AMD Cypress

A technológiai oldalt áttekintve térjünk is rá a világ első DirectX 11-es lapkájának a vizsgálatára. A Cypress kódnevű chip az AMD Evergreen termékcsaládjának első képviselője. A vörös oldal természetesen folytatja a két generáció óta elkezdett, úgynevezett Sweet Spot stratégiát, így a most bemutatkozó lapkának lesz a legnagyobb a mérete. Ez egészen pontosan 334 mm²-es kiterjedést jelent, amibe kicsivel több mint 2,1 milliárd tranzisztor fért bele a TSMC 40 nm-es gyártástechnológiáját használva. Az architektúra alapjai még mindig a 2007-ben debütált R600-ra építenek, ám jelentős változások is vannak, amik a lehető legjobb DirectX 11-es teljesítmény érdekében kerültek a rendszerbe. Az AMD fejlesztési vonala már évek óta teljesen világos, hiszen a vállalat mindig az aktuális DirectX-re készíti fel a termékeit, ezzel a rendszer a grafikai számításokban nyújtja a legnagyobb teljesítményt.
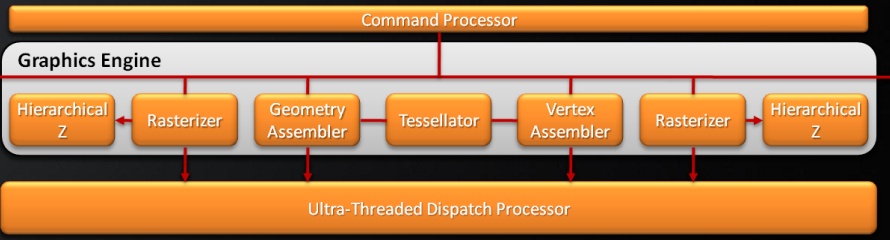
A Cypress legnagyobb újítása a feldolgozó motorban található. Az AMD a logikai vázlatba két raszterizálót rajzolt. Az elgondolás teljesen logikus, hiszen elméleti oldalról megközelítve a dolgokat a tesszellálás legnagyobb problémája a rendszerek triangle setup teljesítménye. A setup motor felel a nem látható háromszögek levágásáért, illetve beállítja a végleges poligonvázat, mely alapján majd a raszterizálás történik. A mai unified shader alapú rendszerek kivétel nélkül órajelenként egy háromszöget dolgoznak fel. A tesszelláció használatával azonban ez a teljesítmény a modellek részletességének ugrásszerű növekedésével esetenként kevés lehet. Elméletben tehát a háromszögek feldolgozásának párhuzamosítása a megoldás. A gyakorlati oldalon azonban ez az elgondolás rendkívül komplex szerkezeti felépítést eredményezne, és a vezérlése is hihetetlenül nehéz.
Hirdetés
Az AMD a tesszellációs folyamatra úgymond az arany középutat alkalmazza. A Cypress továbbra is egy háromszöget dolgoz fel órajelenként, ugyanakkor a scan conversion egységek számát megduplázták, ami a primitívek gyorsabb rendereléséhez vezet. Az elgondolás elméletben nyilván nem a leghatékonyabb, de a háromszögek párhuzamos feldolgozásával elérhető gyorsulás valószínűleg nem lett volna összhangban az összetett felépítés nagyon komoly tranzisztorigényével. Az AMD-nek volt ideje a régebbi rendszerek alapján vizsgálni a tesszellátor működését, így kellő adat van a birtokukban arról, hogy hol keletkeznek a rendszeren belül a legszűkebb keresztmetszetek, és erre mik az orvosságok. Fontos még megjegyezni, hogy a tesszelláció a legtöbb esetben a kamerához közel lévő objektumokon lesz csak végrehajtva, mivel a távoli modellek részletességét felesleges növelni.
A Cypress a számítások elvégzésénél továbbra is az Ultra-Threading Dispatch Processzorra támaszkodik, mely vezérli és eteti a 20 darab shader tömböt. A lapka logikai vázlatán rögtön látszik egy komolyabb eltérés, ugyanis ezek a tömbök az előző generációs kialakítástól eltérően nem egy, hanem két nagy shader blokkba rendeződnek. A működésben ez nem jelent változást, ugyanakkor a tervezés szempontjából elengedhetetlen az új felépítés. A mai lapkákban található belső rendszerbuszt kisebb átalakításokkal csak korlátozott mértékben lehet skálázni. Ez a Cypressre is igaz, így ha a lapka egy darab nagy shader blokkból állna, akkor az előző generációs chipekben alkalmazott buszstruktúrát teljesen újra kellett volna tervezni. Az AMD ezzel a megoldással rengeteg időt takarított meg, ami nagyban hozzájárult ahhoz, hogy a vállalat jelenleg egyedüliként kínáljon a piacon DirectX 11-es grafikus processzort.
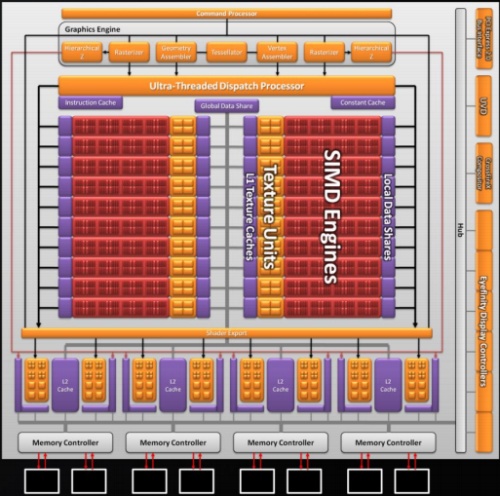
A shader tömbök felépítése az előző generációhoz mérve változatlan, azaz továbbra is 16 darab szuperskalár shader processzor teljesít bennük szolgálatot. Újdonság azonban a Local Data Share, mely egy 32 kB kapacitású tároló egy-egy shader tömbhöz kötve. Természetesen nemcsak helyi, hanem globális adatmegosztásra is képes a Cypress. Utóbbi szerepét a két shader blokk között található, nagy sebességű, 64 kB-os (Global Data Share) tárterület tölti be. A shader tömbönként található textúrázó blokk négy darab Gather4-kompatibilis csatornát alkalmaz, melyek csak szűrt mintákkal térnek vissza. Itt érdemes megjegyezni, hogy az előző generáció óta az AMD megvált a fix funkciós interpolátoroktól, így az új lapka már a shader processzorok segítségével emulálja az interpolációt. Ez tulajdonképpen jó is, meg rossz is. Nem kétséges, hogy a fix funkciós egységek gyorsabban végzik a feladatukat az emulált megoldáshoz viszonyítva, így a rendszernek le kell mondania némi számítási kapacitásról az interpolálás javára, ez összességében néhány százalékos teljesítményveszteséghez vezet. Előfordulnak azonban olyan esetek, amikor az interpolátor egységek limitálják a feldolgozást. Ilyenkor az emulált feldolgozás a nyerő, mivel a rendszer sokkal kiegyensúlyozottabban tud működni. Tekintve, hogy a mai 3D-s programok mennyire eltérő igényekkel rendelkeznek, a fix funkciós interpolátorok elhagyása nem tűnik rossz döntésnek. Az elgondolás számos esetben fog gyorsabb munkavégzéshez vezetni, azonban nem mehetünk el szó nélkül amellett, hogy alkalmanként, ha kismértékben is, de negatívan is befolyásolhatja a teljesítményt.
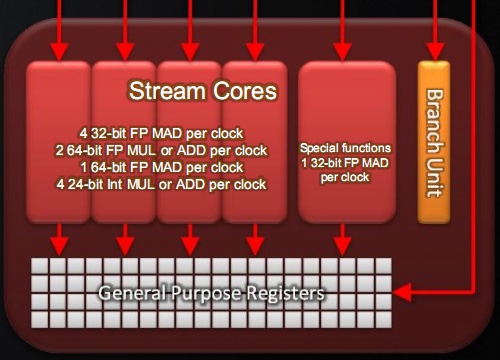
A 4 darab skalár és 1 darab speciális végrehajtó egységgel működő szuperskalár shader processzor okosabb lett az előző generációhoz viszonyítva. Ez szerencsére nem merül ki az DirectX 11-ben megkövetelt bitszintű utasítások és az IEEE754-2008-as lebegőpontos szabvány támogatásában. Az új ALU-k támogatják az FMA (Fused Multiply-Add) utasítást. Ennek a lebegőpontos számítások esetében van értelme, ugyanis a sokat használt MAD (Multiply-Add) instrukciónál pontosabb eredményt ad. Ez annak köszönhető, hogy az FMA esetében csak a végeredményt kell kerekíteni a lebegőpontos szabványnak megfelelően. A MAD utasítás a szorzást és az összeadást egymás után végzi, így a szorzással keletkezett részeredmény már eleve egy kerekített érték lesz. További újítás még, hogy a szuperskalár shader processzor képes egyszerre futtatni egy MUL és egy ADD utasítást, még akkor is, ha az utóbbi számítás az előbbi eredményétől függ.
A rendszer a dupla pontosság mellett változatlanul üzemel, azaz a szuperskalár shader processzor 4 darab skalár ALU-ja egy 64 bites MAD és két szintén 64 bites ADD, illetve MUL utasítást futtat. Emellett új instrukció a SAD (Sum of Absolute Differences), amelyet főleg multimédiás alkalmazásoknál lehet használni.
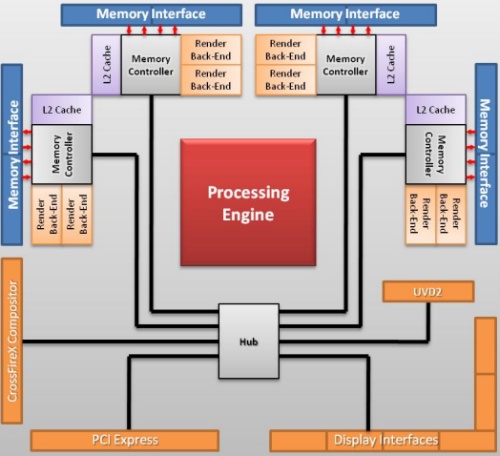
A memóriavezérlő továbbra is az RV770-ben megismert Control Hub, ami négy 64 bites csatornát üzemeltet. Ezekhez a csatornákhoz kapcsolódik egy-egy 128 kB kapacitású másodlagos gyorsítótár és két-két ROP blokk. Utóbbiból összesen nyolc darab van, ami 32 blending és 128 Z mintavételező egységet eredményez.
A cikk még nem ért véget, kérlek, lapozz!




