- Igencsak szerény méretekkel rendelkezik az Aetina Xe HPG architektúrás VGA-ja
- Miniképernyős, VIA-s Epomaker billentyűzet jött a kábelmentes szegmensbe
- Különösen rendezett beltér hozható össze a Cooler Master új házában
- A középkorra és a pokolra is gondolt az új AMD Software
- Új gyártástechnológiai útitervvel állt elő a TSMC
- A Gigabyte is visszaveszi alaplapjainak alapértelmezett tuningját
- Épített vízhűtés (nem kompakt) topic
- Intel Core i5 / i7 / i9 "Alder Lake-Raptor Lake/Refresh" (LGA1700)
- AMD APU (AM4 és AM5) topik
- AMD GPU-k jövője - amit tudni vélünk
- TCL LCD és LED TV-k
- Milyen egeret válasszak?
- A régi node-okra koncentrál a szankciók miatt Kína
- Milyen belső merevlemezt vegyek?
- Házi barkács, gányolás, tákolás, megdöbbentő gépek!
Hirdetés
-


Free Play Days 2024 - 17. hét: Railway Empire, Prison Architect
gp Extraként a TramSim: Console Edition című játékot is kipróbálhatják az érdeklődők.
-


Olcsó 5G-s ajánlatot nyújt a Realme Indiának
ma Megérkezett a Realme C65 5G, az első készülék a MediaTek Dimensity 6300-zal.
-


Igencsak szerény méretekkel rendelkezik az Aetina Xe HPG architektúrás VGA-ja
ph Az 50 wattos modellt beágyazott rendszerekbe, MI-vel kapcsolatos munkafolyamatokhoz és edge applikációkhoz szánták.






Új hozzászólás Aktív témák
-
#1
 Petykemano
veterán
Petykemano
veterán
Petykemano
veterán
A zen(2) jelenlegi felépítésére küldik rá (mennyi értelme lenne) az SMT4-et, vagy szélesítik a feldolgozókat?
Találgatunk, aztán majd úgyis kiderül..
-
#9
Petykemano
veterán
Pug
#6
Petykemano
veterán
Az intel a foverost kapja elő. Idén talán látunk belőle valamit. Abu azt írta, a kurrens butított 10nm nem annyira jó magas frevencián még.
De tudjuk milyenek a megmondóemberek, milyen a mindshare. Most minden tesztben intelt használnak (kivéve persze az olyan csóringer magyar weboldalakat, mint a prohardver, ahol az "ajándék" 2700X-cel mérnek) minden nagyobb megmondóember, jútúber, streamer gépében intel 9900K van, mert az hajtsa ki legjobban a videokártyát.
Ha a következő 6-9 hónap során az amd a zen2-vel át tudná venni a ST perf leadet úgy, hogy teljesítmény nem omlik össze a threadhoppingtól, akkor az lenne ám csak az igazi fegyvertény, mert akkor ősszel az nvidia új 7nm-es gpu-it már nagy tiszteletlenség és elfogultság lenne nem a leggyorsabb CPU-val mérni és nagy ostobaság lenne a streamerek részéről is, ha nem a legjobb proci világítana ki a gépházból.Ez persze csak egy lehetőség az AMD-nek.
A foveros meg a kalap ott jöhet képbe, hogy ha a 10nm nem is alkalmas 5ghz-re, de a 3d stackingel esetleg megoldhatják az L3 cache méretének jelentős emelését, hovatovább többszáz MB eDRAM vagy STT-MRAM L4$-ként való alkalmazását, ami esetleg valamiképp alkalmassá tehet a ST korona visszavételére. Biztos adják fel könnyen.
Találgatunk, aztán majd úgyis kiderül..
-
#26
Petykemano
veterán
Vitamincsiga
#24
Petykemano
veterán
válasz
 Vitamincsiga
#24
üzenetére
Vitamincsiga
#24
üzenetére
vmikor lesz elvileg AVX512 is
Nekem az első kérdésem az volt, hogy a 4 szálat milyen backendre fogják ráépíteni - vagyis szélesedni fog-e
A zen jelenlegi backendje szélesebb, mint amit a frontend 1 szálon tud etetni, ezért látványos az SMT yield.még azt tudom elképzelni, hogy az AVX512 úgy jön, hogy 4x128-os feldolgozó, vagy 4x256, a lényeg, hogy több mint a jelenlegi 2x128 és akkor ott már szélesebb a feldolgozási képesség, amire érdemes lehet több szálat ráindítani.
[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#52
Petykemano
veterán
joysefke
#48
Petykemano
veterán
Még a bulldozer idejében voltak viták arról, hogy az SMT vagy a CMT megközelítés hatékonyabb-e. Jellemzően mindkettő 2 szál kezelésére alkalmas felépítésű. A CMT ugye arról szól, hogy a 2 szálat feldolgozó rész viszonylag kevés erőforráson osztozik, eléggé szét van választva. Cserébe a szálakat feldolgozó részek/oldalak háborítatlanul tudnak működni, nem versengnek egymással, és egyszerű felépítésűek, ezért tud pörgös és energiahatékony (khm-khm) lenni.
Az SMT abból indul ki, hogy egy széles (sok feldolgozót tartalmazó) magra indít két szálat. Itt a megosztott erőforrás vastag, a szálak versengnek egymással a processzor erőforrásainak használatáért.
(Elég részletes leírás itt)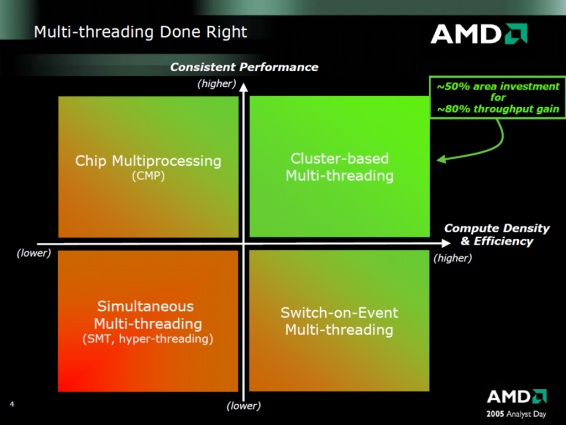
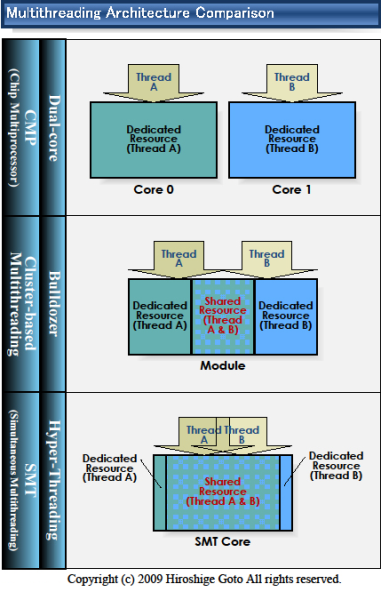
Az érvelés mindig valami olyasmi volt, hogy az SMT többlet-szilikon igénye 5% lehet, a yield pedig 20-30%
(Azoknál a programoknál, amelyeknél nem számít az egyszáles teljesítmény, mert valójában 1db 100%-os (potenciál) szál helyett a 2db az erőforrásokért versengő 60-65%-os (a ST potenciálhoz képest) szál fut)A CMT pedig mintegy 50% helyigény mellett 80%-os teljesítménytöbbletet adott 1 szál helyett 2 futtatásával.
Most itt nekünk az persze a CMT és az SMT kérdése már rég nem érdekes, csak az, hogy az SMT implementálása 5%-os többlettel jár.
Ez azt jelenti, hogy a szálkezeléshez dedikált részegységek csupán mintegy 5%-át tehetik ki lapkának, illetve SMT implementálása esetén ~10%. Tehát az SMT4-hez további 10% lehet szükséges.
Az SMT letiltását (ami ugyebár a szilikon 5%-ának elpazarlását jelenti) eddig is megtették Az AMD oldalán most ugyan nem gyakori, de az intel mostanában előszeretettel él vele. Az AMD nem sajnálta a szilikont a zeppelinből sem, amikor olyan részeket pakolt bele, amelyeket csak a szervereknél, illetve theadrippereknél használtak, AM4 tokozásnál nem.
Szóval én ezt a 10% többletet nem látom olyan nagy veszteségnek, ami miatt külön kéne választani a szerver és konzumer piacra tervezett lapkákat. Még csak letiltani sem feltétlenül kell, annyit kellene csupán csinálni, hogy AM4 alaplapok esetén a default az SMT2, de bátrak adott esetben átállíthatják 3-ra, vagy 4-re.Ha valahogy ügyesen csinálják, akkor esetleg még azt is megoldják az alábbi képen zölddel jelölt statikusan partícionált erőforrásokat a BIOS beállítás alapján partícionálják, vagyis 4 helyett 3 vagy 2 vagy 1 szált engedélyezése esetén a a 3, 2, vagy 1 szálnak azokból is több/nagyobb áll rendelkezésre. Így dekstop (SMT2) még Single Thread szempontjából még kevesebb az elvesztegetett erőforrás a "letiltás" miatt

Ami miatt ez az egész SMT4 számomra sokkal nagyobb kérdés, az az, hogy szerintem a Zen jelenlegi feldolgozóira nézve egy harmadik és egy negyedik szál már nagyon kicsi yieldet hozna.
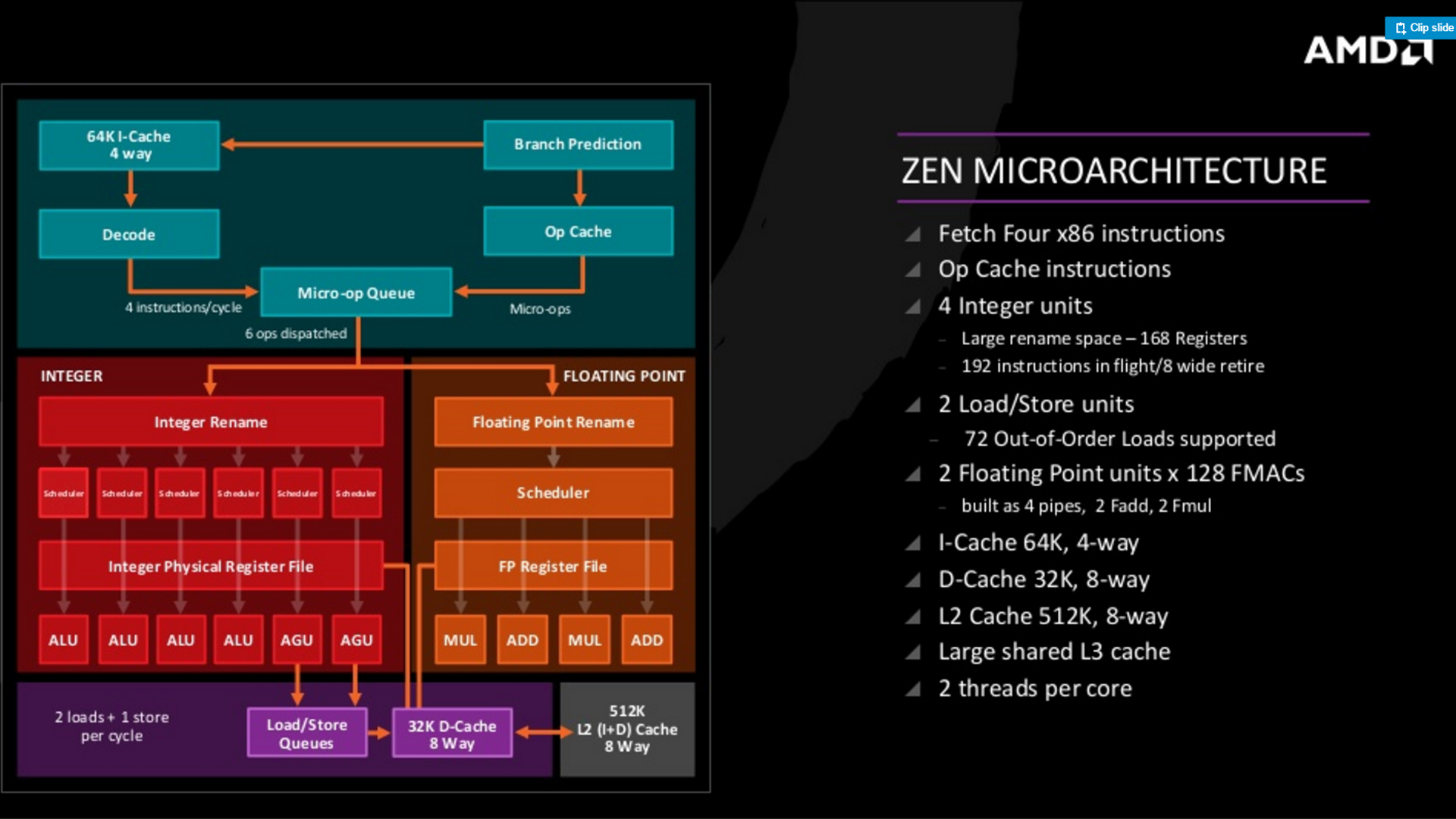
Itt van az integer pipeline-ban 4 ALU és 2 AGU, és van FPU: 2x128bites FMAC 4 pipe: 2 add és 2 MUL
Van egy ilyen is: "Dispatch is capable of sending up to 6 µOP to Integer EX and an additional 4 µOP to the Floating Point (FP) EX. Zen can dispatch to both at the same time (i.e. for a maximum of 10 µOP per cycle)." (src)És a zen esetén így hoz az SMT 40-50% többletet. Ami azt jelenti, hogy természetesen a zen backendje erősebb, szélesebb, mint a frontend - a frontend 1 szálon nem tudja maximálisan kihasználni a backend kapacitásait.
Ezen - a frontenden - a zen2 nyilvánvalóan javít:
Ha majd méri valaki a zen2 SMT hatékonyságát, akkor derülhet ki, hogy a zenben az SMT 50%-os yieldje mennyire pörgette ki a backendet a limitig.
Ha a zen2 a frontend javításával továbbra is 50% körüli SMT yieldet ér el, akkor a backendben még van lóerő.
Igazából ha SMT4-gyel mondjuk még 25% throughputot el lehet érni, az már lehet, hogy megéri (+25% throughput +10% szilikon árán)
az IBM power8 esetén a yield SMT2-ről SMT4-re 50% volt, így a 4 szálas throughput majdnem két és félszerese volt az 1 szálasnak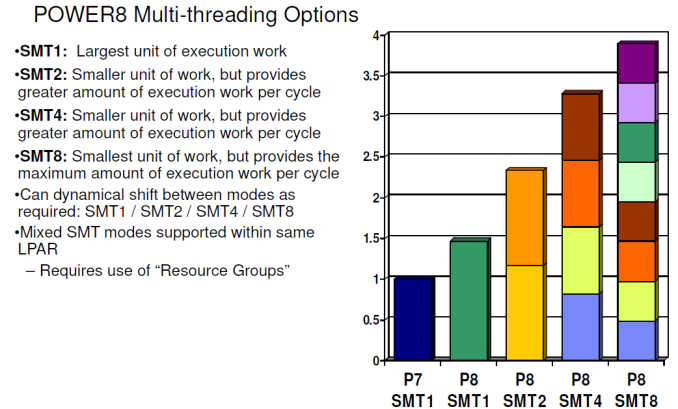
Persze az igazsághoz hozzátartozik, hogy a power szerver architektúra, ott kvázi megengedhető, hogy az egyszálas teljesítményt kicsit lazábban kezeljék és az IBM processzoraiban ez így is történik, ahogy azt az egyik kolléga linkelte is a cikkben, hogy az SMT4 humbug.
Tehát én jelenleg inkább meglepődnék, ha a zen jelenlegi backendjére ráengednék az SMT4-et. Ehelyett arra számítok - abban bízok -, hogy szélesítik az architektúrát. Egyrészt 4 ALU helyett mondjuk 5, vagy 2 AGU helyett 3, vagy 4 ALU, 4 AGLU (lásd piledriver) és az FPU oldaláról pedig azt várnám, hogy a 256bit, majd az 512 bit vektorutasítások végrehajtására úgy készítsék föl, hogy azokban 2, illetve 4 128bites utasítást - akár ha azok különböző szálakból jönnek is - végre lehessen hajtani egy ciklus alatt.
Így a backend megint fölénybe kerülne, de desktop vonalon ha az SMT4-nek, nem feltétlenül, de SMT3-nak is lehetne értelme, amíg a frontend felzárkózik.
Találgatunk, aztán majd úgyis kiderül..
-
#53
Petykemano
veterán
Balala2007
#50
Petykemano
veterán
válasz
 Balala2007
#50
üzenetére
Balala2007
#50
üzenetére
Én ugyan ennyire nem értek hozzá, de hasonló backend kapacitás-korlátokra gondoltam én is, ami számomra kérdésessé teszi a harmadik, negyedik szál yieldjét.
Ezt az 1load+1store képességet egyébként nem lehet javítani? Amikor a zen1 kiadásra került, a zen2 lényegében készen volt, már akkor nekifoghatott az A team a zen3-nak, ez két év. Ha tényleg az SMT4 a cél, és akkor ezen a tényezőn 2 év alatt csak tudnak valamit faragni, nem?
Talán ha a piledriverből átemelnék az aglukat, és 4 alu + 2 agu helyett 2 alu + 4aglu lenne benne, a load/store kéoesség is bővülne. De mondom, ehhez nem értek.
Az AVX512-vel kapcsolatban persze az a szóbeszéd, hogy ha már vektor, arra ott vannak a CU-k, és hogy offloadolni kellene. De amíg ehhez szoftveres támogatás kell, addig veszett fejsze nyele. Ezt egyébként chiphelles pletyka hintette el.
Mit gondolsz az infinity.fabricon keresztül meg lehet oldani, hogy avx512 utasítást valójában ne az fpu, hanem egy igp.hajtson végre?Találgatunk, aztán majd úgyis kiderül..
-
#66
Petykemano
veterán
awexco
#65
Petykemano
veterán
Én úgy tudom, a frontendet csiszolják (ST IPC) és a vektoros feldolgozást bővítik 128bitról 256-ra (annak minden velejárójával együtt - és ez persze nem jelenti azt, hogy eddig ne tudott volna 256bitet, de most már kétszer annyit tud egy órajelciklus alatt.)
Ezek nem tudom mennyiben járulnak hozzá az SMT4 implementálásához, implementálhatóságához.
[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..








Új hozzászólás Aktív témák

ph Itt sincs a második generációs EPYC, de már harmadik generációs fejlesztés előkészítése zajlik.
- A Gigabyte is visszaveszi alaplapjainak alapértelmezett tuningját
- TP-LINK routerek
- Épített vízhűtés (nem kompakt) topic
- Gyúrósok ide!
- Intel Core i5 / i7 / i9 "Alder Lake-Raptor Lake/Refresh" (LGA1700)
- AMD APU (AM4 és AM5) topik
- AMD GPU-k jövője - amit tudni vélünk
- Napelem
- Telekom mobilszolgáltatások
- TCL LCD és LED TV-k
- További aktív témák...

- Beszámítás! AMD Ryzen 7 7800X3D 8 mag 16 szál processzor garanciával hibátlan működéssel
- Beszámítás! Intel Core i5 6500 4 mag 4 szál processzor garanciával hibátlan működéssel
- Beszámítás! Intel Core i3 9100 4 mag 4 szál processzor garanciával hibátlan működéssel
- ELADÓ - Ryzen 7 5800X
- Újszerű - INTEL Core i5-14600KF 14mag 20 szál 5.3GHz CPU - bolti garanciával