
Hirdetés
Az NVIDIA a tegnapi napon kezdődött GPU Technology Conference alkalmával mutatta be a legújabb, Fermi kódnevű architektúráját, mely a világ első úgynevezett cGPU-ja (computational Graphics Processing Unit) lesz. A lapkát valószínűleg GF100-nak fogják nevezni, amivel némileg eltér az eddigi névadási sémától. A 3 milliárd tranzisztorból álló chipet a vállalat a TSMC 40 nm-es gyártástechnológiájával készíti.

GF100
A GF100 felépítése jelentősen eltér a nemrég megjelent Cypress lapkától. Az AMD a rendszerét láthatóan a DirectX 11-re szabta, míg az NVIDIA egy korlátok nélküli architektúrát alkotott, kifejezetten a jól párhuzamosítható számításokhoz. A Fermi lelke a 16 streaming multiprocesszor, melyek egyenként 32 darab úgynevezett CUDA magot tartalmaznak két csoportba rendezve. Ezeken a 16 utas feldolgozókon lesznek párhuzamosan végrehajtva az utasításszavak. Természetesen a zöldek a speciális végrehajtó egységeket sem hagyták ki, egy streaming multiprocesszorban összesen négy ilyen ALU található, melyek trigonometrikus és transzcendens utasításokat képesek futtatni. A textúrázási képességekről egyelőre annyit lehet tudni, hogy összesen 256 csatorna van a rendszerbe építve, ám ezek felépítését és képességeit homály fedi.
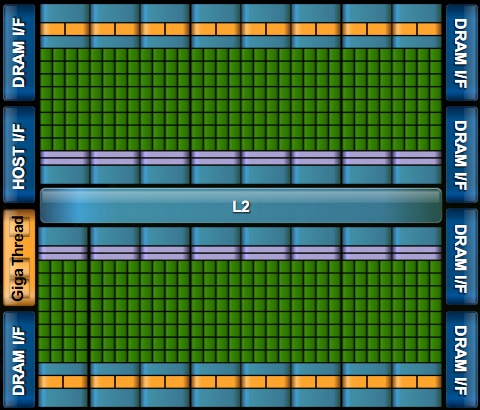
A GF100 lapka logikai felépítése
A G80 óta a rendszer memóriahierarchiája gyökeresen átalakult. A Fermi egy nagy, 768 kB kapacitású L2 gyorsítótárat alkalmaz, mely minden streaming multiprocesszornak elérhető. Az utóbbi egységek rendelkeznek 64 kB-os L1 gyorsítótárral is, mely a feladatnak megfelelően dinamikusan szétosztható egy 16 és egy 48 kB-os részre, attól függően, hogy mekkora megosztott memóriát igényelnek a CUDA magok. További újdonság az ECC-támogatás, ami ellenőrzi a memóriában és a lapka gyorsítótáraiban tárolt adatok hibátlanságát, tovább fokozva ezzel a megbízhatóságot. Ez a szolgáltatás egyébként elengedhetetlen, ha az NVIDIA az új chippel tényleg a HPC-s piacokat szeretné meghódítani. A memóriavezérlő 384 bites lesz, melyhez összesen 12 darab ROP blokk tartozik.
A GF100 teljesítményadatai sajnos titkosak, így csak a Fermi architektúrájából lehet kiindulni. A zöldek szerint a rendszer dupla pontosság esetén nyolcszor gyorsabb az előző generációs GT200-hoz viszonyítva, ami hozzávetőleg 650 GFLOPS-os teljesítményt jelent. Ezt a sebességet gyakorlatilag úgy éri el, hogy az adatok feldolgozásáért már nem dedikált egységek felelnek, hanem a CUDA magok. Két darab ilyen ALU képes egy dupla pontosságú műveletre. Természetesen az egyszeres pontosság esetén egy ALU hajt végre egy utasítást, így a számítási teljesítmény megduplázódik, azaz 1,3 TFLOPS lesz. Fontos megjegyezni, hogy hivatalosan nincsenek megadva az órajelek, továbbá azt sem tudjuk, hogy a Fermi kihasználása mennyivel javult. Ennek megfelelően a számítások pusztán az NVIDIA nyilatkozataira épülnek, és teljesen elméleti jellegűek.
A szoftveres oldalról a Fermi természetesen támogatja a CUDA, az OpenCL és a DirectCompute platformot, továbbá a C és a Fortran programnyelvek mellett már C++ kódot is lehet a rendszerre fordítani. A grafikai részről sajnos nem sok szó esett. Ez főleg annak köszönhető, hogy a GF100 hagyományos értelemben nem nevezhető grafikus processzornak. Természetesen képes támogatni a legújabb OpenGL és DirectX API-kat, de számos funkciót nem támogat hardveresen, így azokat emulálni kell. A legszembetűnőbb dolog, hogy a rendszer nem rendelkezik fix funkciós tesszellátorral, ami a DirectX 11 legnagyobb újítása. A teljes tesszellációs folyamatot a CUDA magok segítségével kivitelezik. A Microsoftot megkérdeztük a megoldással kapcsolatban. A redmondi óriáscég szóvivője elmondta, hogy nem beszélhetnek egy még meg nem jelent termék DirectX 11-es támogatásáról, de az API nem követeli meg a fix funkciós egységek jelenlétét, azaz a feldolgozó futószalag bármely részét lehet emulálni. Persze a sebesség szempontjából az emuláció viszonylag lassú megoldás, így nem optimális azt használni.

Forrás: bit-tech.net
Jen-Hsun Huang, az NVIDIA elnök-vezérigazgatója megmutatta a közönségnek az első, Fermi architektúrára alapozó terméket is, mely 16 csatornás PCI Express 2.0 csatolóba illeszthető, és egy 6, illetve egy 8 tűs tápcsatlakozót igényel. Természetesen a forgalomba kerülő modell kinézete eltérhet a képen látható kártyáétól. A konferenciáról kiszivárgott információk szerint a zöldek november végére szeretnék időzíteni a startot, de hivatalosan erről még nem beszélnek. Azt azonban elmondták, hogy tanultak az előző generációs termék debütálásakor elkövetett hibákból, így nem fogják aránytalanul túlárazni az új modellt. Érdemes megjegyezni, hogy a Fermi felépítése nagyban hasonlít a Larrabee kódnéven fejlesztett rendszerre. Ez nem véletlen, hiszen a zöldek a termékkel azokat a piacokat célozzák meg, ahova az Intel is érkezni fog, tehát nagy összecsapás várható a jövőben.

