Hirdetés
-


Friss előzetesen a Destiny 2: The Final Shape
gp Érkezik az utolsó nagy kiegészítő, azonban a fejlesztők szerint ettől még nem lesz vége a franchise-nak.
-


Közel 1 billió dollárt vesztettek a big tech óriásai
it Nagyot kaszáltak a shortolók, az úgynevezett Magnificent 7 közel 1 billió dollárt veszített a piaci értékéből a múlt héten.
-


Toyota Corolla Touring Sport 2.0 teszt és az autóipar
lo Némi autóipari kitekintés után egy középkategóriás autót mutatok be, ami az észszerűség műhelyében készül.






-

PROHARDVER!
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
Annyit hozzátennék, hogy egyrészt jól leírtad, hogy az explicit API-k a skálázás szempontjából elkerülhetetlenek, illetve mindenkinek a Vulkan tetszik igazán
![;]](//cdn.rios.hu/dl/s/v1.gif) , de nem biztos, hogy pont maga az API a hiba oka, ha egy program mondjuk lassul DX11-ről DX12-re váltásnál.
, de nem biztos, hogy pont maga az API a hiba oka, ha egy program mondjuk lassul DX11-ről DX12-re váltásnál.
Ahogy észrevettem a legnagyobb limit (van még pár, de most a legfőbb bűnösről beszéljünk) a memóriamenedzsment. Ezt ugye explicit API mellett a program oldaláról kell meghatározni, és az tök jó, hogy a Vulkan és a DX12 szépen specifikál memóriatípusokat, memóriahalmazokat, bizonyos flageket, amelyekkel meghatározhatók az egyes memóriatípusok képességei, stb. Ugyanakkor ezek mellett nem feltétlenül találják a fejlesztők azt az optimális procedúrát, amivel jó lehet a memóriamenedzsment. És az alábbi három kép eléggé jól megmutatja, hogy ez miért baj: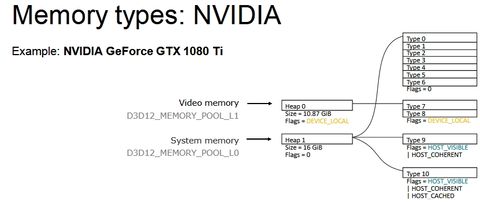

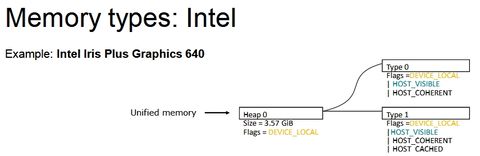
Na most tehát egy olyan menedzsmentet kell írni, ami a fenti három IHV strukturális memóriakezelését jól lefedi. És hát ez a memóriakezelés marhára különböző, már ránézésre is, tehát nem egyszerű ez a feladat.
Na most a probléma kétirányú. A memóriatípusokra vonatkozóan káosz van. Minden IHV-nek van két típusa erre. Az Intelnek egy host által látható és koherens, illetve egy még gyorsítótárazható is. Az AMD-nek van egy normál és egy host által látható és koherens, míg az NV-nek van két normál. Tehát effektíve nincs közös nevező. A memóriatípus szerinti menedzsment ezzel kizárható, ugyanakkor mégis ez a legegyszerűbb mód, tehát annak ellenére, hogy minden IHV mást támogat, sokszor erre erőszakolnak rá valamit a fejlesztők. És innentől kezdve már a strukturális implementáció hatékonysága lesz a döntő. Ez a legfőbb oka annak, amiért egy DX12 mód lassabb lehet egy DX11 módnál az egyes hardvereken.
A használhatóbb koncepció a nagy blokkos menedzsment. Mondjuk 256 MB-os blokkokkal, és ezeken a blokkokon belül lehet kisebb allokációkat létrehozni az erőforrásoknak. A halmazok esetében optimális felosztás az eszközlokális halmazok kapacitásának a tizede, vagy nyolcada. A nyolcada azért jó, mert az a legtöbb hardveren 1 GB lesz, és abba pont befér négy blokk. Juhéé. De amúgy ez sem egy szuperoptimális megvalósítás, mert az NV struktúrájával vannak buktatói, de összességében ez adja a legtöbb közös nevezőt. A Vulkan esetében azért látni, hogy az NV sem annyira rossz ebben az API-ban, mert a Khronos már szabványosította a dedikált allokációt, és azzal az NV struktúrájának buktatói kezelhetők. Extra munka, de működni fog. DX12-ben viszont ilyen utólagos kezelésre nincs lehetőség. Emiatt ritka, hogy az NV gyorsabb legyen a DX11-es módnál.
De amúgy ez sem egy szuperoptimális megvalósítás, mert az NV struktúrájával vannak buktatói, de összességében ez adja a legtöbb közös nevezőt. A Vulkan esetében azért látni, hogy az NV sem annyira rossz ebben az API-ban, mert a Khronos már szabványosította a dedikált allokációt, és azzal az NV struktúrájának buktatói kezelhetők. Extra munka, de működni fog. DX12-ben viszont ilyen utólagos kezelésre nincs lehetőség. Emiatt ritka, hogy az NV gyorsabb legyen a DX11-es módnál.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.


![;]](http://cdn.rios.hu/dl/s/v1.gif) , de nem biztos, hogy pont maga az API a hiba oka, ha egy program mondjuk lassul DX11-ről DX12-re váltásnál.
, de nem biztos, hogy pont maga az API a hiba oka, ha egy program mondjuk lassul DX11-ről DX12-re váltásnál.
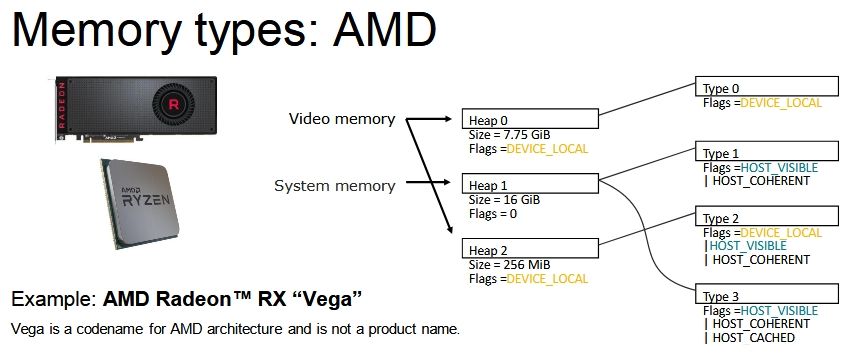

 De amúgy ez sem egy szuperoptimális megvalósítás, mert az NV struktúrájával vannak buktatói, de összességében ez adja a legtöbb közös nevezőt. A Vulkan esetében azért látni, hogy az NV sem annyira rossz ebben az API-ban, mert a Khronos már szabványosította a dedikált allokációt, és azzal az NV struktúrájának buktatói kezelhetők. Extra munka, de működni fog. DX12-ben viszont ilyen utólagos kezelésre nincs lehetőség. Emiatt ritka, hogy az NV gyorsabb legyen a DX11-es módnál.
De amúgy ez sem egy szuperoptimális megvalósítás, mert az NV struktúrájával vannak buktatói, de összességében ez adja a legtöbb közös nevezőt. A Vulkan esetében azért látni, hogy az NV sem annyira rossz ebben az API-ban, mert a Khronos már szabványosította a dedikált allokációt, és azzal az NV struktúrájának buktatói kezelhetők. Extra munka, de működni fog. DX12-ben viszont ilyen utólagos kezelésre nincs lehetőség. Emiatt ritka, hogy az NV gyorsabb legyen a DX11-es módnál.Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az NVIDIA éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

