A fúzióig vezető rögös út
Majdnem napra pontosan öt évvel ezelőtt szinte bombaként rázta meg az IT uborkaszezont a hivatalos bejelentés, hogy az AMD felvásárolja az ATI Technologiest. Az akkoriban leginkább Radeon márkajelzésű grafikus processzorairól, valamint Intel és AMD processzorokhoz tervezett lapkakészleteiről ismert kanadai vállalatot végül nem kevesebb mint 5,4 milliárd dollárért kebelezte be az AMD. Az elsőre némileg irracionálisnak hangzó lépés mögött sokkal inkább a hosszútávú túlélés, mintsem egy azonnal milliárdokat hozó bombaüzlet bújt meg valódi okként. A GPU és a chipkészlet üzletág már akkor sem volt aranybánya, ráadásul a felvásárlás előtt az ATI termékek nagy része Intel-alapú számítógépekben landolt, mely piac egy részétől nem sokkal később értelemszerűen búcsúznia kellett az új tulajdonos AMD-nek.

Dave Orton és Hector Ruiz, az ATI és AMD egykori vezetői 2006 júliusában
A hárombetűs processzorgyártó belátta, hogy a piacon maradáshoz az Intelhez hasonlóan elengedhetetlen lesz egy teljesen saját és komplett platformmegoldás bevetése. Ehhez a processzor mellett az akár grafikus maggal ellátott lapkakészletnek, valamint az esetleges diszkrét grafikus vezérlőnek is házon belül, saját és egységes márkanév alatt kell készülnie. Ezt megelőzően a processzorokhoz szükséges infrastruktúrát különböző partnerek biztosították (pl.: NVIDIA, VIA, ATI). A vállalat az akvizícióval számtalan értékes szabadalomra és versenyképes fejlesztésre tett szert, melyek kifejlesztése nem csak nagy költségekkel járt volna, de hosszú éveket vett volna igénybe. Igaz, a végül sikerrel lezárult üzletbe így is majdnem beleroppant a cég, hiszen a milliárdos kölcsönök törlesztése mellett a konkurencia egyre növekvő nyomása, valamint a nem sokkal később beütött gazdasági válság sem volt éppen pozitív hatással a pénzügyi mutatókra.
![]()
Mindezzel párhuzamosan a teljesen saját platform mellett egy másik, a hosszú távú jövőre nézve szintén rendkívül fontos projekthez is szüksége volt az ATI-ra az akkori processzorgyártónak, ez pedig nem más, mint a csak Fusion kódnéven megismert termékvonal, mely gyakorlatilag a CPU- és GPU-funkciók egyetlen szilíciumlapkán való egyesítését rejti a név mögött.
Ismétel a történelem
A Neumann János-díjas amerikai Ivan Edward Sutherland egyik, Wheel of Reincarnation elnevezésű, 1968-ban íródott szabályának lényegi jelentése szerint olcsóbb kiváltani egy speciális célú hardvert (pl.: GPU) a megfelelő szoftver és egy általános célra készített hardver (pl.: CPU) kombinációjával. Viszont olykor a piacnak nagyobb szüksége van a magasabb számítási teljesítményre, mint az olcsóbb hardverekre, így idővel ennek érdekében a funkció kikerül az általános célra készített hardverből, és egy külső, speciális célú egység formájában születik újjá. Később, ha már a korábbi, még speciális célú hardver feladatai már túl általánossá válnak, akkor a költségek csökkentése érdekében visszakerül az általános célra készített hardverbe, mellyel gyakorlatilag kialakul egy ördögi kör.
Az előbbi szabályt már számtalanszor bizonyította az idő. Elég, ha visszamegyünk nagyjából 22 évvel ezelőttre, amikor az Intel bemutatta i486DX elnevezésű processzorát. Ennek a központi egységnek egyik nagy újítása az volt, hogy elsőként tartalmazta a CPU-val egy közös szilíciumlapkán integrálva a matematikai koprocesszort, azaz az FPU-t (Floating-Point Unit, magyar fordításban lebegőpontos egység). Az egység a lebegőpontos matematikai műveletek jelentős meggyorsítására lett hivatott. Ezt megelőzően az FPU nem volt szerves része a CPU-nak, csak külön, extraként volt megvásárolható, és az alaplapokon található erre szánt foglalatba lehetett illeszteni. A szóban forgó processzornak volt még egy másik nagyobb újítása is. Az i486DX ugyanis 8 kB belső L1 gyorsítótárral is gazdagodott, de ezzel párhuzamosan megmaradt az alaplapon található cache is, amely így egy szintet feljebb (illetve pontosabban inkább lejjebb) csúszott, amellyel L2 cache vált belőle. Az FPU mellett az L1 cache betelepülése is maradandóvá vált, mivel az FPU-hoz hasonlóan az ezután megjelent, magasabb kategóriás, újabb processzorok már hasonló módon tartalmazták ezen egységeket. Összességében elmondható, hogy az i486 magas szintű integrációja miatt egy mérföldkőnek számított a processzorok történelmében.

Az i486DX
Az integráció nem állt meg. Az Intel 1998 augusztusában megjelent, Mendocino kódnevű lapkát felvonultató Celeron-A processzorának szilíciumába ugyanis az L1 cache mellé már az L2 cache is beköltözött. Ez természetesen nem csak a számítási teljesítményre volt kedvező hatással (gyorsabb elérés), hanem később a gyártási költségekre is.

Mendocino lapka – jobb szélen az L2 cache
A következő nagy lépést már az AMD tette meg az Athlon 64 megjelenésével. A cég a K8 tervezésénél úgy döntött, hogy az x86-os processzorgyártók között elsőként a gyakorlatban is megvalósítja a CPU-ba integrált memóriavezérlőt (IMC). Így az addigi alaplapok északi hídjában található egység átkerült a CPU-t tartalmazó szilíciumlapkába, mely a K8 esetében a mindenkori magórajelen üzemelt. Ezzel egy huszárvágással kiiktatták az FSB-t, aminek következményeképpen a memória-hozzáférés sebessége jelentősen javult, és nőtt a valós, mérhetően kihasználható sávszélesség is. Az FSB helyét a HyperTransport vette át.

A K8 architektúra bevezetésével tehát az AMD végleg leszámolt a külső memóriavezérlőkkel; a fentebb említett lépés óta kizárólag IMC-t tartalmazó lapkákkal szerelt CPU-kat mutatott be a gyártó. Az Intel első IMC-s CPU-ja a Core i7 (Bloomfield) volt, mely 2008 novemberében debütált. A témában az imént említett Bloomfield közvetlen rokona, a Lynnfield mutatta be a következő mozzanatot, mivel a lapka egy 16 sávos PCI Express vezérlővel gyarapodott, melyet az idei év elején megjelent Sandy Bridge természetesen tovább is vitt.
Hirdetés
Az évek, évtizedek folyamán egyre több, eredetileg külső egység lelt új otthonra a központi végrehajtóegység lapkáján belül, mellyel szépen lassan, szinte észrevétlenül átfogalmazódott az egység mögött rejlő szilíciumlapka jelentése és feladata. Az, hogy az idők során pontosan mikor milyen részegységeket foglalt magában a processzor vagy éppen egyetlen mag, az mindig az éppen aktuális, gyártók által diktált trendtől függött és függ még ma is. A folyamat természetesen nem állt és nem áll meg ennél a pontnál...
APU kezdődik!
Na de mi is az az APU? Az AMD úgy döntött, hogy a Fusion égisze alatt megjelenő processzoroknak egy új kategóriát hoz létre, melyet az eddig jól megszokott CPU (Central Processing Unit, azaz központi végrehajtóegység) helyett APU-nak hív. Az APU az Accelerated Processing Unit rövidítése, mely nyers fordítás szerint annyit jelent, hogy gyorsított végrehajtóegység. Az alapötlet olyan processzorok megalkotása volt, amelyek heterogén módon programozhatóak, biztosítva egy belépőt a rendszerszintű integrációba, avagy más néven megkezdődhet a heterogén éra térhódítása.
A többség egyfajta divathullámnak értékeli a grafikus mag processzorhoz való társítását, de ennél sokkal többről van szó, ugyanis a GPU-ban szunnyadó számítási kapacitást általános számításokra is fel lehet használni, ráadásul bizonyos esetekben lényegesen kedvezőbb teljesítmény/fogyasztás mutatót képes ezzel felmutatni a rendszer.

[+]
Az előző évtized első felében még kemény órajelháború folyt. A processzorok egyetlen x86-os magot tartalmaztak, és a mérnökök ebből próbálták kipréselni a lehető legnagyobb számítási teljesítményt. A tervezők idővel belátták, hogy ez az irány sokáig nem járható tovább, így inkább az adott processzoron vagy szilíciumlapkán belüli magok számának növelése felé indultak el. Ez egy meglehetősen tranzisztorigényes megoldás, ráadásul probléma, hogy a többmagos processzorok programozása sem egyszerű, mely helyzet a magok számának növelésével csak még tovább romlik. Mindez oda vezet, hogy az extra magok beépítése a teljesítményt alig növeli tovább a megfelelő szoftverek hiányában, vagyis a többmagos elgondolás skálázhatósága jó néhány esetben nem optimális.

[+]
A heterogén rendszerek ezekre a problémákra próbálnak gyógyírt nyújtani. Természetesen a helyzet itt sem olyan egyszerű, hiszen hiába a sok esetben mérföldekkel jobb teljesítmény/fogyasztás mutató, ha mindezt nem lehet kihasználni, ugyanis mindezen erőforrások kiaknázásához szükséges egy újfajta programozási modell, egy megfelelő felület. Ilyen például az OpenCL, mely már jó ideje elérhető, így már "csak" az ezen felületet kihasználni képes alkalmazások tömkelegének érkezésére kell várnunk.
A fúzióig vezető rögös út folytatása
Az AMD az ATI sikeres felvásárlása után néhány hónappal már prezentálta is hosszútávú terveit, melyben fel is tűnt az első CPU-t és GPU-t egyesítő fejlesztés néhány morzsája.

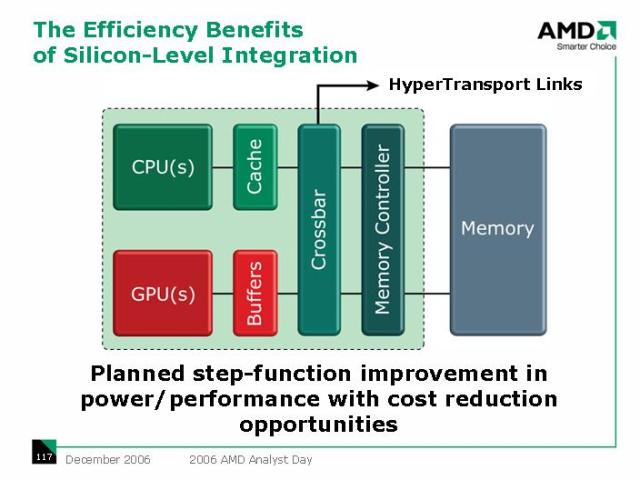

Akkor, 2006 decemberében a cég nagyjából 2009 környékére datálta az első, még meglehetősen nagy homályba burkolózó APU megjelenését. Ekkor még egy 65 nanométeres variánsról szólt a fáma.


A következő információkat 2007 derekán, majd végén publikálta a vállalat, ekkor egy Falcon és egy Swift kódnevű termékről beszéltek. A tervek szerint előbbi Bulldozer, míg utóbbi Stars (K10) CPU-magokat tartalmazott volna, és 45 nanométeres SOI gyártástechnológiával gurult volna le a gyártósorokról. A Swiftre 2009 második negyedévével egy körülbelüli időintervallumot is megjelölt a cég, de ma már tudjuk, hogy pontosan ilyen formában végül egyik termék sem jelent meg. A napvilágot látott információk szerint a Swift több próbálkozás után sem akart összeállni. Ennek állítólag a gyártástechnológia volt az oka, ugyanis az AMD az első, 130 nanométeres Athlon 64 óta úgynevezett SOI (Silicon-On-Insulator – szilícium a szigetelőn) technológiát alkalmaz processzorainak gyártásánál, ezzel ellentétben a GPU-k készítésénél azelőtt sosem alkalmazták még ezt a módszert. Ráadásul a grafikus lapkák gyártását korábban a területen jóval nagyobb tapasztalattal rendelkező TSMC végezte, akik egy egyszerűbb, úgynevezett bulk CMOS eljárással termelték és termelik őket mind a mai napig.


A 2008. évi Analyst Day nevű rendezvényen hivatalosan is megerősítésre talált, hogy a Swift helyét a Llano (ez egy Texas állambeli város neve, ejtsd: lánó) kódnevű fejlesztés vette át, mely így 32 nanométeren fog készülni. Ez hasonló tranzisztorszám mellett a 45 nanométerhez képest kisebb méretű lapkát és egyben fogyasztást is sejtetett, amely sok szempontból ideálisnak tűnt egy ilyen jellegű, első generációs új termék bevezetéséhez. Egyébiránt ebben az időben szervezte ki a gyártást az AMD, mely azóta GlobalFoundries néven egy teljesen különálló vállalat formájában működik tovább.


Egy újabb évet követően, a megjelenés dátumának kitűzött 2011-hez közeledve egyre több részlet látott napvilágot a Llanóról. Nyilvánvalóvá vált, hogy a korábbi Swifthez hasonlóan ez az APU is Stars (K10) CPU-magokat fog kapni. A DirectX 11 kompatibilis GPU részről viszont egyelőre csak találgatni lehetett. Egyesek 480, míg mások 400 shader egységre tippeltek, de azt senki sem tudta, hogy ezek pontosan melyik, éppen aktuális (vagy majdan megjelenő) Radeon architektúrára fognak épülni. Ezen túlmenően a Fusion fejlesztési vonalban rejlő heterogén számítási lehetőségekről is ejtett néhány szót az AMD.


2010 februárjában az AMD az ISSCC 2010 konferencián (International Solid State Circuits Conference) tartott egy nagyobb előadást, melyben a Llano kapta a főszerepet. Szó esett az x86-os Stars magokról, valamint részletezték az új energiagazdálkodási funkciókat is. Ekkor elsősorban az órajelkapuzásra és a tápkapuzásra tértek ki. Ezt követően a várható megjelenéshez még tovább közeledve jó néhány dátum (negyedév és hónap) látott napvilágot. Először 2011 januárja, később pedig tavaszi, majd a nyári hónapok kerültek terítékre, ám ezt követően ősszel ismét érkeztek nem túl pozitív pletykák a gyártástechnológiával kapcsolatban, aminek következtében további csúszást várt mindenki. Az AMD meglepetésre ezt cáfolta, és elmondták, hogy a nyár elejére tervezett időpont tartható. Később néhány kiszivárgott hivatalos dia alapján már 2011 július és augusztus volt a céldátum. Az egésznek végül az lett a vége, hogy a korábban csak a Llano után várt Brazos platform rajtolt el előbb, így gyakorlatilag a Zacate és az Ontario lett az AMD első, kereskedelmi forgalomba is került APU-ja. Érdemes még megemlíteni, hogy ezekkel szinte napra pontosan egy időben indult útjára az Intel által fejlesztett Sandy Bridge is, amely szintén egy szilíciumlapkába integrálva tartalmazza a CPU-magokat és a GPU-t. Így gyakorlatilag fej-fej mellett tette meg a két gyártó az előző oldalon taglalt lépések közül a következő nagyot, annyi különbséggel, hogy a Sandy Bridge GPU-jának számítási teljesítményét nem lehet általános számításokra felhasználni, azaz csak a képi megjelenítés gyorsítható általa.
A leleplezett Llano közelebbről
Végül idén júniusban, néhány évnyi izzadságos fejlesztőmunka után beérett a régóta dédelgetett újítás, azaz útjára indultak az A szériás APU-k. Ahogy az előző oldalon említésre is került, végül házon belül a netbookba, ultravékony notebookba és nettopokba szánt, alacsony fogyasztású Zacate és az Ontario (ugyanaz a lapka) beelőzte a Llanót, de ennek ellenére a várhatóan jóval nagyobb számítási teljesítmény miatt a közönség részéről mégis nagyobb érdeklődés övezte utóbbit. Sokan (nem véletlenül) csak ezzel a fejlesztéssel azonosították az egész Fusion hadjáratot.

[+]
Az AMD állítása szerint a Llano az azt megelőző platformokban található, összesen 374 mm² szilíciumlapkányi területet 228 mm²-en képes kiváltani. Ebbe a 374 mm²-be a korábbi alaplapi északi híd, egy négymagos CPU és egy alsó-középkategóriás diszkrét grafikus kártya tartozik bele. Természetesen azt vegyük figyelembe, hogy a Llano egy alacsonyabb, 32 nanométeres csíkszélességen készül, azaz ennek köszönhetőn kisebb területen képes ugyanazt a tranzisztorszámot felvonultatni. Apropó, gyártástechnológia: a Llano az első 32 nanométeren tömeggyártásban érkező AMD processzor. A lapkák a GlobalFoundries drezdai üzemében készülnek, egy meglehetősen öszvér technológia keretein belül. Ez alkalmazza az AMD által már az első Athlon 64-ek és Opteronok (2003) óta gyakorlatilag folyamatosan alkalmazott SOI (Silicon-On-Insulator, szilícium a szigetelőn) technológiát, melyet – az Intel által még 45 nm-en bevezetett megoldásához hasonló, de itt gate-first megvalósításon alapuló – HKMG (High-K Metal Gate, magas k együtthatós fémkapu tranzisztor) technológia egészít ki.

Ezen túlmenően a 45 nm-es Deneb és Shanghai lapkák gyártásánál először alkalmazott immerziós litográfiát is továbbvitték a 11 fémrétegből felépülő lapka gyártásához. Mindezen technológiák ötvözése a fejlesztők szerint számottevően növeli a tranzisztorsűrűséget és csökkenti a szivárgási áramot. Jelenleg az Intel rendelkezik még 32 nanométeres processzorral. Összehasonlítás gyanánt, míg a négymagos Sandy Bridge 216 mm2-en 995 millió tranzisztort tartalmaz, addig a négymagos Llano 228 mm2-en 1,45 milliárdot. Természetesen ilyen egyszerűen nem lehet összevetni a két lapkát, hisz eltérő arányban tartalmaznak különféle részegységeket, melyek tranzisztorsűrűsége jelentősen eltérő lehet.

[+]
Míg a Sandy Bridge az x86-os CPU-magokra helyezi a hangsúlyt, addig a Llano inkább a GPU-ra gyúr. Az egyes magok méretének összehasonlítása is sokat sejtető.

forrás: www.chip-architect.com
Egyetlen Sandy Bridge mag és a szervesen hozzá kapcsolódó L3 cache szelet majdnem akkora, mint a két, 1 MB-os másodlagos gyorsítótárral operáló, Husky kódnévre hallgató x86-os Llano mag. Itt nagyon eltérő architektúrákról van szó, de azért azt tudni lehet, hogy a méret és a számítási teljesítmény általában (jó esetben) bizonyos mértékben arányos egymással.

[+]
A Llano lapka egyelőre egyféle fizikai kialakításban létezik. Ez összesen négy darab, Stars családból származó CPU magot tartalmaz és egy meglehetősen méretes GPU-t. Mindezek mellett egy összesen 24 sávból álló PCI Express vezérlő is integrálásra került, mely mellől nem maradhatott el az integrált, maximum DDR3-1866 szabványú memóriát támogató IMC sem.

A Sumo
A GPU rész gyakorlatilag a HD 5600 és 5500 sorozatokból megismert VLIW5 architektúrás Redwood kissé átdolgozott, majd Sumo névre átkeresztelt mása. Az Evergreen alapokra építkező szekció öt darab shader tömbbel rendelkezik, ezzel összesen 400 shader processzort tartalmaz. Ezek 80 utas tömbökbe rendeződnek, ami összesen 20 darab, Gather4-kompatibilis textúrázó csatornát tesz lehetővé két darab ROP blokk mellett, amelyek együttesen nyolc blending egységet eredményeznek. A lassabb verziókat a diszkrét GPU-k esetében már jól bevett gyakorlat szerint a tömbök letiltásával hozzák létre.
| Típus | Magórajel | Radeon magok száma | Dual Graphics opció | Dual Graphics társ-GPU | Grafikus mag kódneve |
| 6550D | 600 MHz | 400 (5 x 80) | van | Turks | BeaverCreek |
|---|---|---|---|---|---|
| 6530D | 443 MHz | 320 (4 x 80) | van | Turks | BeaverCreek |
| 6410D | 600 MHz | 160 (2 x 80) | van | Turks | WinterPark |
| 6370D | 443 MHz | 160 (2 x 80) | nincs | - | WinterPark |
A módosítások között szerepel az UVD motor frissítése, mellyel a harmadik generációs UVD 3 váltotta az eggyel korábbi verziót. Ez utóbbi motor kezeli a H.264/AVC, az MPEG-2/4, a VC-1, a DivX és az XviD videók gyorsítását egészen Ultra HD felbontásig. A GPU támogatja a DirectX 11-es, az OpenGL 4.1-es, az OpenCL 1.1-es, az OpenGL ES 2.0-s, valamint a DirectCompute 5.0-s API-t, továbbá képes a Direct2D és a DirectWrite felhasználásával a weboldalak megjelenítését gyorsítani. Ezen felül támogatja a WebGL-t is, ami a böngészőablakban futó háromdimenziós animáció gyorsítását teszi lehetővé, illetve a flash animációk gyorsítása sem jelent akadályt.
Azzal, hogy ez a GPU beépítésre került a Llanóba, gyakorlatilag megszületett az első 32 nanométeres Radeon is, melyhez hasonló csíkszélességű diszkrét variáns a TSMC stratégiájának átszervezése miatt már biztosan nem lesz. Még említésre érdemes a Dual Graphics névre hallgató technológia támogatása, mely tulajdonképpen a Hybrid CrossFire utódjának tekinthető. Ennek lényege, hogy az APU-ban található grafikus processzor számítási teljesítménye egy extra GPU-t tartalmazó diszkrét kártyával még tovább növelhető. Jelen állás szerint a Radeon HD 6450, 6570 és 6670 társítható az A szériás Fusion APU-k mellé.

Egy elmaradhatatlan változás érintette a memóriavezérlést is, mely a dedikált 128 bites interfész helyett immáron az APU egyetlen 128 bites memóriavezérlőjére csatlakozik rá egy saját, GMC nevű egység segítségével. Ennek értelmében a GPU osztozik a CPU-magokkal a rendelkezésre álló, DDR3-1866 szabványú memória esetén 29,8 GB/secundumos maximális sávszélességen. Összehasonlításképpen egy Redwood-alapú, GDDR5 szabványú, 4 GHz-es effektív frekvencián ketyegő memóriával szerelt HD 5670 ennek több mint duplájával, 64 GB/s sávszélességgel gazdálkodhat önállóan. A mérnökök természetesen ezzel már a tervezés első fázisa óta tisztában voltak, és ennek okán néhány további speciális módosítást is eszközöltek. A GPU saját dedikált kapcsolatot kapott az integrált memóriavezérlőhöz (Garlic bus), így bár a GPU saját memóriaként a rendszermemória egy szeletét használja, amihez a már említett GMC-n keresztül fér hozzá, logikailag ezt a szeletet autonóm módon kezeli (akárcsak korábban a diszkrét GPU-k melletti memóriát vagy a sideport RAM-ot). Erre azért van szükség, mert míg a CPU által kezelt memória-hozzáférések szigorú előírások szerint (sorrendiség = koherencia) történnek, a GPU a saját memóriaolvasásait és írásait meglehetősen szabadon átrendezheti, ezzel növelve hatékonyságát.
Kényesebb kérdés a CPU és a GPU kommunikációja: ennek meggyorsítására létrehoztak köztük egy közvetlen buszt is (Onion bus). Ez már alapvetően előrelépés, hiszen a CPU által kezelt memória, valamint a diszkrét vagy a chipsetbe integrált GPU saját memóriája között idáig ott volt egy PCI Express kapcsolat, illetve HyperTransport-link, amin keresztül folyhatott a kommunikáció. Ezentúl sokkal egyszerűbben hozzá tudnak férni egymás memóriájához. Most vessünk egy pillantást ennek módjára!

A CPU közvetlenül az Onion buszon keresztül tudja küldeni a GPU-nak szánt adatait, amely aztán kiírja azt a Garlic buszon keresztül saját memóriájába; teheti mindezt kb. 8 GB/s sebességgel, míg a PCI Expressen keresztül ez nagyjából 6 GB/s-ben maximalizálódott. A CPU olvashatja is a GPU memóriáját, ez viszont sokkal lassabb, lévén az olvasások előtt jeleznie kell a GPU felé, hogy az fejezze be a még függőben lévő/átrendezett memóriaírásait, csak ezután olvasható a GPU-memória tartalma biztonságosan. A GPU saját memóriáján kívül (a driver által biztosított virtuálismemória-kezelés által) hozzáférhet a rendszermemória többi részéhez is közvetlenül, viszont ilyenkor figyelembe kell vennie, hogy a kért memóriatartalom akár valamely mag L1/L2 cache-ében is lehet, ezért minden ilyen kérést továbbítani kell először a magokhoz is: erre szintén az Onion buszt használja. Ha valamelyik cache-ben van a naprakész adat, akkor közvetlenül onnan kapja meg, nem kell a rendszermemóriához fordulnia.
Mindez azt eredményezi, hogy CPU által kezelt rendszermemória és a GPU saját memóriája közötti adatmásolások/adatduplázások nagy része feleslegessé válik (zero copy), hiszen az egyik fél által feldolgozott kész adatokat a másik közvetlenül felhasználhatja további számításaihoz, felszabadítva ezzel a memóriavezérlő által biztosítottt 29,8 GB/s maximális memória-sávszélesség egy részét "hasznosabb" célokra.
A leleplezett Llano még közelebbről
A Llano első számú célpontja a mobil piac. Ennek megfelelően is tervezték az egész lapkát, azaz különösen nagy hangsúlyt fektettek a fogyasztásra. Gondoljunk csak bele, hogy a notebookoknál minden egyes watt kemény perceket jelent akkumulátoros üzemidőben! Ennek érdekében számos újítás került bevezetésre a gyártástechnológia és az energiamenedzsment terén. Az órajelkapuzást követően implementálásra került az Intel Nehalemben már feltűnt tápkapuzás is. A SOI gyártástechnológiának köszönhetően rendelkezésre álló, tízszer hatékonyabb NFET tápkapuzó tranzisztorok használatával a kapcsolóüzemű működésből eredő veszteség mellett a szivárgási áram is a zéró közelébe redukálható az éppen inaktív egységeknél. Így egy adott lekapcsolt rész teljes fogyasztása akár a nulla szintjének közeléig is lecsökkenthető.

[+]
Mindemellett integrálásra került egy digitális energiagazdálkodási modul, mely folyamatosan monitorozza a főbb részegységek hőmérsékletét és terhelését. Ez még a K10 idejében bevezetésre került rendszer továbbfejlesztése. Amelyik egységre éppen nincs szükség és a tervezésből adódóan alkalmas erre, azt a másodperc tört része alatt mély álomba (C6 deep sleep) ringatja a rendszer. Ez utóbbi a 45 nanométeres Deneb/Shanghai lapkáknál megismert Smart Fetch továbbgondolása, amely az inaktívvá vált magok esetében azok L1 és L2 tárainak tartalmát képes volt kiírni az L3 cache-be, majd lekapcsolni azokat. Mivel a Llano nem tartalmaz L3 cache-t, ezért a rendszer lefoglal 16 MB rendszermemóriát az L1 és L2 esetleges ideiglenes ürítéséhez. Az adott mag ily módon való lekapcsolása után a tápkapuzásnak köszönhetően már csak elenyésző áramfelvétellel kell számolni.

[+]
Természetesen nem csak a CPU-magok, valamint azok másodszintű gyorsítótára, de a GPU, a hozzá tartozó saját GMC (Graphics Memory Control) egység, valamint akár külön az UVD motor is teljesen lekapcsolható tápkapuzással, ha éppen ezekre nincs szükség.
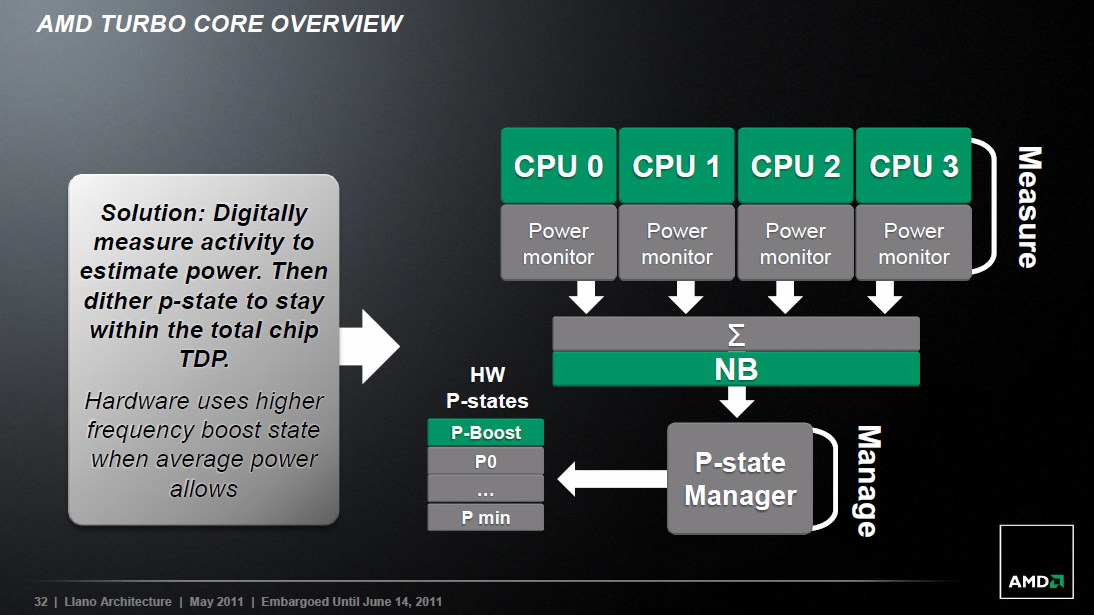
[+]
A Phenom II X6 Thuban lapkájánál bemutatkozó Turbo Core is továbbfejlesztésre került, mellyel a technológia megkapta a 2.0-s verziószámot. A Llano itt nem az pillanatnyi áramfelvétellel és hőmérséklettel kalkulál, hanem az aktuális terheléssel. Minden egyes lehetséges magi aktivitáshoz (melyek száma 100 körül van) hozzárendeltek egy fogyasztási mutatót, ami alapján az energiagazdálkodási modul képes pontosan kiszámolni az éppen aktuális fogyasztást, hogy az minden esetben az éppen szóban forgó modell TDP keretének figyelembe vétele mellett optimálisan működjön. A rendszer ennek megfelelően szabályozza az órajelet és feszültséget is.


Amikor a GPU csak minimális terhelésnek van kitéve (például épp a Windows asztalon vagyunk), akkor a grafikus rész számára fixen fenntartott keretet a CPU-magok kaphatják meg. Ennek köszönhetően órajelüket (akár mind a négy magét egy időben) fel lehet emelni akár a legmagasabb szintre is. Természetesen bizonyos folyamatok jobban, míg mások kevésbé veszik igénybe a magokat és az ezekhez szükséges tápellátást. Egy másik eset, hogy a GPU éppen hevesen számol valamit, de mégsem tölti ki teljesen a hozzárendelt keretet. Ekkor a még fennmaradó fogyasztási keretet megkaphatják a magok, és ha például a négy közül az adott alkalmazás csak kettőt használ, akkor azok órajelét még mindig fel lehet emelni, miközben a másik kettőt addig le lehet kapcsolni. Erre jó példa lehet mondjuk egy játék.

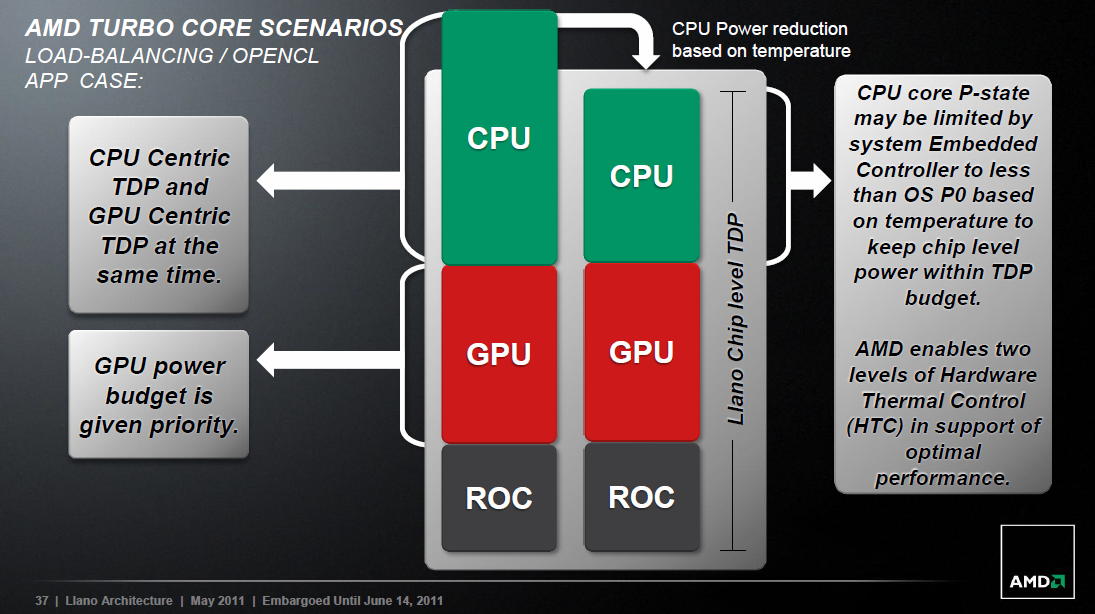
A harmadik eset, hogy a GPU csak minimális terhelésnek van kitéve (például valamilyen videóanyag lejátszását gyorsítja), de eközben az összes mag teljes erőbedobással számol valamit. Ebben az esetben a CPU-magok kapják meg a TDP keret nagy részét, mellyel ismét működésbe léphet a Turbo Core. Az utolsó esetben az összes CPU-mag és a GPU is teljesen aktív. Ekkor a GPU kapja a nagyobb prioritást, és a CPU magoknak a maradék keretből kell gazdálkodniuk. Ebben a szituációban már az APU hőmérsékletet is figyelembe veszi a rendszer, hogy semmilyen esetben se lépje túl a TDP keretet az aktuális fogyasztás. Ennek érdekében ideiglenesen akár lejjebb is veheti a magok órajelét és feszültségét a vezérlő. Ilyen eset lehet például egy nagy terhelést generáló OpenCL-es alkalmazás futtatása. Fontos megjegyezni, hogy a Turbo Core 2.0 csak a mobil, és az alacsonyabb, 100 wattnál kisebb TDP-vel rendelkező asztali négymagos Llanók esetében aktív. A 100 wattos APU-k magórajele a tágabb keretnek köszönhetően bármilyen nagy mértékű CPU és GPU terhelés mellett is a maximumon jár. Ezen túlmenően a GPU órajelére egyelőre semelyik forgalomba került modell esetében sincs hatással a turbó, azaz ennek üzemi frekvenciája egyik esetben sem emelkedik a jelenlegi modelleknél.
| Típus | Órajel/Turbo Core órajel | L2 cache | Radeon HD típusa | Fogyasztás (TDP) | Hivatalosan támogatott DDR3 órajel |
|---|---|---|---|---|---|
| A8-3850 (4 mag) | 2,9 / - | 4 x 1 MB | 6550D | 100 W | 1866 MHz |
| A8-3800 (4 mag) | 2,4 / 2,7 GHz | 4 x 1 MB | 6550D | 65 W | 1866 MHz |
| A6-3650 (4 mag) | 2,6 / - | 4 x 1 MB | 6530D | 100 W | 1866 MHz |
| A6-3600 (4 mag) | 2,1 / 2,4 GHz | 4 x 1 MB | 6530D | 65 W | 1866 MHz |
| A6-3500 (3 mag) | 2,1 / 2,4 GHz | 3 x 1 MB | 6530D | 65 W | 1866 MHz |
| A4-3400 (2 mag) | 2,7 / - | 2 x 512 kB | 6410D | 65 W | 1600 MHz |
| E2-3200 (2 mag) | 2,4 / - | 2 x 512 kB | 6370D | 65 W | 1600 MHz |
A K10-nél bevezetett dual power plane (kettős feszültségszabályzás) itt is megmaradt. A CPU-magok egy teljesen különálló vonalról üzemelnek, melynek éppen aktuális feszültsége eltérhet a másik vonalon helyet foglaló GPU, UVD, GMC, IMC/NB és PCIe vezérlőegységekétől.

[+]
A PCI Express részről még nem sok szó esett, bár itt túl nagy izgalmakra nem nagyon lehet számítani. Az összesen 24 sávból négy darab képezi az úgynevezett UMI (Universal Media Interface) szekciót, amely ebben az esetben a korábban alkalmazott HyperTransport szerepét vette át. Feladata az alaplapi egyetlen vezérlőhíd, vagy más néven FCH (Fusion Controller Hub, erről később) APU-val való összekapcsolása. A négy PCIe 2.0 szabványú sávnak köszönhetően itt 2.0 GB/s a kapcsolat sávszélessége. Egy másik csokor összesen 16 sávot tartalmaz, és ez elsősorban az esetleges diszkrét grafikus kártya (vagy kártyák) összeköttetéséhez van fenntartva. Ezeket két külön slotra felosztva x8-x8 konfigurációban akár CrossFire rendszer is kiépíthető. A maradék négy sáv felhasználása már teljesen a gyártókra van bízva. Ezekre ültethetnek különféle hálózati, SATA vagy akár USB vezérlőket is, illetve még alaplapi PCIe aljzatok formájában a vásárlókra is bízhatják opcionális kihasználásukat.
Az FCH és a rá épülő ASUS F1A75-V PRO
Az asztali Lynx platform szakít a korábbi AMx foglalatos rendszerek I/O architektúrájával. Ez elsősorban az előző oldalon taglalt, processzorba beköltözött PCI Express vezérlőnek köszönhető, mellyel a korábbi északi híd gyakorlatilag immáron feleslegessé vált. Ennek okán az Intel LGA1156-os és LGA1155-ös platformjához hasonlóan már csak egyetlen tagból áll a chipset, mely a pár sorral korábban említett FCH nevet kapta. Az FM1 platform két ilyen chipsettel indított, melyek az A55 (Hudson D2) és A75 (Hudson D3) modellszámozást kapták.

Az A75 SATA vezérlője 6 Gbps-os teljesítményre képes és hat darab portot kínál. A RAID szolgáltatás támogatása is megoldott 0, 1 és 10 módban. A chip négy darab PCI Express 2.0-s sávot is tartalmaz, továbbá három PCI interfész is elérhető. Támogatott az úgynevezett FIS-based switching is. Ez a funkció egy SATA portra kötött elosztó mellett hasznos. Ilyenkor több adattároló működik egy interfészről, de a hagyományos Command-based Switching alkalmazásával egyszerre csak egy meghajtó foglalhatja le a sávszélességet. A FIS-based (Frame Information Structure) megoldással az összes meghajtó működtethető párhuzamosan, és a vezérlő gondoskodik a terhelés megfelelő elosztásáról. A költségek csökkentésének érdekében az FCH az órajel-generátort is magában hordozza.

Az A75 lapka
Az USB vezérlő 16 natív portot támogat, melyek közül négy lehet 3.0-s, tíz 2.0-s és mindössze két interfész érhető el az 1.1-es felülethez. Extraként a rendszer támogatja az mSATA szabványú SSD-ket, az infravörös portot, és egy beépített vezérlő kezeli az SD-kártyákat, amelyek maximum 2 TB-os kapacitással rendelkezhetnek. Az egyszerűbb (és olcsóbb) A55 mindettől annyiban tér el, hogy annak SATA portjai csak SATA 3 Gbps szabványúak, valamint nem képesek a FIS-based switchingre sem, illetve a négy darab USB 3.0 port sem támogatott. A legtöbb gyártó szerencsére az A75 mellett tette le a voksát. Pontosan így tett az ASUS is, amikor megtervezte az F1A75-V PRO alaplapot.

[+]
A dobozban most sem tárulkozik elénk túl sok minden az alaplapon kívül. A szokásos kézikönyv, DVD és hátlap mellett két SATA kábel és egy Q-connector nevű kis kiegészítő lapul, mely a ház bizonyos kábeleinek könnyebb csatlakoztatását segíti elő . A nyolc (6+2) Digi+ vezérlésű fázist itt egy szép kék heatpipe-ba csatlakozó borda hűti, melynek másik vége az FCH bordájánál köt ki. Az új, 905 érintkezővel szerelt FM1 foglalatra bármilyen korábbi Socket AM2/AM2+ vagy AM3 kompatibilis hűtő felszerelhető, sőt egyes, a műanyag keretbe kapaszkodó Socket 754-re vagy 939-re megfelelő hűtők is alkalmazhatóak.

A PWM
A heatpipe alapvetően a magasabb hőmérsékletű rész felől szállítja a hőt az alacsonyabb hőmérsékletű pont felé, így a komponensek aktuális hőmérsékletétől függően segít a hűtésben a két végpont. Az FCH natív SATA 6 Gbps portjaiból mind a hat az alaplapon került kivezetésre, sőt ezen felül még egy plusz portot is kapunk, melyet PCIe sávra ültetett ASMedia vezérlő kezel. A natív USB 3.0 portok közül kettőhöz van csatlakozó, melyeket egy kompatibilis kivezetéssel használhatunk ki. Ezen felül még négy pár USB 2.0 portot is kivezethetünk.

[+]
Az F1A75-V PRO-n két teljes hosszúságú PCI Express slot található, melyekhez fixen ki vannak vezetve a sávok. A felső kék színű tizenhat darabot kapott, míg az alsó fekete négyet. Ezek mellett két x1-es slot is található, a maradék helyet pedig három sima PCI tölti ki. A maximum DDR3-1866 szabványú memóriáknak négy foglalat áll rendelkezésre, melyek megtöltését a fekete színűeknél kell kezdeni.

A hátlapon a kombó PS2 csatlakozó alatt két ASMedia vezérlős USB 3.0 port nyitja a sort. Ezek mellett jobbról egy optikai hangkivezetés kapott helyet, mely alatt egy 1.4-es szabványú HDMI és DisplayPort található. Közvetlenül ezek után a sort egy D-Sub és egy DVI-D folytatja. A megjelenítők csatlakozóival tehát nem spórolt az ASUS, ami mindenképpen dicséretes. A DisplayPort maximum 2560x1600-as felbontásra képes, míg a másik három 1920x1200-ra. A négy port közül a Lynix platform sajátossága miatt ez utóbbi csatlakozókból egy időben maximum kettőt használhatunk, azaz az Eyefinity itt még nem támogatott. A következő állomás egy ASMedia-vezérelt eSATA, és a maradék két natív USB 3.0 port kettőse. Érdemes a natív portokat használni, mivel ezek mindig jobb teljesítményre képesek, mint a külső vezérlők által meghajtottak. A sor végéhez közelítve a jól megszokott Realtek 8111E chipje által vezérelt Gigabit Ethernet alatt két USB 2.0-s port található, melyek mellett a szintén Realtek márkájú ALC 892 HD audiokodek analóg kimenetei kaptak helyet.
Az alaplap támogatja az ASUS-nál már korábban megismert EPU, TPU, MemOK! és Ai Charger+ funkciókat is. Ahogy ezen gyártó esetében már szinte megszokhattuk, úgy ezen az alaplapon is UEFI kapott helyet, melynek beállítási lehetőségeit a következő képeken próbáljuk bemutatni:







ASUS F1A75-V PRO UEFI
Mivel egy teljesen új platformról van szó, ezért számtalan, számunkra eddig még ismeretlen opcióval találkozhatunk. Az APU grafikus magjának elkülönített memóriát például egészen 2 GB-ig emelhetjük. Mindenesetre beállítási lehetőségek terén ennek az alaplapnak egyáltalán nincs semmi szégyellnivalója.
Hammertől Huskyig
Az előző oldalakon szándékosan nem esett túl sok szó a Llano CPU-magjairól. Az eddigiek olvasatában annyit már mindenképpen tudnunk kell, hogy a Stars, azaz a K10 vonalat vitte tovább a Husky. A K10, mint olyan, asztali vonalon leginkább az első, 65 nanométeres Phenom X4 processzorokkal vált ismertté. Ezt követte a 45 nanométeres Phenom II (K10.5), mely az elődhöz képest jóval alacsonyabb fogyasztással és magasabb órajelekkel került piacra.

Egy Husky mag
A Husky tehát gyakorlatilag egy kissé módosított K10.5, vagy ismertebb nevén Athlon II. Azért áll közelebb inkább az utóbbihoz, mint a Phenom II-höz, mert nem tartalmaz L3 cache-t. A K10.5-ös egyenes ági rokonságának köszönhetően a Husky a K8 (azaz az első Athlon 64) dédunokájának is tekinthető. Most aggassuk a K12 nevet a Husky-re! Egyrészt azért, mert az AMD technikai dokumentációjában ilyen néven emlegetik, másrészt talán valamivel egyszerűbb lesz átlátni a következő bekezdéseket.
Az AMD 2003-ban indította útjára a K8 családot, amely a megelőző, 3-utasítás széles K7 processzormag továbbfejlesztett változatán kívül integrált memóriavezérlőt és egy (vagy három) HyperTransport linket tartalmazott; ez(ek)en keresztül a rendszerrel, illetve további két CPU-val tarthatta a kapcsolatot. Az azóta megjelent AMD processzormagok olyannyira erre az alapvető felépítésre alapoznak, hogy egyetlen ábrán bemutatható a K8 (fekete), a K10/K10.5 (kék) és a K12 (piros) működése. Tekintsük át ezen mikroarchitektúrák jellemzőit!
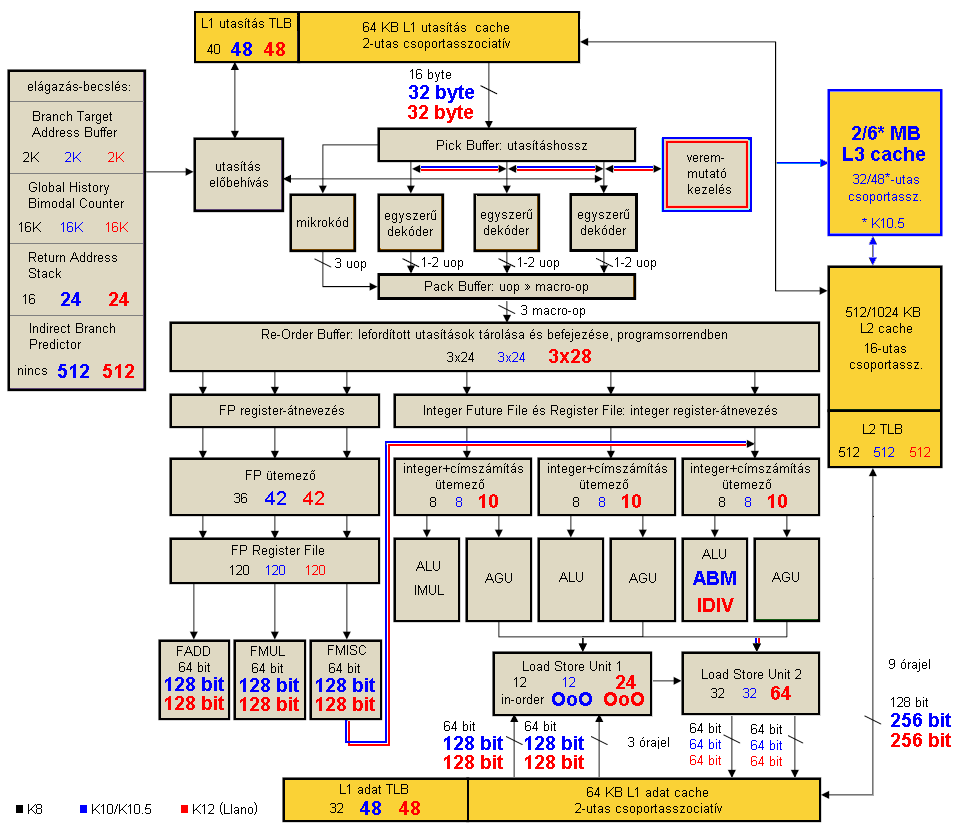
[+]
A processzor 64 KB-os, 2-utas L1 utasításcache-t tartalmaz, amelyből az elágazásbecsléssel együttműködve órajelenként 16 bájtot fogad a processzor Pick Buffer (Scan/Align) egysége, amely a változó hosszúságú x86/x64 utasítások kezdetét, végét és bonyolultságát meghatározza. Innen két úton juthatnak tovább az utasítások:
- órajelenként 3 egyszerű utasítás kerülhet a 3 teljesen megegyező egyszerű dekóderbe, amelyek órajelenként 1-1 x86/x64 utasítást fordítanak le belső, uopnak nevezett RISC-műveletekre (DirectPath);
- a bonyolult, legalább 3 uopra fordítható utasításokból órajelenként legfeljebb 1-et továbbít a mikrokódmotor felé (VectorPath).
A két lehetséges út a Pack Bufferben találkozik újra, amely az összetartozó, aritmetikai és memóriát kezelő uopokat "összecsomagolja" 1-1 macro-opnak nevezett egységgé, és ezekből legfejlebb 3-at programsorrendben továbbít a Re-Order Bufferbe, amely 24 ilyen hármast tud tárolni, azaz legfeljebb 72 macro-op fér el benne. Innen attól függően, hogy milyen jellegű műveletről van szó, vagy az integer vagy az FPU egységbe kerülnek végrehajtásra a műveletek. Egészen addig maradnak itt a lefordított műveletek, amíg be nem fejeződik a végrehajtásuk, majd órajelenként 1 összetartozó, kész macro-op hármas programsorrendben törlődik. Elágazástévesztés esetén ezen puffer teljes tartalma érvénytelenítésre kerül, és a kiszámolt helyes memóriacímről származó dekódolt macro-opokkal fog feltöltődni.
Az integer egység végzi el az egész számokkal dolgozó számításokat és kezeli a memóriaműveleteket is: 3 megegyező egységből áll, amelyeket 1 ALU (aritmetikai-logikai egység), 1 AGU (címszámító egység) és a hozzájuk tartozó közös 8 macro-op méretű ütemező alkot. Egyetlen utasításcsoport nem hajtható végre bármelyik egységen: ezek az szorzó utasítások, amelyek kizárólag az 1. végrehajtóba kerülhetnek; a többi utasításnál annak macro-op hármason belüli helye – vagyis az eredeti programsorrend – dönti el, hogy melyik egységben kerül végrehajtásra. Az osztásokon és az említett szorzásokon kívül a 8-64 bites egész számokon végzett bármely műveletet – ha annak minden bemeneti értéke registerben van és nem kell a memóriából beolvasni – 1 órajel alatt képesek végrehajtani az ALU-k.
A memóriacímek az AGU-kban kerülnek kiszámításra, és párhuzamosan dolgoznak az ALU-kkal. Mindhárom AGU órajelenként 1-1 címet továbbíthat a kétszintes Load Store Unitba, amely programsorrendben órajelenként 2 db 64 bites olvasást vagy 2 db 64 bites írást vagy 1-1 64 bites olvasást és 64 bites írást tud küldeni a 64 kB-os, 2-utas L1 adatcache felé, vagy ha abban nem található a keresett memóriaterület, akkor továbbítja az L2 cache-nek. Az L1 adatcache késleltetése 3 órajel, az L2-é ezen felül további 9 órajel.
Az FPU-egységnek a lebegőpontos és a SIMD-műveletek a felségterülete; 36-elemű ütemezőből és 3 darab, 64 bites végrehajtóból áll, amelyek specializáltak:
- az FADD az összeadás jellegű műveleteket hajtja végre;
- az FMUL a szorzásokat, osztásokat és gyökvonásokat kapja;
- az FSTORE vagy FMISC a többi, ritkább műveletet (pl. integer<->FP konverzió) kezeli.
A 128 bites SSE és SSE2 utasítások két 64 bites lépcsőben, egymás után kerülnek végrehajtásra.

Egyetlen K8 mag L2 cache nélkül
A 2007-ben piacra dobott K10 mikroarchitektúra alapvetően nem rajzolta át felépítést, viszont számos ponton kiegészítette azt:
- jelentősen okosodott az elágazásbecslő egység, egyrészt növelték a munkaterületeit, valamint kiegészítették az indirekt ugrások címjegyzékével;
- az L1 utasításcache-ből órajelenként kétszer annyi, 32 bájtnyi utasítás kerül feldolgozásra;
- a dekódolási lépcsőfok kiegészült egy veremmutatót kezelő egységgel, amely a veremkezelő utasítások manipulált lefordításával segíti azok párhuzamos végrehajtását;
- a 3. integer ALU dedikált ABM egységet kapott a bemutatkozó SSE4A utasításkészlet bitszámláló utasításaihoz;
- a Load Store Unit 1. szintjét a memóriaolvasásokra specializálták, viszont azokat out-of-order módon képes végrehajtani, órajelenként akár 2 db 128 bites olvasást kiadva az L1 adat cache-nek; kizárólag a 2. szint foglalkozik a memóriaírásokkal, valamint az L1-tévesztő memóriaolvasásokkal;
- az FPU-végrehajtók 128 bitesre bővültek, csökkentve ezzel a végrehajtáshoz szükséges időt; bevezettek továbbá egy 64 bit széles FP-to-int buszt, amely közvetlen adatkapcsolatot teremt az integer egységgel (pl. konverziós utasításoknál vagy adatmásolásnál);
- az L1 és az L2 közötti buszszélességet megkétszerezték;
- bemutatkozott a 2 MB méretű L3 cache, mellyel együtt a magonkénti L2 cache mérete fixen 512 KB-ra csökkent;
- az integrált kétcsatornás memóriavezérlő a korábbi 128 bites összekapcsolt (ganged) mód mellett új, 2 x 64 bites "független" (unganged) üzemmódot is kapott, amelynek előnye főleg a több magot használó, memóriaintenzív programokban mutatkozott meg.

Egyetlen K10 mag L2/L3 cache nélkül
A 2009-ben megjelent, sok helyen csak K10.5 néven emlegetett 45 nm-es K10 változatokban még tovább csiszolták a felépítést:
- az L3 cache mérete 6 MB-ra növekedett, késleltetése 2 órajellel csökkent, valamint lehetőséget kínál arra, hogy az inaktívvá lekapcsolt magok L1 és L2 cache-ik tartalmát kimásolják belé, majd kiürítsék azokat, csökkentve energiafelhasználásukat;
- növelték a RAM-sávszélességet;
- hatékonyabbá tették az indirekt ugrások becslésének működését;
- növelték a LOCK prefixszel ellátott, atomi x86/x64 utasítások párhuzamos végrehajtási sebességét;
- 36-ról 42-re növelték a lebegőpontos ütemező méretét, valamint finomították a lebegőpontos register->register másolások végrehajtását.

Egyetlen K10.5 mag L2/L3 cache nélkül
A most megjelenő K12 kódnevű Llano CPU-mag ugyancsak nagyban alapoz a megelőző felépítésre, bizonyos helyeken kiegészítve azt:
- a Re-Order Buffer méretét megnövelik, ezáltal 24 helyett 28 macro-op hármast képes tárolni, azaz legfeljebb 84 macro-opnak biztosít helyet; ezzel párhuzamosan az integer ütemezőket is megnövelik 8-ról 10 macro-opra;
- az osztó utasítások dedikált végrehajtó egységet kapnak a 3. ALU-ban, így ezek gyorsabban kiszámíthatók és velük párhuzamosan folyhat további műveletek végrehajtása a másik két ALU-ban;
- Az L1 adatcache valamint az L2 cache a korábbi 6T (6 tranzisztor cellánként) megoldás helyett immáron 8T (8 tranzisztor cellánként) kialakítással készül. Ez a lépés 33%-kal nagyobb cache területet eredményez, viszont alacsonyabb fogyasztást és megbízhatóbb működést kínál cserébe;
- L3 cache-t nem tartalmaz a felépítés, viszont az L2 cache méretét magonként 1 MB-ra növelték.

Egyetlen K12 mag L2 cache nélkül
Ez utóbbi K12-vel a 2003 óta piacon lévő K8 (más néven Hammer) architektúrától és annak közvetlen leszármazottjaitól végleg elbúcsúzunk. A Hammer helyét a közeljövőben debütáló, teljesen újragondolt Bulldozer mikroarchitekúra fogja majd elfoglalni.
(Az oldalon látható, összesen négy különböző magot ábrázoló kép méretarányos egymással.)
K8-tól K12-ig - áttekintés
Az előző oldalon taglalt változtatások természetesen alkalmazástól és felhasználási területtől függően voltak hatással a számítási teljesítményre. Megvizsgáltuk, hogy az eltelt jó néhány évben lassan véghezvitt módosítások miként befolyásolták a végrehajtási sebességet. Ehhez némi utánajárással kerítettünk mindegyik architektúrából egy-egy darabot.




K8 - K10 - K10.5 - K12
Igyekeztünk úgy összeállítani a mezőnyt, hogy a mag és cache mennyisége, valamint az magórajel megegyezzen. Ebből adódóan a K8 szerepét egy AM2 tokozású, Windsor kódnévre hallgató Athlon 64 X2 6400+ kapta. A K10 személyében egy Athlon X2 7850-et (Kuma) üdvözölhetünk, mely gyakorlatilag egy két magjától megfosztott Phenom X4. A K10.5 feladatát egy Athlon II X2 245 (Regor) vállalta magára, mely egy natív kétmagos lapkával rendelkezik. Végül a K12-es főszerepet egy A8-3850 kapta, mely ugyan alapból négy maggal rendelkezik, de mi ebből kettőt letiltottunk ezen tesztek erejéig.


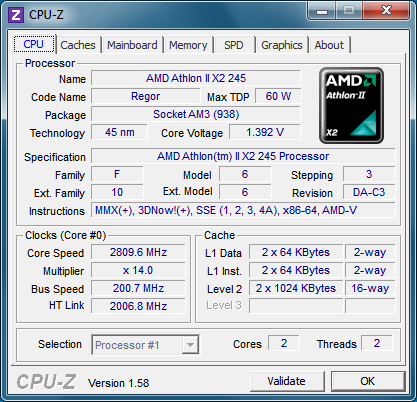

K8 - K10 - K10.5 - K12
Mivel az Athlon 64 X2 még csak egész CPU szorzót ismer, ezért az összes processzor órajelét egységesen 2800 MHz-re csökkentettük le, minden mást a gyári alapértelmezett beállításokon hagytunk.
| CPU Megnevezése | Athlon 64 X2 6400+ | Athlon X2 7850 | Athlon II X2 245 | A8-3850 |
|---|---|---|---|---|
| Kódnév | Windsor | Kuma | Regor | Llano |
| Architektúra | K8 | K10 | K10.5 | K12 |
| Tokozás | AM2 | AM2+ | AM3 | FM1 |
| Gyártástechnológia | 90 nm SOI | 65 nm SOI | 45 nm SOI | 32 nm HKMG SOI |
| Stepping | F3 | B3 | C3 | B0 |
| Beállított magórajel | 2800 MHz | |||
| Szorzó és ref. clk | 14 x 200 MHz | 28 x 100 MHz | ||
| NB/IMC(/L3) órajele | magórajel | 1800 MHz | 2000 MHz | 900 MHz |
| L1 cache / mag | 64 KB adat és 64 KB utasítás (2-utas) | |||
| L2 cache / mag | 1 MB (16-utas) | 512 KB (16-utas) | 1 MB (16-utas) | |
| L3 cache | nincs | 2 MB (32-utas) | nincs | |
| Utasításkészletek | 3DNow!(+), MMX, SSE, SSE2, SSE3 | 3DNow!(+), MMX, SSE, SSE2, SSE3, SSE4a | ||
| Rendszerbusz | 2 GT/s HyperTransport | 3,6 GT/s HyperTransport | 4 GT/s HyperTransport | 5 GT/s UMI |
| Támogatott RAM | DDR2-800 | DDR2-1066 | DDR3-1333 | DDR3-1866 |
| CPU feszültség | 1,40 V | 1,30 V | 1,40 V | 1,40 V |
| TDP | max. 125 W | max. 95 W | max. 65 W | max. 100 W |
A K10-es Athlon X2 7850-en kívül az összes szereplőben magonként 1 MB L2 cache lapul. Mivel olyan K10 nem született, amely magonként 1 MB másodszintű gyorsítótárral rendelkezne, sem olyan, amelyben ne lenne benne a 2 MB L3 cache, ezért jobb híján ezzel kellett beérnünk. Egy magra leveítve így is 1,5 MB cache jutott ennél a processzornál, igaz, az L3 lényegesen lassabb is, mint az L2.
| AM2 tesztplatform | AMD Athlon 64 X2 6400+ 3,2 GHz (2800 MHz-en járatva, azaz 5600+) ASUS M3A79-T Deluxe (790FX chipset, BIOS: 1801) 2 x 1 GB CSX Diablo DDR2-1200 memória DDR2-800 beállítás, 5-5-5-16-21-1T időzítések |
|---|---|
| AM2+ tesztplatform | AMD Athlon X2 7850 2,8 GHz ASUS M3A79-T Deluxe (790FX chipset, BIOS: 1801) 2 x 1 GB CSX Diablo DDR2-1200 memória DDR2-1066 beállítás, 5-5-5-15-33-1T időzítések |
| AM3 tesztplatform | AMD Athlon II X2 245 2,9 GHz (2800 MHz-en járatva) ASUS Crosshair IV Formula (890FX chipset, BIOS: 1902) 2 x 1 GB Crucial DDR3-2000 memória DDR3-1333 beállítás, 9-9-9-21-33-1T időzítések |
| FM1 tesztplatform | AMD A8-3850 2,9 GHz (2800 MHz-en járatva, 2 mag letiltva) ASUS F1A75-V PRO (A75 chipset, BIOS: 8629) 2 x 1 GB Crucial DDR3-2000 memória DDR3-1866 beállítás, 9-10-9-28-32-2T, időzítések |
| Videokártya | AMD Radeon HD 6870 1024 MB – Catalyst 11.6b |
| Háttértárak | Intel SSD 510 250 GB SSDSC2MH250A2 (SATA 6 Gbps) Kingston SSDNow M Series 80 GB SNM225-S2/80 GB (Intel X25-M G2) Seagate Barracuda 7200.12 500 GB (SATA, 7200 rpm, 16 MB cache) |
| Tápegység | Cooler Master Silent Pro M600 – 600 watt |
| Monitor | Samsung Syncmaster 305T Plus (30") |
| Operációs rendszer |
Windows 7 Ultimate 64 bit |
DDR2 memóriából csak 2 x 1 gigabájt állt a rendelkezésünkre, ezért a DDR3 modulokat alkalmazó AM3 és FM1 platformokba is hasonló kapacitás került. Azért döntöttük így, mert bizonyos tesztek profitálhatnak a nagyobb rendelkezésre álló szabad memóriából, és ez beleszólhatott volna az eredményekbe. Hasonló megfontolásból ezeknél a platformoknál a SATA 6 Gbps helyett SATA 3 Gbps-t használtunk. A Llanóban található grafikus mag ellenére a többi platformhoz hasonlóan az FM1-es ASUS alaplapba is bekerült a HD 6870, mellyel az APU grafikus magja inaktívvá vált. Erre azért volt szükség, mert itt most kizárólag tisztán a CPU magok számítási teljesítményét szerettük volna összevetni.
K8-tól K12-ig - a szintetikus eredmények tükrében
Első körben szintetikus méréseket végeztünk a négy különböző processzorral és platformmal. Ehhez az AIDA64 nevű programot hívtuk segítségül. Először az L1D cache sebességét néztük meg.

Látható, hogy itt a K10 óta gyakorlatilag szinte semmilyen változás nem történt, igaz, ez az azóta véghezvitt módosítások listájának ismeretében nem is túl meglepő.

Itt is az iméntihez hasonló a felállás. A K8->K10 váltáskor megejtett, L1 és az L2 közötti buszszélesség megkétszerezésének hatása jól látszik, de azóta ehhez a területhez nem nyúltak, aminek köszönhetően nem is történt semmi említésre érdemes.

Az L1 cache késleltetése a K8 óta azonos. Az L2 cache hozzáférési ideje a K8-ról K10-re váltáskor csökkent, míg a K12 esetében 4 tizedett nőtt, ami elképzelhető, hogy az immáron 6 helyett 8 tranzisztort tartalmazó celláknak köszönhető.

A memóriaelérés sebességét ábrázoló grafikon már egy fokkal talán érdekesebb, mint az előzőek. Az írás sebessége jókorát zuhant a K8-ról K10-re, majd a K10.5-tel valamelyest visszaállt, de még így sem érte el a K8 értékét. Ez valószínűleg a K8 magórajelen üzemelő memóriavezérlője miatt lehet. Az olvasás és a másolás szépen emelkedett az újabb generációkkal, persze ebben a gyorsabbnál gyorsabb memóriaszabványok támogatása is nagy szerepet játszott. A K12 eredményei érdekesek, mivel a négyfős mezőnyből ennek a memóriavezérlője üzemel a legalacsonyabb órajelen, egészen pontosan 900 MHz-en.
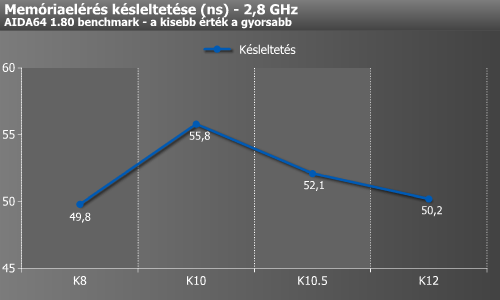
A memóriaelérés késleltetése is érdekes. A magórajelen üzemelő memóriavezérlővel szerelt K8-at csak a K12 tudta jobban megközelíteni. Emlékeztetőül: A K8 DDR2-800, míg a K12 DDR3-1866-os memóriák mellett lett lemérve.
Ezt követően az AIDA benchmark moduljai felé vettük az irányt, melyekből öt különféle teszttel mértük meg a processzorokat. Az egyik ilyen a CPU Queen, mely egy egyszerű, egész számokkal dolgozó benchmark, amely a processzorok elágazásbecslési képességeire fókuszál, és a „nyolc királynő egy sakktáblán” feladványra épül (10 x 10-es sakktáblán). A teszt MMX-, SSE2- és SSSE3-optimalizált (melyek közül az utóbbit éppen egyik tesztelt CPU sem támogatja), és kevesebb mint 1 MB memóriát foglal le. Ebben a tesztben az elágazáskezelés képességei határozzák meg a pontszámot. Nemcsak a branch prediction táblák és a becslés pontossága, a return stack mérete, hanem az is, hogy az utasításkészlet támogatja-e valamilyen módon maguknak az elágazásoknak az elkerülését (van-e CMOV vagy PABSB utasítás), illetve képes-e egyszerre párhuzamosan több bábu helyzetével számolni.
A következő integer teszt a CPU Photoworxx, amely különböző digitális fotófeldolgozási műveleteket hajtat végre a processzorral (kitöltés, forgatás, random stb.). Ez a teszt főleg a processzorok integer számolási végrehajtási egységeit dolgoztatja meg a memória-alrendszerrel egyetemben, ezért nem skálázódik olyan jól több processzormag esetén. A teszt csak alap x86-os utasításokat használ. A Photoworxx a legösszetettebb teszt, többféle méretű képpel dolgozik, sok minden számít benne, de leginkább az átlagos memóriaelérés ideje a döntő. Sokat jelentenek a jobb prefetcherek, és itt számít a legtöbbet a memória és a cache-ek hatása.
Végül a harmadik integer teszt az CPU AES, mely az AES (azaz Rijndael) adattitkosító algoritmust használja. A teszt Vincent Rijmen, Antoon Bosselaers és Paulo Barreto publikusan elérhető C kódját használja ECB módban. A benchmark alap x86-os utasításokat és összesen 48 MB memóriát használ. Itt is inkább a CPU sebessége a fontos, illetve kiugróan az out-of-order load képesség számít.
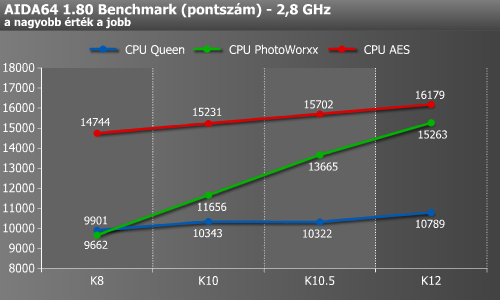
A CPU Queen esetében a K8-ről K10-re, majd a K10.5-ről K12-re váltásnál láthatunk említésre méltó növekedést. A CPU Photoworxx eredménye meredeken, a K10.5-ig generációnként nagyjából 2000, majd onnan végül durván 1500 pontot emelkedett. Ez jó eséllyel a memória-írási sebesség hasonló mértékű növekedésének tudható be, ami a feljebb található grafikonról is könnyen levehető. A CPU AES esetében némileg hasonló a helyzet, csak itt egy kevésbé meredek, 500 pont körüli növekedés látható a négy generáción átlépkedve.
Az integer tesztek után kettő, lebegőpontos számításokat végző mérést is elvégeztünk. Az első ilyen az FPU Mandel, ami a 64 bites (kétszeres pontosságú) lebegőpontos teljesítményt méri le a „Mandelbrot” fraktál egyes frame-jeinek kiszámolása révén. Ez a benchmark is assemblyben íródott, és kihasználja az egyes SIMD-utasításkészleteket (x87, SSE2, AVX).
Az utolsó teszt az FPU VP8 a Google VP8-as kodekjével tömörít egy 1280x720-as felbontású, 8192 kbps bitrátájú videót a legjobb minőségi beállítások mellett. A tömörítendő képkockákat az FPU Julia fraktál modulja állítja elő. A SIMD-utasításkészletek közül ez az MMX, SSE2 és SSSE3 kiterjesztésekből képes profitálni.
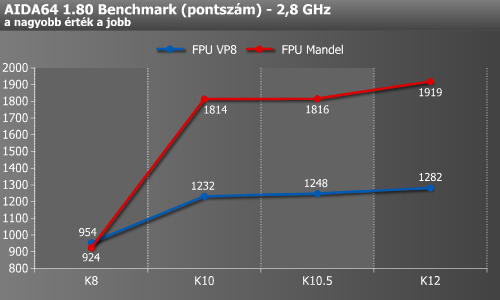
Ahogy látható is, a K8->K10 lépés elég nagy ugrást eredményezett itt, amely minden bizonnyal még az FPU-végrehajtók 128 bitesre való bővülésével magyarázható. Ezután előre haladva leginkább csak kisebb emelkedéseket láthatunk.
K8-tól K12-ig - a valós felhasználás tükrében
Lássuk, hogy a valós, mindennapos felhasználás során alkalmazott programok hogyan reagáltak a különböző architektúrákra!
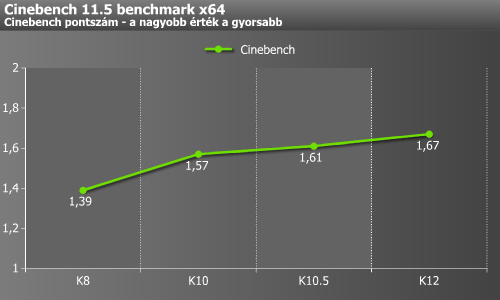
A Cinebench esetében újfent K8-ról K10-re látható egy nagyobb lépés, majd ezután csak néhány tizedet nőtt a pontszám.
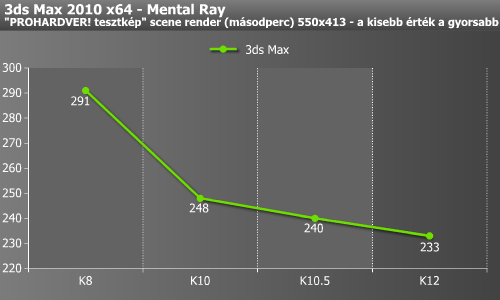
3ds Max esetében is ugyanez a képlet. Ahogy az AIDA FPU tesztjeinek esetében, itt is valószínűleg a 128 bites végrehajtókra való áttérésnek volt köszönhető az első nagyobb ugrás.
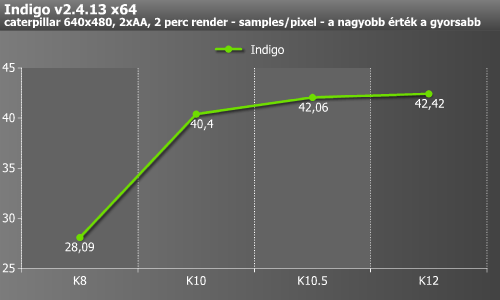
Az Indigo is hasonló képet ad, bár itt a K10->K10.5 lépcsőnél még látható egy durván 4%-os emelkedés is.


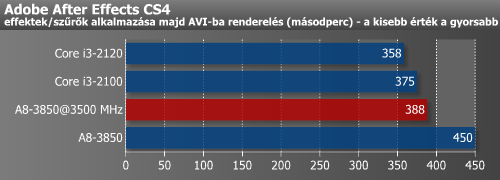
Az Adobe programok esetében már más volt a helyzet. Itt érdekes módon a a három alkalmazásból kettő esetében (Premier Pro és Photoshop) a legnagyobb gyorsulás K10.5-ről K12-re áttérve volt tapasztalható, de After Effects alatt is látható egy hasonló tendencia.

Sony Vegas esetében hol kisebb, hol pedig nagyobb léptékű gyorsulás volt tapasztalható. A Powerdirector a K8->K10 lépcsőnél inkább lassult, mintsem gyorsult volna, míg utána egy erős javulás következett.

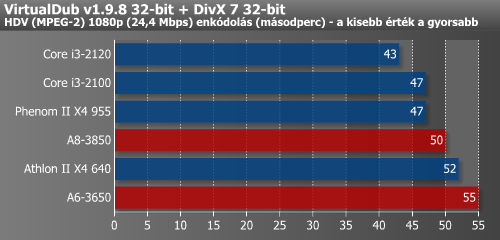
A DivX és XviD konvertálások esetében egy valamivel visszafogottabb tendencia volt megfigyelhető.

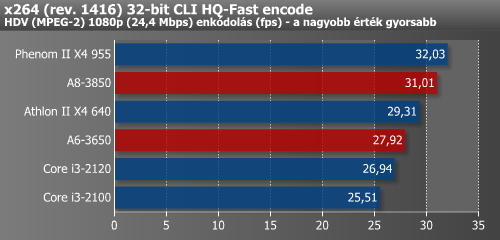
Az x264-es mérésnél ahogy haladtunk előre, annál alacsonyabb volt a gyorsulás.
K8-tól K12-ig - a valós felhasználás tükrében II.

A WinRAR és a 7-Zip is elsősorban az alacsony memóriakésleltetést és a nagy sávszélességet kedveli. Ez szépen meg is mutatkozik most is.

A Sorenson Squeeze mérésénél a legnagyobb ugrást a K8->K10 lépcsőnél tapasztaltuk, míg ebből a szempontból a második helyen a K10.5-ről K12-re való lépés áll.

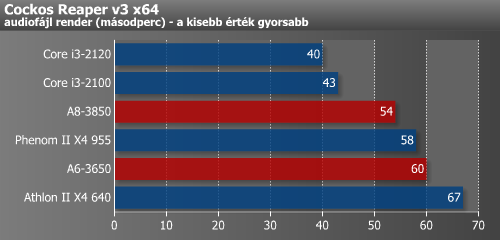
A Cockos Reaper esetében szinte majdnem egyenes úton gurulhatunk le egészen K-hegy lábáig.

Az ingyenes LameXP-vel egy 19 különálló zeneszámot tartalmazó, összesen 76 perc játékidejű CD-t (pontosabban annak WAV fájlait) konvertáltuk át MP3 formátumba. A program minden egyes magon/szálon párhuzamosan konvertál egy fájlt.

A következő méréshez a szintén ingyenes AVG Free víruskeresőt vettük elő. Ezzel egy bő 12 GB, meglehetősen vegyes típusú fájlcsomót vizsgáltattunk meg, melyek egy SSD-n lettek elhelyezve, hogy a tároló olvasási sebessége biztosan ne korlátozzon. Az alkalmazáson belül magas prioritást állítottunk be, majd végül elindítottuk az ellenőrzést.

A fenti Apache teszt volt talán az egyetlen, amely szinte semmilyen mértékű változást nem mutatott ki K10.5-ről K12-re váltva.
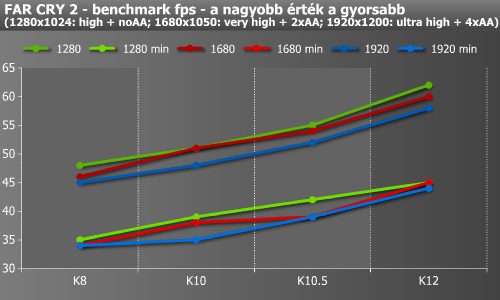

Azért hogy teljesen legyen a kép, még két játékot is beszúrtunk a mérésekbe. Talán ezek eredményeihez nem szükséges különösebb kommentár.
K8-tól K12-ig - összesített eredmények
Egy lakatfogós multiméter segítségével a processzorok fogyasztását is megmértük. Fontos megjegyezni, hogy itt kizárólag a központi egységek értékeit vizsgáltuk, azaz nem a teljes tesztrendszer fogyasztását néztük meg.
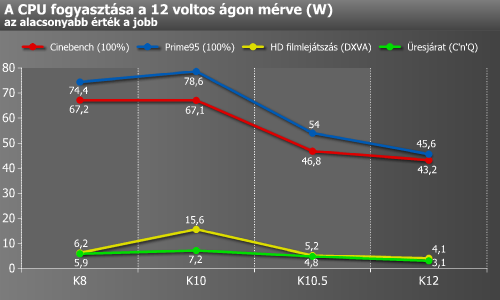
Ezután a szintetikus és a két játék eredményeinek kivételével összesítettük az eredményeket.

Meglehetősen beszédes a grafikon. Az általunk összeállított alkalmazáscsomag alapján a legnagyobb gyorsulást (nem túl meglepő módon) a K10 hozta, melyet a K12, és végül a K10.5 követ. Érdemes még egy pillantást vetni a teljesítmény/fogyasztás mutatóra, mely a K10.5-re váltással és azután is elég meredeken emelkedik.
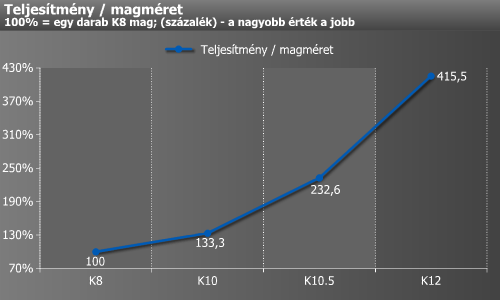
Legvégül még egy érdekesség. A teljesítmény/fogyasztás mutató mintájára elkészítettünk egy teljesítmény/magméret grafikont is. Ez egyetlen L2 (és a K10 esetében L3) gyorsítótár nélküli mag mérete alapján lett kiszámolva. Jól látható a folyamatos architekturális fejlesztések és csíkszélesség-csökkentések áldásos hatása, melynek köszönhetően egyetlen, a K8-nál durván 28%-kal nagyobb számítási teljesítményre képes K12-es Husky magból ma majdnem öt darab férne el az előd egyetlen magjának területén.

[+]
A Llano és a Core i3 csatája: bemelegítés
Most hogy részletesen ismerjük az egész APU-t, itt az ideje, hogy összeeresszük őket áraik szerinti ellenfeleikkel. A cikk írásának időpontjában aktuális árcédulák alapján az A8-3850 közvetlen ellenfele az i3-2120, míg az A6-3650 kihívója az i3-2100. Az i3 két magot tartalmaz, de ezen magok mindegyike két szálon képes feladatokat végrehajtani, míg az A6 és A8 négy különálló maggal oldja meg az összesen négy szálon való működést. Mindkét processzor tartalmaz grafikus magot is, így az igényeknek megfelelően akár egy diszkrét grafikus kártya nélküli konfiguráció is kiépíthető ezek segítségével.

Intel Core i3-2120 és AMD A8-3850 – árban párban [+]
| Processzor típusa | Intel Core i3-2120 Intel Core i3-2100 |
AMD A8-3850 AMD A6-3650 |
AMD Phenom II X4 955 |
AMD Athlon II X4 640 |
|---|---|---|---|---|
| Kódnév | Sandy Bridge | Llano | Deneb | Propus |
| Tokozás | LGA1155 | FM1 | AM3 | |
| Magórajel | 3300 MHz 3100 MHz |
2900 MHz 2600 MHz |
3200 MHz | 3000 MHz |
| Magok / szálak | 2 / 4 |
4 / 4 | ||
| Max. hivatalos memória-órajel | DDR3-1333 | DDR3-1866 | DDR3-1333 | |
| Turbo Boost v. Core | nem támogatott | |||
| L1 cache mérete | 2 x 32/32 kB | 4 x 64/64 kB | ||
| L2 cache mérete | 2 x 256 kB | 4 x 1 MB | 4 x 512 kB | |
| L3 cache mérete | 3 MB | nincs | 6 MB | nincs |
| L3/IMC órajele (uncore/NB) | magórajel | 900 MHz | 2000 MHz | |
| Kommunikáció a chipsettel | DMI (5 GT/s) + FDI (GPU-hoz) |
UMI (5 GT/s) | HyperTransport link (2000 MHz - 4 GT/s) |
|
| Utasításkészletek | MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AVX | 3DNow(+), MMX, SSE, SSE2, SSE3, SSE4A | ||
| Egyéb technológiák | EIST, C1E, C-states Execute Disable Bit, Hyper-Threading, Quick Sync, VT-x |
Cool'n'Quiet 3.0, C1E, C6, EVP, AMD-V | Cool'n'Quiet 3.0, C1E, EVP, AMD-V | |
| Gyártástechnológia / feszültség | 32 nm HKMG 1,14 V (rev. D2) |
32 nm HKMG SOI 1,40 V (rev. B0) |
45 nm SOI 1,375 V (rev. C3) |
|
| TDP | max. 65 watt | max. 100 watt | max. 125 watt | max. 95 watt |
| Tranzisztorok száma Mag mérete |
624 millió 149 mm2 |
1,45 milliárd 228 mm2 |
758 millió 258 mm2 |
300 millió 169 mm2 |
| Integrált GPU (IGP) | HD Graphics 2000 | Radeon HD 6550D Radeon HD 6530D |
Nincs | |
| Grafikus mag kódneve | Gen6 | BeaverCreek | - | - |
| Végrehajtóegységek | 6 Execution Unit | 400 Radeon Core 320 Radeon Core |
- | - |
| Órajel | 850 MHz | 600 MHz 443 MHz |
- | - |
| Turbo Boost v. Core órajel | 1100 MHz | nem támogatott | - | - |
| Támogatott DirectX verzió | DirectX 10.1 | DirectX 11 | - | - |
| Támogatott OpenGL verzió | OpenGL 3.1 | OpenGL 4.1 | - | - |
| Támogatott OpenCL verzió | nem támogatott | OpenCL 1.1 | - | - |
| Multi-GPU opció | nem támogatott | Dual Graphics | - | - |
| HD anyagok hardveres támogatása | Intel ClearVideo HD (H.264, VC-1, MPEG-2) |
AVIVO HD (UVD3) (H.264, VC-1, MPEG-2, MPEG-4 ASP/DivX) |
- | - |
| HDMI Audio | Dolby TrueHD és DTS-HD Master | Dolby TrueHD és DTS-HD Master | - | - |
A fenti összehasonlító táblázatba megpróbáltunk minél több adatot belezsúfolni az egyszerűbb összehasonlíthatóság érdekében. Ami talán elsőre feltűnhet mindenkinek, az az i3 processzorok órajelelőnye, sőt a teljes hatfős mezőnyből a két újonc órajele a legalacsonyabb. Mivel az elmúlt jó néhány évben az Intel processzorai azonos órajelen jobban teljesítenek, ezért ez nem túl jó ómen az APU-k számára, már ami a CPU-s számításokat illeti.

AMD A6-3650 és A8-3850[+]
A másik sokat sejtető adat a TDP. A Core i3-ak esetében ez 65 watt, míg a két APU-nál 100 watt, tehát itt is egy adag előnnyel indul az Intel, legalábbis addig biztosan, amíg be nem futnak a 65 wattos verziók. A tesztbe az előző, AM3-as generációkból is bekerült 1-1 tag. Ezek a már jól ismert Phenom II X4 és Athlon II X4 vonalakról származnak.
| FM1 tesztplatform | AMD A8-3850 (2,9 GHz) AMD A6-3650 (2,6 GHz) ASUS F1A75-V PRO alaplap (A75 chipset, BIOS: 8629) 2 x 4 GB G.Skill RipjawsX DDR3-1866 F3-14900CL9Q-16GBXL memória DDR3-1866 beállítás, 9-10-9-28-32-2T, időzítések |
|---|---|
| AM3 tesztplatform | AMD Phenom II X4 955 3,2 GHz AMD Athlon II X4 640 3,0 GHz ASUS Crosshair IV Formula alaplap (890FX chipset, BIOS: 1902) 2 x 4 GB G.Skill RipjawsX DDR3-1866 F3-14900CL9Q-16GBXL memória DDR3-1333 beállítás, 9-9-9-24-33-1T időzítések |
| LGA1155 tesztplatform | Intel Core i3-2120 3,3 GHz Intel Core i3-2100 3,1 GHz ASUS P8Z68-V PRO alaplap (Z68 chipset, BIOS: 0651) 2 x 4 GB G.Skill RipjawsX DDR3-1866 F3-14900CL9Q-16GBXL memória DDR3-1333 beállítás, 9-9-9-24-1T időzítések |
| Videokártyák és IGP-k | AMD Radeon HD 6870 1 GB GDDR5 – Catalyst 11.6b AMD Radeon HD 6550D (AMD A8-3850 IGP) – Catalyst 11.7 AMD Radeon HD 6530D (AMD A6-3650 IGP) – Catalyst 11.7 MSI Radeon HD 6570 1GB DDR3 (R6570-MD1GD3/LP) – Catalyst 11.7 Sapphire Radeon HD 6670 1 GB GDDR5 (100326L) – Catalyst 11.7 Intel HD Graphics 3000 (Intel Core i7-2600K IGP) – GMA driver 8.15.10.2372 Intel HD Graphics 2000 (Intel Core i3-2120 IGP) – GMA driver 8.15.10.2372 |
| Háttértárak | Intel SSD 510 250 GB SSDSC2MH250A2 (SATA 6 Gbps) Kingston SSDNow M Series 80 GB SNM225-S2/80 GB (Intel X25-M G2) Seagate Barracuda 7200.12 500 GB (SATA, 7200 rpm, 16 MB cache) |
| Tápegység | Cooler Master Silent Pro M600 – 600 watt |
| Monitor | Samsung Syncmaster 305T Plus (30") |
| Operációs rendszer |
Windows 7 Ultimate 64 bit |

[+]
Az ASUS F1A75-V PRO alaplaphoz egy nagyon friss, a cikk írásának időpontjában még nem publikus BIOS (pontosabban UEFI) verziót használtunk, mely már tartalmazott néhány optimalizációt a korábbi, még kezdetlegesebb kiadásokhoz képest. Természetesen igyekeztünk a többi alaplaphoz is a legújabb verziókat felrakni. Egyedül a Crosshair IV Formula kapott szándékosan egy korábbit, mivel a legfrissebb már speciális optimalizációkat tartalmaz az AM3+ kompatibilitás érdekében.

[+]
Szokás szerint először a fogyasztást vettük górcső alá. Ennek mérését egy konnektorba dugható, digitális VOLTCRAFT Energy Check 3000 készülékkel végeztük, és minden esetben a teljes konfiguráció értékeit vizsgáltuk. Mivel a Core i3 és a Llano-alapú A6 és A8 is tartalmaz IGP-t, ezért ezek fogyasztását kétféle módszerrel is megvizsgáltuk. Az első esetben egy diszkrét Radeon HD 6870 került a rendszerekbe, amivel az integrált GPU inaktívvá vált, majd később ezt kivettük és e nélkül is elvégeztük a méréseket. Az üresjárati mérséknél mindhárom platform esetében be volt kapcsolva az összes lehetséges energiagazdálkodási funkció (EIST, C'n'Q, C1E, C6).
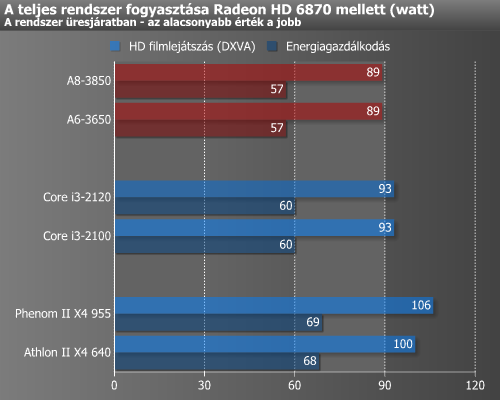

Itt talán egy kisebb meglepetésre minden esetben a Llano hozta a legalacsonyabb értékeket. Úgy fest, hogy a mérnökök a kis terhelés melletti fogyasztás csökkentésének érdekében tett lépései meghozták a kívánt eredményt. Régen láthattunk már olyat, hogy az AMD kevesebbett fogyaszt, mint az Intel.


Terhelés mellett már nem ennyire rózsás a helyzet. Itt szépen ki is jön az a 35 wattos TDP különbség, mely a Core i3 processzorok oldalára billenti a mérleget.
Videóvágás, szerkesztés (CPU)



After Effects alatt eléggé elhúznak a Core i3 processzorok. A Premier Pro már egy más képet mutat; ennek az alkalmazásnak valamiért nagyon tetszettek a K12 kisebb újításai, aminek köszönhetően a két Llano lapkás APU-nak sikerült még a közvetlen konkurenciát is legyűrnie. A Sony Vegas már nem reagált ennyire jól, ennek ellenére a még korábbi, házon belüli ellenfeleket sikerült beérnie alacsonyabb órajele ellenére is.
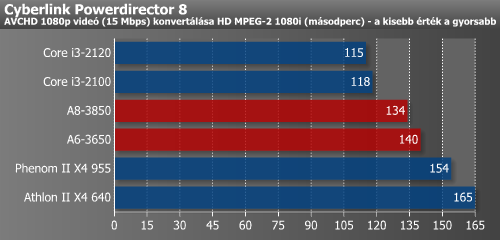

A Powerdirector tesztben szintén csak házon belül sikerült az előzés. A Sorenson Squeez-es mérés eredményei alapján az APU-k hátrébb végeztek, bár itt nem túl nagyok a különbségek. A Reaper az i3 processzorok fölényesebb előnyét mutatta. Az A8-3850 itt ismét megelőzte az X4 955-öt.
Videókódolás, egyéb (CPU)

A DivX és XviD tömörítések folyamán nem szerepeltek túl fényesen az APU-k, és itt is az Intelek törték az élre. Az x264 jobban kedveli a több különálló magon alapuló négy szálat, mint az Intel HyperThreading megoldását, így itt az AMD-k jobban szerepeltek.
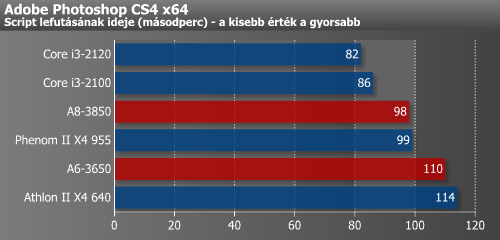


A Photoshop már régóta az Intel processzorainak fekszik inkább, de az Apache webszerver benchmark alatt is jobban szerepeltek, mint az APU-k. A vírusvizsgálatos mérésünk már más képet mutatott, azaz itt a négymagos AMD-k teljesítettek jobban.
Renderelés, tömörítés (CPU)

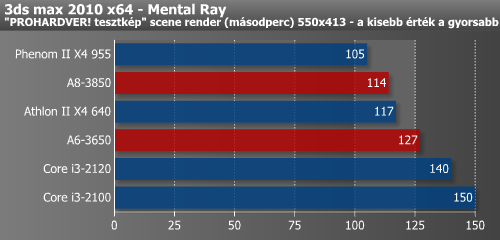

Renderelési időkben is megmutatkozott a négy mag előnye. Ezek az alkalmazások szinte kivétel nélkül jó párhuzamosított kódokat futtatnak, így az AMD-k az Intelek elé tudtak keveredni.


A tömörítéseknél a két i3 visszatért az élre, és az APU-k csak az X4 640-et tudták megelőzni.
Játékok (CPU)



Itt szinte a papírforma érvényesült, azaz a felbontás növelésével és a grafikus opciók feljebb kapcsolásával egyre inkább VGA-limitessé váltak (Radeon HD 6870-et használtunk) a játékok.
Második menet: GPU tesztek
Természetesen a processzorokban található integrált GPU-k teljesítményét is összevetettük egymással. Ebbe a meccsbe még meghívtuk a jelenleg piacon lévő legerősebb Intel GPU-t is, a HD Graphics 3000 névre hallgató IGP-t; ezt az aktuális asztali processzorkínálatból az i5-2500K, valamint az i7-2600K tartalmazza. Nálunk az utóbbi volt kéznél, így ezzel mértünk. Gyakorlatilag az ebben a processzorban található IGP kétszer annyi végrehajtóegységet tartalmaz mint az i3-as társában található HD Graphics 2000, és a maximális turbó órajele is magasabb (1,35 GHz). Mind az AMD, mind pedig az Intel integrált grafikus megoldásainak 512 MB memóriát adtunk, melyek a rendszermemóriából kerültek elkülönítésre.

[+]
Ezen kívül kipróbáltuk az A8-3850 APU Dual Graphics képsességeit is, melyet már a processzor doboza is lelkesen reklámoz. Ehhez nekünk egy MSI HD 6570 és egy Sapphire HD 6670 állt rendelkezésünkre. A kártyákat az FM1-es tesztrendszerben mértük le egymagukban, majd később a Dual Graphics engedélyezése mellett is lefuttattuk a teszteket. Így azt is látni lehet, hogy mikor mennyit számított ez a funkció.

[+]
Az AMD szerint az A8-3850-ben található HD 6550D egy diszkrét HD 6570-nel párosítva HD 6630D2-t ér, míg HD 6670-nel megtámogatva már HD 6690D2-t, bár ez sem az eszközkezelőben, sem a Catalyst Control Centerben nem mutatja magát. A GPU tesztekhez a lehető legfrissebb WHQL minősítésű Catalyst 11.7-et használtuk 11.6 CAP3 alkalmazásprofillal megtámogatva.
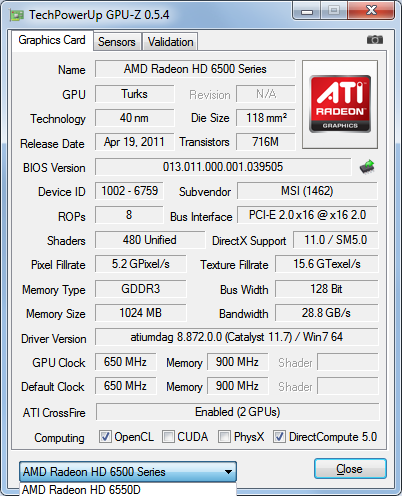

A fentieket látta a GPU-Z, miután engedélyeztük a többkártyás renderelést. A HD 6670 esetében valamiért hibásan 3 GPU-s CrossFire-t mutatott.
Kíváncsiak voltunk a rendszerek fogyasztására magas GPU terhelés mellett is. Ehhez a még mindig meglehetősen erőforrásigényes Crysis Warheadet, és a már korábban megismert, digitális VOLTCRAFT Energy Check 3000 fogyasztásmérőt hívtuk segítségük. Itt is minden esetben a teljes konfiguráció értékeit néztük.
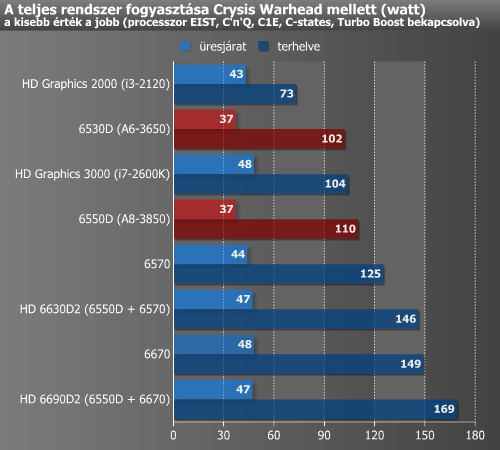
A Core i3 itt is jobb volt, de még a Core i7 fogyasztása is jó, bár ennek TDP-je is alacsonyabb (95 watt), mint az A8-3850 APU-é. Hamarosan kiderül, hogy a fogyasztások mellé milyen grafikus számítási teljesítmény társul. Érdemes megemlíteni, hogy terheletlen állapotban a nagyobbik APU GPU-ja órajelét 282 MHz-re vette vissza.
Crysis Warhead, DiRT 3, Shogun 2
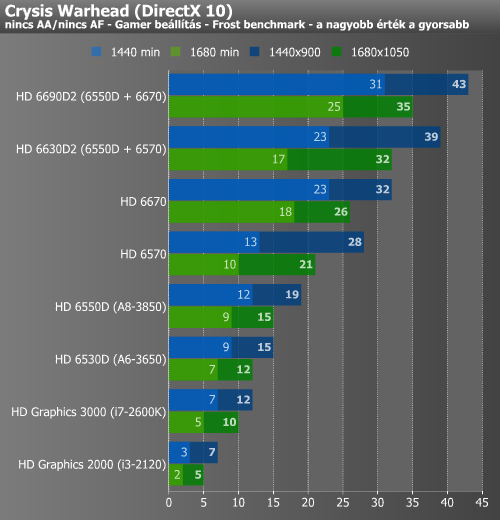
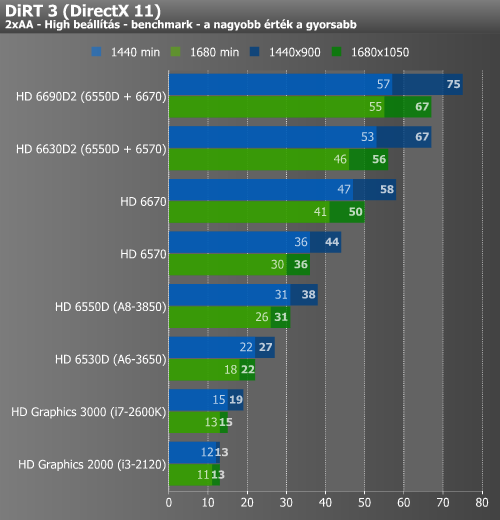
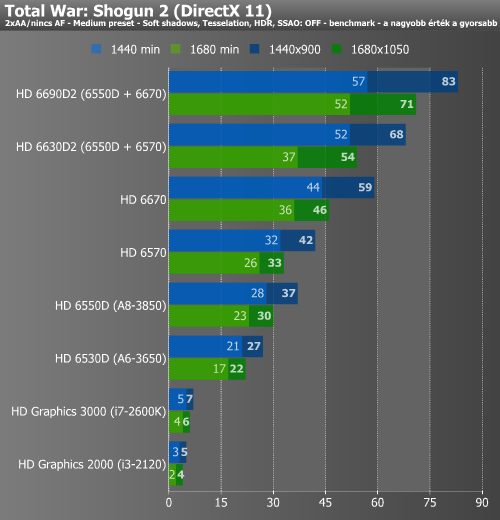
A Crysis Warheadről tudjuk, hogy még az erősebb mai diszkrét videokártyákat sem kíméli, és így természetesen az integrált megoldások sem kapnak kegyelmet. Az önálló HD 6670 az alacsonyabbik felbontásban már játszhatóhoz közeli szintet mutatott, de alatta nem ez volt a helyzet. A HD6690D2 már képes volt játszható szintet hozni mindkét mérésnél. A DiRT 3 az elődhöz hasonlóan egy meglehetősen jól optimalizált motorral rendelkező játék. Ennek köszönhetően kisebb meglepetésre az A8-3850 APU képes volt magas részletességi beállítások mellett 1680x1050-ben is játszható sebességet produkálni. A Shogun 2 alatt is majdnem sikerült megismételni a bravúrt, de itt a nagyobbik felbontás minimum értéke már 25 alá csúszott. Mivel az Intel GPU-k nem ismerik a DirectX 11-et, ezért őket itt 10.1 mellett mértük le, bár láthatóan nem nagyon feküdt nekik ez a játék sem. A Dual Graphics mindhárom esetben szépen skálázódott.
Metro 2033, STALKER, AvP
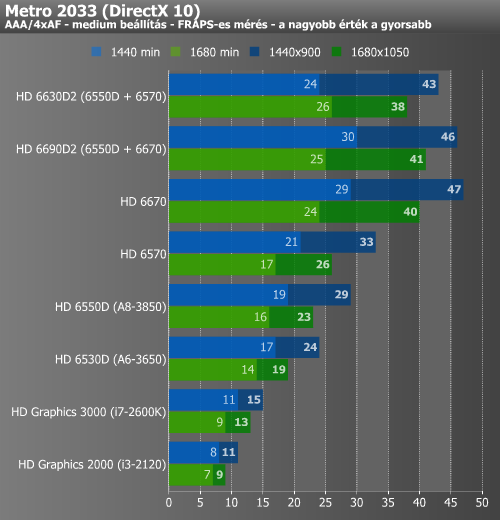


A beállított felbontások és részletességi szint mellett Metro 2033-ban nem sikerült játszható szintet produkálnia az APU-knak. Egyedül a HD 6670 volt képes erre, valamint a HD6630D2. Érdekes, hogy míg az utóbbi esetében láthatóan jól működött a Dual Graphics, addig a HD 6670-nel párosítva nem igazán mutatott javulást. A S.T.A.L.K.E.R esetében már más volt a kép. Itt a nagyobbik APU ismét erőre kapott és vele együtt a Dual Graphics is. Az Intel GPU-kat itt is jobb híján DirectX 10 mellett mértük le. Az AvP benchmark esetében nincs lehetőség a DirectX módjának váltására, így az Intel GPU-k ezt nem tudták lefuttatni, igaz, az APU-k is megizzadtak vele, és mindkét felbontásban csak a HD 6670-nel megtámogatott A8-3850 bírt el tisztességesen ezzel a próbával.
BFBC2, Starcraft 2, GPU-s konvertálás
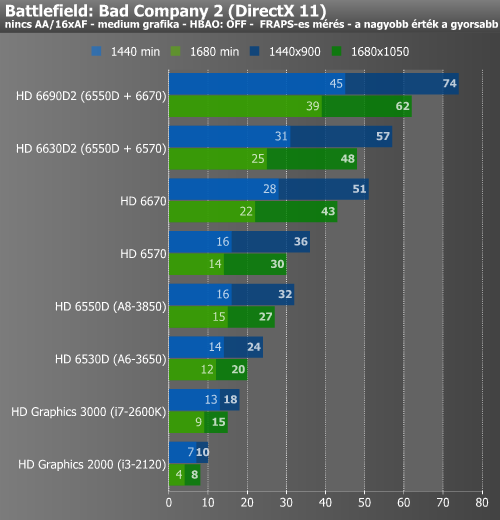

Battlefield alatt az átlagos képkockákkal nem volt gond, de a minimumokkal annál inkább. Itt még a HD 6670 sem tudott folyamatos játékot produkálni 1680x1050-ben, csak az A8-3850 és a két Radeon rokonának párosa. Az Intel grafikus magokat itt is DirectX 10 mellett vizsgáltuk. A Starcraft 2-vel szépen boldogult a nagyobbik APU, és 1440x900-ban még a kisebbik is tudott hozni egy még játszható szintet. Mivel egyelőre a DirectX 9-es játékokkal nem működik a Dual Graphics, ezért ez itt nem hozott semmit a konyhára.
Végül megnéztünk egy GPU-támogatott konvertálót. Az ArcSoft MediaConverter 7 támogatja a Radeonok által támogatott ATI Stream, valamint az Intel Sandy Bridge processzorokban található Quick Sync nevű dedikált transzkódolót is. Ez utóbbi fix futószalagos, így csak MPEG2-be és H.264-be tud kódolni, pontosabban ezeket tudja gyorsítani.
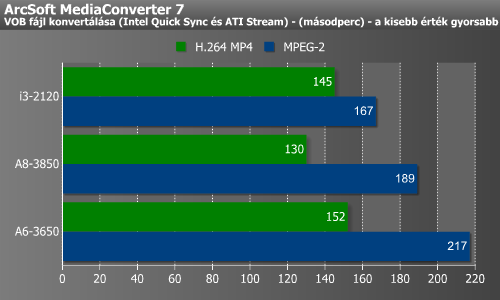
H.264 mellett az A8-3850 volt a gyorsabb, míg az MPEG-2-be való kódolásnál a Core i3-2120. Az A6-3650 lemaradt.

Az AMD készített egy System Monitor nevű kis alkalmazást, amely az APU-k terhelésének nyomon követésére szolgál. Ennek segítségével külön megfigyelhető a CPU magok és a GPU aktuális terhelése, valamint az azok közötti százalékos eloszlás is.
Az A8-3850 APU tuningja
A Llano tervezésévél a legutolsó szempont talán éppen a tuningpotenciál lehetett, már csak azért is mert elsősorban a mobil szegmensbe szánták a fejlesztést. A tesztünkben szereplő két APU szorzózáras, ami azt jenlenti, hogy a szorzó értékét csak csökkenteni lehet. Zármentes (Black Edition) kiadás legkorábban csak év végén várható. A tuningot kedvelők szerencséje, hogy az FCH-ba integrált órajelgenerátor ellenére is van lehetőség klasszikus tuningra. Ez annak köszönhető, hogy az Intel LGA1155 mellé készített Cougar Point PCH családdal ellentétben itt a chipsetben fixálva van a SATA és a PCI Express órajele. Ennek jótékony hatása, hogy nem akadunk el már az alap referencia-órajel felett pár MHz-cel. Egy belső fixált szorzó segítségével a GPU órajele is ebből származik, azaz ha emeljük az alap 100 MHz-et, akkor annak az órajele is azzal párhuzamosan megy fel. Ez jó mert ezzel a grafikus szekció számítási teljesítménye is növelhető, ugyanakkor bizonyos esetekben limitálhatja a CPU magok órajelének magasabbra emelését. Az A8-3850 esetében a GPU szorzója fixen 6x. Mi egy gyors kísérlet erejéig 140 MHz-re állítottuk a referencia órajelet (APU Frequency). A CPU magok szorzóját 29-ről 25-re csökkentettük, hogy a GPU órajele minél magasabb lehessen. Ez 3500 MHz-es CPU magsebességet eredményezett.
Míg a CPU magok feszültségét a gyári 1,400 voltról nem emeltük feljebb, addig az integrált NB (valamint az azzal egy vonalon ülő GPU, UVD, GMC, IMC) feszültségét 1,100-ről 1,300-ra toltuk fel. Ezzel a GPU órajele 40%-os emelést kapott, azaz 600 MHz helyett már 840 MHz-en járt. A memória szorzóját visszavettük kicsit, így ez "csak" 20%-kal lett túlhúzva, 2240 MHz-re.

[+]
Először megnéztük, hogy néhány, az i3-hoz képest nagyobb lemaradást mutató tesztben mennyit jelentett a plusz 600 MHz az A8-3850-nek.


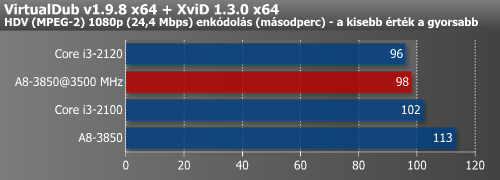
Ezután ismét előkerült a DiRT 3 és a Metro 2033, melyekkel megnéztük, hogy a túlhajtás mennyit jelentett a képkockák másodpercenkénti számában.


Látható, hogy ezzel a kis tuninggal már sikerült átugrani a HD 6570-et. A Metro 2033 futása közben 144 watt körüli értékeket láttunk a fogyasztásmérőn.
Legvégül arra is vetettünk egy gyors pillantást, hogy a RAM modulok órajele mennyiben befolyásolja a 3D-s megjelenítés sebességét.

Végszó
A Llano-alapú Fusionök megérkezésével véget ért egy korszak, valamint elkezdődött egy új. Az új APU-kkal lezárult egy 2003 óta élő mikroarchitektúra-vonal, és végre valóban elkezdődött az AMD által már jó pár éve folyamatosan csak szajkózott Fusion éra. Ennek végső következménye várhatóan az lesz, hogy idővel egyre több processzorban jelenik meg a grafikus mag, melynek teljesítményét idővel remélhetőleg egyre több, nem csak 3D-s megjelenítésen alapuló alkalmazással lehet majd kiaknázni.

Összességében a Llano korábban már jól bevált fejlesztésekre épült. A mérnökök nem szerettek volna a GPU-k számára ingoványos SOI gyártástechnológia mellett további kockázatokat vállalni még be nem járatott architektúrákkal. Ennek köszönhetőek a kissé módosított Stars CPU-magok és a Redwood GPU rész. Jövőre érkezik a második generációs, Trinity kódnevű utód, amely már Bulldozer-alapú modulokat, valamint Barts és Cayman GPU-k összegyúrásából megszülető GPU-t fog tartalmazni. Ezen felül a Turbo Core is tovább fog fejlődni, mely így megkapja a 3.0 jelölést. Ezekkel minden bizonnyal mind a CPU, mind pedig a GPU számítási teljesítménye tovább fog fejlődni.

[+]
Ennél egy hosszabb távú terv a CPU és a GPU még szorosabb összefonódása. Nem kizárt, hogy pár év múlva a a Bulldozer vonalat vélhetően majd hosszútávon is jellemző megosztott FPU valamilyen módon kiegészül a jelenleg még GPU-kban található shader tömbökkel. A Llano még csak a kezdet kezdete.
Cikkünk végéhez érve térjünk vissza a két Core i3 és Llano összecsapásához, pontosabban az eredmények összegzéséhez.

Az összesített számok alapján tisztán CPU teljesítményben kb. 11%-kal van lemaradva az kisebb A6-3650 a hasonló árban lévő i3-2100-tól. Az A8-3850 és i3-2120 viszonylatában ez a lemaradás kicsit kisebb, pontosan 7,8%. Pozitívum, hogy a nagyobbik APU mindent egybevéve bizony nem sokkal marad el a 300 MHz-vel magasabb órajelű Phenom II X4 955-től.

A CPU rész teljesítmény/fogyasztás mutatója esetén már sokkal nagyobb az Intel előnye. A 100 wattos APU-k többet fogyasztanak a 65 wattos i3-nál, ráadásul mindent egybevéve lassabbak is azoknál, ezzel nincs mit tenni. A házon belüli mezőnyből itt az A8-3850 ugrott az első helyre.
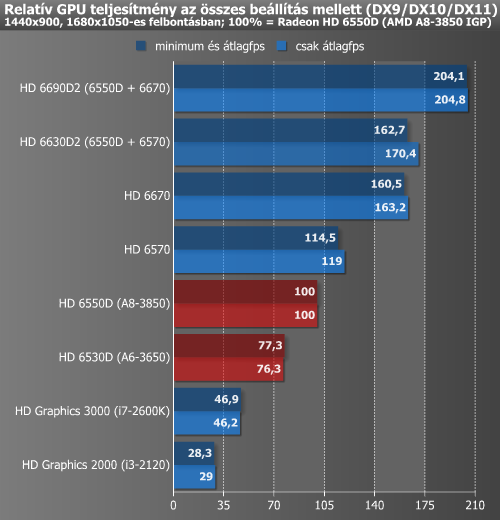
A GPU 3D-s megjelenítési teljesítményét nézve már változik a kép. Itt a két APU utcahossznyi előnnyel vezet. Az A6-3650 - i3-2100 viszonylatban 173%-kal gyorsabb az APU a HD Graphics 2000-nél, míg az A8-3850 113%-kal húz el az erősebb HD Graphics 3000-től. A két relatív teljesítményt taglaló grafikont nézve elmondható, hogy a két új AMD kiegyensúlyozottabb teljesítményt nyújt, ha mind a CPU, mind pedig a GPU sebességét számításba vesszük. Az A8-3850-ben lévő GPU mindent egybevéve 14,5%-kal marad el a
18 000 forint körüli áron megvásárolható diszkrét MSI HD 6570-től. Amikor ezt a kártyát még pluszban beraktuk a nagyobbik APU mellé, akkor átlagosan 62,7% plusz 3D-s teljesítményt kaptunk mindezért cserébe. A HD 6670 esetében pedig átlagosan valamivel több mint duplájára gyorsult a tesztelt játékok megjelenítési sebessége. Az idő szűkössége miatt már nem volt ezt lehetőségünk még alaposabban tesztelni, de ez utóbbival a DiRT 3 1920x1200-as felbontás és négyszeres élsimítás mellett is tökéletesen játszható szintet hozott (minimum 46 fps, átlag 56 fps).

A GPU-k teljesítmény/fogyasztás értékét vizsgálva az előbbiek után talán annyira nem meglepő, hogy még a magasabb fogyasztás ellenére is kedvezőbb mutatóval rendelkeznek az APU-k. Hiába fogyaszt kevesebbet a két HD Graphics IGP, ha ezzel párhuzamosan a számítási teljesítményük is jóval alacsonyabb. Itt feltűnhet még, hogy a két Dual Graphics szülött, a HD 6630D2 és a HD 6690D2 meglehetősen jó mutatókkal rendelkezik.

[+]
Pár hónappal ezelőtti Intel i3-2100 tesztünkben azt mondtuk, hogy annak teljesítménye egy átlagfelhasználónak tökéletesen elegendő lehet. Míg az A6-3650 összesítve 11%, addig az A8-3850 csak 1,7%-kal van lemaradva tőle, így az utóbbiról most elmondható ugyanaz. Egyetlen bökkenő a fogyasztás, ami a két 100 wattos APU esetén egyértelműen magasabb, így azonos ár mellett továbbra is az i3 lehet inkább az ajánlott, ha csak CPU-ként tekintünk ezekre a modellekre. Amennyiben viszont szükségünk van egy belépőszintű GPU teljesítményére is, azaz tudunk mit kezdeni az A8-3850 vagy az A6-3650 integrált grafikus processzorának erejével, akkor már inkább az AMD irányába billen a mérleg. Az A6-3650 HD 6530D nevű GPU-ja körülbelül egy most újonnan 10 000 forint környékén mozgó diszkrét HD 6450 sebességét hozza, míg az A8-3850 grafikus magja, a HD 6550D ennél durván 30%-kal gyorsabb. Ez utóbbi még ugyan nem éri el a 18 000 forint körül tanyázó diszkrét HD 6570 teljesítményét (esetleg csak tuningolva), de közepes részletesség mellett 1440x900-hoz vagy ezen felbontás alá, illetve tisztességesen optimalizált, vagy néhány éves játékok esetén akár az 1680x1050-hez is elegendő lehet. (Természetesen a különböző részletességi beállításokkal még lehet kísérletezgetni a lehető legjobb játszhatóság érdekében.) A korábbi integrált grafikai megoldásoktól hasonló produkció jóformán a lehetetlen küldetés kategóriába tartozott. Mindezekre kisebb ráadás, hogy IGP-s platformról lévén szó rendelkezésre áll az a kellemes tulajdonság, hogy a GPU hűtése a CPU hűtésével egy kalap alatt kipipálható, amivel egy potenciális zajforrással és porgyűjtővel kevesebb lehet a gépházban. További plusz, hogy a 3D-s megjelenítési teljesítmény később a Dual Graphics opció jóvoltából könnyen tovább bővíthető. Az utolsó pozitívum a tuningolhatóság, amit az Intel Sandy Bridge esetében már csak a K jelzésű modellek támogatnak.
Azt még meg kell jegyeznünk, hogy szerintünk a platform mellé nem árt egy legalább 1600 MHz-es órajelű DDR3 memóriacsomag. Egy ilyen sebességű 4 GB-os kit jelenleg már 7-8 ezer forint környékén beszerezhető, ami nagyjából 1-2 ezres többletköltséget jelent a DDR3-1333 szabványú csomagokhoz képest. Aki a legnagyobb sebességet szeretné kihozni a rendszerből, vagy még esetleg tuningolni is akar, annak érdemes elgondolkozni egy 1866 vagy annál magasabb órajelű kiten, ha a pénztárcája is engedi. Ez hosszútávon sem feltétlenül rossz vétel, mivel ha lehet hinni a híreknek, akkor már a jövőre érkező Intel és AMD platformok is hivatalos DDR3-2133 támogatással fognak érkezni.

Meglátásunk szerint aki jelenleg egy Core 2 Quad, Core i3-i5-i7, Athlon II X4, Phenom II X4 vagy ezeknél erősebb processzoros rendszerrel rendelkezik, annak nem éri meg ezekre a processzorokra átváltani, csak ha valamilyen különleges okból lenne szüksége pont egy ilyen platformra. Igen ám, de nagyon sokan még több éves, egy vagy kétmagos Pentium 4 vagy Athlon rendszereket nyúznak, korban hozzá illő grafikus kártyával. Nekik már megfontolandó alternatíva lehet fejlesztés esetében a Llano. Ahogy már utaltunk is rá, ez is leginkább csak abban az esetben igaz, ha a vásárló kihasználja a processzorban rejlő GPU-t is valamilyen módon. Erre most még elsősorban a különböző játékok és bizonyos videókonvertálók lehetnek alkalmasak, de később az OpenCL folyamatos terjedésével már akár szélesebb körű általános számításokhoz is felhasználható lesz az integrált grafikus mag ereje.
Mindent összevetve mi az A8-3850-et tudjuk ajánlani, már csak azért is, mert 31 000 forint környéki árával mindössze nagyjából 5 000 forinttal kerül többe, mint a kisebbik A6-3650. Ez utóbbi meglátásunk szerint ennek ismeretében egyelőre kissé túlárazott.
Mindenképpen említést érdemel még az ASUS F1A75-V PRO, amely az összes tesztünkben szépen, stabilan végezte a dolgát. Ezen felül a még viszonylag friss FM1 platformhoz és BIOS verziókhoz képest nem ütköztünk semmilyen, a teszteket hátráltató gyermekbetegségbe. Az FM1 foglalatos alaplapok táborában jelenleg a felsőházban helyet foglaló alaplap most 30 000 forintért vihető haza, ami a tudást, a felszereltséget és az újdonság már megszokott kisebb felárát is figyelembe véve szerintünk egy jó ár.
 |
 |
| AMD A8-3850 APU ASUS F1A75-V PRO alaplap |
AMD A6-3650 APU |
Oliverda
Az A8-3850 APU-t az AMD, az A6-3650 APU-t pedig Gianni bazárja bocsátotta rendelkezésünkre. Az ASUS F1A75-V PRO alaplapot az ASUS magyar képviselete biztosította.






