A HBM adja a cukormázt
A memórián is változtat az NVIDIA, mivel az ilyen szörnyetegekhez már komoly memória-sávszélesség szükséges, emiatt a vállalat a HBM memóriaszabvány második generációs verzióját veti be. A GP100 meglehetősen méretes interposerére négy darab, egyenként 4 GB-os, azaz összesen 16 GB HBM memória kerül. Ezek a GPU négy darab memóriavezérlőjéhez egyenként 1024 bites buszon keresztül kapcsolódnak. A változás miatt az NVIDIA átdolgozta a memóriavezérlést igazodva a HBM igényeihez, illetve a lapka kapott még 4 MB L2 gyorsítótárat is.
Amolyan extrának számít, de a szerverek területén nagyon fontos lesz az NVLINK, mely összeköttetés a GP100-on belül HUB által lesz vezérelve. Maga a lapka négy darab NVLINK interfészt kezel, vagyis minden GPU-hoz négy további GPU köthető. Egy NVLINK interfész egy irányba 20 GB/s-os adatátviteli teljesítményt kínál. A GP100-hoz alkalmazható topológiától függően az összteljesítmény elérheti a 160 GB/s-ot, de ez nagyban függ a konfiguráció formájától, így általánosítani nem lehet.
Hirdetés
A GP100-akat kétféleképpen lehet beépíteni a szerverekbe. Egyrészt használhatók olyan processzorok, amelyek minimum x16-os PCI Express 3.0-s vezérlővel rendelkeznek. Ilyenkor egy processzorra a megfelelő PCI Express átkapcsolóval akár két GP100 is köthető, de a szerverprocesszorok esetében azért jellemzően jóval több PCI Express 3.0-s csatorna is használható. Az NVIDIA a megfelelő NVLINK topológia miatt processzoronként maximum négy GP100 lapkát enged meg.
Alternatív, de egyben sokkal jobb lehetőség, ha a GP100 nem csak PCI Express 3.0-s interfészen kapcsolódik a processzorhoz, hanem közvetlenül NVLINK-en is. Ilyenre lesz lehetőség, méghozzá az IBM OpenPOWER konzorciumának hála. Érkezni fog ugyanis legalább egy Power8 architektúrát használó processzor, amelyen belül található két NVLINK is. Egy ilyen processzorhoz két GP100-as GPU kapcsolható két x16-os PCI Express 3.0-s és két NVLINK interfészen keresztül. Kétutas szerver esetén ez máris négy GP100-at jelent, amelyek természetesen összeköthetők az NVLINK által. Ezt a topológiát az alábbi ábra szemlélteti.
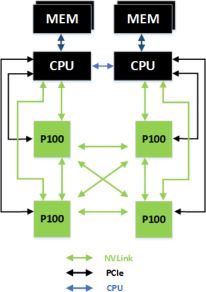
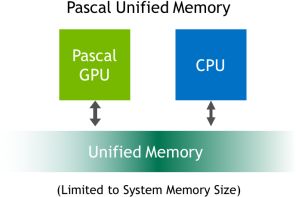
Ennek a modellnek egy hatalmas járulékos előnye az egységes virtuális memória támogatása, az NVIDIA ugyanis a Pascal architektúrát úgy tervezte, hogy közvetlenül támogassa az IBM Power8 címzési modelljét, illetve a processzorarchitektúra által használt lapméretet. Ilyen formában egy GP100-as GPU képes direkten az IBM Power8 processzorhoz kapcsolt teljes rendszermemóriába írni, vagyis elkerülhetők a sok bonyodalmat okozó adatmásolások.
A tényleges termékre rátérve a Tesla P100 nem teljes értékű GP100-at használ, mivel a lehetséges 60 shader multiprocesszorból csak 56 lesz aktív. Ez nem akkora probléma, mivel nyilván a gyártás során keletkeznek selejtek, amelyek a hibás területek letiltásával eladhatóvá vállnak. Évek óta alkalmazott és jól működő modell ez, különösen egy új gyártástechnológia bevezetésénél.
56 darab SM-mel számolva a 300 wattos TDP fogyasztási osztályba sorolt Tesla P100-ban összesen 3584 darab CUDA mag lesz, amelyeket 1792 darab FP64-es feldolgozó egészít ki. A textúrázó csatornák száma összesen 224, míg a teljes memóriabusz 4096 bites. Az NVIDIA a magórajel szempontjából 1328 MHz-es paramétert tervez, míg a GPU Boost órajel 1480 MHz is lehet. Utóbbi értékkel számolva jönnek ki az 5,3 TFLOPS-os, 10,6 TFLOPS-os és 21,2 TFLOPS-os elméleti teljesítményadatok 64 bites, 32 bites és 16 bites lebegőpontos számítások mellett. A valósághoz egyébként közelebb állna az alapórajellel való számítás, mivel a GPU Boost csak bizonyos feltételek mellett teljesül. Emiatt ezeket az értéket is kiszámoltuk, így a Tesla P100 ilyen formában rendre 4,8 TFLOPS-ot, 9,5 TFLOPS-ot és 19 TFLOPS-ot tud. Az NVIDIA megadta a memória effektív órajelét is, amely 1,4 GHz lesz, így a memória-sávszélesség 720 GB/s. Mindemellett az ECC is támogatott.

A Tesla GP100 egyébként gépi tanulásban teljesít igazán jól, ami nem akkora meglepetés, ha figyelembe vesszük, hogy az NVIDIA konkrétan ide tervezte. A gyorsulást nem csak maga a grafikus vezérlő, hanem az egész rendszer biztosítja, kiemelve az NVLINK-et, és ilyen formában nyolc GT100 akár 12-szer gyorsabb lehet négy GM200-as GPU-nál. Ez lesz a rendszer fő előnye, de persze a dupla pontosság melletti teljesítmény is hasznos lesz más területeken.
Abu85







