Hirdetés
Új hozzászólás Aktív témák
-

jattila48
aktív tag
válasz
 jattila48
#4467
üzenetére
jattila48
#4467
üzenetére
Azt hiszem, sikerült kisilabizálni a választ. Függvény nevek esetén a név dekoráció (vagy manglálás) azért kell, hogy a linker meg tudja különböztetni az overload-olt fv. neveket. Ez világos (és eddig is az volt). Függvény pointer nevek azonban nem overload-olhatók, ezért ott nincs szükség név dekorációra, így az extern "C" deklarációnak (ami elnyomja a C++ név dekorációt) sincs értelme. Gondoltam én. Csakhogy fv. pointer nevek esetén a dekorációt nem az overload-olás miatt használják, hanem a hívási konvenció miatt. A különböző TU-kban deklarált és definiált ugyanolyan nevű fv. pointereknek meg kell egyezni a hívási konvencióban. Eddig azt gondoltam, hogy nincs külön C és C++ hívási konvenció (mint ahogy MS fordítóknál nincs is), de elképzelhető, hogy más fordítóknál ez másképp van. Legalábbis a lehetőségét fenntartják.
érdekes olvasmány: [link]
Idézet a cppreference.com -ról:
"Since language linkage is part of every function type, pointers to functions maintain language linkage as well. Language linkage of function types (which represents calling convention) and language linkage of function names (which represents name mangling) are independent of each other"
Tehát a fv. típus és fv. név language linkage-e (mint pl. az extern "C") két különböző, és független dolog. Eszerint fv. pointer esetén a language linkage a pointer által mutatott fv. típusára utal (hívási konvenció), nem pedig a fv. pointer névre.
Elnézést a hosszú hozzászólásért, remélem azért érthető volt min problémáztam.
-
jattila48
aktív tag
-

Archttila
veterán
válasz
 Archttila
#4452
üzenetére
Archttila
#4452
üzenetére
Na, csak megoldottam
 most viszont a decodernel problemazik (de legalabb mar kozelebb vagyok a vegehez)
most viszont a decodernel problemazik (de legalabb mar kozelebb vagyok a vegehez) Found ninja-1.11.1 at /usr/bin/ninja
[456/733] Compiling C++ object src/decoder/plugins/libdecoder_plugins.a.p/FfmpegIo.cxx.o
FAILED: src/decoder/plugins/libdecoder_plugins.a.p/FfmpegIo.cxx.o
clang++ -Isrc/decoder/plugins/libdecoder_plugins.a.p -Isrc/decoder/plugins -I../src/decoder/plugins -Isrc -I../src -I. -I.. -Isrc/lib/sacdiso -I../src/lib/sacdiso -I../src/lib/sacdiso/libdstdec -I../src/lib/sacdiso/libdstdec/binding -I../src/lib/sacdiso/libdstdec/decoder -Isrc/lib/dvdaiso -I../src/lib/dvdaiso -I../src/lib/dvdaiso/libmlpdec -I../src/lib/dvdaiso/libmlpdec/libavutil -I../src/lib/dvdaiso/libudf -I/usr/include/spa-0.2 -I/usr/include/glib-2.0 -I/usr/lib/glib-2.0/include -I/usr/include/sysprof-6 -I/usr/include/opus -I/usr/include/pipewire-0.3 -I/usr/include/dbus-1.0 -I/usr/lib/dbus-1.0/include -I/usr/include/libinstpatch-2 -I/usr/include/SDL2 -fdiagnostics-color=always -D_GLIBCXX_ASSERTIONS=1 -D_LIBCPP_ENABLE_ASSERTIONS=1 -D_FILE_OFFSET_BITS=64 -Wall -Winvalid-pch -Wextra -Wpedantic -std=c++2a -ffast-math -ftree-vectorize -Wcast-qual -Wdouble-promotion -Wmissing-declarations -Wshadow -Wunused -Wvla -Wwrite-strings -Wunreachable-code-aggressive -Wused-but-marked-unused -fno-threadsafe-statics -fmerge-all-constants -Wextra-semi -Wmismatched-tags -Woverloaded-virtual -Wsign-promo -Wno-non-virtual-dtor -Wcomma -Wheader-hygiene -Winconsistent-missing-destructor-override -Wsuggest-override -fvisibility=hidden -ffunction-sections -fdata-sections -D_GNU_SOURCE -march=native -O2 -pipe -fno-plt -fexceptions -Wp,-D_FORTIFY_SOURCE=3 -Wformat -Werror=format-security -fstack-clash-protection -fcf-protection -fno-omit-frame-pointer -mno-omit-leaf-frame-pointer -Wp,-D_GLIBCXX_ASSERTIONS -g -ffile-prefix-map=/tmp/makepkg/mpd-sacd/src=/usr/src/debug/mpd-sacd -flto=auto -fPIC -pthread -D_REENTRANT -D_DEFAULT_SOURCE -D_XOPEN_SOURCE=600 -MD -MQ src/decoder/plugins/libdecoder_plugins.a.p/FfmpegIo.cxx.o -MF src/decoder/plugins/libdecoder_plugins.a.p/FfmpegIo.cxx.o.d -o src/decoder/plugins/libdecoder_plugins.a.p/FfmpegIo.cxx.o -c ../src/decoder/plugins/FfmpegIo.cxx
../src/decoder/plugins/FfmpegIo.cxx:28:10: error: use of undeclared identifier 'AVERROR_EOF'
28 | return AVERROR_EOF;
| ^
1 error generated. -
#4396
jattila48
aktív tag
DrojDtroll
#4391
jattila48
aktív tag
válasz
 DrojDtroll
#4391
üzenetére
DrojDtroll
#4391
üzenetére
Amit a GetDesktopWindow visszaad, az csak egy window handle, nem struktúra pointer. Próbálkozz a
HWND kijelzo=GetDesktopWindow();
RECT rect;
GetWindowRect(kijelzo,&rect);kóddal.
-
#4390
 Tomi_78
aktív tag
DrojDtroll
#4389
Tomi_78
aktív tag
DrojDtroll
#4389
Tomi_78
aktív tag
válasz
DrojDtroll
#4389
üzenetére
Ezt láttam már, de sajnos nem működik: a WM_RESIZE ágra ír ki valami hibát.
De most próbálkoztam így is:
HWND kijelzo=GetDesktopWindow();
ablakszel=kijelzo.right;
ablakmag=kijelzo.bottom;De ez sem jó: error: request for member 'right' in 'kijelzo', which is of pointer type 'HWND {aka HWND__*}' (maybe you meant to use '->' ?)|
-
-
Delete esetén ha a statikus (az első példában Base, a másodikban void) és a dinamikus (Derived) típus különbözik, akkor a dinamikus típusnak a statikus leszármazottjának kell lennie ÉS a statikus típus destruktorának virtuálisnak kell lennie, máskülönben undefined behaviour.
Szóval mindkét példa definiáltlan működés, saccra a gyakorlatban annyi történik, hogy az első példában meghívódik a Base destruktora (így a Derived saját dolgai felszabadítatlanul maradnak), a második példában meg csak egy free() a pointerrel.
-

MageRG
addikt
Tisztelt Hölgyek és Urak!
class Base{/* ..., nincs virtual destructor */};class Derived: public Base{/* ... */};int main(){Base *basePtr = new Derived();delete basePtr; /* (1) memory leak, de miért? */void *ptr = (void*) new Derived(); /* tudom, borzalom */delete ptr; /* (2) itt mi történik? */
return 0;}
Szóval a fenti agymenés lenne a kérdés:
(1)-nél gondolom azt hiszi a fordító, hogy ez egy Base objektum, ezért a származtatott osztály részeit már nem szabadítja fel.
Ez mindig így van? Van olyan fordító, ami "tudja", hogy az adott pointer ténylegesen mekkora területre mutat?
(2)-nél mi történik? Ha jól értem itt már semmilyen takarítás nincs (egy destruktor sem hívódik meg).
Elnézést ha kicsit csekély értelmű kérdés... -
Tomi_78
aktív tag
válasz
 dabadab
#4305
üzenetére
dabadab
#4305
üzenetére
Pedig tényleg nem használok semmi extrát a programozáshoz. De inkább be is szúrom kis programomat (175 sor talán még belefér a fórumba; ha nem, hát szóljatok érte, hogy az ilyet mellőzzem legközelebb), hogy lássátok. Persze így azt is látni, hogy sokminden még nem világos benne nekem sem; ezeket megjegyzésbe írtam.
#if defined(UNICODE) && !defined(_UNICODE)#define _UNICODE#elif defined(_UNICODE) && !defined(UNICODE)#define UNICODE#endif#include <tchar.h>#include <windows.h>/* Declare Windows procedure */LRESULT CALLBACK WindowProcedure (HWND, UINT, WPARAM, LPARAM);/* Make the class name into a global variable */TCHAR szClassName[ ] = _T("CodeBlocksWindowsApp");int xhely=50,yhely=5,xseb=8,yseb=8;UINT idozito;RECT ablak;const unsigned int idozito1=1;int WINAPI WinMain (HINSTANCE hThisInstance,HINSTANCE hPrevInstance,LPSTR lpszArgument,int nCmdShow){HWND hwnd; /* This is the handle for our window */MSG messages; /* Here messages to the application are saved */WNDCLASSEX wincl; /* Data structure for the windowclass *//* The Window structure */wincl.hInstance = hThisInstance;wincl.lpszClassName = szClassName;wincl.lpfnWndProc = WindowProcedure; /* This function is called by windows */wincl.style = CS_DBLCLKS; /* Catch double-clicks */wincl.cbSize = sizeof (WNDCLASSEX);/* Use default icon and mouse-pointer */wincl.hIcon = LoadIcon (NULL, IDI_APPLICATION);wincl.hIconSm = LoadIcon (NULL, IDI_APPLICATION);wincl.hCursor = LoadCursor (NULL, IDC_ARROW);wincl.lpszMenuName = NULL; /* No menu */wincl.cbClsExtra = 0; /* No extra bytes after the window class */wincl.cbWndExtra = 0; /* structure or the window instance *//* Use Windows's default colour as the background of the window */wincl.hbrBackground = (HBRUSH) COLOR_BACKGROUND;/* Register the window class, and if it fails quit the program */if (!RegisterClassEx (&wincl))return 0;/* The class is registered, let's create the program*/hwnd = CreateWindowEx (0, /* Extended possibilites for variation */szClassName, /* Classname */_T("Jatekom"), /* Title Text */WS_OVERLAPPEDWINDOW, /* default window */CW_USEDEFAULT, /* Windows decides the position */CW_USEDEFAULT, /* where the window ends up on the screen */544, /* The programs width */375, /* and height in pixels */HWND_DESKTOP, /* The window is a child-window to desktop */NULL, /* No menu */hThisInstance, /* Program Instance handler */NULL /* No Window Creation data */);/* Make the window visible on the screen */ShowWindow (hwnd, nCmdShow);/* Run the message loop. It will run until GetMessage() returns 0 */while (GetMessage (&messages, NULL, 0, 0)){/* Translate virtual-key messages into character messages */TranslateMessage(&messages);/* Send message to WindowProcedure */DispatchMessage(&messages);}/* The program return-value is 0 - The value that PostQuitMessage() gave */return messages.wParam;}/* This function is called by the Windows function DispatchMessage() */LRESULT CALLBACK WindowProcedure (HWND hwnd, UINT message, WPARAM wParam, LPARAM lParam){HDC hdc; //handle to device context a jelentése, de mire is jó?hdc = GetDC(hwnd);static HBITMAP kep;BITMAP bitmapkep;HDC hdcMem;HGDIOBJ oldBitmap;PAINTSTRUCT ps; //előző helyről törléshezswitch (message) /* handle the messages */{case WM_CREATE:kep = (HBITMAP) LoadImageW(NULL, L".\\kek_labda.bmp",IMAGE_BITMAP, 0, 0, LR_LOADFROMFILE);if (kep == NULL) {MessageBoxW(hwnd, L"Nem tudtam betolteni a kepet!", L"Error", MB_OK);}/*else {System::Drawing::Bitmap::kep.MakeTransparent();};*/idozito = SetTimer(hwnd,idozito1,100,(TIMERPROC)NULL);break;case WM_KEYDOWN:switch (wParam) {case VK_LEFT: xhely-=4; InvalidateRect(hwnd, NULL, true); break;case VK_RIGHT: xhely+=4; InvalidateRect(hwnd, NULL, true); break;case VK_UP: yhely-=4; InvalidateRect(hwnd, NULL, true); break;case VK_DOWN: yhely+=4; InvalidateRect(hwnd, NULL, true); break;}break;case WM_PAINT:hdcMem = CreateCompatibleDC(hdc); //ez mire jó?oldBitmap = SelectObject(hdcMem, kep); //és ez?GetObject(kep, sizeof(bitmapkep), &bitmapkep); //beolvassa a kep változóba a bitmap adatait(?)BeginPaint(hwnd, &ps); //előző helyről törléshezBitBlt(hdc, xhely, yhely, bitmapkep.bmWidth, bitmapkep.bmHeight,hdcMem, 0, 0, SRCCOPY); //ez rendben van: kirajzolás/*BLENDFUNCTION pixelblend = { AC_SRC_OVER, 0, 255, AC_SRC_ALPHA };AlphaBlend(hdc, 0, 0, bitmapkep.bmWidth, bitmapkep.bmHeight, hdcMem, 0, 0, bitmapkep.bmWidth, bitmapkep.bmHeight, pixelblend);*/EndPaint(hwnd, &ps); //előző helyről törléshezSelectObject(hdcMem, oldBitmap); //ez is mit csinál?DeleteDC(hdcMem); //???TextOut(hdc, 10, 10, TEXT("Szia!"),5); //ez is oké: kiírok egy szöveget.GetWindowRect(hwnd, &ablak);char szoveg[30];itoa(ablak.right,szoveg,10);TextOut(hdc, 50, 10, szoveg,5);itoa(xhely+8+bitmapkep.bmWidth,szoveg,10);TextOut(hdc, 100, 10, szoveg,5);Rectangle(hdc, 50, 50, 200, 100); //meg ez is: téglalap rajzolásaReleaseDC(hwnd, hdc); //ez minek kell?break;case WM_TIMER:switch (wParam){case idozito1:GetWindowRect(hwnd, &ablak);xhely = xhely + xseb;yhely = yhely + yseb;if (xhely+xseb+bitmapkep.bmWidth>ablak.right-ablak.left-bitmapkep.bmWidth) {xseb = -1*abs(xseb);}elseif (xhely<0) {xseb = abs(xseb);};if (yhely+yseb+bitmapkep.bmHeight>ablak.bottom) {yseb = -1*abs(yseb);}elseif (yhely<0) {yseb = abs(yseb);};InvalidateRect(hwnd, NULL, true);break;}break;case WM_DESTROY:KillTimer(hwnd,idozito1);PostQuitMessage (0); /* send a WM_QUIT to the message queue */break;default: /* for messages that we don't deal with */return DefWindowProc (hwnd, message, wParam, lParam);}return 0;} -

mgoogyi
senior tag
válasz
 Tomi_78
#4256
üzenetére
Tomi_78
#4256
üzenetére
A pointernek és a LoadFromFile-nak nincs köze egymáshoz.
A pointer csak egy logikai memóriacím.A programod változói mind a memóriában vannak valahol.
Az, hogy valami hol van, azt elrakhatod egy pointerbe, mint pl. egy int * p;
Ebbe a p-be berakhatsz egy memóriacímet és utána azt tudod, hogy azon a memóriacímen - ami a p-ben van - van egy int értéked, azaz 4 byte-od egymás után.Az egyszerűség kedvéért 0-tól 1000-ig legyenek a lehetséges memóriacímek.
Amikor leírok egy olyat, hogy new int, akkor a programod a memóriából kér magának 4 byte-ot egymás után, ahol majd az integer-ed tartalma lesz és ebből a 4 byteből az elsőnek a címét visszaadja. (A másik 3 byte közvetlen utána van.)
Ezért tudod megtenni azt, hogy aint * p = new int;esetén a baloldalt ott van a p, ami értéket kap. Mégpedig ennek az 1. byte-nak a memóriában lévő sorszámát.Itt egy példakód megdebuggolva:
A programom a (hexadecimális) 12461a8-as byte-tól kezdve kapott összesen 4 byte-ot.
És erre a 4 byte-ra a 3-nak megfelelő adat lett beírva.Ez így világos?
Olvasd el sokszor, ha nem érted, elég fontos, hogy ez meglegyen. -
Tomi_78
aktív tag
-
mgoogyi
senior tag
válasz
Tomi_78
#4252
üzenetére
AlakokKepe->LoadFromFile("alak\\alak_all.bmp");
kepei[0] = AlakokKepe;
kepei[2] = AlakokKepe;
AlakokKepe->LoadFromFile("alak\\alak_lep1.bmp");
kepei[1] = AlakokKepe;
AlakokKepe->LoadFromFile("alak\\alak_lep2.bmp");
kepei[3] = AlakokKepe;Anélkül, hogy érteném a teljes kódod, ez a rész biztosan rossz.
Az AlakokKepe egyetlen objektum pointere (memóriacíme).A memóriacím egy szám, ami eldől akkor, amikor a new neked helyet foglal a memóriában:
Graphics::TBitmap *AlakokKepe = new Graphics::TBitmap;
És innentől kezdve ez az érték nem változik.A kepei nevű ugyanilyen pointereket tároló tömbbe berakod ugyanazt a számértéket(pointert/memóriacímet) minden indexre.
Teljesen mindegy, hogy mit csinálsz közben a LoadFromFile függvénnyel.Az AlakokKepe változóra nincs szükséged. Első körben csináld azt, hogy minden alakok elemre ([0], [1], [2], stb.) a benne lévő kepe adattagot külön külön létrehozod
= new Graphics::TBitmap;hívással és ezeken az alakok[ 0/1/2/.. ] . kepe objektumokon hívod meg a LoadFromFile-t.Azt is megeteheted, hogy nem pointert használsz:
Graphics::TBitmap* kepe;->Graphics::TBitmap kepe;
és akkor nem kell new sem. -

leviske
veterán
Sziasztok!
Most felfogok tenni megint egy nagyon amatőr kérdést "good programming practice" témában.
Van egy programom, ami beolvas több száz, sokszor több ezer képet, hogy műveleteket végezhessen rajta. Főbb osztályokat tekintve van egy Feldolgozó, egy I/O és egy UI. Mindháromnak hozzá kell férnie ahhoz a vektor<mátrix> változóhoz, ami a képeket tartalmazza. Az I/O ugye betölti az adatokat, a UI megjeleníti az aktuális állapotot, a feldolgozó osztály meg elvégzi a műveleteket.
A kérdésem a következő:
Az a legjobb megoldás, ha a feldolgozó osztály tartalmazza ezt a vektort és a másik kettőnek a feldolgozó osztály egy objektívének pointerét adogatom oda VAGY az a szebb, ha létrehozok a három osztály számára egy base class-t ami static változó formájában tartalmazza ezt a vektort?Egyelőre az első verziót használom.
Előre is köszi a nem megalázó választ.

-

G.A.
aktív tag
Megvan az erdő!
A for() ciklusban a feltétel a hibás:
for(uint32 i = 0, txbptr = 3; i < sizeToTransfer; i++, txbptr += 4)
{
local_rx_buffer[i] = temp_rx_buffer[txbptr];
}Javítva:
for(uint32 i = 0, txbptr = 3; txbptr < sizeToTransfer; i++, txbptr += 4)
{
local_rx_buffer[i] = temp_rx_buffer[txbptr];
}Az i helyett a txbptr-t (tx buffer pointer) kellett tesztelni.
-

Z_A_P
addikt
1
A screenshotban nem
for (Egitest* b : EgitestLista) {
van, hanem
Egitest b - csilag nelkul.2
typeid(Bolygo) == typeid(b)
Ilyet nem hasznalunk, helyette dyamic_cast<>, ami NULL-t ad vissza ha nem sikerult a cast. Termeszetesen pointert/referenciat hasznalunk.3
Az egesz kod buzlik, ha a listadban Egitest van, es azon kell ilyeneket futtatni, akkor inkabb az Egitest classban kellene egy virtualis GetKeringesiTavolsag().+1
Borzaszto stilus a magyar/angol keveres "GetKeringesiTavolsag"
Hasznalj 100%-ban CSAK angol neveket, minding mindenre.
Ezzel csak nyerhetsz, meghozza sokat. -
mgoogyi
senior tag
A screenshotodban nem pointered van, hanem normál objektumod.
Gondolom a listáddal is ugyanaz a helyzet.Ezzel az a baj, ha csinász egy ilyet, hogy:
Bolygo b;
Egitest e;
e = b; // az EgitestHozzaad-nál gyakorlatilag ezt csinálodEzesetben az "e" egy ledarált Egitest méretű változó lesz, amit a "b" égitestből örökölt részei adnak.
Ez az egész castolás téma akkor nyerhet értelmet, ha pointert vagy ref-et castolsz.
Látom c# háttered van.
C++-ban a normál értékadás by value megy összetett típusokra is, amit pl. az EgitestHozzaad függvény bemenő paraméternél történik. (Kb. mint a struct c#-ban)
Ez azt jelenti, hogy mindig egy másolat változóba megy az adat, amibe vagy copy konstruktorral vagy = operatorral kerül be az adat.A a = b; // copy ctor
a = b; // = operatorHa ki akarod használni a polimorfizmust, akkor vagy referenciákkal vagy pointerekkel kell dolgoznod.
A * a / A & aMiért akarsz visszacastolni bolygóra? Nem azért tartod közös kollekcióban az objektumokat, hogy mind ugyanúgy kezelhesd a közös interfaceükön keresztül?
-
Erre van a typeid:
if ( typeid(*b) == typeid(bolygo) ) {
// ....
}C++-ban egyébként szerintem nem jó ötlet C-s pointereket alkalmazni: a legtöbb esetben egyáltalán nem kell pointer (főleg mióta van move semantics), a maradék nagy részében referenciákat lehet használni, ami meg ezek után is megmarad, ott meg a C++-os smart pointereket.
-
mgoogyi
senior tag
válasz
 Teasüti
#4155
üzenetére
Teasüti
#4155
üzenetére
Amit lehet a stacken jobb tartani(gyorsabb, nem kell delete), a nagy méretű adatot meg heap-en(van neki hely gazdagon).
A new+delete párra meg vannak osztályok, amikbe becsomagolva megkapod az eltakarítást.
std::vector a dinamikus tömbhöz, std::unique_ptr, std::auto_ptr egyéb mutatóhoz.
Ezek az osztályok a delete-et úgy oldják meg, hogy a destruktorukban meghívódik az általuk tárolt pointerre a delete.
És ezeket a pointer "wrapper"-eket pedig stack-en tartod valahol és amikor elhagyod a scope-ot, szépen lefut a destruktor és magától felszabadul a memória.
Ez azért nagyon fontos, mert minden programozó hibázik és nem igazán függ a hibázás gyakorisága attól, hogy mióta űzöd a mesterséget. Ezzel védjük magunkat a memory leak-től.A vector persze elsődlegesen nem pointer wrapper, arra találták ki, hogy nagyon kényelmesen legyen egy bármikor átméretezhető tömböd. A belsejében egy dinamikus tömb van.
-
jattila48
aktív tag
válasz
Teasüti
#4153
üzenetére
"Tehát ami nekem átjött ebből a beszélgetésből, hogy ha new operátorral hozok létre tömböt (foglalok le dinamikus memóriát), akkor az egy ún. heap-re kerül,..."
Ez igaz.
"...míg ha new nélkül, akkor a stack-be."
Ez nem feltétlenül igaz, mert a globális adatterületen is deklarálhatsz tömböt.
Egyéb gyakorlati jelentősége pedig az, amit eddig leírtam. Röviden összefoglalva:
- A tömb név nem változó, nem adhatsz neki értéket, és nem képezheted a címét.
-A pointer változó, ami memória címet tartalmaz (pl. a heapen lefoglalt memória címét, de lehet más pl. "hagyományosan" deklarált tömb címe is). A pointer értéke megváltoztatható, és a címe is képezhető.
-Tömböt csak konstans méretűt deklarálhatsz (kivéve C99), míg new-val változó méretű memóriát foglalhatsz.
-Tömböt nem szabad felszabadítani, new-val létrehozott memóriát pedig fel kell szabadítani.
Kb. ennyi ami gyakorlatban különbség a két fogalom között, és amiről minden programozónak tudnia kell.
Még egy "apróság": C++ -ban tömb név, mint konstans pointer lehet template argumentum (mivel fordítási időben kiértékelhető), pointer viszont nem (mivel csak futási időben értékelhető ki). -
jattila48
aktív tag
válasz
jattila48
#4149
üzenetére
Elnézést, a const int valóban olyan "változó", aminek nem lehet értéket adni. A static const int-re gondoltam, erre már áll az amit eddig írtam. Template argumentumként és tömb méretként is static const int használható, const int nem. Amiket a tömb vs. pointer témában írtam, azt fenntartom.
-
jattila48
aktív tag
válasz
 mgoogyi
#4148
üzenetére
mgoogyi
#4148
üzenetére
Ahogy írtam, a const int kezelése esetleg lehet fordító és helyzet függő, pl. a példa programodban képezhető a címe (bár sok értelme nincs, mivel értéket nem adhatsz neki). De amiket példákat írtam (template argumentum, tömb méret), valószínűleg az értékét mint konstanst fogja használni, hiszen fordításkor még semmilyen memória címet nem tulajdoníthat neki. Értékadásnál esetleg lehet más a helyzet, hiszen az értékadás futás időben történik, és ott hivatkozhat a konstansra a memória címén keresztül (sok értelme ennek sem lenne, esetleg gyorsabb lehet az újra fordítás, ha megváltoztatod a forráskódban a konstans értékét. Ez csak tipp).
A #define egy más kérdés, az pusztán szövegfeldolgozás. Ott tényleg semmi különbség nem lehet ahhoz képest, mintha a konstans literált írtad volna minden helyen.
Kicsit elkanyarodtunk a témától. A const int-et és enum-ot csak a tömb mint konstans cím hasonlósága miatt hoztam fel. Eredetileg arra válaszoltam, hogy a tömb nem pointer, még ha sokszor hasonlóan is kezeljük. A különbség gyakorlatban is fontos vonatkozására is felhívtam a figyelmet, amit minden programozónak tudni kell. A technikai különbségek (mi hogy fordul, mennyire hatékony) valóban nem életbe vágók, de érdemes tudni róluk. -
jattila48
aktív tag
válasz
mgoogyi
#4142
üzenetére
"Pont nem érdekel, nem látom a gyakorlati jelentőségét"
Pl. az lehet a gyakorlati jelentősége, hogy innen már világos, hogy a C/C++ -ban miért nem lehet dinamikus méretű tömböt deklarálni (bár mint most megtudtam, újabb C szabvány szerint lehet):
int n=10;
int a[n]; //hiba. tomb meret csak konstans lehetEzt kezdők általában nem szokták érteni.
Ha az új C szabvány ezt mégis megengedi, akkor a tömb címe szükségképpen eltárolódik a memóriában (mintha változó lenne), de a fordító nem engedi meg a megváltoztatását és a címének képzését (gondolom így van, de nem ismerem a C-nek ezt a lehetőségét).
Másik gyakorlatban fontos vonatkozása a dolognak, hogy a dinamikusan allokált memóriát fel kell szabadítanod (ha nem akarsz memory leaket), a tömböt pedig nem kell (sőt nem szabad!) felszabadítani (hiszen nem a heapen lett lefoglalva). Tekintsük a következő kódrészletet:int tomb[10];
int *dinamik_tomb=new int[10];
int *pointer;
pointer=tomb;
delete[] pointer; //hiba! nem szabad felszabaditani a tomb-ot
pointer=dinamik_tomb;
delete[] pointer; //OK, fel kell szabaditani a dinamik_tombotAmint látod, a pointer felszabadításánál észnél kell lenni, tudni kell, hogy tömb, vagy dinamikusan allokált memória terület címét tartalmazza-e. Ebből bizony sok hiba adódik (jó párat láttam már), és megy a fejvakarás, hogy miért száll el a program, hiszen a "tomb valójában pointer". Hát nem!
-
jattila48
aktív tag
válasz
mgoogyi
#4142
üzenetére
Nevezheted tömbnek a dinamikusan allokált memória területet, de az nem tömb abban az értelemben (konstans mérettel deklarált tömb), ahogy írtam. A különbséget nem írom le még egyszer.
"Pusztán ránézve a kódra én "a"-ra és "b"-re is változóként(előbbire pointer típusú változóként, utóbbira tömb típusúként) fogok hivatkozni."
b nem változó, hiszen nem változhat az értéke, mint ahogy egy változónál (a nevében is benne van) ez megtörténhet. Ennyi erővel a 3-at is nevezheted változónak, holott az sincs sehol a memóriában eltárolva. A tömb esetében kicsit azért kevésbé nyilvánvaló, hogy nem változó, hanem konstans, mert nevet adsz neki. A 3 leírva konstans literál, ezért nyilvánvalóbb hogy ő nem változó. Azonban írhatsz olyat, hogyconst int harom=3;
enum akarmi={nulla,egy,ketto};
ahol a névvel illetett számok szintén konstansok, nem lehet sem megváltoztatni az értéküket, sem a címüket képezni. A tömb ugyanilyen értelemben konstans. Ennek a látszat ellenére igenis van gyakorlati jelentősége, és illik is tudni róla. Csak erre szerettem volna felhívni a figyelmet -
mgoogyi
senior tag
válasz
jattila48
#4141
üzenetére
"Nem, nem lehet a heapen tömb. Az nem tömb lesz, hanem dinamikusan foglalt memória"
Lehet én vagyok a retardált, de nekem a tömb = összefüggő memóriaterület egy adott típusra.
Szóval nekem van olyan, hogy statikusan allokált array és dinamikusan allokált array.https://msdn.microsoft.com/hu-hu/library/kewsb8ba.aspx?f=255&MSPPError=-2147217396
Az msdn meg le mer írni ilyet, hogy "When allocating an array using the new operator"?
"Ahogy írtam, a t NEM változó, hanem konstans és ez a lényeg."
int * a = new int[10];
int b[10];Pusztán ránézve a kódra én "a"-ra és "b"-re is változóként(előbbire pointer típusú változóként, utóbbira tömb típusúként) fogok hivatkozni. Utóbbi konstans és nincs mögötte valódi változó? Pont nem érdekel, nem látom a gyakorlati jelentőségét. Lehet ez rossz berögzültség, soha egyszer nem volt még hátrányom belőle a munkám során.
-
jattila48
aktív tag
válasz
mgoogyi
#4140
üzenetére
Attól tartok, teljesen félreérted.
"...én a t-re gondolok, mint változóra"
Ahogy írtam, a t NEM változó, hanem konstans és ez a lényeg. Ha azt írod, hogyint i=j+3;
akkor az i és j változók, amik a memóriában futás időben keletkeznek, a 3 viszont konstans, ami sehol nem tárolódik el e memóriában, hanem a generált kódban jelenik meg mint konstans adat. Hasonlóan a tömb esetén is, sehol nem tárolódik a tömb (mint cím) értéke, hiszen csak egy konstans.
"Az a konstans cím, amiről beszélsz, az maga a t változó tartalma"
Nincs semmiféle t változó.
"Annyit tud egy pointerhez képest, hogy a típusából kifolyólag tud arról, hogy hány elemű"
Nem, nem tud róla hogy hány elemű, hiszen a konstansban ez nincs kódolva. C-ben egyébként sincs tömb index ellenőrzés (futás közben), és a fordító sem különböztet meg ez alapján típusokat (template-tel megoldható, ha a tömb méret template argumentum).
"nem pointer, de mégis pontosan ugyanúgy viselkedik"
Nem pontosan úgy viselkedik, ahogy előző hozzászólásomban írtam, nem adható neki érték, és nem képezhető a címe (szemben a pointerrel).
"Másrészt nem csak a stacken lehet a tömbünk, hanem a heapen is"
Nem, nem lehet a heapen tömb. Az nem tömb lesz, hanem dinamikusan foglalt memória, aminek a címe bekerül egy változóba (vagyis pointer), bár valóban kezelheted tömb szintaxissal, ha az elemeit akarod elérni. Tömböt deklarálni a stack-en lehet, vagy a globális adatterületen (amit a betöltő foglal le a memóriában).
"Egyébként aki most ismerkedik a C++-szal, annak lehet inkább riasztó, mint segítség."
A C++ nem egy egyszerű nyelv, és szerintem jó az elején tisztázni bizonyos dolgokat (pl. ezt), hogy később ne rögzüljön hibásan, mint ahogy az esetedben is. -
mgoogyi
senior tag
válasz
jattila48
#4139
üzenetére
Ja értem, hogy mire gondolsz, én gyakorlatiasabban közelítem a kérdést.
int t[10] esetén a t a gyakorlatban úgy viselkedik, mint egy konstans pointer. Amikor a tömbről beszélek a kódban, akkor én a t-re gondolok, mint változóra, márpedig ez pontosan a 0. elem címe.
Az a konstans cím, amiről beszélsz, az maga a t változó tartalma. Annyit tud egy pointerhez képest, hogy a típusából kifolyólag tud arról, hogy hány elemű, azaz nem int * hanem int[10] típusú. De ettől még értékként a 0. elem címe van benne. És igen, valóban nem pointer, de mégis pontosan ugyanúgy viselkedik.Másrészt nem csak a stacken lehet a tömbünk, hanem a heapen is new-val foglalva, akkor meg direktbe egy int *-ba toljuk be a 0. elem címét és azzal a pointerrel is pont azt fogod csinálni, mint a stack-en foglalt t-vel.
Az assemblys részt elolvasom megint, amit írtál, abban nem vagyok otthon. Egyetemen meglehetősen félvállról vettem, így ennyi is maradt meg belőle. Egyébként aki most ismerkedik a C++-szal, annak lehet inkább riasztó, mint segítség.
-
jattila48
aktív tag
válasz
Teasüti
#4135
üzenetére
"De hisz a tömb is egy pointer.
 "
"Nem, nem az! C-ben valóban hasonlóan kezelheted a tömböt és a pointert, de ettől még a tömb nem pointer. Sok félreértés és hiba forrása ez, ugyanakkor nagyon kényelmes is tud lenni. A pointer egy változó, ami történetesen memória címet tartalmaz. Mint minden változónak, neki is van címe, és megváltoztathatod az értékét (balérték). Ezzel szemben a tömb egy konstans memória cím (ahol a tönb kezdődik). Ezt a konstanst a fordító/linker/betöltő számolja ki, amit te nem változtathatsz meg, és a címét sem képezheted (hiszen nem is létezik a memóriában).
int tomb[10];
tomb=new int[10]; //Hiba! tombnek nem lehet erteket adni, hiszen az konstans
int **ppi=&tomb; //Hiba! tombnek nem kepezheto a cime, mert az nem valtozo
int *pi=new int[10]; //OK
int **ppi=π //OK valtozonak kepezheto a cime
pi=new int[10]; //OK valtozo erteke megvaltoztathatoAmikor tömb elemre hivatkozol (kiindexeled), a fordító ehhez a konstans címhez adja hozzá az indexet, és erről a címről veszi elő a tömb elemet (intelnél egyetlen utasítás pl. : mov eax, DWORD PTR[ebx+0x1000]; indirekt indexelt címzési mód, ahol 0x1000-nél kezdődik a tömb, ebx-ben pedig az elérni kívánt tömbelem indexe található). Tehát itt a kódba a fordító beleírja a tömb konstans kezdőcímét.
Ha new-val foglalsz helyet, akkor a lefoglalt memória kezdőcímét egy változó kapja értékül, ez a változó a pointer. Ha ezen a memória területen tömb szintaxissal hivatkozol egy elemre, akkor a fordítónak (intel esetén) ehhez legalább két utasításra lesz szüksége. Az elsővel regiszterbe tölti a változó (pointer) címéről a változó értékét (ez maga a new-val foglalt memória kezdőcíme lesz). Ha pl. a pointered címe eax-ben van, akkor mov eax,DWORD PTR[eax] utasítás ezt megoldja. Majd az elem elérése mov eax,DWORD PTR[eax+esi] utasítással történik, ahol az esi tartalmazza azi indexet. Látható, hogy ez jóval lassabb művelet, mint az "igazi" tömb kiindexelése. -
mgoogyi
senior tag
válasz
Teasüti
#4135
üzenetére
Igen, így van, a tömböt is pointerként kezeled. Gyakorlatilag a 0. elemére mutató pointer van a változóban értékként.
A kérdésedre a válasz igen, mindig más memóriaterületen kapsz egy új összefüggő memóriaterületet az új tömbödnek. A pointert írasd ki és látod, hogy mindig más értéket kap. Ez a logikai címe a kezdeti memóriacellának (a programod csak a memória egy számára logikailag elkülönített részét látja).
A régi tömb ugyanúgy meglesz az előző ciklusodból, csak a címe már nem lesz meg és anélkül nehéz felszabadítani.
Csináld ciklus belsejében simán, amit írtál. Ha jó sok kört fut a ciklusod, megzabálja a géped memóriáját.
Azért figyelj arra, hogy ne zabálja meg az összeset, kevés elemű int tömböt foglalj le 1000-szer ciklusban, kísérletnek elég. -

Teasüti
nagyúr
válasz
mgoogyi
#4134
üzenetére
A new (new []) esetében egy pointer-t kapsz vissza
De hisz a tömb is egy pointer.Ha ezeket nem használod és elfelejteted a delete-et, akkor keresheted, hogy miért növekszik a progid memóriahasználata (memóriaszivárgás).
Mi van akkor, ha egy függvény minden lefutáskor létrehoz egy tömböt és elfelejtem törölni miután lefutott, majd újra meghívom a függvényt? Más memóriaterületen fogja megint létrehozni ugyanazt a tömböt?(#4133) dabadab
Áhhá!! Értem.
Ezt mintha olvastam is volna, hogy adott esetben egy szinttel feljebb szokták törölni, mondjuk az adott függvényen kívül. -
mgoogyi
senior tag
válasz
Teasüti
#4132
üzenetére
A new meg nem new között az a különbség, hogy a new-val a heap-en foglalsz memóriát, new nélkül meg a stack-en. (itt nem erre a nem szabványos dologra gondolok:
int p [I]= {};)
Ez utóbbi elég limitált tud lenni, ha majd egyszer írsz rekurzív(önmagát hívó) függvényt, belefuthatsz.
Ezt hívják stackoverflow-nak. Olvass utána, hogy mi az a heap és mi az a stack.
Egyébként paraméterezett méretű tömböt new nélkül nehéz lértehozni.A new (new []) esetében egy pointer-t kapsz vissza és a te feladatod ezt eltakarítani delete-tel ( delete []).
Azért, hogy ezt ne felejtsd el, javasolt olyan osztályokat használni, amik megteszik ezt helyetted.
A vector meghívja helyetted a new[]-t és a delete[]-t, menet közben át is méretezi a benne lévő array-t.
Kényelmessé és biztonságossá teszi a tömbkezelést.
A unique_ptr pedig általánosságban jó arra, hogy egy objektum felszabadításával ne kelljen foglalkozni.Ha ezeket nem használod és elfelejteted a delete-et, akkor keresheted, hogy miért növekszik a progid memóriahasználata (memóriaszivárgás).
-
válasz
 Headless
#4121
üzenetére
Headless
#4121
üzenetére
"hogyan tudom kiolvasni, hogy hány paraméterrel rendelkezik?"
Sehogy. Alapvetően két dolgot tudsz csinálni:
1. valahogy átadod a pointertömb mellé azt is, hogy hány eleme van
2. (és ez a javasolt) hagyod a C-s tömbökét és C++-ban C++-ban programozol, ami jelen esetben azt jelenti, hogy az STL konténerei közül használsz valamit, pl. vectort. -

Headless
őstag
Sziasztok!
Viszonylag új vagyok a c++ programozásban és biztos, hogy nem a helyes úton járok annak megtanulásában/értésében. De most ezt dobta a gép, van egy struktúrám amibe pointerek és dupla pointerek vannak. azt szeretném kérdezni, hogy hogy tudnám megtudni a dupla pointerek nagyságát, hogy egy for ciklussal végig mehessek rajtuk?
typedef struct {
...
API_AddParType **params;
...
} API_ElementMemo
typedef struct {
...
char name[API_NameLen];
....
} API_AddParType;tehát ami most megy
memo.params[0]->nametehát a 0. paraméter nevét kiadja. hogyan tudom kiolvasni, hogy hány paraméterrel rendelkezik?
-
jattila48
aktív tag
válasz
 dobragab
#4087
üzenetére
dobragab
#4087
üzenetére
Köszi szépen a válaszodat. Először is engedd meg, hogy egy hibát javítsak:
static RET fptr_handler(ARGS... args)
{
tl_function(std::forward<ARGS>(args)...);
}helyesen:
static RET fptr_handler(ARGS... args)
{
return tl_function(std::forward<ARGS>(args)...);
}Egyébként szép megoldás a problémára.
Lényegében hasonló, mint amit a szimulációban írtam. Ott globálisan hoztam létre az objektumokat, ezek tfv.-eit pedig free wrapper fv.-eken keresztül hívtam meg (amik a globális objektumokhoz hozzáférnek), és a free fv.-ekre mutató fv. pointert tudom aztán használni callback fv. pointerként.
Lényegében a te megoldásod is hasonló, csak nem globális, hanem (thread_local) static std::function objecteket hozol létre (tl_function), amik tartalmazzák az objektum címét (ez a lambdában kapturált argumentum), és a megfelelő tfv. pointert. Majd ezt a tl_function std::function objectet meghívó fptr_handler statikus wrapper tfv.-nek a címét (mint közönséges pattintott C fv. pointert) adod vissza. A trükk pedig az, hogy a to_fptr function template második argumentuma egy []{} dummy lambda, aminek a típusa mindíg (fordító által generált) egyedi típus, ezért a to_fptr_t class template minden egyes alkalomkor külön-külön példányosul (a dummy lambda aktuális típusával), minden egyes function object-re külön osztályt, és azzal külön fptr_handler fv.-t létrehozva. Szép megoldás, gratula! -
#4102
jattila48
aktív tag
PandaMonium
#4086
jattila48
aktív tag
válasz
 PandaMonium
#4086
üzenetére
PandaMonium
#4086
üzenetére
Szerintem meg azt sem érted, hogy pontosan miről is van szó. target-tel nem fv. pointert kapsz vissza, hanem annak az objektumnak a címét, amit az std::function-ban eltároltál (ha ez történetesen fv. pointer volt akkor azt, ha std::bind volt akkor azt). A target template argumentumában pontosan meg kell adni az std::function-ben eltárolt callable object típusát, különben NULL-t kapsz vissza ([link] . Lambdát ugyan lehet megfelelő fv. pointerré konvertálni, de csak akkor ha nem kapturál semmit (ez számomra érdektelen). Szóval előbb olvass, értelmezz és ne az észt oszd!
-
#4086
 PandaMonium
őstag
jattila48
#4083
PandaMonium
őstag
jattila48
#4083
PandaMonium
őstag
válasz
jattila48
#4083
üzenetére
Ha kinyitod a cppreference.com-ot akkor látod, hogy az std::function
T* target() noexcept;metódusával visszakapod a függvény pointert amit úgy hívsz meg ahogy akarsz. Ha nem észt osztani járnál ide (főleg miután te kérsz segítséget), hanem utána olvasnál a dolgoknak előrébb lennél. -
#4083
jattila48
aktív tag
PandaMonium
#4082
jattila48
aktív tag
válasz
PandaMonium
#4082
üzenetére
És szerinted ez az std::function egy 32/64 bites fv. pointer lesz, amit assemblyben call eax -szel meg tudok hívni? Mert szerintem nem, de erre válaszoltam EQMontoyanak is. API fv.-nek szeretném átadni, mint callback fv. pointert, aminek fogalma sincs az std::function mibenlétéről. Az egy objektum, amit a ctor.-a másol a stackre, ha argumentum-ként adod át. Mit kezdjen ezzel egy API fv?
-
jattila48
aktív tag
válasz
 EQMontoya
#4077
üzenetére
EQMontoya
#4077
üzenetére
Lambdát nem tudsz átadni callback fv. pointerként pl. egy CreateThread vagy StartServiceCtrlDispatcher api hívásnak. Ezek egyetlen pointert várnak, a lambda pedig egy C++ nyelvi konstrukció (a mélyben egy névtelen osztály konstruktorral,...), amit az api fv. nem fog tudni értelmezni.
-
jattila48
aktív tag
válasz
jattila48
#4073
üzenetére
Egy szimuláció a következő lehet:
class Akarmi{
public:
Akarmi(int x):a(x){}
int addto(int x){
return a+x;
}
private:
int a;
};
Akarmi *pa;
int closure_func(int x){
return pa->addto(x);
}
void main(int argc,char *argv[]){
pa=new Akarmi(5);
std::cout << closure_func(6);
}A fenti példában closure_func 5-öt ad hozzá az argumentumához. és nem tfv., címe pedig használható lenne callback fv. pointerként. A gond csak az, hogy ha szükségem lenne egy 11-et hozzáadó closure-re is, akkor létre kéne hozni egy globális Akarmi(11) objektumot is (pl. pa11 nevu pointerrel), és definiálnom kéne egy closure_func11-et, ami a pa11-gyel hívja az addto tfv.-t. Ez nem túl jó megoldás. Amikor előző hozzászólásomban azt írtam, hogy futás közben kódot generálnak, akkor arra gondoltam, hogy kb. ezt a konstrukciót hozzák létre. Amikor létrejön az Akarmi(5) objektum, annak címével (mint konstanssal, vagyis a generált kódban ezt a címet "bedrórozva" konstansként használják) legenerálják a closure_func kódot, és closure fv. pointerként pedig visszaadják a röptében generált kód kezdőcímét. Így talán világosabb mire is gondoltam.
Várom a hozzászólásokat! -
jattila48
aktív tag
C++ -ban nincs lehetőség closure definiálásra, az Embarcadero (Borland) azonban megoldotta ezt a __closure kulcsszó bevezetésével. Szerintetek hogy lehetne sima C++ -ban szimulálni a closure-t? A C++ keretein belül nyilván sehogy, erre kellet a __closure kiterjesztés. De vajon hogy oldják ezt meg a mélyben? Szerintem fordítás/linkelési időben ezt nem lehet, valószínűleg futás közben generálják le a closure végrehajtható kódját (legalábbis egy forwarding fv. kódját), és ezt futtatják. Ehhez azonban Windowsban VirtualProtect-tel futtathatóvá kell tenni azt a memóriaterületet, ahová a kód kerül. Mit szólnak ehhez a vírusirtók?
Ha esetleg valaki nem tudja mi a closure: egy objektum tagfüggvényére mutató fv. pointer. Nem azonos a C++ tfv. pointerével, mert az egy sima fv. pointer, ami történetesen az osztály tfv.-re mutat (fordítás idejű konstans), és csak az osztályból létrehozott objektumon keresztül lehet meghívni. A closure azonban az adott objektumot (a this pointert) "magába olvasztva" (mint konstans értéket) tartalmazza, és csak a this pointeren kívüli argumentumok az argumentumai. Ezáltal alkalmassá valik callback fv. pointerként való használatra (ez a lényeg). -
jattila48
aktív tag
A private tagokat nem csak a konstruktor, hanem az összes tagfüggvény eléri. A tagfüggvények elől nincs elzárva a private tag, csak a külső (nem tfv.) függvények elől. Sőt ugyanannak a típusnak másik példánya is hozzáfér a private/protected tagokhoz (pl. egy olyan tfv., ami argumentumban másik ugyanolyan típusú példányt (vagy pointert/referenciát) kap, szintén gond nélkül eléri az argumentumban kapott objektum private/protected tagjait).
-
jattila48
aktív tag
válasz
 choco01
#4060
üzenetére
choco01
#4060
üzenetére
Ahogy b.kov leírta, k a kölcsönzéseket tároló tömb, ami kolcsonzes * típusú (vagyis kolcsonzes tipusu strukturara mutató pointer). Ez azért pointer, (és nem tömb, de tömbként lesz használva), mert előre nem tudod, hogy hány darab kölcsönzést fog tartalmazni (ezt is fájlból olvasod be a db változóba), tömböt deklarálni pedig csak konstans mérettel lehet. Ha megvan hogy hány darab kölcsönzést tartalmaz a fájl, akkor ekkora méretű tömböt fogsz dinamikusan (new-val) lefoglalni, ami kolcsonzes * típusú pointert ad vissza. Talán az okozza a zavart, hogy nem érted miért kell pointer, ha egyszer tömbbe olvasol be. A C-ben (és C++-ban) pointereket lehet tömbszerű szintaxissal használni (ki lehet indexelni mint a tömb elemet), illetve a tömb neve (indexelés nélkül) a tömb kezdőcímét jelenti. A tömb indexelés tulajdonképpen nem más, mint a kezdőcímhez képest indexszel eltolt pointerre való dereferencia. Tehát tomb ugyanaz, mintha *(tomb+i) -t írnál (ez pedig ugyanaz mint *(i+tomb), ami ugyanaz mint i[tomb]; egy kis nyalánkság a C szintaxisból). Ahogy fent írtam, csak a dinamikus helyfoglalás miatt kell pointer, és nem tömb. Ha azt gondolnád, hogy ilyen módon a pointer és a tömb tulajdonképpen ugyanaz, akkor nem lenne egészen igazad, ugyanis a tömb név (mint a tömb kezdő címe) konstans pointer (fordítás idejű konstans), ezért nem lehet neki értéket adni, és nem lehet a címét képezni, ellentétben a pointer típusú változóval. Elég baj, hogy a C-ben a tömb és pointer fogalma így összemosható, ebből szoktak félreértések (és hibák) adódni. Ennyit a tömbökről.
Hogy miért private ez a tömb (pointer), az pedig azért, mert nem feltétlenül kellene a kölcsönzéseket tömbben tárolni (lehetne pl. lista), ezért az osztályod felhasználója nem kell (nem szabad) hogy tudjon az implementációról, számára elég a publikusan biztosított tagfüggvények ismerete, ami az implementációtól függetlenül mindíg ugyanúgy hívható (ez OOP alapelv).
"De most akkor azt is lehetne írni a feltöltéskor hogykolcsonzes[i].datum;"
Ebben a sorban nem csináltál semmit, egyszerűen a stackre helyezted akolcsonzes[i].datumértékét.
"hogyan tehetem a private tagokat elérhetővé más számára?"
Leginkább public tagfüggvények által, magát a private adatszerkezetet nem szokás (hiszen ezért private). Ha feltétlenül elérhetővé akarod tenni, akkor legyen public. Előfordulhat azonban, hogy bizonyos külső (free vagyis nem tfv.-ek) függények számára meg akarod engedni a private/protected adattagok elérését, akkor az osztályod ezeket a fv.-eket friend-ként deklarálja (komplett osztályt is lehet friend-ként deklarálni). A friend deklaráció nem esik a public, private, protected láthatóság hatálya alá, mindegy hová írod. Mindíg az az osztály fogadhat barátjának egy fv.-t (vagy másik osztályt), amelyik ezek számára meg akarja engedni a private tagjainak elérését. Nem fordítva, tehát egy külső fv. nem jelentkezhet be, hogy szeretné az adott osztály private tagjait elérni.
A struktúra és az osztály között összesen az a különbség, hogy a struktúra tagjai default public elérésűek, míg az osztályé default private. Vagyis ha nem írsz ki láthatóságot, akkor ez vonatkozik a tagokra. Más különbség nincs, ettől eltekintve teljesen ugyanúgy használhatók. Szokás szerint, ha csak adattagok vannak, akkor struktúrát használnak, ha tfv.-ek is vannak, akkor osztályt, de ez csak konvenció.u.i.: közben míg írtam a választ dabadab megelőzött, kb. ugyanazt válaszolta.
-

b.kov
senior tag
válasz
choco01
#4056
üzenetére
Ennek a pointernek a segítségével hozod létre az egyes kölcsönzőkhöz tartozó tömböket, amiknek az eleme "kolcsonzes" típusúak. Tehát ha pontosabbak akarunk lenni, akkor azt is lehet mondani, hogy a k pointered ennek a tömbnek a fejelemére mutat. A
k[i]pedig a fejelemtől i. távolságra lévő elemre.Ennek a pointernek pontosan azért kell privátnak lennie, mivel minden egyes "kolcsonzo" példány létrehozásával egy file-ból olvasod be a kölcsönzéseket. Ezek ugye statikus adatok, amiken később nem szeretnél vátloztatni. Tehát ne lehessen azt mondani, h pl. "mintaKolcsonzo" objektumon keresztül, a 3. kolcsonzés idejét megváltoztatod. Tehát:
kolcsonzo mintaKolcsonzo("inputFile_1");Ekkor beolvasod ugye a fájlból a statikus adatokat. Nem lenne jó, ha ezután tudnál ilyet csinálni:
mintaKolcsonzo.k[2]->datum = "Buddha szobor";Persze létezik igény fájlból beolvasott adatok utólagos módosítására (sőt), viszont ez akkor sem szép megoldás. Arra külön setter függvényeket szokás írni, csakúgy mint a mostani getter függvények.
Tehát az előző példában ha megengednénk a dátum módosítását, akkor így lenne mondjuk szép:
mintaKolcsonzo.modifyDate(2, "2018.02.03");
Ahol ez első paraméter a kölcsönzés száma, a második pedig az új kölcsönzési dátum. -
b.kov
senior tag
válasz
choco01
#4052
üzenetére
Nem rosszabb semmivel, azonban ekkor a stack-en jön létre az objektum, ahogy írták is korábban.
Amíg nem indokolt pointerek használata, addig egyébként is érdemes kerülni őket. Majd ha belemerülsz jobban a témába, és szembe jön veled a dinamikus kötés, referencia szerinti paraméterátadás, öröklődés, stb... akkor érdemes foglalkozni jobban a pointerekkel is. Addig tanulgatni teljesen jó ez a módszer is, ahogyan most csinálod.
-
jattila48
aktív tag
válasz
choco01
#4050
üzenetére
tanulo.nev = "Tamas";helyetttanulo->nev = "Tamas";sorral próbálkozzál. Úgy jónak kell lenni. Mivel new-val hoztad létre az objektumot, egy erre mutató pointert kaptál vissza (mint ahogy helyesen így is deklaráltad a tanulo változót), aminek a tartalma (*tanulo) maga az objektum, és ennek van nev nevű adattagja. Ezért így is írhattad volna:(*tanulo).nev = "Tamas";
De mivel annyira gyakori konstrukcióról van szó, a rövidség kedvéért err bevezették a -> operátort. -
#4024
PandaMonium
őstag
#hpq
#4022
PandaMonium
őstag
Dobj egy PM-et és megbeszéljük.
(#4016) Bici: Alex Allain: Jumping into C++, majd Scott Meyers: Effective Modern C++. Ha van már programozói tapasztalatod, ezt a kettőt elolvasod 1 hét alatt és tudsz alap/közép szinten C++ozni. Mire a memóriamodellt megérted és megtanulod hatékonyan kezelni a kézzel való allokálást (smart pointereket is ideértve) az sokáig fog tartani.
-

thiclyoon
aktív tag
Sziasztok!
Nem rég óta tanulom a C-t és a C++-t. Jelenleg bináris fákkal szórakozok egy ideje, előkerült néhány probléma. Pl. hogyan tudom megszámolni, hogy egy fában hány elem van? (Igazából az átlagukra is szükség lenne, szóval az összeg is kérdéses (egy elem többször is szerepelhet, a db is tárolva van), de azt jobban el tudom képzelni.)
Valamint kódszinten is elvesztem (vagy a kiíratással, vagy a törléssel van a gond. Addig bütyköltem, hogy már teljesen belezavarodtam - átnéztem már stackoverflow-ra és még néhány oldalra is), ha van ötletetek mi a ludas, várom a tanácsokat
(Furcsa lehet a pointer-pointer, de a teljes törléshez szerintem ez kéne. Ja és remélem érthető a kód azért.)
void del(pont ** Head)
{
if (*Head != NULL)
{
del(&((*Head)->Left));
del(&((*Head)->Right));
(*Head)->Left = NULL; //kerdeses hogy kell-e
(*Head)->Right = NULL; //szinten
free(*Head);
}
return;
}illetve
void kiir(pont * Head)
{
if (Head == NULL)
{
return;
}
if (Head->Left != NULL)
{
kiir(Head->Left);
}
printf("%d, %d-szor\n", Head->adat, Head->darab);
if (Head->Right != NULL)
{
kiir(Head->Right);
}
return;
}Futtatáskor a végén (del után) a Head ide mutat: 00794D38 (miért nem nullptr? nem az kéne legyen free után?), valamint nincs se error se warning, csak futás idejű hiba: Exception Thrown (az
if (Head->Left != NULL)sorban akiirfüggvényben). Köszönöm előre is, minden tanács jól jön! -

kutkut
addikt
válasz
dabadab
#3949
üzenetére
Már miért kéne sok ezer soros kód ahhoz, hogy objektumokat használj?! Pláne, tanulási fázisban... Pl. matekban az integrálásnak is akkor van értelme, ha kellően "girbegurba" a függvény, mégis egyszerűbb megérteni a lényegét az y = x típusú függvényekkel...
Bár azzal egyetértek, hogy még korai elővenni az objektumokat, először a pointereket kéne átvenni. De mindenekelőtt a goto-kat elhagyni!

-
#3956
PandaMonium
őstag
dobragab
#3955
PandaMonium
őstag
válasz
dobragab
#3955
üzenetére
Az STL is objektum-orientált, hogy fogja megérteni pl. hogy működnek a file handlerek, vagy smart pointerek, ha nem tudja mi az a konstruktor és destruktor? Vagy, hogy mikor és miért akkor szabadul fel pl. a vector által allokált memóriaterület? Ez nem Java, hogy majd a GC kipucolja, érteni kell a memória allokálás és felszabadítás folyamatát, különben sokszor lábon fogod lőni magad.
Persze, tanuljon algoritmusokat meg konténereket, adatszerkezeteket, de a nyelv szemantikája és a benne használt paradigmák ugyanilyen fontosak. Ezeket sem kell rögtön PhD szinten tudni, csak annyira, hogy értsd amit csinálsz.
-
#3945
 dabadab
titán
m.zmrzlina
#3943
dabadab
titán
m.zmrzlina
#3943
válasz
 m.zmrzlina
#3943
üzenetére
m.zmrzlina
#3943
üzenetére
"1, Miért használ cím szerinti paraméterátadást, ha csak kiiratja a tömböt de nem változtat egyik eleme értékén sem?"
Arra gondolsz, hogy
void printArray(const std::array<int, 5> &n)?Mert kb. egymilliószor gyorsabb átadni egy pointert, mint létrehozni egy új tömböt, abba átmásolni az adatokat, majd a függvényhívás végén felszabadítani az egészet
Egyébként const-ként adja át, az ott elég jól kifejezi, hogy nem fogja módosítani."2. Mire való a függvény paraméterlistájában a tömb előtt a "const"?"
Az azt mondja, hogy nem fogja módosítani, ami a gyakorlatban kb. azt jelenti, hogy csak az objektum const metódusait fogja meghívni és a tagváltozóinak sem fog értéket adni.
"Egy kicsit feljebb a Passing std::array to function résznél azt írja, hogy azért kell mert a fordító így nem készít másolatot a tömbről"
Ez mondjuk így hülyeségnek tűnik, hacsak valamit nagyon félre nem értek, amikor referenciát adsz át, akkor se így, se úgy nem készít belőle másolatot.
Azt esetleg el bírom képzelni, hogy valamelyik fordító a
void printArray(const std::array<int, 5> n)-ből csendben magátólvoid printArray(const std::array<int, 5> &n)-t csinál és erre gondolt a költő. -
#3936
m.zmrzlina
senior tag
m.zmrzlina
senior tag
Van egy kisebb programom amiben C tipusú kétdimenziós tömböket használok (pl: int a[10][10]={....}) amit át szeretnék írni std::array tipusúra Itt tanácsoltátok.
Az a kérdésem, hogy hogyan működik a második esetben a kétdimenziós tömb? Azt olvasom, hogy a C-ben a tömb egy pointer ami a tömb első elemére mutat, az elemek pedig sorban ez után találhatóak a memóriában.
Ezek szerint az alábbi két deklaráció azonos?
int arr[10][10];
array<int, 100> arr;Illetve a C tipusú tömb egy elemére így hivatkozom:
z=arr[2][5];Ez ekvivalens a következővel?
z=arr.at(25); -

dobragab
addikt
válasz
 cadtamas
#3875
üzenetére
cadtamas
#3875
üzenetére
Némi terminológia, hogy eligazodj azon a könyvön túl is:
mutató == pointer
hivatkozás == referenciaHa a függvény feladata egy változó módosítása, akkor miért nem adjuk meg a függvény visszatérési értékének ezt az értéket és írjuk felül az eredeti változót?
Mert nem mindig lehet megtenni, vagy logikailag nincs értelme, vagy 2 értéket kéne visszaadnia, amit nem lehet, stb.
-
dobragab
addikt
válasz
jattila48
#3857
üzenetére
Végül nem is használtam többszörös öröklést emiatt, megoldottam kompzícióval. Így azonban az ősosztály pointert kell static_cast-olnom egy típusmezőtől függően egyik illetve másik leszármazott osztály pointerré, és ezzel elérni a kompozícióval mindkét osztályban létrehozott tagobjektumot, holott ez lehetett volna ős is.
Jol ertem, hogy a dynamic_cast runtime overhead-je helyett felvettel egy tipusmezot?
 Mintha annak nem lenne overheadje, vagy negativ hatasa a karbantarthatosagra.
Mintha annak nem lenne overheadje, vagy negativ hatasa a karbantarthatosagra.Ha az interface konstruktora trivialis, akkor a leszarmazott konstruktoraval nem kell foglalkozni, meg virtualis oroklesnel sem. Megoldja a fordito.
a kompozícióval mindkét osztályban létrehozott tagobjektumot
Ezzel ujrakrealtad a diamond-problema alapproblemajat, hogy ketszer szerepel a diamond "csucsa" a memoriakepben (nalad is ketto van), amit a virtual inheritance old meg. Szerintem sokkal egyszerubb lenne inkabb a diamondbol kihagyni a virtual kulcsszavakat, azt' jonapot. Igen, az interface ketszer lesz benne, de abban csak 1-1 vptr van. [link]
Szerintem sokkal kifizetodobb helyenkent leirni azt a dupla static_cast-ot (ahol mindegy, hogy A-ra vagy B-re cast-olod kozepen), mint tipusmezot hasznalni.

Egyebkent javaban sem fenekig tejfel az interface. Ott kotelezo az implementalt fuggvenyeket mind kiirni, akkor is, ha absztrakt. Azaz a linkelt peldaban A-ban es B-ben is kb. meg kellene ismetelni f deklaraciojat. Ja, es a javas interfesznek is van tisztesseges overheadje.

-
jattila48
aktív tag
C++ -ban sajnos nincs (java értelemben vett) interface, csak valami hasonló az absztrakt class-okkal. Ez azonban nem ugyanaz (egyébként nem ismerem a Javát), mert az ilyen osztályok mérete nem 0. Ebből adódik a jól ismert diamond probléma, annak minden nyűgjével. Ilyen pl., hogy a virtuális ősosztály pointert nem lehet static_cast-olni leszármazott osztályra (csak dynamic_cast => runtime overhead), és a legleszármazottabb osztály konstruktorából kell hívni a virtuális ősosztály konstruktorát. Ez akkor is így van, ha a virtuális ősosztály összes tfv.-e pure virtual és nincs adattagja (interface). Nekem most nagyon jól jött volna, ha java-szerű interface lenne a C++-ban, és nem kell megküzdeni (fölöslegesen) a diamond problémával. Végül nem is használtam többszörös öröklést emiatt, megoldottam kompzícióval. Így azonban az ősosztály pointert kell static_cast-olnom egy típusmezőtől függően egyik illetve másik leszármazott osztály pointerré, és ezzel elérni a kompozícióval mindkét osztályban létrehozott tagobjektumot, holott ez lehetett volna ős is.
Az MSVC-nek van ugyan _interface kulcsszava, de az nem különbözik attól, mintha tiszta absztrakt osztály írnék. Van-e olyan C++ fordító, ami valami java féle interface-t támogat? Nincs is tervbe véve hogy későbbi szabványok támogatni fogják? -
válasz
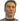 CPT.Pirk
#3854
üzenetére
CPT.Pirk
#3854
üzenetére
Nyilván szükséged van a konkrét példányra ahhoz, hogy meg tudd hívni annak egy függvényét és értelmes adatot kapjál vissza - ez C-ben is pont ugyanígy van, ha egy x változód struct_a típussal, akkor annak nem tudod úgy lekérdezni a tagjait, hogy csinálsz egy struct_a típusú y változót és azt állsz neki olvasni
Mivel a te MainWindow objektumodot pointerét egy random widgetből megkapni nem igazán triviális (és ez jól van így), ezért inkább javasolnám a slotos-signalos megközelítést, az a korrekt (és ennek jelen esetben a C++-hoz semmi köze, ha C-ben lenne megírva a QT, akkor is ez lenne a helyes út).
Ja, az, hogy egy téglalapról szóló infót a QPoint típusú változóban adsz át, azért nem egy nagydíjas ötlet
 , ott van a QRect, használd inkább azt, a geometry() úgyis azt adja vissza.
, ott van a QRect, használd inkább azt, a geometry() úgyis azt adja vissza. -

Domonkos
addikt
válasz
 Hunmugli
#3817
üzenetére
Hunmugli
#3817
üzenetére
Pointeres hackelessel tuti meg tudnad oldani - noha majdnem ugyanott lennel, ha egy pointert passzolgatnal/raknal egy kulso szkopba a valtozo helyett...
Egyeb ami eszembe jut, az a kulonbozo IPC megoldasok, mint peldaul az osztott memoria. Nem nagyo elegans, az olvashatosagon tuti ront es foloslegesen bonyolitja meg a dolgot, ha csak erre szeretned hasznalni, de mukodhet. -
válasz
Hunmugli
#3817
üzenetére
"El tudok érni egy nemglobális változót egy függvényből anélkül, hogy benne hoznám létre, vagy hogy átadnám neki?"
Szerencsére nem.
( Illetve nyilván mindent meg lehet csinálni, pointerekkel pl. megoldható, de ahhoz azért elég jól kell tudni, hogy adott architektúrán az adott fordító mit csinál és pontosan hova kell célozni a stackben. Ja, meg persze feltétel, hogy az adott változó ténylegesen létezzen, mert a példádban a fordítók jó eséllyel kioptimalizálnák a szam változót )
-
dobragab
addikt
válasz
Hunmugli
#3779
üzenetére
C++ szabvány nem engedi meg, hogy ne legyen megadva a visszatérési érték. GCC 4.9 ezek szerint sz*rik rá, ahogy sok minden másra is. [link]
Nem definiált függvény csak akkor fordítási (linkelési) hiba, ha meg is hívod. Ezt gyakran kihasználjuk, pl. template metaprogramozásnál.
int func(int);
double func(char);
using T = decltype(func(1)); // T == int(#3777) EQMontoya
Jogos, erre nem gondoltam. Azt hittem, pointerként kéne kiírnia (
%plenne printf-nél), mert ugye függvénypointer.Ezek szerint a kiírásra nincs függvénypointer-overload (persze, C++98-ban nem lehetne megcsinálni, utána meg kompatibilitási okok miatt nem vezetnék be soha).
Fptr->void*konverzió pedig adatszegmens - utasításszegmens okok miatt nem implicit. Pedigvoid*-os overload van. -

EQMontoya
veterán
válasz
dobragab
#3775
üzenetére
az viszont bool-ra (nem tudom pontosan, miért).
4.12 Boolean conversions
1 An rvalue of arithmetic, enumeration, pointer, or pointer to member type can be converted to an rvalue of type bool.
Szóval azért, mert nincs más konverzió, amit csinálhatna vele. Pointer -> int nincs impliciten. Igen, szerintem is béna.
-
dobragab
addikt
válasz
Hunmugli
#3771
üzenetére
Ha megnézed a fordító hibaüzenetét, közelebb kerülsz a megoldáshoz.
int x(int(int(int(int(int(int(int(int))))))));Ez a sor nem egy változó, hanem egy függvény deklarációja.
int x(int (*)(int (*)(int (*)(int (*)(int (*)(int (*)(int (*)(int))))))))Tehát egy inttel visszatérő függvény, [ami paraméterként egy inttel visszatérő függénypointert vesz át]...., ami paraméterként egy intet vesz át.
Utána, a kiírásnál a függvény automatikusan a címére konvertálódik (ami egy függvényre mutató pointer), az viszont bool-ra (nem tudom pontosan, miért). Ezért ír ki 1-et.
Függvénydeklarációnak viszont nem adhatsz értéket.
Nem véletlenül szokták mondani a C / C++ deklarációkra, hogy syntax only a compiler could love…
-

Hunmugli
aktív tag
válasz
 bandi0000
#3767
üzenetére
bandi0000
#3767
üzenetére
C:
 , asszem c++14-gyel. (gnu gcc)
, asszem c++14-gyel. (gnu gcc)Vagy cpp.sh-val - bár megnézve a figyelmeztetést, szerintem pointereket hoz létre. De értéket nem tudok neki adni
Van ez a módszer:
int y(15);Azt akartam kipróbálni, hogy van-e ilyen:
int y(15);
y(2*y);Mert az első esetben a () értékadás, hát a másodikban miért ne működne?
 (nem működik, y is not a function)
(nem működik, y is not a function)Aztán valahogy az előző kommenben lévő kódot kreáltam
-
válasz
 pvt.peter
#3692
üzenetére
pvt.peter
#3692
üzenetére
"Tehát adott egy void* típusú pointer ami reprezentálhat több egymással semmilyen kapcsolatban nem álló típust ami szintén egymással semmilyen kapcsolatban nem álló interfész megvalósítása."
Hát, ez így első nekifutásra az "elbaszott design" c. kategóriába való, ezt szépen nem lehet megoldani.
-

pvt.peter
őstag
Sziasztok,
Én is bedobnék egy témát
Egy void* típusú pointert hogyan lehet valid típusra castolni?
Tehát adott egy void* típusú pointer ami reprezentálhat több egymással semmilyen kapcsolatban nem álló típust ami szintén egymással semmilyen kapcsolatban nem álló interfész megvalósítása.
Hogyan tudom a valódi típusára castolni ezt a szerzeményt?
Jöhet bármilyen ötlet, amikre én gondoltam azok eléggé csúnyácskák voltak.Jelenleg nem tudok erre valid es relatív "szép" megoldást.
A kérdés az, hogy ti esetleg tudtok-e erre vmit?
-
jattila48
aktív tag
válasz
dobragab
#3617
üzenetére
"Futásidejű költsége nem a static_cast-nak van, hanem a type switch-nek"
Én is ezt írtam. A type switch-et meg nem tudom elkerülni, mert mikor megtalálok egy szimbólumot, akkor a tíőusától függően kell folytatni a fordítást. Pl. egész mást kell csinálni ha a szimbólum változó, mint ha függvény. És azt előre nem tudom, hogy a keresett szimbólum milyen típusú lesz.
Nem értem mi előnye lenne a különböző típusok külön tárolásának, azonban azt látom, hogy rengeteg a hátránya.Minden, típusonként külön szimbólum táblában kezelni kell a scope-ot, holott a scope a típustól függetlenül ugyanúgy vonatkozik az összes szimbólumra. A find_symbol fv.-nek végig kell keresni az összes szimbólum táblát, és attól függően, hogy melyikben találta meg a szimbólumot, vissza kell hogy adja a típusát (ezután pedig mindenképpen type-switch jön). Sőt nem csak a típusát, hanem valami módon magát a szimbólumot is, pl. iterátorral. A visszaadott iterátor minden esetben más típusú lesz, ha csak az összes szimbólum nem egy közös őstől származik, és a táblázatok az ős pointert tárolják, amiket aztán ugyanúgy típustól függően static_cast-olni kell (mint ahogy most is csinálom). De akkor miért kéne külön táblázatokba tenni? Ha valamiért új típusú szimbólumot kell bevezetni, akkor a find_symbol fv.-t bővíteni kell az új típusnak megfelelő táblázat keresésével. Ezek mind hátrányok, és bonyolítják a programot. A Te megoldásod egyetlen "előnye", hogy a szimbólumokban nem kell a típusukat tárolni.
Az, hogy a táblázat vektor-e, vagy más, teljesen lényegtelen. Max. pár száz szimbólumról lehet szó, ennyire pedig talán a vektor overhead-je a legkisebb, úgyhogy a keresés sem lesz túl lassú (egyébként is csak fordításkor van szimbólum tábla, futáskor már nincs).
Egy szó mint száz, nem tudsz meggyőzni a külön-külön tároláskor, de nem is ez volt a kérdés. A static_cast nekem sem tetszik, de nem tudok jobbat. -
mgoogyi
senior tag
válasz
EQMontoya
#3613
üzenetére
Értem mire gondolsz, de ez csak a pointerekre vonatkozó cache miss.
Az objektumok kapcsán annyi cache miss lesz, ahányat feleslegesen megnézünk, azaz set esetén O(log(N)), vektor esetén meg O(N).Ha csak a pointert elég használni a komparálásra, akkor teljesen igazad van, de nem látom, hogy ez milyen esetben van.
A fordító csak a szimbolúm nevét látja, nem?A kis elemszámra hol van algoritmikus overheadje a set-nek pointeren keresztüli elemkeresésnél?
(Mondjuk ez tök mellékes, mert úgyis elhanyagolható.) -
jattila48
aktív tag
válasz
mgoogyi
#3606
üzenetére
Nekem úgy tűnik, mégsem egészen tudod, mi a szimbólum tábla (bocs). Ha egyszer bekerült a szimbólum a táblázatba, akkor azt már nem kell "feldolgozni" (legfeljebb törölni), hanem szükség szerint megtalálni kell, és az attribútumai alapján generálni a megfelelő kódot. A tárolt szimbólumnak ha lenne virtuális fv.-e, akkor az csak getter lenne, de semmiképpen nem "processz". Tulajdonképpen a find const pointereket ad vissza, mivel egyáltalán nincs szükség a megtalált szimbólum megváltoztatására. Azonban a szimbólumok, ahogy írtam teljesen különbözők, így nincsenek hasonló attribútumaik sem (a nevet és típust kivéve). Ezért nem lehet (és nem is kell) őket egységes interfészen keresztül kezelni.
-
-
jattila48
aktív tag
válasz
mgoogyi
#3603
üzenetére
Ne haragudj, de szerintem nem érted miről van szó. Persze, hogy csak a pointerek vannak sorfolytonosan a vektorban (hiszen írtam, hogy csak ezeket tárolom vektorban). EQMontoya arra gondolt, hogy vektorban (a sorfolytonos elrendezés miatt), kis elemszám esetén gyorsabb az ismétlődés keresés, mint pl. set-ben. Ez akkor is így van ha, csak az objektumok pointereit tároljuk, mert az algoritmus ezen fog föl-alá futkosni, miközben a pointerek által hivatkozott objektumokat hasonlítja össze. Ha jól van megírva az ismétlődés kereső algoritmus, akkor mindössze egy összehasonlító operátort kell neki átadni, és pont ugyanúgy működik, mint egyéb esetben.
Na de ennek semmi köze az eredeti problémához, mert szimbólum táblában NEM keresünk ismétlődést. -
jattila48
aktív tag
válasz
dobragab
#3593
üzenetére
Erre gondoltam, de mit adjon vissza a virtuális fv.? A konkrét típusú this pointert (kovariáns típus)? Az nem jó. Más virtuális fv.-t meg nem lehet bevezetni, mert amúgy a típusok teljesen különbözőek. Az egyiken elvégezhető művelet értelmezhetetlen a másikon. Ebben az esetben mit csináljon a virtuális fv,? Exception-t dobjon? Vagy esetleg az ősbeli pure virtual-nak legyen törzse, ami exception-t dob, ha meghívódik? Másrészt az ősosztályban fel kéne venni virtuális fv.-ekként az egyes konkrét osztályokon értelmezhető műveletek unióját. Vagy rosszul értem, amit írtál?
-
jattila48
aktív tag
Egy vektorban szeretnék különböző típusú objektumokat tárolni. Ezt nyilván nem lehet, ezért a tárolandó objektumok osztályai egy közös őstől származnak, ami csak a konkrét leszármazott típusra utaló enum mezőt tartalmaz. Az objektumokat new-val hozom létre, és a pointereket (mint ősre mutató pointer) tárolom el a vektorban. Igazából unique_ptr-eket tárolok, de ez most lényegtelen (std::vector<std::unique_ptr<Base> >). Amikor a vektor egy elemére hivatkozok, akkor az adott unique_ptr-ből nyert raw pointert kapom vissza, amit a típusmezőnek megfelelően futás időben static_cast-olok a konkrét leszármazott típusra. Ezzel az a baj, hogy állandóan vizsgálni kell a típusmezőt, és elvégezni a static_cast-ot. Van-e ennek jobb megoldása? (Boost-ot nem használok, ezt ne is javasoljátok).
-
dobragab
addikt
válasz
EQMontoya
#3502
üzenetére
Csak elkészült ez a válasz, túl régóta írom.
Az emplace_back veszélyét szerintem az első világítja meg legjobban. Nem te hívod meg a konstruktort, így történhetnek olyan konverziók, amit nem szeretnénk.
A második példában az igazi körmös nem az emplace_back, hanem a RAII megsértéséért jár. Sőt, rosszabb: RAII és raw pointer keverése. Ugye resource acquisition is initialization lenne, csakhogy a foglalás után pakolod bele egy unique_ptr-be, itt épp implicit módon.
Ha azt vesszük, hogy a vector deklarációja zömmel három forrásfájllal és 2000 sorral arrébb van, mint ahol belepakolsz, és lehet, hogy rosszul emlékszel, hogy az most A*-ot, vagy unique_ptr<A>-t tartalmaz. push_back-nél ha rosszul emlékszel, a fordító hörögve kiszáll.
Szóval a második esetért közvetve az emplace_back felelős, közvetlenül az, aki nem emlékszik, hogy ott unique_ptr van. Általános esetben is, az emplace_back-nél nem mindig kell tudnod, hogy temporális vagy létező cuccot akarsz-e belerakni, és ez itt a fő veszélyforrás.
Engem kísértetiesen emlékeztet a kérdés a C-s NULL és a 0 esetére, a hatékonyságot kivéve. Mindenhova írhatsz 0-t, ahova NULL-t, de fordítva nem igaz. Most ne keverjük ide a printf-et, talán az az egy kivétel van. Mégis, az olvashatóság kedvéért pointereknél NULL-t, egészeknél 0-t írunk, pedig írhatnánk mindenhova 0-t. Ugyanígy, az olvashatóság kedvéért létező objektumnál tessék push_back-et írni, hogy biztosak lehessünk benne, ott tényleg létező objektumról van szó.
Ennyi indok bőven elég, hogy push_back helyett ne használjunk emplace_back-et.
Továbbmegyek: van egyáltalán létjogosultsága az emplace_back-nek?Ha egy már létező objektumot akarsz belepakolni, a kettő pont ugyanannyira hatékony, ugyanaz történik. Megnéztem, mi a helyzet abban az esetben is, amire az emplace_back elsődlegesen való: temporális objektumnál. Igazából arra ment ki a játék, hogy ilyenkor jobb-e az emplace_back, mint a push_back kiírt konstruktorhívással. Azért mégis csak jobban látni, hogy ott egy temporális objektumot pakolunk bele a vektorba, ha oda van írva.
Ilyenkor szoktam elővenni a Noisy osztályt, ami mindig kiírja, mikor mi történik vele, és számolja, hány példány van belőle, amúgy semmi másra nem jó. Itt a teljes forráskód, a Noisy túl hosszú ahhoz, hogy gátlástalanul bemásoljam, ide csak a lényeget hoztam.
int main()
{
std::vector<Noisy> vec;
vec.reserve (1000);
Noisy n1(1);
vec.emplace_back(n1);
Noisy n2(2);
vec.push_back(n2);
vec.emplace_back(Noisy(3));
vec.push_back (Noisy(4));
vec.emplace_back(5);
}Az elején azért van ott a ronda reserve, hogy ne legyen átméreteződés, az csak összezavar minket.
Az n1 és az n2 esetében kottára ugyanaz történik, ahogy el is várjuk, copy ctor. Noisy(3) és Noisy(4) is egyforma, move ctor. Az igazán érdekes a 4-es és 5-ös összehasonlítása. Annyit nyertünk az 5-össel a 4-eshez képest, hogy egy move ctorral és egy ki-move-olt objektum destruktorával kevesebb. Ezen spórolni meg igencsak barbár dolog C++11 óta.
Ha kikommenteled a move ctort, akkor a fordító sem generál - mert írtunk destruktort -, így a copy ctor hívódik, tehát a push_back lényegesen lassabb lesz.
És mivel az emplace_back eleve C++11, így jó eséllyel van move ctora a tárolt cuccnak. Akkor van igazán értelme az emplace_back-nek, ha nincs move ctor, ilyen-olyan okból. Nem is lehet neki jó move ctort írni - ilyet nehezen tudok elképzelni, de C++-ban semmit nem zárok ki -, vagy C++98-as, nem módosítható API-ból jön.
Ha nincs move ctor, a hatékonyság számít annyit, hogy szerintem elfogadható az emplace_back. Egyéb esetben én azt mondom, fordítva kéne: emplace_back helyett is push_back-et használni: fontosabb az, hogy lásd kiírva a ctort, mint a move ctor overhead-je.
Akkor viszont egy másik probléma jön elő: ha van move ctor, akkor push_back, ha nincs, emplace_back. Ez kb. ugyanolyan rossz, mint az eredeti probléma, szóval temporális objektumra egységesen kéne a kettő közül választani. Nézzük meg a várható kockázatokat és a nyereséget:
push_back: ha nincs move ctor, lassú, de jól olvasható és egyértelmű
emplace_back: ha nincs move ctor, gyorsabb, néhány karakterrel rövidebb. Várható kockázat: egy elrontott emplace_back miatt végtelen debuggolás...Szóval én azt mondom, temporális objektumnál az API függvényében kéne dönteni, hogy az adott projektben melyik. De létező objektumra egész biztosan push_back.
-
jattila48
aktív tag
válasz
dobragab
#3442
üzenetére
Az eredmény tömböt úgy juttatom ki, hogy előbb bejuttatom. Vagy helyben történik a feldolgozás, és akkor az input egybe output is, vagy kívül foglalok az output tömbnek helyet, a rámutató char * pointert és a puffer méretét pedig paraméterként kapja a fv. De ezt szerintem neked nem kell magyarázni.
-
jattila48
aktív tag
válasz
EQMontoya
#3342
üzenetére
Én 136-ot mondanék futtatás nélkül. Többszörös öröklődésnél a this pointert igazítani kell, amit az ún. thunk kód végez. Erről írtam a pimpl példámnál, amikor hatékonysági okból a forwarding fv. hívásokat member pointer-ekkel helyettesítettem. Ha csak az osztály incomplete deklarációját látja a fordító, akkor nem tudja eldönteni, hogy kell-e this pointer igazítás vagy nem, ezért a legrosszabb esetre készült. Ez volt az a bizonyos assembly kód, amit a VS feltehetőleg rosszul linkelt. Ha azonban a a forward deklarációban közöljük, hogy a szóban forgó osztály _single_inheritance (MS kulcsszó), akkor nem generálja a felesleges thunk kódot, és jól működik. A gcc-nek nem okozott ez problémát, persze az is generálta a thunk kódot.
-

kobe24
tag
Köszönöm mindkettőtöknek a választ! Így már érthetőbb, és közben meg is tudtam csinálni struktúra nélkül a feladatot. Még az az egy kérdésem lenne, hogy az osztályon belül definiáltam egy string pointert, majd később mikor már szeretném felhasználni ezt a változót, megadom neki, hogy y=new string[db], viszont ha így próbálom elindítani a programot, akkor egyből lefagy, és be kell zárni, de ha a db helyére egy konkrét számot írok, esetemben 400-at, akkor hiba nélkül lefut a program. Én próbálgattam keresni, hogy mitől lehet ez, de sokra nem jutottam. Az biztos nem lehet, hogy túl nagy lesz a tömb, mert a db változó nem lehet nagyobb mint 400.
-
válasz
dobragab
#3313
üzenetére
"Amíg nem érti tökéletesen, mi az a tömb, hogy a méretét nem tudja lekérdezni függvényből, hogy mi köze a pointerhez, stb. addig nem szabad neki std::vectort tanítani, mert utána már sosem tanulja meg, mi is az a tömb."
Ez abszolút nem igaz. Én is megtanultam, pedig BASIC tömbökkel kezdtem, amik sokkal több rokonságot mutatnak az std::vectorral, mint a C-s tömbökkel.
Valahol el kell kezdeni a tanulást és nem lehet rögtön kettes számrendszerrel meg mutatókkal kezdeni, mert hiányoznak az alapok ahhoz, hogy meg tudják érteni, hogy mi az. Meg én is előbb használtam virtuális függvényt, minthogy tudtam volna, hogy mi az a vtable, aztán mégis ember lettem
-
dobragab
addikt
válasz
jattila48
#3307
üzenetére
Kezdőknek pedig nem OOP szemléletet és STL-t kell tanítani, hanem írja meg C-ben az alap algoritmusokat (keresés, rendezés, stb), értse meg a paraméterátadás rejtelmeit (érték, cím,...), írjon rekurzív fv. hívást, stb. Ez később mind hasznára fog válni, amikor már a C++ esetleg magasabb szintű absztrakcióit használja. Pontosabban enélkül, soha nem lesz belőle jó C++ programozó.
Tökéletesen egyetértek.
Igazából lényegtelen, hogy C vagy C++ a nyelv, de C++-ban egy csomó olyan dolog van, aminek dependency-je, hogy értse, hogyan van C-ben.
Például amíg nem tudja _tökéletesen_, mi az a pointer, nem kéne sem referenciát, sem okos pointert tanulni. Sőt, okos pointereket csak azután kéne, hogy megvolt az OOP, a RAII, a template és esetleg a jobbérték referencia.
Amíg nem érti tökéletesen, mi az a tömb, hogy a méretét nem tudja lekérdezni függvényből, hogy mi köze a pointerhez, stb. addig nem szabad neki std::vectort tanítani, mert utána már sosem tanulja meg, mi is az a tömb.
std::string-et is csak azután kéne tanítani, hogy érti a tömböket, használta a karaktertömböket, stb.
Fvptr -> öröklés ugyanez.
Szóval sorolhatnám még a dependency-ket, de nem sok értelme van. Az a lényeg, hogy ezeket be kell tartani, és bizony C-ben nem lehet ezt a szabályt megszegni, mert nincsenek ilyen cuccok. C++-ban sokkal könnyebb "rossz útra tévedni", míg C-ben nem lehet. Ha betartja ezeket a játékszabályokat, akkor a C++ jobb lehet, mert egy csomó f*szságot meg tud úszni a scanf-től a qsort-ig, de jóval nehezebb ezeket betartani.
-
jattila48
aktív tag
Hogy az eredeti kérdésedre válaszoljak:
Stanley Lippmann: C++ primer
van magyar kiadása is (nem a legújabb) C++ először címmel. Szerintem egész jó könyv kezdőknek. Utána pedig természetesem a Sroustrup könyv. Az internetem is rengeteg könyvet/cikket találsz pl. Scott Meyers effective c++, vagy Herb Shutter GotW cikkei. A DrDobbs folyóirat cikkei kifejezetten jók C++ témakörben (meg másban is).
Egyébként mivel a C gyakorlatilag része a C++-nak, nincs értelme azon vitázni, hogy a kettő közül melyiket tanuld meg. A C-t meg tudod tanulni anélkül, hogy C++-t tanulnál, de fordítva nem. Ha C++-t tanulsz, akkor meg fogod tanulni a C-t is. És it most nem az a lényeg, hogy nem printf-fel iratsz ki. Értelmetlen azon vitázni, hogy a pointerek használatát C-ben vagy C++-ban sajátítod el, mert ez egy és ugyanaz. Referenciák meg nincsenek a C-ben. Aki nem ismeri alaposan a C nyelvet, az a C++-t sem ismeri. Kezdőknek pedig nem OOP szemléletet és STL-t kell tanítani, hanem írja meg C-ben az alap algoritmusokat (keresés, rendezés, stb), értse meg a paraméterátadás rejtelmeit (érték, cím,...), írjon rekurzív fv. hívást, stb. Ez később mind hasznára fog válni, amikor már a C++ esetleg magasabb szintű absztrakcióit használja. Pontosabban enélkül, soha nem lesz belőle jó C++ programozó. Akkor jön az, hogy mindenre (a legegyszerűbb dolgokra is) kész STL tárolókat/algoritmusokat és könyvtárakat keres, mert nem érti elég mélyen a problémát (hiszen soha nem ásott bele amúgy "pattintott" C megközelítéssel), és azt sem látja át, hogy a készen kapott megoldások nem feltétlenül alkalmazhatók az ő problémájára. Na ekkor jön a patkolás: az eszközhöz igazítja a feladatot, és nem fordítva. A C++ és az OOP csak eszköz, és ha "pattintott" C megközelítéssel egy feladata átláthatóbban, hatékonyabban oldható meg, akkor úgy kell megoldani. Nincs ebben semmiféle ellentmondás. A struktúrált és az OOP megközelítés nem zárják ki egymást, egyik sem szentírás. Az osztályod tfv.-eit legalábbis igyekszel struktúrált módon megírni (C-ben az sem szentségtörés ha nem), még ha az adatszerkezet OOP megközelítésű is. A virtuális tfv.-ek mibenlétét, működési módját, használatát sem igazán lehet megérteni anélkül, hogy C-ben soha nem írtál fv. pointereket tartalmazó tömböt. Nem szaporítom tovább a szót, a lényeg, hogy teljesen felesleges és mesterséges a C és C++ nyelvek szembeállítása, mivel nem két külön nyelvről van szó. -

ToMmY_hun
senior tag
Tegyük fel, hogy placement new-val foglalsz területet egy objektumnak és ebből készítesz pointert, vagy készítesz egy szimpla változót, és azt éred el cím alapján. Szerinted ez egy és ugyanaz? Lehet C++-szal kezdeni, de nehéz menet lesz. Szerintem egyszerűbb az alapokkal kezdeni, majd abból építkezni magasabb szintek felé. Nálunk a suliban ASM volt a kezdés, utána C, aztán opcionálisan C++ vagy egyéb. Szerintem így eléggé alaposan el lehet sajátítani a szükséges szemléletmódot és tudást. Nem véletlenül oktatják ilyen sorrendben az egyetemeken sem.
-
válasz
 ToMmY_hun
#3293
üzenetére
ToMmY_hun
#3293
üzenetére
"C-vel kezdtem és sokkal könnyebb, mint C++-ban programozni. Alapozni nagyon ideális."
Meg arra is, hogy rossz szokásokat vegyél fel, szoktam azzal baszogatni a kollégákat, hogy amit írnak, az C, nem C++, szóval az így nem lesz jó
Pointereket meg hasonló alacsonyszintű dolgokat szerintem assemblerben sokkal jobban meg lehet tanulni
Az eredeti kérdéshez sajnos érdemben nem tudok hozzászólni, a kézenfekvő válasz a Stroustrup-féle C++ aktuális kiadása lenne, de azt is csak a polcon van meg, valahogy soha nem jutottam el odáig, hogy el is olvassam.
-

doc
nagyúr
válasz
ToMmY_hun
#3298
üzenetére
mennyivel nehezebb a pointer fogalmat megerteni C++ tanulas kozben mint C tanulas kozben? nyilvan semmivel, pontosan ugyanarrol van szo mindket esetben
valamiert meg vagytok gyozodve arrol hogy aki C++ -t tanul az nem tanul tombokrol meg pointerekrol, mig aki C-t tanul az igen, holott mindket esetben ugyanugy, es ugyanott resze az ismeretanyagnakA kulonbseg hogy amikor eloszor irsz egy tombelemeket ciklusban kiiro kodot akkor nem mondjuk printf("%d\n", arr[i]) hanem cout << arr[i] << endl lesz a kod. A lenyeg, vagyis a ciklus pont ugyanaz lesz mindket esetben.
Amikor pointerekrol tanulsz, akkor meg plane ugyanaz lesz, ugyanugy kell dereferalni mindket esetben, ugyanugy kell megerteni hogy hogyan 'mutat' a pointer a mogotte levo adatra.
Amikor mar benne vagy a surujeben akkor a C++ mar nyilvan bonyolultabb lesz, de ott meg pont nem segit semmit ha a C-specifikus dolgokat tudod (sot, csabit a durva ganyolasra C-s modszerek hasznalataval, lattam mar ilyet...)
-
doc
nagyúr
válasz
EQMontoya
#3292
üzenetére
Mitol kene ebbe 'belezavarodni'?
Miert zavarodsz bele a pointerbe ha C++ tanulas soran talalkozol vele, es miert nem ha ugyanazt C-tanulas kozben tanulod meg?A referencia a pointerek utan nem egy nagy truvaj, a smart_ptr meg mar egy olyan feature ami C-ben nincs (tehat neked kell nullarol megcsinalni), C++ -ban meg keszen kapod. Raadasul az mar eleve nem kezdo anyag.
-
EQMontoya
veterán
Szerinted mi az amit kezdokent C-ben egyszerubb mint C++-ban? (foleg hogy a C++ az kb 99.9%-ban felulrol kompatibilis a C-vel)
Az, hogy C++-ban kb. minden olyannal foglalkozol, amivel C-ben, de ha C-vel kezdesz, akkor nem egyszerre fogsz belezavarodni a referenciákba, pointerekbe, smart_ptr-ekbe és az érték szerinti átadásba, hanem csak a felé kapod egyszerre az arcodba.
Továbbá nem fogsz kapásból belefutni mondjuk a vptr-be, hanem lesz már némi fogalmad a függvénypointerekről, el tudod képzelni, hogy hogyan is működik az egész. -
jattila48
aktív tag
válasz
ToMmY_hun
#3221
üzenetére
Lehet, hogy nekem nehéz a felfogásom, de a magam részéről nem értem mit szeretnél.
"Van néhány egymáshoz nagyon hasonló osztályom, amelyek különböző típusú objektumokat tárolnak."
Tehát ezek az osztályok konténerek? Egy konténeren belül lehet egymáshoz képest különböző típusú objektumokat tárolni, vagy egy konténer egy adott típusú objektumok tárolására alkalmas?
"minden ilyen osztály rendelkezzen előre deklarált metódusokkal, amelyek osztályonként különböző típusú objektummal térnek vissza vagy végeznek rajtuk műveletet"
Mármint az adott metódust (c++ -ban tagfüggvény) tartalmazó osztályonként..., vagy paraméterben kapott objektum típusától függően térnek vissza...?
Ha konténerről van szó, akkor ezt mint template-et akarod a tartalmazott objektumok típusával paraméterezni? Miért akarsz leszármaztatni? A leszármazott osztály valamely objektumára mutató pointert (referenciát) ősosztály típusúként akarod használni?
Egy kicsit konkrétabban, és részletesebben írd le mit szeretnél, akkor talán tudunk segíteni.
-
EQMontoya
veterán
Akkor gyorsan olvass utána a smart pointereknek. Úgy alapból a koncepciónak, hogy miről is szól ez az egész, utána pedig:
-kezdetben vala az auto_ptr
-majd lőn helyette unique_ptr
-kicsit bonyolultabb helyzetekre pedig van shared_ptr és weak_ptr (mint pl. a lentebbi, amikor több "tulajdonosa" van egy objektumnak) -

r4z
nagyúr
Nagyon láma kérdés következik.
Adott egy A és egy B osztály. A-nak az egyik adattagja B. Egy B többszáz A-hoz is tartozhat, és minden A-hoz tartoznia kell pontosan egy B-nek. Mindkettőt külön, rendszerezve szeretném tárolni/módosítani/törölni.
Hogyan érdemes nekiesni az adatszerkezetnek? Mindkettőből lista, és A B-nek csak a pointerét tartalmazza, vagy van ennél jobb megoldás is?
-
jattila48
aktív tag
válasz
EQMontoya
#3196
üzenetére
A gcc generálja a thunk kódot, a virtuális hívást, és még nem tudom mit. Mint ahogy a VS is, ha nem tud a BodyClass-ról semmit. Bármelyik fordítónak a "legrosszabb" esetre kell készülni (többszörös virtuális öröklés, virtuális tfv.), ha csak a BodyClass forward deklarációját látja, és semmi egyéb segítséget nem kap. Magától nem találhatja ki hogy "mizu" van. Nem tudom, hogy a gcc-nek vannak-e erre kulcsszavai, nem nagyon használom. A VS-ben is csak most találtam rá. Mondjuk member function pointert sem igen használtam, és gyakorlatban a forwarding fv. hívás sem túl nagy overhead, inkább csak elméletileg érdekelt a dolog. A C++-ból azért mindig van mit tanulni.
-
jattila48
aktív tag
válasz
jattila48
#3189
üzenetére
Na megint tanultam valamit. Ezt írtam:
"Jó lenne, ha a forward deklarációban meg lehetne mondani, hogy a BodyClass teljesen közönséges osztály, nem örökölt senkitől (főleg nem többektől) és nincs virtuális tfv.-e (még emiatt is lehet ez az igazítás). Akkor talán nem generálná ezt az ilyen osztályokra amúgy tényleg fölösleges igazító kódot. Ilyet sajnos tudtommal nem lehet a C++-ban."És VS-ben lehet! handle_class.h-ban:
class __single_inheritance BodyClass;__single_inheritance kulcsszó a forward deklarációban a megoldás! Így már igazító kód nélkül fordít, és főleg jól. Ha még azt is meg lehetne mondani, hogy az mfp nem virtuális fv.-re mutató member function pointer, akkor az indirekt címzésű call helyett is lehetne direkt címzésűt fordítani (bár ez nem nagy veszteség).





 most viszont a decodernel problemazik (de legalabb mar kozelebb vagyok a vegehez)
most viszont a decodernel problemazik (de legalabb mar kozelebb vagyok a vegehez) 

















 "
"


















 Mintha annak nem lenne overheadje, vagy negativ hatasa a karbantarthatosagra.
Mintha annak nem lenne overheadje, vagy negativ hatasa a karbantarthatosagra.

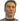
 , ott van a QRect, használd inkább azt, a geometry() úgyis azt adja vissza.
, ott van a QRect, használd inkább azt, a geometry() úgyis azt adja vissza.



 , asszem c++14-gyel. (gnu gcc)
, asszem c++14-gyel. (gnu gcc) (nem működik, y is not a function)
(nem működik, y is not a function)









Új hozzászólás Aktív témák
● ha kódot szúrsz be, használd a PROGRAMKÓD formázási funkciót!

- Apple iPhone 14 128GB, Kártyafüggetlen, 1 Év Garanciával
- iPhone 14 Kék független 256GB
- Samsung Galaxy S24 8/256 GB Onyx Black 6 hónap Garancia Beszámítás Házhozszállítás
- Új, bontatlan, iPhone 17 gyárilag kártya-független, apple világgaranciával
- Komplett PC - GTX 1080 , i7-7700, 32 GB RAM, 750 GB SSD, 1 TB HDD
- Lenovo ThinkPad P15 Gen 2 - i7-11850H 32GB 1000GB Nvidia RTX A4000 8GB 1 év gar.
- Telefon felvásárlás!! iPhone 12 Mini/iPhone 12/iPhone 12 Pro/iPhone 12 Pro Max
- LG 32GS95UX - 32" OLED / UHD 4K / 240Hz - 480Hz & 0.03ms / 1300 Nits / NVIDIA G-Sync / AMD FreeSync
- ÁRGARANCIA! Épített KomPhone Ultra 9 285K 32/64GB RAM RX 9070 XT 16GB GAMER PC termékbeszámítással
- REFURBISHED és ÚJ - HP USB-C Dock G5 (5TW10AA) - 3x4K felbontás
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Laptopműhely Bt.
Város: Budapest