- 3D nyomtatás
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Projektor topic
- Azonnali alaplapos kérdések órája
- Milyen egeret válasszak?
- Fejhallgató erősítő és DAC topik
- AMD Ryzen 9 / 7 / 5 9***(X) "Zen 5" (AM5)
- Két üvegpanel és megdöntött front; itt az APNX V1 névre keresztelt miditornya
- Gaming notebook topik
- Samsung LCD és LED TV-k
Új hozzászólás Aktív témák
-

Louro
őstag
[Személyes vélemény on]
Ez témába nem vág, csak a kérdésre válasz
 :
:
A feladatok el vannak látva. Még plusz is. Többieknek segítek. Megosztom az infót és a társosztályoknak is segítek, amitől az osztály reputációja is nő. A fennmaradó időben próbálom javítani a rendszerünket, spórolni erőforrásokat. Amikor a jelenlegi helyemre kerültem, annyira nem volt kapacitás, hogy folyamatosan jobokkal dolgozott az adatbázisszerver. Volt, ami több, mint 3 órát futott. Kis átírással 10 perc alatt lefutott. (Több nagy tábla összekötve egy lekérdezésben, indexek nélkül. Ezeket szedtem szét több kisebb lépésre.)A fejeseknek az a fontos, hogy az ő felettük állók igényei ki legyenek szolgálva és persze mindenki fel akar valamit mutatni, de azzal nem foglalkozik, hogy a meglévő rendszerrel faragjon, mert túl kocka terület. Sajnos ilyennek miatt olyanok a nagyobb cégek rendszerei, amilyenek. Szívás minden fejlesztés.
[Személyes vélemény off]
[ Szerkesztve ]
Mess with the best / Die like the rest
-

formupest
újonc
Szia Louro,
köszönöm a választ. Gyakorlatilag részben eltaláltad ,hogy mi a feladat és tetszik nagyon a javaslatod. Kicsit bonyolultabb a dolog, mert gyógyszertípusonként más és más tulajdonságokat kell megadni, de vannak olyan tulajdonságok is amelyek minden vagy legalábbis több gyógyszertípusnál szerepelnek. Így például a sűrűség minden készítménynél fontos paraméter, míg például az emulzióstabilitás csak bizonyos esetekben mérhető stb. Ezért mondtam azt, hogy annyi tulajdonságtábla van ahány gyógyszertípus. Holnap este összerakok egy DEMO-t , azaz táblázatokat adatokkal együtt.
üdv -

Szmeby
tag
Oké, azt hiszem nem jól fogalmaztam. Ígérem, ez az utolsó off.
Az, hogy az optimalizálatlan lekérdezések miatt lassú a szolgáltatás, gondolom kimeríti a fejesek felett állók igényeinek kielégítését. Az, hogy nincs elég kapacitás tesztelni, optimalizálni, backupot készíteni ínségesebb időkre, ésatöbbi, mind mind a szolgáltatás színvonalát befolyásolja. Ha az ún. fejes (vagy a felette álló) azt hiszi, hogy nem, akkor vagy hülye vagy igénytelen. Szerény véleményem szerint.
Azzal takarózni, hogy valami túl kocka, ezt nem tudom hova tenni. Ha valami kocka, akkor nincs köze a szolgáltatás színvonalához? Az igényességhez? Ha fejesnek ez túl kocka, akkor miért használ számítógépet? Dolgozzon kockás füzetben, és szolgáltasson abból! Vagy ha az is túl kocka, akkor vonalas füzetből.Bocsánat a kirohanásomért, csak pont ebből lett elegem az IT szférában, és érzékenyen tudok reagálni a hasonló hozzáállásra. Kiborító, amikor azt hallom egy menedzsertől, hogy csak dobj össze valamit, csak működjön; menjen élesbe, mindjárt határidő; ezeknek így is jó lesz, és hasonló szóvirágok. Többnyire ugyanez a menedzser kongatja a vészharagot, hogy nagy baj van a projekten, több erőforrást kell bevonni; azonnali tűzoltásra van szükség; lehalt az éles szerver, mindenki hétvégézik; ha ez ma nem lesz kész, holnap már nem kell bejönnöd; ha ezt megcsinálod még ma, holnap kapsz egy sütit. A fejlesztő meg nyilván megtörik, és inkább hekkel, drótoz, gányol. Mert azt jutalmazzák, aki vilámgyorsan összedob valamit, aki tüzet olt, még ha a saját gányolását is javítja valójában. Ahogy te is mondtad, fontosabb a jó munkánál a "mindenki fel akar valamit mutatni". És aztán eljön az a pont, amikor többségbe kerülnek a valamit felmutatni akaró egyedek a jó terméket gyártó egyedekel szemben. Csodálkozunk, ha kiég az ember?
Csak arra akartam célozni, hogy így látatlanban szerintem a te igényeid nincsenek összhangban a fejesek igényeivel, ami hosszú távon eléggé lélekölő. Persze ha neked (még) tetszik, akkor folytasd nyugodtan. Minden tiszteletem a tiéd, én már eljutottam arra a pontra, hogy az általad lefestett fejeseket nem akarom elviselni.
Mindenesetre sok sikert kívánok és bocs, hogy elkanyarodtam a témától. Ahhoz nem tudok hozzászólni.
[ Szerkesztve ]
-
#4504
 Apollo17hu
őstag
Szmeby
#4503
Apollo17hu
őstag
Szmeby
#4503
Apollo17hu
őstag
Bocs, hogy beleszólok, de Lourohoz hasonló munkakörben dolgoztam, és csak megerősíteni tudom:
- High-level menedzsernek nem fogod tudni elmagyarázni. Nem érdeklik a részletek ilyen mélységben, és nem is akarja megérteni, mert nincs ideje rá. A közvetlen vezetődnek mondhatod, de ő nagyon jól tudja, hogy a nála nagyobb emberek az ilyesmit egyszerűen lesöprik az asztalról. Csak az eredmény számít.
- A másik dolog pedig az, hogy felsőbb szinten a vezetők hajlamosak (sőt, néha kötelező az előmenetel miatt) rotálni szervezeten belül. Tehát, ha 3-5 évig működik a toldozás-foldozás, akkor nyert ügye van, mert úgyis dobbant máshova....és ennek analógiájára: az a fejlesztő balek, aki próbál prudensen, hosszú távban gondolkodva végezni a dolgát. Ahhoz képest mindenképp, aki összehányja a munkát, de feleannyi idő alatt eredményt mutat fel, és 2-3 évente munkahelyet vált (aminek következményeként nem kell saját maga után takarítani).
-

Petya25
őstag
MS SQL-ben valami ötlet erre? Azonosító+dátum és adat sorok követik egymást.
Többszáz megás textben van de így tagolva be tudom tenni egy táblába.
A következő azonosítóig tartanak a hozzá tartozó adatok.
Full változó az adadatsorok száma egy blokkon belül.
Na ebből kellene egy select azonosító, dátum, mező1....5 végül.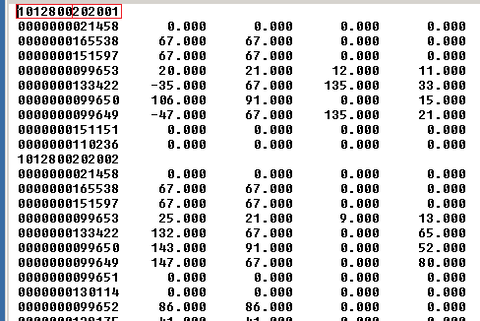
[ Szerkesztve ]
Antonio Coimbra de la Coronilla y Azevedo, bizony!
-
#4511
Petya25
őstag
Apollo17hu
#4510
Petya25
őstag
válasz
 Apollo17hu
#4510
üzenetére
Apollo17hu
#4510
üzenetére
Nem a mezőket nehéz megtalálnom, hanem azt hogy hol kezdődik a következő adatcsoport.
Antonio Coimbra de la Coronilla y Azevedo, bizony!
-
Petya25
őstag
Igen ez is megoldható valami külső eszközzel.
Eredetileg egy rakás kis egyedi fájlneves fájlban figyelnek ezek az adatok, csak össze lett mergelve. Visual studióban megnézem hátha tudok valamit alkotni, a fájokat egyesével fel tudom dolgozni, de tömegesen automatikusa nem, legalábbis most.Antonio Coimbra de la Coronilla y Azevedo, bizony!
-

bambano
titán
válasz
 Petya25
#4509
üzenetére
Petya25
#4509
üzenetére
nem ismerem az mssql-t, postgresql-ben így csinálnám:
csinálnék egy táblát, amiben van egy id mező, aminek serial (más adatbáziskezelőkben autoincrement), meg van benne egy másik id2 mező, aminek a defaultja egy serial aktuális értéke, van egy text mező, meg négy real.
tennék rá egy szabályt, hogyha mind a négy real mezője null, akkor a második mezőt növelje egyel és úgy húzza be a többi sort.szerk: persze a triviális megoldás az, ha awk-val insert-té alakítod a fájlokat.
szerk2: esetleg dobj fel valahova 3-4 ilyen kis fájlt, amivel kísérletezni lehet.
[ Szerkesztve ]
Egy átlagos héten négy hétfő és egy péntek van (C) Diabolis
-

sztanozs
veterán
válasz
Petya25
#4509
üzenetére
Szerintem SSIS-szel be lehet dolgozni ezeket a fájlokat kis c#-ozással (vagy akár valami natív SSIS módon is - most nincs fent a gépemen SSIS Studio, de korábban csináltunk ilyeneket).
Mod: [link]
[ Szerkesztve ]
JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...
-
bambano
titán
válasz
Petya25
#4509
üzenetére
a probléma pár órás tojtorozása után nekem úgy tűnik, hogy a legegyszerűbb megoldás a következő:
csinálsz egy táblát, olyan szerkezettel, ami neked tetszik, plusz hozzáadsz egy oszlopot, pl. sor néve, text típussal:tmp=> \d merestmpTable "public.merestmp"Column | Type | Collation | Nullable | Default--------+------------------+-----------+----------+--------------------------------------id | bigint | | not null | nextval('merestmp_id_seq'::regclass)subid | bigint | | |azon | text | | |meres1 | double precision | | |meres2 | double precision | | |meres3 | double precision | | |meres4 | double precision | | |sor | text | | |utána belemásolod az input fájljaidat úgy, hogy a szövegből minden sort egyben tegyen bele a sor mezőbe:
\copy merestmp(sor) from '/tmp/mteszt.txt';Majd adatbáziskezelős függvényekkel szétszeded a sorokat.
update merestmp set subid=id,azon=trim(both from sor) where array_length(regexp_split_to_array(sor,' +'),1)=1;ezek után a subid-t beállítod az előtte levő sorra:
update merestmp m1 set subid=(select max(subid) from merestmp m2 where m2.id<m1.id) where array_length(regexp_split_to_array(sor,' +'),1)=5;
ennél a megoldásnál nyilván van szebb is, windowing funkciókkal...
utána már csak regexp-ekkel ki kell szedni a mezőket a sorból és betenni a helyükre.Egy átlagos héten négy hétfő és egy péntek van (C) Diabolis
-

cekkk
veterán
Sziasztok!
Egy elég alap lekérdezést szeretnék csinálni. Ma kaptunk a cégnél egy hibakezelő rendszer ahol egyben van az összes lezárt hiba.
status=resolved ezzel megkapom a megoldott hibákat de a "Dealer name" oszlopból ki akarom választani az én kódomat és csak azokat akarom látni amikhozzám tartozik akkor ezt a kódot hogyan folytassam? Dealer name=kód ? Közel 10 éve nem foglalkozta sql lekérdezéssel.
Azt még nem írtam le, hogy JQL.
Köszi a segítséget![ Szerkesztve ]
-
ha ez JIRA, akkor ő felismeri a felhasználónevet, ahogy beírod, és segít. de van egy CurrentUser() nevű függvény is, ezzel a Dealer name = CurrentUser() is működik.
Tudod, mit jelent az, hogy nemezis? Az érintett, erősebb fél kinyilatkoztatása a méltó büntetés mértékét illetően. Az érintett fél jelen esetben egy szadista állat... én.
-
cekkk
veterán
válasz
 velizare
#4519
üzenetére
velizare
#4519
üzenetére
Szia!
Az az. Köszönöm.
Ezt a kódot írtam be, hogy : status = resolved AND assignee = currentUser() viszont így pl nincs benne a tegnapi lezárt hiba, csak a mai. Nem teljesen értem még a működését.
Ha pl a címet akarok lekérdezni, hogy adress szolnok akkor azt, hogyan adjam meg neki?[ Szerkesztve ]
-
akkor a tegnapi lezárt hibának nem resolved a státusza, hanem mondjuk closed. ezeket halmozni is tudod pl így.: status in ('Resolved', 'Closed');
vagy nem te vagy az assignee.
AND address = 'Szolnok'.[ Szerkesztve ]
Tudod, mit jelent az, hogy nemezis? Az érintett, erősebb fél kinyilatkoztatása a méltó büntetés mértékét illetően. Az érintett fél jelen esetben egy szadista állat... én.
-

Ispy
veterán
Használ valaki itt mssql-hez schema compare toolt?
Átraktuk az adatbázist a .net source controlba, és a módosításokat az sql schema comparrel töltjük vissza, de iszonyat lassú, és nem igazán találok rá megoldást. Pedig remek eszköz lenne, ha normálisan lehetne használni, de egy pár tábla módosítás visszaírása is 25 percig fut, ami hát nem túl hatékony. De egy check/unchek is el tud futni percekig...
"Debugging is like being the detective in a crime movie where you're also the murderer."
-
-
Egy lekérdezésben kérném segítségeteket.
Hogyan tudom megírni úgy a lekérdezést, hogy válasszak két rekord közül.
Van egy árlista tábla. Elég hülyén van kitöltve, de ez most mindegy.
Van egy árnak kezdő érvényességi dátuma, ez kötelező, és lehet befejező dátuma, ez nem kötelező. Az indexelés úgy van belőve, hogy lehet olyan rekord, hogy azonos a kezdő dátum, azonos lehet az ár is, de nem feltétlenül, de az egyiknél van záró dátum, másiknál nincs. Na, ha ilyen duplikációk vannak, akkor azt kell vennem, ahol van záró dátum, ha nincs duplikáció, akkor jó a záró dátum nélküli is. Soha nem láttam még ennyire hülye megoldást, de ezzel kell élni.[ Szerkesztve ]
Declare var, not war. - Alcohol & calculus don't mix. Never drink & derive.
-
-
#4530
Apollo17hu
őstag
Jim Tonic
#4527
Apollo17hu
őstag
-

#14069248
törölt tag
Sziasztok!
2010-ben kiszedtem az internetről a Dupal honlapomat. Azóta a gépemen működik. (Jelenleg 20.04-es Xubuntut használok.) Múlt évben még ránéztem, de mára elfelejtettem az Admin jelszót. A kérdésem az lenne, hogy a Mysql adatbázis alatt az sql fájlból ki tudom szedni valahogyan? Előre is köszönöm a segítséget!
[ Szerkesztve ]
-
#68216320
törölt tag
Urak. Van a MySQL 8-nak valami memória kímélő konfigurációja kis terhelésű haszálathoz? Programozás tanuláshoz kellene feltenni, de jó lenne minél kevesebb erőforrást, ez esetben memóriát adni neki.
Valami developing ini található esetleg hozzá valahol? -
-

martonx
veterán
válasz
 #68216320
#4537
üzenetére
#68216320
#4537
üzenetére
Egyébként MySql-nek (meg amúgy bármelyik SQL-nek) tök jól lehet paraméterezni a memória foglalását. Emlékeim szerint a MySql defaultban nagyon is visszafogottan foglal memóriát (rendszergazdák első MySql optimalizációja szokott lenni, átírni a memória foglalást valami egészségesebbre).
Szóval szerintem tedd fel nyugodtan.Én kérek elnézést!
-

nyunyu
félisten
válasz
 martonx
#4538
üzenetére
martonx
#4538
üzenetére
Egyébként MySql-nek (meg amúgy bármelyik SQL-nek) tök jól lehet paraméterezni a memória foglalását.
A teljesítmény rovására.
Nézz meg egy ingyenes, egy procimag+1GB RAMra limitált MS SQL licenszet, meg a rendes verzióját.
DB tipikusan olyan alkalmazási terület, ahol a több RAM mindig jobb.
Persze ha van három táblád, 10-10 sorral, akkor az 1GB is elég lehet, de párezer soros táblák joinolgatásánál már észreveszed a különbséget.
Hello IT! Have you tried turning it off and on again?
-
-
#68216320
törölt tag
válasz
martonx
#4540
üzenetére
Természetesen, otthon használatra megy, tanulásra - hobby célokra. Vagyis kb. zéró terhelés, max 1-2 user egyidejű kiszolgálása lesz. Eddig max 3000-es táblám volt a legnagyobb (retro számítógép program kategorizálásnál). De ez sem jellemző.
Szóval tényleg nem kell sok. Viszont most felhőbe menne majd cucc és jelenleg 1GB RAM-ot bérelek, szeretném, ha ennyi is maradnaDesktop gépen (win10) sikerült még az 5.7-est leszorítanom alapjáratban 30MB körüli értékre. [kép]
A 8-ast is megpróbálom valamennyire visszavenni (win10 / linux), de majd kiderül hogy sikerült.[ Szerkesztve ]
-
válasz
 bambano
#4529
üzenetére
bambano
#4529
üzenetére
Köszi mindenkinek, sikerült megoldanom. Még egy gyors kérdés:
Ha kombinálnom kell min és max értékeket (max(valid_from) és min(valid_to)) akkor az csak dupla select-tel megy, ugye? Mármint azzal megoldom, csak nem tudom, van-e egyszerűbb megoldás.[ Szerkesztve ]
Declare var, not war. - Alcohol & calculus don't mix. Never drink & derive.
-
-
válasz
bambano
#4544
üzenetére
Ki kell szednem a valid_from értékekből a legmagasabbat, ami kisebb vagy egyenlő, mint az aktuális dátum, majd ezek közül a legkisebb valid_to, ami nagyobb vagy egyenlő, mi ma. Ezt nekem nem szedte össze az sql server (tsql) egy select-ben.
Most ezt a rank() függvényt nézegettem.
[ Szerkesztve ]
Declare var, not war. - Alcohol & calculus don't mix. Never drink & derive.
-
nyunyu
félisten
válasz
 Jim Tonic
#4545
üzenetére
Jim Tonic
#4545
üzenetére
Ezeket egy selectben nem tudod összeszedni, mivel az oszlopfüggvények egymástól függetlenül értékelődnek ki.
Tehát nem max(valid_from)-hoz tartozó min(valid_to) értéket kapod vissza, hanem a globálisat.Maximum azt tudod tenni, hogy egy belső selectben leválogatod a max(valid_from)-okat minden termékhez, majd az a köré írt másik selectben kiveszed a min(valid_to)-t.
Valahogy így:
select product,
price
from products p
join (select
p1.product,
a.max_valid_from,
min(nvl(p1.valid_to, to_date('9999-12-31'))) min_valid_to
from products p1
join (select p2.product,
max(nvl(p2.valid_from, to_date('0000-01-01'))) max_valid_to
from products p2
group by p2.product) a
on a.product = p1.product
and a.max_valid_from = p1.valid_from
group by p1.product, a.max_valid_from) b
on b.product = p.product
and b.max_valid_from = nvl(p.valid_from, to_date('0000-01-01'))
and b.min_valid_to = nvl(p.valid_to, to_date('9999-12-31'));Oszlopfüggvények alapból figyelmen kívül hagyják a nullokat!
[ Szerkesztve ]
Hello IT! Have you tried turning it off and on again?
-
Igen, ezt értettem dupla select-en. Jelenleg hasonlóan írtam meg, de ez a rank() felkeltette az érdeklődésem. De ez csak tsql, asszem.
szerk.: Apollo row_number() függvénye alapján jutottam el a rank()-hez. Köszönöm.[ Szerkesztve ]
Declare var, not war. - Alcohol & calculus don't mix. Never drink & derive.
-
nyunyu
félisten
válasz
Jim Tonic
#4548
üzenetére
Ja tényleg, ablakozó függvényekkel lehet, hogy egyszerűbb, mivel ott összetett rendezést is tudsz alkalmazni:
select
p.product,
p.price
from products p
join (select
p1.product,
nvl(p2.valid_from, to_date('0000-01-01')) valid_from,
nvl(p1.valid_to, to_date('9999-12-31')) valid_to,
row_number() over (partition by p1.product
order by nvl(p2.valid_from, to_date('0000-01-01')) desc,
nvl(p1.valid_to, to_date('9999-12-31')) asc) rn
from products p1) b
on b.product = p.product
and b.valid_from = nvl(p.valid_from, to_date('0000-01-01'))
and b.valid_to = nvl(p.valid_to, to_date('9999-12-31'))
and b.rn = 1;Ezzel sorszámozod az egy termék rekordjait kezdő dátum szerint csökkenő és azon belül érvényességi dátum szerint növekvő sorrendben, majd veszed a legelső rekordot minden termékhez.
[ Szerkesztve ]
Hello IT! Have you tried turning it off and on again?
-

user112
senior tag
Sziasztok!
Egy táblából összesített adatokat szedek le, de lenne köztük pár egyedi feltételnek megfelelő adat is: pl: select id, sum(adat1), sum(adat2),adat3, adat4 ahol adat3 csak pl a ho=2 adatsor értéke legyen, az adat4 pedig a ho=9-é.
Hogyan tudom ezt megcsinálni? Belső select? Szeretném egy sorban megjeleníteni. Oracle
Köszönöm.


 :
:






























Új hozzászólás Aktív témák
Hirdetés

- Lenovo / Dell / HP laptop, notebook töltő, adapter OUTLET
- 4K Core I5 12400F GamerRPC 6X4.0GHz 32Gb DDR4 3200MHZ 512 SSD RTX 3060 12GB DDR6 2 Év Gari
- 27GR95QE-B OLED Törött Monitor eladó Minden gyári tartozékával gyári dobozában
- OLED55A16LA Törött alkatrésznek eladó
- Filament tároló doboz páratartalom-mérővel
Állásajánlatok

Cég: HC Pointer Kft.
Város: Pécs

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest