Maxwell, a hatékony maximalista
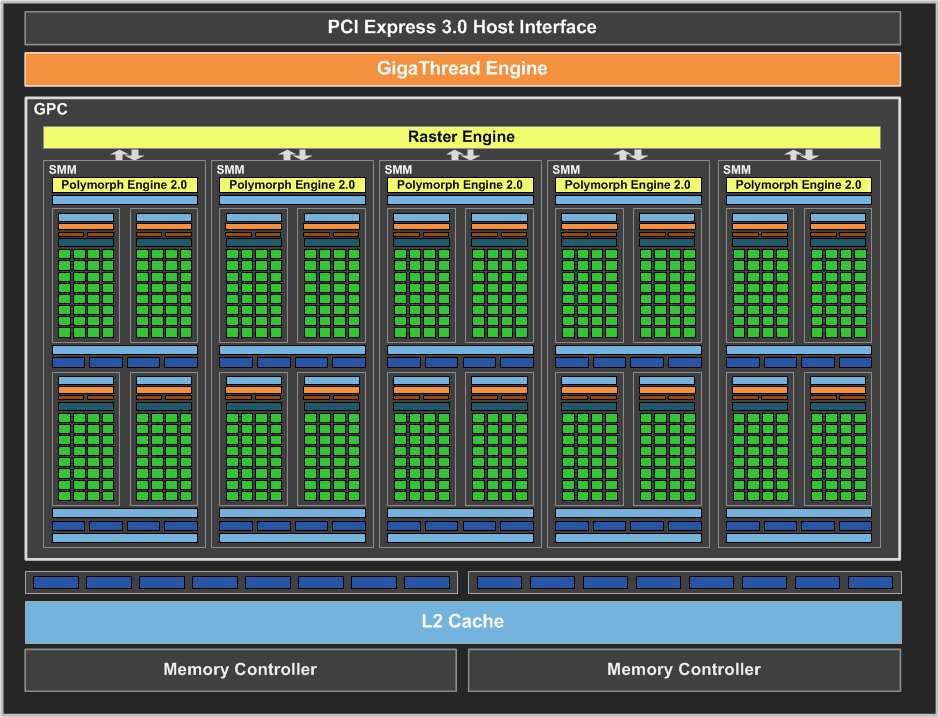
Az NVIDIA évek óta fejleszti a Maxwell architektúrát, melynek kapcsán abszolút a hatékony energiafelhasználást helyezték előtérbe. Ez tökéletesen látszik a GM107-es kódnevű lapkán, mely méretéhez képest lényegében alig fogyaszt, illetve kiterjedése sem túl nagy, tehát a Maxwell minden korábbinál hatékonyabban vethető be majd ultramobil szinten is a jövőben érkező Parker rendszerchipben. Addig azonban még rengeteg hónap telik el, így egyelőre az aktuális rendszert vizsgáljuk meg, mely 28 nm-es gyártástechnológiával készül. Az 1,87 milliárd tranzisztorból felépülő, 148 mm²-es chipbe 5 darab újszerű streaming multiprocesszort sikerült beépíteni, amit az NVIDIA mostantól SMM-nek, azaz Maxwell streaming multiprocesszornak hív.

[+]
A streaming multiprocesszorok felépítése a Keplerhez képest jelentősen megváltozott. Egy ilyen egységen belül négy nagyobb compute blokk került kialakításra, amelyek közös utasítás gyorsítótárat használnak. Mindegyik compute blokk rendelkezik egy utasítás pufferrel, ami nyilvánvalóan az utasítás gyorsítótárból szerzi be az aktuális munkához szükséges információkat. Az egész rendszer komplex ütemezést használ, ami részben a hardverben és részben a szoftverben valósul meg. A hardveres részért a már megszokott GigaThread motor felel, míg az ütemezés szoftveres oldala természetesen a driver fordítójának reszortja. Ebből a szempontból nincs sok változás a Keplerhez képest, de a Maxwell esetében az NVIDIA némileg több feladatott bíz a szoftveres oldalra, amivel természetesen energiát lehet spórolni.
Egy compute blokk két feladatirányító egységet (dispatch) és egy darab warp ütemezőt használ, amelyek 32 darab, úgynevezett CUDA magot etetnek, így az utasításszavak 2 darab, 16 utas feldolgozón hajtódnak végre párhuzamosan. Mindegyik CUDA mag rendelkezik egy IEEE754-2008-as szabványnak megfelelő, 32 bites lebegőpontos végrehajtóval, melyek támogatják a MAD (Multiply-Add) és az FMA (Fused Multiply-Add) instrukciókat. Mindegyik compute blokkban közös regiszterterület található, melynek kapacitása 64 kB. Utóbbi nagyon fontos változás, mert egy CUDA magra levetítve nőtt a regiszterterület. Ezzel a Maxwell megoldja a Keplernek azt a problémáját, amikor a korábbi SMX blokk egyszerűen képtelen volt hatékonyan dolgozni, mivel regiszterhiány miatt a 192 feldolgozóból egyszerre csak 128 működhetett. A Maxwell felépítésével ilyen eset már semmilyen kódnál nem fordulhat elő.

Az SMM [+]
A compute blokkonon belül található még 8 darab, a speciális funkciókért felelő egység (SFU), melyek a trigonometrikus és transzcendens utasítások mellett az interpoláció feladatát is elvégzik. Ez önmagában a Keplerhez képest nem változott, de az NVIDIA a Fermi óta küzd az interpoláció megfelelő kiegyensúlyozásán. A Fermi esetében a fixfunkciós interpolátorok száma egyszerűen kevés volt, amire a Kepler architektúra során a tervezők úgy válaszoltak, hogy technikailag sokszorosára növelték ezek számát. Ez viszont már sok volt, ami végtére is a tranzisztorok pazarlását eredményezte. A Maxwell esetében az NVIDIA belőtte a Fermi és a Kepler közötti értéket, azaz technikailag az arany középutat. Mindezek mellett az NVIDIA bármikor bevethetné az interpoláció emulálását. Ez ugyan elvesz némi nyers számítási kapacitást a rendszerből, de ugyanakkor maximálisan igazodhat a feldolgozás a különböző programok igényeihez.
A GM107 a textúrázási képességek területén is sokat változtatott. Az egyes streaming multiprocesszorok mostantól két darab textúrázó blokkot tartalmaznak, melyekben egyenként négy textúracímző és textúraszűrő található, és ezekhez csatornánként négy mintavételező tartozik. Egy textúrázó blokkot két compute blokk használ egyszerre. Ez hardveres szinten van bedrótozva, így mondható az, hogy az SMM két nagy feldolgozó tömbre oszlik, amelyek két compute és egy textúrázó blokkot tartalmaznak. Ehhez kapcsolódó változás, hogy a Maxwell esetében a textúrázáshoz való 12 kB-os gyorsítótár technikai értelemben már egy adat gyorsítótár. Ez természetesen tárolhat textúrainformációkat is, de számoláshoz szükséges adatok tárolására is használható. Ennek hozománya, hogy ez a gyorsítótár nem csak olvasható, hanem írható is.
Memóriahierarchia szempontjából a Maxwell architektúra strukturális meglepetéssel ugyan nem szolgál, de a 2 MB kapacitású, megosztott L2 gyorsítótár mérete a GPU-k eddigi történelmében kiemelkedő, ráadásul ezt továbbra is elérheti mindegyik streaming multiprocesszor, és a CUDA magok írhatnak is bele. Maguk az SMM modulok 64 kB-os helyi adatmegosztással (Local Data Share) rendelkeznek, melyen a négy darab compute blokk osztozik. Itt az NVIDIA jelentős energiát takaríthat meg, hiszen technikai értelemben nem rendel direkt LDS-t az egyes compute blokkokhoz, tehát kevesebb tranzisztort is kell erre költeniük. Viszont a DirectCompute 5.0-s szabvány ezt a megoldást direkten nem támogatja, mivel a helyi adatmegosztáson egyszerre nem osztozhat több compute blokk, pontosabban fogalmazva több szálcsoport. A Maxwell ennek áthidalására egy trükköt használ, amivel a 64 kB-os helyi adatmegosztás többféleképpen működtethető. Alapértelmezett módban egy blokk maximum 48 kB-os részt kaphat, de ekkor maga a tár egy időegységben mindig csak az egyik compute blokkhoz tartozhat, míg a másik három compute blokknak olyan feladatot kell futtatni, ami nem igényli a helyi adatmegosztást, viszont a fennmaradt 16 kB-ot az említett három compute blokk feldolgozói közösen hasznosíthatják. Emellett amint a tárkapacitás nagy részét birtokló compute blokkhoz tartozó feladat véget ért, a helyi adatmegosztást rögtön igénybe veheti egy másik compute blokk. Alternatív lehetőség a 32-32 kB-ra való felosztás, ami lényegében a DirectCompute 5.0 által előírt minimális kapacitás egy szálcsoporthoz. Ilyenkor már két compute blokk írhat a saját területébe, de a másik két compute blokk elől ez az erőforrás teljesen el lesz zárva.
A GM107 [+]
Az előbbi koncepció bizonyos feladatoknál rendkívül hatékony feldolgozást jelent, míg elfordulhatnak olyan szituációk is, amikor a lapkában található feldolgozók negyede használható csak ki az adott pillanatban. Itt válik lényeges szemponttá az előző előtti bekezdésben említett adat gyorsítótár, illetve a méretes L2 gyorsítótár, ami segít a Maxwell koncepciójának korlátait kevésbé érzékelhetővé tenni. Annak ellenére, hogy az NVIDIA mindent a fogyasztásnak rendelt alá, a Maxwell compute hatékonysága a legtöbb esetben megközelítheti, illetve le is körözheti a Kepler szintjét. Mindemellett a 64 kB-os helyi adatmegosztást a DirectCompute 5.0-tól eltérő platformok – mint például a CUDA – hatékonyabban is kihasználhatják.
A memóriavezérlő tekintetében az NVIDIA továbbra is maradt a crossbarnál. A GM107 128 bites szélességű buszt használ, mely 64 bites csatornákra van szétosztva. Egy-egy csatornához egy ROP-blokk tartozik. Utóbbiból összesen 2 darab van, ami 16 blending és 64 Z mintavételező egységet eredményez.
Az NVIDIA a dupla pontosságot a GM107 esetében nagyjából úgy oldja meg, ahogy ezt teszi a GK110-es lapkában. Jelen esetben minden compute blokkhoz egy-egy darab speciális CUDA mag tartozik. Technikai értelemben ezek az SMM részei, viszont két-két speciális CUDA magon osztozik két-két compute blokk. Ennek következtében egy SMM-ben összesen négy dupla pontosságra tervezett mag található, ami a teljes lapkára nézve 20 feldolgozót eredményez, és ez a GeForce GTX 750 Ti esetében lényegében 40,8 GFLOPS-os tempót jelent.
A cikk még nem ért véget, kérlek, lapozz!





