
- Milyen billentyűzetet vegyek?
- AMD Navi Radeon™ RX 6xxx sorozat
- AMD Ryzen 7 / 5 / 3 1***(X) "Summit Ridge" (AM4)
- AMD Ryzen 9 / 7 / 5 7***(X) "Zen 4" (AM5)
- Autós kamerák
- Házimozi haladó szinten
- Home server / házi szerver építése
- Unigine Superposition Benchmark
- AMD GPU-k jövője - amit tudni vélünk
- Bambu Lab 3D nyomtatók
-

PROHARDVER!
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

stratova
veterán
válasz
 eventus
#18382
üzenetére
eventus
#18382
üzenetére
Nem akarom elhinni, hogy még gyártanak Caicos-t... azaz az említett R5 310-et (még ha csak vélt kártya is).
Szerintem még nem szerepelt ez a cikk szóval köszi. Igaz ezekből én kb. Baffint tartom érdekesnek. Ha Banks R7 360 és R5 310 közé érkezik felmerül a kérdés.. Minek? Rendben max.OEM lesz belőle vagy pár noti GPU is készül vele. Cape Verde és Pitcairn-re nem kevés (néven) készült mobil GPU.
Már az R5 230-nak sem szabadott volna megjelennie..[ Szerkesztve ]
-
stratova
veterán
válasz
 Televan74
#18389
üzenetére
Televan74
#18389
üzenetére
Ez ebben a formában nem teljesen igaz [HD 77xx/78xx/79xxM ugyanúgy GCN volt ahogy az asztali ill.a teljes Tonga előbb jelent meg mobil verzióban mint asztaliként]
 az már igen, hogy több átnevezést él meg mint az asztali variáns.
az már igen, hogy több átnevezést él meg mint az asztali variáns.Ezekben az Yoga modellekben az az érdekes [Skylake miatt megint ki kellett adni egy szériát
 ], hogy eddig GT 920M ill. GT 940M-mel szerelte őket Lenovo és most cserélné R5 M430 ill. R7 M460-re. Utóbbi esetében az Oland alapú R7 360M már eleve 1125 MHz-re lett "feltekerve" így a GPU-nak túl sok mozgástere nincs. Ellenben csak 64 bites DDR3-mat kapott, ezt illene cserélni. Pl. ha emelt órajelű R7 M370 [870 MHz] lenne (ua. lapka 128 bites GDDR5-tel) az M460 (és ez lenne a minimum, hogy ne legyen teljes visszalépés 940M után). Esetleg az R7 M365-öt (Oland + 128 bit DDR3) fokozzák le egy kicsit.
], hogy eddig GT 920M ill. GT 940M-mel szerelte őket Lenovo és most cserélné R5 M430 ill. R7 M460-re. Utóbbi esetében az Oland alapú R7 360M már eleve 1125 MHz-re lett "feltekerve" így a GPU-nak túl sok mozgástere nincs. Ellenben csak 64 bites DDR3-mat kapott, ezt illene cserélni. Pl. ha emelt órajelű R7 M370 [870 MHz] lenne (ua. lapka 128 bites GDDR5-tel) az M460 (és ez lenne a minimum, hogy ne legyen teljes visszalépés 940M után). Esetleg az R7 M365-öt (Oland + 128 bit DDR3) fokozzák le egy kicsit.[ Szerkesztve ]
-
stratova
veterán
válasz
 #85552128
#18430
üzenetére
#85552128
#18430
üzenetére
Ha a kisebbik Polarist GTX 950-nel mérték össze FHD normal preset beállítással Star Wars Battlefront alatt, akkor az akár lehetett egy R7 370-R9 270X kaliberű kártya is csak alacsony fogyasztással, ahová elég akár 4 GB GDDR5(X) akár 4 GB HBM is. Ezek simán hozzák a 60 fps-t olyan beállításokkal, sőt ennyi erővel mérhették volna High szinten:
Normal

High

Ultra
Másrészt simán mehetne felső középkategóriás noti VGA-nak.
GTX 960 [1024:64:32 1027@1228 MHz] 1920x1080 High 70 fps Ultra 47 fps 120 W
GTX 950 [768:48:32 1024@1148 MHz] 1920x1080 High 61 fps Ultra 45 fps 90 W
GTX 965M [1024:64:32 924-950@1151 MHz] 1920x1080 High 53-56 fps 60 WR7 270X [1280:80:32 1000@1050 MHz] 1920x1080 High 64 fps 180 W
R7 370 [1024:64:32 975 MHz] 1920x1080 Ultra 44 fps 110 W
R9 M390 [1024:64:32 958 MHz] 1920x1080 High 55 fps ~100 WTény hogy ez a cím az átlagnél jobban fekszik AMD-nek.
[ Szerkesztve ]
-
stratova
veterán
válasz
 füles_
#18452
üzenetére
füles_
#18452
üzenetére
Ezért jár egy tockos.

Yes, kiadjuk a HD 7770-et megint, immáron 3. nevén! S jók vagyunk mert mobilban volt több is (HD 7870M / 7850M -> HD 8850M / 8870M -> R9 M265X / M270 / M275 -> R9 M365X / M370X változatos órajelekkel [a DDR3 verzióktól most eltekintettem])
[ Szerkesztve ]
-
#18505
stratova
veterán
Malibutomi
#18502
stratova
veterán
válasz
 Malibutomi
#18502
üzenetére
Malibutomi
#18502
üzenetére
Jut eszembe, az adaptív ruhaszimuláción (adaptive anisotropic remesh) nem gondolkodtak még?


Ez talán az egyetlen helyzet amire nincsen még AMD-s megoldás (Nvnek most ott az Apex és ott eleve etrém tesszellációra is kigyúrták Kepler/Maxwellt). Olyan helyzetekben is jól jönne, mint Rise of Tomb Raiderben a hó már ha kombinálható LoD lépcsőkkel.
[ Szerkesztve ]
-
stratova
veterán
válasz
 stratova
#18505
üzenetére
stratova
#18505
üzenetére
Pepeeeee: ez jóval több mint lengedező zászló a szélben (csak ez volt a legnagyobb kép ahol egyértelműen látszik a lényeg). Egyébként nézted is a linket netán olvastad mi a lényege?
A Malubitomi által linkelt hír a Tootle toolról szól, ami mit ad Isten egy fejlesztői eszköz, ami ezen alapszik (ez talán szemléletesebb).
Erre jó:
AMD Tootle can be easily integrated as part of a rendering or mesh pre-processing tool chain since it does not require any update to the rendering logic. Yet, there is a potential high reward through significantly improving the rendering speed of graphics applications that are limited by vertex or pixel performance. This improvement is gained by reordering triangles (both vertex and index buffer) prior to rendering to optimize for the post-transform vertex cache, early Z-culling hardware and hardware cache line size in the GPU. This mesh optimization is applicable indiscriminately for any modern GPUs. After optimization, the resulting triangle mesh can be saved out to disk to replace the original model for rendering as necessary.Ezen felbuzdulva rákérdek, hogy netán a ruhaszimulációra van ötletes megoldás. Csak mert az egyes játékokban alkalmazott mesh-hegyeknek annyira nem örül egyik Radeon sem és a ruhákban vagy a hóban bőven van ilyen (és nem egy a konkurencia támogatásával megjelenő játék előszeretettel épít erre a gyenge pontra).
Valahol vicces (értsd: szomorú), hogy elegánsan elsiklunk afelett, hogy néha többször kerül be ide egy-egy hír - rendben, még visszaolvasás ellenére is megeshet az emberrel ilyen - alkalmasint masszív spekuláció - persze mindenki szeret találgatni latolgatni, én is - az nem gond. De ha egy szoftverrel kapcsolatban vetünk fel valamit az már probléma.
Egyébként én kérek elnézést, hogy néha 3 képen túl meg szeretném érteni, mit is hordoz magában a hír... és ez alapján felmerül bennem egy kérdés, hogy egy problémára készül-e szintén szoftveres megoldás az AMD-től.
[ Szerkesztve ]
-
#18548
stratova
veterán
Malibutomi
#18547
stratova
veterán
válasz
Malibutomi
#18547
üzenetére
Valószínűleg az órajelet kezelik trükkösebben, hogy TDP limiten belül maradjanak a la Fury Nano vs Fury esete csak kicsiben.
Normális árazással azért még lehetne belőle épkézláb kártya. Szvsz nagyobb létjogosultsága van, mint az R7 350-nek, noha igazán olcsó (< 30-35e) de ehhez viszonyítva használható dVGA-ra is van még igény.[ Szerkesztve ]
-
-
-
stratova
veterán
válasz
 MiklosSaS
#18557
üzenetére
MiklosSaS
#18557
üzenetére
Viszont a Dual Link DVI-D, Dual Link DVI-I, Displayport, HDMI miatt több monitoros rendszerhez érdekes lehet (ahol esetleg a 3D teljesítmény nem fő szempont).
Úgy látom GTX 750-ből a legtöbb gyártó One Dual Link DVI-I, HDMI, D-SUB/DisplayPort kombinációt részesítette előnyben, talán csak a referencia GTX 750-en volt Dual Link DVI-D, Dual Link DVI-I, mini-HDMI. -
stratova
veterán
válasz
#45185024
#18613
üzenetére
Legalább már tudom mitől ekkora ez a cucc. Amit nem egészen értek, mi az amire egy FX-8800P képes (aminek létezését alapvetően üdvözlöm, több noti kellene vele), de alapvetően egy random csúcstelefon alkalmatlan. Azaz az egész mögött illene lennie, valamilyen húzó címnek vagy képességnek.
Játékokban nyújtott grafikus teljesítményben némi jóindulattal Radeon R7 a GT 920M-et közelíti alulról.
A demót megnézve ez javarészt AR-re vagy VR filmre alkalmas szerkezet.
[ Szerkesztve ]
-
-
-
stratova
veterán
válasz
#85552128
#18822
üzenetére
Esetleg elszórakoznak vele FirePro-ként. Bár nem tudom mennyire kelendőek, de legalább az asztali játékos kártyáknál drágábban lehet elpasszolni őket (ha már asztali vonalon, viszonylag nyomott áron kell adniuk az ügyes konkurencia miatt).
Pictrain-t már bőven el kell búcsúztatni, de igazából mobil vonalon a Tonga is kissé problémás. ha ezeket nem váltaná AMD kb, végleg elköszönhetne a mobil felső kategóriától, Bonaire pedig éppen népesebb mobil középkategóriának az alapja (emiatt sem ártana cserélni).
Miközben GM204-ből már 150 W-osat is kiadhatnak, mert egyszerűen GTX 970M-től nincs ellenfele Nv-nek.[ Szerkesztve ]
-
-
#18843
stratova
veterán
Malibutomi
#18842
stratova
veterán
válasz
Malibutomi
#18842
üzenetére
Nos akkor a benchből legfeljebb a CU-k száma (pár egyéb paraméter) és az elérhető legmagasabb órajel derül ki, mert a teljesítményadatok nem mérvadóak.
-
stratova
veterán
válasz
 solfilo
#18844
üzenetére
solfilo
#18844
üzenetére
Úgy értette hogy ez a fellelt bench 67FF: C8-ról driver log alapján a legkisebb Baffin lapkát takarja. Amúgy tényleg érdekes kérdés, hogy megmarad-e a CU-kénti 64 SP mert 1024 beugrónak elég soknak tűnik (a táblázatban pedig felette már nem egy még kisebb vga hanem a belépő APU Stoney Ridge). Bár az is igaz, hogy lassan APU-ban is lesz 10 CU.
[ Szerkesztve ]
-
stratova
veterán
válasz
solfilo
#18844
üzenetére
Az izerjú alapján első körben a legnagyobb játékos rétegre fókuszálnak, emiatt nem HBM2-es még Polaris a HBM alkalmazásáról annyit említett, hogy a HBM1 tapasztalatai alapján ez egy drága technológia akkor akarják nagy mennyiségben alkalmazni amikor elérhető a mainstream réteg számára is. A Polarisnál nagyobb és vélhetően HBM2-es GPU Vega lesz a legutóbbi prezentáció alapján.
SP szám: nyilván nem érdemes visszalépni, csak még szoknom kell ezt a shadertengert
cseppet kellemetlen volt hogy az 1024SP-s R7 265 a 640-es GTX 750 Tivel meccsel, de nyilván más volt a lapkák konfigurációja és gyári valamint elérhető órajele.[ Szerkesztve ]
-
stratova
veterán
Látva, hogy milyen órajeleket tudott elérni AMD gyári beállításon a konkurenciához képest, szerintem egyáltalán nem baj, ha látszólag nem kifejezetten sok SP kerül az új GPU-kba, de az lényegesen magasabb órajelet érhet el, amellett hogy az eddigi gyengébb paraméterek javulnak (részben a magasabb órajel részben pedig az áttervezés, limitációk csökkentése vagy megszüntetése miatt). Az ALU teljesítmény egy dolog a sok közül.
Tehát ha a mostani Polaris lapkák a mainstream rétegnek készültek és minden limitációt sikerülne kiiktatni:
P11: 1024, 1280, 1536 SP: vs GTX 950 [768 SP], GTX 960 [1024 SP], ill valamivel afeletti szintet kellene megütni.
Csak P11-gyel le lehetne fedni a játékos notebookpiac egy jelentős részét és asztaliból is talán a legnagyobb réteget. Vö: vélhetően GM206-tal fogy a legtöbb játékos notebook (pontosabban a nagyobb oldalakhoz ebből fut be a legtöbb tesztpéldány).
P10: 36 CU [2305], 40 CU [2560] megfelelő órajelekkel ezeknek rendre GTX 970 [1664 SP] és GTX 980 [2048 SP] körüli/feletti összteljesítényt illene prezentálniuk (tehát nem csak ALU).
Ha a kisebb SKU még beleférne 125-150 W-ba akkor meg lehetne szorongatni a mobil VR-re prezentált GM204-es Quadro M5500-at. A jelenlegi R9 M390 / M395X-nek éppen az a baja, hogy mobilhoz egy kimondottan nagy lapka [359 mm2] ezért 95 W TDP-hez 723 125 W-hoz 909 MHz a legmagasabb elérhető órajele, majdnem akkora mint a GM204 [398 mm2] aminek mindkét variánsa [980M 970M] gyorsabb nála, nyilván a letiltott részegységek miatti magasabb órajel miatt is. 150W-on pedig már teljes GM204-et szállít Nv
Példának okáért itt a GTX 950 GTX 960 vs R7 370, az oldal alján látható az ALU teljesítmény, ahol a GTX 950 órajelből képes ellensúlyozni a kevesebb stream processzort. Miközben éppen ebből kifolyólag a többi paramétere jobb és R7 370 csak GTX 750 TI és GTX 950 közé fut be az összesítésben.
Oké a csúcs Pascal GP100 pl 60 stream multiprocesszort kapott [7680 SP], de ez egy kifejezetten compute célra szánt GPU. Arra ott lesz Vega vagy
[ Szerkesztve ]
-
stratova
veterán
Mea culpa épp az aktuális teljes lapkák peak értékeit számolgattam s itt elfelejtettem leosztani kettővel

Egyébként csak abból indulok ki, hogy elvileg eddig Polaris 10, 11-ből a legkisebb SKU-k szivárogtak ki, és általában ezek alacsonyabb órajelet is szoktak kapni nagyobb testvérüknél. Pl. R9 270X [1000 MHz] R7 265 [900 MHz] (hogy 67FF: C8-cal azonos SP számú példát hozzak )Persze ettől még simán lehet , hogy a konkurencia most is magasabb órajelre lövi be a lapkákat. GP100 értékei megsüvegelendők. Szvsz egyébként AMD Vegánál nem megy 4096 SP alá legfeljebb erősít ott ahol kell.
Ha valamilyen szövegkörnyezettől elütő szó marad a hozzászólásban, elnézést általában telóról írok
[ Szerkesztve ]
-
stratova
veterán
válasz
#00137984
#18865
üzenetére
Azért Tonga már egy picit lecsúszott azon a palettán, ahol HD 6850 vagy HD 7870 bemutatkozott utóbbiak felett 2-3 velük azonos generációba eső 1 GPU-s kártya volt. 380 felett van 380X, 390, 390X, Fury Nano, Fury, Fury X (de ez abból is látszik, hogy a GTX 960-nal kénytelen versenyezni, ami felett ott van GTX 970, GTX 980, GTX 980Ti és GTX Titan X).
Ahogy Malibutomi is írja egyelőre a kiszivárgott nagyobbik Polarison 2560 SP lehet a kistestvér alapján (kivéve ha 4-nél több CU eltérés lenne a teljes és a csonkított 2304 SP-s lapka között). De lejjebb agyaltunk egy sort azon is hogy nem csak ezen műlik a siker.
Egyes oldalak ennyi CUDA magot tippelnek a konkurens GP104-re is és a 60-ból 56 SMP blokkot használó (jelenleg) csúcs GP100-as lapkán aktív 3584 SP (és maximum 3840-nel adhatnak ki még belőle kártyát később).[ Szerkesztve ]
-
stratova
veterán
válasz
#00137984
#18868
üzenetére
Szerintem 4096 shader minden csak nem kevés, más kérdés, hogy ezt a TDP keret és a gyártástechnológia miatt viszonylag alacsony órajelen tudták járatni.
A 64:4:1-es SP : TMU : ROP arány viszont végre lehetne 64:4:2 a felső ligában is.A konkurens compute célra szánt 3584-es kártya 1328 mHz alap 1480 MHz boost órajelet kap, így ha a shaderek száma nem emelkedik Vegának is kell egy legalább 1295 MHz-es boost.
SP vs órajel kicsiben
R9 M390 [1024:64:32] -958 Mhz vs. R9 M295X [2048:128:32] -850 MHz GTX 965M [1024:64:32] 924-950 935-1150
Witcher 3
1920x1080 high 39,2 fps 118% 111%BF Hardline
1920x1080 high 56 fps 104% 115% ultra 36,8 fps 106% 111%Dragon Age: Inquisition
1920x1080 high 39,4 fps 112% 103%Alien: Isolation 2014
1920x1080 ultra 56 fps 105% 104% 104%Middle-earth: Shadow of Mordor
1920x1080 high 53 fps 109% 94% ultra 39 fps 114% 80%Thief
1920x1080 ultra ~33 fps 98% 110%BF4
1920x1080 ultra 56 fps 106% 111%Metro: Last Light
1920x1080 ultra 33,8 fps 126% 123%BioShock Infinite
1920x1080 ultra 49,5 fps - 109%Tomb Raider
1920x1080 ultra 64 fps 95% 96%[ Szerkesztve ]
-
stratova
veterán
válasz
#00137984
#18890
üzenetére
Ha a középkategóriás modelleket tekintjük népkártyának vagy mainstream kategóriának, akkor szerintem viszonyítási alapnak az 1080P felbontást is vehetjük. Az 1440P felső kategória 4K pedig csúcs (oké nyilván később lesz 5K meg 8K).
Szvsz jó esetben P11 valahová R9 380 alá P10 pedig R9 390/390X szintjére vagy a főlé kellene, hogy befusson ha annyit javítanak rajta. Esetleg bizonyos területen (ROP, geometriai teljesítmény) jelentősen el kellene lépnie tőle.
Gondolom ugyan ez az elvárás GP204-gyel szemben GM204-hez képest.Malibutomi látszólag ez a cím annyira érzékeny az ALU teljesítményre amennyire Witcher 3 volt érzékeny a ROP-ra.
[ Szerkesztve ]
-
stratova
veterán
válasz
füles_
#18894
üzenetére
Na jó, ez már-már klickbait. Itt nekem már kavarodik a Polaris 10 Polaris 11... vagy ők írták el. A konzol szintű jelző a 16 CU-s Polarisra lehet igaz (ennél még stimmelne is a 800-1000 MHz-es órajel és a 128 bites GDDR5 bár remélhetőleg legalább a konkurencia szintjére húzták fel a delta color compression hatékonyságát, mert az előd kártya R9 M390 még 5460 MHz-es GDDR5-öt kapott 256 biten, igaz 1080P felbontáson általában megelőzi a 128 bit 5000 MHz GDDR5-ös GTX 965M).
Remélhetőleg AMD rendet tesz kicsit az elnevezésekben is:
M395X - 32 CU 2048:128:32 909 MHz 256 bit GDDR5 5460 MHz
M395 - 28 CU 1792:112:32 723 MHz 256 bit GDDR5 5000 MHz
M390X - 20 CU 1280:80:32 834 MHz 256 bit GDDR5 5460 MHz
M390 - 16 CU 1024:64:32 958 MHz 256 bit GDDR5 5460 MHz
M385X - 14 CU 896:56:16 1100 MHz 128 bit GDDR5 6000 MHzJelenleg ennyi lapkával fedik le azt amit Nv GTX 960M, GTX 965M, GTX 970M-mel és lényegesen kevesebb notit forgalmaznak velük.

-
stratova
veterán
Ez ebben a formában igaz, de nekem úgy rémlik, hogy a legtöbb helyen jelzett core configban ált a SIMD blokkok vector ALU-it számolják és a teljesítmény is g/tflopsban adják meg, ahol az integer alu-t nem számolják bele.
Viszont magyarázat a lényeg:
[0028]
FIG. 4 is a block diagram of a portion of a compute unit (400) with different sizes of SIMD units. It is noted that the compute unit (400) includes various additional components not shown on FIG 4. FIG 4 only shows the portions of of the compute unit (400) relevant to understanding the concepts described herein.[0029]
The compute unit (400) includes a front end fetch and decode logic (402) and one or more arithmetic logic units (ALUs) (404a), (404b). The compute unit (400) also includes a number of different sizes of SIMD units. A two thread wide vector SIMD unit (406) includes two ALUs (408) and has an associated register file (410). A four thread wide vector SIMD unit (412) includes four ALUs (414) and has an associated register file (416). An eight thread wide vector SIMD unit (418) includes two ALUs (420) and has an associated register file (422).[0030]
It is noted that while the compute unit (400) is shown with two scalar ALUs (404) one two thread wide vector SIMD unit (406), one four thread wide vector SIMD unit (412), an one eight thread wide vector SIMD unit (418), the compute unit (400) may be constructed with different numbers of scalar units and the SIMD units without affecting the overall operation of the compute unit (400). Alternatively, SIMD units (406), (412) and (418) may initially have the same width (e.g., each being an eight thread wide SIMD unit) but may be configured (on a demand basis) to deactivate (e.g., gating mechanisms, disabling, powering off, etc.) to have different widths (e.g. a two thread wide, a four thread wide, an eight thread wide SIMD unit, as described above, by deactivating, six, four and zero, respectively, pipes or ALUs in each unit).[ Szerkesztve ]
-
stratova
veterán
[0031]-től kezdődik a magyarázat
By providing a set of execution resources within each GPU compute unit tailored to a range of execution profiles, the GPU can handle irregular workloads more efficiently. Current GPUs (for example, as shown in FIG. 3) only support a single uniform wavefront size (for example, logically supporting 64 thread wide vectors by piping threads through 16 thread wide vector units over four cycles). Vector units of varying widths (for example, as shown in FIG. 4) may be provided to service smaller wavefronts, such as by providing a four thread wide vector unit piped over four cycles to support a wavefront of 16 element vectors.
A +1 skalárhoz:
In addition, a high-performance scalar unit may be used to execute critical threads within kernels faster than possible in existing vector pipelines, by executing the same opcodes as the vector units. Such a high performance scalar unit may, in certain instances, allow for a laggard thread (as described above) to be accelerated. By dynamically issuing wavefronts to the execution unit best suited for their size and performance needs, better performance and/or energy efficiency than existing GPU architectures may be obtained.Példa:
In another example, assume that a wavefront includes 16 threads to be scheduled to a 16 thread wide SIMD unit, and only four of the threads are executing (the remaining 12 threads are not executing). So there are 12 threads doing “useless” work, but they are also filling up pipeline cycles, thereby wasting energy and power. By using smaller (and different) sizes of SIMD units (or vector pipelines), the wavefronts can be dynamically scheduled to the appropriate width SIMD units, and the other SIMD units may be powered off (e.g., power gated off or otherwise deactivated). By doing so, the saved power may be diverted to the active SIMD units to clock them at higher frequencies to boost their performance.Infó:
The smaller width SIMD units may be, for example, one, two, four, or eight threads wide. When a larger thread width SIMD unit is needed, any available smaller thread width SIMD units may be combined to achieve the same result. There is no performance penalty if, for example, the wavefront needs a 16 thread wide SIMD unit, but the hardware only includes smaller thread width SIMD units.In some embodiments, the collection of heterogeneous execution resources is shared among multiple dispatch engines within a compute unit. For instance, rather than having four 16 thread wide vector units, four dispatchers could feed three 16 thread wide vector units, four four thread wide vector units, and four high-performance scalar units. The dispatchers could arbitrate for these units based on their required issue demands.
-
stratova
veterán
Szerk. hibás volt a feltételezés, az által hogy ha elegendő kevesebb ALU-t aktiválni emelhetik az órajelet is adott fogyasztáson belül:
By using smaller (and different) sizes of SIMD units (or vector pipelines), the wavefronts can be dynamically scheduled to the appropriate width SIMD units, and the other SIMD units may be powered off (e.g., power gated off or otherwise deactivated). By doing so, the saved power may be diverted to the active SIMD units to clock them at higher frequencies to boost their performance.
[ Szerkesztve ]
-
stratova
veterán
Bár lassan beilleszthetnénk a teljes szöveget de ez a szakasz is a teljesítményt taglalja:
In this example, therefore, the constant wavefront of a classical GPU architecture would be two threads. The classical GPU architecture would schedule the floating point multiplications over seven cycles across the two FPUs and would schedule the integer instructions over three cycles across the two IUs. So, the classical GPU architecture performs 14 threads of floating point work and six threads of integer work—wasted work for 13 and five threads worth of work, respectively.
Instead, for the floating point multiplication, six cycles×two FPUs and one cycle×one FPU may be scheduled, doing exactly 13 threads of work (the remaining FPU may be powered off, for instance). Similarly, for the integer addition, two cycles×two IUs and one cycle×one IU may be scheduled.
If execution resources R[t] of different types can cover certain computations, then the scheduler can schedule that computation over different heterogeneous resources. In the example above, if the FPUs were also able to execute integer operations (perhaps the IUs cannot execute floating point operations, however), then the extra integer operations available during the trailing cycle of the floating point operation could be used by the integer instructions, further increasing pipeline efficiency.
Finally, if these different types of units ran at different frequencies (or if they were on different voltage islands, allowing them to change voltage and frequency on demand), then it may be possible to schedule some threads on execution units running at different frequencies and with different thread widths, again potentially improving power efficiency. By utilizing the power saved by executing on lower-powered vector units, other vector units (perhaps those running more performance-critical threads) could be overclocked to yield higher overall program performance.
[ Szerkesztve ]
-
stratova
veterán
válasz
 Oliverda
#18969
üzenetére
Oliverda
#18969
üzenetére
Hmm egy magyar összefoglaló arról ami itt is összegyült már több részletben. Nem is tudtam, hogy lapcsaládot valtottál, vagy két helyen is cikkezel?
Régen nem kedveltétek ha konkurenciaát linkeltünk Egész szépen összeszedted egyébként.
Egész szépen összeszedted egyébként.
R7 470-nel a mobil középkategóriát is szépen zsebre lehetne vágni ami nem kis szelet.[ Szerkesztve ]
-
stratova
veterán
válasz
#45185024
#18974
üzenetére
A konkurens GP100-as lapkában sincsen hibátlan állapotban sem 3840-nél több SP, noha az első kártyán csak 3584 aktív. Viszont nőtt a regiszterterület és volt Fijinek egyéb lemaradása, amit lehet orvosolni valamint az órajelen sem ártana tornászni, mert ott bő 30% Pascal előnye alapon.
AMD már GCN-nél is sűrűbb dizájnt használt Maxwellhez képest, emiatt is viselte jobban utóbbi a magasabb órajelet.
Mivel a dizánon AMD valószínűleg nem sokat változtatna a kihasználatlan ALU-k lekapcsolásával nyert fogyasztási keretet órajelemelésre fordíthatják.[ Szerkesztve ]
-
#18983
stratova
veterán
Malibutomi
#18982
stratova
veterán
válasz
Malibutomi
#18982
üzenetére
De, sőt Pascalnál csak a legnagyobb GPU órajele ismert, Polarisnal pedig a kisebbeké. De erről beszélgettünk korábban is. Bár megjelenéshez most P104/106 és Polaris 10, 11 van közel. Hardware.fr-nek adott válasza alapján Nvidiánál jelenleg nem terveznek P100 alapú Geforce-ot bemutatni.
-
stratova
veterán
válasz
Oliverda
#18990
üzenetére
Igen ahogy Kaveri Carrizo közötti eltérés.

Csak gondolom mivel Polaris már szintén (ahogy intel 22 nm-től) FinFET mindkettővel variálnak.Szerintem értelmezzük úgy hogy más a tranzisztorok helyigénye attól függően, hogy mire optimalizálnak igy maga a tranzisztor keret más adott lapkaméreten, nagy sűrűségre vagy nagy teljesítményre optimalizálva.
[ Szerkesztve ]
-
stratova
veterán
válasz
#45185024
#19014
üzenetére
Ég veled Pictrain (egyáltalán nem baj, hogy nem kapta meg az 5. nevét) és Tonga. Mondjuk Cape Verde (ő viszont igen...) és Oland is elmehete már nyugdíjba.
[M290X XT, M290 / M390 Pro] Pictarin -> Polaris 11
[M390X/M395X XT, M395 Pro] Tonga -> Polaris 10cain69 nem nem azok de ettől még Radeonról szól a hír.
[ Szerkesztve ]
-
stratova
veterán
De miért ne duplázhatnák most ők is a ROP-ot a la Maxwell?
Bár nekem a 256 bit GDDR5 még mindig kicsit sovány ha csak nem 7 GHz-en ketyeg, de a minták nem ennyin mentek. Ha mindezt meglépnék akkor illene valahol, GTX 980 szinten lennie a kisebbik Polaris 10-es kártyának (Videocardz-nak honnan jött a 4 variáns?), ha minden klappol és a color compression is legalább Maxwell szinten van.[ Szerkesztve ]
-
stratova
veterán
Pedig már a hivatalos közlés előtt is látszott egyes oldalak/fórumok elemzése szerint, hogy eredetileg 6x64 bites csatornával készült:
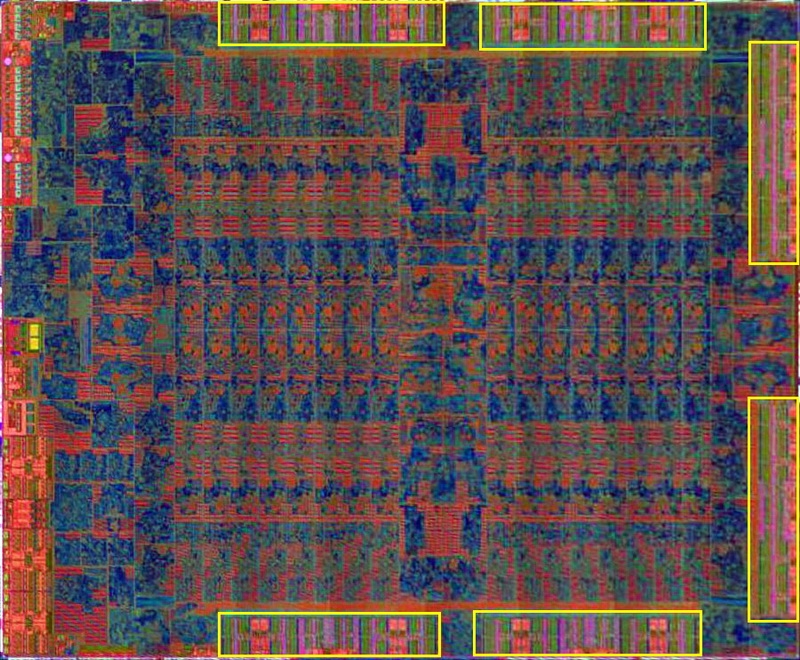
De ha nem lenne független, hogyan készíthetnek volna 1280:80:32 256 bites Pitcraint-t és 2048:128:32 384 bites Tahitit?
Gondolom akkor vetették volna be, ha készül egy asztali GTX 960 Ti, aminek "ideális alap" lett volna a GTX 970M (10 SMM 1280 SP 80 TMU 48 ROP 192 bit GDDR5). Bár itt Tonga 32 ROP egysége még mindig karcsú lett volna.
[ Szerkesztve ]
-
#19209
stratova
veterán
Petykemano
#19208
stratova
veterán
válasz
 Petykemano
#19208
üzenetére
Petykemano
#19208
üzenetére
Nem nekem szólt a kérdés de a GCN kártyacsalád pláne Tahiti abszolút svájci bicska volt AMD-nél, készült belőle compute: Firepro S, ws: Firepro W, gamer: Radeon termék és vélhetően inkább arra költötték a tranzisztor-keretet, ami mindenhol hasznosul, de a nagyobb haszonnal eladható professzionális piacon mindenképpen.
Ezzel szemben Maxwell kifejezetten az asztali és mobil (notebook) piac igényeihez lett igazítva, miközben a profi piacon vele párhuzamosan sokáig csak Kepler futott, amely ott egy frissítést is megélt (GK210). Csak később vezette be Nv a profi piacra Maxwellt de ott is javarészt Keplert mintegy kiegészítendő, más területeket célozva.[ Szerkesztve ]



 az már igen, hogy több átnevezést él meg mint az asztali variáns.
az már igen, hogy több átnevezést él meg mint az asztali variáns. ], hogy eddig GT 920M ill. GT 940M-mel szerelte őket Lenovo és most cserélné R5 M430 ill. R7 M460-re. Utóbbi esetében az Oland alapú R7 360M már eleve 1125 MHz-re lett "feltekerve" így a GPU-nak túl sok mozgástere nincs. Ellenben csak 64 bites DDR3-mat kapott, ezt illene cserélni. Pl. ha emelt órajelű R7 M370 [870 MHz] lenne (ua. lapka 128 bites GDDR5-tel) az M460 (és ez lenne a minimum, hogy ne legyen teljes visszalépés 940M után). Esetleg az R7 M365-öt (Oland + 128 bit DDR3) fokozzák le egy kicsit.
], hogy eddig GT 920M ill. GT 940M-mel szerelte őket Lenovo és most cserélné R5 M430 ill. R7 M460-re. Utóbbi esetében az Oland alapú R7 360M már eleve 1125 MHz-re lett "feltekerve" így a GPU-nak túl sok mozgástere nincs. Ellenben csak 64 bites DDR3-mat kapott, ezt illene cserélni. Pl. ha emelt órajelű R7 M370 [870 MHz] lenne (ua. lapka 128 bites GDDR5-tel) az M460 (és ez lenne a minimum, hogy ne legyen teljes visszalépés 940M után). Esetleg az R7 M365-öt (Oland + 128 bit DDR3) fokozzák le egy kicsit.















 Egész szépen összeszedted egyébként.
Egész szépen összeszedted egyébként.



Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

- Pcie 5.0 ATX 3.0 12Pin - 16Pin Moduláris Tápkábelek És Adapterek 12VHPWR Egyedi Harisnya Nvidia
- BESZÁMÍTÁS! EVGA RTX 3080Ti XC3 ULTRA HYBRID 12GB GDDR6X videokártya garanciával hibátlan működéssel
- PowerColor RX 6700 XT 12GB GDDR6 RED DEVIL Eladó! 99.900.-
- Zotac RTX 4080 16GB GDDR6 Gaming AMP Extreme AIRO - Új, 2 év garancia - Eladó!
- EVGA RTX 3060 Ti 8GB GDDR6 FTW3 ULTRA GAMING Eladó! 92.000.-
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest