A gépi tanulás terjedésével egyre többen terveznek speciálisan erre a területre szánt célhardvereket, amelyek abszolút átvehetik az uralmat a ma használt, általánosan tervezett megoldásoktól, elvégre jóval hatékonyabban végzik a munkájukat. A neurális hálók legnagyobb problémája viszont még mindig a magas fogyasztás. Bár ez viszonylagos szempont, de látni lehet, hogy a feldolgozást mindenki két részre bontja. Egyrészt van egy szerver oldali tréning szakasz, ami igen komoly gépparkkal valósul meg, és csupán a dedukció szakasza lehet kliensoldali. Ez persze a mai világban nem akkora tragédia a felhasználók számára elvégre az internet elérése rendkívül egyszerűvé vált, így mondhatni nyugodtan lehet a felhőre, vagyis egy távoli szerverre építeni.
Hirdetés
Azt viszont nem szabad elfelejteni, hogy ilyen formában az egyes, AI-t igénylő szolgáltatások csak internetelérés mellett működnek, ami például egy mobil eszköznél igényli a beépített modem aktiválását, továbbá a szerver oldali rendszert is üzemeltetni kell, ami nem kevés költség.
Az MIT, vagyis a Massachusettsi Műszaki Egyetem kidolgozott egy speciális AI lapkát, ami állításuk szerint három-hétszeresére növeli a teljesítményt az aktuális modellekhez viszonyítva, miközben 95%-kal csökkenti az energiaigényt is.
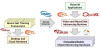
A MIT magyarázata szerint a mai hagyományos modellekkel a memóriaműveletek jelentik a problémát, ugyanis ezekre nagyon építenek a neurális hálók. Ezt nem kell különösebben magyarázni, mivel a jelenleg alkalmazott szisztémában a neurális hálók rétegekre vannak osztva. Ezeken belül találhatók a node-ok, amelyek logikai szinten csatlakoznak egymáshoz. Minden node kap valamilyen bemeneti adatot, ami egy köztes vagy egy végponti réteg esetében már több node-ból származik, és a kimenet is több node felé lesz elküldve. Emiatt figyelembe kell venni, hogy egy node-ra vonatkozó kalkuláció, hány csatlakoztatott node-ban von maga után számítást, amit skaláris szorzattal lehet kezelni. Utóbbi jelenti a problémát, mert ez a művelet rendkívül memóriaintenzív, és minden egyes bemeneti adathoz külön kell számolni.
A MIT megoldása itt trükközik, ugyanis a skaláris szorzat számítása magában a prototípus chip memóriájában történik meg, párhuzamosan akár 16 kalkulációval is elbír a rendszer, és a pontosság szempontjából a veszteség csak 2-3%, ami bőven belefér. Ezzel jelentősen csökkenthető a memória terhelése, ami nagymértékben csökkenti a teljes konstrukció fogyasztását, és végeredményben esélyt ad arra is, hogy az AI-ra építő bonyolultabb szolgáltatások ne csak egy távoli szerveren keresztül legyenek elérhetők.
Rövidebb távon persze a kiépített infrastruktúra miatt mindenképpen a felhős irány a jövő, viszont a szerver oldalon is jelentősen faraghat a költségeken egy olyan rendszer, amely jelentősen redukálja az igényelt fogyasztást. Az mindenképpen látszik, hogy a gépi tanulás szempontjából a ma még főleg bevetett általános megoldások visszaszorulhatnak, elvégre a direkten erre a problémára kigyúrt hardverek sokkal hatékonyabban végzik el a feladatukat.