
- Projektor topic
- Milyen billentyűzetet vegyek?
- Videós, mozgóképes topik
- Most vegyünk RAM-ot, mert drágulni fog
- Milyen belső merevlemezt vegyek?
- CPU léghűtés kibeszélő
- Az agyagtáblás számítógép, avagy ne röhögtess !
- Fejhallgató erősítő és DAC topik
- Azonnali informatikai kérdések órája
- Milyen videókártyát?
Hirdetés
-


Felárat fizet az atomenergiáért a Microsoft
it A Jefferies szerint a Microsoft prémium árat fizet a Constellation számára, hogy indítsák be a Three Mile Island-i atomerőművet.
-
Billentyűzettel autóznék újra, van még ilyen gém?
lo Régebben voltak billentyűzettel jól irányítható "árkád" autós játékok, most csak két ilyet ismerek:...
-


Két hét múlva startol a Dimensity 9400
ma A 3 nm-en várt MediaTek csúcslapka odapakolna a Snapdragon 8 Gen 4-nek és az Apple A18 Prónak is.




-

PROHARDVER!
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
Még nem tudni. Az NDA a megjelenés utánra van tűzve, de szerintem ez meg lesz változtatva, mert értelmetlen. Valószínűleg a megjelenés pillanatában lesznek tesztek.
(#29854) KillerKollar: Ennyi pusztán az elméleti adatokból kiindulva lehet a gyakorlatban is, de nem állandóan. Tehát a Horizon is képes bizonyos helyeken 10%-os differenciát produkálni, de ezek ritka esetek a teljes játékmenet során, és az átlag differencia inkább 6% körüli lesz az új busz javára. Nagy átlagban egy buszt erősen terhelő játéktól nagyjából azt a differenciát fogod látni, mint a Horizonban.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 nubreed
#29862
üzenetére
nubreed
#29862
üzenetére
Alapból nem terveztek, de ugye az AMD beletolt egy csomó pénzt a játék promójába, így innentől bármi lehet, mert ezért a pénzért szoktak is kérni dolgokat a cégek.
(#29864) paprobert: A DirectStorage önmagában nem. Az Xbox-féle Velocity nem csak ebből áll, hanem a DirectStorage és az SFS kombinálásából. Na most a memóriakíméléshez SFS is kell. A DirectStorage abban fog segíteni, hogy nem kell majd 24-magos proci a tartalmak kikódolásához, de a memória menedzselésére nincs igazán befolyása.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#30111
Abu85
HÁZIGAZDA
gainwardgs
#30096
Abu85
HÁZIGAZDA
válasz
 gainwardgs
#30096
üzenetére
gainwardgs
#30096
üzenetére
Kamu.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#30114
Abu85
HÁZIGAZDA
gainwardgs
#30112
Abu85
HÁZIGAZDA
válasz
gainwardgs
#30112
üzenetére
Hát nem 1,7 GHz lesz az órajele.

Nézzétek meg a két konzolt. Az Xbox Series X 1,8 GHz fölött van AVFS nélkül. A PS5 már AVFS-sel működik. De a PC-s RDNA2 valamivel modernebb ezeknél.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#30120
Abu85
HÁZIGAZDA
gainwardgs
#30117
Abu85
HÁZIGAZDA
válasz
gainwardgs
#30117
üzenetére
Attól függ, hogy mi lesz az órajele. Ezen nagyon sok múlik. Nem 1,7 az biztos.
 Már a PS5 képes 2,23 GHz-re, és abban még nem is a hőmérséklethez van kötve az AVFS, ráadásul a PC-s RDNA2 újabb dizájnkönyvtáron jön.
Már a PS5 képes 2,23 GHz-re, és abban még nem is a hőmérséklethez van kötve az AVFS, ráadásul a PC-s RDNA2 újabb dizájnkönyvtáron jön.
A két konzol az AMD High Density Library-jét használja, míg a PC-s GPU-k a High Performance verziót fogják.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#30128
Abu85
HÁZIGAZDA
gainwardgs
#30123
Abu85
HÁZIGAZDA
válasz
gainwardgs
#30123
üzenetére
Az AMD működése könnyen kiismerhető. Emlékezz vissza, hogy mely termékeket hájpolták a megjelenések előtt, és melyekről nem beszéltek egyáltalán. Látni fogod, hogy akkor jöttek a legjobb fejlesztéseik, amikor teljes kussban voltak.

Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
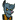 torma1981
#30269
üzenetére
torma1981
#30269
üzenetére
Hol írtam ilyet?
(#30270) gbors: Többször írtam, hogy alapvetően a DXR 1.1-es teljesítmény gyorsult az Ampere-ben, a DXR 1.0-val nem igazán lehet mit kezdeni, mert maga az API működése az oka a lassú teljesítménynek. Előbb meg kell várni az új játékokat, amiket már DXR 1.1-re írnak. Azoknál tényleg nagyon gyors lesz.
(#30272) Jack@l: Már más reagált rá, hogy benézte: [link]
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#30606
Abu85
HÁZIGAZDA
FollowTheORI
#30600
Abu85
HÁZIGAZDA
válasz
 FollowTheORI
#30600
üzenetére
FollowTheORI
#30600
üzenetére
Miféle I/O? Az RTX IO? Az pont, hogy növelni fogja a memóriaigényt.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#30611
Abu85
HÁZIGAZDA
FollowTheORI
#30609
Abu85
HÁZIGAZDA
válasz
FollowTheORI
#30609
üzenetére
De mit? Én most nem arról beszélek, hogy a 10 GB kevés vagy sok, hanem ha az RTX IO-ra gondolsz, akkor az alapvetően arra van, hogy a processzormagokról vegye le a terhelést, amikor tömörített adatot kell a VRAM-ba másolni. Ezt ma is csinálják a játékok, és úgy, hogy bemásolják a tömörített adatot a rendszermemóriába, kicsomagolják a procimagokon, majd átmásolják a kitömörített tartalmat a VRAM-ba.
Ha ezt a folyamatot csak a GPU csinálja, akkor a VRAM-ba kell másolni a tömörített adatot, és a kicsomagolt adat nyilván oda kerül, tehát maga a kitömörítés feladatköre ugyan leveszi a procimagokról a terhet, de annak az árán, hogy megnő a VRAM terhelése, mert ugye a semmit nem tudod kicsomagolni, tehát a tömörített adatot tárolnod kell a VRAM-ban, amit ma például nem ott szokás tárolni.Nem igazán értem, hogy honnan jön, hogy az RTX IO arra való, hogy csökkentse a VRAM terhelését. Az NVIDIA egy szóval nem említette. Arra való, hogy a processzorról vegye le a terhet, de ennek hátránya, hogy növeli a VRAM terhelését. A DirectStorage sem a VRAM hatékonyabb kihasználására van, ez egy teljes félreértés.
Ettől egyébként elég lehet a 10 GB, csak nem az RTX IO miatt, mert az pont ront a helyzeten.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#30615
Abu85
HÁZIGAZDA
FollowTheORI
#30612
Abu85
HÁZIGAZDA
válasz
FollowTheORI
#30612
üzenetére
Értem már hol megy félre a technológia értelmezése. Na most ez nagyon nem így működik. A memóriamenedzsment allokációk szintjén történik, és a rossz hatásfok alapvetően annak köszönhető, hogy egy csomó allokációval kell elbánni a VRAM-on belül, és ezek az allokációk különböző méretűek, vagyis a folyamatos cseréjükkel keletkeznek közöttük üres helyek, ahova már nem tudsz akármilyen allokációt berakni, tehát mondjuk egy 8 GB-os VGA-n idővel eléred azt, hogy a valós memóriahasználat 6,4 GB lesz, és hiába kellene mondjuk beszúrni egy 300 MB-os allokációt, nincs egybefüggően 300 MB-nyi szabad terület, hanem csak töredezve van meg. Ettől lesz rossz a memória felhasználásának hatékonysága, és ezen alapvetően szintén ront a DirectStorage/RTX IO, mert sokkal több lesz az adatmásolás, tehát sokkal gyorsabb kialakul egy rossz hatásfokot biztosító töredezettség a VRAM-ban.
A PS5 nem a DirectStorage-hez hasonló IO API-jával spórol a memóriával, ahogy az XSX sem, hanem a finomszemcsés adatmenedzsmenttel. Tulajdonképpen az új konzolok megoldása két oszlopra épít, az új IO API-ra, valamint a finomszemcsés adatmenedzsmentre. Ebből az IO API úgy néz ki, hogy jön PC-re, az NVIDIA bejelentette az implementációt rá, de a memóriával való spóroláshoz kell a másik oszlop is, ami még nincs meg PC-n. A finomszemcsés adatmenedzsment egyébként azt csinálja, hogy száműzi az allokációk szintjén történű memóriamenedzselést. Egyszerűen 4 kB-os lapokat olvas be, és így soha nem alakulhat ki a memóriában rossz kihasználást eredményező töredezettség, mert minden adatbeolvasás 4 kB. Emellett ez a megoldás hardveres hátterű, a konzolok memóriavezérlőjébe van építve egy menedzsmenttért felelős hardver, ami szoftveres szintről hardveresre viszi ezt a terhet. Tulajdonképpen gyorsítótárat csinál a memória egy részéből.
Ahhoz tehát, hogy a PC elérje a konzolok megoldásait, nem elég a DirectStorage API, az csak a probléma egyik felét oldja meg, a másikat rosszabbá teszi, ezért alkalmazzák az új IO API-kat a konzolok finomszemcsés adatmenedzsment mellett, ami megoldja a probléma másik felét.
És még egyszer kiemelem. Ettől még elég lehet a 10 GB az RTX 3080-ra, de az RTX IO nem segít azon, hogy elég legyen, hanem konkrétan ront. Máshogy kell majd elérni, hogy egy alkalmazás memóriaigénye ne haladja meg a 10 GB-ot. Erre vannak praktikák egyébként, tehát nem reménytelen a helyzet. Akár olyan módon is megoldható, ahogy például a Capcomnak a motorja csinálja, hogy elkezdi betölteni a max textúrákat, amikor pedig kezdenek kifutni a helyből, akkor elkezdik lecserélni őket kisebb részletességűre. Teljesítmény szempontjából nem éri majd hátrány a játékost. A mostani címeiket is 16 GB-ra tervezik, és nem láttam még azért anyázni egyetlen 16 GB-os VGA-val nem rendelkező játékost sem, hogy a játék némelyik textúra minőségét idővel leveszi közepesre, mert nincs elég VRAM-ja. Egyszerűen nem tűnik fel a játék hevében.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#30617
Abu85
HÁZIGAZDA
FollowTheORI
#30616
Abu85
HÁZIGAZDA
válasz
FollowTheORI
#30616
üzenetére
Persze, csak ezt nem az IO API-k biztosítják, hanem a finomszemcsés adatmenedzsment, mert az tényleg azt viszi a memóriába, ami kell. Pont az a baj a mostani, allokációkra építő modellel, hogy ha kell neked mondjuk egy textúrából fél megabájtnyi adat, akkor be kell másolni a memóriába az egész textúrát, ami bőven több az igényelt adatnál. De ez már évek óta probléma, nem most jöttek rá, csak nagyon nehéz megoldást kínálni rá. A konzoloknál az lett kitalálva, hogy másold csak be azt a fél megabájtnyi adatot, ami kell, a többit pedig hagyd ott az SSD-n, de ezt nem az IO API csinálja, hanem a hardverbe épített memóriavezérlő menedzsment egysége, ami szimplán gyorsítótárként használja a memória egy részét és a címzett 4 kB-os lapokat bemásolja.
Az tehát tök jó felvetés, hogy nem kell mindent a memóriában tartani, csak ezt nagyon nem egyszerű megoldani. Valószínűleg a Microsoft kitalál majd valamit, előbb a DirectStorage-et hozzák át, aztán majd kidolgoznak a finomszemcsés adatmenedzsmentre is valami szabványát. Ez biztos egy fontos kérdés a GAB-on belül, csak nagyon sok eltérő architektúra van, többeknek nincs is x86/AMD64 licencük az egyszerű megoldásra, tehát kell majd valami olyan specifikáció, ami a host CPU architektúrájától teljesen függetlenül működik, és azt már nyugodtan lehet szabványosítani. De hogy mikor? Szerintem dátumot még senki sem lát, attól függ, hogy a gyártók mennyire tudnak megegyezni a kérdésekben egymással. Egyszer amúgy tuti lesz rá megoldás, és akkor arra el is kezdhetik a cégek tervezni a kompatibilis memóriavezérlőket.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ugyanarra nem, amire a konzolok.
A konzolok most pusztán az alaptechnológiát figyelembe véve az AMD HBC technológiájának az inkluzív cache módját használják a hierarchikus lapozással, az IO tekintetében pedig az AMD DirectGMA megoldása van kiegészítve a specifikus kitömörítőblokkal, ami a Sony és a Microsoft esetében is ugye saját fejlesztés, tehát ez az egyetlen elem, amit nem nyersen az AMD szállít.
Az IO API tekintetében itt az a jó hír, hogy a DirectGMA sok-sok éves technológia, míg a kitömörítőblokk helyettesíthető pusztán általános feldolgozókkal, GPU-król van szó, a hasonló műveletekben veszettül jók, lásd kriptobányászat. Az NV is erre épít igazán. Az RTX IO lényegében a sok-sok éve létező GPUDirect megoldásokra épül, és a kitömörítést megoldják a shaderek. Ezért sem kell Ampere az RTX IO-hoz, hanem elég a Turing is, de ha akarnák, akkor elég lehetne a Pascal és a Maxwell is, nincs itt semmilyen nagy hardveres csoda. Ha mondjuk az AMD nem is tervez kitömörítőblokkot, akkor ugyanúgy tudják használni a DirectGMA és a shadereket, és náluk is vissza lehet menni egészen a korai GCN-ekig is a támogatást tekintve. Tehát a DirectStorage hardveres igénye nagyon-nagyon régi VGA-val is teljesíthető, a kérdés az, hogy akarnak-e hozzá drivereket írni. De ha mondjuk az újhoz és az egyel korábbi generációhoz írnak az már jó, mert a DirectStorage jövőre még csak preview, tehát megjelenni 2022-ben fog, és 2023 előtt nem igazán fogják használni, addigra még két generáció érkezik, tehát mondjuk a Pascalra, vagy a GCN-ekre már nem is lesz támogatás a driverben, szerintem ezért sem fogják magukat törni azon, hogy a régebbi kártyák megkapják.
Az IO API tehát könnyű falat PC-n. A finomszemcsés adatmenedzsment viszont eléggé kemény dió. Maga a HBCC szegmens, vagyis a HBC technológia exkluzív cache módja nagyon épít arra, hogy a GPU-ban legyen x86/AMD64-es címfordító. Ilyen formában ez nem egy átfogó megoldás a piacnak, mert képes ilyenre az Intel és az AMD. Ráadásul a HBCC szegmens az tud a rendszermemóriából dolgozni, de az SSD-ről nem.
A konzolok megoldásának másolata az inkluzív cache mód, amit támogatnak a Vega és a Navi termékek, de ez meg nem működik csak úgy driverből, tehát kell hozzá egy API, de nem olyan, amilyet most kínál az AMD, mert az aktuális driver runtime annyi, hogy konfigurálhatóvá teszi a fejlesztőknek a rendszermemóriában a működést, de ez azért eléggé a töredéke annak, amit a konzoloknál meg lehet tenni. Például a driverben abszolút nincs implementálva a gaming Radeonokra az SSD-n való adatelérés. Ehhez van egy külön SSG API, ami viszont csak a Radeon Pro SSG-n működik.
Szóval amennyire jól állnak a gyártók az IO API frontján olyan para a helyzet a finomszemcsés adatmenedzsment szempontjából. Ugyan az AMD-nek megvan hozzá a technológiája, hogy lemásolják a konzolok technikai működését, de az csak úgy magától, driver szinten bekapcsolható formában nem fog működni, ahhoz kell egy új API, ami nem olyan limitált, mint a mostani opciók, majd utána masszírozni kell a fejlesztők tökeit, hogy azt azért támogassák is. Maga a driveres megoldás, vagyis a HBCC szegmens ugyan segít valamennyit, de az egy félmegoldás. Leginkább a régebbi játékokra jó, de az új IO API-val, a DirectStorage-dzsel nagyon nem lesz majd barátságban.
Ezt a gondot mindenképpen egy új szabványban kell megoldani, még ha az AMD hoz is egy saját API-t, az a piac problémáján nem segít. A HBCC szegmens pedig a DirectStorage-es játékokkal nem lesz puszipajtás.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ez nem függ az AMD-től. A probléma az, hogy jelenleg az 1 GB-os GDDR6 memóriák sokkal olcsóbbak, mint a 2 GB-osok, míg GDDR6X-ből keveset gyárt a Micron. Utóbbinál abba gondolj bele, hogy ha 20 GB-tal jönne a 3080, akkor fele annyi VGA-t tudnának előállítani.
Az AMD csak azért hoz 12 és 16 GB-ot, mert a memóriabuszukra így jön ki az olcsó 1 GB-os GDDR6-tal a kapacitás. Itt mindenki az olcsóságra megy rá, és az adott konfigurációra kiépíthető minimumot adják. Többre jelenleg nincs lehetőség, vagy azért mert nincs 2 GB-os GDDR6X, vagy azért, mert a 2 GB-os GDDR6 sokkal drágább az 1 GB-os verziónál.
Ez jövőre megváltozhat, ha a Micron már nagyobb mennyiségben gyártja a GDDR6X-et, akkor jöhet a 20 GB-os verzió, és azzal kaphat egy 16 GB-ost a 3070. De amíg a Micron nem zárkózik fel az igényekhez, addig nehéz mozogni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 #98320896
#30908
üzenetére
#98320896
#30908
üzenetére
Az NVIDIA nem tiltja az AIO vizet. A gyártók döntése, hogy mit használnak. A gyári tuningos megoldásoknak azért van batár nagy hűtőjük, mert OC-ben megküldik a kártyákat, és úgy már nem 350 watt a 3090, hanem 400+. Az EVGA-é 485 watt. A Giga is megküldte gondolom.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#98320896
#31100
üzenetére
Az nem egyetemes igazság, hogy a sugárkövetés mindig a GPU-t terheli. A DXR 1.0/1.1 pipeline ugyan tényleg így van megírva, de a Vulkanba épített sugárkövetés kínál programozható bejárást is, és az már a CPU-t terheli.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Yodamest
#31200
üzenetére
Yodamest
#31200
üzenetére
2080S-hez képest. Írtam korábban, hogy ez a dizájn hasonlóan viselkedik az R600-hoz. Valahol elég hasznos a 16+16 co-issue, valahol pedig nem annyira, és eszerint fluktuál a tipikus teljesítményelőny a 2080S-hez képes 40 és 60 százalék között.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 sakal83
#31208
üzenetére
sakal83
#31208
üzenetére
A slide-ok extrém véglegeket mértek. A tipikus maximális kihasználás melletti előny a 2080S-hez képest 90% környéki. De van ugye negatív véglet is, ahol a 16+16 co-issue alig használható, és akkor ebből a 90%-ból lehet +10-15% is. A játékok nagy részét tekintve a tipikus körülmények közötti előrelépés 40-60% közötti.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Yodamest
#31212
üzenetére
Ez nem attól függ. Az NV nem állított hamisat, csak gondosan kiválasztották azokat az alkalmazásokat, ahol az Ampere dizájnja sokszor be tudja fogni a compute blokkokon belüli második feldolgozótömböt. De nem csak ilyen játékok vannak, hanem létezik másik véglet is, ahol ritkán foghatók be ezek az erőforrások, és akkor az előrelépés a közelében nem lesz a 2x-nek, akár az is előfordulhat, hogy csupán +10-15% lesz belőle. Ezért nem érdemes ennél az architektúránál végletekről beszélni, mert a teljesítmény fluktuációja egészen nagy lehet. A tipikus előrelépést kell nézni, amikor sok játékot átnéznek, és ugyan lehet köztük olyan, ahol mondjuk némelyikben jön +70%, másban csak +30%, de nagy átlagban azért a +40-60% jönni fog.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Változott a warpok ütemezése, illetve az adatelérés késleltetése nőtt. Ez az új felépítés sajátja, ami miatt az Ampere minimális szintű kihasználásához több warp kell, mint a Turing esetében. Ha viszont az adott shader pont annyi warpot futtat, amennyi a Turing átlapolási minimuma, akkor az Ampere ugyanannyi warppal az extra ALU-k ellenére is lényegesen rosszabbul teljesít, mert a korábbinál több warp kell már neki, hogy átlapolja az adatelérést. Ebben a szituációban a Turing még képes működni, míg az Ampere már hátrányban van, és kihasználtságot veszít. Ez egy viszonylag szűk tartomány, de ki az Ampere minimum működéséhez legalább 2-vel több warp kell, mint a Turinghoz, tehát finomabban kell majd bánni a regiszternyomással.
Van egy másik tényező is, amire figyelmeztetve vannak a fejlesztők. Régebben opcionális stratégia volt olyan shadereket írni, ahol rámentél az adatlokalitásra, így magát a warpok számát beáldoztad, hogy az adat jó eséllyel ott legyen a multiprocesszoron belüli gyorsítótárakban. Az Ampere esetében ez a stratégia már nem ajánlott. A Turingon viszonylag sokszor működik, de az Ampere-nél elég ritkán válik be.
Van tehát egy szűk tartomány, ahol hiába hasonló a felépítés a Turinghoz, az Ampere több limitbe ütközik bele, és ez jelentősen ront a kihasználtságán, amit nem igazán tud ellensúlyozni a több ALU-val. A jó hír, hogy ilyen szituáció azért elég ritka, de gyakorlatban is előfordulhat, tehát számolni kell a fejlesztés szintjén az elkerülésével.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Általában nem szokták csurig tekerni, de most valamivel könnyebb dolga volt az NV-nek, mert hozzá tudnak jutni a konzolokhoz. Dev. csomaguk ugye nekik is van, mert szükségük van rá, hogy leteszteljék a PhysX-et, és kiadjanak majd egy erre optimalizált verziót, viszont így azt is letesztelhették, hogy mennyit fogyaszt a konzolokban az RDNA2. Tehát effektíve nagyon jól be tudták határolni, hogy az AMD mire lesz képes a saját megoldásával, és eszerint nyilván hozhattak olyan döntéseket, amivel a korábbi tipikus komfortzónából kivitték a fogyasztást, mert lényegében ki tudták számolni egy PC-s RDNA2 dizájn teljesítményét. Talán nem pontosan, mert ilyen módszerrel azért lehet tévedni, de sokkal közelebbi adatot tudtak betippelni, mint korábban. És erre az adatra reagáltak teljesítmény szintjén, amivel ment a fogyasztás is.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#31370
Abu85
HÁZIGAZDA
Malibutomi
#31369
Abu85
HÁZIGAZDA
válasz
 Malibutomi
#31369
üzenetére
Malibutomi
#31369
üzenetére
Ezek konzolok, fel kell készülni a startra. Talán minden leírást nem adnak át a gyártók, de azt igen, amire az NV-nek szüksége van a PhysX portolásához. Egy bizonyos pontig meg tudják oldani gép nélkül, de tesztelni azért jó lenne élesben, ne a usernél fagyjon már a szoftver ugye...
Azért valószínűleg az AMD-t ez különösebben nem zavarja. Attól, hogy az NV tud számolni a konzolokból, hatékonyan azokra nem tud reagálni. Annyit tehetnek, hogy felviszik az órajelet, ha szükségesnek látják, de ezzel megy felfelé a fogyasztás is.(#31371) Alvin_ti4200: Annyiban van köze az AMD-nek, hogy bizonyos dokumentációkat a konzolok megjelenése előtt ők birtokolnak, tehát ha azt mondják, hogy bizonyos infót nem osztanak meg az NV-vel, mert úgy értékelik, hogy az nem kell nekik a PhysX portolásához, akkor azt az MS és a Sony elfogadja. Ezzel kapcsolatban számos lehetőség van, akár az NV-nél is lehet kérni részlegszintű NDA-t, vagyis a vállalat kijelöl egy munkacsoportot, amely egy bizonyos ideig el lesz vágva a cég többi részértől, stb. Tehát szerződés szinten azért vannak itt lehetőségek. A megjelenés után nagyobb azért a szabadság.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az RTX IO egyáltalán nem arra van, hogy javítson a memória kihasználásának hatékonyságán. Ez csak rontani fog rajta.
A DirectStorage az Xbox Velocity architektúrájának a fele. A memória jobb kihasználáshoz kell a másik technológia is az Xboxból. [link][ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Valamilyen szinten gyakorlati, mert bele lehet futni, tehát fontos felhívni a figyelmet rá, hogy az adatlokalitásra az Ampere-nél nem érdemes optimalizálni, mert például a két új konzol akkor működik igazán jól, ha a shaderek pont késleltetésre optimalizáltak, vagyis az adatlokalitásra koncentrálnak a megírásukkor. Tehát ha egy stúdió erre helyezi a hangsúlyt, akkor a konzolra írt shadereket nem nagyon érdemes módosítás nélkül áthozni, mert pont, hogy beleesnek az Ampere rossz végletet jelentő szcenáriójába. Ez lesz az egyik leglényegesebb szempont ennél a dizájnnál, hogy PC-re legyenek külön Ampere-re optimalizált shaderek, és ne a konzolról fussanak be, mint az aktuális generációban, mert amíg a GCN-re való optimalizálás a Maxwell, Pascal és Turing esetében nem volt igazán gond, addig az RDNA-ra való optimalizálás az Ampere-nek pont nem jó.
Ugye ezekkel az NVIDIA még tud dolgozni, hiszen maga a shader cserélhető a driverből. Tehát megtudják ugyanazt csinálni, mint az AMD a Terascale dizájnoknál, hogy folyamatosan optimalizálják a shader fordítót, cserélik a kódokat, de ezzel a day0 support ugrik, így fontos lenne, hogy már a program jó shadereket szállítson.
A day0 support leginkább abból a szempontból egy igen értékelhető lehetőség az elmúlt években, mert a GPU dizájnokból száműzték a co-issue feldolgozási modellt.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#31533
Abu85
HÁZIGAZDA
gainwardgs
#31524
Abu85
HÁZIGAZDA
válasz
gainwardgs
#31524
üzenetére
3700X lesz. PCI Express 4.0-s lappal kell tesztelnünk. De nem gond, mert már rég áttértünk.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#31535
Abu85
HÁZIGAZDA
gainwardgs
#31534
Abu85
HÁZIGAZDA
válasz
gainwardgs
#31534
üzenetére
Visszafogná. A Horizonben, amivel mi speciel tesztelünk 11% előnye is van a PCI Express 4.0-nak. Azért ez jelentős előny, az átlag simán megvan 7-8%, nem véletlenül van új szabványba kérve a teszt. De mondom nekünk ez nem okoz gondot, már rég áttértünk az új csatolóra.
Fun fact: Még a DirectStorage API-ra is felkészültünk, mert PCI Express 4.0-s SSD-re váltottunk.

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#31538
Abu85
HÁZIGAZDA
gainwardgs
#31537
Abu85
HÁZIGAZDA
válasz
gainwardgs
#31537
üzenetére
Navit másfél hónap múlva kapunk max, nem tudjuk, hogy miben lesz gyors. Most alakítjuk ki a tesztplatformot, és abban mennek végig a VGA-k idén. Vulkan meg DX12-es címekben futnak majd.
(#31539) Rison77: Az NDA dátuma is NDA-s.

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 HoaryFox
#31545
üzenetére
HoaryFox
#31545
üzenetére
Nem hiszem, mert a mi játékaink esetében azért ritka tényező, hogy a PCI Express 4.0 1-2%-nál nagyobb előnyt jelentsen, ugyanis amikor kiválasztjuk a játékot, akkor ellenőrizzük, hogy mennyire sok puffert helyez host coherent és host visible memóriába. A cél az volt eddig, hogy keveset helyezzen, mert az NVIDIA nem támogatta a PCI Express 4.0-t, így nem akartuk itt megfogni a GPU-ikat. Most, hogy viszont támogatja már nyitunk olyan játékok felé, ahol a pufferterhelés nagy része nem csak eszközlokális memóriában érvényesül. Ilyen például a Horizon Zero Dawn, ami az eddigi játékoknál lényegesen több puffert helyez host coherent és host visible memóriába. Most már ez nem gond, mert az NV-nek is van erre hardvere, és ilyen játékokban a PCI Express 4.0 sokat jelenthet, átlag 6-8%-ot simán, peak 10%-ot is.
Úgy tudjuk, hogy a Dirt 5 is hasonló irányba megy, azt is bedobjuk, ha megérkezik.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 manning75
#31577
üzenetére
manning75
#31577
üzenetére
Persze, hogy nem kell. 2.0-s PCI Express interfészben is megy például. Csak 4.0-s sávokkal a leggyorsabb.
(#31572) Yodamest: Igen, nagyjából ez lesz. 4.0-s portban bizonyos játékokban, ahol azért a pufferek jó része host visible és coherent memóriába van pakolva, átlag 6-8%-kal több fps-ed lesz a 3.0-hoz viszonyítva. Ennyi.
Itt látható, hogy miképp viselkednek azok a játékok, amelyek nagyon is erősen használják a host visible és coherent memóriatípusokat: [link] - kell nekik az extra PCI Express sávszél, mert ilyenkor az NVIDIA GPU-nak a rendszermemóriáig kell mennie a pufferekért, és nem mindegy, hogy mekkora sávszéllel olvassák és írják azokat ottan.
Ugyanez igaz az AMD-re, csak azzal a különbséggel, hogy az AMD memóriaszegmentálásánál a CPU megy a GPU VRAM-jába a pufferadatokért, de a gond ugyanaz, nem mindegy, hogy a CPU onnan mennyire gyorsan olvas, és mennyire gyorsan ír.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Laraxior
#31579
üzenetére
Laraxior
#31579
üzenetére
Be.

A legtöbb játékban még nem is lesz hátrányos. Az olyan új típusú játékokban lesz az, mint például a Horizon.
Alapvetően az NV ezért ajánl a tesztekhez PCI Express 4.0-t, mert ők ugyan tudják, hogy melyik játékot nem limitálja ez, de például nyilván figyelembe veszik, hogy valaki esetleg bedobja tesztre a Horizont, és ott azért nagyon nem mindegy, hogy 4.0-s, 3.0-s vagy 2.0-s a 16 sáv. Még a Death Strandinghez is ajánlott, bár az annyira nem nagy gond, mint a Horizon, mert jóval kisebb a grafikai terhelése. De különbség ott is lenne.
Megmondom őszintén, hogy mi is erre vártunk, mert a Horizon esetében nagyon is fontos, hogy milyen gyors a PCI Express kapcsolat, és nem akartuk az NV-t addig hátráltatni, amíg nincs ilyen hardverük, de most hogy van, mehet a buli.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#32221
Abu85
HÁZIGAZDA
JóképűIdegen
#32209
Abu85
HÁZIGAZDA
válasz
 JóképűIdegen
#32209
üzenetére
JóképűIdegen
#32209
üzenetére
Nem minden 3080-nak járt le az NDA-ja. A miénknek még nem.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#32233
üzenetére
Te hazudsz. Azt írtam, hogy maximum 10% lesz a hátránya a PCI Express 3.0-nak, és ehhez az kell, hogy sok puffer legyen a host visible memóriatípusban. A tipikus hátrány, amit átlag hozni fog az 4-8% közötti. Ezt a különbséget hozza is a Horizonben, vagy a Death Strandingben, mivel a Decima motor pont úgy működik, hogy olyan memóriába rakja a puffereket, amelyek a host számára láthatók, tehát azt a memóriatípust tudja olvasni a CPU is. Az NVIDIA-t valamivel hátrányosabban érinti ez a megoldás, mert nem használnak a VRAM-ban host visible és coherent memóriatípust, így minden puffert a Horizon és a Death Stranding kiment a rendszermemóriába, amit a GPU a PCI Express interfészen keresztül fog majd elérni, de a CPU közvetlenül tudja olvasni ezeket. Az AMD implementációja fordított, ugyanis a VRAM-ban van host visible és coherent memóriatípusuk, tehát tudják a VRAM-ba menteni az ide szánt puffereket, viszont a CPU ezeket a PCI Express interfészen keresztül tudja csak elérni.
Itt vannak a gyártói memóriakonfigurációk:
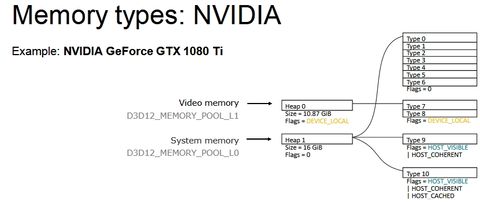

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#32251
Abu85
HÁZIGAZDA
BoneDragon
#32244
Abu85
HÁZIGAZDA
válasz
 BoneDragon
#32244
üzenetére
BoneDragon
#32244
üzenetére
A PCI Express limitje nem állandó. Akkor keletkezik, amikor éppen elérik az adatokat az interfészen keresztül. Az állandó limit nagy bajt jelentene, mert ahogy korábban írtam alig futna az alkalmazás, hiszen állandóan csak memóriamásolás lenne. Ezért mondtam korábban, hogy 10%-nál nagyobb különbséget nem lehet majd látni, mert az már összességében érintené negatívan a számítást. Egyszerűen annyira sok lenne a lassú buszon keresztül az adatelérés, hogy összességében lassítaná az egész feldolgozást, és mindegy, hogy az a busz kétszer gyorsabban működik.
Ilyen a 3DMark erre kialakított tesztje. Nem véletlenül bitang egyszerű, egy csomó másolást csinál, de ezzel csak kevés idő marad számításra.(#32245) Jack@l: Nem a Decima motor a lényeg, hanem az, hogy hova menti a puffereket. A Decima csak amiatt érzékeny erre, mert sok puffert ment host coherent memóriatípusba. Bármelyik motor megteheti ezt, és ugyanúgy PCI Express limit lesz az eredménye.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#32259
Abu85
HÁZIGAZDA
gainwardgs
#32256
Abu85
HÁZIGAZDA
válasz
gainwardgs
#32256
üzenetére
Az NV 24-magos Threadripperrel mért, ha ez fontos. De valószínűleg ennyi azért nem kell, viszont idén lesz 16-magos új csúcs-Ryzen, szóval az esélyesen jó alap.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#32262
üzenetére
A VRAM kapacitása mindegy. Itt a probléma maga a host coherent beállítás. Ezek a pufferek összességében nem nagyok, a Horizonben például ~140 MB-ot tesznek ki 4K-ban. És ez az a játék, ami ebből a szempontból messze a legtöbb adattal dolgozik, a Death Strading már csak 90 MB-tal, más játék még kevesebbel. Viszont ezek a pufferek csak olyan memóriatípusba rakhatók, ami host coherent beállítással működik, tehát nem dobhatók be egy sima eszközlokális flaggel jelölt memóriatípusba, és a VRAM-nak a nagy része ilyen. Maga a gond ilyen szempontból 100-200 GB memóriával nem megoldható, mert nem a kapacitás a gond, hanem a beállítás a memóriatípuson. Kvázi az API-nak a működése kényszeríti ki ezt.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nem csak INT számításban. Van pár egyéb limitáció, amikor a második feldolgozótömb nem fogható be. Az egy igen ritka limit, amikor INT32 feladat van. A legnagyobb limit a függőség, amikor éppen nem fogható be a második feldolgozótömb az nagy eséllyel azért van, mert nincs olyan warp, ami nem függ a másiktól.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 toon87
#32356
üzenetére
toon87
#32356
üzenetére
A függőség az önmagában evidens, mert nem tudsz párhuzamosan futtatni két olyan warpot, aminél az egyik warp az éppen futtatott másik warp eredményét használná, előbb meg kell várni az eredményt, aztán lefuthat.
A játékokban az INT32 nem sűrűn van használva. Nagyjából a teljes feldolgozás 10-15%-a. Ritkán talán több, de a nagy átlag ennyi. Ezért ritka az, hogy azért nem tud majd lefutni egy warp, mert éppen INT32 művelet van. A legtöbbször a függőség szól majd közbe. Főleg manapság, hogy az NVIDIA és az AMD sem csinált már évek óta függőséglimites architektúrát, tehát a shadereket sem úgy optimalizálták, hogy ezeket a szituációkat elkerüljék. Régen 2007-2008 környékén azért tipikusan optimalizáltak erre.A regiszter az maradt 64 kB / compute blokk. Az L1 nőtt 32 kB-tal, és annak a sávszélessége duplázódott meg. Viszont az LDS ugyanúgy 48 kB maradt.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#32585
Abu85
HÁZIGAZDA
gainwardgs
#32582
Abu85
HÁZIGAZDA
válasz
gainwardgs
#32582
üzenetére
Igazából van értelme. A legfőbb gyártói félelem ezeknél a kártyáknál a csatlakozók melegedése. Ez a gyenge pont, mivel a tápegységek 8 tűs konnektorait nem biztos, hogy felkészítették arra az áramerősségre, amit ez a kártya 2 8 tűs mellett kiránt a tápból. Ezzel pedig egy nem csúcsnál is csúcsabb tápnál van esély rá, hogy beleég a konnektor a csatlakozóba. A 3 darab 8 tűs aljzat egy túlbiztosítás az OC-s kártyáknál, mert az esély a megégésre megnő, és hiába nincs jelentősen megnövelve a TDP keret, a probléma ami ellen a 3 csatival védekeznek az a túl magas áramerősség által keletkező hő. Több 12 V-os vezetékkel viszont ez csökkenthető.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#32613
Abu85
HÁZIGAZDA
gainwardgs
#32609
Abu85
HÁZIGAZDA
válasz
gainwardgs
#32609
üzenetére
Olvasd el még egyszer. Itt ez egy kockázati tényező. Az esélye rendkívül kicsi, de szám szerint benne van a pakliban. Azért itt 9 amperről van szó, ami nem kevés, és nem egy táp nincs arra felkészítve, hogy 9 ampert átküldjön a csatlakozókon. Hasonló a helyzet az RX 480-hoz, ami többet fett fel a PCI Express portból a megengedettnél. Ott is gyakorlatilag kizárt volt, hogy a valóságban ebből bármi baj legyen, de papíron megvolt rá az esélye. Itt is gyakorlatilag kizárt, hogy ebből a valóságban baj legyen, de papíron nem zárható ki teljesen. És ezt a papíron létező veszélyt fedi le a három tápcsati. Tehát nem viccből rakják rá a kártyákra.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
nubreed
#32629
üzenetére
Nem csinálnak ilyet. Ami van azt eladják. Egyelőre hiány van a GDDR6X memóriából. Mivel csak ilyen memóriát tudnak használni, így ez elég nagy probléma. Ezért nincs 20 GB-os verzió, mert akkor sokkal kevesebb VGA-t tudnának kiadni, hiszen kétszer annyi memória kellene egy VGA-ra, miközben a Micron nem gyárt többet.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
nubreed
#32637
üzenetére
Akkor drágulhat, ha ez a helyzet hosszabb távon fennáll. De ahhoz látni kell, hogy mekkora szállítmányok érkeznek majd a következő hetekben, tehát lehet kalkulálni, hogy mekkora áremelés kell ahhoz, hogy a termék eladható legyen a következő szállítmányokig.
A 3070-nél memóriából biztos nem lesz hiány. Ott a Samsungon múlik, hogy lesz-e elég.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#32678
Abu85
HÁZIGAZDA
gainwardgs
#32670
Abu85
HÁZIGAZDA
válasz
gainwardgs
#32670
üzenetére
Elfogy a VRAM-ja. 16 GB-ra tervezték a Krízis rimásztert. Ha visszaveszed a textúrákat, akkor elkezd működni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
-
Abu85
HÁZIGAZDA
Nem emiatt. A tesztelőknek mindig válogatott darabokat küldenek, és az Ampere esetében sokkal nagyobb a variancia, mint régen a Turingnál volt. Emiatt válogattak a nagyobb augusztusi batchből.
Valójában GDDR6X-ből nincs elég. Chipből elég mennyiséget gyárt a Samsung, de nem tudnak hozzá memóriát adni.A gyártás komplexitását egyébként jelentősen megnöveli a magas órajel. A korábbinál nagyobb annak az esélye, hogy külön-külön működnek a lapkák, de amikor rárakják a NYÁK-ra, akkor valamiért instabilak. Az így születő instabil példányokat manuálisan kell korrigálni, ami a gyártás időtartamát jelentősen növeli.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A Samsungot elsődlegesen a tömeges szinten eladható memóriatechnológiák érdeklik. Egyébként a Micron sem bénább cég, csak kisebb a gyártókapacitásuk. Ettől függetlenül a Samsung sem tudna jobb GDDR6X memóriákat gyártani, maximum többet, de amíg nem jön meg ezekre a tömeges igény, addig nem fognak lépni. Ha csak az NV rendel GDDR6X-et a jövőben, akkor felesleges pénzt ölni a fejlesztésébe, mert egyrészt kicsi a rendelési tétel, másrészt kialakulna az árverseny, ami az egész GDDR6X projekteket veszteségbe tolná. A Micron azért gyártja, mert egyedül vannak, annyi pénzt kérnek a memóriákért, amennyit akarnak, nincs alternatíva. Ráadásul láthatóan rámentek a biztonságra, vagyis kis gyártási tétellel kezdtek, ha esetleg befürödne a rendszer. Most persze baj van, hogy nem fürdött be, de utólag kevésbé kockázatos kapacitást bővíteni, mint előre kiépíteni, ami esetlegesen nem kellene. Ugye a Micron pontosan tudja, hogy az NV maximum mérgelődni tud, hogy nem rendeltek többet, de máshonnan nem tudnak GDDR6X-et szerezni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Amikor ilyen új technológia van, és nem biztos, hogy szabvány lesz, akkor a kockázatvállaláson van a hangsúly. A Micron annyit gyárt, amennyi a megrendelés, de azt el kell vinni. Viszont ha sok a megrendelés, akkor a Micron a kockázatok egy részét is áthárítja a megrendelőre. Effektíve azt mondják majd, hogy megépítik a gyártósorokat, de akkor a megrendelőnek kötbért kell fizetnie, ha egy meghatározott időn belül nem viszik el a legyártott lapkákat, és még a gyártósorok kiépítésének költségét is állják. Innen kezd ez a dolog izgalmassá válni, mert az a kérdés, hogy a megrendelő mennyire hisz a technológiában, amit megrendelt. Hajlandó-e magát egy igen komoly kötbérbe beleverni, ha mégse jön be. Ilyen szempontból minden döntés a megrendelőé. Ha sokat rendelnek, akkor a Micron megcsinálja, de ha nem kell a piacnak, attól még a pénz elkérik. De benne van, hogy a megrendelő nem akar aránytalanul nagy kockázatot vállalni, mert ugye ki tudja, hátha nem válik be a termék, hátha rákap a GDDR6X-re a Samsung és/vagy a Hynix, akkor meg olcsóbb lesz a memória, miközben az elején lekötöttek egy rakás kapacitást a Micronnál méregdrágán, stb. Mindenki az optimális egyensúlyt keresi, még az NVIDIA is. Aránytalanul nagyot senki sem fog kockáztatni, mert a nagy győzelem mellett a nagy pofára esés is benne van.
A "B" terv kb. annyi, hogy rendelnek még, és akkor a Micron elkezdi építeni a további gyártósorokat. Ezzel nem nagyon tudnak mit csinálni. Esetleg annyit, amit tesznek, hogy 10 GB-os lett a 3080, így nem kell rá 20 memórialapka, hanem csak 10. Az is dupla mennyiségű VGA, ha osztunk-szorzunk.
Elképzelhető még, hogy az NV is stratégiára megy, mert mutatják, hogy kéne még memória, és hátha behúzzák a Samsungot vagy a Hynixot, mert az például az NV-nek elég baj, hogy a GDDR6X-et csak a Micron gyártja, így nincs valódi alkupozíció, annyit kell fizetni érte, amit a Micron kér.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az extra GB-ok esetében a képlet egyszerű. A gyártók csinálhatnak 20 GB-os 3080-at. Akár holnap is. De attól, hogy ilyet csinálnak nem kapnak több GDDR6X-et, tehát a gyártható 3080-ak számát fogják ezzel csökkenteni. Emiatt nem ugrott még rá senki, mert 10 GB-os modellekkel is nagyon keveset tudnak gyártani. De papíron nincs megtiltva, hogy készüljenek a VGA-k.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.






 Már a PS5 képes 2,23 GHz-re, és abban még nem is a hőmérséklethez van kötve az AVFS, ráadásul a PC-s RDNA2 újabb dizájnkönyvtáron jön.
Már a PS5 képes 2,23 GHz-re, és abban még nem is a hőmérséklethez van kötve az AVFS, ráadásul a PC-s RDNA2 újabb dizájnkönyvtáron jön.


![;]](http://cdn.rios.hu/dl/s/v1.gif)


















Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az NVIDIA éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.


Állásajánlatok

Cég: Ozeki Kft
Város: Debrecen

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest