Átgondolt vagy újragondolt stratégia?
Sokan várták már az NVIDIA Kepler architektúrájára épülő termékeket. Nos, a várakozás a mai napon véget ér, már ami a GK104-es kódnevű cGPU-t illeti, mely a GeForce GTX 680-as kártya alapja lett. A zöldek az új generáció startjával kicsit elcsúsztak, hiszen az AMD már mindhárom új generációs cGPU-ját bemutatta, de igazából még nincs veszve semmi, hiszen a TSMC 28 nm-es gyártókapacitása nem túl nagy, és alapvetően a gyártástechnológia is problémás, amit az NVIDIA is elismert.
A GK104-es lapka megjelenése több szempontból is történelmi pillanat az NVIDIA számára. Egyrészt a vállalat első 28 nm-es gyártástechnológián készülő termékéről van szó, másrészt a régóta várt Kepler architektúra is bevetésre került. Az új generáció azonban stratégiailag is tartalmaz meglepetéseket. A vállalat az elmúlt pár generáció során a méretes chipek híve volt, de összességében ez inkább nehézségnek bizonyult, mint előnynek, ami azt eredményezte, hogy közben az AMD a Sweet Spot stratégiával az elmúlt két generációban megépítette a leggyorsabb VGA-kat a Radeon HD 5970 és a Radeon HD 6990 személyében.
A fő gond nem is a nagy lapkák elvével van, sokkal inkább a kivitelezhetőséggel. A gyártástechnológia fejlődik, így a csíkszélesség csökkenésével jelentősen több tranzisztor építhető egy adott kiterjedésű lapkába. A probléma ott keletkezik, hogy a tranzisztorok bekapcsolásához szükséges energia már közel sem csökken a méretekkel egyenes arányban, ami egységnyi kiterjedés mellett a fogyasztás növekedéséhez vezet. Az óriási lapkák jövője tehát erősen kérdéses, ráadásul egy új gyártástechnológia bevezetésénél ez irtózatos kockázat is egyben. Felhozhatjuk példaként a két éve megjelent GF100-as lapkát, melyben az NVIDIA eleinte nem is aktiválta az összes beépített részegységet, mivel csak így fért bele a termék a megcélzott piacokon elfogadott fogyasztási határokba. Ez a PC-s VGA-k piacán 300 wattot, míg a HPC szerverekbe szánt termékek esetében 225 wattot jelent.
Az NVIDIA a felmerülő problémákat látva stratégiai döntést hozott. Egy 400-500 mm2 közé eső lapkával nyitni túlzottan kockázatos, így a biztonság kedvéért most a Sweet Spot stratégiával megegyező elvekre alapozott a vállalat. Ezt tökéletesen szemlélteti a GK104-es cGPU, mely 294 mm2-es kiterjedésű, vagyis tökéletesen megfelel a célnak. Ebből kettőt összekötve csúcs-VGA is építhető a későbbiekben, ami ráadásul nagy eséllyel veheti fel a versenyt az AMD-s konkurens ellen. Korábban az NVIDIA számtalan kompromisszummal szülte meg a GeForce GTX 590-et, mely végül nem is sikerült olyan jóra, hogy egyértelműen megverje a Radeon HD 6990-et.
A későbbiekben egy nagyobb GPU nem zárható ki, de először érdemes tapasztalatot gyűjteni az új gyártástechnológiáról. Az NVIDIA valószínűleg mérlegelte a helyzetet, és arra juthattak, hogy semmi szükség egy újabb, GF100-hoz hasonló szenvedésre, hiszen ebből a lapkából a javított verziónak felfogható GF110-es variáns lett értékelhető alternatíva, mely nagyjából háromnegyed évvel az előd után került piacra. A nagy GPU stratégiáját tehát nem feltétlen kell elvetni, de egy gyártástechnológiai váltás során nagyon magas a kockázata annak, hogy a termék nem lesz jó. Ez rosszabb esetben a fejlesztés törlését is jelentheti az útitervben. Abban biztosak vagyunk, hogy készül egy nagyobb, Kepler architektúrára épülő lapka, csak kérdéses a megjelenés ideje, illetve az is, hogy a fejlesztés során mennyire számított a játékokban való jó szereplés.

GK104 [+]
Fermi újratöltve?
A Kepler architektúrától sokan gyökeres változásokat vártak, látva, hogy az AMD teljesen új architektúrát fejlesztett. A rendszerről általánosan elmondhatjuk, hogy sokat fejlődött a Fermihez képest, de az alapokhoz az NVIDIA nem nyúlt. Ez a GPGPU-s számításokban érdekes lehet, hiszen a GCN architektúra gyorsítótár- és memóriahierarchiáját ennek rendelte alá az AMD. Ez a bonyolult általános számítások során a hatékony működés alapja lehet.
A Kepler ezen a ponton szinte változatlan, ami például ray-tracing vagy hasonló bonyolult számítások mellett nem biztos, hogy előnyös. Az általános felépítés alapján elmondható, hogy az AMD GCN architektúrája sokkal hatékonyabb komplex számítások esetén, ahol az algoritmus erősen épít az adatok megosztására, emellett a multiprecíziós SIMD motorokhoz rendelt, rendkívül méretes dedikált regiszterterületekkel a kontextusváltás is jóval gyorsabb. Ezt a részt a Fermi és lényegében a Kepler architektúra továbbra is mostohán kezeli, ugyanakkor mindez az egyszerűbb számításokban, amelyeket manapság a játékok zömében használnak, nem jelent hátrányt. Rövidtávon ennek a játékokban valószínűleg nem, vagy csak nagyon kicsi lesz a jelentősége, de az általános számításra kihegyezett, GPU erejét kamatoztató programokban már problémás lehet.
Jó hír, hogy változott a Fermihez képest az ütemezés. Ez korábban a rendszer legfájóbb pontja volt, ugyanis jelentősen rontotta az architektúra skálázhatóságát. Az előző generációk alapján általánosan elmondható, hogy a GF104 és a GF114 kódnevű lapkák képezték a termékskála optimális részét. A Fermi ütemezése azonban bonyolult volt, és ezzel rendkívül sok tranzisztort kellett rá elhasználni, ami a kisebb lapkák versenyképességét lerontotta. A GF106, GF116, GF108, GF118 és GF119 legyőzése abszolút nem volt nehéz ügy a rendkívül jól skálázható Radeonok számára, így logikus volt, hogy az NVIDIA ezen a ponton felülvizsgálja a rendszert. A Kepler esetében az utasítások dekódolása szoftveres rásegítést kap. Erről a driver valós idejű shader fordítója gondoskodik, mely ellátja a hardvert a szükséges információkkal, amellyel rengeteg tranzisztor spórolható meg. Az NVIDIA ezzel elmozdult a statikus ütemezés irányába, ami az Echelon projekt tanulmányából kiindulva nem mondható váratlan lépésnek.
A Kepler architektúra mélylélektana
A bevezető után itt az ideje ízekre szedni a 28 nm-es gyártástechnológiával készülő, GK104-es cGPU-t. A 3,54 milliárd tranzisztorból felépülő lapka sokban hasonlít tehát a Fermihez, már ami az alapokat illeti. A rendszerbe 8 darab streaming multiprocesszort sikerült beépíteni, amit az NVIDIA hangzatosan SMX-nek hív; lényegében ezek a modulok felelnek a Kepler képességeiért. A streaming multiprocesszorok felépítése rendkívül komplex: mindegyik ilyen egység 192 darab, úgynevezett CUDA magot tartalmaz két nagyobb csoportba rendezve, így az utasításszavak csoportonként 3 darab, 32 utas feldolgozón lesznek párhuzamosan végrehajtva. Mindegyik CUDA mag rendelkezik egy IEEE754-2008-as szabványnak megfelelő, 32 bites lebegőpontos végrehajtóval, melyek támogatják a MAD (Multiply-Add) és az FMA (Fused Multiply-Add) instrukciókat. A regiszterek szempontjából a Fermi köszön vissza, így a rendszer közös regiszterterületet használ egy streaming multiprocesszoron belül, melynek kapacitása 256 kB. A feldolgozók számának drasztikus növekedésével a feladatirányító egységek (dispatch) számát is növelni kellett, így már nyolc található egy-egy SMX modulban. Ezzel egyetemben a warp ütemezők száma is négyre nőtt.
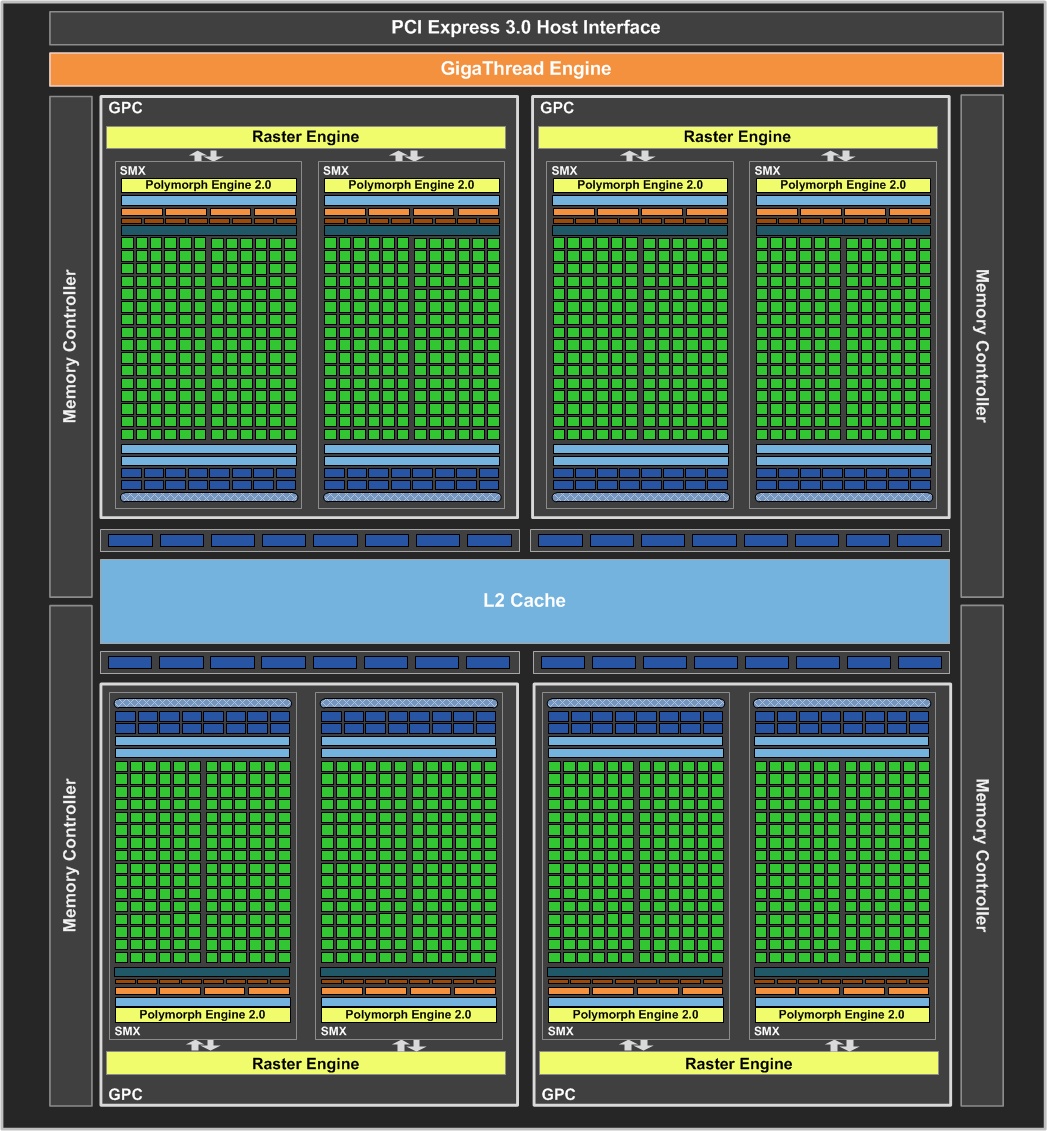
A GK104 logikai felépítése [+]
Az SMX modulon belül a két feldolgozócsoport 16-16 darab, a speciális funkciókért felelő egységet (SFU) kapott, a Kepler architektúrában ezek végzik a trigonometrikus és transzcendens utasítások mellett az interpoláció feladatát is. Utóbbi jelentős erősítésen esett át a Fermihez képest, ami kellett is, ugyanis így a teljes lapkát nézve már 256 interpolátorról van szó, szemben a GF100, GF104, GF110 és GF114 kódnevű GPU-k 64 darab egységével. Az interpoláció során érdemes megjegyezni, hogy az AMD emulációval dolgozik, ami a mai játékok rendkívül eltérő igényei mellett kiegyensúlyozottabb eredményeket ad. Az NVIDIA továbbra is a fixfunkciós interpolátorok mellett teszi le a voksát, de a számuk jelentős növelésével a Kepler is kiegyensúlyozottabban teljesít majd. Igazából mindkét elgondolás járható út, és egyaránt rendelkeznek előnyös és hátrányos hatásokkal. Az NVIDIA még az emuláláson is elgondolkodhat emellett, hiszen mostmár a shaderek oldaláról is elég erős lett a rendszer ehhez.

Streaming multiprocesszor, avagy SMX [+]
A GK104 a textúrázási képességek területén is belehúz. Az egyes streaming multiprocesszorok mostantól négy darab textúrázó blokkot tartalmaznak, melyekben egyenként négy textúracímző és textúraszűrő található, és ezekhez csatornánként négy mintavételező tartozik. Ez a fejlesztés szükséges lépés volt, hiszen a CUDA magok száma jelentősen nőtt a streaming multiprocesszorokon belül. Újítás még a textúrázási modell áttervezése. A Fermi esetében maximum 128 egyedi textúra volt beköthető egy shader kódon belül. Ebből a szempontból a Kepler változtat, és egymillió fölé emeli ezt az értéket. Itt persze meg kell jegyezni, hogy az egyedi textúrák 128-ra való limitálása a shader kódokban a DirectX 11 API sajátossága, vagyis ahhoz, hogy a Keplerhez bonyolultabb shader kódokat lehessen írni, egy kiterjesztés szükséges a Windows 8-ban megjelenő DirectX 11.1 API-n belül. Természetesen ugyanez szükséges az OpenGL oldaláról is.
Az előbbi bekezdésben részletezett technológiát az NVIDIA bindless textúrázásnak hívja. Itt érdemes megjegyezni, hogy az AMD is bevezetett egy hasonló megoldást a GCN architektúrára épülő termékekben, ahol az egyes CU-kban található skalár feldolgozók kiolvashatják az erőforrás állandókat, és ezzel vezérelhetik a textúrázást. Mindez elméletben végtelen mennyiségű egyedi textúra bekötésének lehetőségét jelentheti egy adott shader kódban. Sőt, az AMD még ennél is továbbment a Partially Resident Textures eljárással, mely lehetővé teszi a hardveres virtuális textúrázást (ismertebb néven megatextúrázást) és a hardveres textúra streaming algoritmusok kreálását.
Memóriahierarchia szempontjából a Kepler architektúra szinte teljesen a Fermit másolja. A GK104 egy 512 kB kapacitású, megosztott L2 gyorsítótárat alkalmaz, mely minden streaming multiprocesszor számára elérhető, és a CUDA magok írhatnak is bele. Maguk az SMX modulok 64 kB-os L1 gyorsítótárral rendelkeznek, mely a feladatnak megfelelően dinamikusan szétosztható egy 16 és egy 48 kB-os részre, illetve újítás, hogy mostantól 32-32 kB-os szeletelés is lehetséges, attól függően, hogy mekkora megosztott memóriát igényelnek a CUDA magok. Természetesen a grafikus feldolgozás során a DirectX 11 specifikációinak megfelelően kötelező minimum 32 kB-os helyi adatmegosztást (Local Data Share) alkalmazni. A megújult textúrázó csatornák természetesen most is külön gyorsítótárat kapnak.
Az NVIDIA a GK104 dupla pontosság melletti képességeiről nem beszélt. Egyrészt ez nem olyan fontos a GeForce által megcélzott piacon, másrészt a lapka ebből a szempontból nem éppen erős. Az SMX-eken belül egy 32 utas tömb fogható be dupla pontosságra, eközben pedig a modulon belüli további öt 32 utas tömb dolgozhat bármi máson. A dupla pontosság a tömb elméleti kapacitásának negyedével valósul meg. Ez összesítve a GK104 esetében lényegében 130 GFLOPS-ot jelent, ami tényleg nem sok. A konkurens Tahiti cGPU például 947 GFLOPS-os tempóra képes.
A memóriavezérlő tekintetében az NVIDIA továbbra is maradt a crossbarnál. A GK104 256 bites szélességű buszt használ, mely 64 bites csatornákra van szétosztva. Egy-egy csatornához két ROP-blokk tartozik. Utóbbiból összesen 8 darab van, ami 32 blending és 256 Z mintavételező egységet eredményez.
Tesszelláció és egyéb újdonságok
A tesszelláció az a terület, ahol az AMD és az NVIDIA gyökeresen eltérő megvalósításra épít. Ezt a GCN architektúrát elemző cikkünkben nagyon részletesen kiveséztük, így nem írnánk le újra mindent. A linkelt oldalra építve elmondhatjuk, hogy a Kepler esetében a vállalat továbbra is a brute force megvalósítás híve, ugyanakkor a zöldek is belátták, hogy a GF100 és GF110 esetében túlzásba vitték az egészet, nem kevés tranzisztort elpocsékolva. A tesszelláció ugyanis a DirectX 11-ben alkalmazott NoSplit megvalósítással számtalan gyermekbetegségben szenved, és borzalmasan pazarló is.
A GK104 esetében az NVIDIA továbbra is egy raszteres és egy úgynevezett PolyMorph részre vágja a hagyományos értelemben vett setup motort. Az előbbi egységből négy található a lapkában, azaz egy raszter motor két-két streaming multiprocesszor ellátásáról gondoskodik. Ezt a felállást a vállalat Graphics Processing Clusternek (GPC) keresztelte el a Ferminél, és nincs ez másképp a Kepler esetében sem. A raszter motor működése semmit sem változott. Az egység órajelenként továbbra is 8 pixelt képes feldolgozni, ami a teljes lapkára nézve 32 pixelt jelent. Ez egyensúlyban van a 32 blending egységgel is, azaz a GK104 végre ezen a ponton is kiegyensúlyozottá vált.
A streaming multiprocesszorokban található PolyMorph motor a geometriával kapcsolatos munkálatokat végzi. Mivel csökkent a SMX-ek száma a GF100 és GF110-hez képest, így a PolyMorph motorok száma is felére esett, azaz összesen 8 található a GK104-es lapkában. Az NVIDIA elmondta, hogy ezek fejlettebb PolyMorph motorok, így megkapták a 2.0-s jelzőt. Az erősen szeletelt, párhuzamosításra építő elgondolás azonban tipikusan gátat szab a komolyabb trükközéseknek, amelyekre az AMD például a GCN architektúrában bőszen épít. Valószínű, hogy csak a vertex re-use képességek fejlődtek, ahol a Fermi eleve nem volt túl acélos.
Összességében tehát nem várható előrelépés a GF100-hoz és GF110-hez viszonyítva a tesszellációs teljesítményben, de ahogy azt korábban már sokszor elemeztük, a korábbi két generáció csúcs GPU-i egyszerűen képtelenek voltak kamatoztatni a játékokban ezt a rendkívül tranzisztorpazarló brute force megvalósítást. Ebből a szempontból az NVIDIA jól döntött. Amíg az API-n belül nem kerülnek kigyomlálásra a tesszelláció problémái, addig felesleges a szükségesnél jobban erőltetni ezt a részt. Az egész tesszellálást ráadásul durván korlátozza, hogy a raszterizálás négyes pixelblokkokon zajlik, és ebből a szempontból a Kepler sem kivétel. Ezt a problémát semmivel nem lehet elkerülni, hacsak nem vesszük számításba a rejtett geometriák rajzoltatását, de eleve nincs értelme olyan dolgokat számolni, ami a végső képkockán nem jelenik meg, hiszen az a rendelkezésre álló erőforrás nagyfokú pazarlása, mindenféle képminőségbeli előny nélkül.
A GK104 dióhéjban
A DirectX 11.1-es és OpenGL 4.2-es grafikus API-t támogató GK104 először a GeForce GTX 680 névre keresztelt kártyán kap helyet. Az NVIDIA az új versenyzőnél egyetlen streaming multiprocesszort sem tilt le, így a termék 1536 darab CUDA maggal és 128 textúrázó csatornával rendelkezik. A 256 bites memóriabuszhoz 2 GB kapacitású, GDDR5 szabványú memória kapcsolódik. Itt érhető tetten az első meglepetés, ugyanis a memórialapkák 6 GHz-es effektív órajelen üzemelnek. A Fermi egyik nagy problémája a memóriavezérlő volt, mely egyszerűen instabilitáshoz vezetett 4,5 GHz környékén vagy fölötte. Az NVIDIA rálelt a probléma forrására, és mostantól magasabb órajelű lapkákra is képesek építeni, így innentől kezdve már csak a fogyasztás szempontjából kell mérlegelni a tervezőknek a beállítható órajelet.
A változások azonban az órajel szempontjából nem érnek véget. Az NVIDIA több év után úgy döntött, hogy a GK104 esetében eldobja a különálló mag- és shader órajelet. Ezzel a GK104 egységesen 1006 MHz-es magórajelen üzemel, melyhez tartozik egy GPU Boost szolgáltatás is, ami 1058 MHz-es úgynevezett átlagórajelet eredményez. A változás nagyon előnyös, ugyanis a magas shaderórajel elérése egyre nehézkesebbé vált, és a fogyasztásra sincs jó hatással, emellett a tranzisztorok szintjén is nagyon fontos az úgynevezett órajelcsúszások minimalizálása, ami magas órajel és több milliárd tranzisztor mellett borzalmasan nehezen kivitelezhető. A GPU Boost azonban egy érdekes képesség, ami magával vonja a fogyasztás limitálását is, vagyis végre az NVIDIA is stabil hardveres védelmet épített a rendszerbe a túlterhelés ellen.
A GPU Boost lényegében az AMD Radeon HD 6900-as sorozatban bemutatkozott PowerTune fordítottja. A GeForce GTX 680 TDP limitje lényegében maximálisra van állítva, ami a két darab hattűs PCI Express tápcsatlakozó következtében 225 wattot jelent. A rendszer mindig az alap magórajelen kezdi meg a működést, de ha a terhelés nem komoly mértékű és a GPU Boost belefér a fogyasztási keretbe, akkor a magórajel a terheléssel dinamikusan változik. Ez maximálisan +100 MHz-es emelést jelenthet az alapórajelhez képest. Az órajelváltás minimum 1 MHz-es mértékben valósulhat meg, azaz a GPU Boost mindig a terheléshez igazíthatja a magórajelet.
Érdekes, hogy az AMD PowerTune pont fordítva működik, vagyis van egy alapórajel, ami nem növekedhet, hanem csak csökkenhet a fogyasztás minimalizálása érdekében. Éppen ezért -20 és +20 százalék között változtatható a Radeonok TDP limitje, ami az egyes termékeken más értékeket jelent, de az eddigi gyakorlat azt mutatja, hogy az AMD a 0%-os beállítást igyekszik úgy megadni, hogy a magórajel a játékok alatt stabil legyen, és sose ugráljon. Ezt elsősorban azért alkalmazza így a vállalat, mert az órajelváltás az egyes képkockák számítása között túl nagy is lehet, ami esetleg egy apró akadáshoz vezethet. Ebből a szempontból az AMD szerint a legbiztosabb, ha alapértelmezésben stabil a magórajel, és ha a felhasználó inkább a fogyasztást részesítené előnyben, akkor nyugodtan eljátszhat a PowerTune csúszkájával. Az NVIDIA ezzel szemben a teljesítményt helyezi előtérbe. Érdemes azonban megjegyezni, hogy a GPU Boost órajelváltása nem túl nagy határok között mozog, így valószínű, hogy az egymás utáni képkockák számításában csak minimális különbségek lesznek.

Többmonitoros móka egyetlen GeForce GPU-val [+]
Fogyasztásra az NVIDIA 195 wattos értéket ad meg, ami egy átlagos terhelés melletti paraméter. Persze GPU Boosttal megtámogatva a rendszer meglehetősen tág határok között fogyaszthat, de a limit 225 wattban lett megszabva. Az új GPU egyébként a PCI Express 3.0-t is támogatja, ami nagyon jó, de ahogy a Radeonok esetében is megjegyeztük, játékok alatt ennek kvázi nincs jelentősége – mindenesetre a dobozra rá lehet írni. Sokkal érdekesebb újítás, hogy a referenciamodell hátlapján két darab dual-link DVI, egy 3 GHz-es HDMI 1.4a, illetve egy DisplayPort 1.2 HBR2 interfész kapott helyet. Ebből ugyan még nem következik semmi, de eláruljuk, hogy ez az első olyan egy GPU-t használó GeForce kártya, amelyik támogatja a Surround technológiát. Utóbbihoz eddig SLI konfiguráció kellett, de a GK104 már egymaga elbánik négy kijelzővel.
Extrák a Keplerben
Az NVIDIA a Kepler bemutatásával párhuzamosan több újdonságot is bevezet a driverben. A rendszer az anizotropikus szűrés szempontjából nem változik. A vállalat még mindig nem alkalmaz teljesen szögfüggetlen algoritmust, de ezt a játékokban egyszerűen lehetetlen kiszúrni, így ezen a ponton nem volt értelme fejleszteni. Változik viszont az élsimítás. Az eddigi módok mellett bemutatkozik egy TXAA nevű megoldás. Ez egy temporális mintavételezéssel dolgozó, MSAA-ra épülő algoritmus, ami az egyes képkockáknál máshonnan mintavételez. Hasonló az elv, mint amit anno az ATI vezetett be a Radeon X800 megjelenésével, csak azóta a technológia feledésbe merült, mivel a mai deferred rendert alkalmazó motorok már nem szívlelik az MSAA-t. Az NVIDIA éppen ezért nem is veti be a driverben a TXAA-t, hiszen úgysem működne egy driveres implementáció a játékok többségében, de a játékfejlesztőkkel együttműködnek, hogy támogassák a technológiát.



Nincs AA, 8xMSAA és TXAA [+]
Sokkal érdekesebb azonban az FXAA bevetése, mely a vállalat első, driverből aktiválható post-process élsimítása. Ez a már említett, MSAA-val nem kompatibilis, deferred rendert alkalmazó motorok miatt egyre sürgetőbb volt, hiszen az AMD már két generációval korábban reagált erre a problémára az MLAA-val. Az FXAA-ról egy korábbi hírben már részletesen írtunk, így a működést nem részleteznénk újból. A 300-as sorozatba tartozó GeForce driverbe épített FXAA gyakorlatilag minden DirectX és OpenGL API-ra épülő programmal kompatibilis, ami az algoritmus post-process jellege miatt nem meglepő. Természetesen az MLAA-hoz hasonlóan az FXAA is a motorba építve, extra információkkal segítve mutatja ki igazi erejét, így a driverbe épített megoldástól csodát nem lehet várni. Az algoritmus a végső képkocka alapján dönt az élsimításról, és ez túl kevés információ a tökéletes eredményhez. Mindenesetre a semminél így is több, hiszen a driveres MSAA-t számos játékban nem lehet alkalmazni, ráadásul ezek jó része semmilyen beépített élsimítást nem kínál, és ilyenkor a driverből aktiválható post-process megoldások sokat segíthetnek.


Nincs AA és FXAA [+]
Újszerű vertikális szinkron
Az NVIDIA a Keplerrel bevezet egy újszerű vertikális szinkront, mely az Adaptive Vsync nevet viseli. A vertikális szinkron lényegét valószínűleg minden olvasónk ismeri, de röviden azért taglaljuk, hogy miről is van szó. Az egész rendszer azt a célt szolgálja, hogy a kijelzőn megjelenő képkocka ne törjön meg. A monitorok állandó képfrissítéssel dolgoznak, miközben a képkockák számítása a program futtatása során közel sem állandó. A probléma ott keletkezik, amikor a frame bufferben található információ a kijelző frissítése közben változik, ugyanis ilyenkor a megjelenítő felső részében a régi, míg az alsó részében az új képkocka információja látható valahol egy töréssel a képen, ami esetenként igencsak zavaró lehet. Erre találták ki a vertikális szinkront, ami összehangolja a rendszer működését, így a kijelzőre kikerült tartalom mindig egy képkockáról származik. Ezzel addig a pontig nincs is probléma, amíg a program futtatása során a képkockák számításának sebessége magasabb a kijelző képfrissítésénél. Előfordulhat azonban, hogy a számítás során időnként nem lesz kész időre az új képkocka, ekkor a monitor kénytelen újból kirakni az előzőt. Ez konkrétan azt jelenti, hogy egy képkocka duplaannyi időt töltött a monitoron, mint kellett volna, és ez esetleg egy apró akadást jelenthet. Ez ellen jól lehet védekezni a tripla puffereléssel, ami a frame buffer mellé két back buffert is bevezet, így a képkockák számítása gyorsabb lehet. Ettől függetlenül még így is előfordulhat az előbb részletezett helyzet.
Az Adaptive Vsync lényegében erre jelent némi gyógyírt. A technológia mindaddig aktívnak tekinti a vertikális szinkront, amíg a képkockák számítása gyorsabb a kijelző frissítésénél. Ha ez az állapot megszűnik, akkor a vertikális szinkront azonnal kikapcsolja a rendszer, így a frame buffer, illetve a back buffer megcserélésénél a rendszer nem vár a kijelző frissítésére. Az Adaptive Vsync alkalmazásával nagyobb az esély arra, hogy ugyanaz a képkocka nem kerül ki a kijelzőre kétszer, ezzel együtt azonban a vertikális szinkron inaktiválása azt is jelenti, hogy a kikerülő képkocka megtörhet, ami természetesen hátrány, hiszen a vertikális szinkront pont azért alkalmazná a felhasználó, hogy a képtörést elkerülje. Ezenkívül az Adaptive Vsync az apró akadásokat nem tünteti el, csak csökkenti azokat, mivel ezek nem a vertikális szinkrontól következnek be, hanem pont a teljesítmény visszaesésétől, amire a grafikai részletesség csökkentésén kívül semmilyen gyógyír nincs.
Valójában legyen szó Adaptive Vsyncről vagy hagyományos vertikális szinkronról, rég rossz, ha a program futtatási sebessége a kijelző frissítése alatt van. Ettől függetlenül az Adaptive Vsync használható opció lehet, bár a tripla pufferelés melletti hagyományos vertikális szinkron továbbra is a legátfogóbb megoldás a problémára, noha ezt nem mindegyik program támogatja. Szintén érdemes kiemelni, hogy a WDDM 1.1-es felület a DirectX 10-től kezdve a vertikális szinkron vezérlését a fejlesztők kezébe adta, így a driveres Vsync megoldások főleg a DirectX 9 és az OpenGL API-k mellett működnek jól. A DirectX 10 és 11 esetében némi hackkel meg lehet kerülni a WDDM 1.1-es felület korlátozásait, de ez nem várt eredményeket is szülhet az adott motor működésében.
Bemutatkozik az NVENC
Multimédiás tudásban a Kepler nem lépett előre a Fermihez képest, így a videók gyorsítását továbbra is ugyanaz a PureVideo felület végzi. Ez azonban kiegészült az NVENC technológiával, ami lényegében a H.264-es videók transzkódolását gyorsítja fel. Az egész rendszer hasonló céllal született meg, mint az Intel Quick Sync Video vagy az AMD Video Codec Engine, ugyanis maga a transzkódolás tipikusan jól párhuzamosítható folyamat, de az entropy encoding algoritmus kivétel ezalól, így ezt megéri egy célhardverre bízni. Az NVENC motor 4096x4096 pixeles anyagokkal is megbirkózik, emellett támogatja az MVC-t is, ami a sztereó 3D-s videók esetében fontos szempont.
Az NVENC kihasználásához az NVIDIA a legújabb Cyberlink MediaEspresso programot ajánlja, de a vállalat a többi céggel is együttműködik a támogatással kapcsolatban. Általánosan elmondható, hogy a multimédiás programok fejlesztői tipikusan vevők az újdonságokra, így ebből a szempontból az új multimédiás képességek kihasználásával nem igazán szokott probléma lenni.
A GeForce GTX 680
Az előző oldalakon leírt elméleti ismertető után most evezzünk kicsit tovább, azaz jöjjön maga a GeForce GTX 680!

[+]
A GTX 680 külseje az előző generáció kissé finomított vonásait viszi tovább: a fekete műanyagburkolat hol matt, hol pedig tükröződő felületet kapott. A kártya a leghosszabb pontján 25,5 centiméter, ez a GTX 580-nál 1,5 cm-rel, míg a Radeon HD 7970-nél 2,5 centiméterrel rövidebb méretet jelent.

[+]
Ami talán sokaknak azonnal feltűnhet, az a kártya oldalán található új GeForce logó, vagy inkább felirat. A korábbi kisebb és valamivel visszafogottabb verziót egy határozottabb, de egyszerűbb, zöld színű GEFORCE GTX jelölés vette át. További érdekesség a tápcsatlakozók rendhagyónak nevezhető elhelyezése, melyek emeletes elrendezést kaptak.

Véleményünk szerint külsőre meglehetősen tetszetősre sikerült az NVIDIA ezen referencia dizájnja.


[+]
A műanyagburkolat eltávolítása után elénk tárul a hűtés, amely egy PWM-es légkavaróból, valamint egy méretes alumíniumbordából áll. Ezen felül a már korábban bevett gyakorlat szerint egy fekete fémlap fedi le a nyák nagyobb részét, mely a memóriák és a tápellátás hűtéséért felel.


[+]
A borda két részből áll össze: a függőleges lamellákat tartalmazó felső szekció alatt egy rézbetétes rész kapott helyet, melyben a hő hatékonyabb elosztása érdekében hőcsövek kígyóznak.


[+]
A különböző fémek eltávolítása után megpillanthatjuk a csupasz NYÁK-ot, ahol elsőként, mint mindig, most is a GPU felé vettük az irányt.

[+]
Ahogy az előző oldalakon már leírtuk, a GK104 kódjelű egység 294 mm2 területű, amely az NVIDIA eddigi mércéjével nézve kifejezetten kicsinek számít. Viszonyításképpen a GF110 520 mm2, míg a közvetlen konkurens AMD Tahiti 365 mm2 – utóbbi 24%-kal nagyobb értéket jelent. Mindez a fogyasztás mellett a gyártási költségekre is jótékony hatással lehet.
A GPU körül szokás szerint a memóriák kaptak helyet, melyek 256 bites buszon keresztül csatlakoznak a központi egységhez. Ugyan a fotókon nem kivehető a GDDR5-ös chipekre szitázott felirat, de azok ebben az esetben is a Hynix műhelyéből származnak. A H5GQ2H24MFR-R0C típusjelzésű chipek papíron 6 GHz-es effektív sebességre képesek 1,6 voltos feszültség mellett. Az egyenként 2 gigabit (256 MB) kapacitású egységekből nyolc darab került a NYÁK-ra, amely így összesen 2 GB memóriát jelent.

[+]
A tápellátás meglehetősen egyszerű, vagy inkább fogalmazzunk úgy, hogy klasszikus felépítésű. A közelmúltban debütált, legújabb generációs kártyákon látott DrMOS-hoz vagy DirectFET-hez hasonló komponenst nem láthatunk. Egy fázis két MOSFET-ből és egy vezérlőchipből épül fel, melyekből összesen négy található a referencia GTX 680-on, bár a NYÁK jól láthatóan öt darabra lett tervezve. Ezek vezérléséért a hátoldalon található, Richtek RT8802A típusú chip felel. A kép jobb felső sarkában látható a két hattűs PCI Express tápcsatlakozó, mely a slotból felvehető 75 watt mellé még további 150 wattot képes biztosítani a VGA-nak, így összesen 225 wattból tud gazdálkodni.

Ahogy már utaltunk rá, a hátlap hozott némi változást a korábbi GeForce szériáknál látottakhoz képest. Nekünk első pillantásra a Radeon HD 5800-as széria villant be róla, melynek eléggé hasonló volt a kiosztása. Érdekesség, hogy míg az AMD épp idén tért át az eddig csak az NVIDIA által alkalmazott hátlapi kiosztásra, ahol egy teljes hátlapi helyet kapott a meleg levegő távozására kialkított rácsozat, addig az NVIDIA most pont a másik irányba indult el. A GTX 680 egy normál méretű DisplayPort 1.2 HBR2 csatolóval nyit, mellé került a 3 GHz-es HDMI 1.4a. Ezután a dual-link DVI-I port jön, mely felett egy szintén dual-link DVI-D helyezkedik el. Ezen négy kimenet segítségével hajthatunk meg akár négy megjelenítőt is egyazon időben. A bordáról leváló meleg levegő nagy része az itt található rácson keresztül távozik, bár a kártya oldalán az SLI híd alatt még található egy kisebb rácsozott rész, ami minden bizonnyal szintén hasonló célt szolgál.

[+]
Tesztkonfig, fogyasztás, tuning, specifikációk

GTX 560 Ti, GTX 570, GTX 680, HD 7970, HD 7870 [+]
A főszereplő mellé az összes, előző generáció felsőkategóriájában található GeForce kártyát beválogattuk. Ez név szerint a GTX 570, 580 és 590 VGA-kat jelenti. A konkurencia oldaláról az idén megjelent 7900-as és 7800-as széria tagjai kerültek be a meccsbe, és mivel épp kéznél volt még a HD 6970 is, így azt sem hagytuk ki a megmérettetésből.
| Videokártyák | NVIDIA GeForce GTX 680 2048 MB (Geforce driver 300.99) ASUS GeForce GTX 590 3072 MB (Geforce driver 296.10) ASUS GeForce GTX 580 1536 MB (Geforce driver 296.10) NVIDIA GeForce GTX 570 1280 MB (Geforce driver 296.10) AMD Radeon HD 7970 3072 MB (Catalyst 8.950.5.0) Sapphire Radeon HD 7950 3072 MB (Catalyst 8.950.5.0) AMD Radeon HD 7870 2048 MB (Catalyst 8.950.5.0) AMD Radeon HD 7850 2048 MB (Catalyst 8.950.5.0) ASUS Radeon HD 6970 DirectCU II 2048 MB (Catalyst 8.950.5.0) |
|---|---|
| Processzor | Core i7-2600K (3,40 GHz) – túlhajtva 4,2 GHz-en EIST / C1E / C-state kikapcsolva; Turbo Boost kikapcsolva |
| Alaplap |
MSI P67A-GD65 (BIOS: 1.C) – Intel P67 chipset |
| Memória |
G.Skill RipjawsX 16 GB (4 x 4 GB) DDR3-1866 F3-14900CL9Q-16GBXL |
| Háttértárak | Intel SSD 510 250 GB SSDSC2MH250A2 (SATA 6 Gbps) Seagate Barracuda 7200.12 500 GB (SATA, 7200 rpm, 16 MB cache) |
| Tápegység | Cooler Master Silent Pro M600 – 600 watt |
| Monitor | Samsung Syncmaster 305T Plus (30") |
| Operációs rendszer | Windows 7 Ultimate 64 bit |
Csúcskategóriás kártyákról lévén szó úgy döntöttünk, hogy az i7-2600K processzorunk órajelét egy egészséges tuning keretein belül 4,2 GHz-re emeljük, ami mellé 16 GB memóriánk üzemi órajelét 1866 MHz-re állítottuk be. A GTX 680-hoz az NVIDA-tól kapott 300.99 verziójú drivert, míg a többi GeForce kártyához a legújabb publikus 296.10 jelölésű csomagot telepítettük fel. A Radeon kártyák esetében a HD 7800-as tesztünkben már látott, legfrissebb 8.950.5.0 verziószámú Catalysttal mért eredmények kerültek be a tesztbe. A játékokat a tesztben szereplő kártyákban lapuló számítási teljesítmény miatt 1920x1200-as és 2560x1600-as felbontásban, maximális vagy ahhoz közeli képminőségi beállítások mellett teszteltük. A meghajtóprogramokban a képminőségi beállításokat az NVIDIA videokártyáin „legjobb minőség”-re, a Radeonokon pedig a legszebbre állítottuk. Az anizotropikus szűrést, ha a játék lehetőséget adott rá, akkor 16x-osra kapcsoltuk. Az élsimítást alkalmazásvezéreltre állítottuk. A „Catalyst AI”-t alapállapotban hagytuk.
Játékok
- Batman: Arkham City
- Battlefield 3
- Crysis Warhead
- Deus Ex: Human Revolution
- DiRT 3
- F1 2011
- Metro 2033
- Total War: Shogun 2
- Aliens vs. Predator
A könnyebb és pontosabb mérés, valamint összevetés érdekében a Crysis Warheadnél a benchmark toolt használtuk, ahogyan a Total War: Shogun 2, Metro 2033, Batman: Arkham City, DiRT 3 és F1 2011 esetében is. A Battlefield 3-nál a Going Hunting című küldetés első perceit mértük le FRAPS-szel, míg a Deus Ex esetében a játék elején található demót vizsgáltuk hasonló módon. Az Aliens vs. Predatornál szintén FRAPS-szet használtunk. Korábban észrevettük, hogy a Metro 2033 sokszor hibásan méri a minimum fps-t, ezért itt is a FRAPS-et alkalmaztuk a lehető legpontosabb eredmények érdekében.
A fogyasztást egy konnektorba dugható, digitális VOLTCRAFT Energy Check 3000 készülékkel vizsgáltuk. A grafikonon az egyes videokártyákkal kiegészített rendszerek fogyasztása látható alaplappal, processzorral, táppal és a többi alkatrésszel együtt, de természetesen a monitor nélkül. A méréseket a Metro 2033 benchmarkja alatt mértük, mely 1920x1200-as felbontásban került lefuttatásra. Játékkal terhelt mérés közben meglehetősen sűrűn és gyorsan ingadoznak az értékek, ezért ide egy olyan értéket próbáltunk regisztrálni, mely a legtöbbször villant fel az eszköz kijelzőjén, ergo nem a csúcsértéket jegyeztük fel.
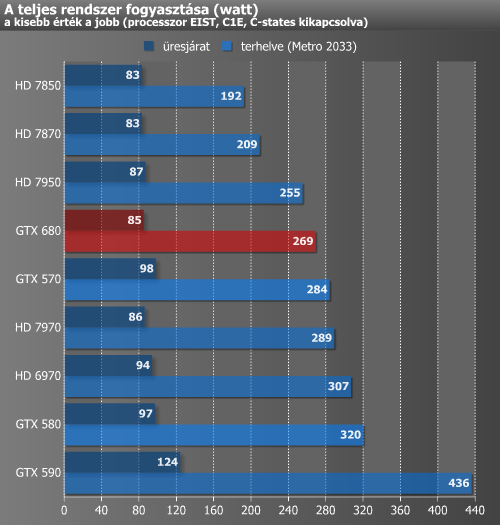
Üresjáratban fogyasztás terén az újdonság a 7000-es Radeonok értékét hozza, ami egyben azt is jelenti, hogy több mint 10 wattal kér kevesebbet egy GPU-s elődjeinél. Terhelésnél már nem ilyen egyszerű a felállás. A GTX 580-hoz képest itt durván 50 wattal fogyaszt kevesebbet a főszereplő, de még a GTX 570-nél is alacsonyabb értéket produkál. A konkurenciához képest is jól áll a 680, hisz a HD 7970-nél 20 wattal kevesebbel éri be, míg a HD 7950-nél nagyjából 14 wattal nagyobb az étvágya.
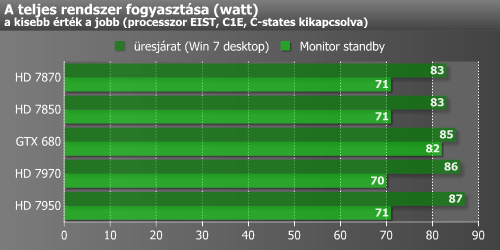
Az AMD GCN mikroarchitektúrás kártyák egyik újítása volt a ZeroCore Power nevű szolgáltatás, amely hosszú üresjárat esetén képes az adott kártya fogyasztását minimális szintre csökkenteni. Mindez akkor következik be, ha a számítógépen az operációs rendszer készenlétbe (stand-by) helyezi a megjelenítőt. Ebben az esetben a kártyán található ventilátor (vagy ventilátorok) leáll, és a termék fogyasztása 2-3 watt körüli értékre csökken. Ugyan az NVIDIA a dokumentációkban nem utalt hasonló technológia jelenlétére, de mi azért tettünk egy próbát. Ahogy a fenti eredményekből látszik, a GTX 680 esetében nem működik hasonló funkció, ergo a ventilátor nem kapcsolt le, és a fogyasztás sem csökkent olyan mértékben, mint a HD 7000-es kártyák esetében.
Szokás szerint megvizsgáltuk a GPU hőmérsékletét és az ahhoz tartozó ventilátor-fordulatszámot is.
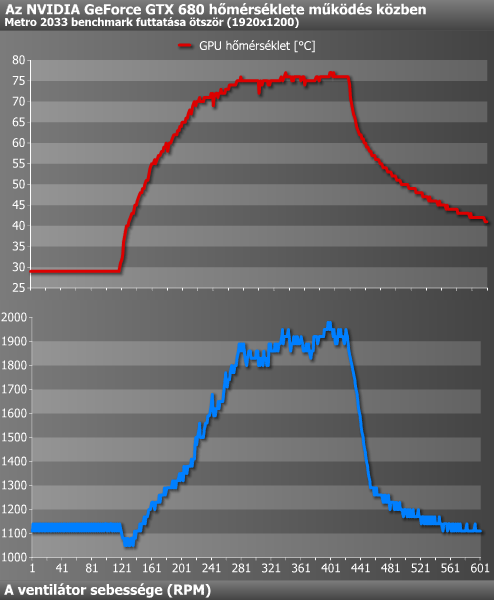
GTX 680
A mérést egy nagyjából 20 °C hőmérsékletű helyiségben végeztük, miközben a konfiguráció egy asztalon volt összeállítva. Üresjáratban ez a kártya is viszonylag csendes volt, bár közelebbről némi egyenletes motorzajt itt is hallottunk, de ezt nem neveznénk zavarónak. Terhelve természetesen már jobban bepörgött a légkavaró, de még ekkor sem volt vészes az általa generált zaj. A közelmúltban hallott kártyák alapján ezen a téren valamivel a HD 7870 fölé helyeznénk a GTX 680-at, ami egyben azt is jelenti, hogy a referencia HD 7970-nél halkabb a kártya.
Tuninggal
A tuning most sem maradhatott, és nem is maradt ki repertoárunkból. Ez a Keplerrel némiképp változott, hisz a korábban már említett GPU Boost beúszott a képbe. Az NVIDIA elmondása szerint ezt a fajta turbót hivatalosan nem lehet kikapcsolni, de nem kell megijednünk ettől. Alaphelyzetben a Boost 53 MHz-et képes rápakolni a GTX 680 GPU órajelére (+5%), ami ugyan nem sok, de a semminél mindenképpen több. Tuning esetén a gyárilag megszabott órajelskálát feljebb tolhatjuk egy általunk beállított értékkel, amivel a GPU Boost órajele is kitolódik. A kísérlethez az EVGA PrecisionX egyik beta verzióját adta az NVIDIA. Első körben a fogyasztási limitet kellett kitolnunk, amit a maximális 132%-ra állítottunk be. Ezután egy rövidebb próbálkozássorozatot követően +150 MHz-en állapodtunk meg a GPU órajelét illetően. Ezen az értéken még stabilnak bizonyult a kártya. A memóriákra +300 MHz-et tudtunk rápakolni úgy, hogy még nem láttunk anomáliákat a monitoron. Az eredményeket elég jónak nevezhetjük, hisz a GPU-ra 15, míg a memóriákra 20 százaléknyi pluszt tehettünk büntetlenül.
| VGA megnevezése | GeForce GTX 680 |
GeForce GTX 580 |
GeForce GTX 570 |
GeForce GTX 590 |
Radeon HD 7970 |
Radeon HD 7950 |
|---|---|---|---|---|---|---|
| Kódnév | GK104 | GF110 | Dual GF110 | Tahiti XT | Tahiti Pro | |
| Gyártástechnológia | 28 nm (TSMC) | 40 nm (TSMC) | 28 nm (TSMC) | |||
| Mikroarchitektúra | Kepler | Fermi | GCN | |||
| Tranzisztorok száma | 3,54 milliárd | ~3 milliárd | 2 x ~3 milliárd | 4,31 milliárd | ||
| GPU lapka mérete | 294 mm2 | 520 mm2 | 2 x 520 mm2 | 365 mm2 | ||
| GPU/Shader v. Turbo órajele | 1006 MHz T: 1058 MHz |
772 MHz S: 1544 MHz |
732 MHz S: 1464 MHz |
607 MHz S: 1215 MHz |
925 MHz | 800 MHz |
| GPU/shader órajele üresjáratban | 324 MHz | 51 MHz 101 MHz |
300 MHz | |||
| Shader processzorok típusa | stream | multiprecíziós vektor | ||||
| Számolóegységek száma | 1536 | 512 | 480 | 2 x 512 | 2048 | 1792 |
| Textúrázók száma | 128 textúracímző és -szűrő |
64 textúracímző és -szűrő |
60 textúracímző és -szűrő |
2 x 64 textúracímző és -szűrő |
128 textúracímző és -szűrő |
112 textúracímző és -szűrő |
| ROP egységek száma | 8 blokk (32) | 12 blokk (48) | 10 blokk (40) | 2 x 12 blokk (2 x 48) |
8 blokk (32) | |
| Memória mérete | 2048 MB | 1536 MB | 1280 MB | 3072 MB | 3072 MB | |
| Memóriavezérlő | 256 bites crossbar | 384 bites crossbar | 320 bites crossbar | 2 x 384 bites crossbar | 384 bites hubvezérelt | |
| Memória órajele terhelve | 1502 MHz (GDDR5) | 1002 MHz (GDDR5) | 950 MHz (GDDR5) | 850 MHz (GDDR5) | 1375 MHz (GDDR5) | 1250 MHz (GDDR5) |
| Üresjáratban | 162 MHz | 67 MHz | 150 MHz | |||
| Max. memória-sávszélesség | 192 260 MB/s | 192 400 MB/s | 152 000 MB/s | 2 x 163 200 MB/s | 264 000 MB/s | 240 000 MB/s |
| Támogatott DirectX | 11.1 | 11 | 11.1 | |||
| Dedikált HD transzkódoló | NVENC | nincs | VCE | |||
| HD képi anyagok lejátszásának hardveres támogatása | Purevideo HD (VP4) | AVIVO HD (UVD 3) | ||||
| Hivatalos TDP | 195 watt | 244 watt | 225 watt | 365 watt | 250 watt | 200 watt |
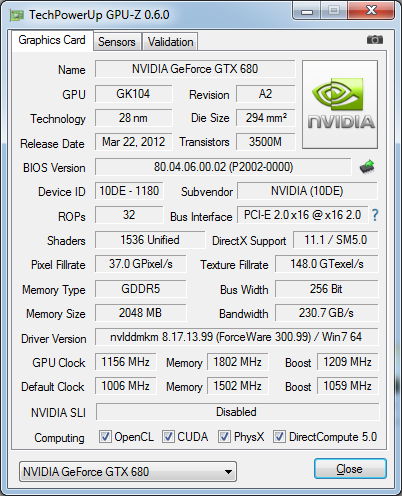
Crysis Warhead, DiRT 3, Shogun 2



Crysis Warhead alatt a GTX 680 nagyjából 20%-kal gyorsabb a GTX 580-nál, de a HD 7970-től már kissé lemarad. DiRT 3-ban 30-35%-os gyorsulást láttunk a közvetlen elődhöz mérten, amivel már a HD 7970-et is sikerült átugrani. Meglátásunk szerint itt a Kepler a teljes sebességű FP16-os textúraszűréssel szedte össze az előnyét, mely a GF110 óta jelen van, de mostmár a számítási teljesítmény is a Radeonok szintjén mozog. A Shogun 2 érdekes képet festett, hisz míg 1920x1200-ban le tudta lépni a GTX 680 a HD 7970-et, addig 2560x1600-ban szinte pontosan ugyanazt produkálta, mint a konkurencia.
Metro 2033, AVP, Deus Ex

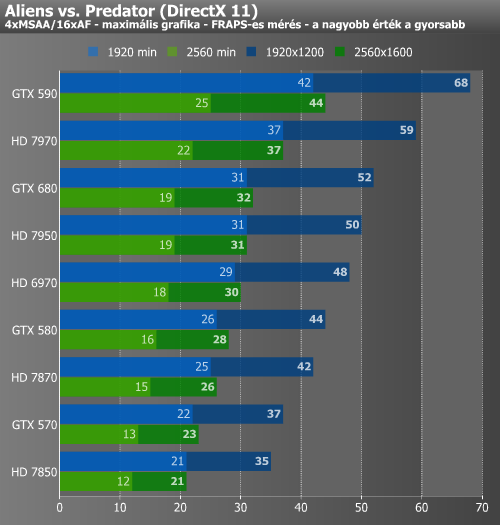

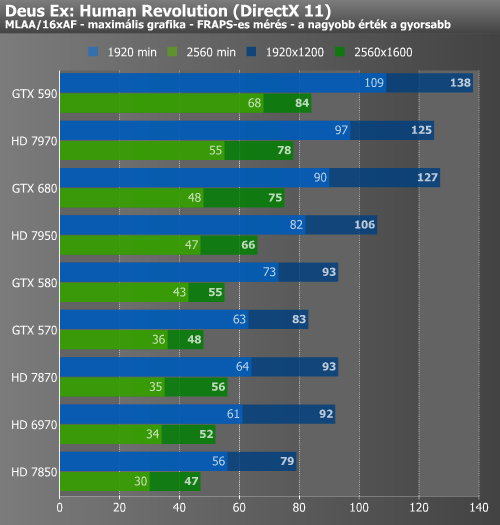
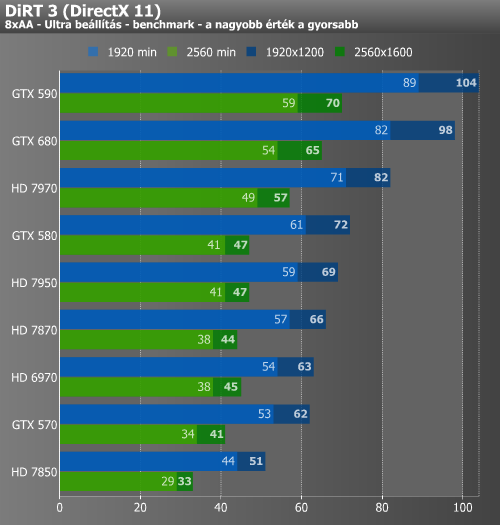
Az elsősorban "optimalizálatlanságáról" híres Metro 2033 alatt a GTX 680 szinte pontosan a HD 7950 eredményeit hozta. Ez a játék amellett, hogy nem jól optimalizált, még olyan komplex post-process számításokat is végez, mint a diffuse DOF (Depth of Field). Ez az a pont, amiről a cikkünk elején beszéltünk. A GCN architektúra a bonyolult számításokat könnyedebben kezeli, emellett fontos, hogy a Tahiti-alapú kártyáknál nagyobb memória-sávszélesség áll rendelkezésre.
Az AVP esetében eléggé hasonló kép fogadott minket. Hasonlóan a Metro 2033-hoz, a játékban alkalmazott advanced shadow sampling algoritmus meglehetősen komplex shadert futtat, ami a komplex feladatokra kihegyezett GCN architektúrán hatékonyabb, noha ez ebben az esetben kisebb előnnyel jár, mivel kevésbé érzékeny a memória-sávszélességre, mint a post-process effektek általában. A Deus Ex érdekes eredményeket adott, hisz míg átlagértékekben tudta hozni a HD 7970 szintjét a GTX 680, addig a minimumokban elmaradt tőle.
Batman, Battlefield 3, F1 2011




A GeForce-ok pályájának számító Batman: Arkham City alatt tarolt a GTX 680, amivel minimum értékekben még a GTX 590-et is maga mögé utasította. A Battlefield 3 ismételten csak tetszett az új jövevénynek, itt a HD 7970 elé került, valamint eléggé elhúzott az előd GTX 580-tól. F1 2011 alatt szintén előnyös a teljes sebességű FP16-os textúraszűrés, de ez a program nem értékeli annyira, noha a megnövelt számítási teljesítmény itt is megteszi hatását a Fermihez viszonyítva. Itt elég szoros volt a GTX 680 és a HD 7970 csatája: 1920x1200-ban a Kepler volt a jobb egy picivel, 2560x1600-ban a GCN-es Tahiti.
ComputeMark, LuxMark, konvertálás
Januártól két általános számítási feladatokat tartalmazó benchmark is bekerült méréseink közé. Mivel félig-meddig szintetikus tesztekről van szó, túl messzemenő következtetéseket szerintünk nem érdemes levonni ezek eredményeiből.


A ComputeMark egyszerűbb DirectCompute shaderekkel operál, melyekkel főleg a játékok alatt lehet találkozni. Ezen a ponton a Kepler nagyjából olyan szinten teljesít, mint ami elméleti számítási teljesítménye alapján elvárható. A Luxmark az egyik legelterjedtebb benchmark a ray-tracing tesztelésére. Ahogy a cikk elején is említettük, a Kepler ezen a ponton nem sokat lépett előre a Fermihez képest, sőt... Valószínűleg a gyenge szereplésből a kezdetleges támogatás is kiveszi a részét, de az NVIDIA által alkalmazott gyorsítótár- és memóriahierarchia nem kedveli annyira a komplex számításokat, mint az AMD GCN architektúrája.

Végül egy mérés erejéig kipróbáltuk az NVENC enkódolót is. Rendszerünk ennek segítségével szinte pontosan feleannyi idő alatt végzett a feladattal, mint amennyire a 4,2 GHz-re húzott négymagos Sandy Bridge processzorunknak volt szüksége. Az NVENC alatt 130 wattos fogyasztást mértünk, míg amikor a CPU számolt, 180 wattot mutatott a mérőeszköz. Ennek fényében elmondhatjuk, hogy még egy izmosabb CPU-hoz képest is meglehetősen hatékony a megoldás.
Összegzés, értékelés

Az összesített eredményeket szemlélve megállapíthatjuk, hogy a minimum és átlag képkockaszámot figyelembe véve a GTX 680 majdnem 30%-kal teljesíti túl a közvetlen előd GTX 580-at, ami már elég szép előrelépés. A közvetlen konkurens HD 7970-hez képest szűk 3% az előny. Ahogy a különböző játékokban megfigyelhető, a GTX 680 egyelőre nem tudta minden esetben maga mögé utasítani a HD 7970-et. Főleg magasabb, 2560x1600-as felbontásban és minimum értékekben jobb bizonyos helyeken a konkurens, ami szerintük sok esetben a jóval magasabb memória-sávszélességnek köszönhető. Mindenesetre jelenleg még így is az első helyen áll a GTX 680 az egyetlen GPU-s VGA-k versenyében.

A teljesítmény / fogyasztás mutatót tekintve a GTX 680 szintén átvette a vezetést. A HD 7970-hez képest kb. 10% az előnye, míg az előd GTX 580-hoz képest már több mint 50%. Ahogy már korábban is hangsúlyoztuk, az itt mutatott eredményében kétségkívül igen nagy szerepe van a 28 nm-es csíkszélességnek. Jól látható, hogy az aktuális legkisebb csíkszélességre épülő GPU-val szerelt kártyák gyakorlatilag egy külön ligát alkotnak.
Összefoglalva a látottakat elmondhatjuk, hogy GeForce GTX 680 bizony egy igencsak jól sikerült termék. Grafikus teljesítményben tisztességes az előnye a 2010 decemberében megjelent GTX 580-hoz képest, valamint fogyasztása is jóval alacsonyabb annál. Külön örülünk annak, hogy az NVIDIA végre nem egy góliát méretű GPU-val próbálta becserkészni ezt a pozíciót – ez egyelőre jó döntésnek bizonyult.

[+]
A teljesítmény növelése, valamint a fogyasztás csökkentése mellett még néhány hasznos új funkciót is kapunk a kártya mellé. A némileg a CPU-k turbójára hajazó GPU Boost képes teljesen kiaknázni a rendelkezése álló TDP keretet, bár egyelőre a maximális növekedés alapesetben nem lehet több, mint 5%. Az Adaptive Vsync és a FXAA szintén hasznos lehet bizonyos szituációkban, valamint ne feledkezzünk meg az NVENC-ről, ami már nálunk is bizonyított. Ezeken felül végre már egyetlen GeForce kártya is képes 3 vagy akár 4 megjelenítő egyidejű meghajtására. Talán az egyetlen funkció, amit igazán hiányoltunk a GTX 680 esetében, az az AMD által a közelmúltban bevezetett ZeroCore-hoz hasonló, energiatakarékossági technológia.

GTX 680 SLI – egyelőre nem volt hozzá szerencsénk [+]
Az GeForce GTX 680 egy csúcskategóriás termék, amit elsősorban a kompromisszumokat nem kedvelő játékosoknak szán az NVIDIA. Ennek természetesen meg kell fizetni az árát, ugyanis a kártya ajánlott fogyasztói ára 150 000 forint, ami nagyjából megegyezik a HD 7970 árcédulájával. Az AMD az eddig megjelent 7000-es kártyákkal megtette azt a kellemetlen szívességet, hogy összességében magasabb szintre emelte a diszkrét grafikus kártyák árát, amit az NVIDIA teljesen érthető módon nem is rest követni.
Árháborúra egyelőre ne nagyon számítsunk, még annak ellenére sem, hogy a GTX 680 előállítási költsége szerintünk bizonyosan a HD 7970-é alatt van. A TSMC 28 nanométeres gyártókapacitása jelenleg még meglehetősen szűkös, így ameddig ilyen ár mellett is gazdára találnak a kártyák, addig egyik vállalat sem fog árat csökkenteni. Talán az év második felében lehet némi reményünk, de erre se vegyünk mérget.Ezzel szemben egy driver-háborúra jóval nagyobb az esély, ugyanis mindkét gyártó egy meglehetősen új megoldással állt elő mostanság, melyekben minden bizonnyal lakoznak még tartalékok. Azt sajnos egyelőre nem tudjuk megmondani, hogy GCN vagy a Kepler fog többet gyorsulni a meghajtóktól a következő hónapok során, de idővel vissza fogunk térni erre a kérdésre.
Addig is a GeForce GTX 680-at különösen ajánljuk mindazoknak, akik ki tudják használni a benne lapuló, igen nagy grafikus teljesítményt, és/vagy egy moderált fogyasztású csúcskártyára vágynak. Természetesen a potenciális vásárlóknak ebben az esetben is meg kell barátkozni a masszív árcédulával, ugyanakkor szinte biztosak lehetünk abban, hogy a legújabb GeForce tudásban és sebességben is egy jó darabig meg fog felelni az elvárásoknak.

NVIDIA GeForce GTX 680 videokártya
(ha nem számít a pénz)
Oliverda és Abu85
A GeForce GTX 680-at az NVIDIA biztosította, az ASUS GeForce GTX 590 és ASUS Radeon HD 6970 DirectCU II kártyákat az ASUS bocsátotta rendelkezésünkre. A tesztben használt többi videokártya beszerzésében a Ramiris Zrt. segédkezett.




