A Trinity újításai
A moduláris Bulldozer mikroarchitecktúra kidolgozása után az AMD előtt állt egy következő nagy feladat: a Piledriverrel olyan szintre javítani a teljestmény/fogyasztás mutatót, hogy az leválthassa a Llanókban alkalmazott K12 felépítést a 2. generációs Trinity APU-kban. Ez elsősorban a fogyasztás lejjebb tornászását jelenti, másodsorban olyan csiszolásokat, amelyek az egy órajel alatt valóban végrehajtható utasítások számát növelik. Mindebből természetesen az ugyancsak Piledriver-alapra építkező, következő FX és Opteron CPU-k is profitálni fognak, melyek bár nem tartamaznak integrált grafikus magot, órajeleiket feljebb lehet tolni vagy még több modult lehet egy lapkába építeni. Mivel az APU-k és a klasszikus sokmagos CPU-k igényei túl széles skálát fednek le, kétféle Piledriver modul készült: a Trinity szerényebb követelményeinek megfelelő Piledriver v1 és a teljesítményorientált v2, mely az újabb FX és Opteron modellekben kap majd helyet. Mindkét modulra építkező lapkákban közös, hogy az órajelelosztás energiaigényét csökkentették a Cyclos által kidolgozott Resonant Clock Mesh technológiára alapozva.
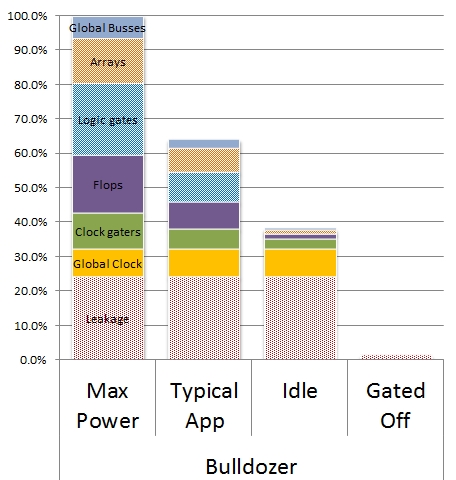
Mint a képen látható, a Bulldozer fogyasztásának 15-35%-áért maga az órajelhálózat a felelős. A Resonant Clock Mesh – amelynek a Trinity az első kereskedelmi forgalomba került megvalósítása – jelentősen csökkenti ezt a fogyasztási tényezőt, ami azonos órajelen kisebb TDP-t, illetve azonos TDP mellett magasabb órajelet jelent. Ennek köszönhetően a AMD termékpalettáján is megjelent az eddigi 25 és 35 W mellett a 17 W-os kategória, lehetővé téve számukra teljesítményorientáltabb ultrahordozható laptopok építését.

A Resonant Clock Mesh megvalósítása a Bulldozer meglevő órajelrendszerére épült a Piledriverben; a Cyclos szerinti optimalizációkkal a következő generációkban akár meg is duplázható a fogyasztási megtakarítás.

[+]
Mindemellé a Llano energiamenedzsmentjét is tovább csiszolták. A Trinity-t az elődhöz hasonlóan elsősorban a mobil szegmensbe szánják, ahol minden egyes wattnak rendkívüli jelentősége van az akkumulátoros üzemidő szempontjából.
[+]
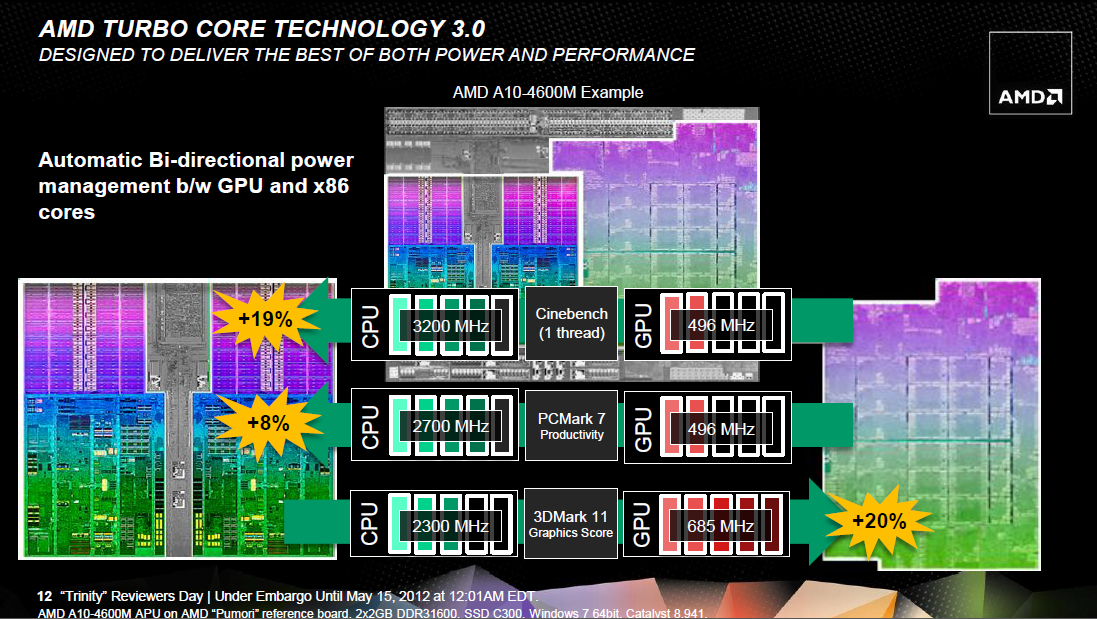
Alapvető változás, hogy míg a Llano esetében a GPU egy fix fogyasztási kerettel rendelkezett, így annak órajelét a rendszer nem tudta megemelni még akkor sem, ha az épp belefért volna a TDP-keretbe, addig a Trinity a terhelés függvényében már dinamikusan szabályozza az éppen felhasználható értékeket a CPU-magok és a GPU között, ergo az utóbbi üzemi frekvenciája megemelhető, ha szükséges és belefér a keretbe.

[+]
A rendszer vezérlője is változásokon esett át. A Llanónál minden egyes lehetséges magi aktivitáshoz (melyek száma 100 körüli) hozzárendeltek egy fogyasztási mutatót, ami alapján az energiagazdálkodási modul képes volt pontosan kiszámolni az éppen aktuális fogyasztást. A Trinity ezt kiegészítve gyors transzformációkkal, termikus számítások alapján modellezi a hőmérsékletet is, mely adatok felhasználásával gyorsabb órajelváltás mehet végbe. Mindezen felül további lépések is történtek az energiagazdálkodás terén a Piledriver köré építhető infrastruktúrákban:
- az integrált északi híd dinamikusan állítható órajelei mellé megjelent a rendszermemória órajelének állítási lehetősége is. Két ilyen lépcsőt ismer a rendszer, a gyári órajel mellett az alacsony NB-aktivitás esetén beállítható visszavett ütemet;
- az integált PCI Express 2.0 vezérlőt is bevonták a fogyasztás csökkentésébe, mivel az kihasználatlanság esetén képes visszaskálázni az eszközökhöz rendelt nagysebességű (x16, x8 vagy x4) kapcsolatot akár x1-re is, a többi vonalat ideiglenesen lekapcsolva. Többféle metódust is kínál erre a vezérlő, de a legrugalmasabbak csak AMD grafikus kártyákkal működnek együtt;
- az integrált kétcsatornás memóriavezérlő támogatja az 1,25 V alapfeszültségű LPDDR3 memóriamodulokat is.

[+]
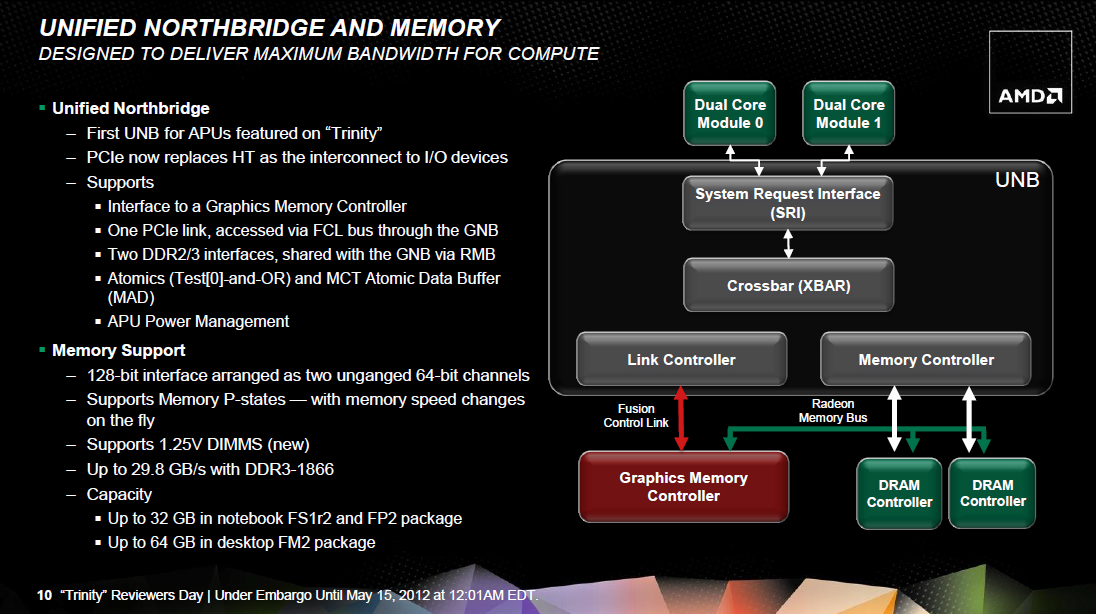
A Trinity integrált északi hídja átdolgozásra került a Llanóéhoz képest: a legnagyobb változást a Garlic és az Onion buszok RMB-re (Radeon Memory Bus) való lecserélése, valamint a 2. generációs IOMMU (IOMMU v2) beépítése jelenti:
- a mindkét irányba 128 bit széles Fusion Control Link ad koherens hozzáférést az IGP-nek a CPU-rész által kezelt memóriához, az I/O-csatornákhoz, továbbá a CPU-nak hozzáférést az IGP-nek dedikált memóriarészhez;
- a mindkét irányba 256 bites Radeon Memory Bus révén közvetlenül kapcsolódik az IGP memóriavezérlője a két 64 bites memóriacsatornához;
- az IOMMU v2 (I/O Memory Management Unit) immár lehetőséget ad arra, hogy a diszkrét kártyák (grafikus kártyák, nagyteljesítményű hálózati kártyák stb.) transzparens módon, a CPU-éval azonos virtuális->fizikai címfordítási mechanizmuson keresztül, de annak közreműködése nélkül érjék el a rendszermemóriát.
[+]
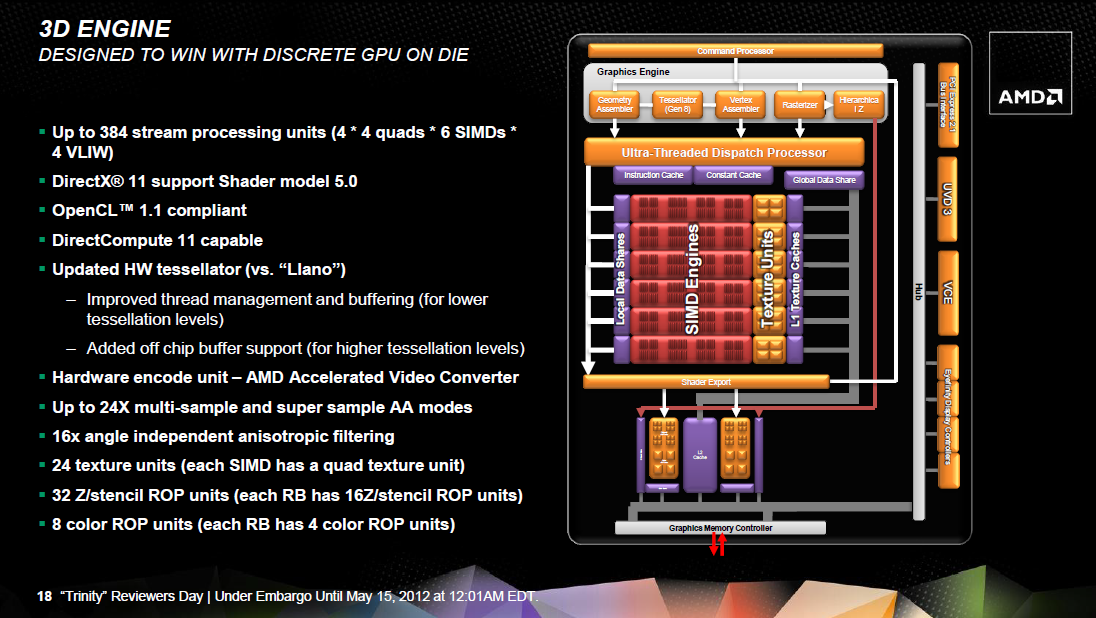
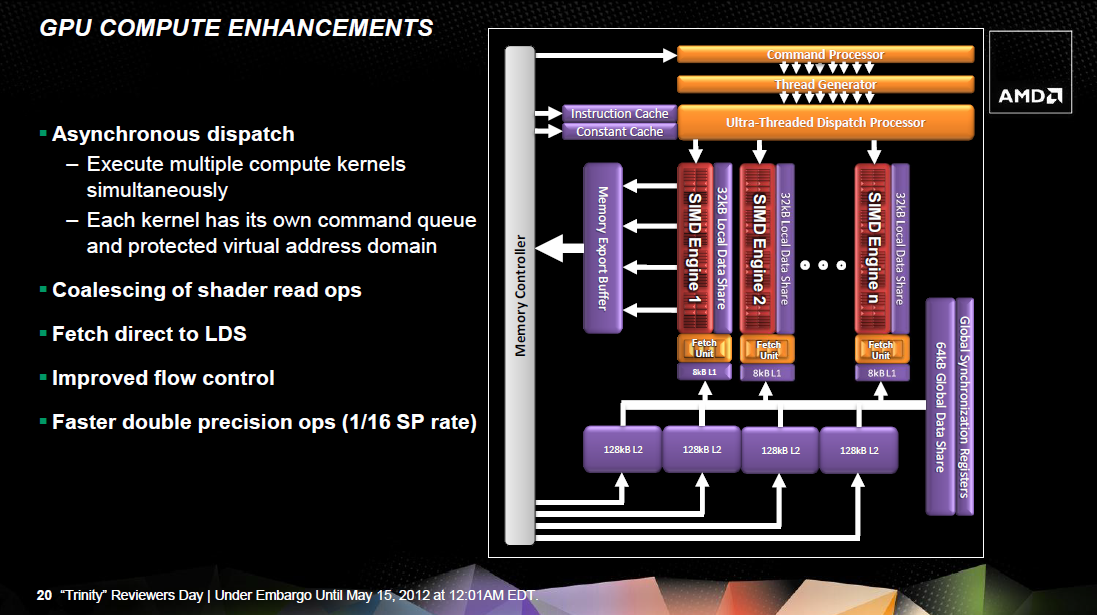
A grafikus mag jelentősnek mondható változáson esett át, mely így tulajdonképpen már a Northern Islands (Cayman – HD 6900) termékcsalád részének tekinthető. A fő különbség a Llano APU IGP-jéhez képest, hogy a szuperskalár shader processzorok úgynevezett VLIW5 felépítését VLIW4-re váltották a mérnökök. Ez összességében jobb kihasználást jelent, illetve a Cayman örökségeként számos értékes technológia is bevetésre került.
Egy shader tömb 16 darab szuperskalár shader processzort rejt, melyhez 32 kB-os Local Data Share, valamint egy 8 kB-os, csak olvasható gyorsítótárral rendelkező textúrázó blokk tartozik. Utóbbi négy darab Gather4-kompatibilis csatornát alkalmaz, melyek csak szűrt mintákkal térnek vissza. Az interpoláció a DirectX 11-es Radeonokhoz hasonlóan emulált, ám a rendszer itt sok optimalizációt kapott, így relatív kevés erőforrás szükséges az interpolálás végrehajtásához. Az új Trinity APU IGP-jében összesen 6 darab shader tömb van, amelyek egy blokkra vannak fűzve. Ez a blokk természetesen egységes Ultra-Threading Dispatch Processzorra támaszkodik. A tömbök közötti adatmegosztást továbbra is egy nagysebességű, 64 kB-os (Global Data Share) tárterület biztosítja.
[+]
Az IGP setup motort is a Caymantől örökölte annak minden előnyével együtt. A tesszellátor az AMD Gen8-as megoldása lesz, míg a raszter motor órajelenként 16 képpontot dolgoz fel. Az igazán értékes újítás azonban a tile-based load balancing, ami a hierarchikus Z algoritmus túlterhelését akadályozza meg. A rendszer a raszterizálást hierarchikus Z nélkül hajtja végre a teljes képkockát több egyenlő méretű, viszonylag kicsi mozaikra osztva. Természetesen itt számos szabályt be kell tartani biztosítva a renderelés sorrendjét. A hierarchikus Z algoritmus a mozaikokon lesz lefuttatva, amelyeket tovább lehet küldeni vagy éppen el lehet dobni, ha nem tartalmaznak látható információt. Ez az elgondolás tesszellálásnál lehet hasznos, mivel a hierarchikus Z motor könnyen túlterhelhető, ami esetenként elég sok problémát jelenthet.

[+]
A memóriavezérlőhöz egy 128 kB kapacitású, csak olvasható másodlagos gyorsítótár és két ROP-blokk kapcsolódik. Ez így összesen 8 blending és 32 Z mintavételező egységet eredményez. Itt a Caymantől megörökölt újítás, hogy a blokkok jelentős fejlődésen mentek keresztül, így a Llano IGP-jéhez képest kétszer gyorsabban végzik a 16 bites unorm és snorm operációkat, valamint a 32 bites lebegőpontos utasítások feldolgozása akár négyszer gyorsabb is lehet. Némi egyenetlenség azért maradt a rendszerben, mivel a raszter motor órajelenként 16 képpontot dolgoz fel, ami sok 8 blending egységhez, de utóbbi inkább legyen túletetve, minthogy adatra várjon.
[+]
A Trinity IGP-je abból a szempontból érdekes a Llano megoldásához viszonyítva, hogy a shader processzorok száma 400-ról 384-re csökkent, miközben a textúrázó csatornák száma 20-ról 24-re nőtt. Alapvetően azonban a változás minden szempontból előnyös, ugyanis a Trinity szuperskalár shader processzorainak felépítése kedvezőbb, mivel hatékonyabban "etethetők". További fontos adalék, hogy a Trinity APU IGP-je az integrált megoldások között elsőként támogat dupla pontosságot. Ebben a módban a rendszer teljesítménye az elméleti számítási tempó tizenhatod részével egyezik meg.
A cikk még nem ért véget, kérlek, lapozz!






