Hirdetés
-


SMITE 2 - Napokon belül indul a zárt alfa teszt
gp Több mint egy tucat karaktert próbálhatnak ki a szerencsésebbek, a teljes listát a május első napján esedékes streamben árulják el.
-


Ülésezik a hardveregylet
ph Az irodai készülékek és monitorok társaságát egy ház, egy egér és egy DAC egészíti ki.
-


Olcsó 5G-s ajánlatot nyújt a Realme Indiának
ma Megérkezett a Realme C65 5G, az első készülék a MediaTek Dimensity 6300-zal.






Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
A Vegán eleve nincs értelme magának a VRAM fogalmának. Te állítod be a driverben azt a mennyiséget, amit szeretnél. Maximum 64 GB-ot. Az így beállított mennyiség olyan, mintha ennyi memória lenne a kártyán. A program amikor lekérdezi, akkor ezt a mennyiséget kapja meg.
A 8 GB memória a Vegán igazából egy gyorsítótár.A lényeg igazából az, hogy ha a Vegán mondjuk beállítasz 24 GB-ot, akkor az ugyanaz, mintha lenne 24 GB-nyi hagyományos VRAM a hardveren. Ez persze csak az exkluzív cache módra igaz. Az inkluzív cache mód az sokkal speciálisabb, azt nem lehet összehasonlítani a hagyományos VRAM rendszerekkel. De ehhez a módhoz kell szoftver oldali támogatás, nem olyan mint az exkluzív cache mód, ami csak driverből is képes akármivel működni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#23
Abu85
HÁZIGAZDA
->Raizen<-
#15
Abu85
HÁZIGAZDA
válasz
 ->Raizen<-
#15
üzenetére
->Raizen<-
#15
üzenetére
Mindenképpen van egy rendszermemóriát használó terület, amit a GPU és a CPU is elér. A lényegi különbség az, hogy a hagyományos VRAM módban a GPU fedélzeti tárába maguk az allokációk kerülhetnek át, és ennek a menedzselését vagy a meghajtó vagy a program oldja meg. A Vega által bevezetett HBC-s megoldásnál a hardverbe épített vezérlő, azaz a HBCC csinál mindent és csak lapokat menedzsel.
A 8 GB-nyi HBC komoly terhelés mellett mindig tele van. Ez a célja ennek a modellnek. Ha nem lenne tele, akkor nem működne optimálisan a koncepció.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#33
Abu85
HÁZIGAZDA
->Raizen<-
#28
Abu85
HÁZIGAZDA
válasz
->Raizen<-
#28
üzenetére
Egyszerűen ábrázolva ez történik:
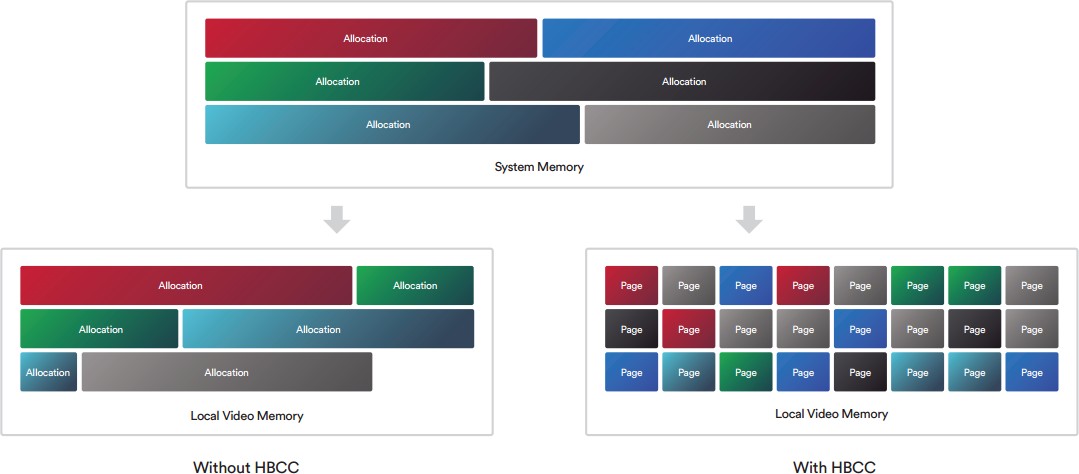
Rohadtul elnagyolt a kép, de tök jól szemlélteti a lényeget. Fent van a rendszermemória, pontosabban annak az a szelete, amit a CPU és a GPU is elér. A HBCC nélkül az allokációk teljes egészében kerülnek át. Innen ered a hagyományos modell problémája, mert lehet egy allokáció 100 MB-os is, de abból elképzelhető, hogy csak 4 kB-nyi adat kell. Tehát ebben a példában 4 kB-ért kötelező 100 MB-nyi erőforrással fizetni a VRAM oldalán. A HBCC-vel elég csak azt a 4 kB-os lapot átmásolni, legrosszabb esetben két lapot. Vagyis csak az van ott a GPU melletti lokális memóriában, amire tényleg szükség van. Így éri el ez a modell a 100%-os hatásfokot. Olyan lap nem kerülhet bele a HBC-be, amire nincs szükség.
Visszatérve a HBCC nélküli megoldáshoz láthatod, hogy ott is ugyanúgy bekerül az adat a VRAM-ba, csak jóval több, mint ami szükséges. Ergo az egy szintén reális megoldás, hogy maga a VRAM legyen mindig jóval nagyobb, mint amire reálisan szükség lenne, mert így bőven elfér az az adat is, amihez a program az adott időszakban hozzá sem fog nyúlni, de muszáj betölteni, mert az absztrakció olyan magas szinten valósul meg, hogy nem lehet lapszinten menedzselni a lokális memória tartalmát. Persze az a "4 kB kell a 100 MB-ból" eléggé extrém eset, nagyon sokszor az allokációk 30-70%-a hasznos adat, de a különbséget jól szemlélteti az extrém példa.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A leírt konfigurációval 11,2 GB-ot tudsz beállítani. Ez a minimum méret. A 24 GB-hoz szükség van 32 GB rendszermemóriára. 8 GB lesz a HBC és 16 GB a rendszermemória fele. Az aktuális exkluzív cache mód előre konfigurált limiteket tartalmaz, hogy egy beállításhoz mennyi rendszermemória kell minimum. Például 64 GB-hoz 96 GB kell.
A másik az inkluzív cache mód. Na itt nincsenek ilyen limitek, de ezt a módot kérnie kell a fejlesztőnek a programban, tehát pusztán driveres szinten nem aktiválható. Ilyenkor viszont maga a VRAM nem is létezik, és előre meghatározott memóriaszegmens sem lesz.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nem. Ez azt teszi lehetővé, hogy a GPU lokális memóriájába csak olyan adat kerüljön be, amit a GPU fel is használ. Ergo az a memória, ami rákerül a hardverre legyen 100%-ban kihasználható a futtatott programtól teljesen függetlenül.
A másik dolog, hogy a rendszermemóriából a HBCC a CPU+GPU közösen elérhető részét fogja HBCC szegmensbe foglalni, vagyis végeredményben ugyanannyi rendszermemóriát igényelne egy hagyományos VRAM-os rendszer. Viszont ehhez előre definiálni kell bizonyos paramétereket, hogy a HBCC lapalapú vezérlése az adott memóriaszegmensre működjön.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A mai játékokban kb. ugyanolyan sebességet kapsz HBCC-t bekapcsolva és kikapcsolva. Ezt kipróbáltuk. HBCC-vel kicsit simább az élmény, mert megmenekülsz a WDDM ellenőrzéseitől, ezért hagyjuk a tesztjeinken aktívan.
A fő kivétel manapság a Shadow of War, ami a külön textúracsomagjával nagyon rosszul működik, és ott az aktív HBCC plusz ~10%-ot hoz. Itt ugye előjön az, hogy a hardver immunis a programkódra, tehát a sebességet az elrontott optimalizálás, vagy annak hiánya nem érinti negatívan.Ahol igazán számít a HBCC azok a 8 GB-nál több VRAM-ot igénylő játékok (nincs ilyen), vagy a Shadow of Warhoz hasonló, rossz streaminggel működő programkódok. Még ha van is elég VRAM-od, akkor is elszenvedi a hardver a programkód problémáit, amire a HBCC immunis.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ezt pont megkérdeztem még a Vega technikai briefingjén, mert ez engem is érdekelt. Jeffrey Cheng, aki tervezte a rendszert azt mondta, hogy ez ugyanúgy megtörténik a hagyományos VRAM-nál is. És ráadásul nem is ritkább maga a jelenség, legalábbis akkor, ha a HBC kapacitásának csak a háromszorosa a hagyományos VRAM kapacitása. Viszont úgy látják, hogy itt is előnyös a HBCC, mert ha esetleg szükség lenne újra az adatra, akkor csak a lapok kellenek, és ez jó eséllyel a teljes allokációnál jóval kisebb, míg a VRAM-os megoldásnál újra vissza kell másolni a teljes allokációt.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 #74018560
#45
üzenetére
#74018560
#45
üzenetére
A next-gen konzolokra való teljes áttérés okozta. Amikor eldobták a PS3 és XB360 portokat, akkor több tartalmat tervezhettek a multiplatform címekbe. Ezért nőtt meg ilyen hirtelen és váratlanul memóriaigény. Szóval alapvetően nem mesterséges, de persze azt nem lehet kizárni, hogy a program oldalán a streaming az átállás alatt nem volt valami optimális. De ez is inkább az alaposabb optimalizálás hiánya az időszűke miatt.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Igazából ezek nem pont a megnövelt memóriamennyiségből erednek, hanem abból, hogy a WDDM nem fog ellenőrzéseket futtatni. De nüansznyik a különbségek, ha a program nincs rosszul megírva.
Nem szükséges több memória. Mint írtam a CPU+GPU által elérhető rendszermemória másképp van kezelve HBCC mellett. Amikor ezt aktiválod, akkor a HBCC fixen detektálja magának az erőforrást, és fizikailag is a meghatározott címtartományra kerül minden CPU+GPU által is elérhető adat. Ha nincs HBCC-d, akkor is szükség van erre, csak ilyenkor a driver nem mondja meg a Windows-nak, hogy milyen címtartományt használjon erre. Alapvetően ezért kell a HBCC-hez Windows 10, mert a korábbi OS-ekben ez nem kivitelezhető. Végeredményben ugyanannyi memória kell a játékhoz HBCC-vel és HBCC nélkül is.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Mivel a HBCC lapalapú menedzsmentet valósít meg, így igazából a programot nem különösebben nézi. Azt nézi, hogy kell-e az adat és mi kell. A lapot pedig szállítja, nem tudja, hogy kinek, de szállítja, mert eszközszinten csak az igényt látja, és arra reagál.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Bekapcsolható. Beállíthatod akármikor. Mi is aktív HBCC-vel tesztelünk.
Alapértelmezett lesz, amikor megszűnik a Windows 7 support, vagy amikor kettéválasztják a Win 7 és Win 10 csomag tesztelését.
(#111) janeszgol: Nem adja oda. A Win csinálja tovább, amit csinálni kell, csak jelezve van neki, hogy a fizikai címtartományon belül hova rakja a CPU+GPU által is elérhető adatokat. Ha azok ott vannak, akkor a HBCC már az operációs rendszer beavatkozása nélkül is képes dolgozni. Az exkluzív cache módnak lényegében ennyi az igénye.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Olvasd el hogyan működik. A későbbi hsz-ekben ezt kitárgyaltuk.
Egyébként ez semmiképpen sem tipp. Ez a rendszer már létezik. Már ma így működik. Semmi olyat nem írtam le ebben a topikban, ami ma ne így működne a gyakorlatban.
Egyedül az inkluzív cache módra nincs gyakorlati példa, de azt nem is igazán tárgyaltuk, mivel az egészet csak az exkluzív cache mód alapján vizsgáltuk.
Az inkluzív cache mód az elméletben annyiban különbözik, hogy nincs HBCC szegmens. Ez a kép szemlélteti a két megoldás különbségét:
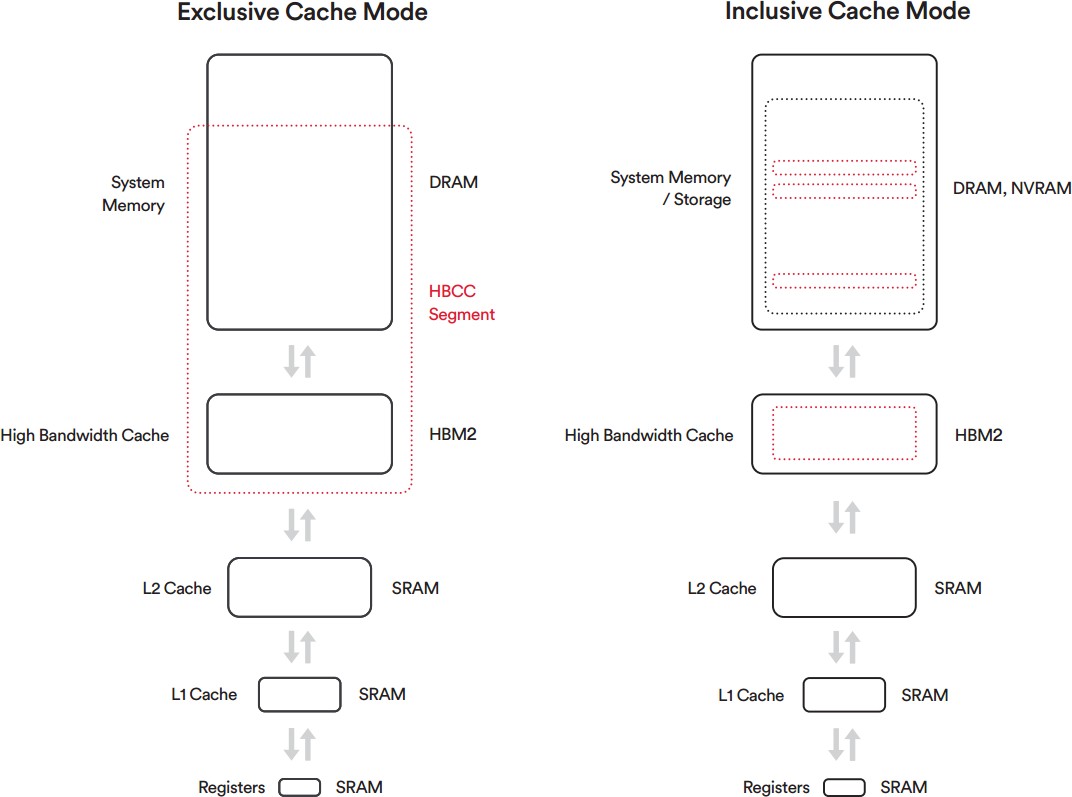
Az inkluzív cache mód aktiválását a program oldaláról kell kérni, míg az exkluzív cache mód driveresen aktiválható.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 janeszgol
#116
üzenetére
janeszgol
#116
üzenetére
A programozásnak ehhez igazából nem sok köze lesz. A HBCC eszközszintű megoldás. Alapvetően az inkluzív cache mód támogatása is csak egy inicializálás, de a program nem menedzsel semmit, csak megengedi a hardvernek a menedzselést.
A HBCC akármilyen módban egy out-of-box hardveres technológia, és direkt program oldali kezelést nem igényel.
Az alapkoncepciója nem sokban különbözik a cache-ektől a processzorban. A gyorsítótárak használatához sem kell direkt támogatás.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Tigerclaw
#119
üzenetére
Tigerclaw
#119
üzenetére
Az AMD olyan keveset tesz majd rá, amennyire csak lehet, mert szoftverben található csúszkával te állítod be a kívánt kapacitást. Én úgy gondolom, hogy a tipikus VRAM target negyedével fognak dolgozni. Legalábbis láttuk, hogy a 8 GB-ot igénylő Deus Ex tökéletesen elvolt 2 GB-tal is exkluzív cache módban. Elképzelhető persze, hogy 1 GB-tal is ellett volna, de erre gyakorlati példa nem volt. Az AMD ezt jobban lemérte már magának, én csak a bemutatott gyakorlati példákból tudok kiindulni, mert olyan meghajtónk nincs, ami korlátozza a HBM2-hoz való hozzáférést.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Minden ismert róla csak el kell olvasni.
Mivel a HBCC eszközszintű menedzsment, így az API mindegy számára. A működése jóval az API absztrakciós szintje alatt valósul meg. Ez az oka annak, hogy a HBCC-s működését nem hátráltatja a rosszul megírt programkód, mert a menedzsment függetlenített a programtól.
(#123) do3om: Ez nem pont a sávszéllel gazdálkodik. Van hatása rá (lásd, amit írt Gbors), de közvetlenül nem ez a célja. A HBCC alapvető feladata, hogy a lokális memóriába kerülő lapok mindegyike igényelt legyen, amivel a memóriában lévő adatok 100%-a hasznos adat lesz. A korábbi modellben nem lapalapú a menedzsment, így az allokációkat másolgatásával rengeteg olyan adat került be a lokális memóriába, amelyekre nem volt szüksége a GPU-nak, de a menedzsment nem volt elég alacsony szintű ahhoz, hogy ezt a problémát meg lehessen oldani. A lapalapú megoldásokhoz mindenképpen hardveres háttér szükséges, míg az allokációk menedzseléséhez elég a szoftveres.
Ez egész alapjára gondolj úgy, mint a CPU-k gyorsítótárára. A koncepcionális alap nagyon hasonló. Alapvetően itt is érvényes a lokalitási elv, csak a feldolgozás mérete miatt jóval nagyobb határok mellett. De ezért van a hardveren GB-os és nem MB-os "gyorsítótár".(#125) gbors: A HBCC szegmensre nem érdemes úgy tekinteni, hogy extra memóriát igényel a rendszermemória oldalán. Ez gyakori tévedés. Induljunk ki az alapértelmezett Vega 10 minimumból. Az 8 GB a kártyán és 4 GB a rendszermemóriában egy 8 GB-os RAM-konfigurációval. Ilyenkor exkluzív cache mód mellett az történik, hogy a meghajtó az operációs rendszert tájékoztatja, hogy a memória felét befogta HBCC szegmensnek. Erről az operációs rendszer tudomást szerez és kap rá egy címtartományt x-től y-ig, ami pont a memória fele. Ezzel lesz 4 GB-nyi rendszermemória azoknak az adatoknak, amelyeket csak a CPU láthat, viszont a játékok igényelni fognak egy olyan szeletet is a rendszermemóriából, amelyet a CPU és a GPU egyaránt elérhet. A HBCC szegmensnél a kijelölt 4 GB használható erre a célra, míg HBCC szegmens nélkül akárhol lehet ez a tartomány. Végeredményben viszont nem lesz több rendszermemória felhasználva, csupán a CPU+GPU által elérhető terület van előre meghatározva a HBCC szegmensnél. Erre viszont HBCC szegmens nélkül is szükség van, csak nem lesz előre meghatározott fizikai címtartomány hozzá. Az adatok viszont akkor is ott lesznek a memóriában. Ha bekapcsolod a HBCC-t a driverben, akkor ugyanúgy megmarad a 8 GB-nyi rendszermemóriád. Még úgy is aktiválni lehet, hogy például egy 7 GB-ot lezabáló CPU-s program éppen fut. Elsötétül a képernyő, visszajön, és fut tovább a program. Egyedül a GPU-t inicializáló programokat kell kilőni, mert a HBCC aktiválásához újra be kell tölteni a drivert, így ezeket a programokat a rendszer lelövi. Gyakorlatilag egy TDR-rel kiszállnak.
(#129) LionW: Eléggé esélyes igen. A hardver szintjén ez a megoldás nem drága, szóval nincs értelme kihagyni a kis VGA-kból, amelyek a legtöbbet profitálnak belőle.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ha tipikusan a fejlesztő oldaláról nézed, akkor a HBCC amire nem kell direkten optimalizálni, mert az az eszközszinten valósul meg, operációs rendszer alatti absztrakcióval. A hagyományos menedzsment viszonylag magasan, a program vagy a kernel meghajtó szintjén dolgozik, tehát az operációs rendszer felett. Ennek a működéséhez erőforrást kell befektetnie a programozóknak. Ha nincs pénz optimalizálni, akkor azzal pont a HBCC jár jól, mert az eleve teljesen függetlenített a programkódtól. De amúgy muszáj, hogy legyen pénz a memóriamenedzsment optimalizálására, főleg úgy, hogy az explicit API-k hatékony működéséhez ez egy alapvető elvárás. Akinek nincs pénze rá, nos ne írjon programot.
Egyébként persze a fejlesztők számára sokkal egyszerűbb lenne, ha mindenhol HBCC lenne, és akkor nem nyomná a vállukat a memória szoftveres menedzsmentje, ami egy komoly teher a PC-n, ahol van egy rakás eltérő memóriával rendelkező hardver. Egyszerűen hagyhatnák, hogy a HBCC oldja meg hardveresen, és kész, munka letudva. Ilyen viszont belátható időn belül nem lesz. Nem elég az, hogy az egyik gyártó megoldja ezt a problémát. Mindenkinek meg kell oldania, és még akkor is ott vannak a legacy hardverek. A dolognak viszont nincs jelentősége, mert a fejlesztő írhat akármilyen szoftveres menedzsmentet, mert a HBCC annak minden hatását képes eliminálni. Tehát az az ideális, ha a HBCC-s hardverekről tudomást sem vesznek. Ezek működnek maguktól is. Ha nagyon akarnak támogatást rá, akkor engedélyezik az inkluzív cache módot, és ennyi. Ez is csak inicializálásra vonatkozó kódot igényel.(#140) gbors: Természetesen, de attól, hogy előre ki van jelölve a szegmens, még a CPU használhatja azt akármire. Ezért van az, hogy egy CPU-t használó alkalmazás nem omlik össze, ha futtatás közben aktiválod a HBCC-t. Ami az aktív HBCC szegmens mellett egyedül kikötés, hogy a CPU+GPU területnek a kijelölt szegmensbe kell esnie. Az nem számít, hogy más adat is van ott, elfér.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ha 20 GB VRAM kell, akkor HBCC nélkül is le lesz foglalva a rendszermemóriában az ehhez szükséges allokációk. A rendszermemóriában nem lesz semmivel sem több adat aktív vagy inaktív HBCC-vel. A különbség annyi lesz, hogy a menedzselés HBCC-vel a lapokra történik, míg anélkül az allokációkra. De mondjuk ha nyersen 20 GB lokális memória kell, akkor ahhoz nem árt majd minimum 64 GB-os VGA-t vásárolni a hagyományos modell tipikus hatásfokát is figyelembe véve, és azért rendszermemóriából sem árt majd ekkor már 128 GB közelében lenni. Ilyen környezetben 8 GB HBC már valószínűleg kevés lesz, mert a rendszer azért csodát nem tud tenni. Ez is ki tud fogyni az erőforrásból, csak jóval később.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#160
Abu85
HÁZIGAZDA
->Raizen<-
#152
Abu85
HÁZIGAZDA
válasz
->Raizen<-
#152
üzenetére
Nekik nem kedvez, mert pont ugyanannyira lényeges a rendszermemória HBCC-vel, mint HBCC nélkül. Az allokációk ugyanúgy ott lesznek mindkét megoldással a rendszermemóriában. Tehát a rendszermemória terhelése nem fog lényegesen változni HBCC-vel vagy HBCC nélkül.
De akkor induljunk ki egy gyakorlati példából. Van egy játék, ami a képkockák számításához tegyük fel, hogy 7-8 GB adatot igényel. Ez már eleve egy olyan tényező, ami ma még felfoghatatlannal tűnik, mert a tipikus adatigénye a játékoknak 2 GB körüli, de nyilván eljön ez az idő is. Talán nem is olyan sokára. Itt már ezek a játékok minimum 32 GB-nyi rendszermemóriát fognak igényelni, mert rengeteg adatot streamelnek. Tehát van mondjuk egy 32 GB-os géped, amiben van egy Vega 8 GB lokális memóriával.
A program igényel magának úgy kb. 5-7 GB CPU által elérhető területet, és úgy 18-20 GB CPU+GPU által elérhetőt területet. Az összes memóriaigény így 27 GB körül lesz, de ugye a dual channel miatt a hardverben muszáj 32 GB-ra ugrani, mert az a következő kétcsatornás lépcső.
A lényeg itt a 16-18 GB-nyi, GPU és CPU által is elérhető terület, ugyanis onnan kerülnek az allokációk a GPU lokális memóriájába. Ha HBCC-d van, akkor beállítasz a meghajtóban egy ideális HBCC szegmenst, és akkor a kijelölésre kerül a Windows számára, hogy hova kell helyeznie fizikailag a CPU+GPU által elérhető adatokat. Innentől kezdve az OS oda helyezi, és ebből 7-8 GB-nyi 4 kB-os lap átkerül a lokális memóriába, és ennek a menedzselése zajlik folyamatosan és hardveresen. Jobb esetben a program elvégzi az inicializálást maga, és akkor inkluzív cache módban fut az alkalmazás, ilyenkor még a meghajtót sem kell megnyitni.
Ha nincs HBCC-d, akkor egy kicsit problémásabb a helyzet, mert ugyanúgy szükséged van arra a 7-8 GB-nyi 4 kB-os lap, de ezeket nem tudod csak úgy betölteni. Ilyenkor a konkrét allokációk kerülnek betöltésre, és itt bele kell számolni, hogy egy allokációnak esetleg csak a 30-70%-a szükséges. Ilyenkor viszont be kell tölteni a teljes allokációt a 70-30%-nyi szükségtelen adattal együtt. És itt még számolni kell a különböző hardveres problémákkal, mint a csatornák keresztbe címzése, vagyis az az ideális, ha egy allokációt akár többször is elhelyezel a VRAM-ban, ugyanis ezzel a módszerrel lesz a feldolgozás a leggyorsabb. Ezt nagyrészt a programozó (program vagy driver) határozza majd meg, mivel teljesen szoftveresen menedzselt rendszerről van szó. Emiatt itt általánosítani nagyon nehéz, már csak azért is, mert a gyakorlatban tipikusan az a jellemző, hogy a program feltölti a VRAM-ot, amíg csak lehet, és amikor betelt, akkor kezdi a probléma menedzselését. Ez nem szerencsés több dolog miatt sem, például a WDDM-nek sem ideális ez a forma, de a rengeteg nehezítő körülményt beszámítva ez tűnik mégis a leginkább működő megoldásnak. Mondjuk úgy, hogy a jobb alternatívák implementálása sokkal nehezebb, és emiatt erre nem feltétlenül éri meg pénzt áldozni. Persze vannak kivételek, például a Sniper Elite 4 motorja akkor is szokott törlést kérni, amikor a terhelés egy rövid időre alacsonyabb lesz, illetve ilyenkor valós időben defragmentál is, hogy egymásra tolja a VRAM-ban található allokációkat, ezzel is helyet nyerve. Mert ugye az sem mindegy, hogy az allokációk mennyire töredezettek. Simán van olyan, hogy a memóriában van még 400-500 MB szabad hely, de esetlegesen nem tudod felhasználni, mert az nem egybefüggően van meg, hanem szétszórtan, így hiába férne be például egy 100 MB-os allokáció 4-szer is, akkor sincs 100 MB-nyi egybefüggő allokálható terület neki. A Rebellion szerencséje, hogy független stúdióként nem mondja meg egy kiadó, hogy a hatékony memóriamenedzsmentre nem ad pénzt, hiszen a játék ugyanúgy eladható a sokkal olcsóbb és bénább megoldás mellett is. Tehát végeredményben hiába kér a program csak 7-8 GB-nyi 4 kB-os lapot, azzal neked hardveres szinten legalább ~16 GB-nyi VRAM-mal kell fizetni. De ha a tipikus optimalizálási modellt nézzük, vagyis a betelik aztán majd menedzseljük koncepciót, akkor már ~24 GB-nyi VRAM kell. És a programnak nem lesz kisebb memóriaigénye a rendszermemória oldalán, ugyanúgy ajánlott lesz hozzá a 32 GB, mert a PC az nem csak egy hardver, itt nem tudsz egyetlen egy memóriakonfigurációra rátervezni mindent. Itt van egy rakás hardver, egy rakás memóriakonfigurációval, vagyis a program igényeit is teljesen általánosra kell szabni, annak érdekében, hogy valamilyen beállítással minél több memóriakonfiguráció mellett működjön. Emiatt van az, hogy amíg régebben a rendszermemória kapacitására vonatkozó igény jóval nagyobb volt, mint a VRAM-ra, addig ma már szinte ugyanannyi VRAM kell, mint rendszermemória. A programok komplexebbek és a bevált menedzsmentrendszerek hatásfoka drámai mértékben romlik.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A HBCC-nek nem számítanak ezek. Ez a rendszer teljesen az eszközszinten működik. Immunis bármilyen eszközszint feletti programozói ténykedésre, legyen annak hatása jó vagy rossz.
Pedig gyakori trükk, hogy egy sűrűn használt allokáció többször is bekerül. Ennek az oka, hogy a crossbar a mai rendszerekben keresztbe csak felezett sávszélességű, vagyis kétszer gyorsabban tölthető be a GPU-ba az adat, ha nincs keresztcímzés. Emiatt a meghajtó nagyon sűrűn fordul ahhoz a trükkhöz, hogy a sűrűn használt adatokat duplikálja a VRAM-on belül, méghozzá úgy, hogy csatornánként egy partícióban ott legyen.
A színtömörítés manapság teljesen általános technológia.
Messze nem ugyanerről van szó, de ha eddig nem sikerült megértened, akkor ezután sem fog sikerülni.

Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Alapvetően igen, csak az eszközszinten oldja meg. Nyilván az AMD nem talált fel semmilyen spanyolviaszt, csak egy évtizedek óta bevált módszert terjeszt ki a GPU-ra. Megtehetik, mert a hardveres igénye lényegében kimerül egy multiprocesszorokba szerelt AMD64-es címfordítóban.
(#171) Kristof93: A megatextúrát, illetve virtuális textúrázást használja még az id, csak nem úgy, ahogy az id tech 5-ben. Programfüggő, hogy miképp valósul meg, de a Doom 16k x 8k-s textúrákat helyez el a memóriában, amelyek 128 x 128-as lapokra vannak felosztva. Ezek lesznek feltehetően szükségesek képszámításhoz, és ha valami új kell, akkor a motor tud 128 x 128-as lapokat cserélni, mivel ehhez van szabva a fix méretű allokáció, ezzel a töredezettség is jól kezelhető. Nagyon hasonló megvalósítást alkalmaz a Frostbite is a terepre.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ha eszközszintű megoldást akarnak, akkor ahhoz kell a licenc. Ha API szintűt, akkor arra már most ott van a Pascalban a megoldás, ami csak a CUDA mellett működik. A Volta is azért ment tovább az eszközszint felé a Power architektúra támogatásával, mert nincs igazán köztes megoldás erre a problémára. Az egyik lehetséges alternatíva az lenne, ha a Microsoft és a Khronos kiegészítené a DirectX és a Vulkan API-t, de annyira át kellene ezeket alakítani, hogy egyhamar ezzel nem végeznének. Hosszabb távon persze mindenképpen érdemes majd bevállalni egy átalakítást.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Itt már a memóriába betöltött adatokról van szó. A PCI Express már nem játszik. Az a probléma, hogy a VRAM is partíciókra van osztva, és nem minden partíció érhető el ugyanolyan sebességgel a GPU belüli blokkoknak. Egy ideje ezzel spórolnak tranzisztort a crossbart használó gyártók, mert maga a probléma kezelhető azzal, hogy a sűrűn használt allokációkat többször berakják a különálló partíciókba, így mindegyik GPU-s belső blokknak lesz egy gyors elérése ugyanahhoz adathoz. Tehát tranyót spórolsz vele, miközben extra memóriával fizetve nem lassulsz semmit. Jelen formában kedvezőbb többletmemóriával fizetni, mint többlettranzisztorral hozni ugyanazt a teljesítményt.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nem. A ROP blokkok azok teljesen a partíciókhoz tartoznak, és a multiprocesszorokhoz nem tartozik partíció. Az történik, hogy a multiprocesszorok nem minden ROP blokkal vannak teljes sebességgel összekapcsolva. Emiatt bizonyos partíciók címzése hátrányosabb, mint más partícióké. A dolog igazából nagy problémát addig nem jelent, amíg van elég warp átlapolni az adatelérést, de vannak bizonyos szituációk, amikor nincs elég warp, és akkor a meghajtó manuálisan trükközik. Erre van egy felépített rutin a driverben, így a problémás alkalmazásokban a sebességért cserébe több memória kerül felhasználásra. Végeredményben ez hasznosabb megoldás, mert kevesebb tranyót igényel maga a lapka, és a problémás szituációkat a meghajtó oldalán le lehet kezelni, és ennek a hátránya csupán a nagyobb memóriaigény.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Kedvező hatással van rá, hiszen maga a menedzselés lapszinten történik, ami lényegesen kisebb adatok mozgatását jelenti a rendszermemória és a GPU lokális memóriája között. Mindemellett a WDDM kellemetlenségei HBCC-vel nem is léteznek. A meghajtó a WDDM egyes parancsait automatikusan kezeli. Például explicit cache módban a WDDM adhat utasítást az allokáció törlésére, de arra vonatkozóan a rendszer nem fog lefuttatni egy ellenőrzést. A meghajtó visszahazudja, hogy kell az allokáció, méghozzá anélkül, processzoridőt vett volna igénybe. Persze a valóságban lehet, hogy nem kell, de hát arról a hardver majd az eszközszinten dönt.
Az eszközszintű működés miatt van, hogy HBCC mellett folyékonyabban futhat ugyanaz a program. [link] - itt egy példa. A felső sarokban láthatod, hogy a frame time grafikonon kisebbek a tüskék aktív HBCC-vel.
Az AMD is a szűk frame time-ot hangsúlyozta, mint aktuálisan tényleg tapasztalható előnyt.A töltőképernyő azért nem sokat ér. Maximum ad egy alapot az indításhoz, de rengeteg folyamat valós időben történik már. Ez igazából nagyon logikus. Amit nem látsz, annak nem kell a memóriában lennie. De lehet, hogy pár másodperc múlva látni fogod, így akkor majd be kell tölteni. A mai rendszerek egyáltalán nem töltenek be előre mindent a videomemóriába. Az az erőforrás nagymértékű pazarlása lenne.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ehhez semmi közük a programozóknak. Az explicit cache mód egy meghajtó szintjén kezelhető funkció. A program fejlesztőjének ezzel semmi dolga nincs.
Az implicit cache mód, amit a program fejlesztőjének kell engedélyezni, mivel szükséges hozzá egy előzetes inicializálás a program indításakor. Itt a programfejlesztő természetesen választhat, hogy rábízza magát a hardverre egy pár soros kóddal, vagy ír egy nagy architektúraspecifikus optimalizálást a Vegára, ami még nem is biztos, hogy gyorsabb lesz az implicit cache módnál. Minden fejlesztő maga eldöntheti, hogy mennyi erőforrást fektet bele. A legtöbben valószínűleg az implicit cache módot fogják választani, mert az sokkal gyorsabban megvan, és az erőforrásukat olyan hardverek optimalizálására fordíthatják, amelyeknek nincsenek eszközszintű menedzseléssel dolgozó hardveres adottságai.Nem tudom, hogy melyik fejlesztő számára realitás egy Vega-specifikus menedzsmentet optimalizálni, amikor a hardver meg tudja oldani ezt magától. Csak az idejüket rabolná le egy szoftveres optimalizálás, mert a user bármikor kiütheti a meghajtóban a HBCC szegmens aktiválásával. Viszont elköltöttek rá teszem azt jó két hetet, így a többi hardverre való optimalizálásra ennyivel kevesebb idő maradt, ezeknek pedig már számít, hogy mit csinál a fejlesztő. Ezt a legtöbben mérlegelni fogják és tök logikus döntés a hardverre bízni a feladatot, mint erőforrást ölni az optimalizálásába.
(#190) namaste: Egy olyan gyártóról beszélünk, amelyik a hardvereit még abszolút minimális szinten sem dokumentálja. A legtöbb fejlesztő abból él, hogy a Twitteren hallotta, hogy valaki egy sarkon kihallgatta az NV mérnökeit, hogy xy textúraformátumnál mekkora a mintavételezési sebesség az egyes szűrési típusokhoz. Merthogy az NV ezt hivatalosan aztán nem mondja el, bármennyire is fontos kérdésről van szó. Én is abból élek, amit az NDA-s briefingeken elmond az NV. Azt, hogy te ezt elhiszed-e a te egyéni döntésed, engem nem különösebben érdekel.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Csak ez nem bug, hanem fícsör. A lényeg a tranyóspórolás a multiprocesszorok és a ROP blokkok összekötésénél. Az így nyert helyet másra lehet költeni. Legacy grafikus API-kban jelenthet problémát, de a meghajtóval ezek jól kezelhetők. Az explicit API-kban ez nem kezelhető, itt elképzelhető a sebességvesztés.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A Pascal működése az NV-nél nagyon titok. Nem igazán reagálnak egyetlen hardverre irányuló kérdésre sem. Arra vonatkozóan általánosan semmit sem lehet mondani. Legjobb esetben is csak következtetni lehet a Maxwellből, hogy talán ugyanúgy működik, de semmi garancia erre.
[link] - itt említettem, hogy a Pascalnak van hasonló API szintű megoldása a CUDA-ra. De más API-val ez nem üzemképes. A Volta helyezi ezt eszközszintre, ahogy a Vega tette az AMD-nél, de a host processzor architektúrájához kötött a működés. A Vega esetében x86/AMD64 a követelmény, míg a Volta esetében Power9. Amúgy egyébként nagyon hasonló a két megoldás, leszámítva a host processzorra és az interfészre vonatkozó igényeket.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Igazából az NV beszélt először magáról az alapproblémáról még az előző évtizedben. Az alapvető kutatások valószínűleg elkezdődtek már úgy 2007 környékén. És ez mindkét gyártóra igaz lehetett, hiszen a Vega és a Volta támogat eszközszintű, lapalapú memóriamenedzsmentet a kompatibilis host processzorok és host interfészek mellett.
A korábbi megoldások zárt API-khoz voltak kötve, tehát az elterjedt API-kkal üzemképtelenek voltak. De hardveres támogatás mellett már az API is lényegtelen, egyedül a beépített technológia hardveres követelményeit kell teljesíteni a működéshez.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Volta alatt már ki van bővítve. A Telsa V100 multiprocesszoraiban van egy-egy címfordító egység, ami képes direkten elérni a Power9 CPU-k laptábláját. De PC-ben ehhez olyan címfordító egység kell, ami az x86/AMD64 ISA-ban meghatározott memóriamodellhez igazodik, ez pedig pont annyira licencköteles, mint a Power9 ISA esetében. Csak amíg az IBM-nél ott az OpenPower konzorcium, addig a PC-nél nincs semmi, vagyis meg kell győzni az Intelt és az AMD-t, hogy licencelje nekik az x86-ot és az AMD64-et. Az AMD megoldása például pont a Power9 ISA memóriamodelljét nem támogatja. Így pont annyira nem ér semmit IBM host proci mellett, mint amennyire az NV megoldása nem ér semmit x86/AMD64-es host proci mellett.
A Pascal által alkalmazott CUDA-s megoldást meg lehet őrizni, csak azzal semmire nem mennek a DirectX, Vulkan, OpenCL és OpenGL API-kra írt programokban.
Egyébként nem tudom miért tartod balfasznak az NV-t a több memória miatt. Ez is csak egy kezelési módja az alapproblémának. Nincs leírva a hírben, hogy ez rossz lenne.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Eszközszinten nem lehet. Az operációs rendszer szintjén lenne rá lehetőség, de ahhoz módosítani kell a meglévő operációs rendszerek struktúráján, ami innentől kezdve a Microsoft és a Linux kernelt fejlesztő közösség reszortja.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.

















Új hozzászólás Aktív témák

ph A következő évben nem lesz ritka a két számjegy a gigabájtok előtt, és akkor még finoman fogalmaztunk.

- NVIDIA Quadro RTX 4000 Ada Generation 20GB GDDR6 új garis eladó
- Nvidia Quadro RTX A2000 12GB GDDR6 192bit LP-normal dobozos VGA eladó
- MSI GeForce RTX 3070 GAMING X TRIO 8GB GDDR6 256bit - Garancia: 2024.05.10-ig!
- GIGABYTE GeForce GTX 1050 OC 2GB GDDR5 128bit Videokártya,hibátlan állapotban,tesztekkel!
- Sapphire HD 4830 512mb/256bit