Erőltetett menet
2009 és 2011 között, azaz több mint 2 évig az AMD nem örvendeztette meg a közönséget új mikroarchitektúrával. Ehhez minden bizonnyal hozzájárult az előző oldalon már taglalt csúszások nagy része is, ergo nyilvánvalóan nem egy tervezett hatásszünetről volt szó. Ezzel szemben a grafikus processzorok oldalán az AMD szekere szinte töretlenül robogott az elmúlt időben, amivel sikerült évente felmutatni egy új, számottevő fejlődést hozó GPU-t vagy GPU-családot. Általánosságban elmondható, hogy a grafikus megoldások fejlődése valamivel gyorsabb, mint az x86-os mikroarchitektúráké, amivel evidens módon a gyártók is tisztában vannak.

[+]
Az AMD ennek megfelelően 2009-es Analyst Day nevű rendezvényén elhintette, hogy a Llano debütálását követően minden évben egy megújult grafikus maggal rendelkező APU-t fognak bemutatni.

[+]
Ezzel párhuzamosan a CPU-magok fejlesztésének területén is megpróbált tempót váltani a vállalat. Ennek eredményeképpen – a GPU-k ütemtervéhez hasonló stratégia keretein belül – minden éveben egy frissített x86-os mirkoarchitektúrát szándékozik az újabb APU-kba beültetni az AMD.

[+]
Emellett a cég egyik hosszútávú, igen magas prioritást élvező célja, hogy a CPU és a GPU szekciókat minél inkább összefonja, és közelebb tolja egymáshoz. Erre vonatkozóan már a Llanóban is láthattunk apró csírákat. Egy ilyen volt például az közvetlen buszrendszer, mely a CPU és a GPU kommunikációját hivatott egyszerűsíteni, ezzel együtt meggyorsítani. A folyamat ezen része (is) viszonylag lassan fog végbemenni, hisz meglehetősen bonyolult fejlesztésekről van szó, amelyeknél figyelembe kell venni a piaci igényeket is. X86-os oldalról bizonyos formában már a Bulldozer is ennek a hosszútávú folyamatnak lett alárendelve, vagy ha úgy tetszik, beáldozva, ugyanis már egy jó ideje köztudott, hogy az AMD az integrációnak rendeli alá fejlesztéseit, ezzel szinte egy lapra téve fel mindent.

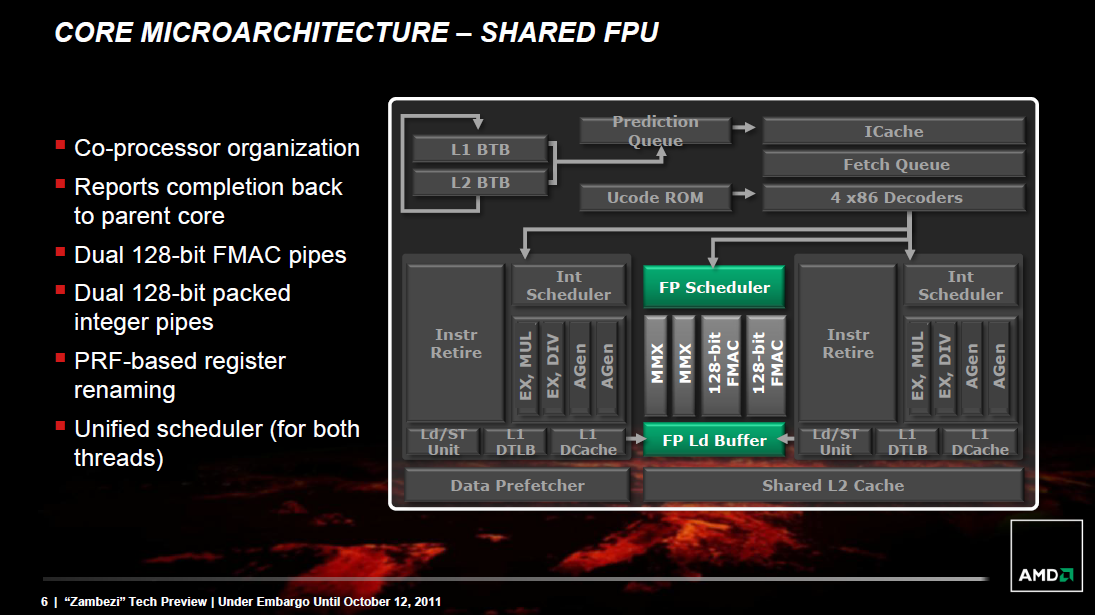
[+]
Az AMD által lefektetett és propagált, HSA nevű virtuális utasításarchitektúra például legfeljebb 128 bites vektorokon tud SIMD-műveleteket végrehajtani, ehhez pont megfelelnek a Bulldozerben található Flex FP 128 bites egységei, azaz a 256 bites végrehajtók kihasználatlanok maradnának. A következő év/évek megoldásaiban helyet kapó grafikus végrehajtók írható-olvasható L1 adatcache-ei write-through irányelvet követő, 16 kB méretű, 4-utas csoportasszociatív gyorsítótárak csakúgy, mint a Bulldozer magokéi, azaz minden memóriaírás azonnal megjelenik a GPU- vagy a CPU-modul saját L2 cache-ében is. A rendszerszintű cache-koherencia megvalósításához elég tehát ezeket az L2-ket összekötni. Az újabb utasításkészletek beköltözésével a CPU-magok immár ugyanúgy támogatják a különböző bonyolult bitmanipulációs műveleteket, mint a grafikus magok skalár egységei.
Problémás szülők gyermeke
Az Intel, az NVIDIA, valamint még számtalan nagyvállalat úgynevezett útiterv (roadmap) alapján dolgozik; természetesen ezalól az AMD sem képez kivételt. Ez jó esetben azt jelenti, hogy az éppen forgalomban lévő terméket követő második generáció is mindig már bőven a kivitelezési fázisban van. Az AMD Trinity kódnévre hallgató fejlesztéséről például már lassan 2 éve hivatalosan is értesülhetett a nagyközönség, holott akkor még a Llano sem jelent meg. Természetesen az útitervek változhatnak, aminek számos oka lehet. A lenti képen látható 2012-es fejlesztések közül például csak jelen cikkünk főszereplője látta meg a napvilágot, ugyanis a Komodo, valamint a Krishna nevű fejlesztéseket bizonyos okokból kifolyólag végül más termékekre cserélt fel az AMD.
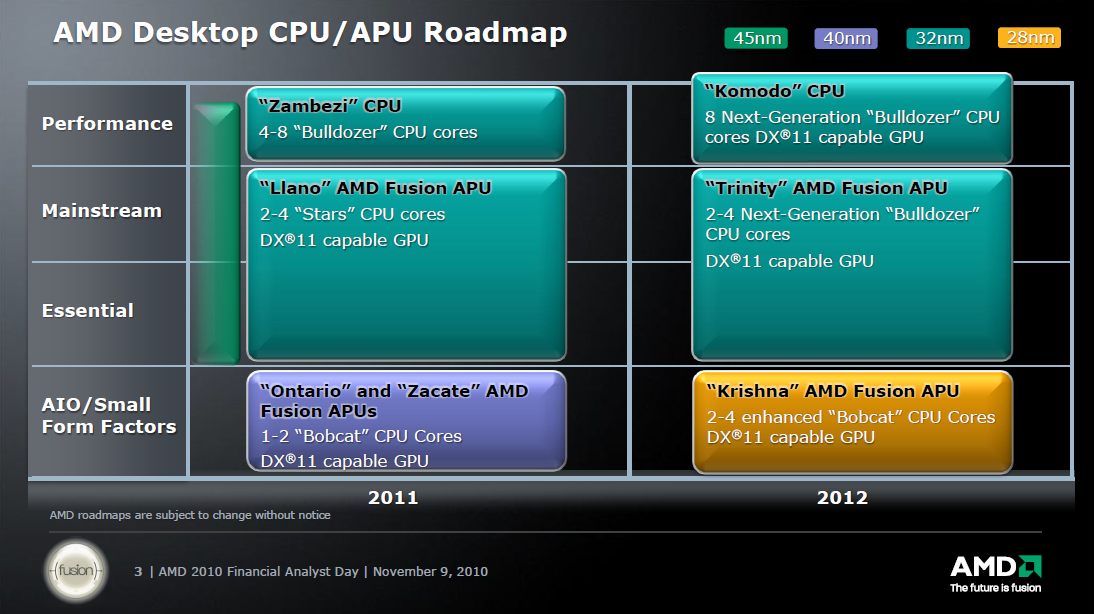
[+]
Azt már tudjuk, hogy mind a Llano, mind pedig a Bulldozer meglehetősen nehéz szülésnek számított az AMD életében. Ebből eredően néhányan kissé szkeptikusan álltak a Trinity kódnevű fejlesztéshez, mely épp a két koncepciót hivatott egyesíteni. A Bulldozerről tudjuk, hogy felépítése radikálisan eltér mind elődeiétől, mind pedig versenytársaiétól, nagyrészt azért, mert már a kezdetektől fogva magas órajeleket szántak hozzá. Ezt a GlobalFoundries 32 nanométeres HKMG SOI gyártástechnológiájának problémái miatt nem sikerült elérnie az AMD-nek, így az arra épülő termékek alulmúlták az előzetes elvárásokat. A szintén ezen gyártósorokról legördülő Llanóval mindeközben folyamatos kihozatali problémákba botlottak a mérnökök, így a vállalat utóbbi fejlesztéssel is rendesen megszenvedett. Mindezen nehézségek ellenére idén májusban a mobil szegmensben debütálhatott a Trinity kódnevű lapka, mely a cikkünk elején említett Falcon alapötletét viszi tovább a Bulldozer és a Llano alapjain.
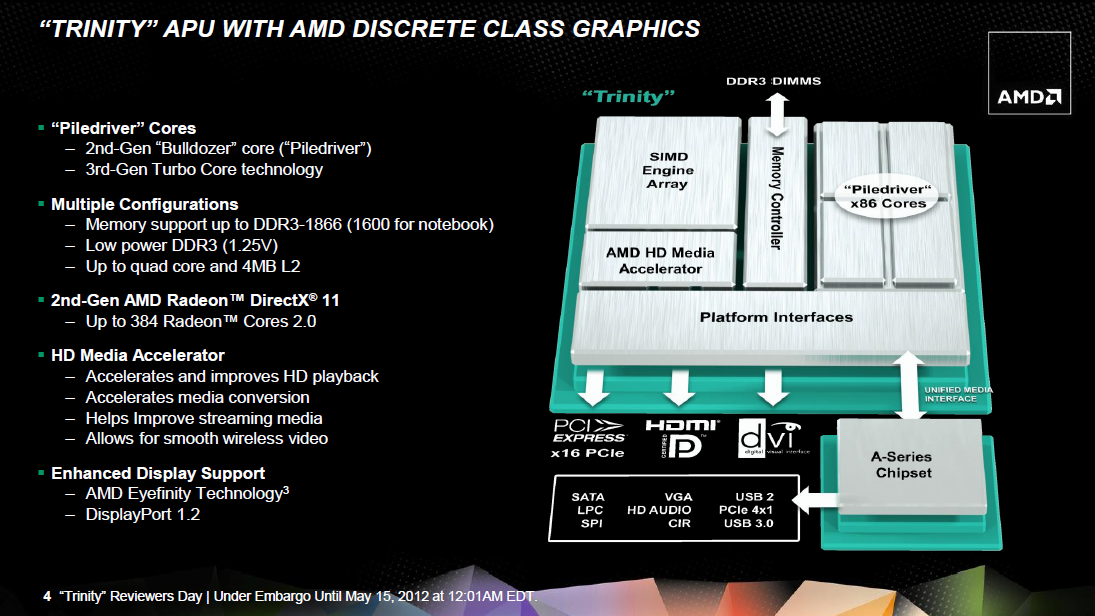
[+]
A különféle gyártástechnológiai problémák nagy részén időközben sikerült úrrá lenni, így a Trinity – a Llanóhoz és a Bulldozerhez hasonlóan – a GlobalFoundries 32 nanométeres HKMG SOI gyártósorain készül. A lapka alapvető felépítése meglehetősen hasonló a Llano esetében látottakhoz. A legnagyobb változás az x86-ps CPU magokat, valamint az integrált grafikus processzort érinti. A négy korábbi, Husky kódnevű, K12-es magot két Piledriver modulra cserélték a tervezők. A két számítási egység mérete szinte pontosan megegyezik a korábbi négy magéval, ráadásul a teljes L2 cache mérete sem változott, azaz maradt 4 MB. A memóriavezérlőt különösebben nem babrálta az AMD, így ez továbbra is 128 bites, és hivatalosan maximum a DDR3-1866 szabványú modulokat támogatja. Az új grafikus szekció immáron a Northern Islands család sarja, de ezt kicsit később taglaljuk. Az UVD motor – újabb híján – a Llanónál már látott, 3-as verziót vonultatja fel. Ezen felül az integrált PCI Express vezérlőt sem érte különösebb módosítás, az egység továbbra is a 2.0-s szabvány szerint dolgozik, így a 3.0 debütálása az AMD-nél csak a jövő évben lesz esedékes.

[+]
A kontroller továbbra is összesen 24 sávból áll, melyből négy darab képezi az úgynevezett UMI (Universal Media Interface) szekciót, amely ebben az esetben a korábban alkalmazott HyperTransport szerepét vette át. Feladata az alaplapi egyetlen vezérlőhíd, vagy más néven FCH (Fusion Controller Hub, erről később) APU-val való összekapcsolása. A négy PCIe 2.0 szabványú sávnak köszönhetően itt 2 GB/s a kapcsolat sávszélessége. Egy másik csokor összesen 16 sávot tartalmaz, és ez elsősorban az esetleges diszkrét grafikus kártya (vagy kártyák) összeköttetéséhez van fenntartva. Ezeket két külön slotra felosztva, x8-x8 konfigurációban akár CrossFire rendszer is kiépíthető. A maradék négy sáv felhasználása már teljesen a gyártókra van bízva, ezekre ültethetnek különféle hálózati, SATA vagy akár USB vezérlőket is, illetve még alaplapi PCIe aljzatok formájában a vásárlókra is bízhatják opcionális kihasználásukat.

[+]
Mindezen változtatásokkal a Llanóhoz képest nagyjából 8%-kal nőtt a lapka mérete, ami 246 mm2-es területet jelent. Ezzel párhuzamosan a tranzisztorszám 1,178-ról 1,303 milliárdra duzzadt.
| Lapka kódneve | Gyártástechnológia | Magok száma | L2 (+ L3) mérete | Tranzisztorszám | Lapka területe |
| Trinity | 32 nm HKMG SOI | 4 (+ IGP) | 4 MB | 1,303 milliárd | 246 mm2 |
|---|---|---|---|---|---|
| Llano | 32 nm HKMG SOI | 4 (+ IGP) | 4 MB | 1,178 milliárd | 228 mm2 |
| Orochi (Bulldozer) | 32 nm HKMG SOI | 8 (4 modul) | 16 MB | ~1,2 milliárd | 315 mm2 |
| Thuban | 45 nm SOI | 6 | 9 MB | 904 millió | 346 mm2 |
| Deneb | 45 nm SOI | 4 | 8 MB | 758 millió | 258 mm2 |
| Ivy Bridge | 22 nm Tri-Gate | 4 (+ IGP) | 9 MB | 1,48 milliárd | 160 mm2 |
| Sandy Bridge | 32 nm HKMG | 4 (+ IGP) | 9 MB | 995 millió | 216 mm2 |
| Sandy Bridge-E | 32 nm HKMG | 6 | 16,5 MB | 2,27 milliárd | 435 mm2 |
| Gulftown | 32 nm HKMG | 6 | 13,5 MB | 1,17 milliárd | 240 mm2 |
| Lynnfield | 45 nm HKMG | 4 | 9 MB | 774 millió | 296 mm2 |
| Bloomfield | 45 nm HKMG | 4 | 9 MB | 731 millió | 263 mm2 |

A Llano és a Trinity méretarányos belső felépítése [+]
A cikk még nem ért véget, kérlek, lapozz!






