Az Atom mikroarchitektúrája
Az Atom mikroarchitektúra minden szempontból ellentéte az Intel 1995-ben a Pentium Próval megkezdett stratégiájának, miszerint az x86(/x64)-es programok végrehajtásának legcélravezetőbb módja azok egyszerű, RISC műveletekké bontása és ezek out-of-order végrehajtása. Ahogy már utaltunk is rá, az Atom a minél nagyobb teljesítmény hajszolása helyett egy teljesen más stratégiát választott: minél kevesebb tranzisztor felhasználásával alkotni mikroprocesszort úgy, hogy annak kihasználtsága a lehető legnagyobb legyen. Természetesen meghúztak egy teljesítményszintet, amit el kell érni a lapkával, de a lécet nem tették túl magasra. Nézzük meg közelebbről a megvalósítás részleteit!
Először is kihagyták az összes soron kívüli végrehajtáshoz szükséges logikát a processzorból, így az az utasításokat a programsorrendnek megfelelően (in-order) hajtja végre. Az x86/x64 utasítások sematikusan a következőképpen kerülnek végrehajtásra:
- betöltik forrásadataikat, amelyek közül legfeljebb 1 lehet egy memóriacímen, a többi regiszterben található;
- végrehajtják a számítási műveletet, ha ilyen van az utasításban;
- az eredményt tárolják regiszterben és/vagy egy memóriacímre írják.
Ez a séma minden utasításra ráhúzható, legyen az valós számítási művelet vagy csak egyszerű adatbetöltés a memóriából, illetve adattárolás a memóriába. A modern processzorok tipikusan a felsorolt 3 egyszerű, uop-nak nevezett RISC-műveletre bontják az utasításokat, és ezeket hajtják végre soron kívül, minden uop-típusnak külön végrehajtó egységeket dedikálva.
Hirdetés
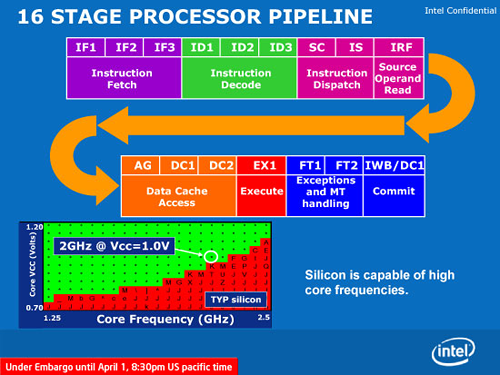
Létezik viszont egy másik megoldási mód is, amikor egyetlen olyan futószalagot hozunk létre a processzorban, amelynek lépcsőit a fenn felsoroltak alkotják: minden utasítás végigmegy minden lépcsőn, közben elvégezve a betöltést, a számítást és a tárolást. Optimális esetben minden lépcsőfokon tartózkodik egy-egy utasítás, és órajelenként továbblép a következőre. Az Atom pontosan ezt valósítja meg, csakúgy, mint a Pentium és az azt megelőző x86 processzorok. Ennek természetesen jó és rossz következményei is vannak: az utasítások dekódolása redukálódik azok elejének és végének megkeresésére, valamint a komplex, mikrokódot igénylő műveletek kiszűrésére; viszont mivel a futószalag úgy épül fel, hogy a lehető legtöbbféle utasítást ki tudja szolgálni, eléggé megnyúlik, soklépcsős lesz: az Atom futószalagja 16 állomásból áll, ami hosszabb, mint pl. a Core 2-é. Továbbá számolniuk kell a tervezőknek azzal, hogy egy-egy hosszabb művelet (például ha a beolvasandó adat nincs az L1 cache-ben, akkor annak betöltése az L2-ből vagy a memóriából) hosszabb-rövidebb időre megállíthatja a futószalagot, tehát egyetlen utasítás miatt nem tud továbblépni a többi sem. Ezt többféle módon kezelték:
- Két pipeline-t tettek egymás mellé, ez - bár az utasítások nem előzhetik meg egymást, – lehetővé teszi, hogy sok esetben 2 egymást közvetlenül követő utasítás végrehajtása egyszerre történjen, ha azok függetlenek egymástól; ezt utasításpárosításnak hívják.
- Mivel hosszú a pipeline, ezért hatékony elágazásbecslő logikát is beépítettek, hogy az utasításbetöltésnek ne kelljen megvárnia az ugró utasítások kiszámítását.
- Újra alkalmazták a Hyper-Threading technológiát, így a két pipeline-t két programszál etetheti: a két szál utasításai biztosan függetlenek egymástól, az esetek nagy részében végrehajtható mindkettőből 1-1 utasítás párhuzamosan. Ha az egyik szál végrehajtása megáll például egy L1-tévesztés miatt, akkor a kért adat megérkezéséig a másik szál teljesen kisajátíthatja mindkét futószalagot.
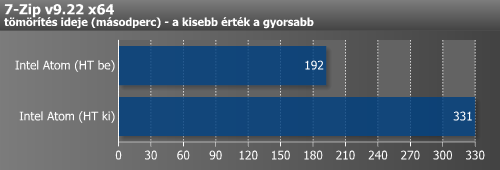

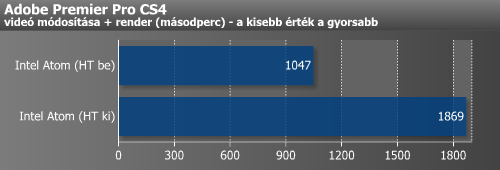
Ha belegondolunk, ilyen megállások esetén nincs meg a processzornak az a választási lehetősége, hogy addig is az adott programszál későbbi utasításait hajtsa végre, mint az out-of-order felépítésnél: egy szál futtatásakor kénytelen megvárni az adatot, két szál futtatásakor pedig szükségszerűen a másik szál utasításait kell végrehajtania. Így meg is magyaráztuk, hogy miért látunk Atomnál a fenti méréseink által is alátámasztott, kétszálas végrehajtásnál akár 70-80%-os gyorsulást az egyszálas futtatáshoz képest, míg a többi Hyper-Threadinggel ellátott CPU-nál ez csak 20-25% körül tetőzik.
Az így összerakott komplett felépítést ábrázolja az alábbi ábra:
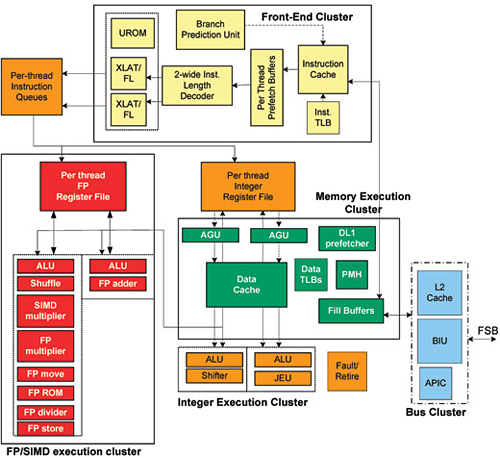
Az előre meghatározott teljesítményszint mellett a tranzisztorszám és a fogyasztás minél alacsonyabban tartásához néhány további trükkhöz folyamodott a tervezőgárda:
- Az L1 cache-eket 6T helyett 8T cellákból építették fel, amelyek ugyan így több tranzisztort emésztenek fel – ezért 32 kB helyett csak 24 kB méretű adatcache-t építettek be –, viszont előnye, hogy alacsonyabb feszültség mellett is stabil működést mutat, így ki lehetett hagyni az L1 adatcache-hez tartozó ECC hibadetektáló és -javító logikát, valamint a szükséges magfeszültség is csökkenthető.
- Két egyszerű adat-előbetöltő (prefetch) logikát alkalmaztak; az egyik a memóriából az L2 cache-be tölt be, a másik az L2-ből az L1-be, így csökkentve a cache-tévesztések miatti futószalag-megállások számát.
- Az utasítások dekódolása eléggé lassú (3 órajel/utasítás), viszont a dekóder feljegyzi az utasítások határait és komplexitását az L1 utasításcache-be, így ha újra találkozik a már egyszer feldolgozott utasításokkal pl. ciklusok esetében, akkor órajelenként 2 utasítást tud küldeni végrehajtásra.
- A processzor az SSE4 kivételével támogatja az összes SIMD-utasításkészletet, amit a 65 nm-es Core 2 is, ezek az MMX, SSE, SSE2, SSE3, SSSE3, viszont csak az egyszerű SIMD-integer műveletek és a 32 bites Single Precision lebegőpontos összeadások kaptak 128 bites végrehajtó egységet, a többi műveletet két 64 bites lépcsőben hajtja végre. Ezáltal a két pipeline SIMD és lebegőpontos része specializált, ezen műveletek meghatározottan csak egyik vagy csak másik pipeline-ban kerülhetnek végrehajtásra (természetesen akár párosítva egy másik, megfelelő utasítással).
- Ugyancsak specializált a memóriakezelés szempontjából is a két pipeline, ugyanis a memória-alrendszerhez csak az egyiknek van hozzáférése, ezáltal minden memóriaparaméteres utasítás erre a futószalagra kerül. Így nincs szükség a hozzáférések költséges összehangolására, bizonyosan mindegyik a megfelelő sorrendben kerül végrehajtásra.
- Bár sok változatában le van tiltva, alapvetően támogatja az x64 végrehajtási környezetet, viszont 32 bites programok végrehajtása közben lekapcsolja a +32 bithez szükséges regiszter-területeket és műveletvégző egységeket.
A cikk még nem ért véget, kérlek, lapozz!