Hirdetés
Aktív témák
-
#50
 t3rm1nat0r
csendes tag
t3rm1nat0r
#49
t3rm1nat0r
csendes tag
t3rm1nat0r
#49
t3rm1nat0r
csendes tag
válasz
 t3rm1nat0r
#49
üzenetére
t3rm1nat0r
#49
üzenetére
Az eredmény magáért beszél.
A csővezetékkel párhuzamosan futnak a véletlenszerűen kiválasztott értékek, amiket össze kell majd szorozni.
Itt már látható a vektorprocesszor üresjárata. Nem ad eredményt addig, míg fel nem töltődik adattal. Pedig a 128. elemtől kezdem, ami az első két véletlen szám helye. Azért nem nullától, mert a pipelineban visszafele vannak az értékek. Előrébb vannak, amik régebben belekerültek.
De amikor az első adat elérte a csővezeték végét, utánna már minden ciklusban kapok egy eredményt.0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0000000000000000= 0 cr= 0 0 * 0 = 0
0100111110101010= 20394 cr= 0 103 * 198 = 20394
0010111100101011= 12075 cr= 0 105 * 115 = 12075
0101000010101111= 20655 cr= 0 81 * 255 = 20655
0100010000111000= 17464 cr= 0 74 * 236 = 17464
0010000011010101= 8405 cr= 0 41 * 205 = 8405
0111110000111110= 31806 cr= 0 186 * 171 = 31806
1110110101000110= 60742 cr= 0 242 * 251 = 60742
0011111000010010= 15890 cr= 0 227 * 70 = 15890
0101110111111000= 24056 cr= 0 124 * 194 = 24056
0101000101100000= 20832 cr= 0 84 * 248 = 20832
0001100001111000= 6264 cr= 0 27 * 232 = 6264
0111111100111011= 32571 cr= 0 231 * 141 = 32571
0010100101111100= 10620 cr= 0 118 * 90 = 10620
0001000111001010= 4554 cr= 0 46 * 99 = 4554
0001111110101101= 8109 cr= 0 51 * 159 = 8109
0111100011101010= 30954 cr= 0 201 * 154 = 30954
0001001111101100= 5100 cr= 0 102 * 50 = 5100
0000100101001011= 2379 cr= 0 13 * 183 = 2379
0001000011011000= 4312 cr= 0 49 * 88 = 4312
0011100101001110= 14670 cr= 0 163 * 90 = 14670
0000110101110001= 3441 cr= 0 37 * 93 = 3441
0000000001110011= 115 cr= 0 5 * 23 = 115
0101000000011000= 20504 cr= 0 88 * 233 = 20504
0100110111011000= 19928 cr= 0 94 * 212 = 19928
0111011011100110= 30438 cr= 0 171 * 178 = 30438
1001111010001110= 40590 cr= 0 205 * 198 = 40590
0110110011111100= 27900 cr= 0 155 * 180 = 27900
0000010110010100= 1428 cr= 0 84 * 17 = 1428
0000011100011100= 1820 cr= 0 14 * 130 = 1820
0001110101110100= 7540 cr= 0 116 * 65 = 7540
0000011111011101= 2013 cr= 0 33 * 61 = 2013
0111010000000100= 29700 cr= 0 220 * 135 = 29700
0110010111110000= 26096 cr= 0 112 * 233 = 26096
0010011011111110= 9982 cr= 0 62 * 161 = 9982
0011100100100001= 14625 cr= 0 65 * 225 = 14625
0110010101100100= 25956 cr= 0 252 * 103 = 25956
0000000000111110= 62 cr= 0 62 * 1 = 62
0100101001010010= 19026 cr= 0 126 * 151 = 19026
1100100100011000= 51480 cr= 0 234 * 220 = 51480
0011111010110010= 16050 cr= 0 107 * 150 = 16050
0001111101001000= 8008 cr= 0 143 * 56 = 8008
0000111100011000= 3864 cr= 0 92 * 42 = 3864
1010001001000000= 41536 cr= 0 236 * 176 = 41536
0011100111011001= 14809 cr= 0 59 * 251 = 14809
0010001000101110= 8750 cr= 0 50 * 175 = 8750
0001001110110000= 5040 cr= 0 60 * 84 = 5040
0001011000100000= 5664 cr= 0 236 * 24 = 5664
0100111010110100= 20148 cr= 0 219 * 92 = 20148
0000000000110100= 52 cr= 0 2 * 26 = 52
0100001001111010= 17018 cr= 0 254 * 67 = 17018
1111010100011110= 62750 cr= 0 251 * 250 = 62750
0010011010000100= 9860 cr= 0 170 * 58 = 9860
0010100000110011= 10291 cr= 0 251 * 41 = 10291
1011101111000110= 48070 cr= 0 209 * 230 = 48070
0000000100101100= 300 cr= 0 5 * 60 = 300
0100011110110000= 18352 cr= 0 124 * 148 = 18352
0110001010111000= 25272 cr= 0 117 * 216 = 25272
0100011111111110= 18430 cr= 0 190 * 97 = 18430
1000010101000001= 34113 cr= 0 137 * 249 = 34113
0100001100110100= 17204 cr= 0 92 * 187 = 17204
0110010001101000= 25704 cr= 0 168 * 153 = 25704
0000100010111011= 2235 cr= 0 15 * 149 = 2235
1010001001111011= 41595 cr= 0 177 * 235 = 41595
1010100010000011= 43139 cr= 0 241 * 179 = 43139
0000010010101011= 1195 cr= 0 5 * 239 = 1195 -
#49
t3rm1nat0r
csendes tag
t3rm1nat0r
#48
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#48
üzenetére
De ha már belekezdtem, akkor legyen itt a teljes szorzo.
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int pipeline[128][32];
int parameter[256][2][8],szam[256][2];
int adder_tablazat[4*4*2][4];
int main()
{
int c,i,j,k,l,mask;
for(c=0;c<2;c++)//carry
for(i=0;i<4;i++)
for(j=0;j<4;j++)
{
int osszeg=i+j+c;
int addr=c*16+i*4+j;
mask=1;
for(k=0;k<3;k++) {adder_tablazat[addr][k]=((osszeg & mask)>>k);mask<<=1;}
}
for(c=0;c<2;c++)//carry
for(i=0;i<4;i++)
for(j=0;j<4;j++)
{
int osszeg=i+j+c;
mask=1;
printf("%d + %d + %d =%d ",i,j,c,osszeg);
for(k=0;k<3;k++) printf("%d",adder_tablazat[c*16+i*4+j][2-k]);
printf("\n");
}
for(j=128;j<256;j++)//eleje ures
{
szam[j][0]=rand()%256;//veletlen ertekeket szoroz ossze
szam[j][1]=rand()%256;
mask=1;
for(k=0;k<8;k++) {parameter[j][0][k]=(szam[j][0] & mask)>>k;mask<<=1;}
mask=1;
for(k=0;k<8;k++) {parameter[j][1][k]=(szam[j][1] & mask)>>k;mask<<=1;}
}
int pl=8*8+1;
int plp=128;//elso elem
for(l=0;l<pl*2;l++)//ciklus
{
//if(l==pl-1)//csak a vegen irja ki
{
// for(j=0;j<pl;j++)
j=pl;
{
mask=0x8000;
int bits=0;
for(k=0;k<16;k++)
{
int bit=pipeline[j][15-k];
printf("%d",bit);
if(bit) bits|=mask;
mask>>=1;
}
printf("= %d ",bits);
printf(" cr= %d ",pipeline[j][20]);
int p=(plp-j);
printf("%d * %d = %d ",szam[p][0],szam[p][1],szam[p][0]*szam[p][1]);
}
printf("\n");
}
mask=1;
for(k=0;k<32;k++) pipeline[0][k]=0;//mindig nullaval kezd
int plp2=plp-pl;
plp++;
for(j=pl;j>=0;j--)//csovezetek
{
int j2=j&7;//8 16-bites adder
int bit_offset=j>>3;
int p=plp2;
plp2++;//a kovetkezo fokozatban regebbi van,j visszafele megy
for(k=0;k<16;k+=2)
{
if((k>>1) == j2 )
{
int bita0=pipeline[j][k];
int bita1=pipeline[j][k+1];
int bitb0=0;
int bitb1=0;
int carry=pipeline[j][20];
if(j2==0) carry=0;//adder start
int d=k-bit_offset;
if(d>=0 && d<8) bitb0=parameter[p][1][d];
d++;
if(d>=0 && d<8) bitb1=parameter[p][1][d];
if(parameter[p][0][bit_offset]==0) //0-val szoroz
{
bitb0=0;
bitb1=0;
}
int addra=(bita1<<1)+bita0;
int addrb=(bitb1<<1)+bitb0;
addra=(carry<<4) + (addra<<2) + addrb;
pipeline[j+1][k ]=adder_tablazat[addra][0];
pipeline[j+1][k+1]=adder_tablazat[addra][1];
pipeline[j+1][20 ]=adder_tablazat[addra][2];//carry
}
else
{
pipeline[j+1][k] =pipeline[j][k];
pipeline[j+1][k+1]=pipeline[j][k+1];
}
}
}
}
return 0;
} -
#48
t3rm1nat0r
csendes tag
t3rm1nat0r
#47
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#47
üzenetére
Ez még nem a teljes megoldás.
Ahhoz a parameter[] tömbből is csővezetéket kell építeni, ekkor a szam1 és a szam2 minden ciklusban más értékű lehet.
A vektorprocesszor lényegét akartam megmutatni, és az így jobban látszik, nincs túlbonyolítva az egész. -
#47
t3rm1nat0r
csendes tag
t3rm1nat0r
#46
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#46
üzenetére
A kimenő értékek.
135 * 212 = 28620
0 + 0 + 0 =0 000
0 + 1 + 0 =1 001
0 + 2 + 0 =2 010
0 + 3 + 0 =3 011
1 + 0 + 0 =1 001
1 + 1 + 0 =2 010
1 + 2 + 0 =3 011
1 + 3 + 0 =4 100
2 + 0 + 0 =2 010
2 + 1 + 0 =3 011
2 + 2 + 0 =4 100
2 + 3 + 0 =5 101
3 + 0 + 0 =3 011
3 + 1 + 0 =4 100
3 + 2 + 0 =5 101
3 + 3 + 0 =6 110
0 + 0 + 1 =1 001
0 + 1 + 1 =2 010
0 + 2 + 1 =3 011
0 + 3 + 1 =4 100
1 + 0 + 1 =2 010
1 + 1 + 1 =3 011
1 + 2 + 1 =4 100
1 + 3 + 1 =5 101
2 + 0 + 1 =3 011
2 + 1 + 1 =4 100
2 + 2 + 1 =5 101
2 + 3 + 1 =6 110
3 + 0 + 1 =4 100
3 + 1 + 1 =5 101
3 + 2 + 1 =6 110
3 + 3 + 1 =7 111
0000000000000000= 0 cr= 0
0000000000000000= 0 cr= 0
0000000000000100= 4 cr= 0
0000000000010100= 20 cr= 0
0000000011010100= 212 cr= 0
0000000011010100= 212 cr= 0
0000000011010100= 212 cr= 0
0000000011010100= 212 cr= 0
0000000011010100= 212 cr= 0
0000000011010100= 212 cr= 0
0000000011011100= 220 cr= 0
0000000011111100= 252 cr= 0
0000000001111100= 124 cr= 1
0000001001111100= 636 cr= 0
0000001001111100= 636 cr= 0
0000001001111100= 636 cr= 0
0000001001111100= 636 cr= 0
0000001001111100= 636 cr= 0
0000001001111100= 636 cr= 0
0000001001001100= 588 cr= 1
0000001011001100= 716 cr= 0
0000000111001100= 460 cr= 1
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000010111001100= 1484 cr= 0
0000011111001100= 1996 cr= 0
0000111111001100= 4044 cr= 0
0010111111001100= 12236 cr= 0
0110111111001100= 28620 cr= 0 -
#46
t3rm1nat0r
csendes tag
t3rm1nat0r
#45
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#45
üzenetére
..és íme a csoda..
ehhez hasonlóan dolgozik a geforce/ati-nk.#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int pipeline[128][32];
int parameter[2][8];
int adder_tablazat[4*4*2][4];
int main()
{
int c,i,j,k,l,mask,szam1=135,szam2=212;
printf("%d * %d = %d\n",szam1,szam2,szam1*szam2);
for(c=0;c<2;c++)//carry
for(i=0;i<4;i++)
for(j=0;j<4;j++)
{
int osszeg=i+j+c;
int addr=c*16+i*4+j;
mask=1;
for(k=0;k<3;k++) {adder_tablazat[addr][k]=((osszeg & mask)>>k);mask<<=1;}
}
for(c=0;c<2;c++)//carry
for(i=0;i<4;i++)
for(j=0;j<4;j++)
{
int osszeg=i+j+c;
mask=1;
printf("%d + %d + %d =%d ",i,j,c,osszeg);
for(k=0;k<3;k++) printf("%d",adder_tablazat[c*16+i*4+j][2-k]);
printf("\n");
}
mask=1;
for(k=0;k<8;k++) {parameter[0][k]=(szam1 & mask)>>k;mask<<=1;}
mask=1;
for(k=0;k<8;k++) {parameter[1][k]=(szam2 & mask)>>k;mask<<=1;}
mask=1;
for(k=0;k<32;k++) pipeline[0][k]=0;//carry + nullaval kezd
int pl=8*8+1;
for(l=0;l<pl;l++)
{
if(l==pl-1)//csak a vegen irja ki
{
for(j=0;j<pl;j++)
{
mask=0x8000;
int bits=0;
for(k=0;k<16;k++)
{
int bit=pipeline[j][15-k];
printf("%d",bit);
if(bit) bits|=mask;
mask>>=1;
}
printf("= %d ",bits);
printf(" cr= %d\n",pipeline[j][20]);
}
printf("\n");
}
for(j=pl;j>=0;j--)
{
int j2=j&7;//8 16-bites adder
int bit_offset=j>>3;
for(k=0;k<16;k+=2)
{
if((k>>1) == j2 )
{
int bita0=pipeline[j][k];
int bita1=pipeline[j][k+1];
int bitb0=0;
int bitb1=0;
int carry=pipeline[j][20];
if(j2==0) carry=0;//adder start
int d=k-bit_offset;
if(d>=0 && d<8) bitb0=parameter[1][d];
d++;
if(d>=0 && d<8) bitb1=parameter[1][d];
if(parameter[0][bit_offset]==0) //0-val szoroz
{
bitb0=0;
bitb1=0;
}
int addra=(bita1<<1)+bita0;
int addrb=(bitb1<<1)+bitb0;
addra=(carry<<4) + (addra<<2) + addrb;
pipeline[j+1][k ]=adder_tablazat[addra][0];
pipeline[j+1][k+1]=adder_tablazat[addra][1];
pipeline[j+1][20 ]=adder_tablazat[addra][2];//carry
}
else
{
pipeline[j+1][k] =pipeline[j][k];
pipeline[j+1][k+1]=pipeline[j][k+1];
}
}
}
}
return 0;
} -
#45
t3rm1nat0r
csendes tag
t3rm1nat0r
csendes tag
Elsőre az ember azt gondolná, hogy a szorzás ennél sokkal bonyolultabb lesz.
Nem.
Szinte ugyan ez a program kell hozzá.
Kissé kell csak módosítani a hardvert, és már szorozhatunk is.Az egyik fontos módosítás, hogy két 8 bites szám szorzata lehet 16 bites, amihez a regisztereket szélesíteni kell.
Binárisan szorozni ugyan úgy kell, mint decimálisan.
Legyen a feladat 12x15 = 180. Hogy megy ez papiron?12x10x1 = 120 +
12x5 = 60Mindig eltoljuk balra a számot a helyiértéknek megfelelően. Ha két számjeggyel toljuk el, akkor ez a 100-as szorzásnak felel meg. Erről már írtam a forgatásoknál és az eltolásoknál. A kettes számrendszerben annyi a külömbség, hogy itt két helyiérték eltolás balra 4-el történő szorzásnak felel meg. Ez ugyan az, mint amikor egy szám után teszünk két nullát, és azt mondjuk, szoroztunk százzal.
Valójában felbontottam a szorzást eltolásokra és összeadásokra. Pont erre van most is szüksék. Az összeadó már kész, már csak ezt az eltologatást kell beleheggeszteni.
Az első négy sor végzi ezt az eltolást, az utolsó 5 a szorzást. Ennek csak annyi a dolga, hogy ha nullával kellene szorozni az adott tagot, akkor lenullázza, és úgy adja tovább a 2bites összeadónak. Ez az üresjárat nem lassít semmit, hiszen a pipeline végén így is minden ciklusban kapunk majd eredményt.int d=k-bit_offset;
if(d>=0 && d<8) bitb0=parameter[1][d];
d++;
if(d>=0 && d<8) bitb1=parameter[1][d];
if(parameter[0][bit_offset]==0) //0-val szoroz
{
bitb0=0;
bitb1=0;
}/Azért leírom, ez a módszer nem fog egy programot felgyorsítani, csak és kizárólag hardveres megoldásoknál gyors../
-
#44
t3rm1nat0r
csendes tag
t3rm1nat0r
#43
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#43
üzenetére
61 + 35 = 96
0 + 0 + 0 =0 000
0 + 1 + 0 =1 001
0 + 2 + 0 =2 010
0 + 3 + 0 =3 011
1 + 0 + 0 =1 001
1 + 1 + 0 =2 010
1 + 2 + 0 =3 011
1 + 3 + 0 =4 100
2 + 0 + 0 =2 010
2 + 1 + 0 =3 011
2 + 2 + 0 =4 100
2 + 3 + 0 =5 101
3 + 0 + 0 =3 011
3 + 1 + 0 =4 100
3 + 2 + 0 =5 101
3 + 3 + 0 =6 110
0 + 0 + 1 =1 001
0 + 1 + 1 =2 010
0 + 2 + 1 =3 011
0 + 3 + 1 =4 100
1 + 0 + 1 =2 010
1 + 1 + 1 =3 011
1 + 2 + 1 =4 100
1 + 3 + 1 =5 101
2 + 0 + 1 =3 011
2 + 1 + 1 =4 100
2 + 2 + 1 =5 101
2 + 3 + 1 =6 110
3 + 0 + 1 =4 100
3 + 1 + 1 =5 101
3 + 2 + 1 =6 110
3 + 3 + 1 =7 111
00100011= 35 cr= 0
00000000= 0 cr= 0
00000000= 0 cr= 0
00000000= 0 cr= 0
00000000= 0 cr= 000100011= 35 cr= 0
00100000= 32 cr= 1
00001100= 12 cr= 0
00110000= 48 cr= 0
00000000= 0 cr= 000100011= 35 cr= 0
00100000= 32 cr= 1
00100000= 32 cr= 1
00111100= 60 cr= 0
00110000= 48 cr= 000100011= 35 cr= 0
00100000= 32 cr= 1
00100000= 32 cr= 1
00100000= 32 cr= 1
00111100= 60 cr= 000100011= 35 cr= 0
00100000= 32 cr= 1
00100000= 32 cr= 1
00100000= 32 cr= 1
01100000= 96 cr= 0Mint látható, helyes eredmény ad, jó kiindulási alap lesz a szorzáshoz.
Az elején az összeadás azért van, hogy lehessen látni, melyik számnak kell kijönnie itt a csővezeték végén.Az elején kiirattam a 2x2x1 bites összeadó táblát is. Igy a legegyszerűbb és a leggyorsabb összeadni, hiszen csak ki kell emelni a memóriából az eredményt.
Az igazi az lenne, ha két 64 bites szám összes összegét le lehetne tárolni, de ez nyilván lehetetlen, mert hatalmas memória kellene hozzá.
-
#43
t3rm1nat0r
csendes tag
t3rm1nat0r
#42
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#42
üzenetére
..és a teljes program..
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int pipeline[8*4][9];
int parameter[8];
int adder_tablazat[4*4*2][4];
int main()
{
int c,i,j,k,l,mask,szam1=61,szam2=35;
printf("%d + %d = %d\n",szam1,szam2,szam1+szam2);
for(c=0;c<2;c++)//carry
for(i=0;i<4;i++)
for(j=0;j<4;j++)
{
int osszeg=i+j+c;
int addr=c*16+i*4+j;
mask=1;
for(k=0;k<3;k++) {adder_tablazat[addr][k]=((osszeg & mask)>>k);mask<<=1;}
}
for(c=0;c<2;c++)//carry
for(i=0;i<4;i++)
for(j=0;j<4;j++)
{
int osszeg=i+j+c;
mask=1;
printf("%d + %d + %d =%d ",i,j,c,osszeg);
for(k=0;k<3;k++) printf("%d",adder_tablazat[c*16+i*4+j][2-k]);
printf("\n");
}
mask=1;
for(k=0;k<8;k++) {parameter[k]=(szam1 & mask)>>k;mask<<=1;}
mask=1;
for(k=0;k<8;k++) {pipeline[0][k]=(szam2 & mask)>>k;mask<<=1;}
pipeline[0][8]=0;//carry
int pl=4+1;
for(l=0;l<pl;l++)
{
for(j=0;j<pl;j++)
{
mask=0x80;
int bits=0;
for(k=0;k<8;k++)
{
int bit=pipeline[j][7-k];
printf("%d",bit);
if(bit) bits|=mask;
mask>>=1;
}
printf("= %d ",bits);
printf(" cr= %d\n",pipeline[j][8]);
}
printf("\n");
for(j=pl;j>=0;j--)
for(k=0;k<8;k+=2)
{
if((k>>1) == j)
{
int bita0=pipeline[j][k];
int bita1=pipeline[j][k+1];
int bitb0=parameter[k];
int bitb1=parameter[k+1];
int carry=pipeline[j][8];
int addra=(bita1<<1)+bita0;
int addrb=(bitb1<<1)+bitb0;
addra=(carry<<4) + (addra<<2) + addrb;
pipeline[j+1][k ]=adder_tablazat[addra][0];
pipeline[j+1][k+1]=adder_tablazat[addra][1];
pipeline[j+1][8 ]=adder_tablazat[addra][2];//carry
}
else
{
pipeline[j+1][k] =pipeline[j][k];
pipeline[j+1][k+1]=pipeline[j][k+1];
}
}
}
return 0;
} -
#42
t3rm1nat0r
csendes tag
t3rm1nat0r
csendes tag
Igazából a program látványos, de nem eléggé átlátható, mi miért történik.
Az írtam, nem foglalkozok a szorzással, de ha már belekezdtem, akkor legyen az is itt. Mivel nem fér el az előző megoldással a monitoron egy teljes szorzó, és nem is átlátható,ezért egyszerűsíteni fogok.
Minden egyes D flip-floppot, ami egy bitet tárolt eddig, és sok NAND kapuból épült fel, most egyetlen INT tipusú változó fogja jelölni. Ez tehát egy regiszer egy bit értéke lesz.
Az összeadót nem kapus megoldással fogom felírni, hanem az előre kiszámolt táblázat módszerrel. Mint írtam, ez gyorsabb, és valami hasonlóan kell működniük a modern grafikus megjelenítőkben található vektorprocesszoroknak is, hiszen ennél gyorsabb módszer nincs.Az összeg úgy fog előállni, hogy egyetlen aritmetikai műveletet sem végzek el, csak a 2bites összeadásra előre kiszámolt táblázatot használom.
Ennek kiszámolása a program elején történik. Ez a hardverbe már készen kerül bele, emiatt nem tartozik közvetlenül a szimulációhoz.for(c=0;c<2;c++)//carry
for(i=0;i<4;i++)
for(j=0;j<4;j++)
{
int osszeg=i+j+c;
int addr=c*16+i*4+j;
mask=1;
for(k=0;k<3;k++) {adder_tablazat[addr][k]=((osszeg & mask)>>k);mask<<=1;}
}Két bit összeadása pedig ennyi lesz.
int addra=(bita1<<1)+bita0;
int addrb=(bitb1<<1)+bitb0;
addra=(carry<<4) + (addra<<2) + addrb;
pipeline[j+1][k ]=adder_tablazat[addra][0];
pipeline[j+1][k+1]=adder_tablazat[addra][1];
pipeline[j+1][8 ]=adder_tablazat[addra][2];//carryAnnyi történik itt, hogy az összeadandó bitekből kiszámolódik a táblázat címe, majd az eredmény bitjei bekerülnek a csővezetékbe.
-
#41
t3rm1nat0r
csendes tag
t3rm1nat0r
#40
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#40
üzenetére
Lehet tanulni sőt kell is, de nincs hatékonyabb módszer annál, mint amit a saját tapasztalat alakít ki.
-
#40
t3rm1nat0r
csendes tag
t3rm1nat0r
#39
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#39
üzenetére
Látszólag van egy hiba, amihez nekem is idő kellett míg rájöttem, hogy nem is hiba.
Néha a számsorban egy-két szám értéke nagyon leesik.
Ennek egyszerű oka van, néha a "bentrekedt" átvitel nem látszik, csak a következő fokozatban adódik a számhoz.Ez a vektorprocesszor titka. Itt jól látszik az is amiről már írtam.
Az első eredmény megjelenéséig fel kell tőltődnie minden fokozatnak.
Ha ezer fokozat van, akkor ezer cikluson keresztül nincs eredmény. De utánna minden ciklusban kapunk egy kiszámolt értéket. -
#39
t3rm1nat0r
csendes tag
t3rm1nat0r
#38
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#38
üzenetére
A kimenet ez, ha 00001010-at ad a counter aktuális értékéhez.
00000101 = 5
00000110 = 6
00001101 = 13
00001100 = 12
00001011 = 1100000110 = 6
00000111 = 7
00001110 = 14
00001101 = 13
00001100 = 12Látszólag összevissza számok vannak idedobálva. Az első a counter értéke, az utanná levő számok a pipeline 4 elemének értékei. Amikor a counter 5, akkor a csővezetékben 4,3,2,1- es értékek kerültek. Azért nem ezeket az értékeket látjuk, mert fokozatosan hozzáadódnak a 00001010 bitjei. Először a legalsó kettő, majd kettessével tovább.
Az utolsó fokozat 11, ami megfelel az 1+10 összegnek.
Ha nullát adok a counterhez, akkor jobban látszik, hogy mennek a számok a pipeline-ban végig.Azért két bitet adok össze egy fokozatban, mert a képernyőre nem fér ki több kapu. De lehet próbálkozni. Igazából kétszer álltam neki, de az első PRÓBÁLKOZÁSOM teljesen hibás értékeket adott, úgyhogy teljesen újrakezdtem az egészet.
Dehát az ember már csak ilyen, próbálkozik, és nem adja fel.
Soha. -
#38
t3rm1nat0r
csendes tag
t3rm1nat0r
csendes tag
Egy vektorprocesszoros összeadó már bonyolultabb. Azért annyira nem, hiszen 1 nap alatt összehozható.
void define_dflip2(int t,int l1,int l2)
{
int tr[]={
t+0, t+1, t+2, t+3, t+4,
t+sor+0, t+sor+1, t+sor+2, t+sor+3, t+sor+4,0};//5-9
define_links(tr[0],link_5V,l1,0); //inverter
define_links(tr[5],link_5V,l2,1);
define_links(tr[1],l1,l2,0); define_links(tr[2],tr[7],tr[1],1);
define_links(tr[6],l1,tr[5],1); define_links(tr[7],tr[2],tr[6],0);
define_links(tr[3],tr[0],tr[2],1); define_links(tr[4],tr[9],tr[3],0);
define_links(tr[8],tr[0],tr[7],1); define_links(tr[9],tr[4],tr[8],1);
}
void nand_gates()
{
int i,j,x,y;
for(j=0;j<sor*sor;j++)
{
nand[j].in1=1;
nand[j].in2=1;
nand[j].link[0]=link_none;
nand[j].link[1]=link_none;
#ifdef random_nand
nand[j].link[0]=j + (rand()%4) + (rand()%4)*sor;
nand[j].link[1]=j + (rand()%4) + (rand()%4)*sor;
#endif
}
nand[0].out=1;
nand[sor].out=0;
define_links(1,0,link_5V,0);//inv
//counter
int counter_bazis=2,dflip_out_offset=4;
int tr=counter_bazis;
define_dflip(tr,0); tr+=ketsor;
define_dflip(tr,tr +dflip_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr +dflip_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr +dflip_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr +dflip_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr +dflip_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr +dflip_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr +dflip_out_offset-ketsor); tr+=ketsor;
//adder
int adder_bazis=8,adder_out_offset=34;
int tr1=adder_bazis,
tr_out1=counter_bazis +dflip_out_offset,
tr_out_carry=link_0V;
int u=7,tr_adder=0,tr2,
adder_parm[]={link_0V,link_0V,link_0V,link_0V,link_5V,link_0V,link_5V,link_0V};//0001010=10
tr2=tr1;
define_adder(tr2, adder_parm[u--], tr_out1 +ketsor*0, tr_out_carry); tr_out_carry=tr2 +adder_out_offset+1;tr2+=ketsor;
define_adder(tr2, adder_parm[u--], tr_out1 +ketsor*1, tr_out_carry); tr_out_carry=tr2 +adder_out_offset+1;tr2+=ketsor;
define_dflip2(tr2, 0,tr1 +adder_out_offset ); tr2+=ketsor;
define_dflip2(tr2, 0,tr1 +adder_out_offset +ketsor); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*2); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*3); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*4); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*5); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*6); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*7); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out_carry ); tr_out_carry=tr2 +dflip_out_offset;
tr_out1=tr1 +dflip_out_offset +ketsor*2;
tr1+=6;
tr2=tr1;
define_adder(tr2, adder_parm[u--], tr_out1 +ketsor*2, tr_out_carry); tr_out_carry=tr2 +adder_out_offset+1;tr2+=ketsor;
define_adder(tr2, adder_parm[u--], tr_out1 +ketsor*3, tr_out_carry); tr_out_carry=tr2 +adder_out_offset+1;tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*0); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*1); tr2+=ketsor;
define_dflip2(tr2, 0,tr1 +adder_out_offset ); tr2+=ketsor;
define_dflip2(tr2, 0,tr1 +adder_out_offset +ketsor); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*4); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*5); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*6); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*7); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out_carry ); tr_out_carry=tr2 +dflip_out_offset;
tr_out1=tr1 +dflip_out_offset +ketsor*2;
tr1+=6;
tr2=tr1;
define_adder(tr2, adder_parm[u--], tr_out1 +ketsor*4, tr_out_carry); tr_out_carry=tr2 +adder_out_offset+1;tr2+=ketsor;
define_adder(tr2, adder_parm[u--], tr_out1 +ketsor*5, tr_out_carry); tr_out_carry=tr2 +adder_out_offset+1;tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*0); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*1); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*2); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*3); tr2+=ketsor;
define_dflip2(tr2, 0,tr1 +adder_out_offset ); tr2+=ketsor;
define_dflip2(tr2, 0,tr1 +adder_out_offset +ketsor); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*6); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*7); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out_carry ); tr_out_carry=tr2 +dflip_out_offset;
tr_out1=tr1 +dflip_out_offset +ketsor*2 ;
tr1+=6;
tr2=tr1;
define_adder(tr2, adder_parm[u--], tr_out1 +ketsor*6, tr_out_carry); tr_out_carry=tr2 +adder_out_offset+1;tr2+=ketsor;
define_adder(tr2, adder_parm[u--], tr_out1 +ketsor*7, tr_out_carry); tr_out_carry=tr2 +adder_out_offset+1;tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*0); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*1); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*2); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*3); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*4); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out1 +ketsor*5); tr2+=ketsor;
define_dflip2(tr2, 0,tr1 +adder_out_offset ); tr2+=ketsor;
define_dflip2(tr2, 0,tr1 +adder_out_offset +ketsor); tr2+=ketsor;
define_dflip2(tr2, 0,tr_out_carry ); tr_out_carry=tr2 +dflip_out_offset;
while(1)
{
//printf("%d.. %d %d \n",k,nand[0].out,nand[sor].out);
draw_layer();
for(i=0;i<100;i++)
{
//draw_layer();//ido kell mig minden beall, kirajzolhato a koztes allapot
for(j=0;j<sor*sor;j++)
if((j%sor))//elso sor nem kell
{
int link1=nand[j].link[0];
int link2=nand[j].link[1];
if(link1==link_5V) nand[j].in1=1;//fix input
if(link2==link_5V) nand[j].in2=1;
if(link1==link_0V) nand[j].in1=0;
if(link2==link_0V) nand[j].in2=0;
if(link1>=0) nand[j].in1=nand[link1].out;//out -> in1,2
if(link2>=0) nand[j].in2=nand[link2].out;
}
for(j=0;j<sor*sor;j++)
if((j%sor))//elso sor nem kell
{
nand[j].out=!(nand[j].in1 & nand[j].in2);//NAND muvelet
}
}
int mask=0x80,bits=0;
for(y=0;y<16;y+=2)
{
// for(x=0;x<6;x++) printf("%d ",nand[x+sor*y].out);
int gate=nand[counter_bazis + dflip_out_offset + sor*(14-y)].out;//counter kimenet
if(gate) bits+=mask;
mask>>=1;
printf("%d",gate);
}
printf(" = %d \n",bits);
for(x=0;x<4;x++)
{
int bazis=adder_bazis+ dflip_out_offset +x*6 +ketsor*2,e;
bits=0;mask=0x80;
for(y=0;y<8;y++)
{
int gate=nand[bazis + (7-y)*ketsor ].out;
if(gate) bits+=mask;
mask>>=1;
printf("%d",gate);
}
printf(" = %d \n",bits);
}
nand[0].out^=1;
printf("\n");
getchar();
}
}
int main()
{
initialize();
nand_gates();
XFlush(disp);
getchar();
return 0;
} -
#37
t3rm1nat0r
csendes tag
t3rm1nat0r
#22
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#22
üzenetére
Van néhány rész a programban, ami nem egyértelmű, miért van úgy megvalósítva.
Az egyik a define_dflip() függvényben minden define_links() utolsó paramétere 1 vagy nulla. Ha lekövetjük, akkor látható, hogy ez a nand[t].out=default_out; sort fogja vezérelni, ami a kezdő kimeneti állapotot állítja be.
Miért kell ez? Az ok egyszerű, nincs reset a D-flipfloppokon, és ezeknek van egy olyan rossz tulajdonságuk, hogy néha nemdefiniált állapotba kerülnek. Ez elkerülhető ha egyből stabil állapotba állítom mindet.
-
#36
t3rm1nat0r
csendes tag
ABnormal
#16
t3rm1nat0r
csendes tag
Nincs kedvem az asm-et részletesen bemutatni, de talán te.
Azért nem írok a logoutba, mert igazából nem oktatni akarok, csak leírtam azt, amit anno megismertem a processzorokról. /Ha oktatni akarnák, akkor valamelyik iskolában lennék tanár, de nem vagyok hála az égnek. /
Lehet hogy csak magamnak írtam le ezt az egészet, felkészülve az öregkorral járó feledékenységre. Mert ha a prohardver életben marad, akkor én ezt már soha többé nem fogom elfelejteni. Csak mindig újra el kell olvassam..
-
#35
t3rm1nat0r
csendes tag
t3rm1nat0r
#18
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#18
üzenetére
CMOS NAND gate
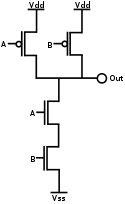
-
#34
t3rm1nat0r
csendes tag
t3rm1nat0r
csendes tag
Igazából ezt az összeadót már nem nagyon használja senki. Ennek oka a sebesség.
Ahogy a programoknál is, előre kiszámolt táblázatokból kiemelni az eredményt sokkal gyorsabb megoldás, mint akármilyen optimalizált űberprofi algoritmus.Egy összeadót fel lehet építeni olyan 4 bites elemekből, ahol a 16X16 lehetséges eredmény egy ROM-ban előre le van számolva.
/Nem tudom, milyen technikát alkalmaznak a jelenlegi processzoroknál, nem vagyok mérnök./ -
#33
t3rm1nat0r
csendes tag
t3rm1nat0r
csendes tag
#define random_nand
Érdemes kipróbálni, semmi értelme, de jól néz ki. Véletlenszerű áramkört generál.
-
#32
t3rm1nat0r
csendes tag
t3rm1nat0r
#25
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#25
üzenetére
Mint kivehető a képből, négy bemeneti vezetékből 16 kimenetet állít elő.
Mármint a programból. A képen csak egy 3-8 -as dekóder van.
-
#31
t3rm1nat0r
csendes tag
t3rm1nat0r
#20
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#20
üzenetére
ROTATE LEFT
Ahogy elnézem, ez inkább SHIFT LEFT lesz. Forgatásnál a bitek visszaforognak.A teljes skála
http://www.osdata.com/topic/language/asm/shiftrot.htm -
#30
t3rm1nat0r
csendes tag
t3rm1nat0r
#27
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#27
üzenetére
/a getchar();-hoz a konzolon kell nyomni egy entert /
-
#29
t3rm1nat0r
csendes tag
t3rm1nat0r
#24
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#24
üzenetére
A dekóder értékének a kiiratása felesleges. Szemmel jól látszik, ahogy mindig csak egy jobb oldali NAND kapunak 1 a kimenete.
Ez címezhetne egy ramban egy sor kondenzátort, ami tartalmazhatna egy egyszerű utasítást. Azt lehetne dekódolni, egyszerű összeadásra és forgatásokra.De ahhoz már nagyobb hely kellene, így ez egyenlőre ennyi.
-
#28
t3rm1nat0r
csendes tag
t3rm1nat0r
csendes tag
Az összeadó mit ad össze mivel? Ez kiolvasható a kódból.
tr_out1=counter_bazis+counter_out_offset
A számláló értékéhez ad hozzá 00001010 értéket, vagyis 10-et. Hol van ez a tíz?
A link_0V és link_5V-re vannak kapcsolva az adder egyik bemenete. Ezek sorban kiadják a 00001010 biteket.A programban az első a legalacsonyabb /nulladik/ bit, amíg egy bináris számban a jobb oldali, pont mint egy decimálisban.
A konzolra /linuxban/ a counter és az összeadó kimenete íródik ki decimálisan, és binárisan visszafele.
define_adder(tr1,link_0V,tr_out1,tr_out_carry); tr1+=ketsor; tr_out1+=ketsor;
tr_out_carry=adder_bazis + adder_out_offset + 1;
define_adder(tr1, link_5V, tr_out1, tr_out_carry); tr1+=ketsor; tr_out1+=ketsor; tr_out_carry+=ketsor;
define_adder(tr1, link_0V, tr_out1, tr_out_carry); tr1+=ketsor; tr_out1+=ketsor; tr_out_carry+=ketsor;
define_adder(tr1, link_5V, tr_out1, tr_out_carry); tr1+=ketsor; tr_out1+=ketsor; tr_out_carry+=ketsor;
define_adder(tr1, link_0V, tr_out1, tr_out_carry); tr1+=ketsor; tr_out1+=ketsor; tr_out_carry+=ketsor;
define_adder(tr1, link_0V, tr_out1, tr_out_carry); tr1+=ketsor; tr_out1+=ketsor; tr_out_carry+=ketsor;
define_adder(tr1, link_0V, tr_out1, tr_out_carry); tr1+=ketsor; tr_out1+=ketsor; tr_out_carry+=ketsor;
define_adder(tr1, link_0V, tr_out1, tr_out_carry); tr1+=ketsor; tr_out1+=ketsor; tr_out_carry+=ketsor; -
#27
t3rm1nat0r
csendes tag
t3rm1nat0r
#24
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#24
üzenetére
A legalsó kép két bitet és egy átvitelt ad össze, az eredmény 1 bit és egy új átvitel.
Ez 8 bites összeadónál annyit jelent, hogy miután beálltak stabil állapotba az első bitösszeadó kapui, a következő bit ekkor kapja meg az átvitelt.
Igaz hogy addig az is beállt valahogy, de az az eredmény érvénytelen, hiszen az első bitösszeadó áltvitel bitje csak most lett "érvényes".Ezt a "beállást" nagyon szépen látni lehet a programban, ha kissé módosítjuk.
draw_layer();//ido kell mig minden beall, kirajzolhato a koztes allapot
//ide meg lehetne tenni valamilyen Sleep(x)-et
//getchar();Ezt a két sort módosítva látható, ahogy végighullámzik ez a beállás a tranzisztorokon. Ezért /is/ lassúak viszonylag a hagyományos processzorok. Az átvitelbitnek végig kell futnia az összeadón. És a szorzásról még nem is beszéltem. /Nem is fogok. xD/
A vektorprocesszorok ezt úgy oldják meg /Cray, geforce, etc/, hogy egy órajelciklus alatt csak egyetlen bitet adnak össze egy számon. A többi bit közben csak tárolódik, mondjuk egy flipflop sorban. Az átvitel a következő fozokatban adódik majd hozzá a számhoz, miközben az előző fokozat sem megy üresjáratban, hanem oda már egy másik szám érkezett. Könnyen belátható, hogy így nincs "beállási hullám", és minden ciklusban helyes eredmény kapunk.
Az egyetlen hátránya a dolognak, hogy a "vektor csővezetéket" fel kell tölteni, addig csak üresjáratban fut. Nincs értelme egyetlen számmal műveletet végezni, csak és kizárólag nagy tömbökkel. -
#26
t3rm1nat0r
csendes tag
t3rm1nat0r
csendes tag
Seymour Cray a legendás Cray1-et ehhez hasonlóan építette fel. Ő csak NOR kapukat használt.
http://en.wikipedia.org/wiki/Cray-1
"The new machine was the first Cray design to use integrated circuits (ICs). Although ICs had been available since the 1960s, it was only in the early 1970s that they reached the performance necessary for high-speed applications. The Cray-1 used only 4 different IC types, an ECL dual NOR gate (4 input + 5 input, each with differential output), another slower MECL 4/5 NOR gate used for address fanout, a 16x1 high speed (6 ns) static RAM used for registers, and a 1k x 1 static 50 ns RAM used for main memory. In all, the Cray-1 contained about 200,000 gates, roughly the same as the Intel 386 of the 1980s."
-
#25
t3rm1nat0r
csendes tag
t3rm1nat0r
#24
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#24
üzenetére
Talán kezdem a decoderrel.
Mint kivehető a képből, négy bemeneti vezetékből 16 kimenetet állít elő. Helyesebben a 16 közül mindig csak egy aktív. A 4 vezeték egy 4 bites decimális számként van értelmezve. A 16 vezeték közül mindig az aktív, amelyik sorszáma megfelel a deciális szám értékének.
Az első lépés, hogy a 4 vezeték invertálódik. Ez azért kell mert mint mostmár tudjuk, az AND kapu akkor fog aktíválódni, ha minden bemenete 1. Itt négy bemenetű AND kapuk vannak a képen. Ezért nem kell megtanulni a táblázatot, elég csak a szabályt alkalmazni. 1000 bemenetű AND kapura is az érvényes.
Tehát a 10 érteknél a vezetéken 1010 érték lesz. A két nullás vezetéknek az inverzét kell venni, így kapjuk az 1111 értéket, ami már aktíválni fogja az AND kaput.void define_decoder(int tr3,int tr4,int mask)
{
int dx[]={sor,sor,sor,sor};//invertalva egy ketsorral lejjebbif(mask&1) dx[0]=0;
if(mask&2) dx[1]=0;
if(mask&4) dx[2]=0;
if(mask&8) dx[3]=0;define_links(tr3 ,tr4+dx[0] ,tr4+ketsor+dx[1],0);
define_links(tr3+1,tr3,link_5V,0); //inverterdefine_links(tr3+2,tr4+ketsor*2+dx[2],tr4+ketsor*3+dx[3],0);
define_links(tr3+3,tr3+2,link_5V,0);//inverterdefine_links(tr3+4,tr3+1,tr3+3,0);
define_links(tr3+5,tr3+4,link_5V,0);//inverter
}/A programban nincs szükség invertálásra, mert a decoder a counter-t dekódolja, ami Dflipfloppokból áll. Azokról pedig közvetlenül levehető a kimenet inverze, hiszen a visszacsatolt rész pont így működik./
-
#24
t3rm1nat0r
csendes tag
t3rm1nat0r
#23
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#23
üzenetére
A program már tartalmazza a cím dekódolót és az összeadót is. Ezek így néznek ki.
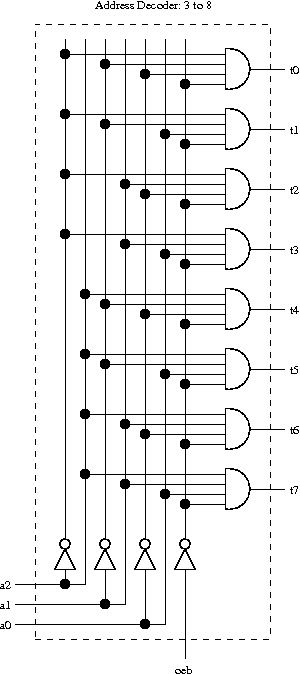
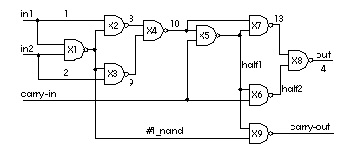
-
#23
t3rm1nat0r
csendes tag
t3rm1nat0r
csendes tag
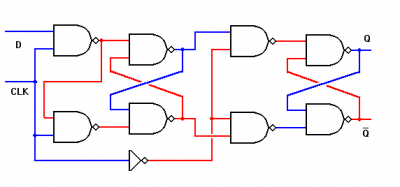
-
#22
t3rm1nat0r
csendes tag
t3rm1nat0r
csendes tag
Elég a mellébeszélésből, lássuk a lényeget.
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <X11/Xlib.h>
#include <assert.h>
#include <unistd.h>
Display *disp;
Window win;
GC gc;
void pixel(int x,int y,int color)
{
XSetForeground(disp,gc,color);
XDrawPoint(disp, win, gc, x,y);
}
void draw_line(int x1,int y1,int x2,int y2,int color)
{
XSetForeground(disp,gc,color);
XDrawLine(disp, win, gc, x1,y1,x2,y2);
}
void initialize()
{
disp = XOpenDisplay((0));
win = XCreateSimpleWindow(disp, DefaultRootWindow(disp), 0,0, 1200, 850, 0,0,0);
XSelectInput(disp, win, StructureNotifyMask);
XMapWindow(disp, win);
gc = XCreateGC(disp, win, 0, (0));
XSetForeground(disp,gc,0);
while(1)
{
XEvent event;
XNextEvent(disp, &event);
if (event.type == MapNotify)break;
}
}
//#define random_nand
struct struct_nand
{
int in1,in2,out;
int link[2];
int xykoord[3][2];
}nand[2000];
int szinek[]={0x777700,0xffff00};
int xykoord[10][2];
const int link_0V =-3;
const int link_5V =-2;
const int link_none=-1;
const int sor=32;
const int ketsor=32*2;
void draw_tranz(int x,int y,int l1,int l2,int l3,int n)
{
draw_line(x,y,x,y+8,0xff0000);
draw_line(x+2,y,x+2,y+8,0xff0000);
xykoord[n][0]=x-4;//in
xykoord[n][1]=y+4;
draw_line(x-4,y+4,x-1,y+4,szinek[l1]);
draw_line(x+3,y+2,x+6,y+2,szinek[l2]);
draw_line(x+3,y+6,x+6,y+6,szinek[l3]);
draw_line(x+6,y-2,x+6,y+2,szinek[l2]);
draw_line(x+6,y+9,x+6,y+6,szinek[l3]);
if(n==1)
{
xykoord[4][0]=x+6;//out
xykoord[4][1]=y+9;
}
if(n==0)
{
xykoord[5][0]=x+6;//0.tr out
xykoord[5][1]=y+9;
}
}
void draw_nand(int j)
{
if(nand[j].link[0]==link_none)
if(nand[j].link[1]==link_none) return;
int x=j%sor;
int y=j/sor;
x*=30;
y*=40;
draw_tranz(x+12,y+12,nand[j].in1,1,!nand[j].in1,0);//1 bal
draw_tranz(x+24,y+12,nand[j].in2,1,!nand[j].in2,1);//3 db jobb lefele
draw_tranz(x+24,y+24,nand[j].in1, !nand[j].in1,0,2);
draw_tranz(x+24,y+36,nand[j].in2, !nand[j].in2,0,3);
int q=0,w=2;//in
draw_line(xykoord[q][0],xykoord[q][1],xykoord[q][0],xykoord[w][1],szinek[nand[j].in1]);
draw_line(xykoord[w][0],xykoord[w][1],xykoord[q][0],xykoord[w][1],szinek[nand[j].in1]);
q=1;w=3;
draw_line(xykoord[q][0],xykoord[q][1],xykoord[q][0],xykoord[w][1],szinek[nand[j].in2]);
draw_line(xykoord[w][0],xykoord[w][1],xykoord[q][0],xykoord[w][1],szinek[nand[j].in2]);
w=4;
draw_line(xykoord[w][0],xykoord[w][1],xykoord[w][0]+3,xykoord[w][1],szinek[nand[j].out]);//out
nand[j].xykoord[0][0]=xykoord[w][0]+3;
nand[j].xykoord[0][1]=xykoord[w][1];
w=0;
draw_line(xykoord[w][0],xykoord[w][1],xykoord[w][0]-3,xykoord[w][1],szinek[nand[j].in1]);//in1
draw_line(xykoord[w][0]+12,xykoord[w][1]+15,xykoord[w][0]-3,xykoord[w][1]+15,szinek[nand[j].in2]);//int2
nand[j].xykoord[1][0]=xykoord[w][0]-3;
nand[j].xykoord[1][1]=xykoord[w][1];
nand[j].xykoord[2][0]=xykoord[w][0]-3;
nand[j].xykoord[2][1]=xykoord[w][1]+15;
w=5;
draw_line(xykoord[w][0],xykoord[w][1],xykoord[w][0]+12,xykoord[w][1],szinek[!nand[j].in1]);//in1
}
void draw_connect(int j,int link,int s,int dx,int col)
{
if(link<0) return;
int x=nand[j].xykoord[s][0];
int y=nand[j].xykoord[s][1];
int x3=nand[link].xykoord[0][0];
int y3=nand[link].xykoord[0][1];
int x2,y2;
x2=x;
y2=y+dx;
draw_line(x,y,x2,y2,col);x=x2;y=y2;
x2=x3;
y2=y;
draw_line(x,y,x2,y2,col);x=x2;y=y2;
x2=x3+dx;
y2=y;
draw_line(x,y,x2,y2,col);x=x2;y=y2;
x2=x3+dx;
y2=y3;
draw_line(x,y,x2,y2,col);x=x2;y=y2;
x2=x3;
y2=y3;
draw_line(x,y,x2,y2,col);x=x2;y=y2;
}
void draw_layer()
{
int j;
for(j=0;j<1000;j+=40) draw_line(0,j+9,1000,j+9,0xffff00);//tap vezetekek
for(j=0;j<1000;j+=40) draw_line(0,j+6,1000,j+6,0x777700);
for(j=0;j<sor*sor;j++) draw_nand(j);
for(j=0;j<sor*sor;j++)
{
int dx=2+(j%8)*2;
draw_connect(j,nand[j].link[0],1,dx,szinek[nand[j].in1]);
draw_connect(j,nand[j].link[1],2,dx,szinek[nand[j].in2]);
}
}
void define_links(int t,int l1,int l2,int default_out)
{
nand[t].link[0]=l1;
nand[t].link[1]=l2;
nand[t].out=default_out;
}
void define_adder(int t,int l1,int l2,int l3)
{
int tr[]={
t+0, t+1, t+2, t+3, t+4,
t+sor+0, t+sor+1, t+sor+2, t+sor+3, 0};//5-8
define_links(tr[0],l1,l2,0); define_links(tr[1],l1,tr[0],0);
define_links(tr[2],tr[5],tr[1],0); define_links(tr[3],tr[2],l3,0);
define_links(tr[4],tr[3],tr[2],0);
define_links(tr[5],tr[0],l2,0); define_links(tr[6],tr[3],l3,0);
define_links(tr[7],tr[4],tr[6],0); define_links(tr[8],tr[0],tr[3],0);
}
void define_dflip(int t,int l1)
{
int tr[]={
t+0, t+1, t+2, t+3, t+4,
t+sor+0, t+sor+1, t+sor+2, t+sor+3, t+sor+4,0};//5-9
define_links(tr[0],link_5V,l1,0); //inverter
define_links(tr[5],link_5V,tr[4],1);
define_links(tr[1],l1,tr[5],0); define_links(tr[2],tr[7],tr[1],1);
define_links(tr[6],l1,tr[4],1); define_links(tr[7],tr[2],tr[6],0);
define_links(tr[3],tr[0],tr[2],1); define_links(tr[4],tr[9],tr[3],0);
define_links(tr[8],tr[0],tr[7],1); define_links(tr[9],tr[4],tr[8],1);
}
void define_decoder(int tr3,int tr4,int mask)
{
int dx[]={sor,sor,sor,sor};//invertalva egy ketsorral lejjebb
if(mask&1) dx[0]=0;
if(mask&2) dx[1]=0;
if(mask&4) dx[2]=0;
if(mask&8) dx[3]=0;
define_links(tr3 ,tr4+dx[0] ,tr4+ketsor+dx[1],0);
define_links(tr3+1,tr3,link_5V,0); //inverter
define_links(tr3+2,tr4+ketsor*2+dx[2],tr4+ketsor*3+dx[3],0);
define_links(tr3+3,tr3+2,link_5V,0);//inverter
define_links(tr3+4,tr3+1,tr3+3,0);
define_links(tr3+5,tr3+4,link_5V,0);//inverter
}
void nand_gates()
{
int i,j,y;
nand[0].out=1;
nand[sor].out=1;
for(j=0;j<sor*sor;j++)
{
nand[j].in1=1;
nand[j].in2=1;
nand[j].link[0]=link_none;
nand[j].link[1]=link_none;
#ifdef random_nand
nand[j].link[0]=j + (rand()%4) + (rand()%4)*sor;
nand[j].link[1]=j + (rand()%4) + (rand()%4)*sor;
#endif
}
//counter
int counter_bazis=2,counter_out_offset=4;
int tr=counter_bazis;
define_dflip(tr,0); tr+=ketsor;
define_dflip(tr,tr+counter_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr+counter_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr+counter_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr+counter_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr+counter_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr+counter_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr+counter_out_offset-ketsor); tr+=ketsor;
//address decoder
int tr3=20,tr4=counter_bazis + counter_out_offset, addr=0;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
define_decoder(tr3,tr4,addr++); tr3+=sor;
//adder
int adder_bazis=9,adder_out_offset=34;
int tr1=adder_bazis,tr_out1=counter_bazis+counter_out_offset,tr_out_carry=link_0V;
define_adder(tr1,link_0V,tr_out1,tr_out_carry); tr1+=ketsor; tr_out1+=ketsor;
tr_out_carry=adder_bazis + adder_out_offset + 1;
define_adder(tr1, link_5V, tr_out1, tr_out_carry); tr1+=ketsor; tr_out1+=ketsor; tr_out_carry+=ketsor;
define_adder(tr1, link_0V, tr_out1, tr_out_carry); tr1+=ketsor; tr_out1+=ketsor; tr_out_carry+=ketsor;
define_adder(tr1, link_5V, tr_out1, tr_out_carry); tr1+=ketsor; tr_out1+=ketsor; tr_out_carry+=ketsor;
define_adder(tr1, link_0V, tr_out1, tr_out_carry); tr1+=ketsor; tr_out1+=ketsor; tr_out_carry+=ketsor;
define_adder(tr1, link_0V, tr_out1, tr_out_carry); tr1+=ketsor; tr_out1+=ketsor; tr_out_carry+=ketsor;
define_adder(tr1, link_0V, tr_out1, tr_out_carry); tr1+=ketsor; tr_out1+=ketsor; tr_out_carry+=ketsor;
define_adder(tr1, link_0V, tr_out1, tr_out_carry); tr1+=ketsor; tr_out1+=ketsor; tr_out_carry+=ketsor;
while(1)
{
//printf("%d.. %d %d \n",k,nand[0].out,nand[sor].out);
draw_layer();
for(i=0;i<100;i++)
{
//draw_layer();//ido kell mig minden beall, kirajzolhato a koztes allapot
for(j=0;j<sor*sor;j++)
if((j%sor))//elso sor nem kell
{
int link1=nand[j].link[0];
int link2=nand[j].link[1];
if(link1==link_5V) nand[j].in1=1;//fix input
if(link2==link_5V) nand[j].in2=1;
if(link1==link_0V) nand[j].in1=0;
if(link2==link_0V) nand[j].in2=0;
if(link1>=0) nand[j].in1=nand[link1].out;//out -> in1,2
if(link2>=0) nand[j].in2=nand[link2].out;
}
for(j=0;j<sor*sor;j++)
if((j%sor))//elso sor nem kell
{
nand[j].out=!(nand[j].in1 & nand[j].in2);//NAND muvelet
}
}
int s=1,a=0;
for(y=0;y<16;y+=2)
{
// for(x=0;x<6;x++) printf("%d ",nand[x+sor*y].out);
int e=nand[counter_bazis + counter_out_offset + sor*y].out;//counter kimenet
if(e) a+=s;
s<<=1;
printf("%d ",e);
}
printf(" = %d \n",a);
a=0;s=1;
for(y=0;y<16;y+=2)
{
int e=nand[adder_bazis + sor*y + adder_out_offset].out;//adder kimenet
if(e) a+=s;
s<<=1;
printf("%d ",e);
}
printf(" = %d \n",a);
nand[0].out^=1;
printf("\n");
// getchar();
}
}
int main()
{
initialize();
nand_gates();
XFlush(disp);
getchar();
return 0;
} -
#21
t3rm1nat0r
csendes tag
t3rm1nat0r
csendes tag
Mivel egy c program lesz ami majd emulálja a hardver működését, ezért kicsit a programozás rejtelmeiben is elmerülök. Ezért került ide ez a topik.
Ha megnézzük, hogy egy D flip-flop mennyi kapuból áll, és egy kapu mennyi tranzisztorból, elsőre elég elrettentőnek látszik a feladat.
Itt jön a képbe a programozás igazi lényege. Mert nem az a lényeg, hogy az összes c nyelvjárás szintaktikai külömbségeit fejből fujja az ember. Azt egy ovodás is kiguglizza.A feladat felbontása kisebb részfeladatokra. Ez az, amit /még/ nem tudnak a gépek.
Mivel a c nyelv egy logikai kapu működését egyszerűen utánnozza, ezért ez lesz az alapszint. Erre épül fel majd minden. Mivel látványos programot akarok, ezért a tranzisztorok állapotát is meg lehet majd jeleníteni a kapu állapotának ismeretében.
Igazából egy processzort nem kapuszinten terveznek, hanem nagyobb egységekből rakják össze. Ez programozásnál is egy bevált módszer. Ha már tesztelt, és biztosan jól működő részegységekből építkezünk, akkor az új rendszer gyorsabban áll össze, és kisebb a hibalehetőség.A nemrég belinkelt Dflipflop-nak ennyi a kódja.Ez egyszerűen megmonja, hogy egy sorXsor-os NAND tömbben melyik kapu melyik két másikhoz kapcsolódjon.
void define_dflip(int t,int l1)
{
int tr[]={
t+0, t+1, t+2, t+3, t+4,
t+sor+0, t+sor+1, t+sor+2, t+sor+3, t+sor+4,0};//5-9define_links(tr[0],link_5V,l1,0); //inverter
define_links(tr[5],link_5V,tr[4],1);define_links(tr[1],l1,tr[5],0); define_links(tr[2],tr[7],tr[1],1);
define_links(tr[6],l1,tr[4],1); define_links(tr[7],tr[2],tr[6],0);define_links(tr[3],tr[0],tr[2],1); define_links(tr[4],tr[9],tr[3],0);
define_links(tr[8],tr[0],tr[7],1); define_links(tr[9],tr[4],tr[8],1);
}Innentől egy 8 bites számlálónak már csak ennyi a kódja.Ez megadja, hogy két soronként legyen lefele egy-egy Dflipflop, és mindig az előző kimenetére csatlakozzon.
//counter
int counter_bazis=2,counter_out_offset=4;
int tr=counter_bazis;
define_dflip(tr,0); tr+=ketsor;
define_dflip(tr,tr+counter_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr+counter_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr+counter_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr+counter_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr+counter_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr+counter_out_offset-ketsor); tr+=ketsor;
define_dflip(tr,tr+counter_out_offset-ketsor); tr+=ketsor;Definiálni kellene a define_links() függvényt. Mondjuk legyen ilyen.
void define_links(int t,int l1,int l2,int default_out)
{
nand[t].link[0]=l1;
nand[t].link[1]=l2;
nand[t].out=default_out;
}Ebből már sejthető, hogy az alapstruktúrának valami hasonlónak kell lennie.
struct struct_nand
{
int in1,in2,out;
int link[2];
int xykoord[3][2];
}nand[2000];Lesz egy kapunak két bemenete és egy kimenete. Hogy honnan szedje az értéket a bemenet, ezt adja meg a link[]. Ezt definiáltam az előbb.
A kapuk szimulációja sem sokkal bonyolultabb.
for(j=0;j<sor*sor;j++)
if((j%sor))//elso sor nem kell
{
int link1=nand[j].link[0];
int link2=nand[j].link[1];if(link1==link_5V) nand[j].in1=1;//fix input
if(link2==link_5V) nand[j].in2=1;
if(link1==link_0V) nand[j].in1=0;
if(link2==link_0V) nand[j].in2=0;if(link1>=0) nand[j].in1=nand[link1].out;//out -> in1,2
if(link2>=0) nand[j].in2=nand[link2].out;
}
for(j=0;j<sor*sor;j++)
if((j%sor))//elso sor nem kell
{
nand[j].out=!(nand[j].in1 & nand[j].in2);//NAND muvelet
}A kapu lehet az 5V-ra vagy a földre kötve, de kaphatja a bemenetét egy másik kapuról. Ha ezt beállitottuk, akkor már csak a NAND művelet elvégzése van hátra.
Igazából ez már így működik, de senki nem kiváncsi egyesek meg nullák ugrálására a képernyőn.
Na ez a rész már kissé bonyolultabb lesz, de nem vészes. -
#20
t3rm1nat0r
csendes tag
t3m1nat0r
#9
t3rm1nat0r
csendes tag
A logikai műveleteknél ezeket az alaputasításokat már említettem. Ott azt mondtam, hogy maszkokkal lehet a biteket manipulálni. Ez annyit jelent, hogy egy 8 bites regiszterhez 8 bitet adunk meg, amiken egyenként végrehajtódik az, amit az imént leírtam.
Esszerint 8 darab A és B bemeneti érték van. A bitek bármilyen állapotban lehetnek.
/terhesek azért nem xD /10101100 A
11001101 B
10001100 out = A AND B10101100 A
11001101 B
11101101 out A OR B10101100 A
11001101 B
01100001 out A XOR B /vagy EOR/Igy látszik a logikája a műveleteknek, ha decimálisan vagy hexában írom fel, akkor már csak gyakorlott szem érti, mi miért történik.
0xac A
0xcd B
0x8c out = A AND BVannak még a forgatások és léptetések. Itt csak annyi történik, hogy jobbra vagy balra eltolódik bitenként a regiszter
10101100 A
01011000 out ROTATE LEFT /a rövidítés processzor függő/10101100 A
01010110 out RIGHT
11010110 out RIGHT a legfelső bit ismétlődik. Mivel INT tipusnál az tárolja az előjelet, ezért így a szám negatív marad.Az A értéke decimálisan 172, jobbra forgatás után 86. Ez a fele, a forgatást osztás helyett lehet használni, ha 2 hatványával osztunk.
Régebbi hardveres megoldásoknál ezért találkozunk lépten nyomon olyan számokkal, hogy 2 4 8 16 32 64 128 256 512 1024 ... mert ez az osztást /és ha balra forgatok, akkor szorzást/ sokkal egyszerűbben valósítható meg hardverileg, és még gyorsabb is a működése, mint majd kiderül.Be fogok mutatni egy teljes összeadó arámkört működés közben, ahol látszani fog, miért eszik olyan sok időt egy hagyományos processzor, és miért számol például egy geforce sokkal gyorsabban.
-
#19
t3rm1nat0r
csendes tag
t3rm1nat0r
#18
t3rm1nat0r
csendes tag
válasz
t3rm1nat0r
#18
üzenetére
A linkbe került egy smile-vezérlő karakter, de jó a link.
-
#18
t3rm1nat0r
csendes tag
t3rm1nat0r
csendes tag
A továbbiakban ahhoz hogy valamiféle értelmes szimulációt lehessen bemutatni, tudni kellene, hogy épül fel egy nand kapu.
Ehhez a cmos megoldást választottam. De itt is sok más fizikai kivitelezés létezik.
http://en.wikipedia.org/wiki/File
 MOS_NAND.svg
MOS_NAND.svg
http://en.wikipedia.org/wiki/CMOSEz egy kevert megoldás, n és p tipusú tranzisztorokból áll. Mindig csak az egyik tipus aktív, amiatt áram csak nagyon rövid ideig folyik. Ezeket használják a kis fogyasztású eszközökben.
Ha A vagy B bemenetet Vss-re kapcsolom /-/, akkor az Out Vdd szintre /+/ áll be, mert valamelyik felső tranzisztor lesz aktív.
A minkét bemenet Vdd-t kap, akkor a két alsó tranzisztor Vss-re kapcsolja a kimenetet. /out/
Ennek van egy igazság táblája
A B out
+ + -
- + +
+ - +
- - +Ez megfelel a nand állapotainak, ha + az az 1, és a - a 0 állapot,
Ezeket az igazságtáblákat nem kell bemagolni. Néhány egyszerű szabályra épül az egész.Az AND csak akkor ad igaz /1/ kimenetet, ha mindkét bemenet igaz. Ez az első eset.
A B out
11 1
01 0
10 0
00 0Az OR csak akkor ad 0-át, ha mindkét bemenet 0. Ha VAGY az egyik VAGY a másik 1, akkor a kimenet is 1.
A B out
11 1
01 1
10 1
00 0A XOR csak akkor lesz 1, ha ellentétes a két bemenet állapota.
A B out
11 0
01 1
10 1
00 0Az N betű a NAND-nál annyit jelent, hogy invertálni kell a kapott értéket.
Ez az 1-est 0-ára változtatja, és fordítva.A NAND kapuk használatának mint látszik, ismét praktikus oka van, ez az egyik legegyszerűbben megvalósítható logikai kapu.
AND kaput úgy kapunk, hogy egy invertert kapcsolunk utánna. Ha nem akarunk túl optimalizált áramkört, akkor kiindulhatunk a tervezésnél tisztán NAND vagy NOR kaputömbből.
Ekkor az invertert úgy kapom, hogy az egy NAND kapu egyik bemenetét felhúzom.
Ezt a módszert fogom alkalmazni. -
#17
t3rm1nat0r
csendes tag
ABnormal
#16
t3rm1nat0r
csendes tag
Na , visszatértem
Mielőtt az asm-ről beszélnék, előbb a hardvert kellene megismerni közelebbről.
Szó volt a Program Counter-ről, ami egy számláló, ahogy a neve is mutatja.
Ezek egy olyan elemekből állnak, amik visszacsatolással megjegyzik az állapotukat.
Ezeknek ismét több megoldásuk lehetséges, a vezérlésük történhet élvezérléssel, lehet rajtuk reset bemenet.De az átláthatóság miatt vegyük a legegyszerűbb megoldást:
http://webpages.charter.net/dawill/tmoranwms/Circuits_2008/Type_D_Flip-Flop.gifEz két visszacsatolt részből áll, a master és a slave flip-flop-ból. Ezek lehetnek nand vagy nor kapukból felépítve, ismét csak részletkérdés. A fontos, az a visszacsatolt hurok, ez a két csatolt kapunál mindig ellentétes állapotú.
A két flip-flop ellentétes jelre áll be. Ez a CLK bemenet, ami vezérli a számlálót. A slave rész ezt invertálva kapja.Ez még igazából nem jó számláláshoz, ahhoz össze kell kötni a D bemenetet az egyik Q kimenettel. Ekkor mindig ellentétes állapotába áll be a bit.
Ha több ilyen bitet összerakok, és a CLK bemenetre az előző Q kimenetét kötöm, akkor meg is kaptam a számlálót.Hogy ne csak a levegőbe beszéljek, ezt működés közben is be fogom mutatni.
-

t3m1nat0r
csendes tag
Ahhoz, hogy fizikailag ez működjön, át kell alakítani ezt a 16 bitet 65536 bitté, hiszen a memóriát ennyi vezetéken lehet elérni.
Igazából ennek elég egyszerű a megoldása. A bináris fákhoz hasonlóan felosztható a memória is. A legfelső bit ha 0, akkor a baloldali memória aktív, ha 1 akkor a jobb. A következő bit ezt a két részt osztja további darabokra.
-
t3m1nat0r
csendes tag
Az elején a bitekkel végzett műveletekhez soroltam az aritmetikai műveleteket. Ez nem a szokásos besorolás, de igaz.
A regiszterekbe és a memóriában mindig bitek vannak.Az hogy mi most egy decimális számként gondolunk rá, vagy egy pixel szinértékeként, már csak értelmezésbeli külömbség. Attól ott még egy kondenzátor tömb van fizikailag, ami biteket tárol.
Szín úgy lesz ebből a bitcsoportból, hogy áthelyezzük a videómemóriába. Ebből egy dekódoló áramkör olyan jelet fog előállítani , ami a monitoron szines pixelként fog megjelenni.
Ha ezt a bitcsopotot a hangkártyára küldöm, akkor hang lesz belőle. Ha ráállítom az utasításszámláló regisztert, akkor programkód.Egy memóriaterület azért fog lebegőpontos számot jelképezni, mert olyan műveleteket végzek el rajta, amelyek ezt lebegőpontos számként kezelik.
-
t3m1nat0r
csendes tag
Miért beszélek én 7. bitről, mikor az a 8.?
Nem elírás, hanem ez egy megszokott számozási módszer a számítástechnikában. Akik programoznak, azok ismerik, hogy az első tömb elem mindig a [0]. Ennek praktikus oka van, a tömbnek van egy báziscíme, amihez hozzáadódik az index.
A bitek ugyan így 0-tól kezdődnek.
-
t3m1nat0r
csendes tag
A logikai és az aritmetikai műveletek az Accumulator értékét manipulálják.
Itt még nem volt szorzás és osztás, bizony meg kellett írni azt is. Mennyivel egyszerűbb, és unalmasabb a mai processzorok programozása.A logikai műveletek bitekre vonatkoznak. Egyszerűen leírva annyi a feladatuk, hogy biteket állítsanak 1-re vagy 0-ra. Ez nem ugy oldották meg, hogy mindig megadom a módosítani kívánt bit azonosító-számát, hanem maszkokkal lehet a biteket manipulálni. Ha 1-esre akarom az akku 7.bitjét állítani, akkor az "ORA Logical Inclusive OR" utasításnak egy 0x80 hexadecimális paramétert adok. A 8 az binárisan 1000 a 0 az 0000, tehát a 7.bit egyes lesz, a többi marad a régi állapotában. A ugyanezt az "EOR Exclusive OR"-al végzem el, akkor a 7. bit az ellentétes állapotába áll be.
Igazából nincs szándékomban leírni az összes utasítás működését, csak a gép alapvető funkcióinak a bemutatása volt a célom.Mint kiderült, nem kell mérnöki végzettség ahhoz, hogy az ember megértse a processzor működésének alapjait.
Ahogy a programozásához sem diploma kell, hanem gép, idő és kódtáblázat.Persze aki úgy képzeli, hogy a próbálkozás egyenlő azzal, hogy összevissza nyomkodja a gombokat, az feleslegesen végzett el annyi egyetemet.
-
t3m1nat0r
csendes tag
A maradék regiszterek
Stack Pointer
Accumulator
Index Register X
Index Register Y
Processor StatusA Stack Pointer-ről már volt szó a szubrutin hívásnál. Ez egy ideiglenes tárolásra kijelölt memória területre
mutat. Ide lehet olyan adatokat "lenyomni", amiket csak kevés ideig kell megőrízni.
A magasszintű nyelvek lokális változói is ide kerülnek.
Ehhez tartoznak a POP és PUSH műveletek, amikke a veremre rakhatunk adatot, vagy leszedhetjük onnan.PHA Push accumulator on stack
PHP Push processor status on stack
PLA Pull accumulator from stack N,Z
PLP Pull processor status from stackAz Accumulator az a regiszter, ahol műveleteket végez a processzor az adatokon. A modernebb cpu-kon már több ilyen funkciójú regiszter is található, és így jobban optimalizálható a kód, kevesebbszer kell a memóriához fordulnia.
Az index regiszterek a címzést segítik.A Processor Status vagy flag register bitjei különböző állapotait mutatják a processzornak. Ezeket bitműveleteket lehet végezni, és a Branches utasításokhoz is ezek adják meg a feltételeket. Ezek általában valamilyen művelet elvégzése után állnak be az adott állapotba. Mondjuk a "CMP Compare accumulator", ami összehasonlít két számot kivonás segítségével, két egyenlő értéket hasonlított össze. Ez a "Zero Flag" bitet fogja beállítani, ami majd a következő "BEQ Branch if zero flag set" vagy "BNE Branch if zero flag clear" utasítást fogja vezérelni.
-
t3m1nat0r
csendes tag
Most kezd érdekes lenni a probléma.
Az már sejthető, hogy a programkód és az adatok a memóriában vannak.De mit jelent az, hogy fut a program?
Ehhez először is a regisztereket kell megismerni.Program Counter
Stack Pointer
Accumulator
Index Register X
Index Register Y
Processor StatusAz elsőnél már meg is állhatunk. Ez az a 16 bites címregiszter, ami arra a memória byte-ra mutat, ami éppen "végrehajtódik".
Ez annyit jelent, hogy a processzor kiküldi a memória fele ezt a címet /rákapcsolja a regisztert a címbuszra/ , az pedig beállítja az adatvezetékeket az adott című memória byte kondenzátorainak megfelelő értékre.
Ezeket a folyamatokat időziteni kell, mivel az elektronok nem végtelen sebességgel haladnak.A behozott byte lesz az utasítás. Ez az adott processzortól függően megmondja, hogy mi lesz a következő lépés.
Lehet, hogy az utasítás utáni byte-ot be kell hozni, és hozzáadni az akkuhoz /Accumulator/, vagy az utasítás után egy cím található, ahova el kell ugrani.
Ha elvégezte a műveletet, akkor a Program Counter értékét növeli automatikusan a processzor, és elhozza a következő byte-ot, a következő utasítást.Már fut is a program.
Látszik, hogy igazából a memóriában bármilyen byte-kombináció lehet. Akár képi információ vagy valamilyen szöveg. A gépet ezt nem érdekli, neki az a feladata, hogy ezt utasítások sorozataként értelmezze, mivel a Program Counter értékét valaki erre a memória területre állította.
Ha a program eltéved /hibás, vagy a memória sérül, stb/ akkor "megfagy" a program, vagy jön a "kékhalál".
A commodore egyszerűen csak újraindult. Nem bonyolította túl a témát.Mostmár az is érthető, hogy hogyan ágazik el egy program.
A Program Counter értékét néhány utasítás képes módosítani. Ezek a Jumps & Calls és a Branches utasítások.
A jump és a "jump to a subrutine2 mindig elugranak, míg a Branches tipusúk csak akkor, ha a megadott feltétel teljesül. A szubrutin hívás még annyiban különleges, hogy a veremben eltárolja a visszatérési értéket, amit majd a "return from subrutine" újra elő fog venni. A magasabb szintű nyelvek ezt használják a procedurák és függvényhívásokhoz. Nem pont ezt, csak ha c64-en fug a progi.Eddig igazából semmi más nem törént, csak byte-ok mozogtak a memóriából a processzor valamelyik regiszterébe. Ez a lényege a gép működésének. Magasabb szinten a memória nem címekkel érhető el, hanem változók neveivel. De ezek mindig ilyen memória-címeket rejtenek.
-
t3m1nat0r
csendes tag
Nem kerülhetem el azt, hogy a számábrázolásokról írjak. Ezek nélkül nem lesz tiszta, miért fér el 16 biten a 65536-1 decimális szám.
A kettes számrenszer igazából egy választott ábrázolás a gépekben, hiszen bármilyen szimbólumrendszert hozzá lehetne rendelni egy adott byte-hoz, ami 8 kondenzátor értéke.
De a kettes számrendszer felel meg a legjobban a célnak. Miért?
Mert a kondenzátor vagy fel van töltve, vagy nem. A kettes számrendszerben pedig egy számot 0 és 1 számokkal írunk le, ami egyértelműen megfeleltethető a kondenzátor állapotainak.Tizes számrendszerben, mint köztudott, 10 számjeggyel /szimbólummal/ írható le bármilyen szám. Elszámolunk 9-ig, utánnak "túlcsordulás" keletkezik. Ezt egy újabb helyiértékkel jelöljük, majd folytatjuk a számolást megint 0-tól 9-ig.
A kettes számrendszerben annyi a változás, hogy mindig 0-tól 1-ig számolunk, majd "túlcsordulás" jön. Az első bináris szám, ahol ez megtörténik a bináris 10,ami a decimális 2-es. Ugye 0, 1, 10/túlcsordulás/, ami decimálisan 0,1,2.Lehet ez már óvodás szintnek tűnik, de nem mérnököknek írok, hanem azoknak, akiknek halvány elképzelésük sincs, mi megy végbe egy ilyen gépben.
Egy egyszerű számológéppel meg lehet nézni, hogy az 10000000000000000 bináris szám, az 65536. Azért írtan hogy -1, mert ez már 17 számjegyű. 16 bittel tehát a legmagasabb címezhető memória a bináris 1111111111111111, azaz a 65535.
Ezt a sok egyest nagyon kényelmetlen kezelni, könnyű eggyel kevesebbet vagy többet írni belőle. Hamar meg is unták a programozók, és bevezettek egy egyszerűbb ábrázolási módot. Ami elsőre talán bonyolultabb.
Ez a hexadecimális, tizenhatos számrendszerbeli ábrázolás.
Mivel nincs a 10 11 12 13 14 15 számjegyekre külön jel, így használni őket pedig veszélyes lenne, mert nem lenne egyértelmű a leírás, ezért ezeket betűkkel helyettesítették. Ezek lettek az A,B,C,D,E,F betűk.
Tehát úgy számolunk 16-os számokkal, hogy 1,2,3,4,5,6,7,8,9,A,B,C,D,E,F,10,11,12,13,14,15,16,17,18,19,1A,1B,.....Két hexadecimális számmal leírható egy byte. Nem csoda, hiszen egy fél byte 4 bit. 2 a 4.-en pedig 16. Egyszerű.
-
t3m1nat0r
csendes tag
Definiálni kellene, hogy mit jelent a hely és bit fogalma a gépben.
Ehhez tudni kell, hogy hogyan tárolja az információt a gép.Ez a memória feladata.
http://en.kioskea.net/contents/pc/ram.php3
A megadott linken rácsban elhelyezett kondenzátorokat lehet látni.
Itt egy 6x6-os rács van a képen. Ez egy 6 byte-os memóriának felel, ahol egy byte-ból most csak 6 bit látszik.Egy byte valójában 8 bites, vagyis 8 kondenzátornak felel meg.A c64-ben 65536x8 ilyen kondenzátor van. A c64 memóriája 64 kbyte. Ennek a fogalomnak fizikailag ez a kondenzátor tömb felel meg.
Ilyen egyszerű a kezdet, és később sem lesz sokkal bonyolultabb.A fizikai megvalósítástól függően nem kizárólag kondenzátor tárolhat egy bitet. Lehet tranzisztorokkal visszacsatolást létrehozni, amik szintén képesek egy bit tárolására.
http://class.ee.iastate.edu/cpre305/labs/lab07.html
A programozás szempontjából a különböző fizikai megoldások nem lényegesek. Annyi azért még leírok, hogy a műveleteket nem követlenül a memóriában végzi a processzor, hanem beolvassa a memória tartalmát egy regiszterbe. Ezek a regiszterek gyors működésű tranzisztorokból állnak legtöbbször. A modern processzorok már nem is egyből a regiszterekbe olvasnak, hanem elöszőr közbeiktatott több lépcsős gyorsító memóriákba. De nem célom a modern cpu-k leírása.
Minden byte-ot /8 kondenzátort/ a memóriába egy címvezetékkel lehet elérni. Ez lehet a vízszintes vonal. Ez a c64-nél 65536 vezzetéket jelent. Ezt binárisan kódolva 16 biten lehet ábrázolni. 2 a 16.-on az pont ennyi. Ezt a 16 bites számot nevezzük címnek. Ez az adott 8 bites kondenzátor tömb memória címe.
Ahhoz, hogy fizikailag ez működjön, át kell alakítani ezt a 16 bitet 65536 bitté, hiszen a memóriát ennyi vezetéken lehet elérni. Ez a memória címző egység dolga, amivel szintén nem kell programozás szinten nekünk foglalkozni.
A memória fele haladó 16 bites vezetékköteg a címbusz, a kondenzátoroktól visszajövő az adatbusz.Innentől ismert, hogy mi az a bit, hogy lesz belőle byte, továbbá mit jelent ennek a helye és címe.
-
t3m1nat0r
csendes tag
Talán érdemes lenne egy egyszerű processzorral kezdeni. Legyen ez a 6502, ami a commodore 64-est is vezérelte, na meg a terminátort.
"In the science fiction movie The Terminator (1984), starring Arnold Schwarzenegger, the audience at one point is treated to a view through the T-800 Model-101 robot character's eye/camera display with some 6502 assembly/machine code program fragments scrolling down the screen. "
http://en.wikipedia.org/wiki/MOS_Technology_6502
http://www.llx.com/~nparker/a2/opcodes.html
http://www.llx.com/~nparker/a2/opcodes.html
Ha az ember megnézi ennek a processzornak az utasítás készletét, akkor első pillanatban megrémül, hogy milyen sok van ezekből. Ha kicsit átnézzük ezeket, akkor kiderül, hogy a legtöbb utasítás ugyan annak az alaputasításnak a módosulatai.http://www.obelisk.demon.co.uk/6502/instructions.html
Igy már 11 csopotra lehet bontani ezeket. Egy kezdőnek még mindig ijesztő lehet, de tovább lehet egyszerűsíteni a képet.
Az első csoport valamilyen adatot visz egyik "hely"-ről a másikra. A hely fogalmát itt még majd definiálni kell. Itt ez a fogalom nem utcákat vagy bármi más megszokott dolgot jelent.
Ezek:
Load/Store Operations
Register Transfers
Stack Operationstöltés/tárolás
register tartalom áthelyezése
verem operációkA második csoport "biteken" "bitekkel" végez műveletet. A bitek fogalmát is definiálni kell majd.
Logical
Arithmetic
Increments & Decrements
Shifts
Status Flag Changeslokigai bit műveletek
aritmetikai műveletek
regiszter érték nővelés, csökkentés 1-el
eltolások és forgatások
státusz beállitásokA harmadik csopot a program elagazasait kezeli, irányítja. Ezek valójában az első csoporthoz tartoznak, mert az a fő feladatuk, hogy az ugrasi cimet a Program Counter-be helyezik.
http://www.obelisk.demon.co.uk/6502/registers.html
Jumps & Calls
Branches
System FunctionsUgrások és szubrutin hívások
elágazások
rendszer funkciók








 MOS_NAND.svg
MOS_NAND.svg




Aktív témák

- Apple iPhone 11 64GB,Használt,Adatkabel,12 hónap garanciával
- Apple iPhone 15 Plus 128GB, Kártyafüggetlen, 1 Év Garanciával
- ÁRGARANCIA!Épített KomPhone Ryzen 7 9800X3D 64GB RAM RTX 5080 16GB GAMER PC termékbeszámítással
- Lenovo ThinkPad E495,14" FHD,AMD Ryzen 5 PRO 3500U,8GB DDR4,256GB SSD,WIN11
- TP-Link TP1600G-28TS switch // Számla - Garancia //
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest