- AMD K6-III, és minden ami RETRO - Oldschool tuning
- AMD Ryzen 9 / 7 / 5 / 3 5***(X) "Zen 3" (AM4)
- Milyen asztali médialejátszót?
- Kormányok / autós szimulátorok topicja
- 33 280 mAh csak elég lesz
- Milyen egeret válasszak?
- 3D nyomtatás
- Mi lehet a gépemmel a baj?
- iPad topik
- Hamarosan megjön a Samsung 360 Hz-es QD-OLED monitora
Hirdetés
-


Saját AI-chipet visz az adatközpontokba az Apple
it A jelentések szerint az Apple saját chipeket fejleszt, hogy AI-szoftvereket futtasson az adatközpontokban.
-


33 280 mAh csak elég lesz
ma Az Ulefone Armor Pad 3 Pro magashegyi kempingezésre is jó, óriás hangfala bulit teremt a semmi közepén.
-


Spyra: akkus, nagynyomású, automata vízipuska
lo Type-C port, egy töltéssel 2200 lövés, több, mint 2 kg-os súly, automata víz felszívás... Start the epic! :)






-

PROHARDVER!
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
válasz
 namaste
#9275
üzenetére
namaste
#9275
üzenetére
Az teljesen világos, hogy két nagy tényező van, amely nagyban meghatározza a fogyasztást. Az egyik az ütemezés. A GCN teljesen hardveres ütemezést használ, a wavefrontok szintjén OOO logikával. Az NV a Kepler óta félig szoftveres ütemezésű, és a feladatütemezés is in-order. A CUDA-ban vannak olyan lehetőségek, hogy az egyes warp-okat lehessen priorizálni.
A másik fontos tényező a belső adatbusz. Ez jelentős fogyasztáskülönbséget okozhat. A GCN egy nagyon széles belső ringbuszt használ, amivel minden egység összekapcsolódik, míg a Maxwell az ultramobil GPU-k irányelveit követve strukturált buszokkal dolgozik és nem minden egység van egymással összekapcsolva.Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
válasz
namaste
#9275
üzenetére
szerintem nem jó ötlet
bővebben?
a 970-es komment jogos, azt kellett volna írnom, hogy a "hivatalos álláspont szerint".
(#9278) HSM: dehogy szalmabáb, a Tonga jelenlegi egyetlen asztali megvalósulása a 285. a mobil chip adatai totál nem relevánsak.
szerintem majdnem mindent logikus a compilerbe költöztetni, ami statikus, és egyszer kell vele dolgozni, szemben azzal, ha folyamatosan realtime csinálnád.
nem az AMD "nem tudja" előnyre váltani, hanem a piaci viszonyok nem teszik számára lehetővé, hogy megtegye.
a kettő között semmi különbség nincs. egy jó innovátor rá tudja a piacra kényszeríteni az akaratát.
Pedro... amigo mio... ma is konzervvért iszunk! Kár lenne ezért a tehetséges gyerekért...
-
válasz
namaste
#9284
üzenetére
így van, megbontja a szimmetriát - feltételezem, hogy a scheduler figyel arra, hogy az SM minél nagyobb valószínűséggel a priorizált ROP-pal beszéljen (különben tényleg nincs értelme a dolognak). gyakorlatilag GPU a GPU-ban.
ill. a szűkebb csatorna a nem-priorizált backend blokkokhoz nagyobb adattranszferek esetén nem gond, mert a MC is csak 64-bites.igen, egy specifikus tesztprogramot én is szívesen látnék. a bizonyítás alatt arra gondolsz, hogy nem hiszed el, hogy léteznek ilyen utak, vagy másra?
(#9288) Menthirist: a 128 ROP-ot gondolom az 1024-bites buszból számolta ki valaki
 de amúgy nem kizárható - nem tudjuk, hogy milyen lesz a backend felépítése, és azt sem, hogy a Hawaii-ban mennyire overkill a 64 ROP. ha megint a 2 hatványa kell legyen a ROP-ok száma, akkor nem kizárt, hogy emelik a tétet.
de amúgy nem kizárható - nem tudjuk, hogy milyen lesz a backend felépítése, és azt sem, hogy a Hawaii-ban mennyire overkill a 64 ROP. ha megint a 2 hatványa kell legyen a ROP-ok száma, akkor nem kizárt, hogy emelik a tétet.Pedro... amigo mio... ma is konzervvért iszunk! Kár lenne ezért a tehetséges gyerekért...
-
válasz
namaste
#12602
üzenetére
A Tahitiben (GCN 1.0) a ROP-blokkok egy külön crossbar busszal kapcsolódnak a memóriakontrollerekre, erre gondoltam varázslás alatt, csak nem emlékeztem pontosan, és lusta voltam utánanézni
 A GCN 1.1-től kezdve az architektúra-ábrák úgy ábrázolják a ROP-okat, ahogy írod, viszont a mélyebb cikkek mindig hozzáteszik, hogy a ROP-ok közvetlenül vannak bekötve az MC-khez, nem a belső adatbuszon keresztül. Én ebből ezt feltételeztem, hogy kidobták a crossbart, és visszatértek az 1:1 megfeleltetéshez - ez lehet téves, de a Hawaii és a Tonga esetében gyanúsan ragaszkodtak a 8 ROP / 64-bit felálláshoz, pedig legalább az egyik GPU-nak nem az az optimális konfiguráció.
A GCN 1.1-től kezdve az architektúra-ábrák úgy ábrázolják a ROP-okat, ahogy írod, viszont a mélyebb cikkek mindig hozzáteszik, hogy a ROP-ok közvetlenül vannak bekötve az MC-khez, nem a belső adatbuszon keresztül. Én ebből ezt feltételeztem, hogy kidobták a crossbart, és visszatértek az 1:1 megfeleltetéshez - ez lehet téves, de a Hawaii és a Tonga esetében gyanúsan ragaszkodtak a 8 ROP / 64-bit felálláshoz, pedig legalább az egyik GPU-nak nem az az optimális konfiguráció.HBM: OK, ezt nem tudtam (thx
 ), bár a lényegen csak annyit változtat, hogy nem 4 csatorna és a ROP-ok viszonyáról van szó, hanem 32-éről.
), bár a lényegen csak annyit változtat, hogy nem 4 csatorna és a ROP-ok viszonyáról van szó, hanem 32-éről.Pedro... amigo mio... ma is konzervvért iszunk! Kár lenne ezért a tehetséges gyerekért...
-

Z10N
veterán
válasz
namaste
#20454
üzenetére
"A Perf/Watt arányból nem lehet az IPC-re következtetni, a Perf/freq arányból lehetne."
uarch + feat."A Perf/Watt mutatót mihez hasonlítják? Az R9 285 vagy a Nano az etalon? Nem mindegy."
Ne kerdezd, nem tudom, mi a ref pont. Tipikus marketinges huzas.# sshnuke 10.2.2.2 -rootpw="Z10N0101"
-

Oliverda
félisten
válasz
namaste
#24044
üzenetére
Mert szerinted én miről beszélek?
Az adatírások és olvasások sebességét meghatározó, a CK órajel (command clock) dupláján működő két differenciált műveleti frekvenciához (WCK_t és WCK_c) rendelt két-két adatszó már QDR (Quad Data Rate) üzemmódban is működhet. Ehhez az összesen négy DQ/DBI_n adatszót egy külön, a WCK-ból származtatott órajelre ülteti a rendszer, így egyetlen CK ciklus alatt négy egységnyi adat továbbítható. Ezzel a GDDR5-höz mérten kétszer annyi, már összesen négy darab 32 bites adatszó (data word) forgalmazható az IO-puffer relációjában.
Emellett az előd GDDR5 8N-prefetch értékét a duplájára, 16N-re emelték. Ennek megfelelően a memória magján belüli írási vagy olvasási művelet mérete már 512 bites (64 byte) lehet, mely két CK órajelciklus alatt megy végbe. Ugyanennyi idő alatt tizenhat darab 32 bites adat mozgatható az IO-puffer viszonylatában. Mindkét érték pontosan duplája a GDDR5 esetében meghatározottaknak, ennek megfelelően pedig azonos magórajelet alapul véve kétszeresére nőtt a GDDR5X effektív órajele.
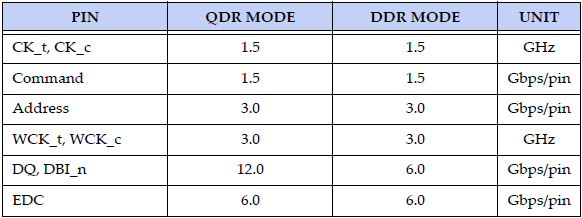
QDR Mode: GDDR5X
DDR Mode: GDDR5[ Szerkesztve ]
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-
Abu85
HÁZIGAZDA
válasz
namaste
#27948
üzenetére
Arról van szó a keresztkötésnél, hogy maga a GPU egy heterogén processzor, és az egyes függetleníthető elemek nem direkten vannak csoportosan egymással összekötve, hanem a csoporton belül is mindegyik elem csatlakozik az előtte lévő csoport össze elemével. Tehát például az egyik setup motor az adatokat továbbküldésénél nem egy multiprocesszorokból álló tömböt céloz, hanem direkten egy multiprocesszort. A belső vezérléstől függ, hogy melyiket.
A gyűrűs buszt korábban megválaszoltam: [link]
Látszatra egyébként az AMD és az NV is egy tömbösítésben hisz, és a tömbön belül mindketten inkább keresztkötést használnak. De amíg az NV a tömbök összekötését is inkább így oldja meg, addig az AMD egy gyűrűs buszra fűzi ezeket. Az AMD a Vega esetében ezt Infinite Fabricra cseréli, ami egy NoC-szerű megoldás.
A gyűrű vagy NoC teszi lehetővé, hogy olyan dolgokat rakjanak a hardverbe, mint a GDS. Ezzel ugye képesek az egész hardveren belüli munkát szinkronizálni. Az NV erre nem képes, mert csak egy GPC-n belül képesen fenntartani a szinkront, de GPC-n kívül már nem, illetve technikailag megtehetnék, csak annyira felesleges. A miértre az a válasz, hogy a global ordered append csoporton belül a legfontosabb függvény lényegében azt igényli, hogy maguk a wave-ek a dispatch sorrendjében fussanak le. Ezt az AMD úgy oldja meg, hogy a hardver folyamatosan kommunikálhat a GDS-en keresztül, hiszen mindegyik multiprocesszor hozzá van kötve ehhez a chipen belüli tárhoz. A szinkronizáció úgy valósul meg, hogy a GDS-be kerülő adatok alapján kapják meg a multiprocesszorok az engedélyt a wavefrontok futtatására, és ez garantálja a korrekt sorrendet. Ennek persze van egy olyan hátránya is, hogy globális szinkronizáció mellett minden multiprocesszor csak egy wavefront futtathat, de erre jött a GCN4-ben az utasítás-előbetöltés, illetve az, hogy a chipen belül marad a munka elég nagy előny. A global ordered append esetében ezt a funkciót az Intel és az NV emulálja. Erre már mindkét cégnek van drivere, és úgy csinálják, hogy a meghajtók lefoglalnak egy tárterületet a VRAM-ból. Az NV 128 kB-ot foglal le, igazából ez bőven elég, maga a lefoglalás a lényeg. Ezen a területen belül történik majd meg a szinkronizáció a processzor segítségével. Itt is multiprocesszoronként egy warp/wave/akármianevegyártónbelül fut, de a problémát az emulált megoldással az, hogy amíg tart az adatok kiírása és olvasása a szinkronizációra fenntartott memóriaterületre, addig egy teljes munkastop van a GPU-ra. Tulajdonképpen a memória elérése, a munkastop, illetve a késleltetés átfedésének ellehetetlenítése okozza a milliószoros teljesítménykülönbséget. Erre a függvényre tényleg durván rá kell tervezni a hardvert, hogy haszna is legyen, szabvány ide vagy oda.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
namaste
#27960
üzenetére
Inkább crossbarhoz hasonló.
Ennél publikusabb nem lesz, hiszen a fejlesztők számára igazából lényegtelen, hogy a lapka belülről milyen buszkonstrukciót használ a blokkok összekötésére.
Nyilván az Infinite Fabric egy neve a technikának. Pontosabban egy gyűjtőnév, ami több buszt, protokollt, vezérlőt jelent. Ezek közül lesznek lapkán kívülre vezetett buszok (pl.: GMI), és belső buszok. Topológiára vonatkozóan azért nincs meghatározás, mert maga a rendszer ebből a szempontból megválasztható, lehet pont-pont kapcsolatú, vagy gyűrűs, vagy hálós, esetleg torus. Ez azért van így csinálva, mert az Infinite Fabric többféle lapkában lesz, és CPU-ba más topológia kell, mint GPU-ba. A Vega 10-ben hálós lesz. A Summit Ridge-ben gyűrűs van.
Pont az a lényege. Ha több wave éri el ugyanazt az atomi számlálót, akkor a wave-ek a létrehozásuk sorrendjében kapnak hozzáférést. Ugye ez manapság nem így van, mert a GPU-k egy multiprocesszoron eleve több konkurens wave-vel dolgozhatnak, így ha az egyik wave adatigénylést kér, akkor az adat megérkezéséig egy másik wave dolgozhat. Ezzel ugye elfedik a hardverek az adatelérésből származó késleltetést. Emiatt a wave-ek ma nem a létrehozás sorrendjében vannak futtatva.
Nem hiszem, hogy ahhoz teszt kell, hogy kijelentsük a GPU-n belül tartott munka sokkal gyorsabb, mint a GPU-n kívülre vitt. Ezért is kap ennyi támadást ez a fícsőr, mert ez a konzolokra jó, de a PC-re egyáltalán nem, ilyen formában semmiképp.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
namaste
#28116
üzenetére
De nem garantálja, hogy a wave-ek a beérkezés sorrendjében futnak le. Ez egy GPU-s specialitás. A wave-ek várnak az adatra, és közben átadják az erőforrást más wave-eknek, amelyeknek esetleg már befutott az adatuk. Ez pedig azt jelenti, hogy a kreálásuk sorrendjétől eltér a lefutási sorrend. Kicsit, de eltér.
Ennek a korrigálására jön a global ordered append csoport, ami tulajdonképpen garantálja, hogy wave-ek munkája a submission sorrendjében fejeződik be a teljes lapkán belül. Hasonló az elv, mint a ROVs esetén, csak compute shaderekre.
Na most erről többször értekezve lett már számos szakmai fórumon, hogy erre azért baromira kell gyúrni hardverből is. Leginkább egy globális adatmegosztásra fenntartott memóriával, amivel szinkronizálható a wave-ek munkája. Ha ilyen nincs a hardverben, akkor a szinkronizálás elvégezhető a VRAM-ban, csak hát az nem egy gyors dolog lesz.Azért érdemes egyébként a lapkán belül tartani a munkát, mert a szinkronizáláshoz az kell, hogy multiprocesszoronként csak egy wave fusson, tehát eleve kiesik egy csomó sebesség azáltal, hogy nem lehet átlapolni a memória-hozzáférés késleltetését. Ez ellen lehet küzdeni persze előbetöltéssel. Viszont a szinkronizáció idejére le is kell állítani a munkát, vagyis okvetlenül fontos, hogy maga a szinkronizálás pár órajel alatt meg legyen oldva, és ne kelljen sokszáz ciklust várni a VRAM-ba való trippel.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
namaste
#28157
üzenetére
A szinkronizálásra vonatkozó memória-hozzáférés késleltetésével lesz lassabb. Wave-enként nagyjából 100 ns-os lesz a büntetés az efféle emulációval.
Sokféle emuláció létezik, de egyik sem lesz gyors.A dedikált hardverrel nem megy sokra egyik gyártó sem, ha multiprocesszoron kívül kell szinkronizálni.
Az egyébként nagyon igaz, és ezt nem lehet letagadni, hogy maga az alapprobléma sokféleképpen megoldható. Tehát van számos hardverünk, mondjuk úgy, hogy 85-90%-ig igen hasonló működéssel. Vagyis lehetne olyan orderes atomics specifikációkat kérni a shader modell 6.0-ban, ami ha nem is az összes, de a legtöbb hardvert jól lefedi. Lehet, hogy nem tökéletesen, de általánosan elfogadható sebességgel, tehát tipikus szabványos megoldást is ki lehet erre alakítani, és ennek az egyik módja nyilván a már meglévő dedikált egységek felhasználása, ami minden hardverben ott van. Ami a lényeg, hogy ezt maga a Microsoft sem tagadja, sosem mondták, hogy a shader modell 6.0 minden esetben optimális lesz a PC-s VGA-k számára. A problémát az adja, hogy a Microsoftot nem tipikusan a PC-s szabványalkotás problémái érdeklik, hanem nekik az a fontos, hogy az Xbox One konzolra írt kódokat ne kelljen módosítani a PC-s porthoz, tehát a PC-s megoldásoknak is olyannak kell lennie, mint amit az Xbox One használ. És innen jönnek elő azok a gondok, amit az Intel már az elején írt, hogy ez a wave operation intrinsics nagyon a GCN-re van írva, és az NV is kifejezetten azt javasolta a fejlesztőknek a GDC-n, hogy a Vulkan megoldását várják, mert az nem egy gyártóra lesz kitalálva, hanem általános lesz. Olyan amilyennek egy szabványnak lennie kell.
A problémát tehát nem tipikusan az jelenti, hogy az Intel vagy az NV szarul fejlesztett hardvert, hanem az, hogy a Microsoft kitalálta, hogy a PC legnagyobb problémája az, hogy a konzolra írt shadert módosítani kell. Ami egyébként részben igaz, részben pedig elég nagy bullshit, de mit tudunk, vagy mit tudnak a gyártók egy olyan Microsoft ellen csinálni, amely azt mondja a gyártók neheztelésére, hogy ha nem tetszik egy fícsőr, akkor ne támogassa. Iszonyatosan sokat fordult a kocka a Microsofttal, amióta nem Ballmer vezeti. Mondjuk úgy, hogy náluk is vége lett a polkorrekt fejlesztésnek.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
válasz
namaste
#33228
üzenetére
Na, szerintem itt van a kutya elásva. ACE-ből van elég, sőt a GCN4 óta a 8 ACE felállásról 4 ACE + 2 HWS-re álltak át. Azaz compute rész vezérlésével nincs gond, s igen, az AMD-nek a compute shadereket kéne ezerrel propagálni, mivel azok megkerülik a ROP-okat.
Ami problémának tűnik, hogy már elég sok ideje a közép és felső kategóriánál 4 shader tömb van, azaz a Tonga, Fiji, P10, V10 ebből a szempontból egyforma, a Hawaii óta nem nyúltak hozzá ehhez a felépítéshez. Najó a P10 meg V10 közvetetten próbált javítani, de erről később.
Ugyanúgy 8-9 illetve 16 CU-t kell etetni egy shader tömbön belül és egy geometria feldolgozó van rájuk. Lehetséges, hogy a Fury és a V10 esetén nagyon jót tett volna, ha 4 helyett 6 vagy 8 tömbbe szervezik a CU-kat, csak ezt nem tehetik meg csak úgy.
Itt jön a képbe a Vega, ami már ezen a szinten hoz újításokat: ott az NGG, ami hozza a primitive shadert, s ettől elvileg elég sokat lehet várni, mert a Vega alap 4 tri / clk sebességét többszörösére emelheti. Összevetésként a GM204 / GP104 is 4 tri / clk, a GM200 / GP102 6 tri / clk sebességet tud, s persze Nv oldalon jóval magasabbak az órajelek. A másik meg ugye a DSBR.
Alapvetően szerintem az a probléma, hogy az GCN hiába nagyon ütős compute terén, egyszerűen nem tudnak hatékony körítést csinálni hozzá grafikai feladatokra.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
namaste
#33228
üzenetére
Ez elméletben jól hangzik, viszont akkor mi magyarázza a Tonga és a Hawaii / Fiji közötti különbséget?
(#33229) lezso6: az elméleti 4-6 tri / clk csak az egyik része a sztorinak. Hasonlítsd össze a fenti linken a GM204-et és a Hawaii-t - rendes rajzolásnál a reject durván magasabb a GeF esetén, tesszeláció mellett meg mind a rajzolás, mind a reject. Ha ezeken a területeken sokat javít a Vega, akkor egy kicsit tisztább lesz a kép.
Pedro... amigo mio... ma is konzervvért iszunk! Kár lenne ezért a tehetséges gyerekért...
-
#35456
 Petykemano
veterán
namaste
#35455
Petykemano
veterán
namaste
#35455
Petykemano
veterán
válasz
namaste
#35455
üzenetére
Minél drágább a RAM, annál inkább megérné spórolni vele.
De nem lehet, mert abu végül bevallotta, hogy - az ő információ szerint legalábbis - a 4GB/stack-nél kisebb stackeket is ugyanannyiért akarták adni. Még ha nem is ugyanannyi, de ha $60 egy 4GB-os stack és mondjuk 2GB-ért meg el akartak kérni $45-50-t, már az is olyan minimális árelőny, - főleg egy $600-700-os kártya esetén, amiért nem lenne érdemes bevállalni a kisebb ramot, hiába van meg a technológia, ami képes lenne kompenzálni (HBCC)Tételezzük fel, hogy Abu infói a GDDR5 modulokról helyes ($18/1GB). Még $60/stack esetén is - a kategóriához mérten - tekintélyes árelőnyt jelentene egy HBM2-vel szerelt kártya egy 8 modulos polarishoz képest, nem? ($60 + interposer v EMIB + tokozás [vs] $144 + nyák + huzalozás)
Találgatunk, aztán majd úgyis kiderül..
-
Abu85
HÁZIGAZDA
válasz
namaste
#35455
üzenetére
Fizikálisan igen, de más memóriákról van szó. A tokozás miatt bele kell tervezni a TSV-t, vagyis kb. 5000 huzalnak át kell mennie az egyes lapkákon, hogy elérjék a legfelül található memóriát is. Ergo igen eltérő a technológia, amit alkalmaznak, és ez eltérő lapkákat igényel. Ezért sem annyira érzékeny ez a telefongyártók igényire, mert olyan mértékű módosítást igényelnének a HBM-et készítő gyártósorok, hogy értelmetlen ezeket másra átállítani.
A GDDR, DDR és LPDDR sokkal közelebb van egymáshoz technológiailag, így a gyártósoraik sem különböznek jelentősen. Ergo, ha a telefongyártók többet fizetnek az LPDDR-ért, akkor a nem lekötött kapacitásból szemrebbenés nélkül átalakítják a GDDR gyártósorokat LPDDR-hez. És bizony nagyon gyorsan tud így növekedni az ár, hiszen a VGA-gyártóknak nincs más választása, mint rálicitálni a telefongyártókra. Ilyenkor szokták azt csinálni a memóriagyártók, hogy mivel látják, hogy nincs elég gyártósor, így kiépítenek újakat, beterveznek újabb üzemeket a meglévő gyárkomplexumokba, és akkor a memória ára elkezd visszacsúszni, hiszen nem licitálnak egymásra a megrendelők. Na és most nem ez történt, hanem Kína már igen erősen gyanítja, hogy ezek a drága memóriagyártók megegyeztek az elmúlt években abban, hogy senki sem épít majd gyárat, és jól felnyomják a memóriák árát, amiből dőzsölnek egy darabig, nyilván a problémát már két és fél éve látták, a jelenlegi helyzet csak annak a kiteljesedése, hogy szándékosan nem reagáltak rá kapacitásbővítéssel. Emiatt mára igen kellemetlen szintre szökött fel a GDDR és LPDDR ára. A koncepció a memóriagyártóknak igazából megéri. Még ha kapnak is büntit, akkor is annyit kerestek, hogy abból ki tudják fizetni.
Ha olyan olcsó lenne a memória, mint amit a GN ír, akkor a legtöbb OEM a seggét csapdosná a földhöz örömében.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

#45185024
törölt tag
válasz
namaste
#35509
üzenetére
Van ettől egy fontosabb ellentét is.
ABU versus GIBBO
Ocuk becsökkentette a Vegák árát:
*** MASSIVE PRICE DROP ON VEGA UNTIL JUNE 30th: VEGA 56 £450 & VEGA 64 £550 !! ***
Ami ha a MSRP árra rászámítod a játékot (Far Cry 5) meg a custom felárat akkor ott is vagyunk újra mint régen !
Ezer köszönet érte Gerr'y nek.
#8 GIBBO:
Well nothing from AMD most likely until sometime in 2019.
I think there were similar delusional thoughts on something new when they did the crazy deals before XMAS too, they simply do these promotions to increase sell out, there is plenty of vega inventory floating around so such promotions give a needed boost in sales.
Na most akkor mi van az idén érkező új AMD kártyával ? -
Abu85
HÁZIGAZDA
válasz
namaste
#35509
üzenetére
Nem tudja elvégezni más részegység. Nem építették bele a hardverbe azt a tudást, ami el tudja helyezni az erőforrás-leírókat egy tömbbe. Ha megtették volna, akkor nem kellett volna a DX12-be egy Tier_2-es köztes szintet tervezni a bekötésnek, és az NV sem gondolkodott volna hónapokig azon, hogy most azzal járnak jól, ha ezt használják, vagy emulálják le a CPU-ra a legmagasabb szintet.
Az Intel IGP-k vezérlése egészen specifikus. A beállított hardverállapottól függ a végrehajtók viselkedése. Van SIMD8, SIMD16 vagy SIMD4x2 módja. A SIMD8 és a SIMD16 esetében a működés inkább SIMT-re hasonlít, míg a SIMD4x2 mód mellett inkább SIMD a modell.
Ehhez képest, ha megkapta a nyolcmagos izomprocit, rögtön felgyorsult DX11-es szintre. Biztos magic...

(#35514) Jack@l: A Vega 20 első körben HPC-be megy.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

Jack@l
veterán
válasz
namaste
#35537
üzenetére
Jól látom hogy egy pentium + 1030 lenyomja a perpill legerősebb amd APU-t?
Akkor még mindig nem jött el az apu-k ideje...A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.
-

Raggie
őstag
válasz
namaste
#36539
üzenetére
Ezt írtam én is, hogy remélem a raytracing számításokra pl ki lehetne használni ezeket a szunnyadó kapacitásokat.
Nyilván nem kell, csak hát amikor megnézi az egyszeri júzer a kártyák összehasonlítását mégis azt látja, hogy Vega64-nál 13TFlops, 1080-nál 9 TFlops és játékban mégis ugyanannyi efpées.Clint Eastwood FTW



 de amúgy nem kizárható - nem tudjuk, hogy milyen lesz a backend felépítése, és azt sem, hogy a Hawaii-ban mennyire overkill a 64 ROP. ha megint a 2 hatványa kell legyen a ROP-ok száma, akkor nem kizárt, hogy emelik a tétet.
de amúgy nem kizárható - nem tudjuk, hogy milyen lesz a backend felépítése, és azt sem, hogy a Hawaii-ban mennyire overkill a 64 ROP. ha megint a 2 hatványa kell legyen a ROP-ok száma, akkor nem kizárt, hogy emelik a tétet. A GCN 1.1-től kezdve az architektúra-ábrák úgy ábrázolják a ROP-okat, ahogy írod, viszont a mélyebb cikkek mindig hozzáteszik, hogy a ROP-ok közvetlenül vannak bekötve az MC-khez, nem a belső adatbuszon keresztül. Én ebből ezt feltételeztem, hogy kidobták a crossbart, és visszatértek az 1:1 megfeleltetéshez - ez lehet téves, de a Hawaii és a Tonga esetében gyanúsan ragaszkodtak a 8 ROP / 64-bit felálláshoz, pedig legalább az egyik GPU-nak nem az az optimális konfiguráció.
A GCN 1.1-től kezdve az architektúra-ábrák úgy ábrázolják a ROP-okat, ahogy írod, viszont a mélyebb cikkek mindig hozzáteszik, hogy a ROP-ok közvetlenül vannak bekötve az MC-khez, nem a belső adatbuszon keresztül. Én ebből ezt feltételeztem, hogy kidobták a crossbart, és visszatértek az 1:1 megfeleltetéshez - ez lehet téves, de a Hawaii és a Tonga esetében gyanúsan ragaszkodtak a 8 ROP / 64-bit felálláshoz, pedig legalább az egyik GPU-nak nem az az optimális konfiguráció. ), bár a lényegen csak annyit változtat, hogy nem 4 csatorna és a ROP-ok viszonyáról van szó, hanem 32-éről.
), bár a lényegen csak annyit változtat, hogy nem 4 csatorna és a ROP-ok viszonyáról van szó, hanem 32-éről.









Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

- ÚJ EVGA GeForce RTX 3080 FTW3 ULTRA GAMING 10GB GDDR6X (10G-P5-3897-KR) Videokártya
- ÚJ GIGABYTE AORUS GeForce RTX 3080 10GB GDDR6X GAMING BOX Videokártya
- Intel ARC A380 6GB (Asrock)
- Zotac RTX 3060 12GB GDDR6 GAMING Twin Edge Eladó! 83.000.-
- XFX AMD Radeon HD 6870 DD 1GB DDR5 Dual DP HDMI PCI-E videokártya
Állásajánlatok

Cég: Ozeki Kft.
Város: Debrecen

Cég: Promenade Publishing House Kft.
Város: Budapest