Intel 5400 chipset: Seaburg és a snoop filter
A lapkakészlet

Az Intel 5400-as chipset diagramja [+]
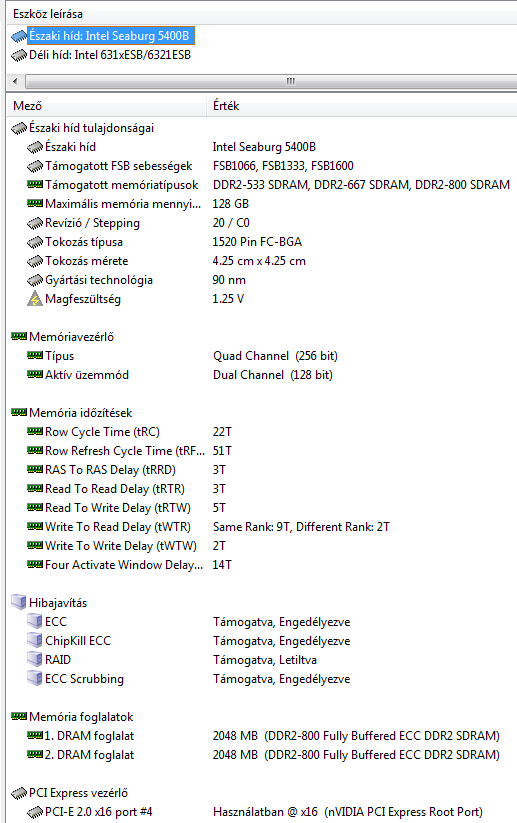
Az 5400-as lapkakészlet másképpen Seaburg chipsetként ismeretes, és a Penryn-alapú Xeonok (Harpertown) bemutatkozásával egy időben vált elérhetővé a Stoakley platform részeként. A Seaburg alapvetően egy belépőszintű szerverekbe és munkaállomásokba szánt chipset, és egyik leglényegesebb tulajdonsága a Dual Independent Bus (DIB) megvalósítása, ami a központi egységek és a chipset között egy-egy pont-pont összeköttetést létesít, így a processzoroknak nem egy közös rendszerbusz-sávszélességen kell megosztozniuk.
Az Everest infói [+]
A Seaburg már támogatja a 400 MHz-es FSB-t (1600 MHz Quad Pumped Bus), a szélesebb rendszerbusz kiszolgálása miatt „mélyült” a lekérdezéseket tároló puffer, és egy új soronkívüli végrehajtást végző tranzakciós mód is bekerült a chipsetbe, amely a HPC (high performance computing) alkalmazások végrehajtását gyorsítja. Az 5400-as chipset elődeihez hasonlóan csak a Fully-Buffered, azaz FB-DIMM memóriákat támogatja, erről a következő oldalon részletesebben írunk. Az Intel kétutas lapkakészletek másik jellemzője a snoop filter, amelyről az érdekesség kedvéért ezúttal kicsit hosszabban szólunk. A technológia iránt kevésbé fogékonyak nyugodtan tovább lapozhatnak.
A snoop filter
A cache, azaz a gyorsítótárak jelenléte megszokott dolog manapság a legegyszerűbb processzortól kezdve a legkomplexebb fürtözött rendszerekig. A cache segítségével a processzor gyakran használt adatokhoz jut hozzá a memóriánál sokkal gyorsabban, így az jelentős mértékben járul hozzá a rendszer végsebességéhez, hiszen nem elhanyagolható mértékű terhet vesz le a rendszerbusz, illetve memóriavezérlő válláról. A többprocesszoros rendszerek esetében viszont mindig figyelni kell arra, hogy az egyes processzorok gyorsítótáraiban megegyező adatok legyenek, és ezzel elérkeztünk a cache-koherencia problémájához. Napjainkban a gyorsítótár-egyezőség fenntartására különböző cache-koherencia protokollok léteznek, ezeknek persze vannak előnyeik és hátrányaik, jelentősen képesek befolyásolni a teljesítményt, hiszen a protokolloktól függ a gyorsítótárak kezelése.

Három különböző cache-egyezőséget fenntartó protokoll ismeretes, ezek a snoopy protokoll, a snarf és a könyvtáralapú koherencia protokoll. Ezek közül a snoopy és a könyvtáralapú protokoll a legelterjedtebb, ezúttal a snoopyról beszélünk kicsit bővebben, ugyanis az 5400-as chipset tartalmaz egy snoop filtert, amely a snoopy protokoll kiszolgálásáért felelős.
A cache-koherencia problémája igen egyszerűen megközelíthető. Arról van szó, hogy amikor a számítógép működik, adatokkal dolgozik, és mivel ezt több processzor teszi, fenn kell tartani a gyorsítótárak egyezőségét. Vegyünk egy egyszerű példát, gondoljunk arra, hogy a rendszerben található (az egyszerűség kedvéért) két processzor. Egy program futása során a gyorsítótár adott címéről mindkét processzor kiolvas egy változót (legyen x), melynek az értéke jelenleg 0. A program azonban nem áll le, és tegyük fel, az első processzoron (CPU1) futó számolások eredményeként az x értéke 1-re változik. A probléma ezzel csupán az, hogy a második processzorban (CPU2) az x értéke még mindig 0. Ha nem teszünk valamit, akkor elképzelhető egy olyan eset, amikor a CPU2 az x változóval akar dolgozni, viszont a változó értéke már nem az aktuális állapotot tükrözni, ami a program-végrehajtás szempontjából végzetes lehet. A koherencia-protokollnak kell arról gondoskodnia, hogy egy cache-line (cella) megváltozása után az összes gyorsítótárba a megfelelő érték kerüljön. Ezt csak úgy tudja elérni, ha az írások során tesz valamit. Két eset lehetséges: vagy érvényteleníti az összes gyorsítótárban az adott cache-cellát (invalidáció), vagy felülírja az új állapottal (értékkel).
Amikor a CPU1-ben az x értéke 1-re változik, egy invalidáció-alapú protokoll érvényteleníti a CPU2 gyorsítótárjában az adott cache-cellát (megjelöli azt). Amikor a CPU2 legközelebb hozzá akar férni az x értékéhez, egy cache-miss következik be (az adatot nem találja meg a gyorsítótárban), ezért kénytelen lesz a memóriához fordulni a helyes értékért. Egy write-through alapú gyorsítótárakat (a cache-cellák felülírása során a memória is frissítődik) tartalmazó rendszerben ezzel nincs gond, mert a memóriában mindig megtalálható a cache-ek tartalmának másolata, viszont egy write-back alapú gyorsítótárakkal (a cache-cellák felülírása nem vonja magával a memória frissítését) épített rendszer nem alkalmas erre, ezért a protokollnak kell arról gondoskodnia, hogy a CPU2 „elkérje” a helyes adatot a CPU1-től. A CPU1 elküldi a helyes adatot, a CPU2 pedig frissíti az adott cache-cellát ezzel az új adattal (cache-miss vége).
Egy felülírás-alapú protokoll ennél egyszerűbben működik: miután a CPU1 gyorsítótárában az x értéke 1-re változik, direktben elküldi a CPU2-nek a változó új értékét, így az azonnal frissíteni tudja az adott cache-cellát. Bármelyik módszer is működik, csak ha ezek a lépések megtörténtek, akkor nevezhetjük a rendszert cache-koherensnek.
Az invalidáció-alapú protokoll sokkal elterjedtebb, mert egyszerűbb implementálni, és nem generál akkora adatforgalmat. Gondoljunk csak arra, hogy csak akkor frissül a cache, amikor arra szükség van, igaz, az invalidációs üzenetet mindenképpen elküldi az összes processzornak még akkor is, ha azok többé nem dolgoznak az adott adattal. Egy felülírás-alapú protokoll mindig elküldi az esetenként 32/64/128 bájt méretű cache-cellát felülírásra, ezzel a rendszerbuszt jelentősen leterheli, így a valós adatforgalomra kevesebb sávszélesség jut.
A cache-koherenciát kezelő protokollnak, mint már említettük, három válfaja létezik, ezek közül a snoopy protokoll az, amit ezúttal érdemes közelebbről is megismerni, mivel a Skulltrail alapjául szolgáló chipset (Intel 5400 MCH) is ezt használja. A snoop, azaz szimatolás tökéletesen kifejezi, hogy miről is van szó. A protokollnak szüksége van egy közvetítő rétegre, ami a cache-változásokat közvetíti az egyes processzorok között. Egy snoopy protokollra alapozó rendszerben minden gyorsítótár folyamatosan kémleli („szaglássza”) a közvetítő réteget (ez lényegében egy busz) olyan tranzakciók után, melyek hatással vannak önmagára. Minden egyes alkalommal, amikor a gyorsítótár egy írást észlel a buszon, azonnal invalidálja saját adott cache-celláját. Olvasásnál a busz ad arra választ, hogy melyik cache tartalmazza a legfrissebb adatokat. A snoop-alapú rendszerek kiépítése igen egyszerű, de a processzorok számának növekedésével növekszik a busz terheltsége is, ami idővel szűk keresztmetszetté is válhat, ezért csak kevés (kettő-négy) processzort tartalmazó rendszerekben használják (fürtözött rendszerekben elképzelhető, hogy sok kisméretű snoopy protokoll található).

Az Intel 5400 MCH-ban található egy úgynevezett snoop filter (adatforgalom-szűrő), amely arra hivatott, hogy csökkentse a rendszerbuszon (FSB) átfolyó, a cache-koherenciáért felelős adatforgalmat, így növelje a hasznos, felhasználható sávszélességet és ezzel együtt gyorsítsa a memória elérését is. Az északi híd tartalmaz egy 24 MB-os szűrőt (tekintve, hogy két Yorkfield processzorban összesen 4 x 6 MB L2 cache található), ami hasonlatos egy gyorsítótárhoz vagy leírófájlhoz: a lapkakészlet itt tárolja el a két processzorban található gyorsítótárak indexét (cache-címkék, koherencia-állapotjelzők). Mivel a chipset minden egyes memóriahozzáférésről tud, a snoop filter jelenlétével szükségtelenné válik, hogy az egyes processzorok rendszerbuszát cache-koherenciával kapcsolatos adatokkal terheljék. A szűrő négy darab cache-leképzéshez szükséges tömböt tartalmaz (ezek egyenként 6 MB-osak, mint az L2 cache a processzorokban). Amikor egy cache-cella hozzárendelődik egy memóriacímhez, a koherenciakezelő protokoll hozzáférhet a szűrőhöz, abban megkeresheti a számára szükséges bejegyzés(eke)t, frissítheti, hozzáadhat bejegyzés(eke)t, vagy invalidálhatja az(oka)t, ha arra van szükség. A snoop filter a chipset órajelének dupláján ketyeg, azaz 533 MHz-en, így másodpercenként 267 MLUU, azaz 267 millió Look-Up-Update (olvasás utáni írás) műveletre képes. A cache-címkék keresési ideje négy SF-órajel, azaz két chipset-órajel.
A cikk még nem ért véget, kérlek, lapozz!




