Mennyi az annyi?
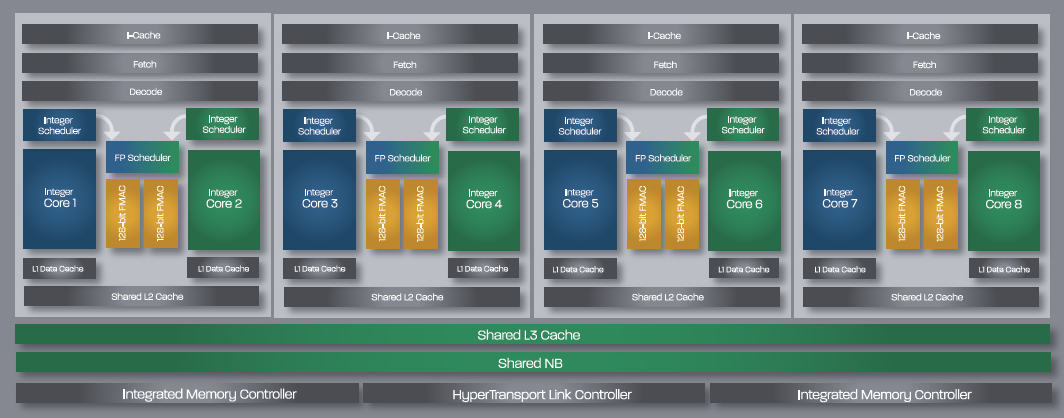
A 4. oldalon már pedzegettük, hogy a Bulldozer teljesen átfogalmazza a "mag" mint egység eddigi jelentését. Egyetlen modulon belül két dedikált, egész számos műveletek végrehajtására hivatott mag található. Az összes többi részegység megoszlik ezen két mag között.
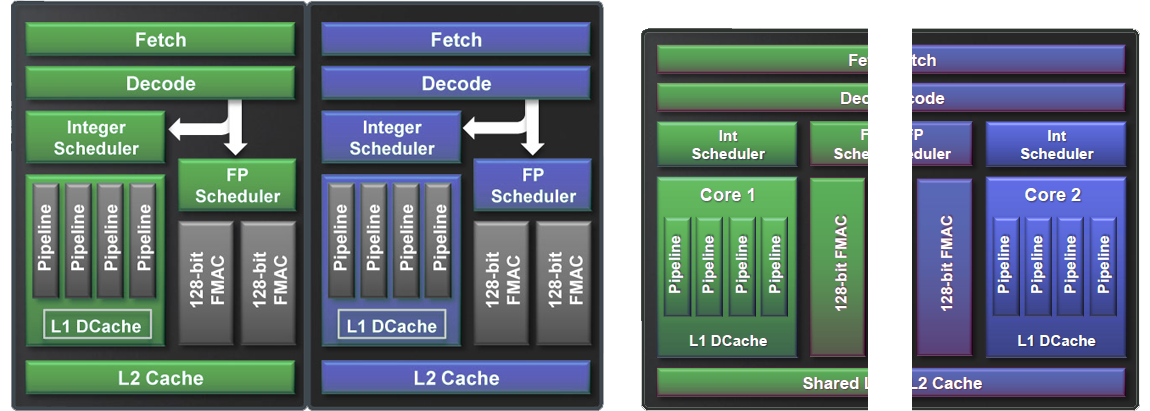
A bal és jobb oldali ábra a Bulldozer egy-egy, eddig megszokott elven felépülő, teoretikus változatát mutatja két-két maggal. Magyarán a klasszikus eddig használt kétmagos (multi-core vagy dual-core) megoldásról van szó, ahol minden mag dedikáltan rendelkezik az összes, önálló végrehajtáshoz szükséges egységgel. Először essen szó a bal szélen látható teoretikus ábráról! Ennél a Bulldozer modulban látható egyetlen mag dedikáltan megkapta a modulban található teljes front-endet, FPU-t és L2 cache-t is. Gyakorlatilag olyan, mintha kivágtuk volna modulból a második dedikált magot, ezzel minden esetben csak egyetlen magra juthatna az összes erőforrás. Ez így elsőre úgyan lehet, hogy jól hangzik, de a második dedikált mag eltávolítása csak kissé, nagyjából 12%-kal redukálná egy modul területét. Ráadásul összesen négy pár ilyen mag kellene ezekből egy nyolcmagos lapka esetében, ami megdobná az anyagszükségletet, ergo drágább és bonyolultabb lenne a gyártás, ami emellett a fogyasztásban is megmutatkozna. Ráadásul az AMD állítása szerint a modul egyetlen dedikált magja csak az esetek kis százalékában tudná kihasználni az összes rendelkezésre álló, jövőben megosztandó egységet, ami általában véve pazarlást jelentene.
A jobb oldali egy szimplán kettévágott modul, mely ismételten csak egy-egy magot próbál ábrázolni. Egy ilyen fél modul önmagában lefedné a jelenleg köztudatban élő "mag" fogalmát. Itt a terület és a költségek nem változnának. Mindkét mag kizárólagosan megkapná a modulban található megosztott egységek pontosan felét, így megint csak teljesen önállóvá válhatnának. Ellenben, ha például a nyolcmagos processzorunkon éppen egy olyan alkalmazást futtatunk, ami például csak maximum egy vagy két szálat képes megtornáztatni, akkor a kettévágással a szóban forgó program által használt magot (vagy magokat) megfosztanánk a potenciális erőforrások felétől. Ennek köszönhetően lassabbá válhat a végrehajtás. Ez a példa a koncepció egy másik lényeges előnyét próbálta kiemelni. Ezzel pedig ismét bejön a képbe az operációs rendszer helyes ütemezése, sok múlhat azon, hogy az ütemező például egy modulra oszt-e ki két szálat vagy egy-egy külön modulra.
Ennek vizsgálatához a Cinebenchet vettük elő. Ez leginkább lebegőpontos számításokat végez, azaz az FPU-t dolgoztatja meg, amiből modulonként csak egy található. Ezen teszt tulajdonsága még, hogy képes nyolc vagy akár több mag kihasználására is, miközben remekül skálázódik.

Ezután az alaplap UEFI-jében először két teljes modult tiltottunk le, majd végül mindegyik modulon belül az egyik dedikált magot. Mindkét esetben egy négymagos processzor lett a végeredmény. A turbót és az energiagazdálkodási funkciókat letiltottuk, hogy az órajel esetleges ingadozása biztosan ne befolyásolhassa az eredményeket.

A modulonkénti egyes magok letiltása durván 20% pluszt adott két teljes modul letiltásához képest, eközben az összes mag visszakapcsolása 68%-os növekedést hozott a konyhára. A tisztán kettőről négy modulra való gyorsulás majdnem pontosan 100%-os volt.
Első hallásra meglehetősen jól cseng, hogy a plusz mag csak 12%-a egy teljes modul méretének, majd ehhez mérten akár 70% körüli pluszteljesítményt is hozhat, amint a fenti példa is mutatja. Egyedül azt a nem éppen elhanyagolható információt nem ismerjük, hogy a modul megosztott részegységeinek méretét esetlegesen mennyivel kellett megnövelni a második mag beépítése miatt. Bármennyire is érdekes lenne ezt az adat, sajnos nem valószínű, hogy valaha is pontos és megbízható választ kapunk erre.
Az új architektúrával, azaz a mag fogalmának radikális átértékelésével nehezen lehet megmondani, hogy pontosan mi számít egyetlen magnak. Egyrészt nincs sehol pontos definíció arra, hogy mit lehet egy magnak nevezni. A számítási teljesítmény alapján ezt nem lehet behatárolni. Gondoljunk csak bele, hogy egy kétmagos Sandy Bridge-hez képest hány magosnak lehetne titulálni egy szintén két maggal rendelkező Atom processzort, ha ez így működne? Az kétségtelen tény, hogy a Bulldozer teljesen szakított a korábbi koncepcióval, így nem könnyű a helyzet. Természetesen az AMD kihangsúlyozza a magszámot, hisz erre még mindig sokan felkapják a fejüket. Mindent egybevéve jelenleg legalább annyi érvet lehetne felhozni a 4 modullal rendelkező Bulldozer nyolcmagos CPU-nak való titulálása mellett, mint ellene. Felmerülhet a kérdés, hogy az Intel például miért nem nyolcmagos processzorként állítja be a Hyper-Threading technológiával rendelkező Sandy Bridge processzorokat? Nos, ahogy az első oldalon említettük, ezen technológia esetében az egy maghoz tartozó két szál csak egy nagyon minimális dedikált résszel rendelkezik, de a fő ok valószínűleg nem itt keresendő.

A választ keresve megnéztük, hogy a Hyper-Threading milyen mértékű sebességtöbbletet nyújt. Ehhez a Sandy Bridge esetében is kikapcsoltuk a turbót, valamint fixáltuk az órajelet. Látható, hogy ebben az esetben durván 20%-ot hozott a plusz négy szál, ami a Bulldozernél látott 68%-nak csak kevesebb mint egyharmada. Példának okáért a Phenom II X6-nál egy magról hatra kapcsolva 100%-os skálázódás tapasztalható, vagyis az egy mag által elért eredmény hatszorosát kapjuk az összes mag aktiválása esetén.
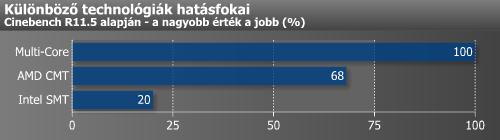
A Cinebenchnél látottak alapján felállítottunk egy szimpla rangsort az egyszerű többmagos megoldásokkal (multi-core), valamint a multi-threadingen alapuló SMT (Intel Hyper-Threading) és CMT (AMD Bulldozer) között. Túlságosan messzemenő következtetéseket ne vonjunk le a számokból, már csak azért sem, mert ahogy feljebb már említettük, a különféle alkalmazásokban található eltérő kódok miatt az eredmények változhatnak. A Hyper-Threading esetében például akad néhány szélsőséges eset, amikor az adott alkalmazás lassabban fut le, mintha ki lenne kapcsolva ez a funkció. Továbbá nem kizárt, hogyha nem is sokkal, de bizonyos alkalmazásokban valamivel többet is ki lehet hozni az utóbbiból a 20%-nál. A Bulldozernél már lárhattük, hogy akár bő 68%-ot is profitálhatunk a megoldásból, de nem kizárt, hogy van olyan eset, ami jobban fekszik ennek a kialakításnak. Két dolog teljesen bizonyos: a multi-core 100% fölé sosem fog menni, valamint ezt a 100%-ot semmilyen multi-threading technológiával nem lehet elérni.
Egy szó mint száz, szerintünk talán az lenne a legjobb, ha a gyártók a magok helyett mostmár inkább a szálak számát tüntetnék fel, de nem valószínű, hogy ez a közeli jövőben így történne. Ellenben valamiféle változás biztosan prognosztizálható, hisz elég csak a GPU-k integrációjára gondolnunk, mely egységek, ha majd aktívan szerepet kapnak az általános számítások gyorsításában is, akkor máris borulhat a rendszer. Addig is vigyázó tekintetünket az órajelekről és a magok, valamint szálak számáról inkább fordítsuk az alkalmazások alatt nyújtott valós teljesítményre. Ez utóbbinál ugyanis általában nem sok beszédesebb és fontosabb dolog van.
A cikk még nem ért véget, kérlek, lapozz!




