Az NVIDIA elképzelése
Az NVIDIA a mai nappal útjára indította legújabb GPU-generációját, a GT200-as kódnevű – nem túlzás, ha azt mondjuk – szörnyet, amely a másfél éves G80 után végre valóban előrelépést jelent, ellentétben az utóbbi időszak nem túl figyelemfelkeltő termékbevezetéseivel (vö. GeForce 9800 GTX). Forradalmi újításról azonban nem beszélhetünk, bár ez nem is csoda, hiszen a mérnökök mozgástere az utóbbi időben erősen beszűkült. A GT200-at úgy is fel lehet fogni, mint egy óriási, a piac egészét tekintve feleslegesen nagy és komplex grafikus processzort, de annak jelét is láthatjuk benne, hogy az NVIDIA biztosra akart menni az inkább a presztízs, mint az eladások miatt fontos csúcskategóriában. Az mindenesetre biztos, hogy a chip új fejezetet nyit ebben a szegmensben, az pedig több mint érdekes, hogy a készítők nem a GeForce 9800 GTX G92-es lapkájához hasonlítgatják a GT200-at, hanem az öregebb GeForce 8800 GTX alapját képező G80-hoz, ezzel is beismerve, hogy igazi fejlesztéseket jó ideig nem végeztek.
A GT200 le sem tagadhatná származását, igazán NVIDIA-s megoldásokat vonultat fel, elsősorban a szimpla erőre, a számok törvényére támaszkodik: „a több az gyorsabb, azaz jobb”. Az új generáció képviselőinek bemutatása és a tesztek előtt a GT200 architekturális újításaival foglalkozunk, a lényegi fejlődés egyes pontjait próbáljuk meg lehetőleg érthető módon tálalni. Jó, ha tisztázzuk már az elején, hogy a GT200 alapjában véve nagyban a G80-ra épül, ezért a fejlesztések megértéséhez elengedhetetlen, hogy ha nagy vonalakban is, de tisztában legyen az olvasó a G80 felépítésével.

A GT200 lényegében az NVIDIA második generációs unified shader, azaz egységesített shader architektúrája. Ez annyit jelent, hogy a GPU-ban nem különálló pixel és vertex feldolgozókat találunk, hanem olyan kis egységeket, az NVIDIA szóhasználatában stream processzorokat, melyek pixel és vertex, illetve a DirectX 10-ben bemutatkozó geometriai shaderek kiszámolására egyaránt alkalmasak. Ennek lényege, hogy a stream processzorok folyamatosan és egyfolytában teljes terhelés alatt képesek működni, nem fordulhat elő olyan eset, amikor egy vertex shaderekre jobban támaszkodó (játék)jelenetben a pixel shaderek pihennek, és fordítva. Az NVIDIA a GT200 elé azt tűzte ki célul, hogy a G80-nál akár kétszer gyorsabb legyen, bár a sebességnövekedés arányai az egyes komponensek és feladatok esetében (shaderek, ROP egységek, textúrázás stb.) eltérőek lehetnek.
Ismerve a G80 paramétereit (128 stream processzor, 32 textúracímző, 64 szűrő, 6 ROP blokk, 384 bites memóriabusz) ez nem tűnik bonyolult feladatnak; duplázzuk meg a különböző egységek számát – gondolná a laikus –, és meg van oldva. Ez azonban nyilvánvalóan nem ilyen egyszerű, hiszen vannak gyártástechnológiai korlátok, meg kell felelni a gyártás műszaki és gazdaságossági feltételeinek, illetve már a tervezéskor figyelembe veszik az előző generációval szerzett tapasztalatokat – minek például egy adott részegység számát megduplázni, ha egyszer már a korábbi mennyiség is bőven elegendő? Akkor tehát mit lehet tenni? Növeljük bizonyos részegységek számát (lehetőleg azokét, melyekből előreláthatólag többre lesz majd szükség), optimalizáljuk a jelenlegi működést, majd „reménykedjünk”, hogy a játékipar abba az irányba tart, ahol a mi architektúránk optimálisan működik. Az NVIDIA ezt tette.
Az NVIDIA igen szoros kapcsolatot tart fenn a játékfejlesztőkkel, és nem mellékes, hogy a diszkrét grafikus kártyák piacán vezető pozícióban van, ezért joggal feltételezi azt, hogy a jövőben megjelenő játékcímek az ő hardverét semmiképpen sem fogják hátrányos megkülönböztetésben részesíteni. Gondoljunk csak a DirectX 10.1-re, amit a Microsoft és az AMD is próbál nyomni, propagálni, de az NVIDIA továbbra sem támogatja ezt a kiterjesztést. Állítják, hogy a GT200 tervezése során fontolóra vették a DX 10.1 támogatásának implementálását, de miután konzultáltak a vezető játékfejlesztő cégekkel, elvetették az ötletet, mert azok úgy nyilatkoztak, hogy a DX10 kiterjesztése nem lényeges, ezért aztán inkább az architektúra sebességét csiszolták tovább.
Rátérve az architektúra főbb jellemvonásaira, illetve az újításokra, nézzük címszavakban, hogy mire számíthatunk:
- a GeForce 8800 GTX teljesítményének kétszerese,
- egy kiegyensúlyozottabb architektúra, mely a jövő játékait gyorsabban futtatja,
- a geometriai shader, illetve stream output teljesítményének javulása a DirectX 10-es játékok miatt,
- jelentősen továbbfejlesztett számítási kapacitás a CUDA alkalmazások és a fizika kiszámítása miatt,
- a teljesítmény/fogyasztás hányadosának javulása.
A felsorolásból látható, hogy az első négy szempont lényegében egyazon paraméterhez kötődik, és ez a teljesítmény.
Belső változtatások
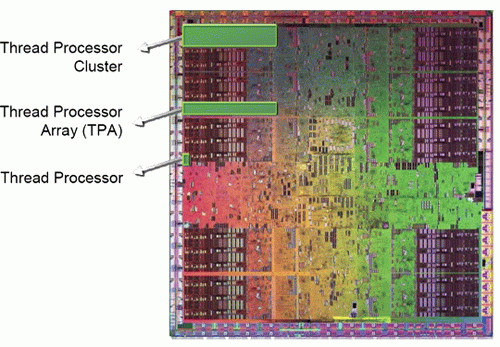
A G80-ra visszaemlékezve felsejlik, hogy a GPU úgynevezett TPC-ket, azaz Thread vagy Texture Processing Clustereket tartalmazott, ezekből is nyolcat. Ezek a TPC-k egyenként két-két darab SM-et, azaz streaming multiprocesszoros tömböt tartalmaztak, melyekben egyenként nyolc-nyolc darab SP, azaz stream processzor, illetve változó darabszámú textúrázó egység volt megtalálható (a G80-ban négy címző és nyolc szűrő, ez később megváltozott 1:1 arányúra). A GT200-ban a TPC-k száma 8-ról 10-re, az SM-ek száma 2-ről 3-ra nőtt, azaz a GT200 összesen 240 stream processzort működtet (10 TPC x 3 SM x 8 SP). A TPC-ken belül megtalálható textúracímzők és szűrők aránya a GT200-ban is 1:1 maradt, TPC-nként nyolc-nyolc darabról beszélhetünk. A számok bűvöletében élőket az eddig felsoroltak nem túlságosan győzhették meg, hiszen csak a stream processzorok és textúrázók száma nőtt, ráadásul ez a megnövelt érték is kevesebb, mint a korábbi csúcs duplája. Szerencsére ez csak a felszín, az architektúra rengeteg további finomhangolást és kiegészítést tartalmaz.

Először is a TPC-k vezérléséért, ütemezéséért felelős részt jelentősen kiokosították, ami elsősorban abban érhető tetten, hogy a G80-énál több szálat képes kezelni. A G80-ban található ütemező SM-enként 768 szálat, míg a GT200-ban található SM-enként 1024-et képes vezérelni, így mivel több az SM és több a kezelt szál, a GT200 ütemezője a G80-énál közel 2,5-szer több szálat kezel egyszerre (12 288 vs. 30 720). Minél több szálat kezel a GPU, annál kevesebb a futószalagban található „buborék” (pipeline stall) miatt bekövetkező várakozás, ami például memóriaelérések (illetve arra való várakozás) során bekövetkezhet, hiszen amíg az egyik szál vár, addig az ütemező egy másik szálat aktiválhat (a Hyper-Threading is valahogy így működik, csak kicsiben).
A GPU GP (general purpose), azaz általános célú felhasználásával kapcsolatos adottságait is továbbfejlesztették. Tudni kell, hogy a G80/GT200-ban található TPC-k között a MIMD (több utasítás, több adat) feldolgozás a jellemző. Ezzel szemben az SM-ek között nem a SIMD, hanem a SIMT, tehát egy utasítás, több szál megvalósítás található. Az NVIDIA azért ezt a megoldást választotta, mert így nincsenek belekényszerítve a SIMD-ek esetén használatos vektorok szélességének állandó korlátaiba. Mivel nem vektoralapú az adatfeldolgozás, a stream processzorok teljes kihasználtsággal tudnak működni, nem fordulhat elő olyan eset, hogy például a három szélességű vektor csak két adatot tartalmaz, így egy „hely” elveszik. A G80-ban található SM-ek 24 elemből álló (szál)láncokat (warp) tudnak feldolgozni, ezzel szemben a GT200 SM-jeinek az IU-ja (instruction unit, nevezhetjük ütemezőnek is) akár a 32 elemű láncokkal is képes elboldogulni.
Az SM-ekben található IU részeként megjelenő regiszterfájl méretét a GT200-ban megduplázták, így a hosszabb shaderkódok végrehajtása esetén ritkábban kell a memóriához nyúlni. Még mindig a TPC-nél (illetve annak egyes részeinél) tartunk, így itt kell megemlíteni, hogy a produktívabb ütemezésnek hála a textúrázás is hatékonyabb lett, az NVIDIA szerint 22%-kal múlja felül elődjét.
Ha már a méretekről esett szó, a GT200 a geometriai shader számolásban is megpróbál valami újat felmutatni. A G80 esetében ez a terület egy tabutéma, ugyanis a G80-ban nagyon kevés a rendelkezésre álló gyorstár vagy regiszter. Mint láthattuk, a regiszterfájlok méretét kiterjesztették, de ezen felül a stream outputként funkcionáló gyorsítótárak méretét is nem kevesebb, mint hatszorosára növelték. Hogy ez az érték pontosan miként oszlik el, arról nincs információnk (annyi biztos, hogy az SM-ekben található lokális memória mérete nem változott, maradt 16 kB), de itt sem szabad elsőre ámulatba esnünk: a GT200 87,5%-kal több SP-t tartalmaz, így pedig a tényleges, SP-számra vetített gyorsítótárméret-növekedés „csak” 320%-os. Ez sem kevés, de azért mégsem 600%. Ezzel kapcsolatban az NVIDIA az általunk is használt Rightmark3D HyperLight geometriai shader tesztjével példálózik, belsős tesztjeik szerint a GT200 a Radeon HD 3870 X2-t is megveri 15–20%-kal. Na majd meglátjuk...

Méretarányos megjelenítés
napjaink egyik csúcsprocesszora (Penryn/Wolfdale, a Core 2 Duo E8000-esek alapja) és a GT200
Nem esett még szó a GT200 elméleti maximális számítási kapacitásáról. Tudvalevő, hogy a chip megjelenése előtt a fórumokon világszerte repkedtek a teraFLOPs-os teljesítményről szóló pletykák, de 100%-ig biztosan senki sem tudta, hogy ebben a tekintetben az AMD vagy az NVIDIA lesz-e a nyerő. Az NVIDIA annak érdekében, hogy ne okozzon csalódást, itt is fejlesztett egy kicsit. A G80 esetében egy stream processzor egyszerre egy MAD (a=b*c+d) és egy MUL (a=b*c) műveletet tud végrehajtani 32 bites lebegőpontos számokon, ez 1350 MHz-es órajel mellett 518 gigaFLOPs-os teljesítményt jelent, amikor a 8800 GTX megjelent, ez egy szinte felfoghatatlan szám volt. A GT200 esetében ezt az értéket feltornászták egészen 933 gigaFLOPs-ig, amit úgy értek el, hogy a special function unitok (SFU), melyekről a G80 esetében nem esett túl sok szó (trigonometrikus és transzcendens matekot, illetve attribútuminterpolálást tudnak), a stream processzorokkal párhuzamosan (tehát egy órajelen belül) egy MUL végrehajtására képesek. Az architektúrát a támogatott precizitás tekintetében is továbbfejlesztették, a GT200 már támogatja a 64 bites (kétszeres pontosságú) lebegőpontos adattípusokat is.
A raszterizálókhoz, azaz ROP egységekhez is hozzányúltak, a legfontosabb, hogy a számukat megnövelték hatról nyolcra (érdekes ez az összehasonlítás, a G92-es chipben már csak négy ROP volt, amiből anno arra következtettünk, hogy az NVIDIA többé nem különösebben törődik az élsimítással). A ROP egységek fejenként és órajelenként 4–4 pixel kirajzolására képesek, ez azt jelenti, hogy a GPU 32 pixel/órajeles ütemmel működik (a G80 24 pixel/órajel). Árnyékkezeléskor, amikor csak Z-értéket kell számolni, az új NVIDIA chip a ROP egységek számának növekedése miatt elődjénél több, egyszerre 256 pixelt (8 x 32) tud elővarázsolni. A 8 bites nem negatív egész számokat (unsigned integer) a GT200 a G80 sebességének kétszeresével képes „blend”-elni (keverni).
Az NVIDIA a G80-nal kezdődően egy-egy ROP partícióhoz köt egy-egy 64 bites memóriacsatornát, ebből következően a GT200 immár 8 x 64, azaz 512 bites memóriabusszal rendelkezik (így alapjáraton 1 GB memóriát pakolnak mellé). Az NVIDIA továbbra sem tud elszakadni az kissé idejétmúltnak tűnő crossbar memóriavezérlőtől. A gyártó a kártya áttervezése során a textúrázók számának megnövekedése miatt optimalizálta a textúrázás során elérhető memória-sávszélességet, illetve számos optimalizációt hajtott végre a memóriavezérlőn, aminek az lett az eredménye, hogy magasabb órajelet képes elérni, és fejlettebb tömörítési eljárásokat használ.
Videokártya, nem csak játékra

Tekintettel az új GPU számítási teljesítményére, az NVIDIA a megszokottnál is jobban igyekszik hangsúlyozni, hogy ezek a videokártyák már nemcsak szimplán játékra használatosak, hanem a 2007 februárjában bejelentett CUDA fejlesztői platformnak köszönhetően hathatós segítséget nyújtanak különböző számításigényes feladatokban is, úgy mint a tudományos kutatások, szimulációs modellek, komputeres vizualizáció, video- és képfeldolgozás, illetve fizikai gyorsítás. Az átlagfelhasználók számára talán közelebb hozza ezt az egész témát, ha azt mondjuk, hogy egy sok párhuzamos számolót alkalmazó GPU (mint amilyen a GT200) egy processzornál nagyságrendekkel gyorsabb, ha filmkonvertálásról van szó (az NVIDIA ezt a RapidHD nevezetű programmal támogatja). A másik érdekesség a Folding@Home számolás, melyhez az NVIDIA szintén kínál GPU-támogatású programverziót. Általánosságban elmondható, hogy egy szimpla processzorhoz képest egy GPU-val a legtöbbször több tízszeresére, de nem ritkán akár egy-kétszázszorosára is gyorsulhat egy adott számítási feladat végrehajtása. Ennek az az egyszerű magyarázata, hogy a unified shader architektúrákban alkalmazott számolók immár a leggyakrabban alkalmazott adattípusokkal képesek elboldogulni, és így ha például egy GT200-at veszünk alapul, és csak a végrehajtó egységek számát nézzük (240), egy közel 1,5 GHz-es órajelen járó Pentium I-es processzor 240-szeres kapacitásáról beszélhetünk. Kicsit visszatérve a fizikára, az NVIDIA ígéretet tett rá, hogy a GeForce-ok (a 8-astól kezdődően) egy hónapon belül támogatni fogják a hardveres fizikaszámolást is, csak a meghajtóprogram hiányzik hozzá, a platform természetesen a felvásárolt Ageia PhysX lesz.

A teljesítménytől függetleníthető szempont a fogyasztás. A videokártyák területén ebben a tekintetben ezidáig az AMD járt előrébb, ugyanis az RV670 köré épülő Radeonok a PowerPlaynek hála viszonylag keveset fogyasztanak, hiszen üresjáratban visszaveszik a GPU órajelét. De ez a megoldás sem tökéletes, rejlik még benne némi potenciál, elvégre a memória fogyasztása is csökkenthető lenne, és a processzorokhoz hasonlóan a GPU-nak sincs szükség minden területére, elég lenne csak annyit bekapcsolva hagyni, ami éppen elég a megjelenítéshez – ez lenne a tökéletes megoldás. Az NVIDIA még ennyit sem tudott felmutatni egészen mostanáig, a G92, illetve elődei semmilyen energiagazdálkodási sémát nem ismernek, nem véletlenül született meg a Hybrid Power.
A GT200 ezen a területen is változásokat hoz magával. Egy olyan chip lett, amely már hasonlóan a processzorokhoz többféle, pontosabban négy különböző energiagazdálkodási módot ismer: üresjárat/2D, Blu-Ray videolejátszó mód, 3D-s mód, illetve a Hybrid Power mód. A dokumentumok szerint a GPU (nem az egész videokártya) üresjáratban mindössze 25 wattot fogyaszt, ezt pedig annak köszönheti, hogy elsőként a GPU-k világában támogatja a chip egyes részeinek lekapcsolását, amikor nincs azokra szükség. Logikus, csak tudnánk, hogy erre miért kellett 2008 közepéig várni? Azt nem ismerjük pontosan, hogy milyen területek válnak inaktívvá, de a chipen belül van bőven redundancia, tehát van mit lekapcsolni, gondolunk itt a sok TPC-re, melyek közül 2D-re bőven elég egy darab, a ROP-ok közül is elég egy (és akkor már a memóriachipeket is le lehet kapcsolni) stb. Mozi üzemmódban a GPU állítólag 35 wattal is beéri, de hogy ne legyen felhőtlen az örömünk, a 3D-s fogyasztás nem kevesebb, mint 236 watt, egy átlag HTPC fogyasztásának 3–5-szöröse, és még csak a videokártyáról beszélünk. Szóval azért van még hova fejlődni, igaz, a 65 nm-es gyártástechnológiától nem várhatunk mást, állítólag a GT200 utódja már készülőben van 55 nm-en.
Mire számíthatunk?
Összefoglalva a látottakat, nem ért minket meglepetés. Az NVIDIA azt az utat folytatja, amit másfél évvel ezelőtt elkezdett, a G80 továbbfejlesztett változatával indul harcba az AMD következő generációs, a pletykák szerint RV770-nek keresztelt GPU-jával szemben. Hogy az iszonyatos mennyiségű tranzisztor mire lesz elég, egyelőre nem tudjuk, a G80 sebességének megduplázására van némi esély figyelembe véve a felsorolt fejlesztéseket, de mint általában, úgy most is játékfüggő lesz az elvárható teljesítmény. Az AMD már évek óta afelé hajlik, hogy a textúrázást háttérbe szorítja a számolás (shader), ám ez idáig nem valósult meg – legalábbis nem olyan mértékben, ahogy azt az AMD várta. Egyebek mellett ennek tulajdonítható, hogy GPU-i máig nem képesek befogni a rivális NVIDIA chipjeinek előnyét. Mindkét cég keze benne van a dologban. Az AMD (illetve az ATI) túl korán, túlságosan előre fejlesztett, márpedig ez így ebben a formában nem működik, amikor a videokártyák piacán a konkurencia szava a döntő. A versenytárs pedig nem arra készült fel, amit az AMD minél hamarabb látni szeretett volna... Most talán megváltozik a trend, ugyanis a GT200-ban az ALU:TEX arány, azaz a számolók és textúrázók aránya még inkább az ALU-k felé tolódott el, az NVIDIA mindezt megtoldotta számos optimalizációval, melyek a geometriai shader teljesítményt javítják, így lényegében, ha kimondatlanul is, de zöld utat adott a játékfejlesztőknek ebbe az irányba. Már csak az a kérdés, hogy erről mit gondolnak majd a G80/G92-re épülő videokártyák tulajdonosai?
Összehasonlító táblázatunkban összefoglaltuk a már ismert paramétereket, melyek, mint láttuk, nem mondanak el mindent, de nagy vonalakban azért látható, hogy mi várható a chiptől.




