- Vezetékes FEJhallgatók
- Kompakt vízhűtés
- Gaming notebook topik
- Milyen belső merevlemezt vegyek?
- ThinkPad (NEM IdeaPad)
- Milyen CPU léghűtést vegyek?
- Intel Core i5 / i7 / i9 "Alder Lake-Raptor Lake/Refresh" (LGA1700)
- Google Chromecast topic
- Halasztja a Recall funkció aktiválását a Microsoft
- Milyen billentyűzetet vegyek?
Hirdetés
-


Spyra: nagynyomású, akkus, automata vízipuska
lo Type-C port, egy töltéssel 2200 lövés, több, mint 2 kg-os súly, automata víz felszívás... Start the epic! :)
-


Final Fantasy XIV Online - Befutott a Dawntrail utolsó előzetese
gp Jövő hónap második napján érkezik a kiegészítő, az előrendelők azonban már június végén belevághatnak az új kalandokba.
-


Spanyolországban kezd a Vivo V40 5G és V40 Lite 5G
ma A V40 az első középkategóriás telefon, mely a Zeiss-szel való együttműködés keretein belül fejlesztett kamerákkal szereltek fel.






Új hozzászólás Aktív témák
-

7time
senior tag
Lehet hogy most két pólusú lett a PH de csak annyi a különbség hogy van + egy szakértőnk aki tud vitázni a kék oldalon, ha nem tudnak megegyezni és levetkőzni az AMD-Intel vitát hatalmas balhék kerekedhetnek, végtére a semmiért mert az AMD vs Intel kezd a múlt lenni.
-

Abu85
HÁZIGAZDA
A GloFo-nál is van LPE node. Pont erről szól a hír. Az LPP is lesz akkorra, amikorra a Samsungnál. Csak az LPE-re nincs nagy érdeklődés, mert gyorsan kész lesz az LPP, ami jobb.
Ez a baj az OpenCL-lel. Megírnak egy tök szabványos kódot az AMD APP SDK-val, és az Intel, illetve az NV OpenCL fordítója nem eszi meg. Mivel úgyis rossz lesz a kód, így inkább előre lefordítják AMD-re. Erre a gondra jön a SPIR, illetve most már a SPIR-V.
Nem az Intel implementációja szar, csak szinte minden gyártó másképp értelmezi az OpenCL C specifikációt, ami a fordításnál gáz. Mivel az APP SDK a domináns fejlesztőkörnyezet, így azt fogod látni, hogy az AMD-n megy és máson nem. Ettől viszont még a specifikációknál vannak értelmezési eltérések.Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

Fiery
veterán
Sajnalom, ha engem a kek oldalra, vagy barmelyik oldalra tesz barki is. Ez azt jelenti, hogy nem erti meg, hogy en mit kepviselek itt vagy mas forumokon
 De hat ez van...
De hat ez van...Meselhetnek pl. egy erdekes tortenetet arrol, hogy egy adott szoftver egyik fejlesztes alatt (!) allo benchmarkjaval kapcsolatban hogyan probal az egyik nagy hardvergyarto puhatolozni, hogyan probalja befolyasolni annak a benchmarknak a kialakitasat, felepiteset, mukodesi mechanizmusat, annak erdekeben, hogy az o hardverehez minel jobban igazodjon, minel jobban lehessen optimalizalni a benchmarkot a hardverre es viszont. Aztan meg egy finom elutasitas utan furcsa valasz jon a hardver gyartotol, mert ugy latszik, nehezen ertik meg, hogy a fuggetlen benchmark fejlesztes mikepp mukodik. Mindenkinek a kepzeloerejere bizom, hogy milyen szinre festi a hardvergyartot, es hogy milyen hardvert gyart. Sokan meglepodnenek, hogy melyik cegrol es milyen termekrol van szo, es talan atertekelnenek bizonyos dolgokat magukban

-
Fiery
veterán
LPE ide, LPP oda, ha lenne mar most a GF-nel 14 nanos tomegtermeles, szerintem az AMD talalna maganak olyan CPU-t, APU-t vagy GPU-t, ami epp passzolna ahhoz a node-hoz. Vagy szerinted az a 14 nanos node, amit mondjuk a Samsung mar jelenleg is hasznal, semmilyen letezo AMD termekhez nem igazithato?
Az OpenCL-rol en is tudnek legendakat gyartani
Pl. van olyan, egy nem is tavoli galaxisban, hogy valaki nem egy nyomoronc SDK-t hasznal, hanem fog egy Notepadet, es elkezdi benne irni az OpenCL kernelt, es egy masik Notepad ablakban az OpenCL koritest (pl. clEnqueueNDRangeKernel es hasonlo nyalanksagok). Namost a megirt kodot ezek utan elesben kiprobalja, es micsoda meglepetes, mukodik GeForce-on siman. Meg Radeonon is. Meg esetleg Intel iGPU-n is, de az mar necces. Igy is lehet, ez is egy modszer, ha az ember olyan OpenCL kodot akar kesziteni, ami _nem az egyik gyarto GPU-jahoz keszul elore feltett szandekkal_."Nem az Intel implementációja szar, csak szinte minden gyártó másképp értelmezi az OpenCL C specifikációt, ami a fordításnál gáz."
A francokat nem sz*r. Egy egyszeru ciklusba is bele tud(ott) bonyolodni az AMD es az Intel forditoja is, a hulye agressziv unroll optimalizacio miatt. Egyszeruen unrollolta 10000 lepesre is az idiota compiler, es belul tulcsordult valami, mindket compilernel, csak adott esetben mas kodnal. Es mi volt a problema? Hogy integert akartam hasznalni. Mekkora barom vagyok, megmondta aztan az AMD/Intel is (bocs, nem emlekszem, melyik hozta fel a temat kettojuk kozul): nem tipikus, ha valaki integert hasznal OpenCL kodban. **sszameg, tamogatja az OpenCL, tamogatja a hardver, nehogymar egy ilyen alap dolgon el kell hogy hasaljon a compiler. Es ezek utan csodalkozik barki is, ha az ember ezerszer jobban erzi magat VS-ben, mint az OpenCL fejlesztes kozepette? Legalabb nem vagy kiteve a compiler gyarto baromsaganak, egy VS-ben (vagy epp gcc-vel) sokkal-sokkal kisebb esellyel fut bele az ember egy compiler bugba.
Egyebkent az nVIDIA compilere meg a trigonometrikus fuggvenyeknel hasalt el. Csak hogy mindharom ceg compilerere le tudjam irni oszinten, hogy sz*r
 Me'g a vegen beallit valaki a zold sarokba.
Me'g a vegen beallit valaki a zold sarokba.[ Szerkesztve ]
-
#56
 hugo chávez
aktív tag
Fiery
#53
hugo chávez
aktív tag
Fiery
#53
hugo chávez
aktív tag
"Meselhetnek pl. egy erdekes tortenetet arrol, hogy egy adott szoftver egyik fejlesztes alatt (!) allo benchmarkjaval kapcsolatban hogyan probal az egyik nagy hardvergyarto puhatolozni, hogyan probalja befolyasolni annak a benchmarknak a kialakitasat, felepiteset, mukodesi mechanizmusat, annak erdekeben, hogy az o hardverehez minel jobban igazodjon, minel jobban lehessen optimalizalni a benchmarkot a hardverre es viszont. Aztan meg egy finom elutasitas utan furcsa valasz jon a hardver gyartotol, mert ugy latszik, nehezen ertik meg, hogy a fuggetlen benchmark fejlesztes mikepp mukodik. Mindenkinek a kepzeloerejere bizom, hogy milyen szinre festi a hardvergyartot, es hogy milyen hardvert gyart. Sokan meglepodnenek, hogy melyik cegrol es milyen termekrol van szo, es talan atertekelnenek bizonyos dolgokat magukban
"Khmmm... Pár éve még éppen te szerettél volna gyártói optimalizációs tanácsokat kapni. Azóta meg már gond, ha valamelyik gyártó adni akarna ilyet? (Persze amennyiben valami csalásra akarnának rávenni, vagy arra, hogy a konkurenciáét ne tudja kihasználni a bench, az tényleg gáz.) Megértem, hogy élvezed az itteni "kritikus-ellenpont szerepet" (ami gyakran szükséges is amúgy), de éppen nemrég méltattam az objektivitásodat, viszont ez most nem igazán tűnik objektív hozzáállásnak. Vagy félreértettem valamit?
"sajnos ez a beszélgetés olyan alacsony szintre jutott, hogy a továbbiakban már nem méltó hozzám" - by Pikari
-
#58
Fiery
veterán
hugo chávez
#56
Fiery
veterán
válasz
 hugo chávez
#56
üzenetére
hugo chávez
#56
üzenetére
Szerintem felreertetted, amit irtam, vagy legalabbis nem arra gondolsz, amirol en beszeltem. Oriasi kulonbseg van akozott, hogy a benchmark fejlesztes/kialakitas/tervezes kozben jon egy tanacs/kérés, vagy csak akkor, amikor a benchmark mar kesz, es csak utolag adnak tanacsot arra, hogy mikepp lehetne gyorsitani a meglevo benchmarkot egy adott hardveren. Direkt oda is irtam, felkialtojellel, hogy a fejlesztes kozben tortent mindez. Ha ugyanis a fejlesztes kozben, netan me'g a tervezesi fazisban jon egy ilyen, es azt figyelembe veszi a benchmark fejlesztoje, azzal frankon el lehet tolni egyik vagy masik iranyba a benchmarkot. Pl. marhara nem mindegy, hogy egy adott feladatot milyen adattipusokkal, mekkora adat halmazon vegzel, ezeken nagyon sok minden mulik. Ha a benchmark fejlesztoje okos, akkor viszont egyedul az a cel lebeg a szeme elott, hogy egy adott problemat kell megoldani vagy szimulalni a benchmarkkal, el kell jutni A-bol B-be vele, es se az A, se a B nem lehet hardver vagy gyarto specifikus, mert azzal megborulna a benchmark objektivitasa. Persze ha mar a benchmark megvan, es a benchmark fejlesztoje nem gondolt valamilyen aprosagra, amivel +2%-ot lehet gyorsitani X hardveren, akkor semmi gond nincs azzal, ha erre a "bakira" a hardver gyartoja felhivja a benchmark fejleszto figyelmét.
Egyebkent ez a "kepzeletbeli" hardvergyarto ceg nem csak egyetlen benchmark fejlesztot presszional folyamatosan, hanem tobbet is. Kerdes, hogy ha az egyik helyen nem jarnak sikerrel, mas helyen is ugyanigy lesz-e. Szeretnem azt hinni, hogy igen, vagyis hogy minden benchmark fejleszto fuggetlen probal maradni.
Es felreertes ne essek, egy pillanatig sem akarom ugy beallitani ezt a ceget (akinek a nevet nem irom le, nyilvan), hogy csak ok akarnak ilyen megkerdojelezheto eszkozokhoz folyamodni. Minden ceg ezt csinalja, kulonbozo mertekben, kulonbozo megoldasokkal. Mindenki a jatekszabalyok felulirasara, kijatszasara, adott esetben konkret csalasra torekszik, csak nem mindenki kerul birosag vagy a trosztellenes hivatal latokorebe
Sok esetben nem is BTK/PTK kategoria, csupan etikailag kifogasolhato lepesekrol van szo. _Mindegyik_ hardver gyarto ezt csinalja, ezert is visszatetszo szamomra az, hogy nehany gyartot divatos ilyen magatartas miatt utalni (pl. itt a PH forumokon), holott mindegyik gyarto tok ugyanazt csinalja, legfeljebb a nullak szama a kulonbseg, meg a rendelkezesre allo, piacot befolyasolo eszkozok tarhaza. Minden kapitalista ceg arra torekszik, hogy penzt csinaljon, ez a lenyege az egesznek. A piaci verseny is mindannyiukra ugyanugy vonatkozik, es mindegyik remenykedik abban, hogy nem fogja senki eszrevenni, hogy epp melyik versenyzo melyik masik hosszutavfuto versenyzo tarsa cipojebe csempeszett egy rajzszoget  Ergo vagy mindegyiket utalni kellene, vagyik mindegyiket egyforman szeretni. Nincs ertelme kivalasztani egyiket vagy masikat -- de persze megertem a kognitiv disszonancia erejét is
Ergo vagy mindegyiket utalni kellene, vagyik mindegyiket egyforman szeretni. Nincs ertelme kivalasztani egyiket vagy masikat -- de persze megertem a kognitiv disszonancia erejét is [ Szerkesztve ]
-

ukornel
aktív tag
#22 Fiery
"[...] ha valaki az AMD/GF-et kritizalja, mert lassabban dolgoznak, mint a konkurencia (ne felejtsuk el, nem csak az Intelnek van mar 14 nanos tomegtermelesu gyartosora! [...]"#24 7time
"Szerintem a Zen sorsa nem a gyártón fog múlni, most van választék bőven."Választék van, de miből? Jó-jó, hogy 14 nm, de az LPE még inkább telefon SOC-hoz passzol, nem nagy teljesítményű asztali procihoz, vagy GPU-hoz. Az majd az LPP lenne az ígéretek szerint - de abból még nem turkálunk könyékig a választékban, hogy finoman fogalmazzak.
-
ukornel
aktív tag
Ott a hatalmas nagy pont.
Pláne hogy a Bulldozer architektúrának pont a szerverfronton lett volna értelme...#36 Fiery
"Ha a Samsung eloszor megcsinalja maganak szepen a 14 nanot, aztan ugyanazt lepasszolja effektive cca. 8-10 honap csuszassal a GF-nek, az nem ugyanaz a technologia lesz mar, hiszen 8-10 honap ebben a bizniszben oriasi ido, sajnos"Én ezt nem teljesen így látom. A gyártástechnológiai fejlesztések egyre lassabban haladnak, 8-10 hónap már egyáltalán nem számít olyan őrült soknak, mint korábban.
Nézd meg a 28nm-es gyártástechnológiát: a TSMC '11 végén kezdte a tömegtermelést, és azóta folyamatosan reszelik, ugyanazon a csíkszélességen simán hoztak azóta kb fél node-nyi előrelépést az elérhető teljesítményt, illetve hatékonyságot nézve. A GloFo meg több, mint egy éves csúszással (!) indította el a saját 28 nm-es gyártását, mégis versenyképes abban a szegmensben (nagy sűrűség, alacsony fogyasztás), ahova szánták.
Ahogy elnézem a 14nm-es Intel csipek bevezetésének ütemét (csúszás, aztán low-power, aztán U-s mobil, aztán majd valamikor a jövőben némi desktop, de még messze a korábban megszokott órajelektől, high-end sehol), és a méregdrága árazását - nem érzem, hogy 8-10 hónap csúszás annyira döntő hátrány lenne, sőt, a korábbi ~1,5 éves lemaradáshoz képest ez már előrelépésnek tűnik.
Szerintem a bérgyártók 14/16 nanón is fognak annyi ideig ülni, mint a 28nm-en, ezt is hosszú évekig fogják reszelgetni.#45 Sir Ny
"Van 10 működőképes lapkájuk. Szép, szép, nem mondom, de az intel ellen kevés lesz."hahahaha
Szerintem két számjegyű kihozatali arányra gondoltak! -
Fiery
veterán
Ha az Intelt nezzuk, akkor nem lehet oket feltetlenul hibaztatni azert, mert a nagyobb volument hozo mobil procikat allitjak at elobb 14 nanora, es nem az egyre olvado desktop szegmensben akarnak ezzel probalkozni. Plane mivel ha megnezed, pont a desktopon volt eddig is a legkisebb elorelepes, nem veletlen, hogy sokan me'g mindig jol elvannak a Sandy Bridge procijukkal. Logikus, hogy az uj technologiat a mobil piacon vetik be eloszor, ahol a TDP csokkenes es a fizikai meret csokkenes (SoC szinten) a leghasznosabb, ahol a legjobban lehet ezeket az elonyoket kommunikalni. Az AMD sem veletlenul a mobil piacon veti be a Carrizot, es ha nem lett volna HSA meg OpenCL 2.0 lazban, akkor a Kaverit is a mobil piacra hozta volna ki eloszor.
-
Abu85
HÁZIGAZDA
És lett három low-level API-nk két év alatt.
Nem mondta a fejlesztőknek az AMD, hogy ne használják az API-t. Azt mondták, hogy ha szabványosan meg tudják oldani a gondot, akkor ne használják.
Mondták a GDC-n, hogy ha vannak egyedi igények, akkor azokat beépítik és elindítják a szabványosítást, úgy hogy a forrást odaadják a Microsoftnak és a Khronosnak.
Az API-t nem a hardverhez tervezik. A GCN előnye a dokumentációban és a publikus disassemblerben rejlik. Az, hogy milyen API-t használ a program lényegében mindegy.
Amire a saját API készült az ott van a szabványban. Most jönnek a még nem kezelt dolgok, például VR. Ezek is szabványban kötnek majd ki.
Pont azt kéri az AMD a fejlesztőktől, hogy jöjjenek a kérések. Így tudják megoldani, hogy úgy fejlődjön a piac, ahogy azt ők szeretnék.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az AMD világosan megmondta, hogy csak olyan node-ra állnak át, ami előnyt is jelent, mint például kisebb fogyasztás. A 28 nm SHP-ról a 14 nm LPE nem előnyösebb a fogyasztásban. Az LPP már az és arra át is fognak állni. Ez egyébként érthető. Egy középkategóriás APU-nál nem annyira kritikus a lapkaméret, mert notiba kerül, viszont az számít, hogy kevesebbet fogyasszon. Egy telefonba tervezett SoC-nál a lapkaméret fontosabb és inkább kezelik a többletfogyasztást az alacsonyabb órajellel.
Ezeket a gondokat is kezeli a SPIR-V. Írhattok saját fordítót hozzá.
(#57) GhanBuri Ghan: A legtöbb jellemző változik a gyártói implementációval, tehát ez bonyolult téma nagyon. Nagyban függ a lapka attól, hogy milyen a szoftveres alap. Ez már többet számít, mint maga a csíkszélesség.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
ukornel
aktív tag
Tyúk, vagy tojás probléma, hogy azért olvad a desktop szegmens, mert nincs jelentős előrelépés a SB óta, vagy azért nem oda teszi a fő hangsúlyt az Intel (sem), mert az embereknek elég a meglevő teljesítmény. Nyilván ezek oda-vissza ható okok, melyek eredménye egy spirál, amit az hajt lefelé, hogy a felső szegmensben elfogyott a gyártástechnológia mozgástere.
A lényeg, hogy összességében lassulást látni az Intelnél is. Az ugyanezen az úton járó bérgyártók (és gyártatók) lemaradása pedig csökkent, a 8-10 hónap már előrelépésnek számít. Összességében a pozíciójuk javult (kevésbé rossz). Nem tagadom tehát, hogy van lemaradás, és ez versenyhátrány, de a versenyhátrány csökken.
-

#06658560
törölt tag
A desktop szegmens nem azért olvad, mert elég a teljesítmény- változnak a szokások. elébb a notebookok kezdték faragni, mostanra viszont az abszolút mobil szegmens-smartphone+tablet- a konzolokkal megtámogatva, ami viszi. Ahogy a saját szokásaimat is nézem, a napi nem munka PC használatomhoz egy tablet is tökéletesen elég. És ez rengeteg emberre is igaz.
[ Szerkesztve ]
-
Fiery
veterán
"És lett három low-level API-nk két év alatt."
Semmi bizonyitek ra, hogy a Mantle nelkul nem szulethetett volna meg pontosan ugyanakkorra a masik ketto. De oke, vegyuk ugy, hogy a Khronos balfekek tarsasaga, es az AMD segitsege nelkul tenyleg nem tudtak volna mostanra osszehozni az OpenGL 5.x-et, hanem mondjuk csak 1 evvel kesobb. A DX12 akkor is elkeszult volna ugyanakkorra. De erre meg azt mondod, hogy erre nincs semmi bizonyitek, oke, de az ellenkezojere sincs. A Microsofttol en sosem lattam olyan nyilatkozatot, amiben leirtak volna, hogy pontosan akkor kezdtek el gondolkozni a DX12-n, vagy akkor alltak neki a munkanak, amikor "oriasi meglepodesukre" az AMD lerantotta a leplet a Mantle-rol.
"Az API-t nem a hardverhez tervezik. A GCN előnye a dokumentációban és a publikus disassemblerben rejlik. Az, hogy milyen API-t használ a program lényegében mindegy."
Kar hogy nem ezt irtad anno a Mantle-s cikkedben. Idezek belole, ha nem haragszol:
"A Mantle API azonban más. Ez a rendszer megköveteli a GCN architektúra alapvető működésének ismeretét, ugyanis ez biztosítja a hardver hatékony kihasználását."
"Bár ezekre a Mantle API nem lesz elérhető, de ez a két gép biztosítja, hogy a fejlesztők ismerjék a GCN architektúra működését."
Tehat semmi koze a Mantle-nek a GCN architekturahoz, fuggetlen tole, vilagos.
"Ha bárki előállna egy hasonló, alacsony szintű API-val, akkor nem biztos, hogy érdekes lenne, mégpedig azért, mert a PC-s piacért egyszerűen nem éri meg megtanulni az adott architektúra felépítését, és a GCN architektúrát sem a PC-ért fogják kielemezni és bemagolni."
Innentol egyre viccessebb masfel ev tavlatabol olvasni a cikkedet
"Ez egy nagyon lényeges szempont, ugyanis a Mantle API gyakorlati beépítése az adott alkalmazásba egyszerűnek mondható, hiszen nagyjából két hónap alatt megoldható. A legtöbb időt annak megtanulása viszi el, hogy a GCN-es Radeonokat hogyan kell hatékonyan használni, de a konzolok miatt ez nem jelent majd problémát."
Tovabbra is vilagos, hogy a GCN es a Mantle fuggetlen egymastol

"Magának az API-nak vannak alapvető funkciói, melyek ugyan a GCN architektúrát figyelembe véve lettek megtervezve, de más, modernnek mondható GPU-architektúra által is támogathatók."
Tehat ahogy irod, "Az API-t nem a hardverhez tervezik". Aham, riiiiiiight.
---
"Nem mondta a fejlesztőknek az AMD, hogy ne használják az API-t. Azt mondták, hogy ha szabványosan meg tudják oldani a gondot, akkor ne használják."
Ismet csak az eredeti Mantle-s cikkedbol idezek:
"Johan Andersson úgy gondolja, hogy az Intel és az NVIDIA a sebesség szempontjából a Mantle alapfunkcióinak támogatásával is jobban jár, mintha a szabványos DirectX és OpenGL kódokban bíznának."
Ezt hivja az angol flip-flopnak. Masfel eve az AMD me'g azt szerette volna, ha a konkurencia is az o API-jat tamogatja a szabvanyos feluletek helyett, most meg mar inkabb maradjanak a szabvanynal, mert jo az mindenkinek. Es hiaba jossz nekem azzal, hogy Johan Andersson nem az AMD alkalmazottja, az AMD akkor is ot allitotta szinpadra a Mantle bemutatonal, tehat nyilvan nem ellentetes az o velemenye/allaspontja az AMD-jevel.
[ Szerkesztve ]
-
Abu85
HÁZIGAZDA
De van. Egyrészt a Vulkanhoz az AMD adta oda a forrást. Másképp 2018 előtt nem érkezett volna meg. Ezt az idei GDC-n a Khronos meg is köszönte nekik azzal, hogy kiemelték az AMD szerepét. A DX12-nél Max McMullen mondta még egy évvel korábban, hogy igazából az egészet az AMD indította el azzal, hogy felhozzák a libGCM-et mint koncepciót PC-re. A Microsoft erre azt mondta, hogy ha azt gondolják, hogy ez megoldható, akkor tervezzenek egy prototípust. 2011-re kész lett, működött és erre épül a DX12.
Ahogy írja a cikk is az architektúrát kell ismerni. Ez minden low-level API-ra igaz, hiszen a fejlesztő írja meg azt, ami ma (még) a driverben van.
Viszont az Intel és az NV támogathatja a Vulkan API-t, és az AMD zárva tarthatja a technológiáját, anélkül, hogy bármi kár érné az ipart.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Még annyit, hogy Johan Andersson nyilván fontos szerepet játszott ebben a történetben, mert igazából ő az a személy, aki 2011 végén kikönyörögte az AMD-től, hogy neki külön csináljanak egy API-t, mert 2013 végére szüksége lesz rá. Valószínűleg sejtette, hogy a DX11-ben nem tudja garantálni a Frostbite új verziójának stabilitását, és ez így is lett. Az összes Frostbite 3 játék random lefagyaszthatja a DXGI-t. Tehát, ha ő nem utazik el 2011 végén Torontóba és nem kéri meg Matt Skymert, hogy a Microsoftnak leadott prototípusra építve jöjjön egy saját API is (akkor még nem volt neve), akkor ma csak a DX12 lenne.
A prototípusról egyébként tudott Johan Andersson már 2009-ben, hiszen Guennadi Riguer és Brian Bennett őt kérte fel technikai tanácsadónak.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Fiery
veterán
"De van. Egyrészt a Vulkanhoz az AMD adta oda a forrást. Másképp 2018 előtt nem érkezett volna meg."
Vagy inkabb a Khronos azert nem allt neki 2013-ban (vagy me'g elobb) a Vulkanon dolgozni, mert tudtak, hogy 2015-ben ugyis megkapjak az egeszet az AMD-tol. Hogy a fenebe irhatsz le 2018-at, amikor legrosszabb esetben is 3 ev alatt egy ilyen API-t ossze lehet rakni? Ha a Khronosszal nem volt megallapodas, akkor legrosszabb esetben is a Mantle bemutatojakor elkezdtek volna fejleszteni a Vulkant. Az plusz 3 ev meg 2016 vege, semmikepp sem 2018. Az me'g mindig baromi keson lett volna, ez teny. De ha a 2013-as esemenyeket osszevetjuk az idei esemenyekkel, valamint a 2014-ben megjelent jatekokkal, akkor szamomra eleg egyertelmu, hogy az egesz Mantle-Vulkan-DX12 sztori ugy buzlik, hogy kilometerekrol erezni. Valaki nem mond igazat, mert olyan nincs, hogy a Microsoft is balf*sz, a Khronos me'g nagyobb balf*sz, az nVIDIA+Intel meg plane balf*sz -- es persze az AMD a teljes vilagnak megtanitotta, hogyan kell low-level API-t irni profi modon, jelentos csuszasokkal, be nem valtott igeretekkel. Ilyen egyszeruen nincs, ezt az idei esemenyek alapjan en nem tudom elhinni, nem tudom elfogadni. Nem lehet a teljes vilag minusz az AMD akkora balf*sz, mint aminek beallitod a kommentjeid alapjan. De ha megis igy lenne, akkor meg az AMD-nek mar nem itt kellene tartania, hanem nagyjabol ketszer ennyi Mantle-os jateknal, Mantle 2.0 demonal (masfel ev alatt illett volna elgondolkozni legalabb a Mantle kovetkezo generaciojan, _ha_ tenyleg komolyan gondoltak volna a dolgot anno), es nem adta volna oda a fel vilagnak azt, ami annyira franko, es nem zavarta volna at a fejlesztoket a DX12-re a sajat API-ja helyett. De mindegy is, hagyjuk a francba az egeszet, mert ........ (es itt jott nemi szemelyeskedes, de kitoroltem, mert probalok kulturalt maradni)
[ Szerkesztve ]
-

joysefke
veterán
De baromi unalmas, hogy már egy gyártástechnológiával kapcsolatos topikban is az API-k folynak a csapból...
Bizony hogy baromi unalmas, és nem hiszem, hogy én lennék az egyetlen, aki megcsömörlött a folyamatos:
- API,
-low level API,
-API overhed
-Mantle (pedig ez már halott )
-draw call,
-OpenCL (vagy mi az aktuális sztár),
-compute,
-stb stb
meg úgy általában a majd egyszer-majd amikor piros hó esik majd akkor elemzésekkel. Nyilván ilyenekre is szükség és igény is van egy szakmai oldalon, de valahol mértéket kéne tartani, arányossá kéne tenni az ilyen jellegű írások mennyiségét a dolog fontosságával és aktualitásával/bizonyosságával.Mert az valahogy aránytalan, hogy az írásoknak érzésre 2/3 része ebbe a kategóriába tartozik, más szintén fontos és érdekes témák pedig erősen alulreprezentáltak...
J.
[ Szerkesztve ]
-
-
joysefke
veterán
Jó lenne, ha lehetne mondjuk leadni téma-ötleteket hogy miről szeretnénk olvasni, aztán ha sokan szeretnénk olvasni egy egy témakörről akkor a PH ráállíthatna egy újságírót hogy néha néha dobjon be a nagy API folyamba egy egy a témakörnek megfelelő írást.
Aminek én örülnék, ha erőteljesebben lenne képviselve a PH!-n az elsősorban a vállalati informatikai megoldások témaköre.
-Szerver processzorok: talán egy kicsit jobban körbejárva.
-Szerverek: Ha valamelyik nagy gyártó frissíti az aktuális x64-es szervercsaládját, akkor talán lehetne róla egy átfogó elemzést írni (modellek-kiépítés-feature-ök, összehasonlítás)
-Tárolók (SAN-ok)
-Virtualizáció: Létezik, hogy a nemrég megjelent vSphere 6-ról még egy rövid hírt sem találok sem a PH!-n sem az IT-cafén?J.
[ Szerkesztve ]
-
Abu85
HÁZIGAZDA
Van szerver rovatunk, pár hírt kap havonta. [link]
A vállalati informatikai megoldásokkal az a baj, hogy nem sok embert érdekel itt a PH-n. A szerver rovatban főleg a felhőt, a szuperszámítógépeket, a GPGPU-t és s speci dolgokat kattintja le a PH olvasóbázisa, ezekre rá is álltunk.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
joysefke
veterán
Van szerver rovatunk, pár hírt kap havonta.
A vállalati informatikai megoldásokkal az a baj, hogy nem sok embert érdekel itt a PH-n.
Nyilván Ti (illetve a PH! vezetősége) látjátok az olvasottságot és ennek megfelelően ti tudtok jó üzleti döntést hozni, hogy mire kell ráfeküdni, mit fognak elolvasni (ehhem kattintani) az emberek, illetve milyen tartalom mellett lehet hirdetési felületet eladni.
Én nem ismerem sem az olvasottságotokat, sem a hirdetési piacot, mindenesetre laikusként a következő a meglátásom:
Ha csak néha (értsd amikor piacra kerül egy egy meghatározó termékcsalád) lejönne egy minőségibb cikk, amit a témával foglalkozó csekély kisebbség elolvasna (a többiek egy része pedig remélhetően kattintaná), akkor feltételezem a Fujitsu/IBM/HP etc is a zsebébe tudna nyúlni egy egy zsírosabb hirdetés kedvéért, már csak azért mert a nagyobb magyar IT portálokon a vállalati téma nagyon alulreprezentált (a HWSW- foglalkozik vállalati IT-vel, de szvsz más mélységben) illetve a reménybeli hirdetők (például a fenti három) tudnák hogy az a pár ezer ember akiket ők Magyarországon jó ha megcéloznak hirdetésekkel azok egy jelentős része PH! olvasó és a megfelelő cikk mellé kihelyezett hirdetéssel elég irányítottan lehetne őket elérni. Azért a PH! olvasótáborának sem 100%-a Radeon/Geforce pistike a szomszédból (csak 90
).
Jó persze a vállalati beszerzések általában nem impulzusvásárlások, de azért jelen kell lenni a célcsoport tudatábanTehát nem azt mondom, hogy az APU/API/Mantle folyamot teljes egészében SAN/Blade/Rack/hálózat folyamra kéne cserélni, de bele lehetne szúrni pár másmilyen cikket is.
http://prohardver.hu/teszt/megjartuk_fujitsu_innovacio_roadshow/notebook_szerver.html
Ez mindenről szól, de igazából semmilyen témát nem jár körül, a szerverekről/tárolókról pedig csak érintőlegesen van szó. (olvastam amikor megjelent)
A szerver rovatban főleg a felhőt, a szuperszámítógépeket, a GPGPU-t és s speci dolgokat kattintja le a PH olvasóbázisa, ezekre rá is álltunk.
Szóval a bulvárt...
Bár szerintem érdemes lenne kipróbálni egy két alapos vállalati IT cikket is.J.
[ Szerkesztve ]
-
Abu85
HÁZIGAZDA
Nem véletlen, hogy a vállalati téma alulreprezentált az IT piacon. Egyrészt az olvasóbázist nem érdekli, másrészt egy ideje célzottan mennek rád, illetve a cégekre az érintettek, és kvázi semmilyen hirdetésben nem gondolkodnak. Ezt a Fujitsu rendezvényéről simán látni lehetett. Arra törekedtek, hogy elkérjék az adataidat, és kiderítsék, hogy miben vagy érdekelt. Annyira kevés potenciális ügyfélről van szó, hogy bőven megéri az igényeiket felmérve célzott ajánlatokat tenni eléjük. Ez egyébként nem baj, ha úgy gondolják, hogy roadshow-val lehet ügyfelet nyerni, akkor tegyék meg, mi beszámolunk a roadshowról.
Nem bulvár az. Ezek azok a területek, amelyben nagy a potenciál és megy körülötte a hype. A hype pedig bevonzza az olvasót.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

leviske
veterán
A Samsungnak elvileg ott van tavaly év vége óta a 14nm FinFET LPE, ez teszt szinten miért nem felelt meg egyébként az nVidia és AMD számára? Ennyire eltér az eljárás a LPP-től vagy LPE-n olyan alacsonyabb fogyasztású cuccokat, mint az nVidia GT sorozata vagy épp a Carrizo-L (vagy akár maga a Carrizo) nem lehet legyártani?
Gondolom szerződés erre vonatkozólag nincs a GloFo-val, mert akkor már a konzol APU-k se landoltak volna a TSMC-nél.
(#77) joysefke: Szerintem is érdemes API témáról egy teljesen felesleges vitára váltani, aminek meg már egy az egyben az IT világhoz sincs köze, csak a magánvéleményhez.
-
joysefke
veterán
Szerintem is érdemes API témáról egy teljesen felesleges vitára váltani, aminek meg már egy az egyben az IT világhoz sincs köze, csak a magánvéleményhez.
fyi ami a 77. hsz után jött az nem vita volt, hanem véleménycsere, és szerintem volt legalább annyi értelme, mint egy gyártástechnológiás cikkben az 1001. sehova nem vezető API vitát tolni.
És igen, herótom van már az állandó API-zástól. Totál felül van reprezentálva a téma itt a PH!-n.
J.
[ Szerkesztve ]
-
Abu85
HÁZIGAZDA
Egy volt, ami a PS4-es, és abban nem szerepelt az AMD. Másrészt nem értem mi a probléma. Az iparág történelmének legnagyobb előrelépése zajlik a szemünk előtt. Nem az új hardverektől fog majd leesni a PC-sek álla, hanem az új API-któl.
Egyébként az egész abból keletkezik, hogy a fejlődés nagyjából 8 éve nem normális irányba tart. Azért képesek olyan elképesztő dolgokra a PS3 exkluzív játékok például az AI szempontjából, mert a fejlesztők hozzányúlhatnak a hardverhez. És olyan AI-t, mint ami pár PS3 címben van még csak a fasorból sem láthatunk PC-n, aminek nagyban köze van ahhoz, hogy jó ideje egy zsákutcának a falát támasztjuk.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Fiery
veterán
SDK, API, jatekengine -- en ezeket egy kalap ala veszem a PH kapcsan, plane mivel eleg sokszor van szo az ilyen hirekben mindenfele API-krol
A mai Intel VR-es hir is az SDK/API hianyarol szol, ha nem tevedek, pl. ilyenek vannak a hirben:
"tehát az Intelnek előbb elő kell állnia egy saját grafikus API-val, ami legjobb tudomásunk szerint nem szerepel a tervek között."
Es mintha a WDDM 2.0-s hirben is az SDK, API es jatekengine szentharomsag korul porognenek a dolgok...
A vulkanos hir meg nyilvan nem az AMD-rol szol, kiveve amikor minden mas hirben le kell irni es nyomatekositani, hogy Vulkan = Mantle

"Az iparág történelmének legnagyobb előrelépése zajlik a szemünk előtt."
Ezzel erosen lehetne vitatkozni, pl. sokak szamara, akik megeltek, szerintem sokkal nagyobb koppanas volt az elso Voodoo vagy az elso GeForce, mint az, hogy most X%-kal tobb frame rate-et kapnak majd DX12 alatt, vagy hogy sokkal tobb objektum fog a robbanasnal a kepernyore renderelodni. Ez utobbi amugy se nagyon jott be mar egyszer, ld. Ageia, vagy fogalmazzunk inkabb ugy, hogy nem volt vegul akkora robbanas, mint sokan gondoltak.
[ Szerkesztve ]
-

stratova
veterán
Egy kis fejtágítást kérnék, ha olvasná valaki, aki kompetens a témában
AMD-nél elvileg korábban a CPU HPL-t HDL váltotta, aminek szemmel láthatóan méretcsökkenés köszönhető, noha eddig úgy látszik az elérhető alapórajel is alacsonyabb lett.

E libek kapcsán érdekelne, olyan eltérés ez mint Intel esetében az azonos gyártástechnológia esetén alkalmazott HDC, LVC, HPC?
Intel 22 nm
6T SRAM options in their SoC technology, including
high density / low leakage (HDC), low voltage (LVC), and high performance (HPC)
Intel 14nm (Core M - 14 nm LVC?)
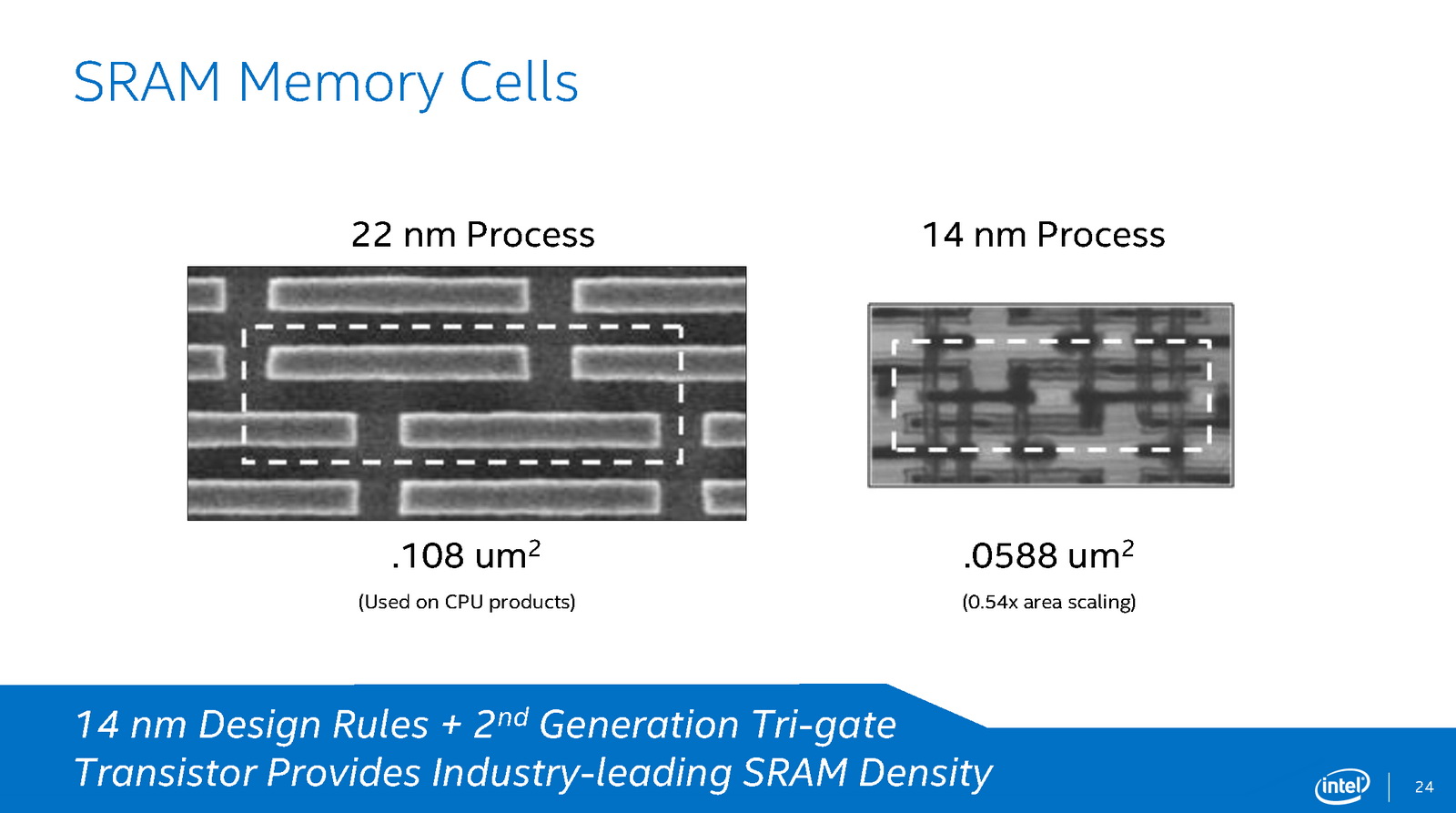
[ Szerkesztve ]
-

P.H.
senior tag
Az iparág történelmének legnagyobb előrelépése a játék? Játék, mint a matchbox, a Monopoly meg a rubikkocka?
Ok, rendben, ennek jelentős(ebb) gazdasági háttere is van, a játékok ma már iparág. Akkor kezeljük is így. Az AMD ebből a szempontból egy szép példája annak, ahogy NEM kellene gazdaságilag kezelni az innovatív ötleteket: például ha a Mantle az előrelépés alapja, akkor
1. vagy ellopták tőle és ezt szó nélkül hagyja (ahogy az Rambus, az Apple vagy a Samsung nem hagyja pl., akármilyen ronda is az állandó pereskedésük),
2. vagy önként adja át másoknak, ami szép dolog, de ezt olyan öngyilkos módon teszi, hogy közben saját maga az innovációs költségeket sem tudja kitermelni; és majd ennek következtében ne adj'isten a jövőben úgy beszélünk róla, mint a VIA-ról (Mini-ITX pl.), a Cyrix-ről (megfizethető x86), a NexGen-ről (RISC86), a DEC-ről (K7/K8/K10 microarch. alapjai az AMD-hez átment mérnököktől), stb.Az Nvidiának volt/van jövőképe (járművek fedélzeti egységei, önvezető járművek), az Intel-nek is (IoT); járműből a világkép szerint egyre több lesz, háztartási eszközökből is, "gyerekből" (játék) meg nem. Az AMD meg áll a GCN meg a HSA-val a kezében, hogy erre is jó, arra is jó, de hogy miért kellene több belőle 5 év múlva, mint most, arra ötlete sincs. Mert ha lenne, mondaná, nem pedig meglevő megoldások újraértelmezését (video, JPEG, ZIP) propagálná, mondván, hogy "majd rákapnak".
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
Abu85
HÁZIGAZDA
Nyilván a gaming iparágra gondoltam. Az 3D-s gyorsítás fennállása óta sosem léptünk akkorát előre.
Egyik sem. Hátsó szándékból adták oda. A legfőbb cél, hogy befolyásolják, hogy merre menjen a Microsoft és a Khronos. Egyszerűen a fejlesztői kéréseket gyorsan beépítik a Mantle-be, és ezzel kikényszerítik a lépést a szabványban is. Függetlenül attól, hogy a hardvergyártóknak az tetszik-e vagy sem a Microsoft és a Khronos lépéskényszerben lesz.
Általában a konzorcium által irányított szabványok legnagyobb gondja, hogy lassan születnek meg. Ezt a problémát az AMD kihasználja, mivel számukra egy funkció beépítése csak egy döntés. Onnan pedig tálcán mehet a forráskód. Ha használják az szuper, mert a Radeon már támogatja. Ha nem használják, akkor az Radeon-only effekteket eredményez.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ettől még az SDK != engine != API
Ha az Intel akar LDL-t és D2D-t, akkor szükségük van egy saját grafikus API-ra. Ezen nem lehet változtatni, mivel az említett dolgokra a szabványos API-kban ma nincs megoldás, és belátható időn belül sajnos nem is lesz. Ezért vezette be ezt a két technikát csak az AMD, illetve a Sony, de nekik ugye fix a hardver.
Nem csak gyorsulás lesz. A legnagyobb előny az, hogy szabadon felhasználható lesz a processzoridő, hiszen eltűnik a kernel driver. Ennek az egyik hozadéka lesz a jobb AI például.
Naná, hogy nem jött be az Ageia. A robbanástól keletkező picike kis darabkák rajzolási parancsba kerülnek, ami drága volt. Másrészt a middleware-ek sosem a teljesítményükről voltak híresek. Ezért akar például az EA mindent saját maga írni.Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
P.H.
senior tag
És megint meg kell kérdeznem: az előrelépés nagyságának elvi mértéke mellett ez gazdaságilag valahol kimutatható?
És ha befolyásolják a Microsoft-ot és a Khronos-t, ettől több hardvert, PC-t, konzolt adnak el a világon? És ha nem, legalább több Radeon-t vagy APU-t? Az x64-nek igenis volt ilyen szemszögből jelentősége.
Mert ha nem, akkor hiába előremutató a dolog, kb. annyi az AMD számára a gyakorlati jelentősége, mint az VIA számára a Mini-ITX mai robbanásszerű terjedése: feljegyezzük, hogy ők találták ki 15 éve. Csak közben eljelentéktelenedtek, pedig nyilván számos előremutató ötlet volt/van még a tarsolyukban. Ez nagyon használ az iparágnak...
Az innováció a gazdagok sportja, mert attól még gazdagabbak lesznek.
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-

sayinpety
tag
Sajnos a Microsoft/Khronos/Intel/Nvidia a kisujat nem mozditotta a problemak megoldasaert. Nem csak az AMD fejet fuzik evek ota, am csak ok hallgatnak rank es megoldasokkal allnak elo.
Balf*szok? Nem. Csak felnek. A Microsoft es Khronos sosem akart explicit APIt PCre. Felnek az outsourcingtol. Joggal. A stabil anyagi hatterrel rendelkezo kiadonk kiszervezte az Intel/Nvidia optimalizalast. A core team csak GCNre fokuszal. Az R&D team zero Intel/Nvidia dev hardverrel rendelkezik. Jartam szomszedos kanadai studioknal. Mindenhol GCNt lattam.
Szamunkra mindegy a verseny. Akkor is eladjuk a szoftvert, ha GCNt hasznal mindenki. Microsoft es Khronos versenyt szeretne.
Intel/Nvidia erthetoen fel. Tudjak hogyan fejlesztik a multi-platform projecteket. A console a dominans faktor.
Egyedul az AMD erdeke az explicit API. A ket console hatalmas elony. A GCNrol mindent tudunk. Maxwellrol igazabol semmit. Intel hatareset, am nem megyunk semmire vele. Annyira gany az µarch, hogy PS4-en 60%ot gyorsito optimalizalas belassitja. Ugyanezzel a koddal AMD es NVIDIA sebesseget nyer.[ Szerkesztve ]
-
#95
hugo chávez
aktív tag
Fiery
#58
hugo chávez
aktív tag
Közben leesett, vagyis azt hiszem, tudom, hogy melyik cégről és a hardverük milyen "képességéről" van szó. Ha jól sejtem, nemrégen meg is említetted ezt a dolgot.
Nos, én messze nem látok bele olyan mélységekben ebbe az egészbe (benchírás, stb.), mint te, ez tény.
"Pl. marhara nem mindegy, hogy egy adott feladatot milyen adattipusokkal, mekkora adat halmazon vegzel, ezeken nagyon sok minden mulik."
Na de ami az egyik hardvernek kedvez, az a másiknak lehet, hogy nagyon nem fog. Akkor? Mi a megoldás? Fusson mindenen egyformán szarul, a legnagyobb közös nevező, vagyis csakis a mindegyik gyártónál egyaránt meglévő képességeket használva, de semmi specifikusat? Vagy mindenre és minden képességre külön optimalizálni, amennyire csak lehet és csak a végrehajtás ideje és/vagy az eredmény számítson, a módja nem, vagyis minden hardveren az annak megfelelő legoptimálisabb módon (az akár specifikus utasításkészleteket, képességeket használva) hajtódjon végre? Mondom, nem értek hozzá, de nézzük pl. a π számolgatós bencheket, mint a Hyper PI is. A feladat adott, konkrét tizedesjegyig kiszámolni a pi-t, minél gyorsabban. De szerintem az már totál lényegtelen, hogy adott hardveren gyártóspecifikus utasításkészleteket vagy egyéb képességeket is használhat, ha történetesen lehet azokra is optimalizálni, vagy a különböző gyártók hardverein akár egymástól teljesen eltérő, az adott hardvernek a legjobban fekvő metódussal hajtódik végre, a lényeg csakis az, hogy a lehető legjobban kihasználva az adott hardver képességeit, mennyi idő alatt végez, illetve, hogy az eredmény egyformán pontos legyen minden hardveren, amin a bench futni fog.
Szóval nem értem, miért baj az, ha egy gyártó ahhoz akar segítséget nyújtani, hogy egy adott bench az ő hardverük képességeit minél jobban ki tudja használni?Vagy most arról van szó, azt akarják, hogy magát a feladatot (nem pedig a végrehajtási módját) igazítsátok a hardverükhöz? De egyáltalán egy bench elkészítésénél mit kell figyelembe venni? Az a fontos, hogy olyasmivel dolgozzon, olyasmit csináljon, ami elterjedt, széles körben használatos? Vagy az, hogy az adott hardver minden képességét megpróbálja kihasználni, akár olyan feladatokkal is, amik végrehajtása a valóságban marginális jelentőségű, csak szűk területen lenne kihasználható?
"Mindegyik_ hardver gyarto ezt csinalja, ezert is visszatetszo szamomra az, hogy nehany gyartot divatos ilyen magatartas miatt utalni (pl. itt a PH forumokon), holott mindegyik gyarto tok ugyanazt csinalja, legfeljebb a nullak szama a kulonbseg, meg a rendelkezesre allo, piacot befolyasolo eszkozok tarhaza. Minden kapitalista ceg arra torekszik, hogy penzt csinaljon, ez a lenyege az egesznek. A piaci verseny is mindannyiukra ugyanugy vonatkozik, es mindegyik remenykedik abban, hogy nem fogja senki eszrevenni, hogy epp melyik versenyzo melyik masik hosszutavfuto versenyzo tarsa cipojebe csempeszett egy rajzszoget
Ergo vagy mindegyiket utalni kellene, vagyik mindegyiket egyforman szeretni. Nincs ertelme kivalasztani egyiket vagy masikat -- de persze megertem a kognitiv disszonancia erejét is "Mások nevében nem nyilatkozhatok ugye, de én leginkább nem azért utálok pár gyártót, mert néha talán etikátlan módszerekkel akarják a termékeiket jobb színben feltüntetni. Hanem azért, amikor szándékosan akadályozzák a fejlődést a piaci részesedésükre, súlyukra támaszkodva. Soha nem voltam AMD fan (sem), de mióta itt a fórumon egyre jobban azt tapasztalom, hogy egyesek pusztán márkafanságból fikázzák az AMD-t, amikor pedig (és most maradjunk elsősorban a PC gamer vonalnál) talán az egyetlen cég (persze ők is a saját érdekükből, ez nem is vitás), aki valóban törődik ezzel a területtel, állnak elő az innovációkkal folyamatosan, akkor azért elszomorodok. Hogy lehet fontosabb a saját érdeküknél ezeknek az embereknek az, hogy az imádott cégük legyen sikeres, az gazdagodjon? Talán mind részvényesek pl. az NV-nél? Nézd, én lesz.rom, hogy az AMD mennyire lesz sikeres, mint cég, mennyit, mennyi pénzt nyer a Mantle-ön, vagy bármelyik API-n, a "low level" irányon, amit elindított. Vagy akár a HSA-n. Engem az érdekel elsősorban, hogy én, mint felhasználó és gamer, mennyit nyerek ezeken a dolgokon.
Lábjegyzetként annyit, hogy kognitív disszonancia nálam pl. nem játszik, mostanáig és jelenleg is Intel procis gépem van és elégedett is vagyok vele. Viszont emiatt az intenzív fikázás miatt azt hiszem, ha a Zen magjai a Sandy (i5 2500, i7 2600) magonkénti teljesítményét fogják hozni hasonló TDP mellett, akkor vevő leszek rá. Annyi azért kell, mert elvek ide, elvek oda, de nem vagyok saját magam ellensége. Viszont a pénzemet inkább egy olyan gyártónak adom, aki, még ha önös érdekből is, de tényleg tesz előremutató lépéseket. Videókártyára meg ez hatványozottan vonatkozik, mert az Intel még hagyján, de az NV-t nem vagyok hajlandó támogatni, amíg ilyen a hozzáállásuk.
"sajnos ez a beszélgetés olyan alacsony szintre jutott, hogy a továbbiakban már nem méltó hozzám" - by Pikari
-
#96
Fiery
veterán
hugo chávez
#95
Fiery
veterán
válasz
hugo chávez
#95
üzenetére
A benchmark fejlesztes kapcsan akkor van gond, amikor nem egy meglevo, kesz otletre huznak ra egy ujabb, optimalizalt megoldast, hanem az otlet maga kerul ugy kidolgozasra, hogy a benchmark egyik vagy masik hardverhez jobban passzoljon. Mondok egy konkret peldat. Koztudomasu, hogy a Maxwell nem jeleskedik az FP64-ben (DP FP, duplapontossagu lebegopontos szamitasok). Ha odamegyek az nVIDIA-hoz, es feldobom neki, hogy irni akarok egy OpenCL 1.x alapu GPGPU benchmarkot, es lenne benne egy csomo FP64 szamitas, az nVIDIA-nak az az erdeke, hogy errol lebeszeljen. Mondhatja, hogy probaljam FP32-vel (hagyomanyos egyszeres pontossagu lebegopontos) megoldani, vagy probaljam minimalizalni az FP64 szamitasok mennyiseget, vagy csinaljak valami teljesen mast. Viszont, ha ugy megyek oda az nVIDIA-hoz, hogy van egy kesz OpenCL kodom, aminel mondjuk valami furcsasagot tapasztalok GeForce-okon (pl. compiler bug vagy compiler sajatossag miatt), az egy teljesen mas kerdes. Ugyanigy, ha irsz egy kodot, ami az integer szamitasokra tamaszkodik, es fejlesztes kozben kikered az AMD velemenyet, ok nyilvan azt mondjak, hogy hajra, tok jo, hiszen a Radeonoknak (GCN) jol fekszik az ilyen kod. Ha viszont az nVIDIA-hoz mesz, ok lehet hogy lebeszelnek rola, vagy megprobalnak arra terelni, hogy maskepp kozelitsd meg a temat, hiszen a Keplereknek nem fekszik az integer kod.
Ezert is a legjobb az, ha az ember (marmint a benchmark fejlesztoje) fejben kitalal egy problemat, amit meg akar oldani benchmarkon keresztul, aminek a megoldasi idejet akarja mérni, es amikor minden fejben ossze van rakva, legfeljebb csak utana megy a hardver gyartohoz erdeklodni, hogy az adott hardveren mikepp lehetne a benchmarkot minel jobban gyorsitani. Ha pl. elore kitalalod, hogy akarsz egy PI szamitast csinalni, AES adat titkositast, hashet szamolni, FFT-t szamolni, es idealis esetben azt is eldontod, mekkora adathalmazon es milyen modon vegzed a benchmarkot, akkor a feladat adott, az A es B pont fix, azon belul lehet csak mozogni. Az adathalmaz merete azert kritikus, mert ugye a CPU-kban es GPU-kban is tobbszintu cache-ek vannak, es nagyon nem mindegy, hogy az adathalmaz teljes egeszeben vagy reszben elfer-e valamelyik cache-ben. Ha elfer, akkor nagysagrendekkel gyorsulhat a benchmark, ill. azokon a hardvereken sokkal kedvezobb lehet az eredmeny, ahol nagyobb a cache. Eleg osszetett kerdes ez, es pont emiatt sem szerencses, ha egy hardvergyarto ad tippeket arra, hogy mikepp kellene benchmarkot tervezned, hiszen sosem tudhatod, melyik javaslat mogott van a gyarto önös erdeke, es melyik olyan javaslat, ami valoban objektiv jotanacs.
[ Szerkesztve ]
-
Abu85
HÁZIGAZDA
Valószínűleg igen. Számomra sokat jelentett, hogy a DA: Inquisitionhoz még ma is elég a Q9550-em, és csak egy ingyenes drivert kellett telepítenem.
Ha befolyásolják a MS-t és a Khronos-t, akkor az állandó előny. Nézd meg most az opcionális funkciókat. Régen alig voltak, mert a konzorcium egyhangúan megegyezett arról, hogy mi lesz. Most tele van opcionális funkcióval mindkét új API.
Nézd a bekötési modelleket. A legjobb szinthez olyan architektúra kell, ami a leírótáblákat direkten a multiprocesszorba tölti be. Van a piacon kb. 7 gyártó, kb. 1x architektúrával, és a bekötési modellt kialakítják egy gyártó egyetlen architektúrájára. Miért? Mert az AMD így adta át, de rajtuk kívül igazából senki más nem akarja ezt, legalábbis úgy nem, hogy kényszerből új architektúrát kelljen tervezniük.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
ukornel
aktív tag
(Úgy látom, elhalt Abu kezdeményezése, hogy az AMD találgatós topikban folytatódjon az API-disputa.)
Egyetértek azzal, hogy lehetne más témákról többet olvasni - bizonyos magyar, vagy külföldi portálokon akad bőven komplementer információ.
Annak viszont semmi értelme, hogy "tiltsuk meg" Abunak, hogy overhead,Mantle,stb témáról ilyen sokat írjon. Akit untat, megcsömörlött, nem érdekli, az nem kattint, és kész!Kíváncsiságból átfutottam a 2015-ös év eddigi híreit az egyes rovatok szerint, és megpróbáltam kategorizálni őket. Érdekességképp, itt van az én nem reprezentatív számolásom:
Életmód rovat - 121 hír, ebből 22 játék, konzol, VR
Videokártya rovat - 120 hír, ebből 65 HSA, CUDA, Vulkan, Mantle, API, VR, gaming, grafika, játék effektek, stb
Egyéb rovat - 68 hír, ebből 16 VR, API, játék, HSA
Adattároló rovat - 42 hír
Processzor rovat - 38 hír
Monitor rovat - 32 hír
Tablet rovat - 25 hír
PC/barebone rovat - 22 hír
Ház/Táp rovat - 19 hír
Memória rovat - 18 hír
Beviteli eszköz rovat - 17 hír
Hálózat rovat - 14 hír
Adattároló rovat - 13 hír
Modding rovat - 12 hír
Hűtés rovat - 9 hír
Szerver rovat - 7 hír
Nyomtató rovat - 3 hír
Összesen - 580 hírMegjegyzendő, hogy kb két héttel ezelőttig fej-fej mellett növekedett az "API" és a hardver kategóriás hírek száma, akkor aztán piszkosul besűrűsödtek ez előbbiek - nem véletlen tehát, hogy most borultak ki a népek.
Ugyanakkor nem látom annyira elviselhetetlenül aránytalannak a Videokártya rovaton belüli ~54%, az összes hír között ~18%-os megjelenést (Physx-estül, CUDA-stul, mindenestül!).
Engem speciel nem hoz lázba, hogy pl az Asus sárga-fehér és piros fekete (vagy mittomén milyen) színű videokártyával ünnepli magát, vagy hogy másik matricával is kiadták ugyanazt a tápegységet.
Tény, hogy a PH! legaktívabb szerzője Abu, neki pedig -úgy tűnik- szakterülete az API téma és játék grafika. Én szívesen olvasok még többet Oliverdától, Daywalkertől, meg a többiektől is, ... ha írnak ők is gyakrabban írnak...[ Szerkesztve ]
-
P.H.
senior tag
Nem tudom, hogy "valószínűleg igen"-ekre meg a "számomra"-kra hogy kell válaszolni, gondolom, nem "valószínűleg nem"-ekkel, meg "számomra nem"-ekkel.
Számomra a Kaveri tökéletes, mert a benne levő GCN számomra pont megfelelő folyamatos 24/7 GPGPU-számításokra 65W-ban, ami egy 7750 önálló fogyasztása CPU nélkül.
Mindenki más meg magasról tesz erre.Hiába mondod újra, hogy állandó előny, én meg harmadszor is megkérdezem, ez az előny gazdaságira is váltható, vagy csak olyan elvi fajta?
1. A Microsoft mindig is pénzért adta, amit megszerzett, a DX-et is (a Windows árában van benne), szóval mivel valószínűleg az AMD nem kapott semmit ezért cserébe, ez veszteséges ügy számukra vagy legalábbis nullszaldós, ha az XBOX-ban használt APU-hoz volt kötve a low-level programozás kidolgozása (ez utóbbi a valószínűbb).
2. Amit az AMD kitalál, ahhoz az Intel-nek közvetlen hozzáférése van, a keresztlicensz-szerződés szerint bárhogy - akár saját néven is - felhasználhatja; ezért pl. egyrészt kérdéses, hogy a HSA-hoz valaki is hozzá fog-e tenni valami érdemlegeset (valószínűleg nem), másrészt a Samsung-nak, a Qualcomm-nak meg a többi kisebb-nagyobb támogatónak valószínűleg 0 fontossággal bír, hogy HSA-val igen jól ki lehet használni az AVXx-et, ez legfeljebb az Intel-t érdekli; innen nézve pedig Fiery forgatókönyve, miszerint megcsinálják ezt házon belül (mivel hozzáférésük van az AMD szellemi termékeihez), teljesen reális, és az is, hogy pont az Intel miatt valószínűleg senki nem fog hozzátenni semmi érdemlegeset.
3. Ez a forgatókönyv már csak azért is valószínű, mert már egyszer lejátszódott a HyperTransport-tal kapcsolatban: ahhoz is csatlakozhatott bárki, szép nagy nevek felsorakoztak, aztán Intel megcsinálta QPI néven, és ma már az AMD is csak többfoglalatos konfigurációkban használja.
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
Abu85
HÁZIGAZDA
Azért az AMD-nek elég sokat jelent, hogy az MS átvette a rendszerük alapjait. Gyakorlatilag már most az a helyzet, hogy az Intelnek és az NV-nek meg kell fontolnia, hogy új architektúrát tervezzen, ha támogatni szeretnék a DX12 legfontosabb funkcióit. Nem tudom, hogy mennyire volt tervben, hogy lemásolják a GCN-t, de mostantól számolni kell ezzel a lehetőséggel, mert nem konzorciumi szinten, széleskörű megegyezéssel születtek meg az új szabványos API-k. Hogy gazdasági előnyre váltható-e, hogy az AMD aszinkron shader tesztprogramja a Hawaii-on ~40%-ot gyorsul, míg a GM204-en csak ~10%-ot, azt mondom, hogy igen. Azért 30% extra csak szoftverből nem elhanyagolható.
Na most a HSA nem az AMD-é, hanem a HSA alapítványé. Ahhoz a hozzáférést úgy lehet megszerezni, ha a HSA alapítvány tagja lesz az adott cég.
A szellemi tulajdon felhasználása teljesen más, mint köré írni egy kompletten új virtuális ISA-t, illetve az egyéb elemeket. Illetve számításba kell venni, hogy az Intel mit tud extraként adni a HSA-hoz képest. Oké tegyük fel, hogy készítenek egy virtuális ISA-t, ami képes legalább olyan hatékonyan kódot fordítani AVXx-re, mint a HSA runtime legacy módja. Miért válassza a fejlesztő az Intel megoldását, amikor a HSA-val ugyanazt megkapja Intelen és még eléri a piac többi részét is, beleértve az androidos érintetteket. Sőt, egy dolgot ne felejtsünk el. Az Intel dokumentálja az IGP-it. Ezek felhasználásával lényegében bárki tud írni egy Finalizert a Gen8 és Gen9 IGP-ikre. Még ha nem is akarják támogatni a HSA-t, maga a platform annyira nyílt, hogy megcsinálhatja helyettük akár a MESA, vagy bárki más. Ezért nem látom az értelmét a HSA lemásolásának, mert két év múlva kínálnának a fejlesztőknek egy olyan dolgot, amelyet ma is megkapnak mindenféle hátrány nélkül. Most fejlesztőként te melyiket választanád, ami ugyanarra képes, és mindenen megy, vagy ami szintén ugyanazt tudja és csak az Intelre jó? Ráadásul utóbbi gondolom zárt lenne, mert nyíltat felesleges bedobni. A HSA-nál nyíltabbat nem lehet tervezni.A HyperTransport főleg egy hardveres technológia. Nem szükséges hozzá az, hogy a programozók is jónak találják.
Egyébként, ha véleményt mondhatok, akkor az Intelnek az ISPC jobb támogatását kellene átgondolni. Az baromira hasznos lenne számukra, de eléggé mostohán kezelik, lényegében egy közösség biztosítja rá a támogatást, ami nem elég jó.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
P.H.
senior tag
Elhiszem, hogy az AMD-nek sokat jelent, és a többi gyártó lépéshátrányba került, én azt kérdezem megintcsak, hogy az AMD-nek jelent-e ez gazdasági előnyt.
Az Intel és az NV legrosszabb esetben 1-2 éven belül előáll DX12-es hardverrel, a 40% meg most került elő; tudnak erről a vásárlók? (Mondjuk egy GrassFX-szel meg HairFX-szel meg kutyafarkszőrFX-szel nehéz is meggyőzni őket).A HSA-val kapcsolatban álljuk meg egy percre: ugye a HSA az egy Eszközkezelőben megjelenő új hardver:
"A gyártóktól megtudtuk, hogy az érkező új BIOS telepítése után minden Kaveri APU-t tartalmazó rendszerben megjelenik majd egy új hardverelem az eszközkezelőben (64 bites Windows 7 és Windows 8.1-es operációs rendszeren), ami az AMDHSA nevet viseli. Erre természetesen lesz egy eszközillesztő, amit telepítve ez az elem felveszi az AMD HSA (with WDDM) nevet, illetve a már meglévő AMD IOMMU Device is AMD IOMMUv2 Device névre vált. Ez azt jelenti, hogy a rendszer az új BIOS és az új meghajtó telepítése után képes lesz kezelni a HSA Runtime szoftvert, így az már telepíthető úgy, hogy a futtatási környezet felismerje, hogy ez egy HSA-t támogató APU, azaz beállítja az alkalmazások gyorsítására vonatkozó módokat."
http://prohardver.hu/hir/frissitett_kaveri_apu_jonnek_asztali_piac.htmlNo most mivel mindketten tudjuk, mi az a HSA, érveljünk amellett, és az ellen is, hogy ez szoftver (ezáltal a HSA alapítványé) vagy hardver (ezáltal, mint az eszköz neve is sugallja, az AMD-é, és így vihető az Intel által). Parttalan vita lesz, előre bocsátom, és jogi kérdésként se egyszerű.
Pl. az Eszközkezelőben való megjelenése miatt a HSA is pont olyan technológia, mint a HyperTransport (az is megjelenik ott), szóval hogy idézzelek, a HSA-val kapcsolatban sem "szükséges hozzá az, hogy a programozók is jónak találják."Továbbá miért gondolod, hogy aki PC-re (azaz asztalra vagy szerverre) fejleszt (nem játékot), azt automatikusan érdeklik az Androidos termékek is? Legalábbis a kijelzők mérete (_nem_ felbontása) vagy a számítási kapacitás korlátozottsága miatt sok olyan dologra nem alkalmas egy alapvetően hordozható eszköz, amire egy fix hardver igen. Azoknak sokkal hasznosabb egy olyan "HSA-klón", ami kifejezetten CPU-ra (és elterjedtsége okán az se baj, ha Intel CPU-ra vagy Intel CPU+GPU-ra) dolgozik.
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
Abu85
HÁZIGAZDA
Hogyne jelentene gazdasági előnyt, ha a többi gyártó számára egy olyan irányt kell követni, amire nem is készültek. Azért az olyan dolgokat, mint az aszinkron compute vagy a teljes bindless nem olyan könnyű lekövetni. Az Intel a GDC-n az aszinkron compute kapcsán elmondta, hogy elvben támogatják, de kikapcsolják, mert a magának az architektúrának az alapvető dizájnja miatt használhatatlan. A Gen8 a compute feladatokat egy teljesen egyedi hardverállapotban futtatja, vagyis kell a kontextusváltás, illetve a megnövekedett terhelés azt eredményezi, hogy a turbó helyett az alapórajelre kényszerül a rendszer. Ezt egyébként az MS és a Khronos is látja. Ilyen korábban nem fordulhatott volna elő, mert az aszinkron compute ötletét az NV és az Intel csípőből leszavazta volna. Most az elkövetkező 3-4 évre elvették tőlük az esélyt, hogy legyőzhessék az AMD-t, mert nem lehet csak úgy a semmiből előállni egy olyan architektúrával, amely hardverállapottól függetlenül futtat compute-ot, amelyben szeparált OOO logikával dolgozó compute parancsprocesszorok vannak, amelyben gyors a kontextusváltás, amelyben a leírótáblákat nem a mintavételezőkbe, hanem a multiprocesszorokba kötik be, és még a multiprocesszorok ki is vannak tömve regiszterrel. Ezek nagy részéhez egy közel nulláról felépített dizájn kell, különben nem lesz hatékony. Ott a Maxwell 2 esete. Támogatja az aszinkron compute-ot, csak közelében sincs annak a sebességelőnynek, amit a GCN nyer ebből, és ehhez nagyban hozzájárul az, hogy csak hirtelen került elő ez a lehetőség, amit támogatni kellett. Ráadásul a teljes bindlesst még semmi sem támogatja a GCN-en kívül. Ahhoz egy olyan multiprocesszor kell, ahol egy skaláregység végzi a feladatok előkészítését. Csúnyán fogalmazva processzorosítani kell a GPU-t, hogy csak a memória limitálja az erőforrás-használatot és ne a különböző formátumtámogatásra vonatkozó egyedi korlátok. És akkor még nem beszéltünk arról, hogy mik vannak tervben következő lépésként, amelyekről szintén nem kérdezték meg az Intelt és az NV-t. Például az egyik realista irány a szoftveres interpolálás bevezetése, hogy a raszterizált háromszög vertex adatait a pixel shader kiolvashassa az LDS-ből. Egyetlen architektúrát dizájnoltak erre a modellre, mégpedig a GCN-t, viszont a konzolokból kiderült, hogy rengeteg fejlesztő olyan analitikai élsimítást csinál, amely erre a képességre épít, vagyis hozni kellene PC-re, különben nem menthetők át az új generációs élsimítási algoritmusok. Persze nem kötelező támogatni, csak hány ember fogja elfogadni, hogy Radeonon van élsimítás, míg a többi hardveren nincs. Ez megint egy olyan döntés, amibe az MS és a Khronos belekényszerít mindenkit. Hogy az AMD-nek menni fog, naná, hozzávetőleg 6-7 éve manuális interpolációt használnak, míg a többiek ezen még csak nem is gondolkodtak eddig. Lehetséges a megvalósítás már a mai hardvereken is, csak azért nem mindegy, hogy a hardvert erre a képességre rátervezed ráadásul úgy, hogy 6-7 éve ismered mik a problémák, vagy csak szimplán írnak egy olyan fordítót, amely így működik, de közben felboríthatja a hardver működését. Ezek a kikényszerített, megbeszélés nélküli irányok igazából egyetlen cégnek jók, és az nagyon biztos, hogy az AMD-n kívül ezeknek senki sem örül. A cégeknek is át kell tervezni a jövőbeli lehetőségeket. Eddig azért tudtak arra építeni, hogy váratlant az MS és a Khronos nem lép, vagyis szépen minden át lesz beszélve, kellő időt hagynak a hardveres implementálásra, stb. És most már közel sem ilyen rózsás a helyzet. Amit nem tudnak átbeszélni, vagy nem tudnak róla megegyezni, azok is jönnek opcionális funkcióként. És ez a modell, ami az AMD-nek nagyon kedvező, hiszen ők azt mondják most, hogy amíg ti beszélgettek, addig mi és a fejlesztők egy csoportja bedobja az új igényeket a Mantle-be, és tálcán, leszegett fejjel szállítják a forráskódot a konzorciumnak beépítésre. Ez abszolút a rendszer gyengeségének kihasználása, csak korábban ez senkit sem érdekelt, mert mindenki ott ült és egyezkedett, de most már megváltozott a sztátuszko, mert az AMD úgy döntött, hogy amíg a traccsparti megy, addig ők inkább cselekszenek. Ez nagyon sok konkurensnek böki a szemét és az majd egy érdekes dolog lesz, hogy ki meddig fest az arcára mosolyt azért, hogy kívülről azt a látszatot keltsék, hogy minden rendben van, vagy ki az aki pont ugyanerre az útra lép, ami végül a szabvány szétbomlását hozhatja.
Várj egy picit. Ha azt mondod, hogy a hardveres alapokat másolhatja le az Intel, akkor azokat már részben lemásolta. A Broadwellben olyan IOMMU (jó tudom az Intel másképp hívja, de ugyanarra szolgál), amit a HSA igényel. Persze az IGP abszolút nem felel meg számos direktíva kiszolgálásának gondolva itt a platform atomicsra és a hard preempcióra, multi-user modellre meg aztán pláne nem ajánlott, de működhet. Viszont tegyük fel, hogy csinálnak egy copyHSA-t (most hívjuk így). És akkor lesz egy lényegében ugyanolyan képességű nyílt HSA és egy zárt copyHSA a piacon. Mennyi haszna lesz ebből az Intelnek? Igazából nem sok. Az AVXx célzása a nyílt HSA-val is megoldható ugyanolyan hatékonyan, tehát a copyHSA lényege csak az IGP elérése lenne (úgy, hogy ne kelljen hozzá a community közbenjárása). És akkor most a fejlesztők. Ír mondjuk valaki egy Java alkalmazást Stream API-val és Lambda Expressionnel. Abból a Java9 JVM fordít egy HSA-hoz megfelelő kódot, míg az Intel kiad egy saját JVM-et, ami fordít copyHSA kódot. Mi történik? Lényegében ugyanaz, az IGP befogható, de ahhoz, hogy ebből az Intelnek előnye legyen azért jóval jobb architektúrára lenne szüksége. Főleg ki kellene műteni a co-issue modellt az EU-kból, ami már eléggé elavult, a grafikában is egyre ritkábban van előnye, compute-ban meg pláne. És akkor még ott van a többi hatékonyságra vonatkozó funkció. Azért senki se gondolja, hogy a hard preempció egy GPU-nál egyszerű, ami viszont baromira fontos fícsőr, mert ha hozunk ilyen alkalmazásokat, akkor jó esély van rá, hogy idővel kettő, három program is egymás mellett fut, vagyis eléggé nem mindegy, hogy melyik kap prioritást. Nem szeretné látni a user, hogy a grafikai program sok ms-ra leáll csak azért, mert a feldolgozásra váró feladatnak meg kell várnia, a többi program éppen feldolgozás alatt álló feladatát. A multi-user meg aztán pláne problémás. És persze hozhatunk OpenCL alkalmazást is, ott is lényegében ugyanez történne. Tehát az Intel sem hagyja figyelmen kívül, hogy az AMD integrációja, illetve maga a GCN architekturális dizájnja még mindig sokkal-sokkal jobb, mint amivel ők rendelkeznek, és ez felerősödik, amikor több HSA/copyHSA programot futtatsz. Azt nem tudom, hogy mik az Intelnek a hosszútávú tervei hardveresen, de a mostani GPU-dizájnjukat záros határidőn belül cserélni kell, mert eddig sem volt hatékony, és egyre kevésbé lesz az. Már csak azért is fontos ezen elgondolkodni, mert ma a hatékonyságot óriási gyorsítótárakkal próbálják fenntartani, vagyis ők ugyanazt a teljesítményt sokkal nagyobb lapkaterületbe rakják bele, a tudást pedig kihagyják, mert nincs több tranyóbüdzsé rá, és ez megint egy olyan dolog, ami miatt nem feltétlenül jó nekik, ha a fejlesztők az IGP-t vadul elkezdik használni.
Emlékszem egyébként még pár éve, amikor Németországban volt alkalmam beszélni a Sandy Bridge IGP-jének tervezőjével, aki elmondta, hogy a turbó itt a kulcs, mert az akkori játékok is csak 30-40%-ra terhelték az IGP-t és volt lehetőség turbózni. És úgy mondta, hogy a jövőben ez még rosszabb lesz, mivel 20-30%-ra számít amiatt, hogy a fejlesztők egyre kevésbé fognak optimalizálni. Na ez nem jött be, és az új API-kkal még rosszabb irányba fordulnak a dolgok. Tehát annak a dolognak, amire feltették az egész tervezési koncepciójuk sikerességét hátat fordított a szoftveripar.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#103
hugo chávez
aktív tag
Fiery
#96
hugo chávez
aktív tag
Jó, de az természetes, hogy minden gyártó azt szeretné, ha az ő hardvere valamiben jobb, mint a konkurenciáé, akkor azt a valamit ki is lehessen domborítani. Ha most egy bench ezt teszi, az szerintem nem baj még önmagában. Említetted pl. az AES-t. Oké, hogy jelenleg mindkét nagy gyártó újabb CPU-iban van direkt támogatás, de ha nem lenne az egyikben, akkor már ne is írjon senki olyan bench-et, ami a másikénál ezt a támogatást ki tudja használni,? Vagy ott van pl, az AVX. Köztudott, hogy az AMD procik ebben jóval gyengébbek, mint az Intelek. Akkor az már tisztességtelen, ha az Intel megemlíti egy fejlesztőcégnek, hogy segítene optimalizálni, vagy akár írni egy bench-et kifejezetten 256 bites AVX-re?
""Ezert is a legjobb az, ha az ember (marmint a benchmark fejlesztoje) fejben kitalal egy problemat, amit meg akar oldani benchmarkon keresztul, aminek a megoldasi idejet akarja mérni, es amikor minden fejben ossze van rakva, legfeljebb csak utana megy a hardver gyartohoz erdeklodni, hogy az adott hardveren mikepp lehetne a benchmarkot minel jobban gyorsitani."
Az a baj, hogy ettől még simán kedvezhet akaratlanul is egy adott architektúrának az adott bench.
"es idealis esetben azt is eldontod, mekkora adathalmazon es milyen modon vegzed a benchmarkot, akkor a feladat adott..."
Ezt a részt nem lehetne úgy csinálni, hogy külön minden hardvernek a legoptimálisabb módon/adathalmazon? Végül is a végeredmény (vagyis hogy egyezzen minden hardvernél), illetve az annak eléréséhez szükséges idő a lényeg, nem?
"ill. azokon a hardvereken sokkal kedvezobb lehet az eredmeny, ahol nagyobb a cache."
Na jó, de ez is egy olyan dolog, hogy oké, nagyobb a cache, de nem véletlenül pakolták oda a plusz tranyókat. Most, ha az egyik gyártó CPU-jában teszem azt kétszer akkora teljesítményű az FPU, akkor már ne is használjunk olyan bench-et, ami nagyon épít az FPU-ra? Ha valamelyik hardver elhasal, mert nem bírja a tempót valamelyik részegység, az nem a bench írójának hibája, hanem a gyártóé. Persze, ha nincs megfelelően optimalizálva az adott bench, az már más eset...
"Eleg osszetett kerdes ez..."
Amennyire belelátok így nagyon felületesen, valóban nagyon összetett. Igazából itt nem is lehet szerintem objektívnek lenni.
"es pont emiatt sem szerencses, ha egy hardvergyarto ad tippeket arra, hogy mikepp kellene benchmarkot tervezned, hiszen sosem tudhatod, melyik javaslat mogott van a gyarto önös erdeke, es melyik olyan javaslat, ami valoban objektiv jotanacs."
Azt hiszem értem a problémát és persze amikor a gyártó ad tippet, amögött minden bizonnyal az a szándék van, hogy az ő termékén jó gyors legyen a bench. Igazából az lehet itt a nehéz, hogy, amint mondod is, simán ki lehet hegyezni egy bench-ben elvégzendő feladatot, vagy akár csak annak bizonyos "végrehajtási paramétereit" egy adott architektúrára. És itt lép be az, hogy ugyanezt a feladatot más paraméterezéssel más architektúrák mennyire gyorsan lennének képesek végrehajtani, illetve, ha már maga a feladat is kifejezetten az adott architektúrához van szabatva a gyártó által, akkor ennek a konkrét feladatnak mekkora gyakorlati jelentősége lenne a bench-en kívül? Az előbbi nyilván jócskán adna plusz melót a fejlesztőnek, az utóbbi meg szerintem nagyon szubjektív dolog...
De lehet, hogy totál rosszul látom, sajna nem nagyon értek a programozáshoz.
[ Szerkesztve ]
"sajnos ez a beszélgetés olyan alacsony szintre jutott, hogy a továbbiakban már nem méltó hozzám" - by Pikari





 De hat ez van...
De hat ez van...

 Me'g a vegen beallit valaki a zold sarokba.
Me'g a vegen beallit valaki a zold sarokba.



 Ergo vagy mindegyiket utalni kellene, vagyik mindegyiket egyforman szeretni. Nincs ertelme kivalasztani egyiket vagy masikat -- de persze megertem a kognitiv disszonancia erejét is
Ergo vagy mindegyiket utalni kellene, vagyik mindegyiket egyforman szeretni. Nincs ertelme kivalasztani egyiket vagy masikat -- de persze megertem a kognitiv disszonancia erejét is 








![;]](http://cdn.rios.hu/dl/s/v1.gif)









Új hozzászólás Aktív témák

ph A vállalat jól halad a 14 nm-es LPE node bevezetésével, amelyre akad jelentkező is.

- PlayStation 4/Slim/Pro konzolok teljes karbantartása, pasztázással Thermal Grizzly 1 órán belül!!
- XBOX360/One/One S/One X konzolok teljes karbantartása, pasztázással Thermal Grizzly 1 órán belül!
- XBOX Series S / X HDMI csatlakozó csere, 1 napos határidővel, 3 hónap garanciával, üzletben!!
- XBOX ONE S/X HDMI IC csere aznapi elkészüléssel, 3 hó garanciával, üzletben!
- PlayStation 5 / PlayStation 4 Fat/Slim/Pro HDMI IC / csatlakozó szerviz, garanciával, üzletből!