K8-tól K12-ig - a szintetikus eredmények tükrében
Első körben szintetikus méréseket végeztünk a négy különböző processzorral és platformmal. Ehhez az AIDA64 nevű programot hívtuk segítségül. Először az L1D cache sebességét néztük meg.

Látható, hogy itt a K10 óta gyakorlatilag szinte semmilyen változás nem történt, igaz, ez az azóta véghezvitt módosítások listájának ismeretében nem is túl meglepő.

Itt is az iméntihez hasonló a felállás. A K8->K10 váltáskor megejtett, L1 és az L2 közötti buszszélesség megkétszerezésének hatása jól látszik, de azóta ehhez a területhez nem nyúltak, aminek köszönhetően nem is történt semmi említésre érdemes.

Az L1 cache késleltetése a K8 óta azonos. Az L2 cache hozzáférési ideje a K8-ról K10-re váltáskor csökkent, míg a K12 esetében 4 tizedett nőtt, ami elképzelhető, hogy az immáron 6 helyett 8 tranzisztort tartalmazó celláknak köszönhető.

A memóriaelérés sebességét ábrázoló grafikon már egy fokkal talán érdekesebb, mint az előzőek. Az írás sebessége jókorát zuhant a K8-ról K10-re, majd a K10.5-tel valamelyest visszaállt, de még így sem érte el a K8 értékét. Ez valószínűleg a K8 magórajelen üzemelő memóriavezérlője miatt lehet. Az olvasás és a másolás szépen emelkedett az újabb generációkkal, persze ebben a gyorsabbnál gyorsabb memóriaszabványok támogatása is nagy szerepet játszott. A K12 eredményei érdekesek, mivel a négyfős mezőnyből ennek a memóriavezérlője üzemel a legalacsonyabb órajelen, egészen pontosan 900 MHz-en.
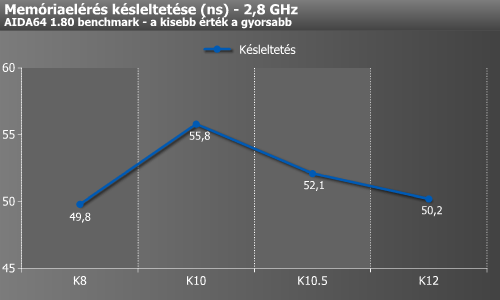
A memóriaelérés késleltetése is érdekes. A magórajelen üzemelő memóriavezérlővel szerelt K8-at csak a K12 tudta jobban megközelíteni. Emlékeztetőül: A K8 DDR2-800, míg a K12 DDR3-1866-os memóriák mellett lett lemérve.
Ezt követően az AIDA benchmark moduljai felé vettük az irányt, melyekből öt különféle teszttel mértük meg a processzorokat. Az egyik ilyen a CPU Queen, mely egy egyszerű, egész számokkal dolgozó benchmark, amely a processzorok elágazásbecslési képességeire fókuszál, és a „nyolc királynő egy sakktáblán” feladványra épül (10 x 10-es sakktáblán). A teszt MMX-, SSE2- és SSSE3-optimalizált (melyek közül az utóbbit éppen egyik tesztelt CPU sem támogatja), és kevesebb mint 1 MB memóriát foglal le. Ebben a tesztben az elágazáskezelés képességei határozzák meg a pontszámot. Nemcsak a branch prediction táblák és a becslés pontossága, a return stack mérete, hanem az is, hogy az utasításkészlet támogatja-e valamilyen módon maguknak az elágazásoknak az elkerülését (van-e CMOV vagy PABSB utasítás), illetve képes-e egyszerre párhuzamosan több bábu helyzetével számolni.
A következő integer teszt a CPU Photoworxx, amely különböző digitális fotófeldolgozási műveleteket hajtat végre a processzorral (kitöltés, forgatás, random stb.). Ez a teszt főleg a processzorok integer számolási végrehajtási egységeit dolgoztatja meg a memória-alrendszerrel egyetemben, ezért nem skálázódik olyan jól több processzormag esetén. A teszt csak alap x86-os utasításokat használ. A Photoworxx a legösszetettebb teszt, többféle méretű képpel dolgozik, sok minden számít benne, de leginkább az átlagos memóriaelérés ideje a döntő. Sokat jelentenek a jobb prefetcherek, és itt számít a legtöbbet a memória és a cache-ek hatása.
Végül a harmadik integer teszt az CPU AES, mely az AES (azaz Rijndael) adattitkosító algoritmust használja. A teszt Vincent Rijmen, Antoon Bosselaers és Paulo Barreto publikusan elérhető C kódját használja ECB módban. A benchmark alap x86-os utasításokat és összesen 48 MB memóriát használ. Itt is inkább a CPU sebessége a fontos, illetve kiugróan az out-of-order load képesség számít.
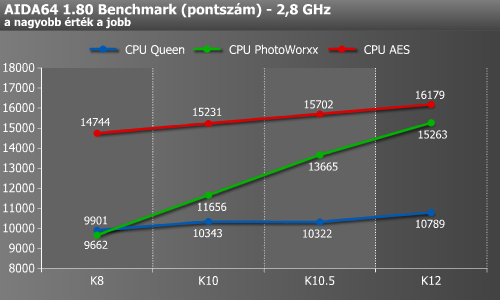
A CPU Queen esetében a K8-ről K10-re, majd a K10.5-ről K12-re váltásnál láthatunk említésre méltó növekedést. A CPU Photoworxx eredménye meredeken, a K10.5-ig generációnként nagyjából 2000, majd onnan végül durván 1500 pontot emelkedett. Ez jó eséllyel a memória-írási sebesség hasonló mértékű növekedésének tudható be, ami a feljebb található grafikonról is könnyen levehető. A CPU AES esetében némileg hasonló a helyzet, csak itt egy kevésbé meredek, 500 pont körüli növekedés látható a négy generáción átlépkedve.
Az integer tesztek után kettő, lebegőpontos számításokat végző mérést is elvégeztünk. Az első ilyen az FPU Mandel, ami a 64 bites (kétszeres pontosságú) lebegőpontos teljesítményt méri le a „Mandelbrot” fraktál egyes frame-jeinek kiszámolása révén. Ez a benchmark is assemblyben íródott, és kihasználja az egyes SIMD-utasításkészleteket (x87, SSE2, AVX).
Az utolsó teszt az FPU VP8 a Google VP8-as kodekjével tömörít egy 1280x720-as felbontású, 8192 kbps bitrátájú videót a legjobb minőségi beállítások mellett. A tömörítendő képkockákat az FPU Julia fraktál modulja állítja elő. A SIMD-utasításkészletek közül ez az MMX, SSE2 és SSSE3 kiterjesztésekből képes profitálni.
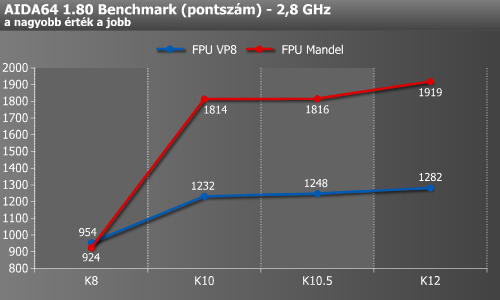
Ahogy látható is, a K8->K10 lépés elég nagy ugrást eredményezett itt, amely minden bizonnyal még az FPU-végrehajtók 128 bitesre való bővülésével magyarázható. Ezután előre haladva leginkább csak kisebb emelkedéseket láthatunk.
A cikk még nem ért véget, kérlek, lapozz!




