Hirdetés
Piledriver v2: Bulldozer kipofozva
A moduláris Bulldozer mikroarchitektúra kidolgozása után az AMD előtt állt a következő nagy feladat: a lehető legkevesebb idő alatt, radikális módosítások nélkül, az egységnyi órajel alatt végrehajtandó utasítások számát megemelni a magórajellel párhuzamosan. Ehhez született meg a Piledriver v2 (a Piledriver magyarul "cölöpverő" jelentéssel bír), mely többek között tartalmazza a Trinity Piledriver v1 moduljai esetében már látott, Cyclos által kifejlesztett Resonant Clock Mesh órajelelosztási technológiát, aminek fogyasztáscsökkentő hatását teljes egészében az órajelnövelésre fordították.
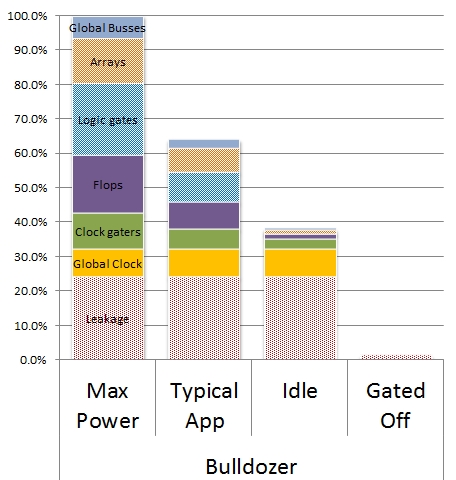
Mint a képen látható, a Bulldozer fogyasztásának 15-35%-áért maga az órajelhálózat a felelős. A Resonant Clock Mesh – amelynek a Trinity volt az első kereskedelmi forgalomba került megvalósítása – jelentősen csökkenti ezt a fogyasztási tényezőt, ami azonos órajelen kisebb TDP-t, illetve azonos TDP mellett magasabb órajelet jelent. A Resonant Clock Mesh megvalósítása a Bulldozer meglevő órajelrendszerére épült a Piledriverben; a Cyclos szerinti optimalizációkkal a következő generációkban akár meg is duplázható a fogyasztási megtakarítás.

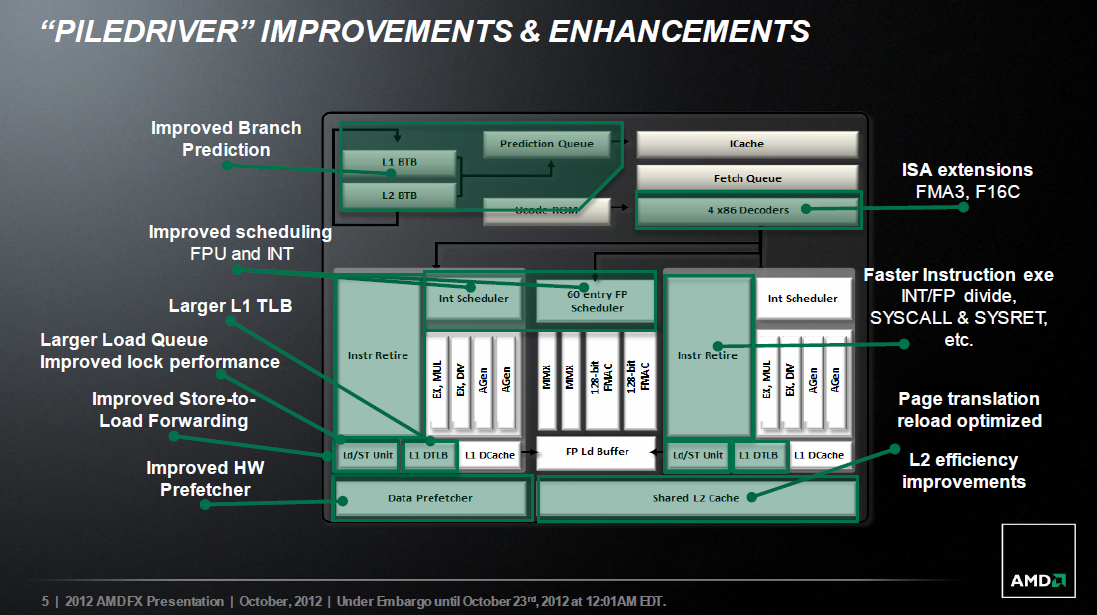
A most debütáló modulokban a dedikált egész számos végrehajtók működését is némileg átszervezték. A Bulldozer magjaihoz hasonlóan a Piledriver integer műveletvégző egységeit is 2 ALU (Arithmetic-Logic Unit) és 2 AGU (Address Generation Unit, címszámító egység) alkotja, viszont míg utóbbiak feladata a Bulldozerben a memóriacímek kiszámítására korlátozódott, addig itt a regiszterből regiszterbe történő elemi 32 vagy 64 bites adatmásolásokat is el tudják végezni.
- A legegyszerűbb ilyen másolást a MOV regiszter1, regiszter2 x86/x64 utasítás végzi, mely a regiszter2 tartalmát átmásolja regiszter1-be. Mivel az x86/x64 integer utasítások egyik bemenő regiszterparaméterüket felülírják az eredménnyel, ezért sokszor annak tartalmát át kell másolni egy másik regiszterbe a további munkához, ezáltal az ilyen MOV utasítások a leggyakoribb műveletek közé tartoznak a programokban; a Piledriver-magok az AGU-k segítségével 4 regisztermásolást tudnak végrehajtani órajelenként.
- Ritkább eset az XCHG regiszter1, regiszter2 utasítás, amely a két regiszter tartalmát megcseréli. Ezt a dekóder két adatmásoló elemi műveletre fordítja le: az egyik a regiszter1 eredeti tartalmát másolja a regiszter2-be, a másik a regiszter2-ét a regiszter1-be; az AGU-k közreműködésével 2 ilyen XCHG utasítás futtatható le órajelenként egy-egy magban, vagy pedig egyetlen XCHG esetén az ALU-k tehermentesíthetők ennek végrehajtása alól, és más számítási műveletekkel foglalkozhatnak párhuzamosan.
- Kifejezetten ritka utasítás az XADD regiszter1, regiszter2, amely a következő műveletet végzi el: (1) összeadja a regiszter1 és regiszter2 tartalmát, (2) a regiszter2 eredeti tartalmát a regiszter1-be másolja, (3) az összeadás eredményét a regiszter2-be helyezi el; itt a 2. lépésben történő adatmásolást vehetik át az AGU-k.
- Még egy utasításban vállalhatnak szerepet az AGU-k: ez a Piledriverben újonnan bevezetett BEXTR regiszter1, regiszter2, regiszter3 utasítás, amely a regiszter1 eredeti tartalmából regiszter2 bitpozíciótól kezdődően regiszter3 darab bitet kiemel, és ezt elhelyezi a regiszter1-ben.
[+]
Mindezek mellett a v2 modul tartalmazza a v1 modul összes fejlesztését a Bulldozer óta:
- az integer magokban és a Flex FP-ben található ütemezők hatékonyságát a végrehajtó egységek kihasználásának növelése érdekében javították;
- az integer magok Load/Store egységében az olvasási sor méretét 40-ről 44-re növelték, azaz 10%-kal több, függőben levő memóriaolvasási műveletet kezelhet egyszerre 1-1 mag;
- az L1 adat TLB és az utasítás Translation Lookaside Buffer mérete egyaránt 32-ről 64 bejegyzésre nőtt, így kevesebb időigényes virtuális->fizikai memóriacím-fordítás szükséges a programok futása közben;
- az elágazásbecslés hatékonyabb lett, kevesebb téves elágazásjóslatot eredményezve: a hibrid branch prediktor két egységből áll, amelyek kétféle szempont szerint elemzik azt, hogy a következő órajelben mely utasítások kerüljenek beolvasásra az utasításcache-ből. Arra az esetre, ha a két jóslat ellentmond egymásnak, egy kis logika nyomon követi, hogy melyik jósol egy-egy adott szituációban korrektebben, és annak eredményét fogja használni legközelebb;
- a felhasználói és kernel mód között váltó instrukciók, az atomi (LOCK) műveletek, valamint a a lebegőpontos és az egész számos osztó utasítások végrehajtása gyorsabb lett; utóbbiak 10-60%-kal kevesebb órajelet igényelnek, míg az atomi műveletek akár 20%-kal kevesebbet;
- a Flex FP különböző alegységekből áll, az ezek közötti adattovábbítás további 1 órajellel növeli a művelet végrehajtási idejét; a Piledriverben a leggyakoribb ilyen eset a kiszámított eredmények memóriába írása (ez az adott lebegőpontos számítási alegységből a STORE alegységbe történő továbbítást jelenti), ami már nem igényli ezt a +1 órajelet;

[+]
- négy új utasításkészlet költözött be a CPU-ba: az Intel Haswellben alkalmazandó, 3 paraméteres FMA-utasítások (a Bulldozer csak a rugalmasabb, 4 paraméteres formákat kezeli); a 32 bites egyszeres és a 16 bites félpontosságú lebegőpontos számok közötti konverziót megvalósító F16C készlet két utasítása; továbbá a BMI- és TBM-készletek, amelyek egyrészt lehetővé teszik egy-egy 16, 32 vagy 64 bites egész érték bizonyos bitjeinek feltételtől függő csoportos 1-re állítását és/vagy törlését – kiváltva ezzel 2-3 korábbi külön utasítást –, másrészt implementálják az ANDNOT műveletet, és a BEXTR utasítás révén az ilyen számok összefüggő bitmezőinek kiemelését;
- az adat prefetcherek a spekulatívan előbetöltött adatokat azonnal 'legrégebben használt'-nak jelölik meg, kerülendő a valóban szükséges adatok későbbi felülírását téves jóslat esetén.
A cikk még nem ért véget, kérlek, lapozz!








