Az NVIDIA készül a CUDA 6 bemutatására, ami első látásra nem akkora durranás, mint az egy éve megjelent CUDA 5, de ezúttal az igazi finomságok a részletekbe rejlenek. A vállalat temérdek új funkció beépítése helyett egy égető probléma megoldására koncentrált, mely a programozóknak igencsak megnehezíti az életét. A GPGPU mindig is attól a gondtól küzdött, hogy a CPU-nak és a GPU-nak két különálló memóriája van. Ezt a CUDA korábbi verziói megpróbálták kezelni, de igazán átfogó megoldás még nem született rá.
Hirdetés
A probléma szoftveres oldalon annyi, hogy az adatok folyamatos másolgatását a programozónak meg kell oldania a programkódban, és a használható sebességű implementáció szempontjából ez kulcsfontosságú, hiszen a GPU-s gyorsítást a nem jól kivitelezett adatmásolások könnyen GPU-s lassítássá változtathatják. Éppen ezért minden GPGPU-s program esetében a legfontosabb optimalizálást az adatok másolása kapja a különálló memóriaterületek között. Ez sokszor igen extrém algoritmusokat szül, ami önmagában nem feltétlenül hatékony a GPU-n, de a memóriamásolás szempontjából már az, tehát összességében az adott program hatékonysága is nő. Ez adja ennek az iránynak a nehézségét, mivel nem a GPU hatékony kihasználásával lesz gyors a kód, hanem a memóriamásolások minél jobb optimalizálásával.
A CUDA 6 egy alapvető megoldást kínál a problémára, mivel a rendszer bevezeti az egységes memóriakezelést. Ez elsődlegesen csak egy látszat, mivel a CPU és a GPU továbbra is két különálló fizikai memóriával rendelkezik, de a programozónak ezzel mostantól nem kell törődnie. Persze a különálló fizikai memóriaterületek miatt elképzelhető olyan szituáció, ahol kézileg optimalizálva esetleg egy picit gyorsabb kód írható, de a nagy átlagot figyelembe véve valószínűleg hatékonyabb lesz, ha a CUDA kezeli ezt a problémát.
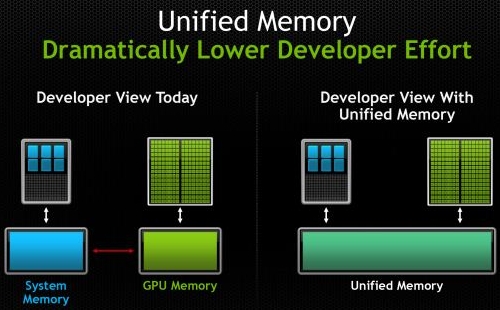
Ez a rendszer egyébként egy úgymond lite verzió, mivel a hardveres oldalon nem oldja meg a memóriamásolások gondját, tehát ezek továbbra is megtörténnek, így csodát nem kell várni. Az újítás kihasználáshoz Kepler architektúrára épülő grafikus processzor kell, a központi processzor utasításarchitektúrája pedig nem érdekes, tehát lehet ARMv7, ARMv8, x86 és AMD64 is, illetve ez még a jövőben kiegészülhet. Az NVIDIA ezt úgy éri el, hogy menedzselt pointereket vezet be, és ezek automatikusan elintézik az adatmásolásokat. A később érkező úgymond full verzió ennél jóval több lesz, és ez a rendszer mindenképp Maxwell architektúrára épülő integrált grafikus processzort igényel, illetve a lapkán belüli processzorrésznek is ARMv8-as magokat kell használnia. Utóbbi modellel már fizikai szinten is mellőzhetők az adatmásolások, hiszen egy ilyen SoC hardveresen is egységes virtuális memóriát támogat.
A CUDA 6 az alapvető fejlesztés mellett tartogat még némi optimalizálást, így többek között megjelentek az automatikus tempónövekedést eredményező BLAS és FFT könyvtárak is. Bár látszatra ez nem tűnik soknak, de a finom részletek ismeretében kétségtelen, hogy ez a legnagyobb előrelépés a CUDA történelmében. A mély integrációt megvalósító hardveres alap biztosítása lesz a következő nagy dobás, így a későbbi CUDA verziók is nagyon fontos fejlesztéseket fognak kínálni, amelyek alapvetően meghatározzák majd az NVIDIA jövőjét.
A CUDA 6 fejlesztőkörnyezet a következő év első negyedévében lesz letölthető. Esetleg az érdeklődők felvehetik a kapcsolatot az NVIDIA-val, hátha van lehetőség a tesztverzió kipróbálásra.





