A Tahiti és a grafika
Eddig a rendszert az általános számítások szempontjából vizsgáltuk, így ideje rátérni a grafikai részre is, ami valószínűleg jobban érdekli az olvasókat. A rendszer setup része a Cayman GPU-ban bevezetett utat követi, vagyis a Tahiti két darab teljesen elkülönülő egységgel dolgozik. Ennek köszönhetően a rendszer órajelenként két háromszöget dolgoz fel. A feldolgozó motoronként elhelyezett, kilencedik generációs tesszellációs egység azonban egy rendkívül izmos megoldás lesz.
Az AMD úgy gondolja, hogy a fix funkciós tesszellátor esetében sokkal jobb döntés az extrém mértékű skálázás helyett az egység teljesítményét növelni, illetve különböző trükkökkel gyorsítani a tesszellálást. Itt tulajdonképpen látható, hogy az NVIDIA és az AMD nem ért egyet megvalósítás szempontjából. Az előbbi vállalat a Fermi architektúrában egy úgymond brute force megvalósítás híve volt, vagyis tranzisztorok tízmillióit áldozva ide egy teljesen szétválasztott setup részt alkalmazott. Ennek az elgondolásnak az összesített hatékonysága a gyakorlatban nem volt a legjobb az elméletben elérhető maximumhoz viszonyítva, de annyira túl volt méretezve a rendszer, hogy ez bőven korrigálva lett.
Az AMD technikailag felkészítette a GCN architektúrát akármennyi setup motor kezelésére, de a vállalat szerint nagyon meg kell gondolni, hogy mennyi tranzisztor legyen felhasználva itt, mivel a tesszelláció a DirectX 11-ben a nem éppen hatékony NoSplit megvalósításra épül. Korábban írtunk már ennek hibáiról, illetve a lehetséges alternatívákról. Az világosan látszik, hogy a linkelt hírben az aktuális megoldások közül az úgynevezett DiagSplit elv kínálja a legjobb működést, de ez nem mutatkozik majd be a DirectX 11.1-es API-ban, így a fejlesztők továbbra is a NoSplit algoritmusra vannak kényszerítve.
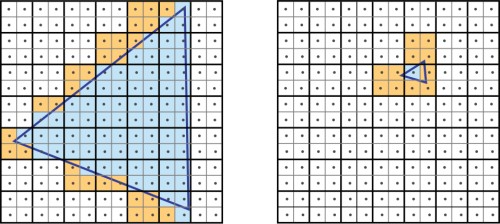
Nem elhanyagolható szempont az sem, hogy a tesszellálás legnagyobb rákfenéje a raszterizálás hatékonysága. Ez korábban nem jelentett problémát, de az apró háromszögek alkalmazásával erősen meg lehet közelíteni egy olyan határt, ami egyszerűen túlterheli az összes kártyát ebből a szempontból. Egy korábbi cikkben részletesen elemeztük a helyzetet, miszerint a mai GPU-kra egységesen jellemző, hogy a raszterizálást négyes pixelblokkokon hajtják végre, ami annak köszönhető, hogy ez a feldolgozási elv a párhuzamos munkavégzés mellett nagyon hatékony.
Az elsődleges gond akkor merül fel, ha egy háromszög kisebb, mint négy pixel. Ilyen esetben a négyes blokk nem azonos háromszögön dolgozik, vagyis a másik háromszögre is ki kell számolni a teljes blokkot, ami lényegében az erőforrás nagymértékű pazarlása. Ennél sokkal rosszabb, ha egy háromszög egy pixel nagyságú, mivel számítás az egyik háromszöggel kezdődik az egyik pixelen, ami mellé további három képpont tartozik a blokkosított feldolgozás miatt. Ez már önmagában azt jelenti, hogy egyetlen apró háromszögért négy pixelt kell ellenőrizni, ám a poligon kicsi, így jó eséllyel mellette lesz a társa, ami további ellenőrzéseket jelent. A gyakorlatban ez a jelenség még rosszabb, ugyanis a háromszögek nem fedik tökéletesen a pixelt, vagyis legrosszabb esetben 12 pixel ellenőrzését is végre kell hajtani ahhoz, hogy egyetlen képpont raszterizálva legyen.
A tesszellátor a tranzisztor szintjén alapvetően nem drága, így ezen a ponton sok lehetőségük volt a mérnököknek, de a kapcsolódó raszter motor már nagyon is költséges. Az AMD a tranzisztorszám kímélése miatt úgy döntött, hogy a rendkívül pazarló, de mégis gyors brute force elv helyett inkább okos trükkökkel operálnak a teljesítmény növelésénél. A raszter motorokkal alapvetően a Cayman esetében sem volt gond, mivel ebből a szempontból az előző generációs Radeon a piac legfejlettebb és leggyorsabb megoldásának számított. Éppen ezért itt az AMD apróbb optimalizálásokkal élt, de az egység többnyire ugyanarra képes, mint az előd, azaz órajelenként 16 képpontot dolgoz fel, ami a teljes lapkára nézve 32 pixelt jelent, a renderelés pedig 2 x 2 pixeles tömbökön zajlik. Természetesen megmaradt a tile-based load balancing, ami a hierarchikus Z algoritmus túlterhelését akadályozza meg. Ezzel a rendszer a raszterizálást hierarchikus Z nélkül hajtja végre, a teljes képkockát több egyenlő méretű, viszonylag kicsi mozaikra osztva. Itt nyilván számos szabályt be kell tartani biztosítandó a renderelés sorrendjét. A hierarchikus Z algoritmus a mozaikokon lesz lefuttatva, amelyeket tovább lehet küldeni, vagy éppen el lehet dobni, ha nem tartalmaznak látható információt. Tulajdonképpen az elgondolás a teljesítmény tekintetében messze nem a legjobb, de összességében még mindig jobb bevállalni ezt, minthogy a hierarchikus Z motor túlterhelődjön, ami sokkal nagyobb problémát jelent. Hasonló megoldást alkalmaz az NVIDIA a Ferminél is, ám a zöldek raszter motorjának teljesítménye órajelenként csak 8 képpont.
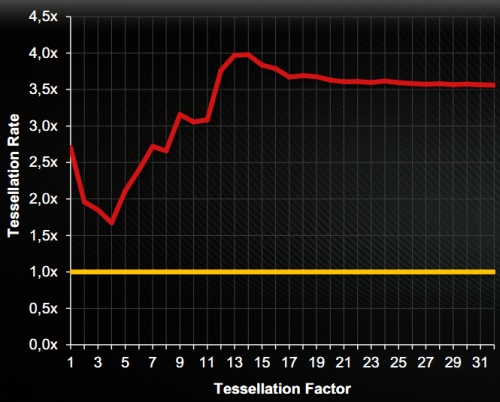
A nagy változások tehát alapvetően a tesszellációs egységeket érték. Az új megoldások az előző generációs rendszerhez képest, magas tesszellációs faktor mellett átlagosan három és félszer gyorsabban dolgoznak, sőt a manapság alkalmazott kritikus faktorszint mellett négyszer tempósabban bontják fel a háromszögeket. A kilencedik generációs egység ráadásul írhat az összesen 768 kB-os L2 gyorsítótárba. Alapvetően már a Cayman GPU-ban alkalmazott motor is lehetővé tette, hogy a magas tesszellációs faktorral rendelkező felületeket lementse a rendszer a fedélzeti memóriába, így azokat a következő képkockák számítása alatt elég betölteni, amivel megspórolható a felbontással eltöltött idő. Ez a megvalósítás azonban csak akkor volt hatékony, ha a memória nem túl gyors elérése még mindig gyorsabb volt a háromszögek felbontásánál. Ez nagyon ritkán előfordulhatott, de az esetek többségében jobb opció volt számolni, mint trükközni. Az írható másodlagos gyorsítótár elérése azonban jóval gyorsabb, így az ACE elemzi a felületek felbontásával töltött időt, és ha azt túl soknak ítéli, akkor a parancsprocesszornak jelzi, hogy le kell menteni az adott részletet a gyorsítótárba. A következő képkocka számításánál a raszter motor már csak egy parancsot kap, hogy az előzőleg kiszámolt felületet töltse be a cache-ből.
Természetesen egy méretesebb felület rengeteg helyet foglal, vagyis elsősorban a kritikus részek lementését érdemes megfontolni. Az AMD ezt persze driverből is koordinálhatja, figyelembe véve az adott program igényeit. Maga a rendszer tehát nagyon trükkös, és abszolút tranzisztorkímélő. A driverekből való rásegítés azonban valószínűleg sok támadást fog kapni a konkurens gyártótól. Bár a felületek lementése és visszatöltése a képminőségen egyáltalán nem változtat, az adott alkalmazásra szabva viszont elképesztő sebességelőnyt hozhat, így a tesszellálásra kihegyezett tesztprogramokban nem biztos, hogy a valós erőviszony köszön majd vissza. A népszerű Unigine Heaven például rengeteg, extrém mértékben tesszellált felületet használ, így ebben a programban az AMD elgondolása komoly előny lehet. Persze figyelembe kell venni, hogy mindez a játékokban is alkalmazható, így az AMD valószínűleg kihasználja a Catalyst meghajtókban régóta tengődő optimalizált tesszelláció opciót, melyre eddig még egyetlen profil sem született.
A cikk még nem ért véget, kérlek, lapozz!



