Bevezető
Az Intel a 2004-es év folyamán kénytelen volt belátni, hogy az eredetileg rendkívül magas órajelek elérésére kifejlesztett NetBurst architektúra napjai meg vannak számlálva, a szivárgási áram olyan gondokat okozott (magas fogyasztás és hőtermelés), melyekkel még a világ legnagyobb chipgyártója sem volt képes megbirkózni. Szerencsénkre ez a fordulat egyben a többmagos központi egységek eljövetelét is jelentette, hiszen mindkét processzorgyártó úgy vélte, hogy a jövő a párhuzamos adatfeldolgozásé. Az Intel először egy gyorsan összedobott Pentium D-vel (Smithfield) rukkolt ki (ekkortájt még az volt a központi kérdés, hogy az AMD vagy az Intel fog hamarabb kétmagos processzort bemutatni), melyben két Pentium 4-es core volt "összedrótozva", majd később a Presler kódnéven ismert újabb kiadású Pentium D-ben az ötlet továbbfejlesztése volt megtalálható, ezúttal a tok alá két különálló processzormagot zsúfoltak be (egyszerűbb és költséghatékonyabb gyártás). Ugyanakkor a Presler egyben a 2000-ben megjelent NetBurstre épülő processzorok utolsó zászlóvivője is lett, hiszen az Intel már gőzerővel egy új mikroarchitektúra bevezetésének utolsó simításait végezte, ami végül a Core nevet kapta.

Az Intel Core egy teljesen új fejlesztése az Intel-architektúrákon alapuló asztali, mobil és szerver multi-core processzoroknak. Ez a több magra optimalizált, energiahatékony felépítésű architektúra a megnövelt teljesítmény, illetve teljesítmény per fogyasztás jegyében született. Elődjének a mobilplatformra kifejlesztett Pentium M tekinthető, azt persze rengeteg újítással és továbbfejlesztéssel megfűszerezve.
Érdekes módon most, hogy az Intel egy teljesen új felépítésű CPU-családot vezet be, kiemelkedő fontosságú tényezővé lép elő a processzor, illetve a rendszer fogyasztása, és a fejlesztők dokumentumok tucatjain keresztül magyarázzák mindenféle csili-vili képlettel kiegészítve, hogy a teljesítmény nem csak az órajeltől, hanem az órajelenként végrehajtott utasítások számától is függ. Emlékezzünk csak vissza, ugyanez az Intel 2000-től 2005-ig, a kétmagos processzorok megjelenéséig azt állította, hogy csakis a megahertzek számítanak, vegyünk minél magasabb órajelű processzort, annál jobb lesz nekünk, mindeközben a Pentium 4 processzorok fogyasztása 130 watt fölé emelkedett; ez persze akkor nem volt lényeges kérdés... Micsoda fordulat!

Conroe (balra az óriási L2 cache)
Az Intel szerint az új képlet mostantól: teljesítmény = órajel x órajelenként végrehajtott utasítások (IPC) száma. Az AMD már az Athlonok megjelenését követően erre az álláspontra jutott, mégsem vették komolyan a kisebb processzorgyártót, mert az Intel sokkal nagyobb befolyással bír. Ez a képlet végeredményben a MIPS (million instructions per second) értékének meghatározása, tehát kimondhatjuk, hogy az Intel ismét feltalálta a spanyolviaszt... Azonban napjaink egyre fejlettebb processzorai esetében ez a képlet már nem állja meg a helyét, mert a teljesítmény másképpen is fokozható, mint az órajel vagy az IPC növelése. Vannak még különböző módszerek, mellyekkel ugyanez a "hatás" érhető el, gondolunk itt arra, hogy például bizonyos módszerekkel csökkenthetjük a végrehajtandó utasítások számát, így végeredményben nő az egységnyi idő alatt végrehajtott utasítások száma (lényegében ugyanoda lyukadunk ki), ezt hivatottak elősegíteni a Single Instruction Multiple Data (SIMD) utasításkészletek is, mint amilyen az 1996-ban bevezetett MMX-technológia, vagy a később bevezetésre kerülő SSE, SSE2, SSE3, 3DNow!, 3DNow!+ is, és ugyanezt a nemes feladatot látja el a Pentium M-ben debütáló Micro-Ops Fusion, avagy mikroutasítások fúziója is. Erről később még szó lesz.
A teljesítmény kifejezésére már van egy képletünk, azonban ez még nem elegendő, mert ezúttal a rendszer fogyasztása is központi szerepet tölt be, így ezt is meg kell határozni valamilyen módon. Az Intel szerint a képlet: fogyasztás = áramköri elemek száma x feszültség x feszültség x órajel. Mindez mit is jelent? Ahhoz, hogy processzorunk minél kevesebbet fogyasszon, meg kell próbálni a felvett feszültséget csökkenteni (hiszen a feszültségtől négyzetesen függ a fogyasztás), a processzor órajelét meg kell próbálni alacsonyan tartani (ami persze nem olyan egyszerű, hiszen az alacsonyabb órajel egyet jelent az alacsonyabb teljesítménnyel is), és meg kell próbálni – amennyire csak lehet – leszorítani a működő alkatrészek számát, ami szintén nem egy szimpla feladat, elvégre napjaink csúcsprocesszoraiban (pl. Pentium EE 965) már 300 milliónál is több tranzisztor található.
A lecke fel van adva, lássuk, hogy az Intel fejlesztőmérnökeinek hogyan sikerült válaszolniuk a kihívásokra.
WDE, ADMB
Az Intel a Core mikroarchitektúrában megpróbálta vegyíteni a Pentium 4-gyel debütáló NetBurst és a Pentium M-ben bemutatkozó mobil-mikroarchitektúra előnyeit. A Pentium M az 1995-ben bemutatkozó Pentium Pro (P6) leszármazottjának tekinthető, és igen alacsony fogyasztásával, illetve órajeléhez képest magas teljesítményével emelkedett ki a tömegből, míg a NetBurst szintén hozott magával jó néhány újítást, melyeket az Intel sajnált a kukába dobni (Quad Pumped Bus, SIMD utasításkészletek).
Kicsit térjünk ki az Intel P6-ra, amely az x86-os világ hatodik mikroprocesszor-architektúrájaként vonult be a történelembe. A P6 elsőként a szerverekbe szánt Pentium Próban mutatkozott be 1995-ben (!), és lényegében a P5 (azaz Pentium) utódjának tekinthető. A P6 a világon elsőként alkalmazta a következő technológiákat:
- superpipeline-elvű megvalósítás; a Pentium futószalagjának hosszát 5-ről 14 lépcsősre fejlesztették (a Pentium 3-ban 10, a Pentium 4-ben 20, majd 31 lépcsős futószalag található), ezzel elérték, hogy a feldolgozás (utasítás behívás, dekódolás és regiszter behívás, végrehajtás, eredmény visszaírás) több lépcsőben hajtódjon végre. Minél több lépcsős a futószalag, azaz minél egyszerűbb részegységekből épül fel, annál magasabbra emelhető az órajel,
- először integrálták a lapkára a másodszintű (L2) gyorsítótárat, amely a processzor órajelén futott, ellenben a korábbi processzorokkal, melyeken az L2 cache a magon kívül (alaplapon) volt megtalálható, és a magfrekvencia bizonyos hányadán működött,
- szélesebb, 36 bites fizikai címzést tett lehetővé, így 4 GB-nál nagyobb méretű memória vált megcímezhetővé (a lineáris címzés továbbra is max. 4 GB maradt),
- bemutatkozott a spekulatív és soron kívüli (out-of-order) végrehajtás, előbbi lényege, hogy elágazásoknál az elágazásbecslő (hatékonyságát 75-ről 90%-ra javították) eredménye alapján folytatódik a végrehajtás abban a reményben, hogy az előrejelzés jó volt. Ha jó volt, akkor a CPU sok-sok ciklusnyi időt takarított meg, ha nem, akkor kénytelen a másik ágon újrakezdeni a végrehajtást, ami a futószalag hossza miatt nagy kiesést jelent. Az OoOE lényege, hogy a feldolgozás során az utasítások végrehajtása folyamatos akkor is, ha egyes utasítások számára az operandusok még nem állnak készen, hiszen a végrehajtó egység végén egy "tárolóban" (reorder buffer) a műveleti végeredmények kivárják, hogy a programkódban előttük található, de később operandushoz jutott utasítások eredményeit átvegyék a regiszterek. Ez csökkenti a futószalag-várakozásokat, és magasabb órajelek elérését teszi lehetővé (jobb skálázódás),
- megjelent a Reservation Station, egy ütemezőként is funkcionáló puffer, ami végrehajtandó utasításokat tárol, és bonyolult algoritmusok segítségével próbálja meg a végrehajtó egységek étvágyát kielégíteni, lehetőleg úgy, hogy ne alakuljanak ki várakozások,
- regiszter-átnevezés (register renaming), amellyel hatékonyabbá vált a parancsok végrehajtása, hiszen a regiszter-függőséget csökkentette (korábban "a" utasítás nem tudott az "x" regiszterbe írni, mert a "b" utasítás szintén "x" regiszterbe akart írni, de "a" parancs még nem futott le). A regiszter átnevezés engedélyezi, hogy egy architektúrális regiszterre egy belső regiszter által is hivatkozhatunk, így mindkét utasítás lefuthat egymástól függetlenül, majd amikor az első utasítás végrehajtódott, a virtuális regiszterből az adatok átkerülnek az architektúrális regiszterbe. A függőségeket, instrukciókat a ROB tárolja. Tekintve, hogy az x86 kevés regiszterrel rendelkezik, ez egy kulcsfontosságú újítás,
- itt mutatkozott be a GTL+ rendszerbusz is, amely azóta sem tűnt el az Intel processzorokból (Pentium Pro-P3: GTL+, Pentium 4-től AGTL+). Ennek jellemzői 66-133 MHz-es órajel, 64 bites szélesség, amin a rákapcsolódó processzoroknak osztoznia kell (bár ekkortájt még nem ez volt a szűk keresztmetszet), egyirányú adatforgalom (100 MHz-es órajel esetén 800 MB/s-os átvitel), az adatátvitel során 8 bites ECC hibajavító kód küldése.
A P6 architektúra alacsony hőtermeléséről, magas integerteljesítményéről és magas IPC-jéről volt ismert, amit a Pentium 4 bevezetésével az Intel lényegében eltemetett – most pedig újra előásta azt.
A Core esetében a chipgyártó (majdnem) minden, a NetBurstben és P6-ban megtalálható nemkívánatos elemet kizárt, majd öt főbb újítást eszközölt, és így megszületett egy teljesen új generáció, a Core.
A Core mikroarchitektúra öt legfőbb újítása a következő:
- Intel Wide Dynamic Execution
- Intel Advanced Digital Media Boost
- Intel Advanced Smart Cache
- Intel Smart Memory Access
- Intel Intelligent Power Capability
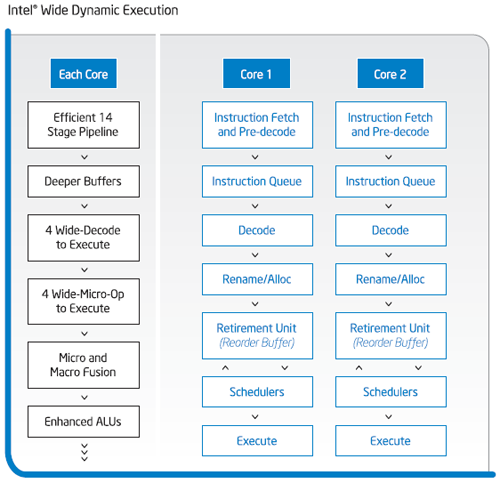
Intel Wide Dynamic Execution
[+]
A Dynamic Execution (dinamikus végrehajtás) olyan technikák kombinációja (többszörös elágazásbecslés, adatfolyam-elemzés, spekulatív végrehajtás), melyet az Intel anno a P6-ban mutatott be (Pentium Pro). A Pentium 4-ben a Dynamic Execution továbbfejlesztett változatát, az Advanced Dynamic Execution névre keresztelt verziót találhattuk, amely egy igen mély, továbbfejlesztett spekulatív elágazásbecslésű (out-of-order speculative execution) engine lett, mellyel még tovább csökkent az elhibázott elágazásbecslések száma a Pentium III-ban találhatóhoz képest.
A Core esetében az Intel ezt a részegységet ismét továbbfejlesztette, így megszületett a Wide Dynamic Execution. Ez órajelenként több utasítás végrehajtását teszi lehetővé (wide = széles), aminek hatására gyorsul a végrehajtás sebessége és javul a fogyasztási mutató. Az Intel Mobile és NetBurst mikroarchitektúra (és a K8 is) egy időben három x86-os utasítás végrehajtására/dekódolására képes, ezzel szemben a Core már négyet (egyes esetekben ötöt, lásd későb Macro-Ops Fusion) tud elvégezni. Ennek következtében azonos órajeleket feltételezve a Core minden valószínűség szerint gyorsabb, mint az előzőleg felsorolt architektúrák, már amennyiben a 16 byte széles előbehívó elegendőnek bizonyul ehhez. A hatékonyság további növelése érdekében még pontosabb lett az elágazásbecslő és nagyobbak lettek az utasításpufferek is. A Pentium III 10 lépcsős és a Pentium 4 (Northwood) 20, illetve 31 (Prescott) lépcsős futószalagjával ellentétben a Core-ban 14 lépcsős pipeline-ok találhatóak.

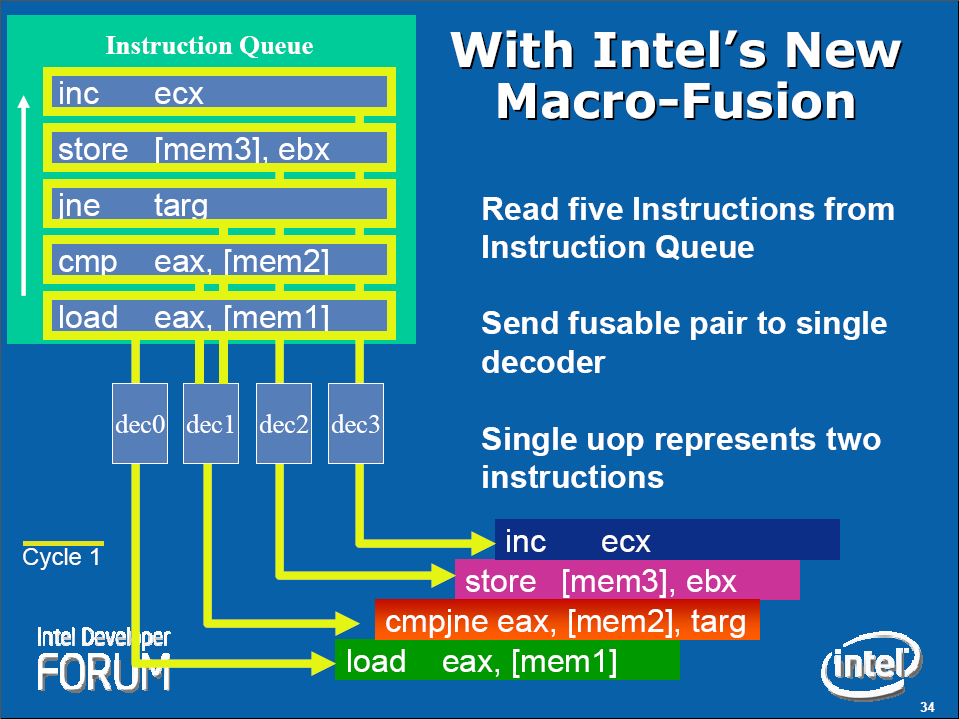
Korábban volt szó a Micro-Ops Fusionról, melynek egy továbbfejlesztett változata is megtalálható a Core-ban, illetve egy Macro-Fusion névre keresztelt technológia is elősegíti a processzor hatékonyságát. Az előző generációs processzorokban az utasítások egyenként hajtódtak végre, azonban a Macro-Fusion segítségével a Core az olyan gyakori x86-os utasításpárokat (macro-op), mint pl. cmp és jmp összevonhatja egyetlen utasításba (micro-op), ezzel pedig csökken a processzorra háruló munka, így adott idő alatt nő az elvégzett utasítások száma (ciklusonként akár 4+1).
A mikroutasítások fúziója (Micro-Ops Fusion – a Pentium M-ből ered) révén a Core képes több olyan mikroutasítást újra összefűzni (fuzionálni), melyek eredetileg egy macro-op-ból származnak (a Core a macro-opokat, azaz x86-os utasításokat micro-opokra bontja le, mielőtt elküldené őket a futószalagnak feldolgozásra), ezzel csökkentve a micro-opok számát. A micro-opok számának csökkentése hatékonyabb ütemezést és magasabb teljesítményt tesz lehetővé alacsonyabb energiaigény mellett. Egyes kísérletek szerint a micro-op fusion a soron kívüli végrehajtást végző logika által kezelt micro-opok számát 10%-kal képes csökkenteni.
[+]
Végül, de nem utolsósorban továbbfejlődött az ALU-egység is (Aritmethic Logical Unit), amely elősegíti a Macro-Fusion sikeres működését.
Intel Advanced Digital Media Boost

A nevéből (továbbfejlesztett digitális médiagyorsítás) is sejthető, hogy a következő újítás azokkal az utasításkészletekkel foglalkozik, melyeket ezidáig Streaming SIMD Extension (SSE) néven ismertünk. Ezek az utasítások oroszlánrészt vállalnak az olyan feladatok elvégzésében, mint pl. videó-, zene- vagy képszerkesztés, kódolások, konvertálások és minden olyan program, melyek kihasználják az SSE-utasításkészletek által felkínált lehetőségeket. Ezek a 64 vagy 128 bites integer és lebegőpontos operandusok csökkentik az összes végrehajtandó utasítás számát (egy vektorban vagy tömbben eltárolt összes adaton egyszerre hajtódik végre egy utasítás), így növekszik a teljesítmény. Az előző CPU-generációkkal volt egy probléma, ugyanis ezidáig egyetlen 128 bites SSE utasítás végrehajtásához két órajelciklusra volt szükség, hiszen ezek az egységek csak 64 bites feldolgozásra lettek felkészítve. Ezzel szemben a Core a 128 bites SSE operandusokkal már egyetlen órajelciklus alatt végez, ami a korábbi processzorokhoz képest kétszeres gyorsulást jelent, amennyiben 128 bites SSE utasításokkal dolgozik a processzor (64 bites utasítások esetén a Core 4, a K8 pedig 3 kalkulációval tud végezni órajelenként). A Core mikroarchitektúrára építkező processzorokat az Intel felvértezte egy új, SSSE3 nevű utasításkészlettel (SIMD) is, amely állítólag a soha meg nem jelent Tejasban debütált volna eredetileg (TNI-ként is ismert, azaz Tejas New Instructions), és 16 új utasítást tartalmaz:
- PSIGNW, PSIGND, PSIGNB
- PSHUFB
- PMULHRSW, PMADDUBSW
- PHSUBW, PHSUBSW, PHSUBD
- PHADDW, PHADDSW, PHADDD
- PALIGNR
- PABSW, PABSD, PABSB
ASC, SMA, IPC
Intel Advanced Smart Cache

Az Advanced Smart Cache (továbbfejlesztett intelligens gyorsítótár) nem más, mint a Core processzorokban található megosztott, továbbfejlesztett gyorsítótár "beceneve". Intelligens (smart) elnevezését annak köszönheti, hogy a Core-ban a másodlagos gyorsítótáron a két processzormag megosztozik. Az Intel úgy fejlesztette ki az L2 cache-t, hogy ahhoz a két mag bármikor hozzáférjen, tehát a Core esetében már nem a rendszerbuszt terheli a két cache közötti adatforgalom. Ez a megoldás egyrészt csökkenti az adatokhoz való hozzáférés idejét (csökkenti a késleltetést), csökkenti a cache-koherencia szűréséből adódó adatforgalom mértékét (tehát nagyobb sávszélesség marad a hasznos adatok számára), másrészt hatékonyabbá teszi a helykihasználást, hiszen nem kell duplikálni az adatokat ahhoz, hogy mindkét processzormag számára elérhető legyen. A Core processzorok modelltől függően összesen 2 vagy 4 MB L2 cache-en osztoznak, ezt a végrehajtó egységek dinamikusan osztják fel egymás között, tehát erősen többszálú alkalmazások esetében a fentebb vázolt pozitívumokban részesülünk, a gyorsítótár attól függően kerül felosztásra, hogy az egyes végrehajtó egységek milyen gyakran szeretnének hozzáférni a gyorsítótárban található adatokhoz. Ugyanakkor az egyszálon végrehajtott alkalmazások során az egyik processzormag abban a megtiszteltetésben részesülhet, hogy egyedüliként használhatja akár az egész másodszintű gyorsítótárat (ha a másiknak éppen nincs rá szüksége).
Intel Smart Memory Access
A Smart Memory Access (intelligens memóriaelérés) égisze alatt két új technológiával ismerkedhetünk meg. Az egyik az Advanced Pre-fetch, amely továbbfejlesztett előbehívást jelent. A prefetcherek detektálják az alkalmazások adatmozgatási sémáit, és a gyakran igényelt adatokat gyorsabban elérhetővé teszik (beteszik a cache-be), ezzel csökkentve a memóriakésleltetést. A Core processzorokban összesen 8 prefetcher található (magonként 4), 2-2 db az L1 (ezek képesek szimultán több sémát is kezelni) és L2 (magonként több sémát is képesek követni) gyorsítótárban. A prefetcherek folyamatosan figyelik, hogy mikor milyen adatokra van szükség, és ennek megfelelően irányítják az adatforgalmat.

Az Advanced Pre-fetchen kívül a Smart Memory Access-t egy továbbfejlesztett Memory Disambiguation (egyértelműsítés) nevezetű technológiával is felvértezték, amely a soron kívüli (out-of-order) algoritmusok írási és olvasási hatékonyságát próbálja meg növelni azáltal, hogy a LOAD műveleteket a STORE-ok elé helyezi (lényegében a memóriaműveleteket újrarendezik a gyorsabb végrehajtás érdekében). Erre azért van szükség, mert nem lehet tudni, hogy az egymást követő LOAD és STORE műveletek függenek-e egymástól (azaz ugyanazon memóriacímre/regiszterre/stb. hivatkoznak-e). A Core architektúra elődeihez mérten akár 30-40%-kal is gyorsabb lehet abban az esetben, ha az algoritmus jól "jósolt", és az adatok közötti függőségben ez a "kavar" nem okoz galibát később (vagyis a LOAD utasítással előretöltött adattól a később meghívásra kerülő STORE nem függ). Ha viszont a művelet nem végződik sikeresen, a Memory Disambiguation detektálja a problémát, visszatölti az eredeti adatokat és újraindítja a kódot.
A Memory Disambiguation nem önmagában fejti ki csodálatos hatását, hanem a Core processzorok továbbfejlesztett előbehívóival (Advanced Pre-fetch) karöltve alkot egy komolyan előremutató újítást, utóbbi ugyanis képes előre megjósolni, hogy milyen adatokra lesz szükség a későbbiekben, ami pont kapóra jön a Memory Disambiguation számára. Ez a páros jelentősen képes növelni a processzor és a memória közti kommunikáció hatékonyságát (később látni fogjuk).
Intel Intelligent Power Capability
Az IIPC (intelligens energia-vezérlés) olyan tulajdonságok gyűjtőneve, melyek a hőtermelés kordában tartásáért felelősek.
- Ultra fine-grained Power Control (precíz energiavezérlés): a processzormagok kihasználatlan részei egyszerűen leállhatnak, miközben a mag más részei még dolgoznak. Itt nem az egész magról van szó, hanem annak egyes részeiről!
- Split Buses: a processzormagok és a belső adatbuszok feloszthatóak több kisebb részegységre, melyeket így egymástól elkülönülve tud vezérelni (ki-be kapcsolni) egy vezérlőáramkör.
- Platformization of Power Management Architecture, három részből tevődik össze:
- PSI-2 vagyis Power Status Indicator (mobil CPU-k): a processzor jelzi a rendszer felé a terhelést, így együttesen képesek optimalizálni a feszültségszabályzó áramkör és a leadott teljesítmény hatékonysági mutatóit.
- DTS (Digital Thermal Sensor): a processzorban immár nem egy, hanem több hőszenzor található, melyek a processzor minden egyes részén külön-külön felügyelik a hőmérsékletet, ezzel a precíz mérési metódussal pedig tovább tökéletesíthetőek a különböző hőmérsékletszabályozási sémák (az alaplapgyártókon sok múlik).
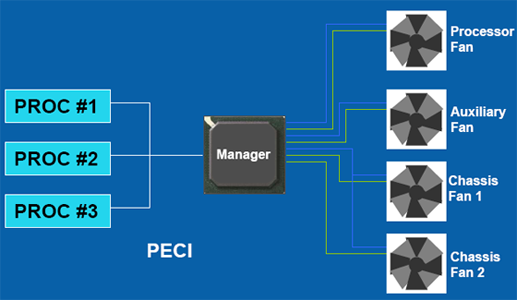
- PECI Interface (Platform Environment Control): a processzor képes egy külön erre a célra tervezett chipen keresztül a hőmérséklettől függően szabályozni a rendszer többi elemét is (ventilátorok).
Összegezve és összehasonlítva
Az új architektúra tehát a következő főbb részletekben tér el az elődtől, Core Duótól (Yonah):
- továbbfejlesztett utasításdekóder, az x86-os macro-opok száma 4-re nőtt (a Core Duóban 3 van),
- a 128-bites SIMD utasítások végrehajtása duplájára gyorsult a Yonah-hoz képest, mivel egy utasítás hajtódik végre ciklusonként,
- jelentősen továbbfejlesztett prefetch,
- az L2 cache a két mag számára megosztott, a mérete dinamikusan változik az egyes magok terhelésének függvényében (ez már a Core Duóban is így volt),
- jobb energiatakarékossági technológiák,
- új SIMD utasításkészlet támogatása (SSSE3).
A Core 2 és Athlon 64 X2-es processzorok összehasonlítása:
| Processzor | Core 2 Duo (Extreme) | Athlon 64 X2 (FX) |
| Órajel | 1866-2933 MHz | 2000-2800 MHz |
| Támogatott memória | DDR2-800 | DDR2-800 |
| Gyártástechnológia | 0,065 µ | 0,09 µ SOI |
| Tranzisztor (millió) | 291 (Conroe) | 227 vagy 154 (Windsor) |
| Magméret (mm2) | 143 (Conroe) | 230 (Windsor) |
| L1 cache | 2 x 32 kB adat és 32 kB utasítás (8-utas) | 2 x 64 kB adat és 64 kB utasítás (2-utas) |
| L2 cache | 2 vagy 4 MB megosztott (16-utas; 256-bit) | 2 x 512 KB vagy 2 x 1 MB (16-utas; 128-bit) |
| SIMD | MMX, SSE, SSE2, SSE3, SSSE3 | 3DNow!, MMX, SSE, SSE2, SSE3 |
| Rendszerbusz órajele | 266 MHz FSB - 1066 MHz QPB | 1000 MHz HyperTransport |
| Feszültség | 0,8500 - 1,3625 V | 1,025-1,40 V |
| Maximális fogyasztás | 75 W (Extreme), 65 W (Duo) | 125 W (FX-62), 89 vagy 65 W |
| Architektúra | Core | K8 |
| Futószalag hossza | 14 lépcső | 12/17 (integer/float) lépcső |
| x86-végrehajtók száma | 4 | 3 |
| FP-végrehajtók | Multiply+Add+Load+Store(+1) | Multiply+Add+Store |
| SSE-végrehajtók száma | 3 (128-bit) | 2 (64-bit) |
A két teljesen eltérő processzor jelen pillanatban kb. ugyanabban a frekvenciatartományban tartózkodik. Mindkét processzor a DDR2-es platformot támogatja, azon belül is legfeljebb a DDR2-800-as memóriákat. Gyártástechnológia terén egyelőre jobban áll az Intel, hiszen már 0,065 mikronon gyártja a Core 2-es processzorokat, míg az AMD a már jól bejáratott 0,09 mikronon futtatja Athlon 64-eit. Ez az Intel számára igen jelentős előny, hiszen alacsonyabb csíkszélességgel kisebb az előállítási költség és alacsonyabb a hőtermelés is. A Conroe magmérete 143 mm2, ami jóval kisebb a Windsor magos Athlon 64 X2-énél (ez eleve 0,09 mikronon készül), és kisebb két Cedar Mill magnál (162 mm2) is (ami egyébként a Preslernek felel meg).
A gyorsítótárak esetében is jelentős különbségek vannak, L1 cache-ben például első látásra jobban áll az Athlon 64, hiszen duplaannyi memóriát tartalmaz, mint Core 2-es ellenfele. Azonban a Core 2-ben 8-utas, az Athlon 64-ben pedig 2-utas csoportasszociatív cache található, ennek következtében pedig jóval kevesebb a cache-miss (magasabb a találati arány) a Core 2-es rendszerekben. Általános szabály, hogy az asszociativitás megduplázása 4-utasig felér a cache megduplázásával, efölött már viszont nem ez a jellemző. A Core 2-ben kétszer vagy négyszer annyi L2-es cache található, mint az Athlon 64 X2-ben, ráadásul a sávszélesség is duplája ellenfelének (256-bit vs. 128-bit), és ha még ez sem lenne elég, akkor meg kell említenünk, hogy a Core 2-ben a gyorsítótár dinamikusan oszlik fel a magok között: ezen a területen egyértelmű fölényben van a Core 2.
Az utasításkészletek terén is az Intel áll jobban, hiszen a Core 2 már ismeri az SSSE3-at (valószínűleg az AMD is át fogja venni). A 64-bites utasításkészletet (EM64T vagy x86-64) mindkét architektúra támogatja. A feszültséget tekintve mindkét processzor kb. azonos tartományban tartózkodik, igaz, a Core 2 üresjáratban megelégszik 0,85 volttal is, ebben az esetben pedig (órajelcsökkentéssel együtt) a TDP értéke 65-75 wattról leesik 20-22 wattra. Az Athlon 64 egyelőre itt is le van maradva, hiszen a leggyorsabb FX-62 125 wattos maximális fogyasztással kerül forgalomba, és az alacsonyabb órajelű példányok is 89, esetenként 65 wattot (Energy Efficiency modellek) fogyasztanak. Ha az AMD átáll a 0,065 mikronos gyártásra, akkor a Core 2-nek ez az előnye valószínűleg el fog tűnni.

[+]
A rendszerbuszt nem véletlenül hagytuk a végére, ugyanis ez az egyetlen pont, ahol a Core – elméleti síkon – egyértelmű lemaradásban van a K8-cal szemben, és itt nem a maximális sávszélesség kérdésére gondolunk, ami első látásra a Core 2-nek kedvez, hiszen 8,53 GB/s, míg az Athlon 64-nél 8 GB/s. Az AMD a K8-as processzorok esetében azt a HyperTransport buszt használja, melyet ő maga fejlesztett ki, majd a HyperTransport konzorcium tagjaival együtt finomított tovább. Ez a szó szoros értelmében nem egy rendszerbusz (FSB), hanem egy nagyon magas órajelű, csomagalapú, chipből-chipbe összeköttetés, amely 16 vagy 32 biten továbbítja az adatokat. Ezzel szemben az Intel azt a GTL+-ból (Gunning Transceiver Logic) továbbfejlesztett AGTL+ nevű rendszerbuszt használja, amely a Pentium Próban szerepelt először, most, 2006-ban. Miért is baj ez? A busz maximális órajele 266 MHz, és csak az adatbusz négyszeres sebességű, azaz 1066 MHz-es. A cím- és parancsbusz még mindig csak 266 MHz-en jár, kétirányú, de nem full-duplex, ami azt jelenti, hogy adott órajel alatt az adat/cím/utasítás-folyam egyszerre csak egy irányba mozoghat. Természetesen az adatok egy időben ide-oda szeretnének vándorolni, így az a tény, hogy egyidejűleg csak egy irányba mehetnek, igencsak visszafoghatja az új Intel processzorokat.
Ez a probléma egyprocesszoros környezetben még nem ütközik ki, azonban amikor 2, 4, esetleg 8 processzoros szerverekről van szó, az AGTL+ busz már korlátozó tényező lehet az amúgy igen impozáns felépítésű Core magok számára. Valószínűleg az Intel is jól tudta ezt, amikor kiadta a Bensley platformot (Intel 5000P és 5000V chipset), melyek két egymástól független rendszerbuszt biztosítanak a processzorok irányába, így azoknak nem kell megosztozniuk egymással egyetlen busz szűkös sávszélességén. Ez azonban csak egy átmeneti megoldás lehet, ezért mi azt gondoljuk, hogy a K8 szerverekben valószínűleg jobban fog skálázódni a HyperTransportnak köszönhetően (ez főleg 2, 4, esetleg 8 processzoros szerverekben lesz érezhető).
Tesztkonfiguráció és fogyasztás
| Processzor megnevezése | Órajel | L2 cache mérete | FSB | TDP |
| Core 2 Extreme X6800 | 2,93 GHz | 4 MB | 266 MHz | 75 W |
| Core 2 Duo E6700 | 2,66 GHz | 4 MB | 266 MHz | 65 W |
| Core 2 Duo E6600 | 2,4 GHz | 4 MB | 266 MHz | 65 W |
| Core 2 Duo E6400 | 2,13 GHz | 2 MB | 266 MHz | 65 W |
| Core 2 Duo E6300 | 1,86 GHz | 2 MB | 266 MHz | 65 W |
Az Intel ezúttal 5 processzort indít útjára. A csúcskiépítés továbbviszi az Extreme megkülönböztető jelzőt, és Core 2 Extreme néven kerül a boltokba, az egyszerű CPU-k pedig a Core 2 Duo nevet kapták. Az első kiadású Extreme verzió csak és kizárólag magasabb órajele miatt lett Extreme, egyes pletykák szerint a döntés hátterében az Intel magabiztossága áll, hiszen az AMD-t ez az egyszerű, órajelemelt CPU is szinte megoldhatatlan feladat elé állítja, így felesleges lett volna azonnal egy olyan Extreme processzorral előrukkolni, amiben pl. nagyobb az L2 cache, vagy még ennél is magasabb az órajel (pl. 3,13 GHz), netán az FSB (333 MHz). Mások szerint az Intel nem képes ennél magasabb órajelű példányt gyártani egyelőre. A kérdés irreleváns, a teljesítmény a lényeg.
A Core 2 processzorok sem órajel szerint lesznek megkülönböztetve, hanem egy modellszám alapján. A Core 2 márkanév mögött egy Exxxx vagy Xxxxx jelölés látható, az E betüjel után található szám határozza meg egy adott típus besorolását a családba, míg az X jelöli az Extreme verziót (T - mobil CPU). Idővel elképzelhető, hogy megjelenik egy új Extreme processzor, ekkor valószínűleg az X6800-asat átnevezik E6800-ra, és a legújabb Extreme felveszi az X6900 jelölést.
| LGA775-ös tesztrendszer | Core 2 Extreme X6800, Core 2 Duo E6700, Pentium D 950 processzorok Intel D975XBX alaplap (BIOS 2006.06.01.1340) Intel Chipset Driver v7.2.2.1007 2 x 512 MB Corsair TwinX1024-8000UL DDR2-1000 - 4-4-4-10 |
|||||
| Socket AM2-es tesztrendszer | Athlon 64 X2 5000+, 4600+, 4200+, 3800+ processzorok MSI K9N SLI Platinum alaplap (BIOS v080014) NVIDIA Unified Driver 9.34 Beta 2 x 512 MB Corsair TwinX1024-8000UL DDR2-1000 - 4-4-4-10-1T |
|||||
| Videokártya | ASUS EN7900GT TOP (520/720 MHz) | |||||
| Videokártya-driver | NVIDIA Forceware 84.21 | |||||
| Merevlemez | Maxtor Diamondmax 10 250 GB (PATA; 7200 rpm; 16 MB cache) | |||||
| Operációs rendszer | Windows XP Professional Service Pack 1 + DirectX 9.0c | |||||
| Tápegység | Cooler Master RS-550-ACLY | |||||
A szerkesztőségben két Core 2 processzor landolt, egy Extreme X6800 és egy Duo E6700. Sajnos nem kaptunk E6400-at, ami azért fájó pont, mert ebben már csak 2 MB az L2 cache, kíváncsian vetettük volna össze azonos órajelen a Core 2 processzorokat különböző cache-méretekkel. Talán majd máskor...

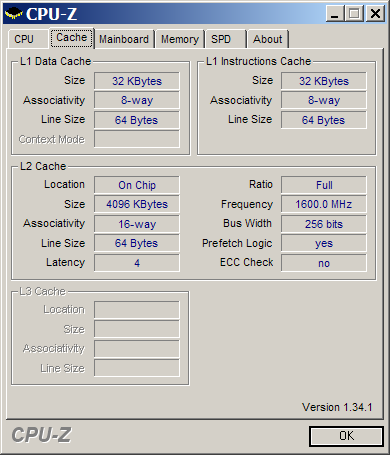
Intel Core 2 Extreme X6800 üresjárat / terhelve / cache[+]

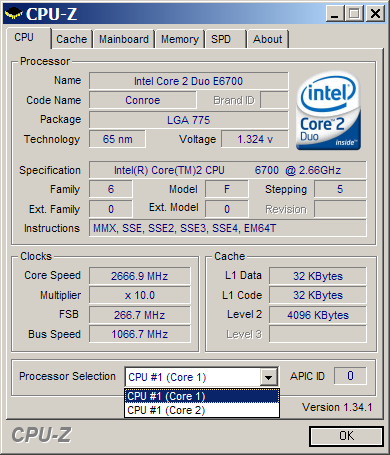

Intel Core 2 Duo E6700 üresjárat / terhelve / cache[+]
A processzorok mellé egy Intel DB975XBX alaplapot kaptunk, a rendelkezésünkre álló 975X chipsetes lapok nem indultak el az új processzorokkal. Ez sajnos rossz hír minden i975X és ennél gyengébb chipsettel szerelt laptulaj számára, mivel nagy valószínűség szerint csak a legújabb gyártású alaplapok fogják támogatni a Conroe-t. A Core 2 processzorokkal való kompatibilitásnak két feltétele van, egyrészt a 266 MHz-es FSB támogatása (legalább 925, 945, 955, 975, 965 chipsetek), másrészt az alaplapot a gyártónak már a VRM 11-es specifikációkban foglaltak szerint kell legyártania (alacsonyabb támogatott feszültségek, kisebb lépésközönkénti feszültségemelés). Ha az adott alaplap a két feltételnek eleget tesz, akkor képes a Core 2 fogadására.
Visszatérve a Core 2-höz, a túlhajtás terén nem lettünk sokkal okosabbak, mivel az Intel lap BIOS-ában nincs lehetőség az FSB-emelésre, ezért csak a szorzó változtatásával tudtunk órajelet emelni. Amit sikerült megállapítanunk, hogy az X6800 képes volt alapfeszültségen a 3,2 GHz-es órajelet stabilan vinni (ez eggyel nagyobb szorzót jelent), viszont 13-as szorzóval már nem volt stabil a rendszer (3466 MHz) még 1,45 V-on sem. A processzort egy Pentium D 950-es gyári hűtője hűsítette.

A tuningpróbálkozások után lemértük a rendszerek fogyasztását. A Core 2-es processzorokat tartalmazó rendszerek üresjáratban 8 watt különbséggel 90 watt alatt maradtak. Sajnos nem tudjuk, hogy az EIST valójában működött-e, ugyanis bár az alaplap BIOS-ában bekapcsoltuk, és a CPU-Z képei szerint működött is, utólag kiderült, hogy a CPU-Z 1.34-es verziója még nem kezeli jól ezeket a processzorokat, tehát az is lehet, hogy a mért értékeket még mindig maximális órajel mellett kaptuk. Ha lesz nálunk megint Conroe, akkor megvizsgáljuk a kérdést. Terhelve a két Core 2-es processzorral szerelt rendszer közel ugyanannyit fogyasztott, viszont ez a két érték (135 és 132 watt) több mint 10%-kal alacsonyabb, mint amit az Athlon 64 X2 5000+ rendszerrel mértünk (151 watt). Fogyasztás terén tehát jól áll a Core 2.
DDR2-667 vs. DDR2-800
| Core 2 Extreme X6800 | ||
| Memória sebessége | DDR2-667 | DDR2-800 |
| Everest memóriaolvasás | 6403 MB/s | 7011 MB/s |
| Everest memóriaírás | 3901 MB/s | 3953 MB/s |
| Everest memóriakésleltetés | 64,3 ns | 59,5 ns |
| 7-Zip (mp) | 95 | 90 |
| WinRAR (mp) | 48 | 45 |
| Mainc. MPEG Enc. - AVI->MPEG2 (mp) | 79 | 78 |
| AutoGK XviD - MPEG->AVI (mp) | 93 | 93 |
| XMpeg + DivX - MPEG->AVI (mp) | 60 | 57 |
| WME9 - MPEG->WMV (mp) | 67 | 66 |
| QuickTime - MPEG->MP4 (mp) | 72 | 71 |
| Lame MT - WAV->MP3 (mp) | 79 | 78 |
| 3ds max (mp) - MAX Scanline render | 55 | 54 |
| 3ds max (mp) - V-Ray render | 63 | 60 |
| 3ds max (mp) - Mental Ray render | 48 | 48 |
| 3ds max (mp) - Brazil Rio render | 67 | 66 |
| Lightwave (mp) - Skull Head Newest | 66 | 66 |
| Lightwave (mp) - Teapot | 57 | 57 |
| Maya (mp) | 40 | 40 |
| Cinebench 9.5 pontszám | 905 | 908 |
| Photoshop (mp) | 64 | 64 |
| Quake 4 fps - 1280x1024 HQ | 133 | 135 |
| Far Cry fps - 1280x1024 HQ | 147 | 149 |
| Half Life 2 fps - 1280x1024 HQ | 145 | 147 |
| F.E.A.R. fps - 1280x960 HQ | 177 | 181 |
| Tomb Raider Legend fps - 1280x1024 HQ | 145 | 146 |
A processzorokat összevető tesztek előtt kíváncsiak voltunk, hogy a memória sebessége milyen mértékben befolyásolja egy Core 2-es rendszer teljesítményét. Ugyanis jól tudjuk, hogy a Pentium 4-es rendszerek (és leszármazottai) sebessége igen komoly mértékben függött a memória sebességétől egy bizonyos határig, asztali használatra azonban a DDR400/DDR2-533-as memóriáknál gyorsabb modulokkal nem tudtunk kimutatni érzékelhető gyorsulást.
A Core 2 Extreme X6800-as processzor mellé először a jelenleg még a legelterjedtebb DDR2-667-es, majd később a még csak aranyárban kapható DDR2-800-as memóriákat tettük. Az Everest memóriatesztjében szemmel látható a változás, a memóriaolvasás értéke 9%-ot, a késleltetés pedig 8%-ot javult. Ez – mint később kiderült – a memória sebességétől leginkább függő alkalmazásokban (tömörítés és játékok) okozott némi javulást, máshol azonban elhanyagolható a különbség. Ez jó hír azok számára, akik az olcsóbb Core 2 Duo processzorok megjelenésére várnak.
Memóriasebesség, tömörítés


Everest alatt a Core 2 processzorok memóriaolvasásban közel azt az értéket futották, amire az AM2-es Athlon 64 is képes. Érdekes módon az Athlon 64 X2-esek esetében az órajel növelésével gyorsult a memória elérése is, ez a programfejlesztő magyarázata szerint annak köszönhető, hogy az Athlon 64-ben a cache és a core közötti adatbusz valószínűleg szűk keresztmetszetet képezett a rendszerben, mivel ez egy 64 bit széles adatbusz, amelynek az áteresztőképessége függ az órajeltől.
A memóriakésleltetési értékek is igen érdekesen alakultak, ezen a téren az Athlon 64-ek továbbra is élen járnak, de a Core 2 Duo megközelítette az eddig megközelíthetetlennek hitt integrált memóriavezérlővel felszerelt CPU-kat 8-17 %-ra, annak ellenére, hogy a Core 2 processzorok is a chipseten keresztül kommunikálnak a memóriával, ahogyan a Pentium D is. A magyarázat a korábban már tárgyalt prefetcherekben keresendő, az Intel nagyon jó munkát végzett!
Az elkövetkezendőkben az E6600-as Core Duo 2 teljesítményét az X2 4600+ eredményeihez hasonlítgatjuk, mivel mindkét processzor 2,4 GHz-es órajelű.

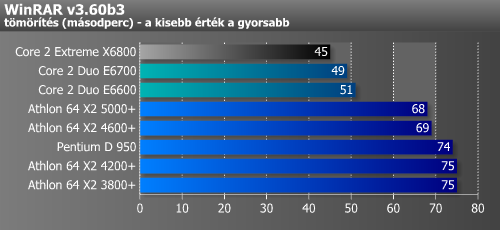
A tömörítések tipikusan memóriasebesség-függő alkalmazások, ennek tudható be, hogy az Athlon 64 X2 3800+ és 4200+, illetve a 4600+ és 5000+ párosok közel azonos eredményt futnak (lásd az AM2 memóriavezérlőjét). Ezúttal már a WinRAR-nak is olyan verzióját használtuk, amely támogatja a többprocesszoros működést. A Core 2 Duo kb. 35%-kal gyorsabb az Athlon 64 X2-nél.
Konvertálás-kódolás
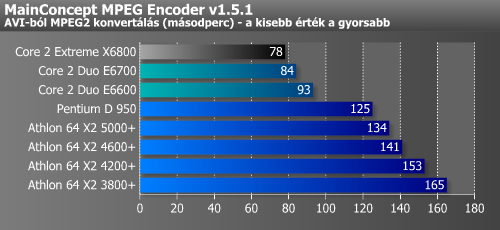
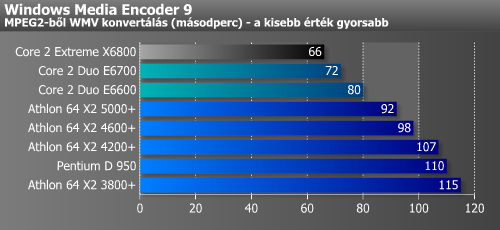




A következőkben multimédiás programokat futtattunk, melyek kihasználhatják a Core 2-ben rejlő "Advanced Digital Media Boost" nyújtotta előnyöket. Ezek az alkalmazások jellemzően stream (folyam) jellegű adatmozgatással járnak. Itt a Core 2 Duo előnye 20-50% az A64 X2-vel szemben.
Renderelés
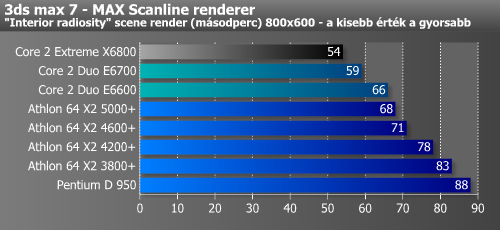

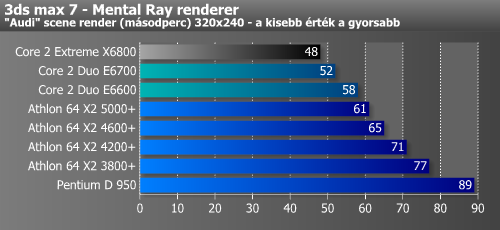
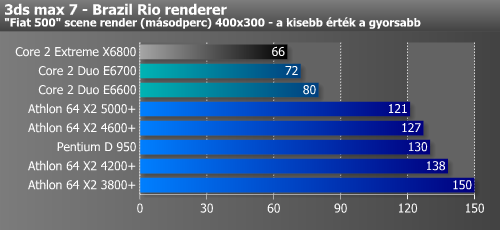
Érdekes módon a 3ds max 7 első három pluginjével kaptuk a legszorosabb eredményeket, az Athlon 64 X2 ezekben az esetekben csak 7-12%-kal maradt le a Core 2 Duótól. Ennek szöges ellentéte a Brazil Rio render, melyben sokkoló, majdnem 60%-os különbséget mértünk.
Renderelés (folyt.), Photoshop


Lightwave alatt két scene-t szoktunk lerenderelni, ezek közül a „skull head newest” a fényszóródásra koncentrál, míg a „Teapot” scene ray-tracinget számol. 15-22%-os a Core 2 Duo előnye.

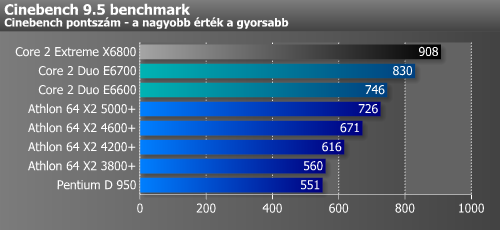
Maya és Cinebench 9.5 alatt 29, illetve 11%-kal bizonyult gyorsabbnak a Core 2-es rendszer azonos órajelet feltételezve.

A Photoshop-szkript lefutásának sebessége nagyban függ a memóriától és a merevlemeztől is, a Core 2 Duo ennek ellenére 17%-kal gyorsulta le az Athlon 64 X2-t.
Játékok

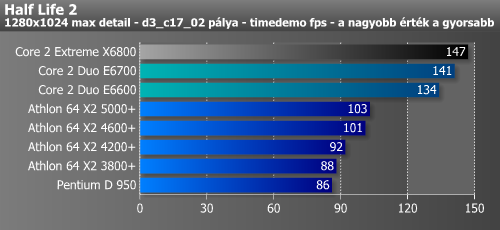
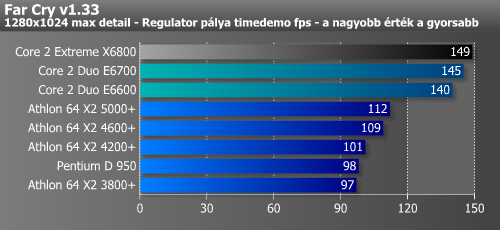

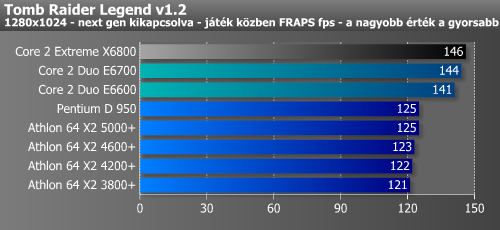
Lássuk a játékokat; minden esetben 1280x1024-es felbontást teszteltünk. Ez egy processzorteszt, ezért az élsimítást nem kapcsoltuk be, bár a Core 2 Duo eredményei nélkül nagyon úgy tűnt, hogy több játékban is VGA-limitbe ütköztünk, végül az új CPU-k eredményeinek ismeretében ez csak egy kósza gondolat maradt. A Conroe az összes játékban fantasztikusan szerepelt, még a Tomb Raider Legendben is 12%-kal gyorsabb volt az Athlon 64 X2-nél, pedig ez a játék látva az fps-értékeket teljes mértében VGA-limitesnek tűnt (az összes korábbi CPU-val 121-125 fps-t mértünk). A többi játékban a Core 2 Duo előnye 20-35%. A videokártyák teszteléséhez platformot kell váltanunk...
Értékelés

Az Intel Core alapú processzorok rendkívül meggyőzően teljesítettek. A Core 2-esek minden tesztben verték aktuális ellenfelüket, nem egyszer már megalázó mértékben, azonban volt egy terület, ahol nem szerepeltek "annyira" kimagaslóan, ez pedig a 3D-modellezés. Sejthető, hogy ezek az alkalmazások főleg az FPU-t veszik igénybe, és nem mintha gyengének találnánk az eredményeket, de látható, hogy létezik egy terület, ahol a K8-nak is van még keresnivalója. A tömörítő, konvertáló, kódolóprogramok és a játékok alatt viszont a Core 2 dominált, a nagy átlagot tekintve 20-25%-os a Core architektúra teljesítménybeli előnye a K8-cal szemben, ez pedig óriási különbség.
A sok technológiai specifikáció, a sok újítás, amire az ember először csak legyint egyet, egy csapásra értelmet nyer, amikor azt érzi, hogy a keze alatt futó Core 2-es rendszer gyorsabb, mint egy Athlon 64 X2-es. Ez pedig igen nagy szó, mert eddig az AMD viselte a koronát, de most hosszú idő után ismét kénytelen lesz átadni helyét az Intelnek; addig legalábbis egészen biztosan, amíg nem jelenik meg a K8L, a K8 továbbfejlesztett változata. Az AMD-nek szüksége is lesz már a frissítésre, mert 3 éven keresztül az órajelet tekintve egy helyben toporgott és a processzorban található újításokat végignézve sem túlságosan erőltette meg magát (SSE3, kétmagos processzorok, DDR2-es memóriavezérlő, virtualizáció és slusszpassz), igaz, eddig nem is volt rákényszerítve, hiszen az Intel sem produkált semmi kiugrót.
Most azonban ugyanez az Intel totális támadásba lendül át, a Pentium D processzorokat leárazza, de olyan mértékben, hogy az AMD-nek esélye se legyen. 100 dollár alá esik a Pentium D 805 (!), és 200 dollár alá esik az összes 950-esnél lassabb Pentium D, illetve a Core 2 Duo E6300. Az AMD-nek erre olyan árcsökkentéssel kell válaszolnia, amit biztosra vehetően meg fog sínyleni, hiszen még mindig a gazdaságtalanabb 0,09 mikronos gyártástechnológiával készülnek az Athlon 64-esek, melyek ráadásul már sokkal kevésbé versenyképesek a Core 2 Duóval (azonos órajelet feltételezve) szemben, mint a Pentium D-kkel szemben voltak.
Az AMD most igen nagy bajba kerülhet, ha nem képes sürgősen átállni a 0,065 mikronos gyártástechnológiára. A kisebb csíkszélesség egyet jelent a processzorok gyártási költségeinek leszorításával, ami jelen pillanatban az egyetlen kiút lehet számára, már ha nem akar több, profitot hozó év után ismét veszteséget termelni, hiszen a szükségszerű árcsökkentések után aligha marad nyereséges az Athlon 64-ek eladása. A kisebb csíkszélesség emellé még alacsonyabb hőtermelést és magasabb órajelek elérését is lehetővé teszi, amire jelen állás szerint szüksége is lesz az Athlon 64 X2-nek.
Ami tetszett:
- alacsony fogyasztás,
- nagyon gyors,
- még annál is gyorsabb,
- kiforrott chipkészletek.
Ami nem tetszett:
- nem tudjuk az itthoni árát.
 |
| Intel Core 2 Duo |
fLeSs
A tesztben szereplő Core 2 processzorokat az Mmd PR Hungary-től kaptuk.


