- Kicsit extrémre sikerült a Hyte belépője a készre szerelt vízhűtések világába
- Egészen nagy teljesítményspektrumon fedné le a mobil piacot az AMD
- Kihívás a középkategóriában: teszten a Radeon RX 7600 XT
- Már a Sparkle is jegyezhet fehérbe öltöztetett videokártyákat
- Modern monitorokra köthető 3dfx Voodoo kártya a fészerből
- Amlogic S905, S912 processzoros készülékek
- Kormányok / autós szimulátorok topicja
- Milyen CPU léghűtést vegyek?
- Kicsit extrémre sikerült a Hyte belépője a készre szerelt vízhűtések világába
- Fejhallgató erősítő és DAC topik
- Publikálta a Microsoft az MS-DOS 4.0 forráskódját
- Házi barkács, gányolás, tákolás, megdöbbentő gépek!
- Modern monitorokra köthető 3dfx Voodoo kártya a fészerből
- OLED TV topic
- NVIDIA GeForce RTX 3080 / 3090 / Ti (GA102)
Hirdetés
-


Az Apple iPadOS-t is megrendszabályozza az EU
it Az EB közölte: az Apple iPad táblagépekre írt iPadOS rendszere is kapuőrnek számít, az üzleti felhasználókra gyakorolt fontossága miatt.
-


Kihívás a középkategóriában: teszten a Radeon RX 7600 XT
ph Az AMD Full HD felbontáshoz ajánlja a legnagyobb Navi 33 alapú GPU-ját, melyet a PowerColor tálalásában próbáltunk ki.
-


Lenovo Essential Wireless Combo
lo Lehet-e egy billentyűzet karcsú, elegáns és különleges? A Lenovo bebizonyította, hogy igen, de bosszantó is :)






Új hozzászólás Aktív témák
-
#13
 Abu85
HÁZIGAZDA
flashpointer
#10
Abu85
HÁZIGAZDA
flashpointer
#10
Abu85
HÁZIGAZDA
válasz
 flashpointer
#10
üzenetére
flashpointer
#10
üzenetére
Ami ellenőrzött információ, azt lehozzuk, ami nem ellenőrzött, azt nem hozzuk. Ennyire egyszerű. Ha csak az Ampere-re gondolsz, akkor amit kiraktunk cikkeket róla, azok igazak lettek, mert nem Samsung EUV-s node-on jött (ezt leellenőriztük), és traversal coprocessor (ez akkora marhaság volt, hogy nem kellett utánakérdezni) sincs rajta.

A jelen cikk arról szólj, hogy nem érdemes mindent elhinni.
(#9) arn: Nem, a gyártók ilyet nem csinálnak. Magukat nem szeretik tökön szúrni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A feldolgozók számát nem én terjesztettem, hanem a Twitteren páran. De már mondták a gyártók, hogy majd a whitepaper leírja pontosan hogyan működik ez a dizájn, abból ki fog derülni, hogy miért hoz 3x nagyobb TFLOPS kb. +50-60%-ot a gyakorlatban például Borderlands 3-ban. (3080 vs. 2080) Most már én is váron a trükköt. Utoljára az R600-zal trükközöt az AMD, azóta ez kiveszett, és már igényem van valami hasonlóra. Végre lehet jó elemzést írni.
 Ezek a trükkök nekem mindig nagyon bejöttek.
Ezek a trükkök nekem mindig nagyon bejöttek. Erről szól a cikk. Kiderült, hogy ezek nem jönnek, ha jönnének bejelentették volna őket, és még mindig az van, hogy talán/tuti jönnek, csak valahol elvesztek, de már túrják a fiók mélyét. Sokkal egyszerűbb magyarázat is van a "7 nm, NVCache, RT koprocesszor, DLSS 3.0 és Tensor memóriatömörítés" pletykákra. Akik híresztelték, azok hazudtak, lehet, hogy nem önszántukból, egy ügyes kamuzó megvezette őket, de nem jött be, amit mondtak. És a legviccesebb, hogy most lehet, hogy a befolyt reklámpénzből, amit generáltak az oldalaikon, vagy a YouTube-on, Hawaii-on süttetik a hasukat, és röhögnek a sok csórin, aki bekajálta a kamukat, és üdülteti őket a kattintásokkal.

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Bonyolultabb ez ennél. A trükközések mögött mindig valós ALU-k vannak, csak nem mindig használhatók. Ez benne a trükk, mivel az ALU maga nem egy nagy tranzisztorköltség, az ütemezés és a regiszterek teszik azzá, de ha valamiféle móddal eléred, hogy bizonyos kódokban működjön az összes ALU, akkor megspórolhatod a sok tranyóba kerülő részegységeket, miközben a kódok egy részében előnyöd lesz, igaz a másik részében nem.
A trükk valamiért itt negatív szó, pedig egyedül azt kell nézni, hogy a tranzisztorköltséghez képest a trükknek mekkora az előnye. Ha nagyobb a viszonyított tranyóköltségnél, akkor megérte.
Az is fontos, hogy erre illeszkedjen maga a dizájn. Az AMD például nem járna jól egy 16+16 co-issue megoldással. Le is írtam itt, hogy miért: [link] - tehát azért nem mindegy, hogy milyen az alaparchitektúra, ahhoz kell igazodni a döntéseknél. Az NV valószínűleg úgy számolta, hogy nekik megéri az Int32 pipeline-t kiegészíteni FP32-re is, mert kevés tranyó, és még ha a feladatok kisebb részében is van haszna, akkor is úgymond olcsó volt bevetni. Tehát a befektetésnél nagyobb lesz a nyereség.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nem. Az NVCache esetében megjegyzi, hogy az AMD-féle HBC-re reflektál(na), de az RTX IO nem az. Ez csupán a DirectStorage API hardveres implementációja. A valóságban egy igen régi hardveres fícsőrre épít, mégpedig a GPUDirectre:
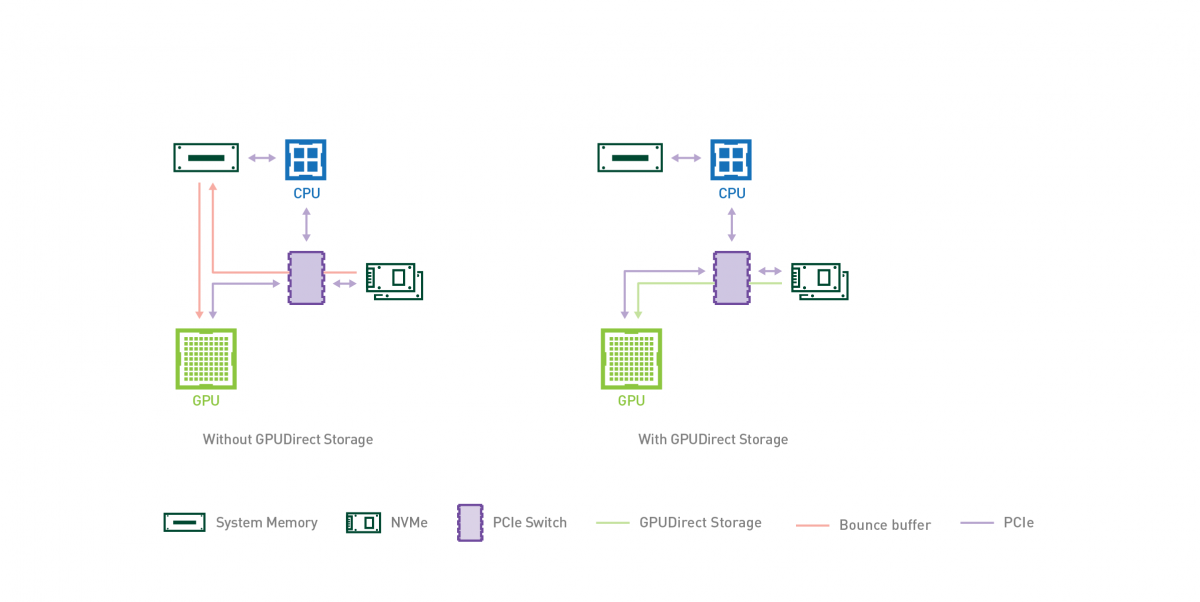
Ez már évek óta része a Quadro vonalnak, az AMD oldalán is van hasonló DirectGMA néven. Nem is emlékszem mikor vezették be, de 6 éve biztos. És tulajdonképpen a DirectStorage API sem igényel mást, csak ezeket az évek óta elérhető GPUDirect és DirectGMA funkciók implementálhatók alatta, tehát nem kell mostantól a gyártóknak saját API-jaikhoz ragaszkodni. Tehát újdonságról egyáltalán nincs szó, annyi történt, hogy írtak még ehhez egy GPU-s kitömörítést, és ennyi. Ja meg adtak neki egy hangzatos nevet, de évek óta ott van a technológia a GPU-kban, mind a Radeonban, mind a GeForce-ban. A Turing is támogatja, és igazából még a Pascal/Maxwell is tudná, csak nem biztos, hogy az NVIDIA ír rá implementációt. Hasonlóan az AMD-nél is egészen az első GCN-ekig vissza lehetne menni a támogatásért, de persze lehet, hogy ők sem teszik, és csak az újabb dizájnokra hozzák. Nem annyira közismert a GPUDirect és a DirectGMA, simán azt fogja hinni a legtöbb felhasználó, hogy ezek újdonságok. Pláne ilyen flancos nevekkel.
A finomszemcsés adatmenedzsment az ez: [link] - és erre írtak a konzolokon belül specifikus API funkciókat. Ez az Xbox Series X esetében a sampler feedback streaming, de PC-ben ebből a sampler feedback van meg, ami ennek a butítása, ráadásul a Feature_level_12_2-be még egy Tier0.9-es butítás került bele követelményként, mert nem mindegyik VGA támogatja majd a Tier1.0-t.
Egyelőre nem tudni, hogy mikor lesz majd az igazi sampler feedback streaming PC-be átmentve. Annyira gyorsan valószínűleg nem, mert a DirectStorage is csak previewben jön jövőre, tehát valós bevetése majd 2022-ben lehetséges, ha a csillagok együttállása úgy akarja.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Csak, hogy reagáljak arra, hogy a dupla TFLOPS-ot miért nem vizsgálja ez a cikk. Erre egy külön cikk lett. Ezen már reggel óta dolgozok. [link]
Elég hosszú kifejteni, hogy miért dupla a TFLOPS, mikor vannak a hardverben limitek, stb. Ezért lett ez szétválasztva.

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Hol is köhögtem, hogy balfaszok az NV-nél?
Az AMD-nél nem tudom, hogy röhögnek-e. Nekem a TUL-hoz van egy kontaktom, és ő nem izgul. Ma is beszéltem vele, leírtam itt: [link] - effektíve ők a megjelenés előtt 2,4x gyorsabbra számolták a 3080-at a 2080-hoz viszonyítva a 3DMark TSE-ben. Ebből ~70+% lett a gyakorlati pontoknál. Ezt a különbséget nem értették, de már elérhető a whitepaper, ami leírja, hogy az Ampere függőséglimites architektúra lett, így már ők is ~80% pluszt számolnak papíron. Most nyilván az early driver benne lehet, ebben a különbségben, csak némi órajelskálázás, de ugye a papír már nem különbözik annyira a gyakorlattól, mint amikor korábban számolták.
(#80) cskamacska: A technikai cikket itt többen hiányolták, hogy miért akkora a TFLOPS, amekkora. Ha nem írom meg, akkor az a baj, ha megírom, akkor meg az. Döntsétek már el végre.

A programozás szempontjából mindegyik dizájn esetében számít valamennyit, hogy optimalizálnak rá. Mindegyik architektúra alapvetően kihasználtságlimites, tehát a megadott számítási teljesítmény minden esetben elméleti. A kihasználtságlimiten azt értjük, hogy az adott multiprocesszoron futhat egy fix mennyiségű munkamenet. Ezek számát az határozza meg, hogy egy adott shader mennyi regisztert és compute feladat mellett mennyi LDS-t igényel. A kihasználtságlimit ott jelentkezik, ha nem lehet elég munkamenetet betölteni, mert nincs elég statikusan allokálható erőforrás rá, így az egyes munkamenetek közötti váltásnál a multiprocesszor nem biztos, hogy tud dolgozni, mert az adat beérkezéséig nem lesz elég szabadon futtatható feladat.
A legtöbb mai GPU-architektúra ilyen, lásd GCN, RDNA, Fermi, Kepler, Maxwell, Pascal, Turing, az ARM Malik közül a legújabbak, stb. ... ezeknek a dizájnoknak a jellegzetessége, hogy már a felépítésük ellehetetleníti a függőség kialakulását.Az alternatív dizájnokat a függőséglimites architektúrák képviselik, amikor az történik, hogy az ütemező képes úgy kiosztani a munkameneteket, hogy bekövetkezhet a függőség. Tulajdonképpen ezek a hardverek is kihasználtságlimitesek valahol, csak nagyobb esély van arra, hogy mielőtt elfogy a leköthető erőforrás, bekövetkezik valami függőség, ami hamarabb limitálja feldolgozást. Ilyen architektúrának tekinthetők például az Intel GenX és Xe dizájnok, az AMD régi Terascale-ja, illetve az új Ampere.
Viszont mindegyik rendszernek van valahol egy limitje, és az optimalizálás abból áll, hogy azt a limitet próbálod elkerülni. A kihasználtságlimit esetében a legfőbb stratégia, hogy egy shader a lehető legkevesebb regiszternyomást fejtse ki, compute esetén itt még bejön a képbe az LDS-nyomás is. Minél jobb az erőforrások allokációja, annál több munkamenet lehet bekészítve, hogy átlapolja memóriaelérést.
A függőséglimit annyi pluszt visz ebbe a buliba, hogy arra is figyelni kell, hogy lehetőség szerint minimális legyen a konkurens munkamenetek egymástól való függése. Tehát nem elég, hogy jó legyen az erőforrások allokációja, az sem mindegy, hogy miképp fogsz számolni. Erre is vannak különböző programozási stratégiák, az AMD például évekig nyomta ezt, és az Intelnek még közelebb van az Ampere-hez a dizájnja, tehát az erre vonatkozó tudásbázis elég nagy, az NV-nek nem kell a nulláról vinnie az egészet, nem újdonság ez.A fordítókat is majd ehhez kell igazítani, mert azon is múlik, hogy az adott shaderből mit tud kihozni. Felerősödhet a shader csere, hiszen ez az elmúlt években nem volt annyira túlerőltetve a meghajtó oldalán az AMD és az NV szempontjából sem, de a függőség bevisz egy olyan tényezőt a képbe, ami több fordítóoldali optimalizálásra ad lehetőséget.
Önmagában tehát a függőséglimit nem egy rossz irány, ha az lenne, akkor senki sem alkalmazná, az Intel se, az AMD sem csinált volna ilyen dizájnt sok-sok éve, meg persze az NVIDIA sem most. Ezeknek megvannak a maga előnyei, illetve maga hátrányai. Az előnye kétségtelen, kis tranzisztorköltségből tudsz bedobni ALU-kat co-issue módra, tehát az extra számítási kapacitáshoz nem kell ezekhez az ALU-khoz saját ütemezőt rendelni, és ez viszi ám el a sok tranzisztort, meg a regiszterek, nem pedig maga az ALU. A hátránya szoftveres oldalon keletkezik. Többet kell optimalizálni a fordítón, illetve magán a programkódon, hogy a kódfuttatás optimális legyen. És ez egy proven technology szintű dolog, ha nem működne, akkor az AMD nem tudott volna jó eredményeket elérni a Radeon HD 5000-es sorozatban. Meghajtókat pedig folyamatosan lehet hozni a termékhez, tehát ha találnak xy címhez pár százaléknyi extrát, pár shader cseréjével, akkor kiadnak egy új drivert és kész. Az AMD is elég sokáig ezt csinálta a TeraScale időkben, megjelent egy játék, nekiestek, és volt, hogy még másfél hónap múlva is extra tempót találtak hozzá, tehát a koncepció működik. Ma már ez ritkább, nincs annyi lehetőség szoftveres oldalon egy kihasználtságlimites architektúrával, gyorsabban jutsz el arra a pontra, amikor a program optimálisan fut, de humánerőforrás ma már elég sok van a driverbe épített fordítók megírására, tehát az NVIDIA számára ez nyugodtan bevállalható volt.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ő azért eléggé a hozzáértő kategória, és megbízható kontakt régebbről. Egy információt általa egy évvel a megjelenés előtt szállítottam, ráadásul a világon egyedüliként, igaz akkor nem a TUL-nál dolgozott.
Ugye ők alapvetően a nyers számokból számolnak. Amikor megszerezték a CUDA magok számát és az órajelet, akkor még nem tudhatták, hogy a compute blokk egy 32 utas feldolgozót használ-e, vagy 16+16-os leosztásban co-issue van. Előbbire tippeltek, mert az NVIDIA utoljára a GeForce 7000 sorozatban alkalmazott co-issue feldolgozást (sőt, akkor dual issue-t használtak, ami ugye azt jelenti, hogy a multiprocesszoron belül is úgy vannak a feldolgozók párosítva, hogy egymással co-issue módra képesek, és két co-issue feldolgozás egy dual issue módot eredményez), így olyan módon számoltak, hogy az összes CUDA mag olyan feldolgozóra van felfűzve, amelyeknek egymástól független ütemezője van és egymástól független regiszterfájlja. Úgy ki is jön ez a sebesség, de nemrég árulta el az NV, hogy nem így van ez beépítve, hanem 16+16 co-issue modellel, vagyis a feldolgozótömbök párosával osztoznak a regisztereken és az ütemezőn. Így már számolni kell azzal is, hogy hiába van beépítve ennyi CUDA mag, bizonyos kedvező feltételeknek kell teljesülnie, hogy mindegyik működjön egy blokkon belül.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 paprobert
#173
üzenetére
paprobert
#173
üzenetére
Az eddigi adatok alapján az Ampere-t lehet majd undervoltolni, mert messze a peak efficiency fölé van dobva az órajel. Még tuningolni is jól lehet, csak brutálisan elszáll a fogyasztás, 400-500 watt közé, ide majd jönnek nagyon kigyúrt kártyák. Az EVGA 3090-es csúcsdizájnja 550 wattra van felkészítve, tehát még a gyári OC-t is lehet majd húzni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A start pillanatában referencia. Nem valószínű, hogy az AIB-k idén kész lesznek, mert az AMD nem fogad el olyan hűtési megoldást, ami a referenciájuknál rosszabb, ezen azt kell érteni, hogy adott zajszint mellett nem hűt legalább annyira jól, mint a referencia. Ezzel egy csomó cégnek át kell terveznie a hűtőjét, amit nem lehet kivitelezni pár héten belül.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.




 Ezek a trükkök nekem mindig nagyon bejöttek.
Ezek a trükkök nekem mindig nagyon bejöttek. 









Új hozzászólás Aktív témák

ph 7 nm, NVCache, traversal coprocessor, DLSS 3.0 és Tensor memóriatömörítés. Ezek voltak a pletykaszezon legnagyobb slágerei, amelyekből végül nem lett semmi.
- DIGI internet
- Tőzsde és gazdaság
- Amlogic S905, S912 processzoros készülékek
- Gyúrósok ide!
- Samsung Univerzum: Az S23-at is megbabonázta a Galaxy AI
- Kormányok / autós szimulátorok topicja
- Milyen CPU léghűtést vegyek?
- Kicsit extrémre sikerült a Hyte belépője a készre szerelt vízhűtések világába
- Mozgásban a 33 Immortals
- ASUS routerek
- További aktív témák...
