
- Versenybe hozta magát az új Xeonnal az Intel
- Titan Army P27GR monitor: hogy tud ilyen olcsó lenni?
- ATX 3.1-es Seasonic tápok a picit pénztárcabarátabb szegmensben
- Boldog-boldogtalan kézikonzolt akar kiadni, de egyelőre nincs meg a felvevőpiac
- Megszellőztették az MSI Unify-X alaplapsorozat visszatérését
- Autós kamerák
- Nem teljesít túl jól a kasszáknál az aktuális Xbox generáció
- RAM topik
- NVIDIA GeForce RTX 4080 /4080S / 4090 (AD103 / 102)
- Elengedheti a köztes generációkat az Intel
- Milyen TV-t vegyek?
- NVIDIA GeForce RTX 4060 / 4070 S/Ti/TiS (AD104/103)
- Projektor topic
- HiFi műszaki szemmel - sztereó hangrendszerek
- Milyen billentyűzetet vegyek?
Hirdetés
-


Ismét a vietnámi OLED-gyártásba fektet a Samsung
it További 1,8 milliárd dollárt fektet be Vietnámban a Samsung az OLED-kijelzők gyártása kapcsán.
-
"A homoszexualitás természetellenes" 😠
lo Ehhez képest a természetben nem ritka és evolúciós előnyei is vannak. ...
-


GreedFall 2: The Dying World - Elindult a PC-s korai kiadás
gp A premierrel együtt kaptunk egy új rövid előzetest a játékhoz, valamint a készítők megosztották velünk a roadmapet.




-

PROHARDVER!
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#38002
 lezso6
HÁZIGAZDA
Petykemano
#38001
lezso6
HÁZIGAZDA
Petykemano
#38001
válasz
 Petykemano
#38001
üzenetére
Petykemano
#38001
üzenetére
Én mindig úgy voltam vele, hogy ha két hasonló kártya közül lehet választani, de az egyikben van valami plusz, akkor azt választom, akkor is, ha még nincs kihasználva. Az RTX 2070 nem drága (a többi kártyához képest).
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Hát, eddig nem mertem leírni, de akkor most leírom:
Nem lesz itt semmilyen Navi még. Lesz helyett új Vega 12 nm-en, s lehet kiadják a Vega 12-t is shrinkelve, low profile kártyaként vagy Zen 2 prociba integrálva.
![;]](//cdn.rios.hu/dl/s/v1.gif)
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 #45185024
#38030
üzenetére
#45185024
#38030
üzenetére
Mióta létezik a Kaby Lake G, jól látható, hogy a chiplet (több chipes) dizájn a nyerő, s Abu is ezt nyomja, pGPU-nak hívta. Persze itt fontos azt megjegyezni, hogy a pGPU saját memóriát kap, amiből szerencsére nem is feltétlenül kell sok, mivel ott a HBCC. De attól még drágább megoldás. Viszont effektíve egy erős APU-ként működik, konzolba is jobb lenne ez, durvítva. De lényeges, hogy a közös rendszermemória megmarad, a HBCC csak egy hardveresen vezérelt cache-ként működik. Persze ha a játék úgy igényli, akkor közvetlenül is hozzá lehetne férni, bár sok értelme ennek valószínűleg nincs.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 schawo
#38033
üzenetére
schawo
#38033
üzenetére
Nem bullshit. A heterogén éra már jóideje megy. Ott az Intel mainstream desktop, ahol már a Sandy Bridge óta APU van. Az Ryzennél már nem nagyon van, de ez igazából átalakult. Ott a Vega, ami gyakorlatilag a rendszermemóriát tudja használni, és a mellette lévő csak egy gyors cache.
Az AMD beszopta azzal, hogy a GPU és CPU nem igazán megy együtt, egy lapkán, gyártástechnológiai okokból. Illetve külön gyártani amúgy is olcsóbb, főleg nagy lapkáknál. Ehhez is jól jött az új összeköttetés (IF), illetve a Vega is igazából az APU koncepció kiterjesztéséről szól, dGPU-ra. A hagyományos APU megmarad, teljesen mindegy, hogy most lapkán belül vagy lapkán kívül van összekötve a CPU és a GPU, a lényeg, hogy egy tokon van, és szoftveresen is egyként látható.
Ez az egész chiplet dizájn persze leginkább egy tünet. Mivel rohadt drága gyártatni, ezért trükközni kell.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Induljunk ki abból, hogy a Vega 20 az 331 mm2, a Vega 10 az pedig 486 mm2. Ez elég hülyén hangzik, hisz 0.68x, de egyrészt ugye Lisa Su-t idézve I/O doesn't scale, ráadásul dupla I/O van a Vega 20-on. Ez a die shot összehasonlítás igazolja: Fiji vs Vega
Másrészt a Vega 20 tartalmaz jópár feature-t, ami biztosan nem kevés helyet foglal tranzisztorban, ez pedig játékos kártyára úgy sem kell, megspórolható.
Azonban hiába, az I/O-t nem lehet kihagyni, a GDDR PHY még több helyet foglal a HBM-nél egy lapkán, lásd korábbi képen a Polarist, amin 256 bit van, miközben a kb dupla méretű Hawaii-n az 512 bit relatíve jóval kevesebb helyet foglal. Szóval nincsenek annyira jó kilátások.
A GDDR6 talán megmentő lehet, mert ugyanannyi PHY területből dupla sávszél csikarható ki, bár ez még mindig csak félúton van a HBM területhatékonyságához képest. De ha megnézzük a Polarist, és 2x skálázódású a 7 nm a 14 nm-hez képest, akkor oda simán be kell férnie egy vegányi számolónak. És a GDDR6 miatt pont elég sávszélt is kap. Fogyasztás pedig lehet 150-200 watt, attól függően, hogy mennyire ragaszkodnak az eddigi szénnéhúzós stratégiához. S akkor megkapjuk a 250 dolláros Vegát, vagy kicsit többet, de akkor a fogyasztás elszáll.
Azonban ha sikerül valahogy a HBM árát lejjebb szorítani, akkor sokkal jobban megéri arra menni, hiszen a GDDR6-tal megegyező sávszélhez képest fele területből megvan ugyanaz a sávszél. Ez pedig 7 nm-en kritikus.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 dergander
#38225
üzenetére
dergander
#38225
üzenetére
Ha minden alkalmazásban out-of-the-box hatékonyan működik speciális támogatás nélkül, akkor tökmindegy hány GPU. Persze gondolom ez még ilyen nulladik generáció lenne az AMD-nél, szóval sokat nem érdemes várni tőle.

A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
dergander
#38230
üzenetére
Ha chipletszerűen oldják meg, alacsony szinten, akkor semmi gond, simán lehet hatékony. Persze ehhez úgy is kéne tervezni az architektúrát, anélkül nem lesz annyira hatékony.
Az SLI-t már el kéne felejteni, az egy driverből tákolt szemét. Persze sok helyen működik, de nem túl hatékony és ezen felül is az AFR jellegű működésnek rengeteg hátránya van.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Lehet egy ROP blokk nem 4 rop egységet, hanem 8-at tartalmaz. Jó lenne már látni egy rohadt die shotot, rögtön látható lenne. De a render die shotok alapján mintha tényleg duplázva lenne a ROP.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
-
#38761
lezso6
HÁZIGAZDA
Petykemano
#38760
válasz
Petykemano
#38760
üzenetére
Nekem a legfrissebb spekulációm a problémáról szimplán az, hogy egyszerűen nem skálázódik a GCN. Lásd:
Generáció lapkanév ACE + HWS SE CU/SE ROP/SE R/SE
GCN1: Tahiti 2 + 0 2 16 16 16
GCN2 Hawaii 8 + 0 4 11 16 16
GCN3 Tonga 8 + 0 4 8 8 8
GCN3 Fiji 8 + 0 4 16 16 16GCN4 Polaris 4 + 2 4 9 8 8
GCN5 Vega 10 4 + 2 4 16 16 16
GCN5 Vega 20 4 + 2 4 16 32 16Ami mindegyikre igaz, hogy 1 SE az 1 geometria is tartalmaz Illetve adalék magukról a lapkákról.
Szóval úgy állunk, hogy már GCN3-nál elfogyott az SE. A Polarisból nem is készült valamiért nagy lapka, a compute és a geometriai frontend javítása (HWS, PDA) ellenére. A Vega pedig a frontend további javításával (DSBR, NGG) foglalkozott, de ez nem jött össze. Lehet itt a bibi. Az biztos, hogy a 4 SE az egy limit.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
AMD-nél a geometriai motor és a raszter egyben van, ezért frontend, nem? Mindenesetre összeszedtem a raszter adatokat, frissítettem a táblázatot. Hátömm. Egyébként a TU106-ban is van ilyesmi, mert ott 48 raszterre jut 64 blending, bár ez enyhébb.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 Cathulhu
#38848
üzenetére
Cathulhu
#38848
üzenetére
Biztos nem a HBM szar.
A Radeon VII-nél a ROP duplázva van, de a raszter nem, ez lehet limit. De eleve ott a geometriai motor is, az is limitálhat. Vagy szimplán az, hogy a GCN egyszerűen nem skálázódik jobban. Szerintem utóbbi, vagy legalábbis a probléma gyökere ez. Lásd ezt a hsz-em.
Ha kicsit akarunk hasonlítgatni, akkor vessük össze nyers erőben a Vega 64-et az 1080 és 1080 Ti-vel!
Egységek száma, op / clk:
RTX 2070 GTX 1080 Vega 64 GTX 1080 Ti RTX 2080
geometria 3 4 4 6 6
raszter 48 64 64 96 96
shader 2304 2560 4096 3584 2944
ROP 64 64 64 88 64
RAM (GB/s) 448 352 484 484 448Alapórajelekkel számolva, op / s:
RTX 2070 GTX 1080 Vega 64 GTX 1080 Ti RTX 2080
órajel 1410 1607 1247 1480 1515
geometria 4.2 6.4 5.0 8.8 9.1
raszter 68 102 80 142 145
shader 3248 4113 4944 5304 4460
ROP 90 102 80 130 97
RAM (GB/s) 448 352 484 484 448Konklúzió: compute meg sávszél van, más nincs. Persze, Vegát kicsit alulbecsültem hisz annak eléggé alacsony az alapórajele a boosthoz képest, de hiába adsz hozzá 10%-ot is, akkor is épp valahogy megközelíti az 1080-at, a Ti pedig rohadt messze van. Kész csoda, hogy az 1080-at eléri gyakorlatban. Ha Radeon VII-t akarjuk nézni a Vega számaihoz kb 15-20%-ot érdemes adni, talán ennyivel magasabb órajelen jár. Illetve a ROP-ot meg a RAM-ot lehet duplázni. De frontend attól még harmatos marad.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
-
Az az érdekes, hogy a 2070 raszter és geometria limites, aztán még sincsenek furaságok, eléggé közel van a 2080-hoz. Meg az is érdekes, hogy a 2080 2/3-nyi rop teljesítményből az 1080 ti felett van. Ennyire számítana a raszter és geometriai teljesítmény, amiben már az 1080 ti szintjét hozza? De akkor a 2070-nél miért nem számít ez? Lehet az NV ábrái félrevezetőek és nem 48 illetve 96 háromszöget dolgoznak fel, hanem 64-64-et, ami pont egyezik a ropokkal.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Jelenleg azt látjuk, hogy semmit sem oszt vagy szoroz a kiegyensúlyozatlanság a Turingnál.
2070-nél hol felezett a blending?
Órajelet hiába normalizálsz, nem fog kijönni. Ha az 1080 Ti-t alapórajelen és de 2080-t booston számolod (ez aligha reális), akkor is csak 13%-ot adhatsz hozzá a számaihoz a táblázatban, s nem jön ki. Ráadásul ugye úgy minden más is emelkedik, szóval a kiegyensúlyozatlanság nem változik. A komolyabb egyesített L1 / LDS cache meg az alapvető architektúrális változások viszont már tetszetős érv, csak homályos. Ettől még mindig kiegyensúlyozatlan a két kártya, s a 3 kártya egymáshoz való viszonyában ez nem látszik semennyire.
Ez egyébként azért lenne ON topik, mivel a Vegánál is hasonló lesz, bár kicsit jobban. Meg az NV illetve VS topkban amúgy sem lehet szakmaizni, úgyhogy maradt ez a topik.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
A 4-nél több SE szerintem skálázhatósági probléma miatt nem lehetséges, valószínűleg kb lehetetlen (jól) megcsinálni GCN-re. Navinál is most az a pletyka, hogy két GPU-s megoldás lesz a nagy kártya. Szóval marad a 4 SE. Szerintem a post-GCN architektúránál lesz először 4-nél több SE vagy hasonló egység. NV-nél ugye ez a GPC, s ha ezt megnézzük, akkor érdekes dologra bukkanunk, hisz az NV pont ott húzott el, amikor meg tudta csinálni a 6 GPC-re skálázódást:
GF100: 4 GPC
GF110: 4 GPC
GK104: 4 GPC
GK110: 5 GPC
GM200: 6 GPC
GP102: 6 GPC
TU102: 6 GPC (és a TU104 is!)Azonban itt már nagyon hamar jön a 8 GPC, amikor az AMD-nek eleve a 6 SE nem jött még mindig össze. Bár lehet egyből 8-ra fognak lépni, talán.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#38923
lezso6
HÁZIGAZDA
Petykemano
#38921
válasz
Petykemano
#38921
üzenetére
4+4. De attól még szoftveres megoldás, nem hardveresen 8. Persze ha működik, akkor mindegy hogy miképp, a lényeg, hogy gyors. A többchipes megoldásnak innentől meg csak előnye van.
A 4-nél több SE bizonyára kemény mérnöki feladat, hisz 2015-ben a Fijinél megszívták vele, 2017-ben a Vegánál se sikerült 4-nél többet csinálni, így most 2019-ben tanultak belőle, s úgy néz ki a Navi többchipes megoldás lesz.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Órajelekkel számolva van +37% a 2080 javára, s annak már ugye nem kripli a geometriai és raszter képessége. Ehhez képest csak +20% játékokban.
Igen a Fermi és Kepler esetén fele, de már Maxwell óta ugyanazt az arányt használják, mint a GCN.
What? 2080-nál 1860 MHz az hogy? 1710 a boost clock. Az 1080 Ti-nél meg 1582 MHz a boost. Valamiről lemaradtam?
De így is akkor 16% a különbség az 2080 javára, amit a gyakorlat hoz is, mintha a 2080 ROP-béli kriplisége nem számítana.[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
-
ComputerBase-nél a 2070 van összevetve a 2080 FE-vel, s ott 4K-ban tényleg 29% különbség van, de hát ugye sima 2070 vs 2080 FE.
Ja úgy felezett blending, én meg az egységek számára gondoltam. Hát WTF ha az NV gyengébb blendingben, akkor miért az Radeonnál kevés a ROP?
Nekem ez inkább pont ez ellen szól, a GCN nem skálázódik jól játékban. 
Na, akkor tehát 2070 vs 2080 közötti különbségek, részegységekre bontva:
geometria: +116%
raszter: +116%
ALU: +37%
ROP: +8%
RAM: 0%Tehát akkor az a gyakorlati +20% azt jelenti, hogy elég durván kevés a ROP 2080-nál, ami WTF.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Ha ALU, geometriai és raszter képessséget nézek, akkor a minimum 37%. Azonban a ROP csak 8%. Mivel nem 37%, hanem 20% jön össze, akkor nyilván ROP limit. Nem nagyon, de az van. Ha nem lenne ROP limit, akkor a 2080 jóval gyorsabb lenne.
Vega 64 vs 1080 Ti különbsége azért elég jól látszik a táblázatban. A Vega ALU-ban és sávszélben hozza az 1080 Ti-t, de backend és frontend terén már az 1080 is alig van meg. És nyilván a körítés limitálja, a grafikai feladatok. Ezért játékban 1080 szintű, compute-ban meg 1080 Ti felett is van sokszor.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#38981
lezso6
HÁZIGAZDA
Petykemano
#38976
válasz
Petykemano
#38976
üzenetére
Nem egészen. Egyrészt nemrég derült ki, hogy gbors számára a raszterizáció is backendnek számít (render szempontból), amikor az szerintem frontend (műszaki szempontból), ebből adódott egy kis félreértés. Ráadásul Másrészt limit alatt itt most nem arról van szó, hogy überlimit, csak egyszerűen az néz ki szűk keresztmetszetnek. Meg kéne vizsgálni a TU104 és TU102 viszonyát is skálázódásban.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
De ugye műszakilag nem kiegyensúlyozott, ezért lehet következtetni, hogy a ROP kevés. Több SM-mel egy Vega elcseszettségét kapnánk, nem hiszem hogy nőne a teljesítmény.
S ha már a Vegánál tartunk: ugye raszter is kell a ROP mellé. Ez viszont elkerülhetetlenül hozza magával a több SE problémáját, hisz 1 SE egy 1 tri / clk geometriai + egy max 16 px / clk raszter motort tartalmazhat, nem többet. Szóval ha növelni akarod a ROP-ot, akkor az SE-k számát is növelni kell, elkerülhetetlenül, mert egyenként max 16 px/clk rasztert tud. Tehát a Vegának 4 SE x 16 CU, 16 ROP helyett 6 SE x 10 CU, 16 ROP-nak kéne lennie, s akkor kapnánk egy 1080 Ti szerű kártyát (szorozd fel 1.5x-re a táblázatban a Vega geometriai, raszter és rop képességeit).
Polarisnál egyszerűbb lenne a helyzet, mert ott csak 8 px / clk raszter motorok vannak, szóval ezt simán lehetett volna duplázni + ROP másfelezés. Csak ez valamilyen okból nem jött össze.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Lehet, végül is a Vegát se fogja vissza annyira a kripli körítés, megoldja ALU-ból. Igaz kissé más arch.
PH-s tesztben. Egyébként a Tonga is ilyen, csak 32 pixel / clk az összesített max raszter, mert 32 ROP mellé minek több. Miközben a Fiji ugyanígy 4 SE-vel már 64 pixel / clk rasztert tud, duplázott ROP mellett.
De amúgy ezt a raszterbéli különbséget még nem sikerült kisakkoznom die shotokból, szóval lehet nem igaz... ...Abu?
Vagy esetleg valahol (pl hardware.fr) mérnek peak raszterizációs képességet?
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Na ettől féltek én is, hogy nem mérhető. Lehet szimplán csak le van tiltva vagy titkolva a raszterképesség.

A lényeg, hogy több SE kell, és kész. 4+ éve 4 SE-vel van szerelve minden kártya: Tonga, Fiji, Polaris, Vega. Utóbbi kettő pedig a frontendet próbálta erősíteni, ez egy jel. Most meg a Vega 20 kap izom backendet, csak minek. Hamarosan kiderül.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
#45185024
#39033
üzenetére
Milyen az a saját ray-tracing eljárás?
Úgy tudom nincs sok. Nagy esélyét látom annak, hogy az NV-féle utat választják, hacsak nem lesz valahonnan hirtelen elég sávszél illetve csodadriver.DL az egy érdekes terület. Az Vega 20 viszont meglehetősen gyenge ebben.
Amíg az NV pl 1 egységnyi FP32 mellé tud 8x annyi 16 bit mátrixszorzós elemi műveletet, a Vega 20 ennek csak negyedét (!) tudja. Mert utóbbi nem dedikált hardvert használ (mátrix FMA), hanem a CU-k képesek natívan dot product műveletet végezni. Ez jó is meg nem. De leginkább nem jó, ha DL-ről van szó.A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
Cathulhu
#39040
üzenetére
Na igen, az NV GPU-i a célhardverek mellett elbújhatnak. Így hosszabb távon az AMD megoldása jobbnak tűnik, hisz ha nem használod a dot product utasításokat, attól még nem marad kihasználatlan a hardver. Az NV tensorjai viszont feleslegesen foglalják a helyet, hogy ha nem fut rajtuk DL. Ugyanez igaz az RT magokra is, bár utóbbiaknál azért elég nagy esély van, hogy előbb-utóbb minden játék kihasználja.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
#45185024
#39043
üzenetére
Jó, csak amíg a az NV csúcs ~130 TOPs sebességet tud FP16-ban, addig az Vega 20 csak ~30 TOPs-ot. Legalábbis ha mátrixszorzásról van szó. Ha már valami más, pl egymástól független dot product számítás esetén az NV teljesítménye rögtön negyedelődik. Csak az a kérdés, hogy hol van szükség ilyenre, mert erre nem tudok példát.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Már Volta óta tudni mire való. Egy tensor mag az 64 db speciálisan összedrótozott FMA ALU, ami egy órajel alatt képes egy D = A + B * C mátrixművelet elvégzésére, ahol A pedig egy-egy 4x4 FP32 (vagy FP16) mátrix és B és C pedig egy-egy 4x4 FP16 mátrix. Turing óta van INT8 és INT4 támogatás is, mely 2x illetve 4x sebességű mátrix FMAC-ra képes.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
Cathulhu
#39135
üzenetére
Nem igazán értem mire gondolnak az alatt, hogy NV-hez hasonló designt csinálnak. Nemrég pont az NV ment a Voltával az AMD után az SM szervezéssel compute-nál. Egy SM ugyanúgy 4 db alcsoportot tartalmaz. Az NV annyiban más, hogy egy SM-en belüli csoportban nem csak egy 16 utas SIMD motor, hanem többféle egyszerű feldolgozó is lehet, így tensor, FP64, INT, FP külön van mind. Az AMD a szétválasztás helyett a SIMD motor képességeit maximalizálja, azaz egy komplex egység csinál mindent. A Super SIMD ezt még csak tovább bonyolítja, inkább távolabb lesz az NV designjától.
Persze annyiból kéne közelíteni az NV-hez, hogy a hatékonyság és a skálázhatóság sokkal jobb legyen. Ebben az NV mérföldekkel előrébb van.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Csak ez nem valós termék, csak koncepció. De tény, hogy az AMD ezt simán megcsinálhatná, hisz ott az IF, ragaszthat GPU-t is a CPU-k mintájára. HPC-re csodadriver nélkül is simán működőképes, hisz azok gond nélkül skálázódnak több GPU-ra.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#39151
lezso6
HÁZIGAZDA
Petykemano
#39149
válasz
Petykemano
#39149
üzenetére
Bullshit.
A GCN ütemezése nagyon rugalmas, s jó. A 16 utas SIMD-ek mind függetlenül vezérelhetők, s közvetlen bekötés lehetséges a skalár feldolgozóval. NV-nél az előbbi csak a Volta óta van, utóbbi pedig még nincs. Előtte Pascal és Maxwell 2x16 utas volt, ez ugye pont 1 warp-nak felel meg:
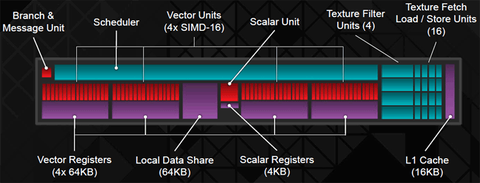
A GCN baja az, hogy hiába istenes a compute, ha köré nincs elég (hatékony) körítés. Már a számokon látszik. Pont, hogy sok CU van. Inkább több SE kéne, izmosabb grafikai frontenddel és backenddel.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#39154
lezso6
HÁZIGAZDA
Petykemano
#39153
válasz
Petykemano
#39153
üzenetére
Az AMD compute képességek terén patent, sőt ha compute energiahatékonyságot nézel, ott sem rossz. Bár nyilván lehetne jobb, mert az NV az idő folyamán eléggé feljött mellé, illetve kínál olyat is, amit az AMD nem (Tensor). Szóval van értelme javítani rajta. De ez még eléggé a jövő zenéje, szvsz nem a Navinál mutatkozik be.
A grafikai körítésben meg ugye már jó ideje elmaradtak, ez természetesen sokkal-sokkal fontosabb lenne. A Navinak elvileg ezen kéne nagyot javítania, remélhetőleg így lesz.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
-
válasz
 Oliverda
#39298
üzenetére
Oliverda
#39298
üzenetére
Nagysebességű memeória (GDDR / HBM) a konzumerpiacon a GPU-k mellé szokott kerülni, máshová nem igen. Tehát Intel, AMD, NV jöhet szóba. Ebből kettő használja a HBM-et. Így csak jobbnak tűnik a HBM terjedésének helyzete.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
Oliverda
#39300
üzenetére
Mert az NV-nek nincs vele annyi tapasztalata? Meg nem igazán konkurenciája a GDDR6-nak a HBM2. Az inkább a HBM3 lesz. Ebből következően kicsi az esély, hogy a Navi mellett nem GDDR6 lesz, hacsak nem előbb jön a HBM3.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#39313
lezso6
HÁZIGAZDA
Petykemano
#39312
válasz
Petykemano
#39312
üzenetére
Van már ilyesmi, úgy hívják hogy RT Core. Ennek a koncepciónak egyébként több értelmét látom, legalábbis ha az RT-nek nem kell sok RAM. Gondolom nem kell, hisz a texturák szokták legjobban enni a RAM-ot.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Ma azt álmodtam, hogy a Navi hozza az igazi ray-tracinget, legalábbis az NV-s RTX az gagyi lesz mellette.
Most nézem, hogy 2017 elején az első generációs Zen árlistás álmom gyakorlatilag bejött, szóval...
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#41339
lezso6
HÁZIGAZDA
Petykemano
#41336
válasz
Petykemano
#41336
üzenetére
Ez a Navi lesz, amin 8x32 bitnyi GDDR6 csatornát, 32 ROP-ot, illetve 20 CU-t (?) számolok, s utóbbiak eléggé különböznek az eddigiektől. Meg nyilván a frontend (vezérlés) is más, itt kellene ugye újítani.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
A Navi 251 mm2, a Polaris 232 mm2. Shader részelemre vetítve (2560 vs 2304) tök ugyanannyi jut adott területre. Egyedül az órajelek növekedtek 20-30%-kal. Elméletben az "IPC" +25%-kal nőtt, így 1.6x gyorsulás számolható ki, s akkor így megkapjuk a nagy Vegát.
Ez nem rossz, de alig érték be az NV-t, aki 3 éve 314 mm2-ből hozta ezt teljesítményt 14 nm-en, míg a Navi 251 mm2-ből 7 nm-en. Szóval nem lesz nagy csoda ez. Reménykedjünk, hogy a 7 nm ennél többet tud és jobban össze fogják tudni sűríteni a tranzisztorokat, mert ez hosszú távon kevés lesz.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#41431
lezso6
HÁZIGAZDA
Petykemano
#41427
válasz
Petykemano
#41427
üzenetére
A Dual Compute Unit egy érdekes, ami 2 CU-t foglal magában, illetve hogy az SE is két részre van osztva. Gondolom itt erőforrás-megosztásról van szó, legalábbis így lehetne energiát spórolni. Nagyon várom már azt a részletes leírást az RDNA-ról.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#41435
lezso6
HÁZIGAZDA
Petykemano
#41434
válasz
Petykemano
#41434
üzenetére
A Navinál várható volt, hogy nem lesz olcsó. A GDDR6 árának még be kell állnia (a GDDR5 már 10+ éves technológia!), meg a TSMC 7 nm se olcsó, nem véletlen nem érdekli az NV-t. Na meg ez egy 250 mm2 lapka, míg a prociknál használt chipletek mérete ennek a alig harmada.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Hoppá.
 Köszönöm, végre.
Köszönöm, végre. 
Szóval akkor a Navi tényleg egy érdekes cucc lett, ilyen SIMD with ILP izé, meghíztak a CU-k, DCU lett belőlük. Lényeges különbségek:
GCN CU RDNA DCU
SIMD-ek száma 4 4
SIMD szélesség 16 32
SIMD ALU-k száma 64 128
Skalár ALU 1 4
Issue 4 clk 1 clk
ILP nincs van
Wave szélesség 64 32/64Szóval, mindegy egyes SIMD motor kapott egy dedikált skalár feldolgozót, ennek köszönhetően a vezérlés jóval hatékonyabb, minden órajelben mehet egy issue. Az eddigi 64 szálas Wave mellett képes 32 szálasra is, s ugye az NV-féle Warp is 32 szálas. Szóval elment az NV felé. S felépítésben is nagyjából a Pascal SM-et idézi a Navi DCU.
De a legnagyobb változásnak az ILP tűnik, bár még nem igazán esett lett, hogy pontosan hogyan. Hogy ez most VLIW vagy már a DCU-k is tudnak OoO-t? De gondolom ez lenne Super SIMD. Mindenesetre az RDNA tett még egy nagy lépést a CPU-k működése felé.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.



![;]](http://cdn.rios.hu/dl/s/v1.gif)












 Az RTX 2080-nál meg pont fordítva van.
Az RTX 2080-nál meg pont fordítva van.









 Köszönöm, végre.
Köszönöm, végre. 
Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- Revolut
- Autós kamerák
- Vicces képek
- Nem teljesít túl jól a kasszáknál az aktuális Xbox generáció
- RAM topik
- Gigantikus chipgyárat vihet az Egyesült Arab Emírségekbe a TSMC és a Samsung
- NVIDIA GeForce RTX 4080 /4080S / 4090 (AD103 / 102)
- Elengedheti a köztes generációkat az Intel
- iPhone topik
- Milyen TV-t vegyek?
- További aktív témák...

- (Akár komplett PC-vel is eladó!) AORUS GeForce RTX 4090 MASTER 24G - 3+ év garancia
- Nvidia Quadro P400/ P600/ P620/ P1000/ T1000 - Low profile (LP) + P2000 5Gb, RTX 4000 8Gb
- Hibátlan - GIGABYTE Aorus AMD Radeon RX 580 8GB GDDR5 VGA videókártya
- MSI GTX 1050 TI OC 4 GB GDDR5 PCI-E videokártya
- XFX RX590 FATBOY 8GB OC+
Állásajánlatok

Cég: Ozeki Kft
Város: Debrecen

Cég: Ozeki Kft
Város: Debrecen