- Azonnali informatikai kérdések órája
- Intel Core i3 / i5 / i7 / i9 10xxx "Comet Lake" és i3 / i5 / i7 / i9 11xxx "Rocket Lake" (LGA1200)
- Gaming notebook topik
- Milyen TV-t vegyek?
- Projektor topic
- Milyen videókártyát?
- NVIDIA GeForce RTX 4060 / 4070 S/Ti/TiS (AD104/103)
- Apple notebookok
- TCL LCD és LED TV-k
- Bambu Lab X1/X1C, P1P-P1S és A1 mini tulajok
Hirdetés
-


MediaTek lapkával érkezhet a következő Samsung csúcstablet
ma Merőben szokatlan lenne, ha a Samsung nem Qualcomm vagy Exynos szettet használna a prémium termékvonalon, de a Geekbench szerint mégis ez lehet a helyzet a Tab S10+ esetében.
-


Demót kapott a Steel Seed (PC)
gp A Steam Next Fest keretén belül bárki kipróbálhatj a készülő játékot.
-


Spyra: nagynyomású, akkus, automata vízipuska
lo Type-C port, egy töltéssel 2200 lövés, több, mint 2 kg-os súly, automata víz felszívás... Start the epic! :)






Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
A Kaveri inkább a konzolokhoz igazodik. Azokat a szolgáltatásokat amiket támogat a két új konzol, átmenti PC-re, így a PC-s portból nem kell kivágni az effekteket/extrákat. Már 2014-ben lesznek ilyenek. 2014-től a Fifának három évig két programkódja lesz. Egy a HSA hardverekhez, és a butított a többi konfighoz.
(#17) Bici: Amelyik konzoljáték az IGP-t használja általános számításokra az portolhatatlan PC-re. Ilyen a Fifa 13. Ezért kap a PC butított portot, amit a PS3 és az Xbox 360. Az AMD azt találta erre ki, hogy partnerkednek az EA-val és két programkód lesz pár évig a PC-s Fifában. Ha van hardvered hozzá, akkor a modernebb portot is eléred. A grafikát meg majd számolja a VGA.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A HSA-val nem fordulhat elő, hogy másképp fut a megírt kód a többi gépen. Ez a rendszer egyik alappillére. A fordítást minden gyártónak a saját finalizere végzi. Úgy működik a rendszer mint a Java. Lesz egy runtime, és mögötte a kapott HSAIL kód fordításáért egy gyártói finalizer felel, ami küldi a hardverhez a kódot. Ma is így működik a GPU-s dolog, csak az a különbség, hogy a HSAIL az egy szabványos vISA lesz, míg ma minden gyártó sajátot használ.
Az Intel és az NV GPU-kra eleve nem fordul majd HSAIL kód. Azokra a rendszerekre legacy opció lesz, vagyis a lapkában található processzoron fut majd a kód.
A direkt programozás kizárt. Erről már Johan Andresson is beszélt, nincs rá pénz és idő. Ő már kiadta az ultimátumot, hogy vagy beáll mindenki a HSA mögé, vagy aki nem áll be az így járt.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

dezz
nagyúr
Az Intel a tőkéjével ér el sokmindent, miközben az ilyen kis cégeknek, mint az AMD, nem nagyon marad más, mint az kreativitás, szellemi innováció...
Ez a "HSA maszlag", tehát a GPU valós beemelése a rendszerbe (eddig csak mint "külsős" dolgozott) szerintem nagyon is forradalmi dolog.
Az AVX512 a szokványos FPU némi kibővítése, de szerintem hosszabb távon nem bizonyul túl hatékonynak.
Az OpenCL-nek valóban van egy overheadje, a HSA részben pont ennek alapos lefaragása érdekében született.
[ Szerkesztve ]
-

stratova
veterán
Sajnos én nem merültem el ebben kimondottan részletesen. Programozás szintjén pedig egyáltalán nem. Nekem úgy tűnik, maga a HSA is változik idővel. Gondolom a hardverek/integráció előrehaladottságával párhuzamosan.

Elvileg a pointerek + zero copy hivatott mérsékelni a pl. Llano esetében sem éppen bőséges sávszélességet.
De a GDDR5 elvetését én sem értem. A Sony is amellett tört lándzsát. Ha másutt nem is Opteron vonalon tán még kifizetődő is lehetne (bár ott a kimondottan nagy mennyiségű memória is szempont).
-
dezz
nagyúr
A HSA-t nem húzzák rá az OpenCL-re (esetleg fordítva), mert ez egy rendszerarchitektúra. A kedvedért ide másolom a linkről:
"Heterogeneous System Architecture
Heterogeneous System Architecture (HSA), maintained by HSA Foundation, is a system architecture that allows accelerators, for instance, graphics processor, to operate at the processing level as the system's CPU. To ease various aspects of programming heterogeneous applications, and to be HSA-compliant, accelerators must meet certain requirements, including:
- Be ISA agnostic for both CPUs and accelerators
- Support high-level programming languages
- Provide the ability to access pageable system memory
- Maintain cache coherency for system memory with CPUs, and so on.[17] HSA is widely used in System-on-Chip devices, such as tablets, smartphones, and other mobile devices.[18] HSA allows programs to use the graphics processor for floating point calculations without separate memory or scheduling.[19]"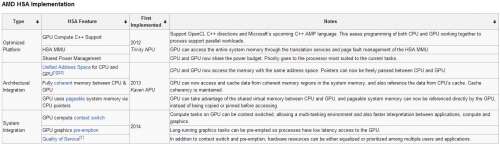
Az OpenCL csak egy lehetőség a több közül a HSA-compliant HW programozására.
Amiket írsz, az első és második bekezdésben is, nos abból nem az jön le, hogy ismernéd és értenéd, sőt éppen ellenkezőleg. A helyedben inkább alaposan utánanéznék, mielőtt nyilatkozok róla.
A HSA többek között éppen, hogy közvetlenebb, egyszerűbb és gyorsabb hozzáférést biztosít a GPU-hoz:

E helyett:

Ajánlott olvasmány(ok): [link]
[ Szerkesztve ]
-
dezz
nagyúr
Én is programozom (idestova 25 éve). Igaz, a GPU programozással, OpenCL-lel csak mint érdekesség ismerkedem, érintőlegesen (jelenleg nincs rá szükségem és időm sem, bár kedvem lenne szórakozni vele). Mindenesetre tudom, milyen távol tud állni egy rutin/függvény megírása egy rendszerre az utóbbi beható ismeretétől. Meg hát az OpenCL és a HSA más állatfaj. Nem értem, miért esik ennyire nehezedre akár csak az alap pdf elolvasása. Előre eldöntötted, hogy bukásra ítélt hülyeség az egész GPGPU téma, mert hogy jön majd a megváltó AVX512, ezért annyira sajnálod rá az időt, hogy meg sem nézed, pontosan miről is van szó?
Igen, többektől hallottam már, hogy sokat lehet szívni az OpenCL-lel. Kb. ugyanígy van a CUDA-val is (vagy pl. az FPGA-kkal, ehhez képest egy egész iparág foglalkozik vele). Aztán valahogy mégis sikerül összehozni, amit akarnak. Ha kell, kerülőutakon. Egyébként szerintem konzultáljatok lenox-szal (lásd blogja!).
Szóval, jelenleg OpenCL és C++AMP, de nem sokára Java is, aztán C++ és a többi. De valószínű az OpenCL compilernek is könnyebb dolga lesz a HSA-compliant hw-eken (most teljesen más architektúrák között kell hidat képeznie.) A HSA nagyon sokmindent leegyszerűsít, megkönnyít és felgyorsít. Programfejlesztés és végrehajtás terén is.
Az Xbox One-ban is ott van az EDRAM, márpedig ez volt az olcsóbb opció a PS4 GDDR5 ramos megoldásával szemben. Lehet persze, hogy desktopra/mobil vonalra így is drága, nem tudom. Megjegyzem, nem feltétlen kell 128 MB belőle (mint az Iris Pronál), hogy sokat gyorsíthasson a számításokon. A DDR4 nem létszükséglet mellette (inkább a CPU-nak van rá szüksége).
[ Szerkesztve ]
-
dezz
nagyúr
Pl. #33-asból eléggé ez jött le. Nem tudom, mennyi realitása van, hogy a programozók nekiállnak direktben különféle GPU-khoz low-level kódolni GPGPU-s alkalmazásokat, amikor eleve a CPU-tól is nehezen szakadnak el? Vagy tulajdonképpen az Intel AVX-512 alapú GPU-szerű, x86 alapú chipjeire gondolsz, ami talán véleményed szerint idővel majd kiszorít mindent, így a végén nem kell majd többfelé kódolni? Én meg erre nem fogadnék.
A HSA-nak csak egy része a HSAIL-es megoldás. A HSA kompliancia adott szintjeihez tudnia kell a hw-nek az ezen a képen látható tulajdonságokat. Ezek könnyítik meg a programozó és a compiler dolgát és teszik gyorsabbá a több szinten a folyamatokat. (Talán nem kell ecsetelnem a közös címtér, pointerek, lapkezelés, koherens memória- és cache-kezelés előnyeit. Aztán jön majd a többi.) A HSA tehát a korábbiaknál nagyobb elvárásokat támaszt a GPU-kkal szemben, hogy mindezzel sokkal jobb alapokat nyújtson GPGPU-s célra.
A HSAIL-nek lényeges eleme a portolhatóság (ami manapság igen fontos szempont), de nem csak ezt tudja. Nem ront az eddigi OpenCL-es "helyzeten", hanem javít. Gyorsabbá teszi a funkció invokációt, stb.
Maga az egész HSA nagyban optimalizálja az egész GPGPU-s funkcionalitást. (Nem csak a host <-> device sávszélt.)
Nem tudom, a HSA hogy viszonyul a dGPU-khoz, nem biztos, hogy parlagon hagyja őket.
A HSA Finalizer közvetlenül az adott platform CPU-jára is tud natív kódot fordítani, a HSAIL kihagyásával.
Ha az eDRAM vagy eSRAM cache-ként funkcionál, akkor különösebb szoftveres bűvészkedés nélkül is sokat tud segíteni a sávszélproblémán.
Egyelőre nem nagyon ismerjük az AMD későbbi terveit. Megtehetik, hogy gondolnak egyet, és a dGPU-ik helyére is (brutális) APU-kat tesznek majd... Az Nvidiának is vannak efféle tervei, csak x86 licencek híján ARM alapon.
-
dezz
nagyúr
Sok közös vonás van a HSA és az OpenCL 2.0 között. Ebből is láthatod, hogy nem haszontalan dolgok ezek.
 Jól megférhetnek egymás mellett, sőt egymást erősítik. Ha egy hw támogatja az OpenCL 2.0-át, onnan már nem sokból áll a HSA támogatása. A HSA jobb kompatibilitást és könnyebb portolhatóságot biztosíthat a programoknak, az OpenCL mellett más nyelveken írottaknak is.
Jól megférhetnek egymás mellett, sőt egymást erősítik. Ha egy hw támogatja az OpenCL 2.0-át, onnan már nem sokból áll a HSA támogatása. A HSA jobb kompatibilitást és könnyebb portolhatóságot biztosíthat a programoknak, az OpenCL mellett más nyelveken írottaknak is. -
dezz
nagyúr
Persze, az Intel is megteszi, ami tőle telik, csak nem vagyok biztos benne, hogy ez hasonlóan energia- és helytakarékos/-hatékony tud lenni, mint egy GPU, aminek a nagy részét az "ömlesztett" ALU-k teszik ki.
Jelenleg az egyik legnagyobb gátja a GPGPU-zásnak a kernelek körülményes és nagy késleltetésű indítása. Ezért kisebb számításokat nem érdemes GPGPU alapon megvalósítani. Ennek megoldása egy jelentős lépés lesz. Az már az adott számítástól függ, hogy milyen sávszélre van szüksége.
Az Xbox One-t csak az eSRAM vélhetően GDDR5-nél alacsonyabb költsége kapcsán említettem meg. (Igaz, ott az CU-kból is kevesebb van.)
-
Abu85
HÁZIGAZDA
Az OpenCL-nek az a gondja, hogy a kód teljesítménye és működése nem portolható direkten. A későbbi fejlesztésekkel az lesz, de ma még nem az. A gondot tetézi, hogy az AMD OpenCL implementációja igen specifikus, tehát a manapság jellemzően erre optimalizált programok igen rosszul működnek a többi cég OpenCL meghajtóján. A WinZipnek ez volt a baja egy évig, így a 16.5-ös verzió nem is működött az Intel és az NV termékeken, de a 17-es verzió már igen. Az Adobe jelenleg ugyanezzel a gondal küzd. Működik a többi hardveren az OpenCL implementációjuk, de annyira az AMD-re szabták, hogy iszonyatos hátrányban vannak a többiek a sebesség szempontjából. Ezért vannak a HSA mellett, mert azzal portolható teljesítményű kódokat írhatnak.
John Carmack sosem volt a direkt programozás mellett. Sweeney volt az, aki azt mondta régen, hogy a direkt GPU programozás a jövő, és lesz egy GPU-architektúra, ami domináns lesz, és csak arra kell dolgozni. A többiek majd szépen kiesnek. Ezzel ugye az a probléma, hogy nyilván a konzolok miatt ezt az AMD igen támogatja, hiszen a GCN lett a Sweeney által vizionált domináns architektúra, de szerinted egy Intel vagy egy NVIDIA ehhez mit szól? Az meg kizárt, hogy háromszoros munkát végezzen egy fejlesztőcsapat, mert egyszerűen nincs meg rá az anyagi keret. A PC-s porton nincs pénz, a konzolos portok hozzák az eladást.
Carmack a HSA-s jövőképről ennyit mondott egyszer egy interjúban: "The current generation Fusion parts are really a separate CPU and separate GPU connected on the die by better or worse interconnects, but their vision is integrating them much more tightly such that they share cache hierarchies, address space, and page tables. I think its almost a foregone conclusion that its going to be the dominant architecture in the marketplace ..."
Igazából őt ma a megatextúrázás érdekli, és jelenleg két cég (AMD és NV - még az ARM is, de ők ultramobil szint) kínál olyan GPU-architektúrát, ami tartalmaz MMU-t, és képes bindless textúrázásra. Ezzel már hardveresen támogatható a megatextúrázás, ahogy az OpenGL ezt fel is vette ARB-be. Az AMD annyiban kínál extrát a PRT-vel, hogy a GCN úgy támogatja a megatextúrázást, hogy minden hardver által támogatott textúraformátum megfelelő, így nem kötelező tömörítetlen textúrát használni.A GPU-k tervezése nem olyan egyszerű, mint azt sokan gondolják. Sokkal nehezebb összerakni egy ilyen rendszert, mint egy CPU-t. Bárki le tud rakni az asztalra egy működő GPU multiprocesszort, mert az nem nagy dolog, de egy olyat, ami skálázódik is, az már nehéz. Oda 10-20 év tapasztalat kell és nem dollármilliárdok. Tipikus példa erre a Larrabee. Az Intelnek is volt tapasztalata és szakembergárdája, csak a vezetőség elküldte azokat az embereket, akik azt mondták, hogy a Larrabee sohasem fog működni. Itt követték el a hibát, hallgatni kellett volna rájuk. Főleg John Gustafsonra, Michael Abrashra, vagy Andrew Richardsra. Ők a világ legokosabb emberei a parallel computing területén, és semmibe vették a véleményüket. Végül nekik lett igazuk.
A Larrabee ma a MIC. Annak hatékony kihasználásához van a vector intrinsics, de ez olyan mintha assemblyben programoznál. Nem fogom elhinni a programozókról, hogy ez számukra kedvezőbb, mint a C++. Szóval én ezt a direkt programozást kapásból kilövöm, senki sem szeretne Assembly szint közelében data parrallel kódot írni, még az Intel kedvéért sem.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az Intelnek még nincs Gen8 IGP-juk. A Haswell az Gen7.5. A Broadwell is az lesz, de nem biztos, hogy fejlődik, mert a 20 EU-ről 40-re lépés 10% pluszt hoz, és a tervezett 40-ről 80-ra lépés semmi gyakorlati sebességelőnyt nem jelent. Éppen ezért a mai Gen7.5-tel nem érdemes 40-nél több EU-t beépíteni, mert hiába raknak bele akár 500 EU-t, 40-nél nem skálázódik tovább a teljesítmény. Ez tipikus GPU-architektúra para. A rendszer elérte az úgynevezett skálázhatósági maximumot. Ez minden gyártóra érvényes, és ez az oka, amiért az NV, az AMD, és az ARM-os grafikában utazó társaság 4-7 évente kidobják a kukába az aktuális GPU ISA-t és terveznek egy újat, ami jobban skálázódik majd.
Itt elértünk oda, ahol a Larrabee életképtelen volt, és az egész AVX is az lesz. Nem tudod kidobni, így ha eléri a skálázhatósági maximumot, és a Larrabee azért nem jelent meg, mert már elérte, akkor ennyi volt. Nem lehet tovább növelni a teljesítményét. A Knights Ferry 32 magból nagyjából 12-14 magig skálázódott grarfikai számítás során, minden beépített mag afölött csak tranzisztorpazarlás volt. Ez ellen a Knights Corner úgy védekezik, hogy óriási cache-t és belső buszrendszert használ. Ezzel a skálázhatóság biztosítható, de csak akkor, ha minden adat ott van a mag saját L2 gyorsítótárában. Így működhet a MIC, de kérdés, hogy mennyire gazdaságos egy maghoz 1-2 MB-os gyorsítótárat fenntartani, illetve mi lesz akkor, ha a háromszöglista mérete nagyobb lesz, mint amennyi a hardver által támogatott mérethatár. Ilyenkor a feldolgozást két fázisra kell bontani mélységpufferrel, ami nagyon kellemetlen lesz a teljesítményre nézve. Illetve kötelező lesz a programozók számára a scene markerek használata, mivel ezek nélkül a hardver nem tudja majd, hogy minden háromszöget felpatchelt-e, vagy esetleg van még ilyen elem a mozaikon belül. És ha van, akkor az látszik-e, mert ha látszik, és nincs benne a listázásban, akkor az megjelenítési hiba lesz. Nem véletlen, hogy ma már az ultramobil szintre fejlesztő GPU-s cégek is menekülnek ettől a feldolgozási elv elől.Tök esélytelen ez az egész MIC és AVX irány. Nem véletlen, hogy minden legalább egy maréknyi GPU-s tervezési tapasztalattal rendelkező cég elveti. Túl sok vele a programozói probléma, és a skálázhatóság megszűnésével az egész átcsap masszív tranzisztorpazarlásba, mert direkt programozás mellett nem tudod lecserélni az ISA-t
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
De nem fog működni a direkt programozás. Ezerszer nekivágtak már a gyártók ennek, de sosem jutottak egyezségre, mert megakasztja a fejlődést. Azok a cégek, amelyek GPU-architektúrát fejlesztenek tényleg nem viccből cserélik le az ISA-t 4-7 éves ciklusokban. A GPU-knál a memóriamodellbe van beletervezve a skálázódás, ami szükséges, hiszen egy multiprocesszor sokszáz, vagy többezer szálat kezel párhuzamosan. Meg lehet enélkül is oldani, csak akkor irtó tranzisztorpazarló lesz az egész, mert amit amúgy megoldanak az ISA szintjén azt a gyorsítótárakkal kell helyettesíteni. Nem véletlenül dolgozik a Larrabee/MIC multiprocesszoronként 512 kB-os L2 gyorsítótárral és egy baromi vaskos belső busszal. A többiek ezt elvetik, mert nekik erre nincs szükségük, hiszen a rendszereik 16-32 vagy akárhány MB-os gyorsítótár nélkül is működnek.
Az x86 skálázása is lehetséges ilyen módon, csak lassan 1 MB-os tár kell magonként, aztán 2 MB-os, és a buszrendszert is folyamatosan duplázni kell. Ez korlátozza a lehetőségeket, mivel a legtöbb tranzisztor nem a feldolgozókra megy el, hanem a skálázódást biztosító buszra és L2-re, amivel viszont a többiek nem élnek, mert ők nem restek letervezni egy új ISA-t.
Egyébként ha a fenti probléma nem lenne már rég lenne egy közös ISA és a GPU-kat direkten programoznák a fejlesztők, csak hát van ez a probléma. Abból pedig hiba kiindulni, hogy ha az x86 vagy az ARM 4-8 maggal megfelelő skálázódást mutat, akkor bizony kötelessége 40-80 maggal is azt mutatnia. Nem, sajnos ez nem így működik.Szerintem, ha az Intel bármit el akar érni, akkor a mostani architektúrát kell gatyába rázni. A Larrabee/MIC látványosan nem működik, kár erőforrást pazarolni rá. A grafikában óriási hátrány lesz a mozaikos deferred feldolgozás. A ZiiLabs-ot vették meg a Creative-tól, de ők csak úgy illenek a képbe, ha olyan lenne a lapka, hogy lenne pár főmag, lenne egy ZiiLabs-féle számolótömb, és maradna egy Genx IGP, amiben lennének a fixfunkciós egységek. A Parallella efféle dizájnokat már felvázolt. Igaz a saját rendszerükkel, de a ZiiLabs architektúrája ettől nem sokban különbözik. Ha a Parallellával működik, akkor működni fog a Zii-vel is.
A Gen 7.5 egyébként annyira nem tragikus. Mint hardver nyilván több ponton az, de mint irány igen jó, hogy az Intel felismerte a problémákat. Végre belátták, hogy minden amit eddig csináltak semmit sem ér, mert már a driveren elvesztik a teljesítmény zömét. Az írjuk újra felfogás tehát üdvözlendő, és úgy írják újra, ahogy az AMD és az NV évek óta csinálja, vagyis a driver parancsai az API-hoz igazodnak, erős profilozással, és komplex rutinrendszerrel. A mostani architektúra nyilván kuka ebben a formában, mert felesleges bele 80 EU-t rakni, ha a teljesítményen nem látszódik majd. Kell egy új alap, és arra fel kell húzni egy jobban skálázódó rendszert. Az Intel ráadásul maradhat az egyszerűbb szeletes skálázásnál, mert őket csak az IGP érdekli. Csak az AMD-nek és az NV-nek szükséges a jóval komplikáltabb tömbös skálázás, mert nekik 300+ wattos VGA-khoz is kell lapka.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.



![;]](http://cdn.rios.hu/dl/s/v1.gif)


 Jól megférhetnek egymás mellett, sőt egymást erősítik. Ha egy hw támogatja az OpenCL 2.0-át, onnan már nem sokból áll a HSA támogatása. A HSA jobb kompatibilitást és könnyebb portolhatóságot biztosíthat a programoknak, az OpenCL mellett más nyelveken írottaknak is.
Jól megférhetnek egymás mellett, sőt egymást erősítik. Ha egy hw támogatja az OpenCL 2.0-át, onnan már nem sokból áll a HSA támogatása. A HSA jobb kompatibilitást és könnyebb portolhatóságot biztosíthat a programoknak, az OpenCL mellett más nyelveken írottaknak is.Új hozzászólás Aktív témák

ph A gyártók két microATX-es modellel készül az év végére, melyek támogatják a Kaveri APU-t is.
