Megjött az új Radeon
Néhány éve találkoztunk egy nagyszerű felépítésű és jövőbe mutató grafikus processzorral, mely földbe döngölte nehezen megszülető konkurensét. Annak idején az ATI R300 GPU-ja szakított a hagyományokkal, teljesen új belső felépítést és Shader Model 2.0 támogatást hozott. Konkurense, az NVIDIA NV30 ugyan modernebb gyártástechnológiával és kifinomultabb belsővel kecsegtetett, de a sok újítás csúnyán megbosszulta magát. Azóta a balszerencsés chipnek már a nyomát sem találni a kaliforniai gyártó weboldalán, de az R300 hagyatéka a mai napig él - vagyis élt.
Míg az NVIDIA az elmúlt években szorgos munkával végül mégis meghozta mindazt, amit ígért, az ATI a régi architektúra bővítésére koncentrált. Az idő előrehaladtával, az SM 2.0 megszokottá vált. Az ATI HDR technikája korlátai miatt nem került be a játékokba, megmaradt kirakati bemutató tulajdonságnak. Eközben az NVIDIA NV40 és továbbfejlesztett változata, a G70 elhozta a Shader Model 3.0-t, és a játékokban is alkalmazható HDR-t. Mondhatni az ATI kissé kerékkötőjévé vált a fejlődésnek, váltig azt hangoztatta, hogy a játékokban semmi szükség az SM 3.0-ra, ezért a hardvernek sem érdemes tudnia. De ha nem tudja a hardver, akkor hogyan – és miért – tudja a játék?
Eleinte 2005 tavaszára – az NVIDIA második SM 3.0-t támogató architektúrájával egy időre – vártuk az ATI újdonságát, de a tervezésben adódó problémák miatt a nagy debütre most, az utolsó negyedév elején került sor. A bemutatkozást eddig nem látott találgatássorozat és pletykaáradat előzte meg. Olyan órajelekről és futószalag-felállásokról lehetett hallani, melyek szinte hihetetlenek voltak, csak az új, 90 nanométeres gyártási technológia volt biztos. A történelemben volt már egy hasonló, merőben új felépítésű és csíkszélességű grafikus processzor, melynek megjelenése nem ment simán. A szerencsétlen NV30 végül bukásra lett ítélve, sokan az új ATI GPU esetében is hasonlótól tartottak.
Végül csak eljött a nagy nap: 2005 október 5. Ugyan nem a beígért teljes modellválaszték, csak a fele vált elérhetővé ezen a napon, de megjött az ATI forradalmi újdonsága. Egy kis késéssel hozzánk is eljutottak a tesztpéldányok, bennük mindennel, amivel az ATI tartozott a kedves olvasóknak és nekünk.
| Kódnév | R520 | R520 | R480 | G70 | G70 | NV40 |
| GPU neve | Radeon X1800 XT | Radeon X1800 XL | Radeon X850 XT PE | GeForce 7800 GTX | GeForce 7800 GT | GeForce 6800 Ultra |
| Gyártástechnológia | 0,09 µm (TSMC) | 0,09 µm (TSMC) | 0,13 µm low-k (TSMC) | 0,11 µm (TSMC) | 0,11 µm (TSMC) | 0,13 µm (IBM) |
| Tranzisztorok száma | 321 millió | 321 millió | 160 millió | 302 millió | 302 millió | 222 millió |
| GPU órajele | 625 MHz | 500 MHz | 540 MHz | 430 MHz | 400 MHz | 400 MHz |
| Pixelfutószalagok száma | 16 | 16 | 16 | 24 | 20 | 16 |
| ROP-egységek száma | 16 | 16 | 16 | 16 | 16 | 16 |
| Pixel fillrate | 10000 Mpixel/s | 8000 Mpixel/s | 8640 Mpixel/s | 6880 Mpixel/s | 6400 Mpixel/s | 6400 Mpixel/s |
| Futószalagonkénti textúrázó egységek száma | 1 | 1 | 1 | 1 | 1 | 1 |
| Textúra fillrate | 10000 Mtexel/s | 8000 Mtexel/s | 8640 Mtexel/s | 10320 Mtexel/s | 8000 Mtexel/s | 6400 Mtexel/s |
| Vertex shader egységek száma | 8 | 8 | 6 | 8 | 7 | 6 |
| Támogatott PS-verzió | 3.0+ | 3.0+ | 2.0+ (24 bites precizitás) | 3.0+ | 3.0+ | 3.0+ |
| Támogatott VS-verzió | 3.0+ | 3.0+ | 2.0+ (32 bites precizitás) | 3.0+ | 3.0+ | 3.0+ |
| Memória órajele | 750 MHz | 500 MHz | 590 MHz | 600 MHz | 500 MHz | 550 MHz |
| Memória effektív órajele | 1500 MHz | 1000 MHz | 1180 MHz | 1200 MHz | 1000 MHz | 1100 MHz |
| Memóriainterfész | 256 bit | 256 bit | 256 bit | 256 bit | 256 bit | 256 bit |
| Memória-sávszélesség | 48000 MB/s | 32000 MB/s | 37760 MB/s | 38400 MB/s | 32000 MB/s | 35200 MB/s |
| Memória mérete | 256-512 MB | 256-512 MB | 256-512 MB | 256-512 MB | 256 MB | 256-512 MB |
| Memóriatípus | GDDR3 | GDDR3 | GDDR3 | GDDR3 | GDDR3 | GDDR3 |
| Alaplapi interfész | PCIe | PCIe | PCIe / AGP | PCIe | PCIe | PCIe / AGP |
| Támogatott DirectX-verzió | 9.0c | 9.0c | 9.0b | 9.0c | 9.0c | 9.0c |
| Memória-optimalizáció | HyperZ HD; 3Dc Compression | HyperZ HD; 3Dc Compression | LMA III; Color Compression; Normal Map Compression (V8U8, 3Dc) |
LMA III; Color Compression |
||
| További optimalizációk | AVIVO; Adaptive AA | SmartShader HD; SmoothVision HD; Temporal AA | IntelliSample 4.0; CineFX 4.0; UltraShadow 2.0; Adaptive Transparency AA |
IntelliSample 3.0; CineFX 3.0; UltraShadow 2.0; |
||
Fény derült arra is, hogy a tervezett menetrendhez képest miért kellett többször is elhalasztani az új architektúra bemutatóját. Az első próbagyártás után szivárgásra visszavezethető problémák merültek fel az új, 90 nanométeres grafikus processzorban. A fő gond a hiba rendszertelen megjelenése volt, így több hónapot igényelt a feltárása. A hiba nem az ATI által tervezett áramkörben volt; a kisebb, alsó kategóriás GPU-t nem is érintette. Végül, több hónapos keresgélés után egy külső beszállítótól érkező alkatrészt sikerült azonosítani. A probléma megoldásához elég volt a vezetékeket áttervezni.
Architektúra – VS, PS
Az R520 fő újdonsága, hogy végre támogatja a hármas Shader Modelt, ami a teljes feldolgozási folyamatban 32 bites pontosságot igényel. Az eddigi ATI chipek pixel shaderei csupán 24 bites precizitással dolgoztak. A másik fontos újdonság, hogy az R520 HDR képességeit jelentősen továbbfejlesztették.
A korábbi felépítési diagramokhoz képest az R520 esetében sokkal kisebb hangsúlyt fektettek a vertex és pixel shaderekre, a középpontban teljesen más egységek állnak. Piros színt kapott egy „Ultra-Threading Dispatch Processor” nevezetű elem, egy különálló textúracímző és egy hatalmas általános célú regisztertömb.

Nagyjából ez a hármas rejti az R520 fő újdonságait. A vertex shaderek továbbra is egy négykomponensű vektor- és egy skalárműveletet tudnak egyszerre elvégezni. Mivel precizitásuk már korábban is 32 bit volt, így az SM 3.0-támogatáshoz csak az összetettebb programkód támogatására volt szükség. Ez legfeljebb 1024 utasítás hosszú kódot, dinamikus folyamatirányítást ciklusokkal és szubrutinokkal, valamint több regisztert jelent.

A teljes VS 3.0-támogatáshoz elengedhetetlen a geometriai egységek textúraolvasó képessége, ami hiányzik az R520-ból, az ATI véleménye szerint ugyanis a textúrázók tervezési költsége aránytalanul magas. Azért nem maradt az R520 sem vertex textúrázási lehetőség nélkül. A pixel shaderek a memória egy olyan területére is írhatnak (Vertex Buffer), melyet a vertex shaderek egyenesen el tudnak érni. Az eljárás neve Render to Vertex Buffer, és sok esetben gyorsabb lehet a hagyományos vertex textúrázásnál, ugyanis a pixel egységek felépítése elrejti a textúrázás késleltetéseit. A megoldás érdekessége, hogy egyelőre DirectX alatt, támogatás hiányában, csak kerülő úton érhető el, de amint beveszik a hivatalosan elismert megoldások közé, bármelyik DirectX 9- (tehát SM 2.0- vagy SM 3.0-) kompatibilis videokártya képes lehet rá. Igen, a konkurens NVIDIA hardverei is!
A pixel shaderek felépítése sem sokat változott, de erre nem is volt szükség. Az ATI-nak már jól optimalizált fordítói vannak az R420-ban megszületett elrendezéshez. Ami változott, az a precizitás. Immár az ATI pixel egységei is 32 bitesek, ráadásul a komplexebb SM 3.0-t is támogatják.

Ugyan a cikk elején bemutatott blokkdiagramon a textúra-mintavételezők külön egységet alkotnak, a felépítés ugyanaz maradt, mint korábban. A Pixel Shaderben két-két skalár-, illetve háromkomponensű vektorszámoló helyezkedik el. Az első egység textúrakezelésre is képes, a második csak számolni tud.
Ultra-Threading
Az R520 felépítésére pillantva látható, hogy ugyanúgy 16 pixelfutószalaggal rendelkezik, mint elődei, az R420 és az R480. Az ATI pusztán az órajelek emelésére támaszkodott volna? Az órajelek növelése és az architektúra párhuzamosítása (több futószalag) mellett létezik még egy módszer, amivel nagyobb teljesítmény érhető el, ez pedig az optimalizáció. Vegyünk egy példát. Egy textúraolvasás nagyságrendekkel lassabb művelet, mint egy számolás. Ha a pixelfutószalagnak várnia kell az adatokra, akár több száz hasznos, számolós ciklus is elveszhet. Ha a memória szervezése nem megfelelő, akkor ez a várakozás még hosszabbra nyúlhat.
Az ATI az optimalizálás talán leghatékonyabb módszerét, a feladatok kisebb részekre bontását választotta. A megoldás lelke az „Ultra-Threading Dispatch Processor”, mely a shadereket 16 pixeles (4 x 4) szálakra bontja le. Az R520 minden pixel quadja (4 pixelfutószalagos csomag) 128 ilyen szál kezelésére képes. A 16 darab futószalag négy quadba rendeződik, így összesen 512 szál futhat egyszerre. Ha egy quad végzett a feladatával, vagy valamilyen adatra vár, akkor az elosztó egységtől további munkát kap, így a kihasználatlan ciklusok száma drasztikusan csökken. Hasonló filozófiával működik a Pentium 4 Hyper-Threading architektúra is.
A sok szál kezeléséhez, ahogyan a P4-nél, úgy az R520 esetében is nagy mennyiségű adat gyors hozzáférését kell biztosítani. A CPU esetében ezt nagy L2 cache oldotta meg, az R520-ban hatalmas általános regisztertömb áll rendelkezésre. Alapesetben mind az 512 szálhoz 32 darab 128 bites (négy 32 bites komponensű vektor) regiszter áll rendelkezésre, ez összesen 256 kB-ot tesz ki! Ha egy-egy összetettebb feladathoz több változóra van szükség, a többi szál rovására (vagy számuk csökkentésével) átszervezhető a tárterület.
A kisebb blokkméret további gyorsuláshoz vezet SM 3.0-ban. A dinamikus ciklusvezérlésnek köszönhetően kizárhatóak azok a kódrészek, melyeket nem kell az adott pixelen végrehajtani. Ennek a módszernek a hatása különösen nagy blokkoknál áldásos. A jobb megértéséhez lássunk egy ábrát.

A középső képen látható képrészt (fa árnyékát és hátterét) tekintjük egy blokknak. A jobb oldali kód feltételt szab – ezért dinamikus. Ha a fa árnyékában tartózkodunk, akkor más kódrész fut le, mint amikor a hátteret számoljuk. A kis blokkméret tovább javít a helyzeten, ekkor a feltételes kódnak sokkal kevesebbszer kell váltania, megspórolható (hiszen más-más kódrész fut le) az ilyenkor fellépő környezetváltás okozta késleltetés.

Minél kisebb a blokkméret, annál kevesebb a fölösleges munka
Az elágazási feltételek feldolgozását tovább gyorsítja a különválasztott végrehajtó egység, így a komplex kódok még gyorsabban futhatnak. A konkurens G70 blokkmérete 64 x 16 (1024) pixel, de belső felépítése is más.

Hagyományos és különválasztott feltétel-kiértékelős architektúra
Memóriavezérlő
A korábbi Radeon architektúrákban – ahogyan az NVIDIA megoldásaiban is – négycsatornás crossbar vezérlő kezelte a memóriát. Ez annyit jelentett, hogy négy darab, egyenként 64 bites memóriasáv csatlakozott a vezérlőhöz. A megvalósítás 256 biten nagyon sok vezetékezést igényel, emiatt órajele már nem nagyon emelhető, 512 bitesre szélesítése pedig óriási tervezési ráfordításokat igényelne.

Crossbar memóriavezérlő sok-sok vezetékkel
Az R520-ban az ATI egy forradalmi újítást vezetett be. Mondhatni, a korábbi crossbar kereszteződést egy körforgalommal váltotta fel, melyet Ring Busnak neveznek. A chip kerületén két 256 bites memóriabusz fut körbe a memória órajelén. Irányuk egymással ellentétes, így a leghosszabb adatút is legfeljebb fél körívnyi. A gyűrűn négy fő állomás van, mindegyikhez egy pár memóriacsatorna kapcsolódik. Van egy ötödik, kisebb sávszélességű kapcsolat is, ez a PCI Express és a kimeneti kép számára van fenntartva.

Ring Bus memóriavezérlő
A középen elhelyezkedő memóriavezérlő körül kevesebb vezeték található, ez nagyobb órajelet tesz lehetővé. Az egyes kliensek a vezérlőnek jelentik be igényüket, az megkeresi, melyik memóriamodulnál van a kívánt adat, és eldönti, melyik gyűrűn juttatható el leggyorsabban a klienshez. A vezérlőnek saját logikája van, figyeli a memóriaaktivitást, és egyes kliensekhez prioritásokat rendel. Ha az egyik kérvényező ugyan magas prioritású, de az aktuális helyzetben csökken miatta a gyűrűk hatékonysága, ideiglenesen alacsonyabb prioritást kaphat. Ráadásul az egész folyamat szoftveresen is irányítható, a későbbi meghajtókban találkozhatunk majd egyedi, alkalmazásra – vagy alkalmazáscsoportra – kihegyezett memóriabeállítással, ami további gyorsulást eredményezhet.
Az ATI állítása szerint az új architektúra véletlenszerű elérésnél akár négyszer is gyorsabb lehet a korábbiaknál. Ebben szerepet játszik az is, hogy az R520-nak nyolc memóriabankja van, így a korábbi 4 x 64 bites felállás helyett 8 x 32 bitest alkalmaz. Emlékezzünk csak vissza, a blokkméret kicsinyítése már önmagában is jobb kihasználtságot biztosít. Az új memóriavezérlő támogatja az összes mai GDDR memóriatípust, és a közeljövőben érkező GDDR4-gyel is kompatibilis. Az új szabvány életciklusa alatt eléri majd az 1,8 GHz-es órajelet.
Az új vezérlő mellett a cache felépítése is változott az R520-ban. Az eddigi közvetlen cache helyett most teljesen asszociatívat használnak. A korábbi módszerrel minden memóriarészhez egy cache-rész tartozott, most a memória bármely területéről elérhető az egész és fordítva.

Direkt és asszociatív cache felépítése
HDR, AA és AF
Az ATI R300 GPU-ja volt az első grafikus chip, mely lebegőpontos precizitással tudott textúrázni, így képes volt nagy dinamikatartományú – HDR (High Dinamic Range) – hatások megjelenítésére. A nagyobb tartomány intenzívebb fényforrásokat tudott megjeleníteni úgy, hogy közben a finom, árnyékos részek is megmaradtak. Sajnos ezt a kezdetleges módszert játékokban nem lehetett használni, ugyanis az átlátszóságot nehézkesen kezelte.

Az első HDR hatás PC-n – Radeon 9700
Játékokban is használható HDR hatást elsőként az NVIDIA NV40 produkált, erről a chip bemutatásakor részletesen írtunk. A hatással először FarCry-ban találkoztunk, elbűvölő volt. Az NVIDIA HDR-jének egyetlen hibája, hogy Anti-Aliasinggal nem tud együttműködni; vagy szép fényeink vannak csipkés élekkel, vagy fakóbbak sima élekkel.


Az R520 SM3.0-kompatibilitása mellett a legfontosabb újítása, hogy HDR-rel is tud Anti-Aliasingot. A megnövelt dinamikatartományhoz négyféle formátum áll rendelkezésre. Alapvető a komponensenként 16 bites (összesen 64 bites) lebegőpontos formátum, de ennek memóriasávszélesség-igénye a legnagyobb, ráadásul AA-val összekombinálva még tovább növekszik. A szintén 64 bites Int16 ugyanazt tudja, mint az előző, de komponensei fixpontosak. Az Int10 szabvány gyorsabb, csupán 32 bites. Három színkomponense 10 bites, de így az átlátszóság kezelésére csupán 2 bit jut, vagyis a teljes átlátszóság és a teljes átlátszatlanság között csupán két köztes lépcsőt kezel. A negyedik formátum szabadon konfigurálható a teljesítmény és a képminőség függvényében.

Az Anti-Aliasing algoritmusain is javított az ATI. A nagy memória-sávszélességgel rendelkező X1800-aknál már érdemes a megszokott 4xAA fölé kapcsolni. A gyártó állítása szerint a hatszoros mód sebességcsökkenése kisebb, mint korábban, ezt majd a tesztekben megvizsgáljuk.

Az Anti-Aliasing technikák terén érdekesebb előrelépést – vagy inkább kiegyenlítést – jelent az ATI Adaptive Anti-Aliasingja. Az eljárás az NVIDIA G70-ben megismert Transparency AA-hoz hasonlítható; a textúrák belsejében tapasztalható töredezettség mérséklésére való. Hatása legjobban az átlátszó textúráknál figyelhető meg – a tesztben szintén megvizsgáljuk.
Anizotropikus szűrés területén is hozott újat az ATI. Korábban sokan bírálták a kanadai gyártót, hogy szűrési eljárása szögfüggő. A Radeon 8500 idejében még csak függőlegesen és vízszintesen működött, így jelentősen kevesebb erőforrást emésztett fel, mint a GeForce 4-ek szögfüggetlen, és sokkal szebb eredményt hozó metódusa. Az NV40 megjelenésekor az NVIDIA is átállt az R300-ban bevezetett AF módszerre, mely 45 fokonként adott helyes képet. Ugyan a képminőség szempontjából ezek a stratégiák támadhatóak, de a régebbi és mai játékokban szinte észrevehetetlenek a szögfüggő AF okozta pontatlanságok, ugyanis a legtöbb játékban éppen a kiemelt függőleges, vízszintes és 45 fokos irányú textúrák a legelterjedtebbek, hiszen az emberi szem éppen ezekre a legérzékenyebb.

Az egyre részletesebb grafikájú programok előbb vagy utóbb igényelni fogják a szögfügetlen anizotropikus szűrést, ráadásul a mai hardverek már elég erősek is hozzá. Nem csoda hát, hogy az ATI előrukkolt az irányfüggetlen változattal, melyet szintén kielemzünk.
X1000 család
A csúcskategóriás R520 mellett két kisebb chip is bemutatkozott október 5-én. Az RV530-at a középkategóriába, az RV515-öt az alsó szegmensbe szánják. Az előbbi chip az X1600 család alapját képezi, az utóbbi az X1300-ét; többféle órajel és memória variációval kerülnek majd forgalomba.
| Kódnév | R520 | RV530 | RV515 | ||||
| Videokártya - Radeon | X1800 XT | X1800 XL | X1600 XT | X1600 Pro | X1300 Pro | X1300 | X1300 HyperMemory |
| Gyártástechnológia | 0,09 µm (TSMC) | 0,09 µm (TSMC) | 0,09 µm (TSMC) | ||||
| Tranzisztorok száma | 321 millió | 157 millió | 105 millió | ||||
| Vertex shader egységek száma | 8 | 5 | 2 | ||||
| Pixelfutószalagok száma | 16 | 12 | 4 | ||||
| Textúrázók száma | 16 | 4 | 4 | ||||
| ROP-egységek száma | 16 | 4 | 4 | ||||
| Z-egységek száma | 16 | 8 | 4 | ||||
| Szálak száma | 512 | 128 | 128 | ||||
| GPU órajele | 625 MHz | 500 MHz | 590 MHz | 500 MHz | 600 MHz | 450 MHz | 450 MHz |
| Memória órajele | 750MHz | 500 MHz | 690 MHz | 390 MHz | 400 MHz | 250 MHz | 500 MHz |
| Memória mérete | 256/512 MB | 256 MB | 128/256 MB | 256 MB | 128/256 MB | 32 MB | |
| Memóriavezérlő | 256 bites Ring Bus | 128 bites Ring Bus | 128 bites crossbar | 32 bites HyperMemory | |||
| Megjelenés | nov. 5. | okt. 5. | nov. 30. | okt. 5. | ? | ||
A legkisebb RV515 minden tekintetben az R520 szűkítésének – negyedelésének – tekinthető. A nyolc vertex egységből kettő, a négy pixel quadból csak egy maradt, mely 128 szálat tud kezelni. A memóriavezérlő nem gyűrűs, hanem hagyományos crossbar. Különlegessége, hogy a 128 bites sávszélességet nem 2 x 64 bit, hanem 4 x 32 bit formában valósították meg. A Ring Bus vezérlő hiányában a gyártáskor jelentkező problémák nem érintették az RV515-ös chipet, így az első Radeon X1300-ak már ma megvásárolhatóak. A 600 MHz-es GPU-val, és 400 MHz-en járó memóriából 256 MB-tal ellátott X1300 Pro bevezető ára a GeForce 6600 szintjén mozog.

RV515
Ahogyan látható, a közepes chip számozása magasabb, 30-ra végződik. Belső felépítése nagyon hasonlít az R520-éra, de néhány helyen más szervezésű. Öt vertex egysége és 12 pixel futószalagja van – ez három quadot jelent. Míg a korábbi 12 pixelfutószalagos Radeonoknak 12 textúrázója és 12 ROP (raster operation) egysége volt, addig az RV530-nek csupán négy textúrázója és ugyanennyi ROP egysége van. További érdekesség, hogy az NV43-hoz (GeForce 6600 sorozat GPU-ja) hasonlóan a ROP egységekben megbúvó Z-tesztelők száma kétszeres – vagyis nyolc. Az ilyen felépítésű GPU árnyékok számolásában jelentős előnyre tehet szert.

RV530
Az RV530 ugyanúgy Ring Bus memóriakezelést kapott, de esetében két 128 bites gyűrű dolgozik. Az R520-szal közös memóriavezérlő miatt az RV530-at is érintette a gyártáskor felmerülő hiba. Ebből sejteni lehet, hogy az új memóriavezérlő egyes részei (talán a logikája?) külső forrásból származik. A hibából adódó késlekedés leginkább az RV530 chipre alapozó Radeon X1600 sorozatot érintette, melynek képviselő csak november végén kerülnek a boltok polcaira.
Az X1000 család csúcsán természetesen az R520 GPU-ra épülő X1800-ak állnak. Egyelőre két változat ismert. Az október 5-től elérhető X1800 XL a lassabb, GPU- és memóriaórajele egyaránt 500 MHz. A csúcsmodell az X1800 XT, melynek GPU- és RAM-órajele is jelentősen magasabb: 625 MHz, illetve 750 MHz, de csak november elejétől lesz kapható. Mai írásunkban az utóbbi két kártyára koncentrálunk. A Radeon X1000 család kisebb tagjait külön cikk keretein belül elemezzük majd.
Természetesen az új Radeon család is támogatja a kétkártyás – CrossFire – megoldást. Az X800-as családhoz hasonlóan, az X1800 és X1600 párban hajtásához egy átlagos és egy extra, CrossFire Edition kártyára lesz szükség. A speciális kártyák érkezésének pontos dátumáról egyelőre semmit nem lehet tudni. A nagyobbik, X1800 CrossFire Edition kártya 512 MB memóriával 599 dolláros ajánlott áron várható. Az X1600 CrossFire Edition 256 MB memóriát kap. Ajánlott ára – 299 dollár – valamivel az X800 CrossFire Edition ára fölött van, ez nem túl jó jel.
Az X1000 sorozatban a CrossFire vitatott problémái eltűnnek. Mivel az X1600 és X1800 sorozat is dual-link DVI csatlakozókkal érkezik, a kétkártyás üzemmód mentesül az 1600x1200/60 Hz felbontási korláttól, az új csúcsérték 2048x1536 képpont 70 Hz fölötti képfrissítéssel. A nagyobb felbontás mellé új csatlakozó is érkezett. A Super AA már nem a PCI Express buszt lassítja, hanem a többi CrossFire módhoz hasonlóan a képösszerakó logikára hagyatkozik.

Radeon X1800 CrossFire Edition – forrás: Beyond3D
A PCI Express busszal szoros kapcsolatban áll az X1300 CrossFire. A legkisebb új Radeonból két átlagos kártya is hajtható párban, egymással az adatbuszon keresztül kommunikálnak. Míg a nagyobb kártyáknál ez a módszer lassúnak bizonyult, addig a kisebb felbontásokban üzemelő low-end kártyáknál elegendő. Meglepő, de a képösszerakó logika nélkül is elérhető az összes CrossFire mód. Ez a tény felveti a kérdést: vajon bármilyen – akár korábbi – PCI Express-es Radeon képes kétkártyás üzemmódban működni?
X1800 XL és XT testközelben
A Radeon X1800 XT a Radeon X850 sorozat két kártyahelyet elfoglaló hűtését kapta, melynek csak a rögzítését variálták át. Beindítás után a lapátkerék felsírt, majd néhány másodperc múlva meglepően lecsendesedett. A csendességnek egyetlen baja volt: nem tartott sokáig. A rendszer felállása után már 2D-ben is felgyorsított a ventilátor.

ATI Radeon X1800 XT [+]
A légáramlás a házból kifelé irányul, ez örvendetes tény. Nem túl nagy gond, hogy a szomszédos kártyahelyet nem használhatjuk. Ki lenne az a vakmerő, aki bármilyen csúcskategóriás videokártya tőszomszédságába másik hardvert költöztetne? A hűtésre ismét Ruby került, ezúttal egy kardot szorongat.


Az X1800 XT jelentősen hosszabb az elődeinél, nagyjából a GeForce 7800 sorozat külső méreteivel rendelkezik. Felépítésében is hasonlít a konkurensre. A kártya végén helyezkednek el az áramellátásért felelős alkatrészek, a 256 MB-os kártya hátulján pedig nincsenek memóriamodulok.


A hűtőt leszerelve meglehetősen fura memóriakiosztást láttunk. A szokatlan elrendezés az új memóriavezérlőnek és a 8 x 32 bites memóriacsatornának köszönhető. Ahogyan az elméleti részben írtuk, nyolc darab 32 bites modul található a kártyán. Az X1800 XT esetében 1,26 ns-osak, és a Samsungtól származnak. A kártya áramellátásához szükséges hattűs csatlakozó már kötelező tartozéknak számít.


Eggyel nagyobb kardos Ruby látható az X1800 XL vékonyabb hűtőjén. A megoldás leginkább a GeForce 7800-akon láthatóra hasonlít, sajnos a kártya melegét a gép belseje felé tolja.

ATI Radeon X1800 XL [+]
A képes fémlemezt eltávolítva hatalmas rézbordát találtunk. A X1800 XT és X1800 XL hátsó fele teljesen egyforma.


A hűtéstől megszabadítva ugyanaz a látvány tárult elénk, mint a nagyobbik testvérnél. A két X1800-as nyomtatott áramköre hajszálra egyforma, különbség csak a GPU és memória órajelében van.


A lassabban járó XL memóriamoduljai 1,4 ns-osak, és szintén a Samsungtól származnak. Ez a késleltetés elvileg 700 MHz körüli névleges sebességet jelent, az XT 1,26 ns-os értéke pedig 800 MHz-et. Még kimondani is brutális, egy éve ezen órajelek fele is tisztességes értéknek számított.


ATI Radeon X1800 XT és XL memória [+]
A hűtők hátoldalán vastag hővezető párnácskák láthatóak, de alattuk csupán alumínium lapul. Kell is a komoly hűtés. A magas órajelek miatt az X1800 XT, de az XL is, jelentősen melegedett, jobban mint az NVIDIA kártyái.


ATI Radeon X1800 XT és XL hűtés [+]
Az R520 grafikus mag a 37. héten, vagyis szeptember második felében készült, alig egy hónapos! Ez a tény is jelzi, hogy az ATI nagyon az utolsó pillanatra készült el; a tesztpéldányokon általában 2-3 hónapos alkatrészek szoktak lenni.

ATI R520 GPU [+]
Az X1800 jelentősen túlnőtte elődeit, akkora, mint a konkurense; kérdés, hogy teljesítményben is felnő-e hozzá.

Hosszban egy szinten van az X1800 XT és a 7800 GTX [+]
Tesztkonfig és fogyasztás
| Videokártya / driver | ATI Radeon X1800 XT 512 MB (625/750 MHz) és ATI Radeon X1800 XL 256 MB (500/500 MHz) / Catalyst 8-173-1-050921a-026915E ASUS Extreme N7800GTX TOP/2DHTV (@430/600 MHz) / Forceware 81.84 MSI NX7800GT-VT2D256E (400/500 MHz) / Forceware 81.84 MSI NX6800U-T2D256E (400/550 MHz) / Forceware 81.84 ATI Radeon X850 XT PE 256 MB (540/590 MHz) / Catalyst 5.9 |
| Processzor | AMD Athlon 64 3800+ (2,4 GHz; 512 kB L2 cache; dual-channel) |
| Alaplap | ASUS A8N-SLI Deluxe |
| BIOS-verzió | 1006 |
| Chipset | NVIDIA nForce4 SLI |
| Chipset-driver | NVIDIA Unified Driver 7.11 |
| Memória | Corsair TwinX1024-3200XL – 2 x 512 MB |
| Idozítések | 2-2-2-5 |
| Merevlemez | Hitachi Deskstar 7K250 160 GB (PATA, 7200 rpm, 8 MB cache) |
| DVD-meghajtó | Asus DRW-0804P |
| Tápegység | Cooler Master RS-450-ACLY (450 W) (Expert Computer Kft.) |
| Operációs rendszer | Windows XP Professional Service Pack 1 + DirectX 9.0c |
Játékok
- ID Software – Wolfenstein: Enemy Territory
- ID Software – Doom 3
- Microsoft/Bungee Studios – Halo: Combat Evolved
- Eidos – Tomb Raider Angel of Darkness
- Codemasters – Colin McRae Rally 05
- UBISoft – Lock On: Modern Air Combat
- EPIC Games – Unreal Tournament 2004
- Valve – Counter-Strike: Source
- Valve – Half Life 2
- UBISoft – FarCry
- EA Game – Medal of Honor Pacific Assault
- People Can Fly – Painkiller
- Vivendi Universal Games – Chronicles of Riddick: Escape from Butcher's Bay
- Vivendi Universal Games – F.E.A.R. Multiplayer Beta Demo
A meghajtóprogramokban a képminőségi beállításokat az NVIDIA kártyák esetében „Minőség”-re, az ATI kártya esetében pedig a legszebbre kapcsoltuk, később csak az FSAA-t és az anizotropikus szűrést állítottuk. A „Catalyst AI”-t alapállapotban hagytuk. Minden játék esetében maximális grafikai beállításokat használtunk, hiszen csúcskategóriás versenyzőkről van szó. A Wolf ET, Doom 3, LOMAC, TRAoD, Half Life 2, FarCry, UT2004 és Riddick játékokban saját magunk által felvett demókat/replayeket használtunk fel a kártyák teljesítményének leméréséhez, minimálisra csökkentve így a meghajtó-optimalizációk esetleges hatását. A többi játékban egy begyakorolt útvonalat jártunk be háromszor egymás után, miközben FRAPS-szel mértük az fps-eket. A három lefutott kör után az átlagot jegyeztük fel (kivéve a F.E.A.R.-t, melyben a benchmarkot futtattuk le).
A teljesítménytesztek előtt a különböző videokártyákkal lemértük a teljes rendszer fogyasztását.

Az új Radeonok terheletlen állapotban jelentősen többet fogyasztanak elődjüknél és konkurenseiknél is. Az eddig tétlenül legéhesebb GeForce 6800 Ultrára is alaposan rávernek. Az X1800 XL-t hajtó rendszer 127 wattos fogyasztása 42 %-kal több mint a GeForce 7800 GTX-es rendszeré. A kisebbik X1800-as nagyjából az órajeleinek megfelelő arányban, 22 %-kal eszik kevesebbet az XT-nél.

Terhelés alatt (Doom 3 1600x1200, 4xAA/16xAF) nagy meglepetésre az X1800 XL-es rendszer fogyasztotta a legkevesebbet, bár a GeForce 7800 GT sem volt sokkal éhesebb. A csöppet sem dicsőséges győzelmet, ha hajszállal is, de az X1800 XT szerezte meg. Ugyan az új Radeonok 90 nm-es csíkszélességgel készülnek, de magas órajelei miatt az X1800 XT mégis többet fogyaszt.
Tesztek – Fillrate
Először a kártyák fill-rate eredményeit vizsgáltuk. Ezekben a tesztekben nincs geometriai számolás és a pixel shadereken csak átszaladnak a képpontok, de képet kapunk a textúrázó egységek igazi sebességéről.
| ATI Radeon X1800 XT | NVIDIA GeForce 7800 GTX | ATI Radeon X1800 XL | NVIDIA GeForce 7800 GT | NVIDIA GeForce 7800 GTX (500/500 MHz) | ATI Radeon X850 XT | NVIDIA GeForce 6800 Ultra | |
| Pure fill-rate (Mpixel/s) | 9387 | 6708 | 6797 | 6275 | 7532 | 5756 | 6025 |
| Z pixel rate (Mpixel/s) | 9709 | 13060 | 7674 | 12057 | 15079 | 7557 | 12049 |
| Single texture (Mpixel/s) | 6255 | 6710 | 4315 | 6275 | 7532 | 4380 | 6027 |
| Dual texture (Mpixel/s) | 4499 | 4519 | 3213 | 3764 | 4518 | 2411 | 3011 |
| Triple texture (Mpixel/s) | 2508 | 3261 | 1931 | 2591 | 3317 | 1700 | 2069 |
| Quad texture (Mpixel/s) | 1930 | 2400 | 1257 | 1923 | 2381 | 1176 | 1506 |
Bizony, eljött az az idő, amikor a Radeon X850 XT PE és GeForce 6800 Ultra csupán a sereghajtó szerepét játssza. Az ATI új csúcsmodellje tiszta pixelsebességben több mint 60 %-kal előzte meg őket. Az X1800 XT alaposan – 40 %-kal – maga mögött hagyta a szintén 16 ROP egységgel rendelkező GeForce 7800 GTX-et. Architektúra tekintetében mégis az NVIDIA-t kell kiemelni, ugyanis egyformán 16 raszterezővel, de alacsonyabb órajelen tartotta a lépést a Radeon X1800 XL-lel. A Radeon órajelére (500/500 MHz) húzva a GTX 11 %-os előnyre tett szert, de lemaradása a nagyobbik X1800-hoz képest még így is tetemes volt. A GeForce 7800 GT órajelének megfelelő mértékben volt lassabb nagytestvérénél. Az ATI-féle konkurens, az X1800 XL, kevesebb mint 10 %-kal előzi meg.
Z koordinátáknál érdekes eredményeket kaptunk. Arra számítottunk, hogy a megkettőzött feldolgozójú GeForce-ok a pure eredmények dupláját teljesítik és utolérhetetlenek lesznek, de nem gondoltuk, hogy az X1800-asok ilyen kevés többletet hoznak. Meg kell hagyni, tisztán Z terhelés nem fordul elő játékokban, inkább az architektúra részleteire lehet belőle következtetni. Esetünkben az új ATI-belső teljesen másképp viselkedik, mint a régi. Míg az X850 XT PE 30 %-ot gyorsult a pure eredményeihez képest, addig az X1800 XL 11 %-ot, az X1800 XT pedig kevesebb mint 4 %-ot. Mindenesetre az új ATI csúcsmodell elődjénél 28 %-kal volt jobb.
Ha már nemcsak a végsebességről van szó, hanem textúraolvasásról is, akkor egy csapásra elszáll az X1800-ak pure esetben tapasztalt előnye. Az ok minden bizonnyal a Pixel Shaderektől jobban elkülönített mintavételező. Lényegesen magasabb órajele ellenére egytextúrás esetben a Radeon X1800 XT majdnem 10 %-kal lemaradt a GeForce 7800 GTX mögött, nagyjából a 7800 GT teljesítményét hozta. Az X1800 XL az X850 XT PE szintjén teljesített, és még a GeForce 6800 Ultra mögött is jelentősen lemaradt. Az architektúrákat összevetve, vagyis a GeForce 7800 GTX-et 500/500 MHz-re gyorsítva bődületes teljesítményt kapunk. Az azonos órajelű X1800 XL majd’ 75 %-kal, a gyorsabb X1800 XT 20 %-kal maradt le mögötte.
Két textúrával a Radeon X1800 XT már a GeForce 7800 GTX közelébe lopódzott, és az X1800 XL lemaradása is csökkent a 7800 GT-hez képest, sőt a 6800 Ultrát meg is előzte. Amiben az ATI jobb volt, az a százalékos csökkenés. Míg az NVIDIA új vasai az egytextúrás esethez képest átlagosan 36 %-ot lassultak, az X1800-ak visszaesése 27 % körül mozgott. Ez az érték azért is nagyon jó, mert a korábbi ATI architektúra ugyanezen lassulása 40 % fölötti volt. Az 500 MHz-re állított memóriájú 7800 GTX nem mutatott gyorsulást, ez nem is csoda, hiszen memóriáján ilyenkor lassítani kellett. Ezzel a hendikeppel éppen hogy csak meg tudta előzni a magasabb órajelű X1800 XT-t, de az azonos sebességre állított X1800 XL-t alaposan lehagyta.
Három textúrával nagyjából azt tapasztaltuk, amit eggyel: az X1800 XT csupán a GeForce 7800 GT tudta befogni, az X1800 XL pedig picivel lemaradt a 6800 Ultra mögött. A 7800 GTX elsőségéhez nem fért kétség, az 500/500 MHz-s mérés ismét nem sok változást mutatott.
Négy textúrával csak annyit változott a helyzet, hogy az X1800 XL már a 6800 Ultrával sem tudta tartani a lépést. Ki kell viszont emelni, hogy az X1800-ak sebességcsökkenése arányosan minden esetben kisebb volt a konkurensékénél. A textúrázásban tapasztalt lemaradás minden bizonnyal annak köszönhető, hogy az ATI inkább a komoly shader programokkal teletűzdelt játékokra optimalizál, melyeknél nem a fill-rate, hanem a pixelfutószalagok áteresztőképessége szokott lenni a szűk keresztmetszet.
Tesztek – Vertex Shader
Szintetikus geometriai teljesítményben nem tapasztaltunk olyan nagy ATI-előnyt, mint amilyet a magasabb órajelektől vártunk.

A régi DirectX 7, 8 és az egyszerűbb, forgalomirányítás nélküli DirectX 9 tesztben a Radeon X1800 XT átlagosan 15 %-kal volt gyorsabb a GeForce 7800 GTX-nél, és ugyanennyivel verte az X1800 XL a 7800 GT-t. Mindeközben a 7800 GT és X1800 XL sebessége nagyon közel volt egymáshoz.
Ezután jött a folyamatirányítással megtűzdelt VS 2.0 teszt, és az ATI új architektúrája robbantott. A GeForce-ok sebességének kétszeresét produkálta a kisebbik és a nagyobbik X1800 is. Ebben a tesztben az X850 XT PE szintén megelőzte az összes GeForce-t. A dinamikus folyamatirányítású (VS 2.x) tesztsorról bebizonyosodott, hogy az X850 XT PE korábbi, borzasztóan magas értéke valami hibának vagy trükknek köszönhető. Ugyan az ATI hangsúlyozta, hogy új architektúrája előnye az összetettebb kódok esetén bontakozik ki igazán, de a VS 2.x tesztben ezt nem tapasztaltuk. Előnye a NVIDIA-val szemben 20 % volt, ennyit pusztán a magasabb órajelű vertex egységnek is illene hoznia.
A Right Mark VS 3.0 tesztkörét eddig csak az NVIDIA kártyái tudták megfutni, most kíváncsian vártuk, hogyan reagálnak a Radeonok. Az X1800 XL és XT azonos, GeForce 7800 GTX-nél tízszer nagyobb sebességéből nem a kártyák tudására, hanem a program hibájára lehet következtetni – lassan új szintetikus mérőeszköz után kell néznünk.
Architektúrákat vizsgálandó megnéztük a GeForce 7800 GTX-et nyolc letiltott pixelfutószalaggal 500/500 MHz-en, és összehasonlítottuk a szintén 500/500 MHz-en futó Radeon X1800 XL-lel. A szemléletesség érdekében az X1800 XT eredményeit is feltüntettük.

A statikus folyamatirányítású és a kétes pontosságú VS 3.0 esettől eltekintve a G70 architektúra győzelmet aratott a friss R520 fölött. A magasabb órajelű X1800 XT mentette meg a kanadaiak becsületét. Kétségtelen, hogy egy úgy architektúránál nem csak a felépítést, hanem az elérhető órajeleket is figyelembe kell venni.
Tesztek – Pixel Shader
A pixelfutószalagokat először procedurális textúrákkal nyaggattuk. Ez az eljárás az elkövetkező játékokban egyre nagyobb teret nyer majd. Segítségével előre elkészített, memóriát zabáló raszteres textúrák helyett a GPU által számolt mintázatokat használhatunk, melyek nem igényelnek textúrán belüli élsimítást és alig foglalnak memóriát.

Egyszerű Pixel Shader 1.1-et használva a megfelelő GeForce 7800 és Radeon X1800 sebessége megegyezett – a magasabb órajelet jól ellensúlyozta a több futószalag. A valamivel modernebb, de ritkán használt Pixel Shader 1.4 tesztben sok lúd gyors disznót győzött; a több futószalaggal rendelkező GeForce-ok biztosan vezettek. A Radeon X1800 XT is lemaradt a GeForce 7800 GT mögött, a Radeon X1800 XL kevéssel előzte meg a korábbi NVIDIA csúcsmodellt, a GeForce 6800 Ultrát.
A kettes Shaderek mezejére lépve két választásunk van. A textúra kiszámolásához használhatunk mintavételező periodikus szögfüggvényt (matekot), vagy a megfelelő értéket kiolvashatjuk egy egydimenziós textúrából. Az utóbbi azt jelenti, hogy a szögfüggvény előre kiszámított értékeiből – melyeket egy számoszlopban juttatunk a GPU-hoz – választjuk ki a megfelelőt. Olyan ez, mintha egy függvénytáblázat oszlopát kapná meg a processzor. Ezt az oszlopot hívjuk egydimenziós vagy LUT (Look-Up Table – értéktábla) textúrának. Segítségével a GPU számolói tehermentesíthetőek a textúraolvasók rovására.
A magyarázatra azért volt szükség, mert korábban az NVIDIA termékei textúrás esetben, az ATI kártyái számolásban voltak jobbak. Bizony, a helyzet változott. Az új Radeon architektúra már nem olyan gyors, a megfelelő GeForce mind számolásos, mind textúraolvasós esetben jobban muzsikált, ráadásul az NVIDIA chipek továbbra is többet profitáltak a LUT textúra használatából. Ismét kijelenthető, hogy a több jobb, mint a gyorsabb. Ugyanez volt a helyzet a PS 2.a tesztben is, de ott csak hajszálnyival voltak jobbak a GeForce-ok. A Radeon X850 XT PE, valami hiba vagy trükk folytán, ismét őrületes teljesítményt produkált. A rövid ciklusos kódok sorossá bontásának hatására gyanakszunk.

Azonos órajel- és futószalag-beállítás mellett minden tesztben jobb volt a G70 az R520-nál. Textúrát használó PS 2.0 és PS 2.a tesztben csak megközelítette, de PS 1.4-ben le is előzte a magasabb órajelen járó X1800 XT-t. Érdemes megfigyelni, hogy a G70 memóriaórajelének csökkentésével csökkent a PS 1.1 teljesítménye is. Ez a teszt annyira egyszerű, hogy a futószalagoknak a memóriára kell várniuk.
Shadereket általában árnyékolásra szokás használni, mi is megtettük. Fények számolásánál a LUT textúrás mintavételezés mellett a visszaverő felületek is számolhatóak vagy olvashatóak textúrából, melyben felületi egyenetlenségeiket tárolják. Az ilyen textúrát normal mapnak nevezik, mert térképszerűen tárolja, hogy melyik képpontról milyen irányban verődik vissza a fény.

A GeForce-ok előnye ezekben a tesztekben is egyértelmű volt. A Radeon X1800 XT nem sokkal előzte meg a GeForce 7800 GT-t, az X1800 XL lemaradt mögötte. Minkét 7800-as stabilan hozta teljesítményét teljesen számolós, vegyesen számolós és textúraolvasós, valamint teljesen textúrákra támaszkodó PS 2.0 tesztben is. Míg a korábbi Radeon architektúra inkább számolásban jeleskedett, az X1800-ak textúrázásban voltak erősebbek. A komplexebb PS 2.a tesztben már kisebb volt az új Radeonok lemaradása, bár textúrás normalizálást használva ismét megvillantották tudásukat a GeForce-ok. Ebben az esetben az NVIDIA kártyák majdnem 10 %-ot, az ATI kártyái alig valamit gyorsultak.
A Pixel Shader tesztek után ismét kijelenthetjük, hogy a több jobb, mint a gyorsabb. Az új Radeon architektúra magasabb órajelen nem volt elég a több pixelfutószalaggal szemben. Természetesen egyforma órajelen és pixelfutószalag-számmal is végeztünk összehasonlítást.

A Radeon X1800 XL órajeleire állított és 16 futószalaggal szereplő GeForce 7800 GTX állta a sarat. Teljesítménye egy hajszálnyival maradt le a 400 MHz-en 20 futószalaggal dolgozó GeForce 7800 GT mögött. Ez nem is csoda, hiszen a két felállás ugyanazt az elméleti sebességet hozza. Mivel a 7800 GT verte az X1800 XL-t, így az architektúrák összehasonlításában is az NVIDIA a győztes.
Hogy képet kapjunk a jövőbeli kisebb csíkszélességen és magasabb órajelen járó NVIDIA csúcskártyáról, megjárattuk a 7800 GTX-et 500 MHz-en 24 futószalaggal is. Az eredmények letaglózóak voltak; az órajel emelésnek megfelelően átlagosan 16 %-os pixel teljesítménynövekedést tapasztaltunk. Kár hogy tesztünk idején még nem volt elérhető tuningprogram a Radeon X1800-akhoz.
Tesztek – OpenGL


Az OpenGL mindig is az NVIDIA territóriuma volt. Doom 3-ban szűrők nélkül a Radeon X1800 XL ugyanúgy teljesít, mint a GeForce 7800 GT. A több futószalagos 7800 GTX előnye minimális volt, bár nagyobb processzorral talán jobban kifutotta volna magát. Az X1800 XL csak kevéssel előzte meg a korábbi csúcs Radeont, a GeForce 6800 Ultra mögött viszont lemaradt.
A szűrők bekapcsolásával jobban lemaradtak a Radeonok. Alacsonyabb órajelei miatt az X1800 XL az X850 XT PE mögé szorult. Doom 3-ban továbbra is az NVIDIA a király, de a láthatáron már feltűntek az első fellegek. A Hexus.net tesztelői kipróbálhatták a memória Ring Bus OpenGL-re optimalizált üzemmódját, mellyel az X1800-ak teljesítménye közel 30 %-ot nőtt. A módosított memóriaprogram az 5.11-es Catalystban lesz elérhető. Hatására talán az OpenGL játékokban tapasztalt erősorrend is megváltozik, bár nem szabad elfelejteni, hogy bizonyos mértékben a G70 memóriavezérlője is programozható!


Következő OpenGL játékunkban a Doom 3-ban tapasztalt forgatókönyv játszódott le, azzal az apró különbséggel, hogy az X1800 XL végig az X850 XT PE mögött maradt.


OpenGL-es a Riddick is, így nem csoda, hogy ismét a korábbi sorrend alakult ki.
Tesztek – DirectX I.


A modern DirectX-alapú játékok között a legismertebb a FarCry. Tesztünk idején még nem volt elérhető az ATI HDR-jét kihasználó változat, így az 1.33-as verzióval mértünk. Az X1800 XT már szűrők nélkül is szorongatta a GeForce 7800 GTX-et, szűrőkkel pedig alaposan meg is előzte. A Ring Bus jó teljesítményét mutatja, hogy az intenzívebb memóriaműveletekkel járó szűrős tesztekben az addig gyengélkedő X1800 XL előretört, és megelőzte konkurensét, sőt 1600x1200-ban a 7800 GTX-et is megközelítette. Az új Radeonok FarCry produkciójával meg voltunk elégedve, kíváncsian várjuk a HDR+AA-s folytatást.


Half Life 2-ben az X1800 XT volt jobb szűrők nélkül, és a 7800 GTX szűrőkkel. Az X1800 XL végig a 7800 GT mögött maradt, a szűrős tesztekben nagyobb volt a hátránya. A korábbi ATI architektúrához képest ismét jól teljesített az újonc; szűrők nélkül az X850 XT PE egy szinten volt az X1800 XL-lel, de szűrőkkel jelentősen lemaradt mögötte. A jelenséget minden bizonnyal az új memóriavezérlő és az AA módok optimalizálása okozta.


A Half Life 2-höz hasonló motorra épül a Counter-Strike: Source. A nagyok között minimális előnnyel az NVIDIA kártyája nyert. A 7800 GT és X1800 XL csatája szintén kaliforniai győzelmet hozott. Az X1800 XL és X850 XT PE teljesítményének viszonya ugyanúgy alakult, mint Half Life 2-ben.


A Medal of Honor: Pacific Assault szintén szoros GeForce-győzelmet hozott a csúcson és egy lépéssel lejjebb is.

Halo-ban visszavágtak a Radeonok. Az X1800 XT alaposan megverte a 7800 GTX-et, de az X1800 XL előnye pici volt a 7800 GT-vel szemben.
Tesztek – DirectX II.


Az Unreal Tournament kissé elavult motorja már nem tudja hitelesen összemérni a legerősebb videokártyákat. Ezt bizonyítja az eddig sereghajtó GeForce 6800 Ultra első helyezése szűrők nélkül. A leggyorsabb videokártyák még szűrőkkel bekapcsolva is közel ugyanazokat az eredményeket hozták.


A Tomb Raider: Angel of Darkness volt az első igazi Shader Model 2.0-s játék. Megjelenésekor derült ki, hogy a korábbi NVIDIA architektúrák nem teljesítettek jól ezzel a shader modellel. Különösen szűrőkkel, az új Radeonok is győzelmet arattak. Ugyan szűrés nélkül az X1800 XL még a hétezres GeForce-ok mögött volt, jobb minőségben már megelőzte őket.


A Colin McRae Rally 05 győztese ismét a Radon X1800 XT lett. Szűrők nélkül az X1800 XL még lemaradt, de bekapcsolásuk után megelőzte az X850 XT PE-t és a 7800 GT-t is.


Repülőszimulátorban a legjobb minőségi beállítástól eltekintve a 7800 GTX győzedelmeskedett, de így diadala nem sokat ért. A nagyobbik Radeon X1800 sebességcsökkenése a felbontás növelésével kisebb volt. A GT és XL párharcát az előbbi nyerte, előnye szűrőkkel nagyobb volt.

Végezetül – és talán utoljára – a F.E.A.R. bétájával is teszteltünk, de az eredmények kissé furcsák lettek. Talán driver- vagy optimalizációs gondok léptek fel, majd a teljes játékkal meglátjuk, hogyan alakulnak az eredmények.
Adaptive/Transparency AA
Az átlátszó textúrákhoz való Anti-Aliasing technikák összehasonlításához kis animációkat hívtunk segítségül, melyeken kinagyított FarCry képrészlet látható. Először az NVIDIA Transparency Anti-Aliasingját vizsgáltuk. A képek alaphelyzetben a hagyományos AA hatását mutatják, a kurzort rájuk húzva látható a Transparency AA. A képek különböző világossága a kissé pontatlan fényképezés miatt van, de nem befolyásolja a vizsgált hatást. Fontos kiemelni, hogy nagyításokról van szó!



Látható, hogy a Multi Sampling- (MS-) alapú Transparency AA inkább árt, mintsem használna. A Super Sampling-alapú változat viszont gyönyörűen kisimította az éleket. Már a kétszeres mód is kiváló hatással volt a levelek éleire, a négyszeres szinte tökéletes. A célkereszt méretéből ki lehet következtetni, hogy milyen apró részlettel van dolgunk. Aki a nyolcszoros és a négyszeres mód között játék közben, a játékélményre koncentrálva különbséget tud tenni, annak gratulálunk.
Az ATI ugyanezt az eljárást – vagy valami nagyon hasonlót – Adaptive Anti-Aliasing névvel illeti. Nekünk az NVIDIA elnevezése jobban tetszik, de hát az ATI csak nem használhatja ugyanazt a nevet!



Pár perces ízlelgetés után az NVIDIA átlátszós AA módjait valamivel jobbnak találtuk, de játék közben teljesen egyformának mondható az Adaptive Anti-Aliasing és a Super Sampling Transparency Anti-Alisaing minősége. A jobb megítéléshez különálló, tovább nagyított képeken is megörökítettük a jelenséget,




NVIDIA – hagyományos 2x / 4x / 8x / nincs FSAA [+]




ATI – hagyományos 2x / 4x / 6x / nincs FSAA [+]
Az átlátszó textúrákat szűrő módszerek aktiválása nélkül a levelek minden szinten és mindkét kártyán egyformák.



NVIDIA Transparency Anti-Aliasing – 2x + MS / 4x + MS / 8x + MS [+]



NVIDIA Transparency Anti-Aliasing – 2x + SS / 4x + SS / 8x + SS [+]



ATI Adaptive Anti-Aliasing – 2xA AA / 4xA AA / 6xA AA [+]
Tényleg mintha az NVIDIA Super Samplingja jobb lenne az ATI Adaptive AA-jánál. Persze mit sem érnek a speciális hatások, ha élvezhetetlenül lassúvá teszik a játékot.

Az X1800 XT hatalmas memóriaórajele, forradalmi memóriavezérlője és a továbbfejlesztett 6xAA algoritmus megtette a hatását. Még négyszeres módban csak-csak tartották a lépést a többiek, de hatszoros (NVIDIA esetében nyolcszoros) módban már alaposan leszakadtak. Az AA nélküli teljesítményhez képest 25 %-os lassulás hatalmas fegyvertény az ATI oldalán. Csúcskártyájukkal ez a brutális memória-sávszélességet igénylő mód is játszható sebességet produkált. Azért is kiemelten fontos ez a tény, mert az AA mellé bekapcsolt HDR még további igényeket támaszt majd a memória felé. Talán a 4xAA+HDR beállítás még élvezhető sebességet produkál majd. A Radeon X1800 XL esése már nagyobb mértékű, de végig a GeForce-ok előtt van. Ki lehet mondani, hogy az ATI jobb a hagyományos AA implementálásában, és a piacon egyedüliként tud egyszerre HDR-t és Anti-Aliasingot.

A Multi Sampling-alapú TAA említést sem érdemel, koncentráljunk a Super Sampling TAA és az Adaptive AA sebességviszonyára. Minőségben a 2xA AA és a 2xSS TAA van nagyjából egy szinten, de az ATI megoldása kisebb mértékű lassulást okoz. Hasonló a helyzet a négyszeres SS TAA és A AA között is, de itt már jelentős lassulást tapasztalhatunk. Valószínűleg a jobb képminőség már játszhatatlanul alacsony fps értékeket produkálna a modernebb játékokban. A legjobb minőségű módok lassulása óriási, nincs arányban a képminőség javulásával.
Véleményünk szerint az ATI kétszeres Adaptive AA-ja hozza a legjobb teljesítmény/minőség arányt. Bekapcsolásával nem lassultak túl sokat a kártyák, de az átlátszó textúrák nagyon szépen kisimultak. NVIDIA kártyák esetében a kétszeres Super Sampling Transparency Anti Aliasing használata ajánlott. A négyszeres Transparency AA-k teljesítménycsökkentő hatása már túl nagy.
Anisotropic Filtering
Az ATI új, szögfüggetlen anizotropikus szűrését szintetikus tesztképeken elemeztük. A színes sávok a felhasznált különböző részletességű textúrákat (MIP mapeket) jelzik. Ha szögfüggő a szűrés, akkor bizonyos irányokban csúnya túlszaladásokat látunk, melyek azt jelentik, hogy arrafelé gyengébben dolgozik az algoritmus. Minél nagyobb szintű az anizotropikus szűrés, annál kisebb köríveket kell kapnunk.
| ATI R520 | ATI R520 Quality | ATI R420 | NVIDIA G70 | |
| Trilinear filtering |  |
|
 |
 |
| 2x-es aniso |  |
 |
 |
 |
| 4x-es aniso |  |
 |
 |
 |
| 8x-os aniso |  |
 |
 |
 |
| 16x-os aniso |  |
 |
 |
 |
Látható, hogy a korábbi ATI chip már kétszeres AF-nél kezd csúnyán „kivirágozni”, és ugyanez a helyzet az R520-nál is sebességre állítva. Kétszeres szinten még az ATI minőségi AF-je is lemaradt a G70 mögött. Négyszeres szinten az R520 minőségi beállítása már egyértelműen vitte a prímet. A második helyre szoruló G70 megoldása már erősen szögfüggő, de jobb volt, mint a Radeonok alapértelmezettje. Nyolcszoros anizotropikus szűrésnél a sorrend változatlan maradt, de már az R520 minőségi beállítása is kezdett bizonytalankodni a 45 fokos irányokban. A bizonytalankodás tovább erősödött tizenhatszoros szinten, de az R520 minőségi beállítása klasszisokkal jobb volt konkurenseinél; kérdés, milyen a sebessége.

Fel kell hívni a figyelmet, hogy a grafikon a felső 20 %-ot mutatja! Meglepetéssel tapasztaltuk, hogy az új Radeonoknál elhanyagolható sebességbeli különbség volt az ugyanazon a szinten lévő minőségi és sebességre kihegyezett mód között. Ráadásul az esés mindig kisebb, mint az NVIDIA kártyáknál. Számunkra érthetetlen, hogy ilyen jó és gyors minőségi beállítás mellett mi szükség van a sebességire.
Konklúzió
Most a megrögzött ATI-fanatikusok biztosan fujjognak, hogy nem WHQL minősítésű meghajtóval teszteltük az NVIDIA kártyáit. Választásunkat azért tartjuk indokoltnak, mert játékok alatt, a játék élvezetére koncentrálva, az előző meghajtókhoz képest nem találkoztunk képminőségbeli romlással, és az ATI kártyához is béta állapotú meghajtót mellékeltek. Mai tesztünk a jelenlegi helyzetet tükrözi. A jövőben biztosan lesz még X1800 vs. 7800 párharc a PROHARDVER! hasábjain.
Szintetikus tesztjeink alapján úgy véljük, az NVIDIA G70 jelenleg nagyobb nyers shader teljesítménnyel bír, mint az R520. A két architektúra között nem is lehetne nagyobb különbség. Az NVIDIA oldalán egy olyan fejlesztést látunk, melyre már jó másfél éve is épült piacképes hardver, kiforrott, a gyártó ismeri minden csínját-bínját, átesett egy optimalizáláson, ereje teljében van. Az ATI R520 most érkezett a szülőasztalról, meghajtója még kiforratlan, de hatalmas potenciál rejlik benne. Kisebb csíkszélességgel készül, felépítését magasabb órajelekhez igazították, és a jövő szoftverigényei szerint tervezték. Jobban ki tudja használni erőforrásait, ráadásul több olyan képessége van, amivel az NVIDIA chipje nem rendelkezik.
Játékos tesztjeink közül újra összefoglaljuk a legjobb képminőség mellett mért eredményeket, hiszen ezek a meghatározóak a csúcskategóriás videokátyáknál.
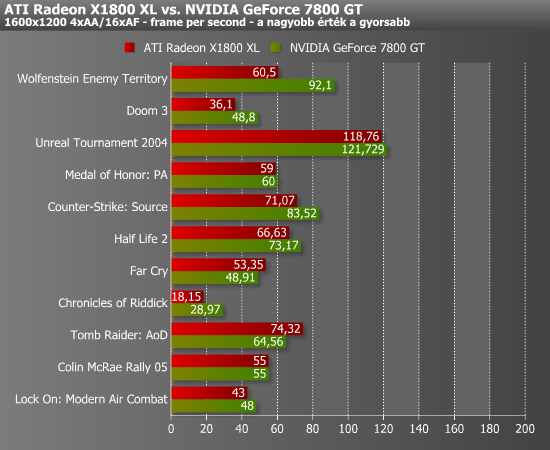
A Radeon X1800 XL két esetet kivéve a GeForce 7800 GT mögött maradt. Ha hozzászámoljuk az új memóriaprogramtól várható 30 %-os OpenGL-gyorsulást, akkor sem változik a helyzet. Az X1800 XL csak szorosabb meccseket vívna, de nem tudna újabb győzelmeket aratni. Ami az ATI kártyája mellett szól, az a jobb minőségű és gyorsabb Anti-Aliasing hagyományos és átlátszó textúrákkal, valamit a minőségi AF, melyből játék alatt vajmi keveset érzékelni. Fontos kiemelni, hogy az X1800 XL egyszerre tud HDR-t és AA-t, kérdés, hogy memóriavezérlője meg tud-e birkózni a megnövekedő sávszélesség-igénnyel. További kérdés, hogy az újabb meghajtók milyen gyorsulást hoznak, látunk-e majd varázsütésre meglóduló fps-eket. Bonyolítja a helyzetet az is, hogy nemsokára több olyan komplex shaderkóddal teletűzdelt játék is érkezik, amilyet eddig még nem láttunk, és nem tudjuk, melyik architektúrának fekszenek majd jobban. A jobb Anti-Aliasing és AF eljárások, valamint a HDR+AA lehetősége az X1800 XL mellett szól, ám teljesítménybeli hátránya, valamint 7800 GTX-et megközelítő ára a konkurencia malmára hajtja a vizet.

A Radeon X1800 XT négy játékban tudta megelőzni konkurensét, a GeForce 7800 GTX-et, további három esetben volt a lemaradása kevesebb mint 10 %. Ha hozzászámoljuk az 5.11-es meghajtóban várható 30 %-os OpenGL gyorsulást, akkor további két játékban lesz szoros a küzdelem. Az X1800 XT mellett szól a jobb minőségű és gyorsabb AA és AF. Legalább ilyen fontos, hogy a csúcshardvereken szinte kötelező, új, átlátszó textúrákat kezelő Anti-Aliasing eljárásokban az ATI fölényesen diadalmaskodott. A legerősebb kártyákon a legjobb képminőséget kell hozni, így a HDR+AA (esetleg a HDR+Adaptive AA) is az X1800 XT mellett szól.
Azért csak elő kell rángatni a tömegből a kisgyereket, hogy kikiáltsa: „Meztelen a király!” Melyik boltban lehet ezt a nagyszerű Radeon X1800 XT-t megvenni? Semelyikben! A kérdés eldőlt: továbbra is a GeForce 7800 GTX a király. Hogy mi lesz a Radeon X1800 XT tényleges megjelenése után, azzal majd foglalkozzunk a maga idejében.
fLeSs és rudi
Extra – Ruby, Parthenon
Akinek még nem lett elege az új Radeon architektúrából, annak mutatunk néhány érdekességet, amivel az R520 kapcsán lehetett találkozni. Melegítsünk be az ATI demóival, melyeket, egyelőre még csak film formájában, innen lehet letölteni.
Rubyt, az X800-zal debütáló vörös ruhás hölgyet már a legtöbben ismerik, most találkozhatunk új ellenfelével, a cyborg Cynnel. A lény érdekessége, hogy 120 000 poligonból épül fel, ez másfélszer annyi, mint Ruby alkatrészeinek száma. Egyelőre számunkra is csak a videó és néhány 1024x768 pixel felbontású kép vált elérhetővé, melyeken sajnos nem látszanak a finomságok. Az ATI minden bizonnyal a futtatható változatot is leközli idővel.






Képek a The Assassin demóból
A következő demó Paul Debevec munkája, ő készítette a Radon 9700 bemutatásakor megjelent HDR demót is. Az új demóban – jelenleg csak film formájában elérhető el – az athéni Parthenont járhatjuk körül. Ugyan korábbi fejlesztésről van szó, már a Siggraph 2004-en találkozhattunk vele, valami mégis a Radeon X1800-hoz köti. A felvételek lézeres letapogatással készültek, az eredmény egy 90 millió (!) poligonból álló 3D modell lett, aminek kezeléséhez szupergyors videokártyára van szükség.

Hogy a Radeon X1800 meg tudjon birkózni a roppant feladattal, a részletességet 15 millió poligonra csökkentették, ami a megcélzott felbontáson nem okozott látványbeli változást. További egyszerűsítéshez több geometriai részletességi szintet (LOD – Level Of Detail) hoztak létre, melyeket egy „Progressive Buffer” köt össze. Minden részletességi szinthez két vertex puffer tartozik. Az egyikben a megfelelő poligonok csúcsait tárolják, a másikban az eggyel durvább – kevésbé részletes – szint adatait. A geometria részletességét a kamerától mért távolság határozza meg.

A különböző részletességi szinteket az eltérő színek jelzik
A megfelelő szinthez tartozó finomabb (aktuális) és durvább szint is bekerül a vertex shaderekbe, és mindkettővel számol is a hardver. Így geometriai duplázódásról beszélhetünk, ez teljesítménycsökkenéshez vezet. A két számolást a kamerától mért távolság függvényében súlyozzák. Például: ha az adott LOD szint 10 méteres távolságnál kapcsol be, és 15 méternél követi az eggyel durvább, akkor 12 méteres távolságban a részletesebb modell eredményét 3-as, a durvábbét 2-es súllyal számolják. Ha elérjük a következő LOD szint távolságát (példánkban a 15 métert) akkor a nagyobb részletességhez tartozó adatok kikerülnek a pufferből, a kisebb részletességűek kerülnek a helyükre és betöltődnek a következő szinthez szükséges adatok.

Két Progessive Buffer szint finom (fine) és durva (coarse) része
Az eljárás legjobban a textúráknál alkalmazott MIP map szintváltáshoz hasonlít. Előnye az eddigi megoldásokhoz képest, hogy most már a geometriai részletesség is dinamikusan változik. Ha egy épület a távolban van, csak a főbb alkotóelemei jelennek meg, ahogyan közeledünk hozzá, egyre több és több részlet bontakozik ki, ráadásul a váltás nem ugrásszerű, hanem folyamatos. Minden bizonnyal nem a Parthenon részletességi szintjén, de ezzel az eljárással majd találkozunk a következő játékgenerációkban, esetleg konzolokon.



Képek a Parthenon demóból
Extra – Toy Shop
A számítógépes 3D világok sokszögekből és sima felületekből épülnek fel, a valóság nem ilyen. Eddig többféle eljárás született, melyekkel megpróbálták ezt a simaságot eltüntetni, de mindegyiknek megvoltak a maga korlátai. A legelterjedtebb, domborúság illúzióját keltő eljárás a Bump Mapping, melyről korábban már részletesen írtunk. A megoldás hátránya, hogy tüzetesebb vizsgálat után látszik, hogy mégiscsak egy sima felületről van szó, és a látszatra domború felület nem vet árnyékot a környezetére. Korábban ezek a jelenségek nem voltak olyan zavaróak, hiszen az árnyékolás még gyerekcipőben járt.
Mára megváltozott a helyzet, a modern shaderek és egyre nagyobb teljesítményű grafikus processzorok eddig nem látott grafikai részletességet hoztak, a Bump Mapping mellettük már kevésnek bizonyul. Az első komolyabb próbálkozással az NVIDIA rukkolt elő. A Shader Modell 3.0-ban már a vertex egységek is képesek textúraolvasásra, melyekből geometriát alkotnak. Az eljárás neve Displacement Mapping, és a hatodik GeForce generációval együtt tárgyaltuk.

Displacement Mapping – rücskösödés Vertex Shader textúrából
Mivel az ATI hardverei korábban nem tudtak vertex textúrázást, valami más megoldás után kellett nézniük, mellyel a mélység illúziója kelthető, és dinamikus fényekkel is korrekt árnyékolást biztosít. A megoldás a Parallax Mapping nevet kapta, néhány demóban és játékban már találkozhattunk vele. A következő animáción a Splinter Cell: Chaos Theoryból kiragadott részlet látható hagyományos Bump Mappinggel és az egeret ráhúzva Parallax Mappinggel.

Pixel shaderes Parallax Mapping a Splinter Cell: Chaos Theoryban
Az eljárás a Bump Mapping továbbfejlesztett változata. Elődjéhez képest figyelembe veszi a nézőpont változásából adódó látszólagos eltolódást – parallaxist – így a felület minden irányból másképp fog kinézni, valóságosabb lesz. A megvalósításhoz a Bump Mappingnél használatos normal map mellett (lásd R420 cikk) egy magassági térképet (height map) használnak, melynek színe a kiemelkedés mértékét határozza meg. Ha pontosabban akarunk fogalmazni, akkor besüllyedés mértékét kell mondanunk, ugyanis a Parallax Mapping a poligon felülete mögött játszódik.

A kiválasztott képponthoz először a normal map alapján képezik a megfelelő pontot a poligon felületére, majd a kamera nézési iránya alapján sugárkövetéssel (ray trace) kiszámolják, hogy az adott irányból melyik pont lenne a helyes válasz. A két érték különbsége a szükséges eltolás (offset), mellyel módosítani kell a normal map mintavételezését. Látható, hogy a kamera irányának változásával az eltolás is változik.

Az eljárást azt ATI még tovább fejlesztette. Az általuk kidolgozott Parallax Occlusion Mapping (POM) az egyszerű Parallax Mapping pontatlanságait is kiküszöböli, helyesebben adja vissza a felület egyenetlenségeit még lapos beesési szögeknél is, pontosabban képezi a felület többi részének árnyékát. Lássunk egy összehasonlítást:

A bal oldali katona POM segítségével készült egy 1100 polygonos vázra. A jobb oldali tiszta geometriával 1,5 millió polygonból áll. Az előbbi kevesebb mint 14 MB memóriát emésztett fel és több mint 200 fps sebességgel tudta megjeleníteni egy modern Radeon. A második memóriaigénye 45 MB és a komplex geometria miatt csupán 32 fps-sel futott. Az ATI Toy Shop demójában sok érdekesség mellett több helyen találkozhatunk POM-mal.

A felirat lemászik a képről – mozgás közben még jobb!
Hosszúra nyúlt elemzésünk végén bemutatunk még egy érdekességet, ami szintén a Toy Shop demóban látható. A kirakaton lefolyó víz útját a GPU számolja ki a fizika törvényeit felhasználva. A felületet cellákra bontják, melyek meghatározott mennyiségű vizet tartalmaznak. A cseppek sebességét beérkezéskor függőlege és vízszintes összetevőre bontják, majd a felületen található vízmennyiség, gravitáció és a súrlódás alapján módosítják. Ahogy a vízcsepp lefelé halad, és újabb cellába kerül, ismét módosul a sebessége és iránya.

A folyamat eredménye egy csatornánként 16 bites textúra, mely Bump Map eljárással hasznosítható. Hasonló módszerrel többféle fizikai jelenség kiszámolása is a GPU-ra ruházható

A vízcseppek útját leíró textúra...

...és felhasználása




