizede, vagy nyolcada. A nyolcada azért jó, mert az a legtöbb hardveren 1 GB lesz, és abba pont befér négy blokk. Juhéé. De amúgy ez sem egy szuperoptimális megvalósítás, mert az NV struktúrájával vannak buktatói, de összességében ez adja a legtöbb közös nevezőt. A Vulkan esetében azért látni, hogy az NV sem annyira rossz ebben az API-ban, mert a Khronos már szabványosította a dedikált allokációt, és azzal az NV struktúrájának buktatói kezelhetők. Extra munka, de működni fog. DX12-ben viszont ilyen utólagos kezelésre nincs lehetőség. Emiatt ritka, hogy az NV gyorsabb legyen a DX11-es módnál.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nem számít itt igazából a driver. Lehet hozzá profilt írni, de a teljesítmény 98%-a a programkódból jön a Vulkan esetében, és a DX12-nél is. A driver maximum ezt elronthatja, de javítani eléggé nehézen tud rajta, hacsak nem működik valami egészen szarul, de már mindegyik implementáció elég idős, szóval egyre kisebb extra van bennük.
Rövidebb távú megoldások nincsenek a DX12-re. Ugye az itt a gond, hogy a fejlesztőknek azért ideális legalább az IHV teljes termékskáláján ugyanazt a struktúrát adni. Még ha a Volta számára jobb lenne egy egyszerűbb struktúra, akkor sem fogják bevetni, mert a korábbi struktúrára írt játékokban sok sebesség veszne oda. De ezzel az NV be is zárja magát egy kevésbé ideális struktúrára, mert tuti nem tudják majd mindenkinek elmagyarázni, hogy ne nagyon írjanak már memóriatípusok szerinti menedzsmentet. Ördögi kör ez. A legelején kellett volna átgondolni, hogy milyen struktúrával jönnek ki, és valószínűleg már ezerszer megbánták a korábbi döntéseiket, de mára hozzájuk ragadtak. Annyit tehetnek igazából, hogy a Microsoft Residency Starter Library használatát javasolják, ami önmagában nem egy csoda, de marhára jó kiindulási pont egy jó memóriamenedzsment megalkotásához. Ráadásul az egész egy open source header, vagyis tök jól beépíthető és átírható. [link] - ha ezt a Microsoft vagy a fejlesztők közösen fejlesztenék, akkor tök jó dolog alakulhatna ki belőle. Simán érdemes lenne ebbe leportolni az AMD VMA-jának fejlesztéseit. Az már egy nagyon vaskos cucc, és alapból iszonyatosan sokat tud. [link]
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Maximum csak a shadereket cserélik, de azt mindenki megcsinálja. Az AMD sokszor még a játék megjelenése előtt. Szerintem amúgy az NV is, csak náluk valamelyik totál elmebeteg marketinges kitalálta, hogy ezeket vissza kell tartani a játék megjelenéséig, de biztos nem az utolsó utáni pillanatban fognak hozzá, hanem hetekkel korábban.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az, hogy kitalálta valamelyik "marketingfejű", hogy még ha el is van készítve xy programhoz a profil, akkor is a program megjelenése környékén legyen berakva. Ez szimplán hülyeség, mert simán berakhatnák egy hónappal korábban is, és akkor nem kellene új meghajtót kiadni xy játék megjelenésére, hanem ami már kint van azzal futna az alkalmazás. A kevesebb meghajtó miatt még a hotfix is kevesebb lenne, mert nem kellene annyi batch-t párhuzamosan fejleszteni, ami majd a committelés során random hibákat generál.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Ren Hoek
#18316
üzenetére
Nem. A Turing az létezik, már februárban megírtam, csak elfelejti: [link]. Nem írtam volna meg, ha nem létezne. De a többi pletyka az hülyeség volt, azt nem írtam meg, hogy bányász GPU lesz stb, mert nem lett az.
Most, hogy az NV bejelentette lehet beszélni róla, hogy ha megnézitek a Turingot, akkor annak van egy RT mag nevű fejlesztése. Na most az nem igazán egy mag, persze a parancsmotorban az egy viszonylag combos vezérlő, de a TPC-ken belül skálázódó rendszerről van szó. Egy GPC-n belülre két multiprocesszorral is többet lehet építeni, ha nincs az RT mag tranzisztorköltsége, és ez egy olyan hardverelem, amire reálisan nem lehet várni consumer szoftvert. Egy fizetett cím van csak bejelentve, geometriailag az is jól le lett butítva. [link]
Ergo a Turing az leginkább professzionális szinten hasznos, mert ott tervezhetsz 700+ mm^2-es GPU-t, amiben benne van az a teljesítmény, ami erre kell. Mert az RT mag vezérlője igazán tranzisztorzabáló, miközben az csak annyi, hogy a TPC-k áramköreit működtesse megfelelő elosztással. És a teljesítmény végeredményben innen a TPC-kből jön, de ha kevés a TPC, akkor kevés lesz a ray-triangle intersection teljesítmény a valós idejű leképezéshez, miközben a vezérlőt ugyanúgy beépíted. Egy középkategóriás GPU-ba közel 400 CUDA maggal többet rakhatsz az RT mag hiányában, annak az RT magnak a hiányában, amely nagyjából 2000 CUDA mag alatt amúgy sem ér semmit a túl gyenge teljesítménye miatt. Csak ezt egy átlag muki nem nagyon érti, mert ő csak kódnevet néz, és hát biztos a Turing lesz mindenhova, csak az NV-nél a mérnökök nem olyan hülyék, mint egy átlag muki. Ők is utánaszámolnak, hogy 300 mm2-en az a 400 mag többet ér, mint egy címben az RT mag, ahol ez a középkategóriás GPU amúgy sem adna ki magából 30 fps-t sem.Persze 7 nm-en ez az egész már teljesen realitás, ott annyival több a tranzisztorbüdzsé, hogy elkölthetsz egy rakás tranyót olyan területre, ami szökőévente számít.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Mármint a DXR támogatására gondolsz a Tomb Raider kapcsán? Nem hiszem, hiszen Windows 7-en is fut. Ha valami DXR-t támogat, akkor a minimum igénye az OS oldalán Windows 10 Redstone 5 lesz. Nincs lejjebb, mert a Microsoft kiegészítése kötelezően elírja a DXIL legújabb specifikációját, amit más OS-en belül nem lehet kezelni. És ehhez a már meglévő, sokszor közel 300-400 ezer sornyi shadert is újra kell írni a fejlesztőknek. Csak úgy működhetne Windows 7(/8/8.1) mellett, vagy a tavaszi és régebbi Windows 10 frissítéssel, ha az új DXIL mellé szállítaná a fejlesztő a D3BC kódot is, de az azért durván költséges a QA szempontjából. Nem véletlen, hogy akármilyen API-kat is támogat valaki, azért arra ügyel, hogy a shaderek forrása szempontjából a követett specifikáció nagyrészt egységes maradjon. Ez egyébként a Microsoft sara alapvetően, hiszen a DXIL alapvetően nem kötődik szorosan magához a Windows 10-hez, az új specifikációk pedig a Redstone 5-höz, de a Microsoft magát a runtime-ot úgy alakította ki, hogy a DXR-hez szükséges rendszer igényelje a legújabb DXIL specifikációra fordított IR kódokat. Annak egyébként nincs technikai akadálya, hogy ez a runtime elérhető legyen Windows 7 mellett is, akár DXR nélkül is, és akkor legalább a shaderek szempontjából nem kellene többszörös munkát végezni a fejlesztőknek, de a Microsoft ragaszkodik hozzá, hogy a DXR programok csak Redstone 5-től legyenek futtathatók. Nyilván ők is tudják, hogy olyan fejlesztő nem lesz, aki kétféle IR-re is szállít shadert, tehát inkább beírják a gépigénybe, hogy Redstone 5 minimum, akkor is, ha nem kellenek a funkciói.
Egyébként a Tomb Raiderre pont van dokumentum. ShadowPlay Highlights és Ansel lesz benne.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Televan74
#18416
üzenetére
Televan74
#18416
üzenetére
Maga az RTX egy buzzword. Valójában a DirectX Raytracing, azaz a DXR a lényeg, mert azt RTX nem más, mint erre egy driver, csak az NV nem drivernek hívja, hanem RTX-nek, de ettől még nem lesz több egy drivernél. Na most maga a DirectX Raytracing kétféle módot támogat. Egyrészt van a fallback layer, ami tulajdonképpen önmagában egy amolyan univerzális driver, és ez minden compute shadert támogató GPU-n futtatható. A másik módban a gyártók bizonyos feladatokat kihelyezhetnek gyorsításra, ettől még mag a sugárkövetés marad compute shader, tehát egy ilyen GPU itt is kell, de például a ray-triangle intersection, a denoising, stb, implementálható driverben. Ezeket egyébként maga a fallback layer is implementálja csak compute shaderben. Nyilván utóbbinak az a hátránya, hogy nem tud hozzáférni a hardverek speciális képességeihez. A Microsoft a driver szempontjából sok mindent elfogad. A sugárkövetés van compute shaderhez kötve, méghozzá 32 bites lebegőpontos formátumban, ami végeredményben a DirectCompute API-n fog működni, de ezen túlmenően más szempontból szabad a választás, tehát mondjuk a denoisingot az NV kirakhatja a Tensorra, az AMD használhatja hozzá a speciális SAD/QSAD/MQSAD utasításait, stb (maga a denoising a fallback layeren SAD-dal van implemetálva). A ray-triangle intersectionre is lehet speciális hardvert használ.
Effektíve tehát a DXR a DirectCompute API-n fut, és egyes funkcióira lehet natív, hardverhez közeli implementációt írni.Az NV a SIGGRAPH-on megerősítette, hogy a DX12-t támogató hardvereknél a Fermi, Kepler, Maxwell és Pascal a fallback layert használja, míg a Volta és a Turing kap drivert. Ezt hívják RTX-nek. Az Intel a fallback layerre utalja magát teljesen, míg az AMD a GCN-ekre hoz drivert, így ők a fallback layert egyik hardverükhöz sem használják.
(#18417) Keldor papa: Igen és nem. A teljesítmény nem egzakt tényező. Ha a ray-tracing effektek mondjuk 20 ms-ot igényelnek, akkor meg lehet csinálni azt, hogy a jelenet geometriáját, illetve a raszterizálást annyira lebutítsák, hogy az meglegyen 1 ms alatt. Tehát ez egyfajta játék a minőségre vonatkozó egyensúllyal. Ezért sem túl erős a Metro Exodus geometriai és textúrarészletessége [link], ahhoz, hogy a sugárkövetés normális sebességgel működjön, butítani kellett minden mást.
Két kritikus tényező van egyébként. Nem lehet túl sok geometria a jelenetben, mert a DXR csak nagyon memóriapazarló vertex formátumot támogat, illetve mivel a vertexek szempontjából pazarolja a memóriát, így a textúrákat is vissza kell fogni, hiszen eléggé kevés VRAM áll majd a streaming rendelkezésére. Ezért volt tervben anno 24-48 GB VRAM, de a memóriaárak közbeszóltak.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Televan74
#18422
üzenetére
Nincsenek árak. De a memóriaárak alapvetően beleköptek a levesbe, hiszen a DXR vertex formátuma tényleg brutálisan memóriaigényes. Jobb lenne a minél több memória, de járható az az út is, hogy a textúrák felbontása lesz feleakkora. Ezek kezelhető dolgok szoftveresen is.
Hosszabb távon egyébként ez meg lesz oldva, mert a DXR következő nagyobb frissítésébe már bekerül a 16 bit snorm, de ez 2020 előtt nem történik meg. Addig csak 32 bit float van, mert a 16 bit float az túl ronda.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Ren Hoek
#18440
üzenetére
A memóriakapacitás. Az AMD-nek ez nem gond, mert lapalapú a memóriamenedzsment. Ergo nekik teljesen reális megoldás, hogy 4-32 GB közötti memóriát használnak HBM2-vel, mert ha nem elég, akkor a HBCC-ben beállítanak többet, vagy NAND-on raknak hozzá 1-2 TB-ot, elvégre van bájtszintű memóriakezelés is. Az NV-nek ez nem járható út, mivel a multiprocesszorokban Power9-hez való címfordítók vannak, illetve a beépített memóriavezérlő csak blokkszintű információkat kezel. Tehát ami az AMD-nek csak egy szoftveres probléma, az az NV-nek brute force módon kell hardverrel pótolni. És mindegy, hogy lassabb, többet fogyaszt, több helyet igényel, mert a kapacitásra való igény miatt erre kényszerülnek.
A Turingnak is van egy olyan képessége, hogy ha két 48 GB-os Turing Quadro kerül egymás mellé, akkor az egyik GPU használhat 96 GB memóriát, ha a másik GPU éppen nem dolgozik. Ez direkt arra van, hogy ha nagyon kell a memória, akkor biztosítható legyen a felszereltnél több, mert az NV-nek nincs a driverben egy szimpla csúszkája erre. Azt nem tudom, hogy ezt a képességet átmentik-e asztaliba, de alapvetően így bővíthető az NV-nél a VRAM.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nyilván csak pletyka, de az biztos, hogy a GDDR6 túl drága ahhoz, hogy consumer kártyára sokat lehessen rakni. Még a GDDR5 ára is egészen magasan van.
 Tök jó lenne 16-24 GB-ot rakni rá, ahogy tervezték, de amikor tervezték, akkor még nem ilyen drága memóriaárakkal számoltak. Ez a tényező azért nagyon erősen beleszól a végeredménybe. Ráadásul a GDDR6-nál az árnyékolás sem olcsó mulatság.
Tök jó lenne 16-24 GB-ot rakni rá, ahogy tervezték, de amikor tervezték, akkor még nem ilyen drága memóriaárakkal számoltak. Ez a tényező azért nagyon erősen beleszól a végeredménybe. Ráadásul a GDDR6-nál az árnyékolás sem olcsó mulatság.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Bármire odaírhatják az RTX jelölést. Ez csak három betű a terméknévben. Az RTX viszont valójában a driver neve, ami lesz Volta és Turing GPU-khoz. De a marketingből nem igazán éri meg kiindulni. Sose a logika hajtotta a mögöttes döntéseket.
A SIGGRAPH-on arról lehetett hallani, hogy három GPU érkezik. Egy Turing, amit nemrég mutattak be, de kódnevet nem mondtak rá, valamint egy GV102, illetve egy GV104. A többi pedig Pascal újrahasznosítás lesz, ez ugye az alsóház.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ez nem olyan egyszerű. Az RT mag nem pici, egészen sok tranzisztort elvisz, és eközben nulla tartalom van rá. Leghamarabb a Metro Exodus fogja támogatni, és nehéz lesz meggyőzni más stúdiókat, hogy a kiadott PC-s játékuk futtatását korlátozzák Windows 10 Redstone 5 vagy újabb rendszerre. A Volta bizonyos szempontból sokkal célszerűbb megoldás, mert a tranzisztorokat olyan feldolgozókra lehet költeni, amiből minden játék profitálni tud.
Ráadásul hiába skálázható az RT mag dizájnja, egy teljesítményszint alatt hasztalan, mert túl lassú lesz a hardver magához a sugárkövetéshez, tehát kb. 40 multiprocesszor az az alsó határ, amibe megéri beépíteni, de alá nem. Hiába van ott, még Full HD-ben sem lesz meg a 30 fps, így pedig csak a tranzisztort foglalja. 40 multiprocesszor pedig erősen 400-500 mm2-es lapka a Turinggal, tehát nem egy középkategóriás szint.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Dare2Live
#18461
üzenetére
Mennek rajta biztos, elvégre a hardver megvan benne, csak sok tranzisztort költ ma még nem használt egységekre. Azt eleve figyelembe kell venni, hogy a Titan V egy butított GV100, tehát annak a teljesítményét azért nem nehéz hozni, persze csak akkor, ha nem butítják a Turingot. De az teljesen irreális, hogy 754 mm2-es lapkával 500 dollárra lőnek. A 12 darab 16 gigabites GDDR6 memória alig olcsóbb ennél, és akkor még hiányzik a VGA 99%-a.
(#18462) gV: Persze abba belefér, de a 7 nm-es kapacitása a TSMC-nek véges, és ezt marhára lekötötte az első node-ra az Apple, a Qualcomm és az AMD. Az NV a második, olcsóbb 7 nm-es körben van benne.
Az a baj, hogy ezt kiműteni azért nem egyszerű. Összelegóznak neked egy dizájnból 3-4 lapkát, de amikor az "építőelemeket" kell változtatni, akkor bonyolulttá válik a helyzet. Meg lehet csinálni, de olyan költsége van, mintha külön architektúrát terveznél. Ha tehát megvan a multiprocesszor dizájnja, akkor azon nem igazán változtatnak a termékskálán belül. Mellesleg, ha kiműtöd az RT magot, akkor a Turing nagyjából egy mezei Volta. Vagyis sokkal célszerűbb a Volta multiprocesszorát használni.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
- Tensorral se sokra mész a DirectX és Vulkan API-ban. Ezek nem támogatják az említett feldolgozótípust.
- Már a Volta is unified volt, ráadásul dupla széles buszokkal bekötve. Az NV mindent a Pascalhoz viszonyított, de a Voltához képest nem változik az L1.
- Az NVENC nincs hozzákötve az architektúrához. Azt be lehetne legózni a Fermibe is.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nem tudom, hogy mi a 2080. Senki sem tudja. De az biztos, hogy nem az lesz a selling point, hogy jön egy olyan játék, amiben DXR lesz, és ilyen grafikát tud vele: [link]
3 év múlva jóval gyorsabb kártyák lesznek, javul a DXR is, így nem kell visszavenni a geometriai és a textúrarészletességet azért, mert pár RT effektet akarnak belerakni. Lesz hozzá kellő memória is, elvégre tényleg beteg mód zabálja a memóriát a 32 bit float vertex formátum. A 32 bit snorm majdnem feleakkora memóriaigénnyel rendelkezik, miközben a minősége nem sokkal rosszabb. Úgy képzeld el ezt, hogy van egy büdzsé a geometriára, és mivel a memóriakapacitás nem nő, így DXR esetében ezt a büdzsét úgy lehet betartani, ha a geometria vagy a textúrák részletessége drasztikusan csökken, vagy mindkettő csökken egyszerre, de egyfajta egyensúlyra való törekvés szerint.Ami egyébként jó a Turingban azt a Volta már tudta. [link] - le is írtam az L1 gyorsítótár résznél.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#18476
üzenetére
Vertex adatokhoz nem. Eleve hülyeség lenne, hiszen a csúcspontok csak pozíciók az adott objektum köré vont "hálós dobozon" belül. Mindegyik vertexhez külön letárolni a skálázást float kitevőként iszonyatos erőforrás-pazarlás, mert szebb nem lesz, de durván több memóriát fog zabálni.
Mivel a DXR specifikációja kizárja a 32 bites snorm formátumot, így bizony csúnyán megnő a geometria memóriaigénye. Még akkor is, ha az RT effekteket nem kapcsolod be.
A Frostbite motor memóriavezérlése miatt. [link] - itt leírtam, hogy az IHV-k implementációi a strukturális memóriakezelésre vonatkozóan egészen különböznek, vagyis amikor írnak egy vezérlést egy motorba, akkor nem egy IHV-re dolgoznak, hanem megpróbálnak egyfajta közös alapot találni. Ez bizonyos hardvereknél kisebb vagy nagyobb memóriapazarláshoz vezet, de itt a cél a teljesítmény szinten tartása. Érti egyébként a Frostbite Team is, hogy ez egy probléma, de rohadt nehéz ám segíteni rajta. Az AMD részben emiatt fejlesztette ki a HBCC-t. Nem akarják, hogy a rossz programkódok lerontsák a hardver teljesítményét, így amit a fejlesztők most szoftverből csinálnak, azt a Vega óta inkább megcsinálják maguk hardverből. Jobban bíznak magukban, mint a játékfejlesztőkben. Azt hiszem, hogy abban egyetérthetünk, hogy nem teljesen alaptalan az AMD meglátása, legalábbis figyelembe véve, amit eddig láttunk az DX12 API-nál a memória kezelése kapcsán.
A Frostbite Team átválthatna Vulkan API-ra, ott van dedikált allokáció, az megoldaná a gondjaikat. Nem szép megoldás, de működik.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
- A Pascal dizájnja nem tud felülkerekedni az LDS-pressure problémán. Az nem valami jó megoldás, hogy mondjuk megduplázzák az LDS-t.
- Az ISA és a memóriamodell szempontjából minden aktuális NV dizájn a Fermi leszármazottja, de azért változik a rendszer belülről.
- Bele lehet tenni. Ez tényleg csak egy fixfunkciós blokk. Nincs szorosan köze az architektúrához.Felfigyelnél arra, ha azt mondanák, hogy a Turing a Fermi sokadik változata? Na ugye. Ettől még a memóriamodell és az utasításarchitektúra a Fermi óta nem igazán változott, csak kiegészítik generációnként. Ezzel semmi gond nincs, mert eléggé skálázható a Fermi memóriamodellje ahhoz, hogy ne kelljen még belenyúlni. A Volta is nagyon jó újításokat vezetett be, csak nem megfizethető a Titan V, így sokan nem tudják ennek a hatását látni. Majd jönnek a megfizethetőbb modellek.
(#18479) Jack@l: Nem én. Felőlem lezabáltathatják a VRAM-ot a geometriával, csak nem szerencsés, mert minden vertexhez külön letárolni a skálázást marhára értelmetlen. Nem véletlen, hogy a mai motorok kivétel nélkül 32 bites snorm formátumot használnak erre. Sokkal memóriakímélőbb, és a végeredmény szempontjából nincs hátránya a 32 bites floathoz képest. A DXR-nél a Microsoft az snormot nem azért hagyta ki, mert nem működhet a sugárkövetéssel, hanem azért, mert egy biztonságos minimumra törekedtek, és úgy voltak vele, hogy majd ha működik, akkor belerakják az elterjedt formátumokat. Emiatt a Microsoft sem hibás ebben a kérdésben, de ettől a 32 bites float zabálni fogja a memóriát, és a DXR-t használó fejlesztők kénytelenek lesznek a geometriával finoman bánni, ha nem akarnak kifutni a relatíve kevés VRAM-ból. Ezt nem árt figyelembe venni, mert ha nem tud róla a világ, akkor csak annyi marad meg a sugárkövetésből, mint a Metro Exodus demójánál, hogy eléggé csúnyácska. Holott annak nem igazán a sugárkövetés a baja, hanem a geometriai és textúrarészletesség, amit vissza kellett venni a sugárkövetés alkalmazása miatt. Ettől maga a sugárkövetés még jó, csak áldozatokat kell hozni érte. [link] - olvasd el nyugodtan a kommenteket. Pedig magának a sugárkövetésnek tényleg semmi baja a videóban, kifejezetten szépen van megoldva.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A 6 fölötti GPC-hez valószínűleg bele kell túrni a memóriamodellbe. Mivel az az ISA átalakításával is jár, így húzzák ameddig tudják.
A GPC-n belül lehet játszani. Van egy határ, de a 640-et akkor hasraütésre mondta, tehát nem igazán tudni, hogy hol az igazi határ. Azért a multiprocesszorok is elég sok módon tömbösíthetők.
Persze, ha megfizetnék, akkor mind 7 nm lenne. De a 7 nm az nem olyan ám, mint régen. Természetesen megvan benne valamekkora fogyasztáselőny a 12-16 nm-hez képest, de ezzel együtt a node drága marad, tehát attól, hogy valami 7 nm, még nem fogsz tudni rajta olcsóbban gyártani, ami azért nem mindegy.Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ez bonyolultabb. Egyszerűnek tűnik, hiszen elvben csak többet kell ajánlani például az AMD-nél, és a TSMC rögtön nem nekik adja a kezdeti gyártósorok egy részét. De a 7 nm-es node, különösen az első körös fejlesztés elég drága. A waferárakat a TSMC nagyon durván méri, vagyis alig van olyan cég, amelyik ki tudja gazdálkodni ezeket. Nem véletlen, hogy több gyártó csak a második körben megy 7 nm-re, mert akkor olcsóbb lesz a wafer. Ha mondjuk az AMD csak GPU-kat gyártana a TSMC-nél, akkor ők is maradtak volna 12-16 nm-en, mert egyszerűen nem lehetne optimálisan kigazdálkodni a VGA-piacból, de mivel gyártan fognak ott CPU-kat is, a szerverbe, ahol egy termék átlagos eladási ára 3000-4000 dollár lesz, hát így már mindjárt más.
Szóval persze jó lenne a 7 nm-es node, de ezeket a döntéseket úgy kell meghozni, hogy legyen jó vaskos profit a terméken, ami megfelel a befektetői igényeknek, így pedig már hajlik a mutató a 12 nm felé. A vásárló pedig nem mindent fizet meg. Ez nem szerverpiac, ahol a CPU-ra bemondod a 3000-4000 dollárt és megveszik, mert kell a teljesítmény, hiszen az egészre egy üzleti modell épül a megrendelőnél. A GPU-k esetében a lapkák zöme végfelhasználói szintre készül.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 hoolla
#18520
üzenetére
hoolla
#18520
üzenetére
A Vega 20 elérhető lesz az adatközpontokba idén. Erre a SIGGRAPH-on volt utalás, de arra nem, hogy máshova mikor jön, viszont a lapka kész, ősszel már a végleges mintákat szállítják.
Azt figyelembe kell venni, hogy a TSMC-nek egyelőre az EUV nélküli 7 nm-es node-ja érhető csak el. Az EUV-s 7 nm-es eljárás kísérleti gyártása csak jövőre kezdődik meg (kicsit most a vírus is bekavart, így a TSMC a kísérleti gyártások eltolásán próbálja behozni a rendelésekben keletkezett elmaradását), és a tényleges, tömeggyártáshoz szükséges gyártósorok elérhetősége legalább egy év múlva esedékes. Az NV mindenképpen az EUV-s 7 nm-re ugrik, mert a mostanit túl drágának tartják. Az AMD-nek az EPYC-ekkel a hátuk mögött ez belefér, de az NV-nek csak GPU-ja van ide, amivel a mostani waferár nem realitás, és tavasszal sem lesz az, mert akkor sem lesz EUV-s node.
Egyébként a költségek szempontjából nem járnak rosszul. A 7 nm-es váltás eleve egy olyan tényező, hogy ami mondjuk 12 nm-en egy 600 mm2-es lapka, az 7 nm-en kb. 380-400 mm2- lesz. De árban ettől még nem lett olcsóbb, mert a 7 nm-es waferek legalább ennyivel drágábbak is.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Looserke
#18524
üzenetére
Looserke
#18524
üzenetére
Ők a TSMC-nél minden új lapkát 7 nm-re visznek. A GloFo-nál elvileg lesz még egy GPU 12/14 nm-es node-on (azt nem tudom, hogy 12 vagy 14 nm-en, de igazából majdnem mindegy, olyan hatalmas különbség nincs a 12/14/16 nm-es node-ok között - sőt alig van, a nanométer előtti szám nem igazán jó indikátor). Később a GloFo esetében is EUV-s 7 nm-re váltanak, de tudtommal csak a Matisse CPU-ra vonatkozóan, ami gyakorlatilag ugyanaz, amit a TSMC-nél készítenek a szerverekbe. A GPU marad a TSMC-nél.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
hoolla
#18526
üzenetére
A bányászat miatt a legtöbb fejlesztés eleve csak állt a fiókban. Tehát ez most nem olyan start, mint régen. Ha nem lett volna bányászláz, akkor már kint lenne több új termék is, de sajnos volt. Emiatt is tűnhet furcsának, hogy nem 7 nm-en jönnek, de ezek amúgy hamarabb jöttek volna "túrás nélkül". Mivel a túrásnak annyi, így ömlesztve megéri frissíteni. Nem mindent egy héten belül, de a szokásosnál gyorsabban lezavarva.
Persze a Vega 20-ból bármikor csinálhatnak halandó verziót. Az Instinct minta kint volt a SIGGRAPH-on. Elzárták, de nem elég jól, ilyen Nano-szerű apróság 1 darab 6 tűs PCI Express csatival. Úgy néz ki fizikailag, mint az Instinct MI6 a csicsák nélkül.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 NightGT
#18608
üzenetére
NightGT
#18608
üzenetére
Nem, de drága nagyon a DRAM. Felkarterezték az árát. Emiatt jön ilyen 11 GB, stb, mert egy lapkán is hatalmasat lehet spórolni. Mindeközben az egész helyzetet tudja úgy kezelni az NV, hogy a partnerstúdiókkal lebeszélik, hogy ne használjanak már olyan sok VRAM-ot, amit eléggé egyszerűen el lehet érni, ha nem szállítják mondjuk a legnagyobb tervezett textúrákat, stb. Egyedül az AMD lesz a probléma, mert ők pedig pont azt fogják mondani, hogy de-de szállítsátok csak, a Vegának pont ez az erőssége. Szóval izgi lesz.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 keIdor
#18629
üzenetére
keIdor
#18629
üzenetére
Az lesz az izgi meccs, hogy az NV azért fog puncsolni, hogy ne fussanak ki a memóriából, míg az AMD azért, hogy futtassák ki őket. Tényleg nem nehéz ezt megcsinálni egy 8 GB alatti VGA-val, míg a Vegának mindegy a memóriaigény, ~16 GB-ot is lekezel úgy, hogy a hardveren fizikálisan 2 GB van. Ezért megy a HBCC-s Kaby Lake-G-n is folyamatosan az alapvetően 14 GB VRAM-ot igénylő ME: Shadow of War maximális textúrákkal.
Mindenképpen itt fogják ütköztetni az akaratukat, hiszen tényleg ellentétesek lettek az érdekeik. Az AMD-nek innentől az a jó, ha brutális, akár 8K-s textúrákkal szállítja a partner a játékot, míg az NV-nek az, ha közepes, leginkább 2K-s méretűekkel. A legtöbb fejlesztő gondolom behúz majd középre, mert egyrészt a 4K az ideális, másrészt mondhatják a cégeknek, hogy a 8K nagyrészt faszság, a 2K pedig nagyrészt kicsi. Szóval egyiknek se tettek a kedvére, és pont.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.


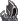




 Amíg ez ott van a Windowsban, addig az ARM-os megoldások igen szűk piacon versenyképesek csak.
Amíg ez ott van a Windowsban, addig az ARM-os megoldások igen szűk piacon versenyképesek csak.




![;]](http://cdn.rios.hu/dl/s/v1.gif) , de nem biztos, hogy pont maga az API a hiba oka, ha egy program mondjuk lassul DX11-ről DX12-re váltásnál.
, de nem biztos, hogy pont maga az API a hiba oka, ha egy program mondjuk lassul DX11-ről DX12-re váltásnál.



 Tök jó lenne 16-24 GB-ot rakni rá, ahogy tervezték, de amikor tervezték, akkor még nem ilyen drága memóriaárakkal számoltak. Ez a tényező azért nagyon erősen beleszól a végeredménybe. Ráadásul a GDDR6-nál az árnyékolás sem olcsó mulatság.
Tök jó lenne 16-24 GB-ot rakni rá, ahogy tervezték, de amikor tervezték, akkor még nem ilyen drága memóriaárakkal számoltak. Ez a tényező azért nagyon erősen beleszól a végeredménybe. Ráadásul a GDDR6-nál az árnyékolás sem olcsó mulatság.



Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az NVIDIA éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

