Az AMD a mai napon végre útjára indítja a Bulldozer kódnevű architektúrát, mely egy gyökeresen új elvekre épülő rendszer. A vállalat ugyan nem mondja ki, de nem kérdés, hogy a fejlesztés során a legfőbb szempont, egy olyan processzor architektúra tervezése volt, mely sikeresen szolgálhatja ki a Fusion projekt következő lépcsőjét, mely az architektúrális integrálás lesz. Ezzel az AMD mindent alárendelt az új generációs követelményeknek, felkészülve a heterogén érában előkerülő igényekre.

A Zambezi kódnevű lapka [+]
A Bulldozer modul
A fentiekből adódik, hogy a Bulldozer koncepciója az egyszerűsítés. A kiindulási pont két teljes értékű mag volt, melyet az AMD egy modullá vont össze. Ez két darab integer magból, és egy megosztott lebegőpontos egységből áll. Az elgondolás alapján egy Bulldozer modulon egy-egy szál fut az integer magokon, és a Flex FP névre keresztelt lebegőpontos végrehajtó közös. Utóbbi működése nagyon érdekes. Az integer magok megfelezhetik a megosztott erőforrást, vagy az egyik mag teljesen ki is sajátíthatja azt, esetlegesen az is előfordulhat, hogy a munkafolyamathoz nem szükséges a Flex FP használata, így a teljes erőforrás lekapcsolható, ezzel pedig növelhető az integer magok órajele. A Flex FP lényegi előnye azonban a flexibilis működés. A Bulldozer modulon belül az AVX használata nélkül is kihasználható a feldolgozómotor 256 bites szélessége. Tudniillik a lebegőpontos feldolgozók egyszeres (32 bites) és dupla (64 bites) pontosságú utasításokkal dolgoznak. Lehetőség szerint annyit hajtanak végre, amennyi belefér a megadott hosszúságú egységbe. Ebbe sajnos beleszól az utasításkészlet is, ugyanis csak az AVX támogatja a 256 bites feldolgozást, ami azt jelenti, hogy egy AVX-et nem támogató programnál a 256 bites lebegőpontos végrehajtó 128 bitesként működik. A Bulldozer megvalósítása erre a problémára megoldást jelent, és az architektúra az alkalmazás újrafordítása nélkül képes kamatoztatni a két darab 128 bites FMAC egységet. Ez a gyakorlatban azt jelenti, hogy a 128 bites feldolgozást támogató SSE utasításkészlet maximálisan ki tudja használni a Bulldozer hardveres képességeit. Ez a dedikált ütemezőnek hála, akkor is él, ha a modulon belül az egyik integer mag teljesen kisajátítja a lebegőpontos feldolgozót. A modulban a magok természetesen megosztják az információkat, és a rendszer még végrehajtás előtt képes elemezni a feladatot, vagyis előre el tudja dönteni, hogy a 256 bites lebegőpontos feldolgozót megossza, vagy rendelje hozzá az egyik integer maghoz.
A Flex FP számottevő újdonsága még a MOV eliminálás. A MOV utasítást a mai kódok sűrűn használják, hiszen ezzel lehet átmásolni az egyik regiszter tartalmát a másikba. Ez azonban a mai processzorarchitektúrák többségében pár órajel alatt megy végbe, vagyis egyáltalán nincs ingyen. Erre a problémára megoldás az eliminálás, amivel a Bulldozer modulon belül 4 darab 128 bites SSE regiszter tartalmát lehet másolni zéró késleltetés mellett, azaz gyakorlatilag ingyen. Ez az integer regiszterekre sajnos nincs kiterjesztve, így ott a MOV utasítás egy, vagy két ciklus késleltetést jelent. Ettől függetlenül a szolgáltatás az SSE kódoknál nagyon értékes lehet, de az AVX esetében már nem igazán, mivel ezzel az utasításkészlettel lehetőség van háromoperandusú műveletre implicit másolással. Az AVX persze a Bulldozer modulban is előny lesz, de az SSE kódokat a Flex FP eléggé hatékonyan dolgozza fel, így az AVX-szel nyerhető extra sebesség nem lesz akkora, mint az Intel processzormagokon.
Hirdetés
Az újszerű felépítés felveti magok számának kérdését is. Az AMD a Bulldozer modult hivatalosan két magnak tekinti, de ez csupán értelmezés kérdése. A vállalat szerint a két darab integer mag kisajátíthatja a megosztott erőforrások felét, vagyis technikailag teljesen elkülöníthetőek. Ez mind igaz, de arra az esetre is gondolni kell, amikor az egyik integer maghoz kötelezően oda kell rendelni a teljes Flex FP feldolgozót, hiszen másképp az adott feladat nem lenne végrehajtható, ilyenkor a modul technikailag már egy magnak tekinthető, hiszen a másik integer feldolgozó csak olyan műveletet végezhet, aminél nincs szükség a lebegőpontos motorra. A magokkal kapcsolatos kérdés tehát továbbra is él, és igazából pontos válasz nincs rá. Ami biztos, hogy egy modul két szállal dolgozik, de ezt leszámítva a Bulldozer modul megközelítéstől függően tekinthető egy vagy két magnak. A rendszer többszálú feldolgozása egyébként úgynevezett CMT-szerű (Cluster-based Multi-threading) megvalósítás. Mint ismeretes, egy processzormagon belül számos megoldás van több feldolgozási szál kezelésére. A legelterjedtebb elgondolás az SMT (Simultaneous Multi-threading), amit például az Intel is alkalmaz a Hyper-Threading technológia égisze alatt. Az SMT nagyon kis tranzisztorigénnyel rendelkezik, miközben egy megfelelően optimalizált kód végrehajtásának idejét akár 20-25%-kal is csökkentheti. Ezzel ellentétben persze problémák is felüthetik a fejüket, mivel a program optimalizációja kulcsfontosságú. Volt már rá példa, hogy a processzor teljesítményét az aktív Hyper-Threading fogta vissza, ami azzal magyarázható, hogy a processzormagon belül a szálak közös egységeket használnak, azaz szó szerint küzdenek egymás ellen az erőforrás birtoklásáért. A CMT esetében ez nem fordulhat elő, mivel a feldolgozási szálak dedikált végrehajtóegységeket kaptak. Az elérhető gyorsulás az optimalizálástól és az operációs rendszer ütemezőjétől függ, de átlagosan 80%-os teljesítménynövekedés lehetséges. Természetesen a dedikált erőforrások nagyobb tranzisztorigényt jelentenek, de az AMD elmondása szerint az extra integer mag 12%-kal növeli meg a Bulldozer modul méretét. Ez persze nem ilyen egyszerű, hiszen a modul kezelése és ütemezése sokkal komplexebb lett, így a valós méretnövekedés valamivel nagyobb. A integer magok egyébként egy-egy dedikált 16 kB-os L1 gyorsítótárat használnak az adatok tárolására egy közös, 64 kB-os utasítás gyorsítótár mellett. A modulon belül szintén teljesen megosztott a mikrokód ROM, az utasítás behívás illetve a dekódolás is. Az utóbbi egység egy órajel alatt négy instrukciót képes lefordítani, míg az ütemező 40 bejegyzést tárolhat.
A Zambezi processzor
Az új lapka esetében a tervezők magas órajelet elviselő dizájnt alakítottak ki, vagyis az asztali piacon a 3 GHz alatt üzemelő megoldások gyakorlatilag nem lesznek. A 2 milliárd tranzisztort tartalmazó, 315 mm²-es kiterjedésű, Zambezi kódnevű chip a GlobalFoundries 32 nm-es SHP node-ján készül, és négy Bulldozer modult tartalmaz, melyek egy-egy 2 MB-os L2 gyorsítárat használnak. A közös L3 cache mérete 8 MB lesz, és az AMD a MOESI koherencia protokollt alkalmazza, így a magot a teljes L3 gyorsítótárba írhatnak. Az L3 cache az úgynevezett Northbridge órajelen ketyeg, míg a többi gyorsítótár a processzor adott órajelén üzemel.
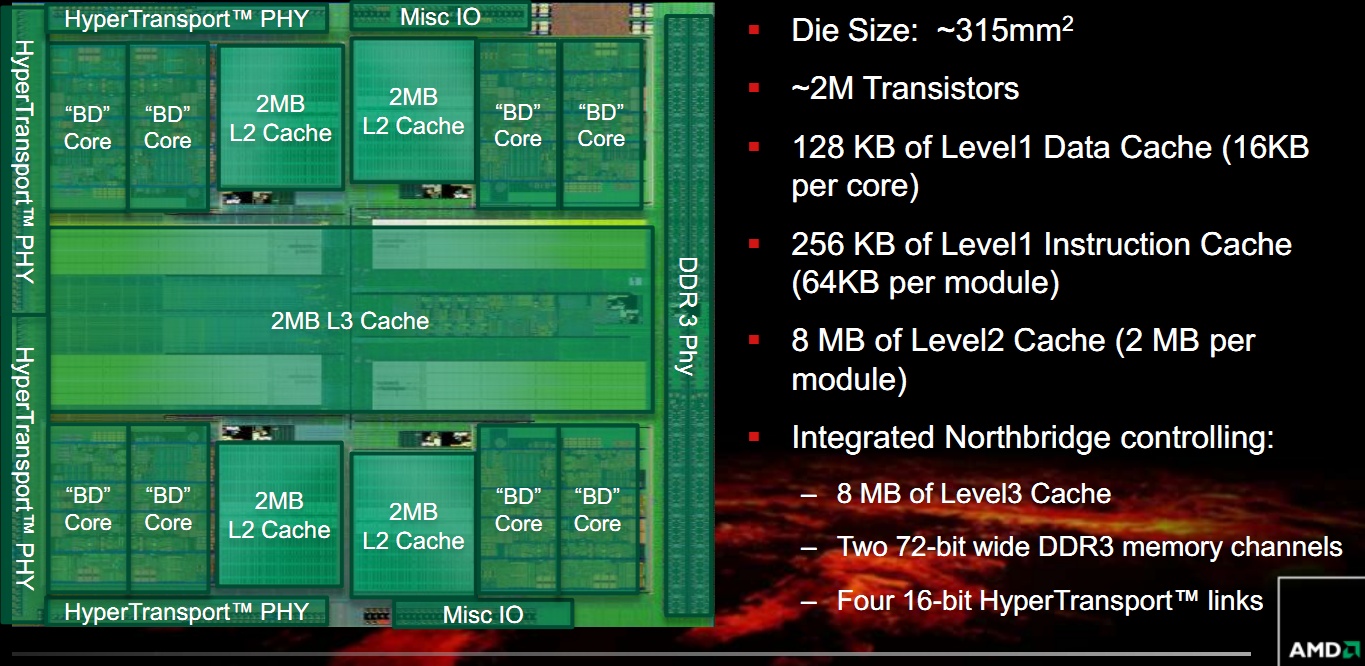
[+]
Az utasításkészlet tekintetében a Bulldozer tekinthető a piac legokosabb x86 kompatibilis processzorának, hiszen a 64 bites kiterjesztés és az MMX, SSE, SSE2, SSE3, illetve SSE4A mellett a rendszer kezeli az SSSE3, az SSE4.1, az SSE4.2, az AVX, az AES, az FMA4, az XOP és a PCLMULQDQ utasításkészleteket. Megszűnik azonban a 3DNow! támogatása, de az AMD a sűrűn használt PREFETCH és PREFETCHW utasításokat megtartja egy 3DNowPrefetch csoportban, így ezek továbbra is használhatók maradnak.
A konkurens megoldásokkal szemben az előnyt az XOP és az FMA4 jelenti. Előbbit a különböző multimédiás alkalmazások kamatoztathatják, míg az utóbbi elsősorban a HPC szerverek piacán lesz hasznos. Ez lényegében a Bulldozer ütőkártyája, hiszen a fejlesztők évek óta szeretnék a sokszor használt MAD (a*b+c) utasítást összefűzni, mivel az FMA a jelenleg alkalmazott, két részre bontott számításnál pontosabb eredményt ad, hiszen csak egyszer szükséges kerekíteni a számítás során. Az OCL Perf Mandrelbot teszteket az AMD már felkészítette az FMA-ra, és az FX-8150-es csúcsmodell esetenként 56-szor gyorsabb a Core i7-2600K-nál. Ebbe az eredménybe bele kell számítani, hogy az Intel processzora az FMA-t a hardveres támogatás hiányában emulálta, így az eredmények ugyanolyan pontosak voltak a két rendszeren, de az emulálás nagyon lassú folyamat, így nem csoda, hogy az FMA szoftveres megvalósítása ennyivel lassabb. Természetesen a számítások FMA nélkül is elvégezhetők, de akkor az eredmény nem lesz olyan pontos, mint FMA-val. Érdemes megjegyezni, hogy az otthoni felhasználás során az FMA4 támogatása nem igazán fontos, így ez a funkció a szerverek esetében hasznos.

A hardveres FMA előnye [+]
A Zambezi lapka kétcsatornás memóriavezérlője hivatalosan az 1866 MHz-es effektív órajelű, DDR3 szabványú modulokat kezeli. Természetesen ennél gyorsabb memória alkalmazására is van lehetőség, de az tuningnak számít. A mai napon négy darab FX szériás processzort indít útnak az AMD, melyek pontos paramétereit az alábbi táblázat részletezi:
| Típus | Órajel/Turbo Core alap/max. órajel |
L2 cache |
L3 cache | Fogyasztás (TDP) | Northbridge órajel | Listaár - dollár |
|---|---|---|---|---|---|---|
| FX-8150 (8 mag) | 3,6/3,9/4,2 GHz |
4 x 2 MB | 8 MB | 125 W | 2,2 GHz |
245 |
| FX-8120 (8 mag) | 3,1/3,4/4 GHz | 4 x 2 MB | 8 MB | 125 W | 2,2 GHz | 205 |
| FX-6100 (6 mag) | 3,3/3,6/3,9 GHz | 3 x 2 MB | 8 MB | 95 W | 2 GHz | 165 |
| FX-4100 (4 mag) | 3,6/3,7/3,8 GHz | 2 x 2 MB | 8 MB | 95 W | 2 GHz | 115 |
Mindegyik újdonság esetében állítható a processzor szorzója, és az AMD az alapórajel emelését is lehetővé teszi, hiszen fixre állítható a PCI és a PCI Express órajel is. Ezzel lényegében a tuning semmilyen formában nincs akadályozva. A Turbo Core is megújul, így bemutatkozik a 2.0-s verzió. Ez szintén érdekes rendszer, ugyanis az órajelemelés két szintre osztható. Az alap Turbo Core órajel az összes magra vonatkozik, és akkor lép érvénybe, ha a Flex FP feldolgozók kihasználatlanok a modulokon belül. Ilyenkor az integer magok extra teljesítményre tesznek szert. A maximális Turbo Core órajel a modulok felére vonatkozik. Ennek megfelelően a rendszer erre az órajelre vált, ha a processzor erőforrásainak fele kihasználatlan. Ezek persze tökéletes szituációk, így a gyakorlatban nem biztos, hogy sokszor előidézhetők, de a Bulldozer modul számtalan köztes állapotban működik a legjobb teljesítmény érdekében. A rendszer energiagazdálkodása is jelentős előrelépést hoz, így a Zambezi lapka teljesen lekapcsolhatja a nem használt modulokat, vagy akár a modulokon belül nem használt erőforrásokat.
A Scorpius platform
Az FX szériás processzorok megjelenésével a Scorpius platform is útnak indul. A rendszer alapja egy Socket AM3+-os foglalattal rendelkező alaplap lehet, melyekhez a 9-es szériás lapkakészletek még a Computexen startoltak el. Ezeket kell kiegészíteni egy, vagy több Radeon HD 6000 sorozatba tartozó grafikus kártyával, és a PC máris a skorpió erejére épít. A platform része a teljes funkcionalitású I/O Memory Management egység (IOMMU), amivel bármelyik új generációs grafikus processzor elérheti az x86 virtuális memóriát, ezzel lehetőséget teremtve például a teljesen hardveres megatextúrázásra.
Az új processzorok hivatalosan nem helyezhetők bele a Socket AM3-as foglalatba, de az AMD nem akadályozza meg a gyártókat abban, hogy az előző generációs alaplapokhoz készítsenek egy megfelelő BIOS-t. A vállalat azonban az esetleges problémákért semmilyen felelősséget nem vállal, így hiba esetén a felhasználónak az adott alaplap gyártójához kell fordulni. A rendszer megfelelő működéséhez Socket AM3+-os foglalat szükséges, így érdemes követni az AMD hivatalos ajánlását.
Szoftveres kérdések
Az AMD új generációs architektúrájával problémák is jönnek. A rendszer felépítése annyira újszerű, hogy a szoftverek oldaláról is szükséges hozzá támogatás, ami jelenleg nyilvánvalóan nincs meg. A legnagyobb gond az operációs rendszer oldaláról keletkezik. A többszálúság CMT-szerű megvalósítása logikailag hasonló a SMT-szerű elgondoláshoz, de a gyakorlatban számottevő különbségekkel kell számolni. A Windows 7 ütemezője nem ismeri a Bulldozert, így előfordulhat olyan szituáció, amikor a rendszer a feladatokat rossz erőforrásokon futtatja. Ez a Hyper-Threading esetében is lehetséges, de ott nem beszélhetünk szálakhoz rendelt dedikált feldolgozókról, a Bulldozer esetében azonban igen.
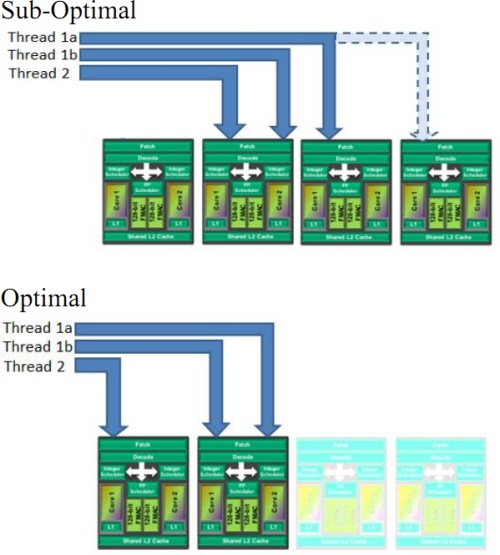
A fenti képen látható az egész elméleti működése. A Windows 7 ütemezőjével nem ritkán előfordulhat az első ábrán látható elv, amikor az operációs rendszer két modulnak kioszt két független szálat, majd az egyik szálon futó feladat folytatását odaadja a másik feladatot számoló modulnak. Ez a Bulldozer esetében óriási probléma, ugyanis a rendszer képtelen olyan Turbo Core órajelet beállítani, ami ideális a munkafolyamat számára. Az optimális működést a második ábra mutatja, amikor a két független szálhoz két független modul van használva, így a maradék két modul szimplán lekapcsolhat, azaz lehetőség adódik a maximális Turbo Core órajelre. Ezt mindenképpen javítani kell, és a vállalat dolgozik a Microsofttal az ütemező átszabásán, de nem kis feladatról van szó. Mindenesetre a Windows 8 fejlesztőknek szánt előzetes verziója már jóval fejlettebb ütemezőt használ, így ott a Bulldozer is gyorsabb, amit az AMD ki is mért.

Az operációs rendszer ütemezőjén is múlik a sebesség [+]
A listaár alapján az AMD a legerősebb processzorát az Intel Core i5-2500K és i7-2600K közé szánja, közelítve az előbbi árát. Ami nagyon érdekes, hogy a rendszer elsősorban az új játékokban teljesít jól, ráadásul olyan helyzetben, amit többnyire VGA-limitesnek lehet értékelni. Itt kifejezetten a hárommonitoros Eyefinity esetében mérhető előny érdekes, ami ugyan meglepő, de esetenként elég jelentős.
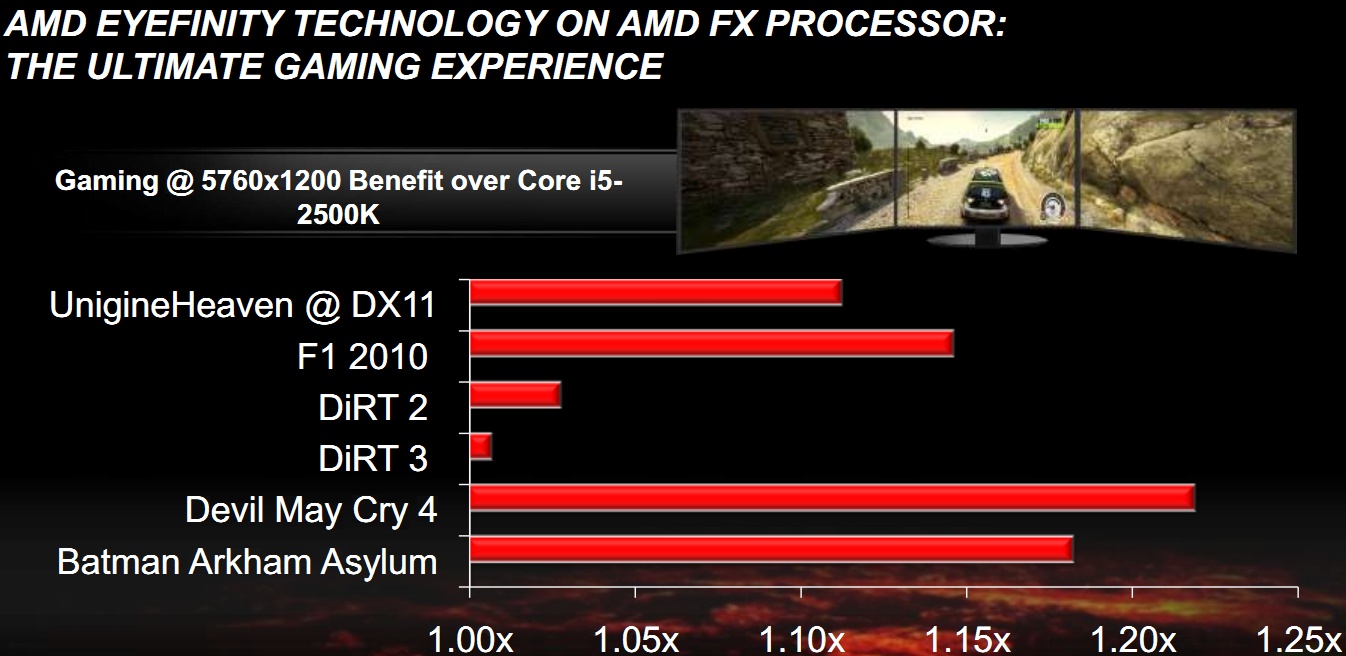
[+]
Az AMD elővette a Battlefield 3 béta verzióját is, ami lényegében az első olyan játék lesz, ami optimalizálást tartalmaz a Bulldozer architektúrához, és ez az eredményeken szintén meglátszik.

[+]
Szintén erős az AMD FX-8150 a rengeteg szálon futó programokban, de más szemszögből viszont gyengén teljesít a termék. Itt rendszerint a maximum 2-3 szálat használó játékokra, illetve a szintetikus tesztekre kell gondolni. Az előzetes összkép tehát nagyon vegyes, így mindezt egy alapos teszttel fogjuk később elemezni.


