DirectX 10 és 10.1
Kapcsolódó cikkek (szükségesek lehetnek a cikk megértéséhez):
Harmadik dimenzió / A reformok kora / Dávid és Góliát
Kapcsolódó leírások (szükséges lehet a cikk megértéséhez):
Grafikus fogalomtár
Alig egy hónap múlva hivatalosan is felavathatjuk a Microsoft új, DirectX 11-es API-ját, melynek legfontosabb újításairól már korábban beszámoltunk. Ennek megfelelően a linkelt cikkben leírt dolgokat nem tárgyaljuk újra, azonban érdemes megvizsgálni, hogy milyen előnyök érik a felhasználókat az új rendszer alkalmazásával. Manapság sok olyan kijelentést lehet hallani, hogy a DirectX 9-et kellene megfelelően kihasználni. Nos alapvetően a kihasználás mint fogalom ez esetben értelmetlen. Természetes, hogy a shader modell a 3.0-s verzió bevezetésével komoly bővítésen ment keresztül, ami azt eredményezi, hogy a legtöbb effekt megvalósításához nincs szükség úgymond modernebb kódra. Ettől függetlenül fontos szempont lehet az algoritmus sebessége is, és itt jönnek a képbe az új DirectX verziók. A gyártók a Microsofttal karöltve olyan új eljárásokat vezetnek be, melyek a látványvilág javítása mellett gyorsabb feldolgozást tesznek lehetővé.
A felhasználók körében nem igazán kedvelt DirectX 10 egy nagyon fontos táptalaja volt a későbbi 10.1-es és az új 11-es kiterjesztésnek. A Windows Vistában megjelent API a reformra helyezte a hangsúlyt, és olyan változásokat vezetett be, melyek előnyösek a fejlesztőknek. A Microsoft egy merőben új, mindent vagy semmit elvet alkalmazott, ami azt jelenti, hogy a grafikus processzoroknak az API összes tulajdonságát támogatniuk kellett. Érdemes azt is megjegyezni, hogy ha a videokártya esetleg többet tud, mint amit a támogatott DirectX verzió megkövetel, akkor az nem számít. Ezzel gyakorlatilag a fejlesztők konkrétan a szabvány szerint dolgozhattak. A DirectX 10 előtt ez nem így volt, ugyanis voltak úgynevezett gyártói kiterjesztések is, így ügyelni kellett arra, hogy a program olyan eljárásokra épüljön, amelyeket az összes piacon lévő termék támogat. Amennyiben ez nem volt megoldható, akkor az effektet többször kellett megírni gyártóspecifikus algoritmusokkal, ami természetesen időveszteség.
A reformok után a DirectX 10.1 olyan eljárásokat vezetett be, melyek a sebesség növelését és a felmerült kompatibilitási problémák javítását célozták meg. Az újításokkal átlagosan 20-25%-os teljesítményjavulás volt elérhető. Természetesen az így nyert sebességet a fejlesztők szebb effektekre is elkölthették, így az előbbi, átlagosan elérhető gyorsulás nem nevezhető általánosnak. A felhasználók számára a legjobb hír, hogy az API úrrá lett az multisampling-alapú élsimítást és az anizotróp szűrést érintő nehézségeken. Az előbbi a deferred renderinget használó motorokon nem működik megfelelően, míg az utóbbi a parallax occlusion mapping mellett mutat gyenge hatásfokot. Ennek köszönhetően a multisample access és a LOD utasítások bevezetése komoly problémákat oldott meg.


DirectX 10 4xAA - DirectX 10.1 4xAA [+]
DirectX 11
A DirectX 11-be a Microsoft számos új funkciót épített be, melyekkel további sebesség nyerhető. A fejlesztők beszámolója szerint a tesszellátor a legfontosabb újítása a rendszernek, ám komoly lehetőségek vannak a compute shaderben is. Előbbi eljárást már a fentebb linkelt cikkben teljesen kiveséztük, így koncentráljunk az utóbbi funkcióra. A compute shader segítségével a programozók olyan programokat írhatnak, melyek a grafikus processzor erejét általános számításokra hasznosítják. Természetesen a programok és a fejlesztői platformok folyamatosan érkeznek majd a gyártófüggetlen rendszerre. A cikkünk fő témája azonban a grafika fejlődése, így elsősorban a funkció képminőségre vonatkozó hatásait vizsgáljuk.
A DirectX 11 futószalagján a compute shader a pixel shader úgymond független mellékágának tekinthető. Ez gyakorlatilag azt jelenti, hogy a grafika szempontjából a majdnem kész képen lehet vele módosításokat végrehajtani. Tulajdonképpen mondhatjuk azt, hogy az egyes pixel shader kódokat mostantól érdemes compute shaderben írni, hiszen maga a programnyelv számos előnyös újítást kínál, továbbá visszafelé kompatibilis egészen a DirectX 10-es kártyákig. Itt azonban meg kell jegyezni, hogy az egyes funkciók között különbségekkel kell számolni. Erről az alábbi táblázat ad felvilágosítást:
| Microsoft DirectX 11 |
|||
| Compute Shader 4.0 |
Compute Shader 4.1 | Compute Shader 5.0 | |
| Szálakhoz rendelt memória |
16 kB | 16 kB | 32 kB |
| Helyi adatmegosztás |
nincs | nincs | van |
| Memóriamegosztás | 256 byte (csak írás) | 256 byte (csak írás) | 32 kB (írás/olvasás) |
| Szálvezérlési forma | kétdimenziós | kétdimenziós | háromdimenziós |
| Futtatott szálak száma |
768 | 768 | 1024 |
| Gather4-támogatás |
nincs | van | van |
| Atomi művelet | nincs | nincs | van |
| Dupla pontosság | nincs | van | van |
A compute shader 5.0 legnagyobb előnyének a helyi feladatmegosztás (Local Data Share) számít, ami a különböző folyamatszálak közötti memóriamegosztást teszi lehetővé. Ezzel a megoldással a textúrázó csatornák több esetben is felmenthetők a munka alól, hiszen jó esély van rá, hogy a szükséges adat egy korábbi mintavételezés alkalmával létrejött. A felesleges munkától megkímélve a rendszert az algoritmusok számítási sebessége akár a háromszorosára is gyorsítható. Ez a teljes képkockára levetítve 15-25%-os gyorsulást jelenthet a DirectX 10.1-es módhoz képest. Itt fontos megjegyezni, hogy a compute shader 4.1 és 5.0 támogatja a Gather4 utasításokat is, amelyekről már tudjuk, hogy egy mintavételből négyszer annyi adatmennyiséget generálnak. Ez majdnem négyszeres gyorsulás a DirectX 10-es kódhoz képest, ami a gyakorlati tapasztalatok alapján 20-25%-kal sebesebb képkocka-feldolgozást eredményez. A párhuzamosan futtatott szálak száma is megnőtt a DirectX 11-ben, így ezen a fronton is lehet nyerni némi teljesítményt.
A compute shader természetesen nem csak sebességben előnyös. Az atomi műveletek alkalmazása nagymértékben megkönnyíti a fejlesztők munkáját, továbbá rengeteg programszál problémamentes futtatását teszi lehetővé. Az atomi műveletek bevezetésére már régóta várnak a programozók, ugyanis a grafikus processzorok rengeteg, mondhatni több száz programszálat futtatnak párhuzamosan. Ilyen körülmények mellett aránylag sűrűn előfordulhat az az eset, amikor egy vagy több programszál ugyanazt a változót próbálja kezelni, vagy azonos memóriacímet kísérel meg elérni. Ezek a problémák természetesen hibás feldolgozást eredményezhetnek az úgynevezett korrupt adatok miatt. Ilyen esetben a programozónak át kellett alakítania az egyik algoritmust, hogy elkerülje a jelenséget, rosszabb esetben pedig soros műveletvégzést kellett alkalmazni a megosztott változók, illetve a memória eléréséhez. Utóbbi elgondolás természetesen hatalmas probléma, hiszen kiüti a párhuzamos feldolgozást, ami esetenként komoly teljesítményveszteséget eredményez. Az atomi műveletekkel lehetőség van az előbbi problémát úgy kezelni, hogy a párhuzamos feldolgozás megfelelően legyen végrehajtva.
Aminek mindenki örülni fog
A DirectX 11 az első API, amelyik támogatja a többszálú feldolgozást, azaz az objektum megrajzolásához szükséges rajzolási parancsok és az effektek létrehozásánál bekövetkező állapotváltások már nem csak egyetlen processzormagon lesznek végrehajtva. Az új rendszer természetesen a régebbi, minimum DirectX 10-es grafikus kártyák mellett is működik, csupán egy szoftveres frissítés szükséges. A funkciót az AMD és az NVIDIA már korábban beépítette a Windows 7 és Vista operációs rendszerekre telepíthető driverekbe. Érdemes megjegyezni, hogy a többszálú feldolgozást a DirectX 11-es kódhoz optimalizálták, így a hatékonyság szempontjából a régebbi rendszerek némi hátrányt szenvednek.
Nincs ellenérv
A Microsoft szerint a DirectX 10-nek egy hibája volt: nem kompatibilis a DirectX 9-cel. Ennek köszönhetően a fejlesztőnek gyakorlatilag két API-t kellett támogatnia. Ezenkívül érdemes megjegyezni, hogy az API nem volt elérhető a jó öreg Windows XP-re, és a Vista sem terjedt megfelelő mértékben, ami a legtöbb programozót választás elé állította. Nos, a DirectX 11 a WDDM (Windows Display Driver Model) hiányában továbbra sem telepíthető XP-re, azonban a fejlesztők problémáját megoldotta a redmondi óriáscég. Az új API ugyanis hat futtatási szintet támogat:
-
D3D_FEATURE_LEVEL_11: értelemszerűen ez a szint mindent tud, így nincsenek korlátozások.
-
D3D_FEATURE_LEVEL_10_1: DirectX 10.1-es kártya esetén jön létre.
-
D3D_FEATURE_LEVEL_10: a DirectX 10-es kártyával ebben a módban fut a kód.
-
D3D_FEATURE_LEVEL_9_3: a shader modell a 3.0-s kártyákat támogatja, azaz ideális a GeForce 6 és 7, valamint a Radeon X1000 szériához.
-
D3D_FEATURE_LEVEL_9_2: speciális szint, kifejezetten a shader modell 2.0-s Radeon termékekhez.
-
D3D_FEATURE_LEVEL_9_1: az összes fentebb nem említett DirectX 9-es grafikus chip ide tartozik, beleértve a GeForce FX-et is.
Az előbb tárgyalt hat erőforrás automatikusan, a program indulásakor jön létre a számítógépben talált hardvernek megfelelően. Ez azt jelenti, hogy a programozónak elég a DirectX 11-es kódot megírni, és az API minden mást kezelni fog, azaz a kódban szereplő nem kompatibilis utasításokat és funkciókat egyszerűen nem futtatja. Ezzel a módszerrel a fejlesztők mindenkinek az igényét kielégíthetik, és még a befektetett munka is jelentősen csökkenthető.
AMD Cypress

A technológiai oldalt áttekintve térjünk is rá a világ első DirectX 11-es lapkájának a vizsgálatára. A Cypress kódnevű chip az AMD Evergreen termékcsaládjának első képviselője. A vörös oldal természetesen folytatja a két generáció óta elkezdett, úgynevezett Sweet Spot stratégiát, így a most bemutatkozó lapkának lesz a legnagyobb a mérete. Ez egészen pontosan 334 mm²-es kiterjedést jelent, amibe kicsivel több mint 2,1 milliárd tranzisztor fért bele a TSMC 40 nm-es gyártástechnológiáját használva. Az architektúra alapjai még mindig a 2007-ben debütált R600-ra építenek, ám jelentős változások is vannak, amik a lehető legjobb DirectX 11-es teljesítmény érdekében kerültek a rendszerbe. Az AMD fejlesztési vonala már évek óta teljesen világos, hiszen a vállalat mindig az aktuális DirectX-re készíti fel a termékeit, ezzel a rendszer a grafikai számításokban nyújtja a legnagyobb teljesítményt.
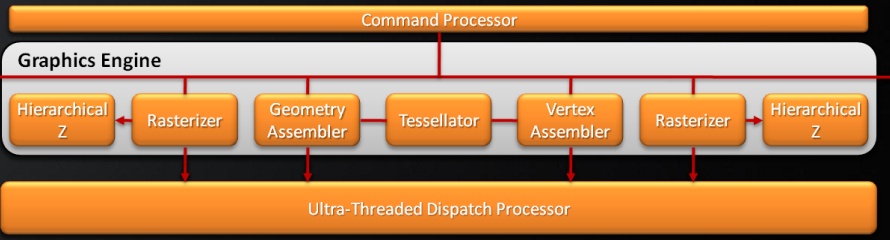
A Cypress legnagyobb újítása a feldolgozó motorban található. Az AMD a logikai vázlatba két raszterizálót rajzolt. Az elgondolás teljesen logikus, hiszen elméleti oldalról megközelítve a dolgokat a tesszellálás legnagyobb problémája a rendszerek triangle setup teljesítménye. A setup motor felel a nem látható háromszögek levágásáért, illetve beállítja a végleges poligonvázat, mely alapján majd a raszterizálás történik. A mai unified shader alapú rendszerek kivétel nélkül órajelenként egy háromszöget dolgoznak fel. A tesszelláció használatával azonban ez a teljesítmény a modellek részletességének ugrásszerű növekedésével esetenként kevés lehet. Elméletben tehát a háromszögek feldolgozásának párhuzamosítása a megoldás. A gyakorlati oldalon azonban ez az elgondolás rendkívül komplex szerkezeti felépítést eredményezne, és a vezérlése is hihetetlenül nehéz.
Az AMD a tesszellációs folyamatra úgymond az arany középutat alkalmazza. A Cypress továbbra is egy háromszöget dolgoz fel órajelenként, ugyanakkor a scan conversion egységek számát megduplázták, ami a primitívek gyorsabb rendereléséhez vezet. Az elgondolás elméletben nyilván nem a leghatékonyabb, de a háromszögek párhuzamos feldolgozásával elérhető gyorsulás valószínűleg nem lett volna összhangban az összetett felépítés nagyon komoly tranzisztorigényével. Az AMD-nek volt ideje a régebbi rendszerek alapján vizsgálni a tesszellátor működését, így kellő adat van a birtokukban arról, hogy hol keletkeznek a rendszeren belül a legszűkebb keresztmetszetek, és erre mik az orvosságok. Fontos még megjegyezni, hogy a tesszelláció a legtöbb esetben a kamerához közel lévő objektumokon lesz csak végrehajtva, mivel a távoli modellek részletességét felesleges növelni.
A Cypress a számítások elvégzésénél továbbra is az Ultra-Threading Dispatch Processzorra támaszkodik, mely vezérli és eteti a 20 darab shader tömböt. A lapka logikai vázlatán rögtön látszik egy komolyabb eltérés, ugyanis ezek a tömbök az előző generációs kialakítástól eltérően nem egy, hanem két nagy shader blokkba rendeződnek. A működésben ez nem jelent változást, ugyanakkor a tervezés szempontjából elengedhetetlen az új felépítés. A mai lapkákban található belső rendszerbuszt kisebb átalakításokkal csak korlátozott mértékben lehet skálázni. Ez a Cypressre is igaz, így ha a lapka egy darab nagy shader blokkból állna, akkor az előző generációs chipekben alkalmazott buszstruktúrát teljesen újra kellett volna tervezni. Az AMD ezzel a megoldással rengeteg időt takarított meg, ami nagyban hozzájárult ahhoz, hogy a vállalat jelenleg egyedüliként kínáljon a piacon DirectX 11-es grafikus processzort.
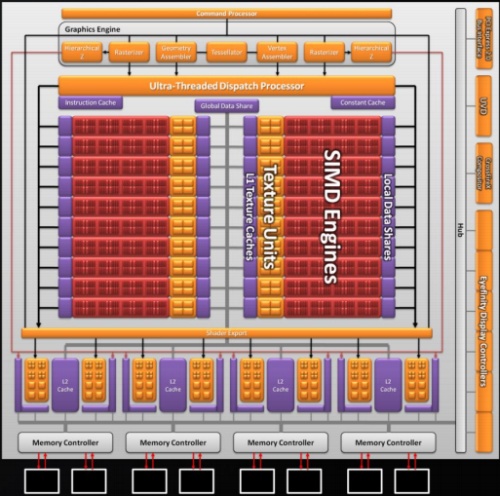
A shader tömbök felépítése az előző generációhoz mérve változatlan, azaz továbbra is 16 darab szuperskalár shader processzor teljesít bennük szolgálatot. Újdonság azonban a Local Data Share, mely egy 32 kB kapacitású tároló egy-egy shader tömbhöz kötve. Természetesen nemcsak helyi, hanem globális adatmegosztásra is képes a Cypress. Utóbbi szerepét a két shader blokk között található, nagy sebességű, 64 kB-os (Global Data Share) tárterület tölti be. A shader tömbönként található textúrázó blokk négy darab Gather4-kompatibilis csatornát alkalmaz, melyek csak szűrt mintákkal térnek vissza. Itt érdemes megjegyezni, hogy az előző generáció óta az AMD megvált a fix funkciós interpolátoroktól, így az új lapka már a shader processzorok segítségével emulálja az interpolációt. Ez tulajdonképpen jó is, meg rossz is. Nem kétséges, hogy a fix funkciós egységek gyorsabban végzik a feladatukat az emulált megoldáshoz viszonyítva, így a rendszernek le kell mondania némi számítási kapacitásról az interpolálás javára, ez összességében néhány százalékos teljesítményveszteséghez vezet. Előfordulnak azonban olyan esetek, amikor az interpolátor egységek limitálják a feldolgozást. Ilyenkor az emulált feldolgozás a nyerő, mivel a rendszer sokkal kiegyensúlyozottabban tud működni. Tekintve, hogy a mai 3D-s programok mennyire eltérő igényekkel rendelkeznek, a fix funkciós interpolátorok elhagyása nem tűnik rossz döntésnek. Az elgondolás számos esetben fog gyorsabb munkavégzéshez vezetni, azonban nem mehetünk el szó nélkül amellett, hogy alkalmanként, ha kismértékben is, de negatívan is befolyásolhatja a teljesítményt.
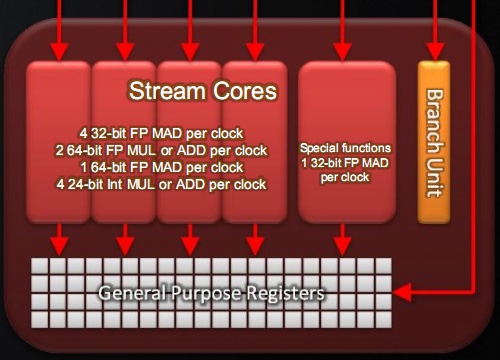
A 4 darab skalár és 1 darab speciális végrehajtó egységgel működő szuperskalár shader processzor okosabb lett az előző generációhoz viszonyítva. Ez szerencsére nem merül ki az DirectX 11-ben megkövetelt bitszintű utasítások és az IEEE754-2008-as lebegőpontos szabvány támogatásában. Az új ALU-k támogatják az FMA (Fused Multiply-Add) utasítást. Ennek a lebegőpontos számítások esetében van értelme, ugyanis a sokat használt MAD (Multiply-Add) instrukciónál pontosabb eredményt ad. Ez annak köszönhető, hogy az FMA esetében csak a végeredményt kell kerekíteni a lebegőpontos szabványnak megfelelően. A MAD utasítás a szorzást és az összeadást egymás után végzi, így a szorzással keletkezett részeredmény már eleve egy kerekített érték lesz. További újítás még, hogy a szuperskalár shader processzor képes egyszerre futtatni egy MUL és egy ADD utasítást, még akkor is, ha az utóbbi számítás az előbbi eredményétől függ.
A rendszer a dupla pontosság mellett változatlanul üzemel, azaz a szuperskalár shader processzor 4 darab skalár ALU-ja egy 64 bites MAD és két szintén 64 bites ADD, illetve MUL utasítást futtat. Emellett új instrukció a SAD (Sum of Absolute Differences), amelyet főleg multimédiás alkalmazásoknál lehet használni.
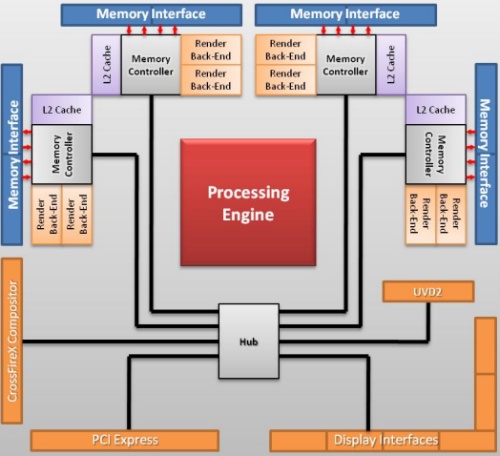
A memóriavezérlő továbbra is az RV770-ben megismert Control Hub, ami négy 64 bites csatornát üzemeltet. Ezekhez a csatornákhoz kapcsolódik egy-egy 128 kB kapacitású másodlagos gyorsítótár és két-két ROP blokk. Utóbbiból összesen nyolc darab van, ami 32 blending és 128 Z mintavételező egységet eredményez.
AA, AF és konklúzió
A Cypress az anizotropikus szűrés és az élsimítás területén komoly újításokat alkalmaz, melyek jelenleg az elérhető legjobb képminőséget nyújtják. Ez természetesen várható volt, hiszen ezen a fronton közel három éve nem fejlődtek a grafikus processzorok.

A rendszer teljesen új szögfüggetlen algoritmust használ az anizotropikus szűrésre, mely ráadásul gyorsabb is az előző generációs megoldáshoz viszonyítva. Sokkal nagyobb újdonság azonban a supersampling élsimítás ismételt bevezetése. Ez az eljárás eredményezi az ismert anti-aliasing technikák közül a legjobb képminőséget, hiszen a textúrákon is képes szűrni, ellenétben a jelenleg kedvelt multisampling eljárással. Probléma viszont, hogy hatalmas teljesítményigénnyel rendelkezik. Ettől függetlenül a Cypressben rengeteg erő van, így reális alternatíva az alkalmazása. További előny, hogy a manapság igencsak elterjedt deferred rendering motorokban is működik a technika. Fontos megjegyezni, hogy az AMD egyelőre nem engedélyezi a supersampling élsimítást a DirectX 10-es módban futó motorok esetén. Ez vélhetőleg annak köszönhető, hogy csak a DirectX 9 nem ad lehetőséget a szín- és a mélységinformációk kinyerésére, így a vörös oldal próbálja rákényszeríteni a fejlesztőket a shaderalapú anti-aliasing alkalmazásra, ami a sebesség és a képminőség szempontjából a legjobb megoldás.
DirectX 11 a gyakorlatban
Természetesen sokan kíváncsiak, hogy a DirectX 11 mit eredményez majd a gyakorlatban. Alapvetően minden a programozókon múlik, de a visszafelé kompatibilitás tulajdonképpen csak a fejlesztőnek előny, míg a felhasználónak esetenként inkább hátrány. Példaként érdemes felhozni a tesszellátort az Aliens vs. Predator című játékban. A motor csak DirectX 11-es módban engedélyezi a tesszellálást, aminek hiánya láthatóan gyengébb képminőséget eredményez a felületeken. Gyakorlatilag ez azért történik, mert a nem támogatott eljárások a gyengébb futtatási szinteken lekapcsolnak.

A képen látható a felület tesszellálás mellett és nélküle. Természetesen a régebbi rendszerekhez alkalmazható egyéb eljárás a jobb minőségért, de kérdés, hogy ezt hány fejlesztő építi majd be a rendszerbe. Láthatóan az AMD Tessellation SDK-t sem használják az öregedő Radeonok tesszellátorának életre keltésére, pedig az igen egyszerűen bevethető. Bár itt vélhetően az AMD érdekei is közrejátszanak, hiszen nekik fontos, hogy mindenki váltson DirectX 11-es kártyára.

Az SSAO és a HDAO különbségei
A compute shader alkalmazása mindenkinek kedvező lesz. A BattleForge már megkapta a DirectX 11-es frissítést, mely nemcsak az AMD szebb képminőséget nyújtó HDAO eljárását alkalmazza, hanem 25-30%-kal gyorsabban fut a DirectX 10.1-es módhoz viszonyítva.
Sok felvetés van a konzolokkal kapcsolatban is. A felhasználók körében általános az a nézet, hogy a PC-k háttérbe szorulása miatt a DirectX 9 marad az elterjedt, mert a konzolok erre épülnek. Ez az állítás viszont nem teljesen igaz, mert nem a PC-s API-t használják, hanem saját fejlesztési környezetük van. Számos olyan dolgot támogatnak a masinák, amit a DirectX 9 nem, és ez természetesen igaz fordítva is. A fejlesztő szempontjából az a fontos, hogy a PC-s közegnek szánt terméket is egy API-n keresztül készítse el. Itt jött a DirectX 10 problémája, hogy nem volt kompatibilis a régi platformokkal. Ahogy azt a cikkünk elején leírtuk a DirectX 11-nél már sokkal több futtatási szint van, és könnyebb fejlesztést tesz lehetővé. Ennek megfelelően a konzolok nem fognak beleszólni az új API terjedésébe.
Konklúzió
Az AMD legújabb, Cypress lapkájának felépítése nekünk kifejezetten tetszett. Számos ponton megújult a rendszer, és kimondottan a grafikai igényekhez tervezték. Még nagyobb a lelkesedésünk a DirectX 11 újításaival kapcsolatban. Az előzetesek alapján sejtettük, hogy a Microsoft nagyon jó munkát fog végezni, de az összes információ birtokában a kalapunkat is megemeljük a redmondi óriáscég előtt. Láthatóan a fejlesztők is lelkesek az API miatt, így reméljük, hogy az NVIDIA hamarosan bemutatja a Fermi kódnéven fejlesztett, következő generációs lapkáját. Ennek köszönhetően megindulhat majd az árverseny, ami vélhetően olcsó DirectX 11-es kártyákat eredményez majd.
Abu85


