

Gyártástechnológia és a lapka
A Llano után a Bulldozer az AMD második, immáron tömeggyártásban is létező, 32 nanométeres csíkszélességen készülő processzora. A lapkák a GlobalFoundries drezdai üzemében készülnek, egy meglehetősen öszvér technológia keretein belül. Ez alkalmazza az AMD által már az első Athlon 64-ek és Opteronok (2003) óta gyakorlatilag folyamatosan alkalmazott SOI (Silicon-On-Insulator, szilícium a szigetelőn) technológiát, melyet – az Intel által még 45 nm-en bevezetett megoldásához hasonló, de itt gate-first megvalósításon alapuló – HKMG (High-K Metal Gate, magas k együtthatós fémkapu tranzisztor) technológia egészít ki.

A fejlesztési munkálatok kezdete 2006 végére tehető, amikor az AMD még házon belül gyártotta saját processzorait. Ezen, 32 nm-es technológia kifejlesztése is az IBM-mel közösen történt, itt az egyik legfontosabb újítás a 45 nanométerhez képest a már említett HKMG alkalmazása volt.

Ennek lényege, hogy a kapuelektródát polikristályos szilícium helyett fémes anyagokból készítik, míg a kapuoxid szilícium-dioxid rétegét egy magas k állandójú dielektrikum váltja fel. A megoldással jelentősen csökkenthető a szivárgási áram, emellett kisebb energiaigényű, gyorsabb kapcsolási sebességű integrált áramkörök alakíthatók ki, összességében tehát jelentős mértékben javulhat a teljesítmény/fogyasztás arány.

Az IBM eredeti elgondolásával szemben az Intel már a kezdet óta az úgynevezett gate-last megoldást alkalmazza. A hagyományos sorrend szerint a kapuelektródák kerülnek elsőként a szilícium hordozóra, ami egyszersmind megkönnyíti a source és drain elektródák végleges kialakítását is (self-alignment). A kapu fém anyagának viszont megvan az a kedvezőtlen tulajdonsága, hogy nem áll ellen a gyártás során alkalmazott magas hőmérsékletnek, ezért az Intel a kapu kialakítását hagyja utoljára.

Ezt a gate-first esetében bizonyos új anyagok bevetésével küszöbölték ki, ami kibírja az extrém magas hőmérsékleti értékeket, valamint kompatibilis az alkalmazott feszítési technikával. Mindez egyszerűbbé és olcsóbbá tette az új technológia bevezetését, mivel a gyártási folyamat nagyon hasonló a korábbi SiON/poly-Si megvalósításhoz. A gate-first eljárás segítségével 15-20%-kal kisebb chipek hozhatók létre a konkurens vállalatok technológiához viszonyítva, feltételezve az azonos tranzisztorszámot.

Ezek mellett az úgynevezett immerziós litográfia alapú levilágítás alkalmazása is megmaradt a szilíciumostyák feldolgozása során, a kritikus áramkörök precízebb megrajzolása érdekében. A hagyományosnak nevezhető fotolitográfiai eljárás esetében a fényforrás (ultraibolya fénysugarak) rávilágít egy maszkra (ami az adott szilíciumréteg áramköri struktúráit tartalmazza), majd miután a fény átszűrődik rajta, kialakítja az áramköröket a szilíciumostyán (ez elméletileg 50 nm-ig jól működik). Az immerziós litográfiai eljárás annyiban más, hogy egy nagy tisztaságú folyadékréteget állítanak a fényforrás és a wafer közé, a folyadékréteg pedig könnyebben fókuszálhatóvá teszi a fénysugarat, azaz nagyobb felbontású leképezést tesz lehetővé.

Az imént dióhéjban taglalt, 32 nm-es gyártástechnológiával készült, Bulldozer architektúrára épülő Orochi lapka a SiGe feszítési technika alkalmazása mellett összesen 11 fémrétegből épül fel. A már említett, négy különálló, egyenként 2 MB-os szekcióból felépülő L3 cache részletesebb tulajdonságit a következő két rajzról lehet leolvasni.


Egyetlen Bulldozer modul az L2 cache-sel együtt 30,9 mm2 területű, mely így 213 millió tranzisztort foglal magába. Összehasonlítás gyanánt a következő ábrán három, egyaránt 32 nm-es csíkszélességen készülő, eltérő dizájn méreteit láthatjuk, legfelül a Bulldozerrel.
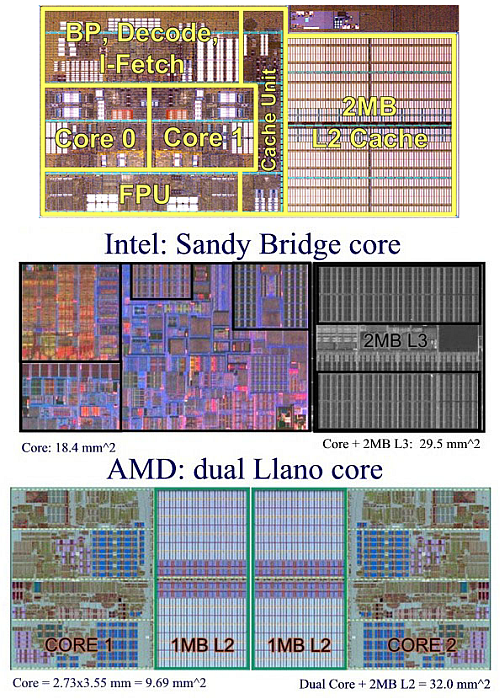
forrás: www.chip-architect.com
Az adatok birtokában könnyen kiszámolható, hogy a Sandy Bridge egyetlen magjához viszonyítva nagyjából 68%-kal lesz nagyobb egy modul. Azért nem árt megjegyezni, hogy ez utóbbiban pontosan nyolcszor nagyobb L2 cache lapul az SB 256 kB-os méretű másodszintű gyorsítótárához képest. A K10 architektúrás Deneb/Propus továbbcsiszolt magjait tartalmazó Llano (Fusion) két magja, melyek összesen szintén 2 MB L2 cache-t tartalmaznak, 1,1 mm2-rel foglalnak el nagyobb területet. A képen jól látható az is, hogy a nagy gyorsítótár önmagában mennyi szilíciumot emészt fel.
A teljes nyolcmagos lapka 8 MB L3 cache mellett szinte már példátlanul magas számú, körülbelül 2 milliárdnyi tranzisztort vonultat fel 315 mm2-es területen.
| Lapka kódneve | Gyártástechnológia | Magok száma | L2 + L3 mérete | Tranzisztorszám | Lapka területe |
|---|---|---|---|---|---|
| Orochi (Bulldozer) | 32 nm HKMG SOI | 8 (4 modul) | 16 MB | ~2 milliárd | 315 mm2 |
| Llano | 32 nm HKMG SOI | 4 (+ IGP) | 4 MB | 1,45 milliárd | 228 mm2 |
| Thuban | 45 nm SOI | 6 | 9 MB | 904 millió | 346 mm2 |
| Deneb | 45 nm SOI | 4 | 8 MB | 758 millió | 258 mm2 |
| Sandy Bridge | 32 nm HKMG | 4 (+ IGP) | 9 MB | 995 millió | 216 mm2 |
| Gulftown | 32 nm HKMG | 6 | 13,5 MB | 1,17 milliárd | 240 mm2 |
| Lynnfield | 45 nm HKMG | 4 | 9 MB | 774 millió | 296 mm2 |
| Bloomfield | 45 nm HKMG | 4 | 9 MB | 731 millió | 263 mm2 |
A táblázatból jól kivehető, hogy mezőnyünkben tranzisztorszám tekintetében a Bulldozer áll az élen, míg lapkaméretben a Thuban. Ez utóbbinál 31 mm2-rel kisebb az Orochi családnevű szilícium, ami így a Lynnfield előtt a második helyen van. Érdekességképpen megemlítenénk, hogy az AMD aktuális, 40 nm-en készülő csúcs Cayman kódnevű GPU-ja 389 mm2 területű, míg az NVIDIA GF110 kódnévre hallgató nagyágyúja nem kevesebb mint 520 mm2-es.
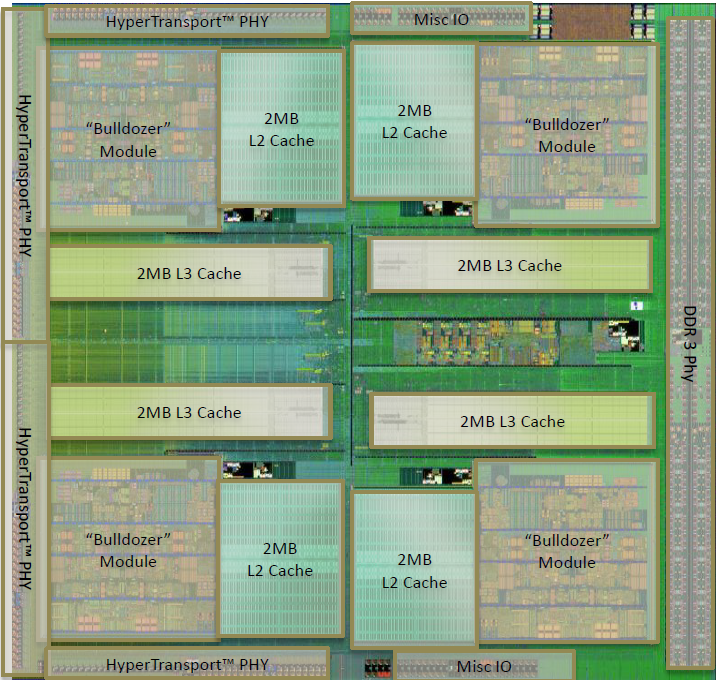
Mindenképpen vegyük figyelembe, hogy a lapka elsősorban a szerverek világának igényei alapján épült. Többek között ezért található benne négy darab HyperTransport link, mely többprocesszoros rendszerekben a CPU-k közötti kapcsolatért felel. Ezekből asztali környezetben összesen egy darab van kihasználva, mely az északi híddal való adatcserének nyújt átjárót. Az integrált memóriavezérlő természetesen most sem maradhatott ki. Ez a korábban bevett gyakorlat alapján kétcsatornás (dual-channel) működést biztosít, asztali rendszerek esetében egészen DDR3-1866-os szabványig, mellyel teoretikusan 29,86 GB/secundumos csúcsérték érhető el. A megoldás a Llano, valamint a konkurens Sandy Bridge megoldásával ellentétben nem tartalmaz integrált PCI Express vezérlőt.
A cikk még nem ért véget, kérlek, lapozz!








