Az AMD az első Bulldozer architektúrára épülő processzor után idén már bemutatta a Piledriver kódnevű modult, mely elsősorban az energiahatékonyság szempontjából jelentett előrelépést az elődhöz képest, így tökéletes alapot képzett a Trinity APU-ba. A vállalat azonban korábban már közölte, hogy a következő generációs Steamroller modul főleg a teljesítmény növelésére fog koncentrálni, és a Bulldozer modul gyengébb pontjait foltozza be. A Hot Chips 24 alkalmával Mark Papermaster röviden taglalta is, hogyan is gondolják ezt.
Hirdetés
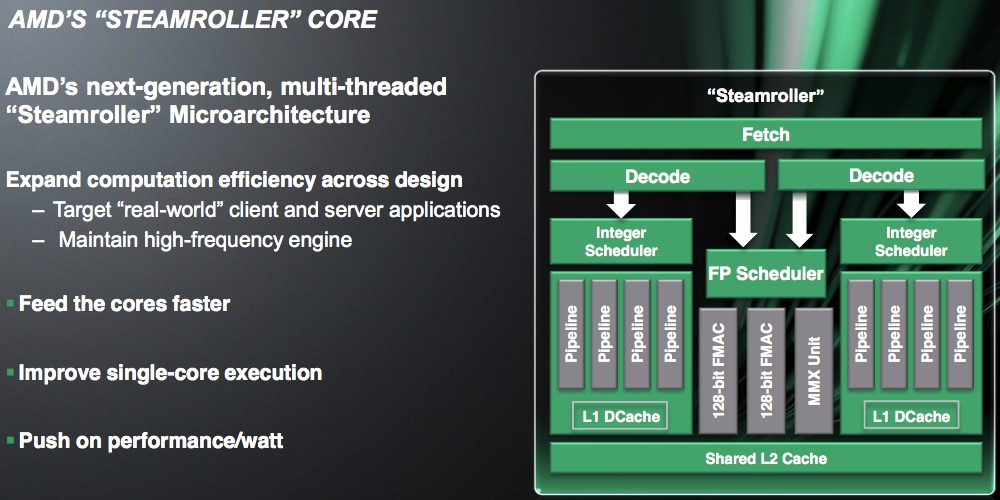
Az alapvető dizájn megmarad, vagyis a moduláris felépítés nem változik. Ez nem is gond, hiszen a rendelkezésre álló egységek hatékonyabb kihasználását teszi lehetővé, tehát borítékolható volt, hogy ehhez az AMD nem nyúl majd. A Bulldozer és a Piledriver modul esetében viszont a két integer magot és a megosztott Flex FP lebegőpontos egységet modulonként egyetlen dekóder eteti, ami órajelenként 4 utasítás fordítását végzi el és küldi a végrehajtók felé rögzített, Dispatch Groupnak nevezett makro-op négyesekbe. Itt keletkezhet a rendszerben egy komoly limitáció, ugyanis egy dekóder sok esetben nem tudja megfelelően etetni a teljes modult, amit a Steamroller kódnevű fejlesztés úgy orvosol, hogy mostantól modulonként két dekóder dolgozik ezen. Ettől nem kell megduplázott teljesítményt várni, de jelentős segítség lehet a rendszernek, ha a feldolgozók kihasználása javul. A radikális módosítás persze több tranzisztort is igényel, és a fogyasztást is növeli, de az AMD szerint az előnyök mindenképpen megérik.
[+]
Az AMD az integer magokon alig változtatott, de ezek a többi optimalizálásból előnyt kovácsolnak, illetve az ütemezésük hatékonysága 5-10%-kal javult. A Flex FP viszont módosult. A rendszer továbbra is két darab 128 bites FMAC egységgel dolgozik, de a korábbi kettő helyett a Steamroller modul már csak egy MMX egységet tartalmaz, ami lényegében megosztott erőforrást jelent az FMAC között. Az AMD ezzel tranzisztorokat spórolt, de a cég szerint a megosztott erőforrás a kódok nagyon nagy részében nincs negatív hatással a teljesítményre, a megosztás miatt pedig a Flex FP energiahatékonysága javul.
A feldolgozók hatékonyabb etetése érdekében az AMD átdolgozta az utasítás gyorsítótárat, aminek a tárkapacitása nőtt a Bulldozer és a Piledriver modul 64 kB-os egységéhez képest. A konkrét értéket a vállalat nem leplezte le, de Mark Papermaster elmondta, hogy a változás 30%-kal csökkenti a tévesztések (cache miss) lehetőségét. Az elágazásbecslés hatékonysága is sokat javult, ugyanis a Steamroller modul az elődökhöz képest 20%-kal kevesebbszer becsül rossz irányt. Az integer és a lebegőpontos regiszterfájlok szintén nagyobbak, de az AMD nem közölte a részleteket. Fontos adalék viszont, hogy a cég szerint az IPC (órajelenként végrehajtható utasítás) 30%-kal nőtt a korábbi fejlesztésekhez viszonyítva.
[+]
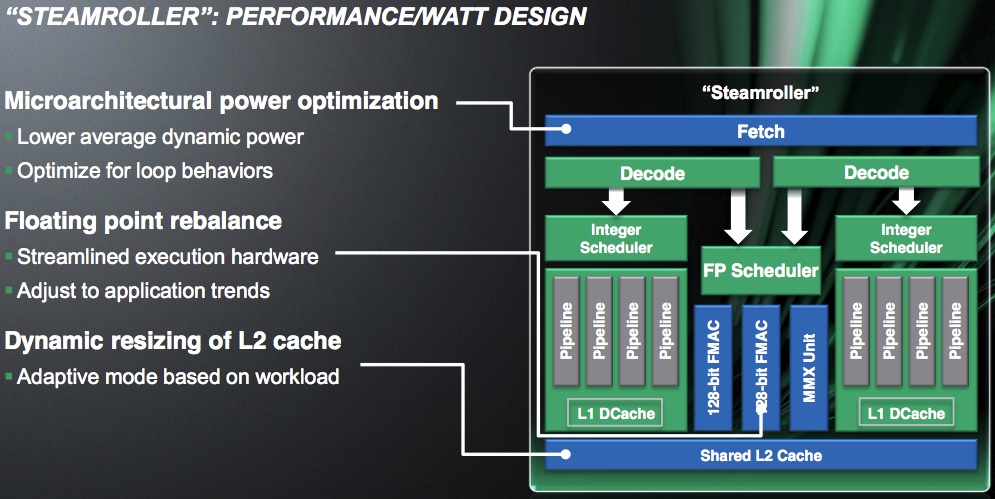
Az L1 és L2 gyorsítótár közötti interfész is javult, így hatékonyabban működik itt is a rendszer, de az igazán érdekes módosítás, hogy a modulhoz tartozó L2 gyorsítótár átméretezhető. Ezt úgy kell elképzelni, hogy nagy terhelés mellett a gyorsítótár teljes kapacitása kihasználható, de ha az adott folyamat nem igényli ezt, akkor a gyorsítótár negyede, fele vagy háromnegyede lekapcsolható, amivel rengeteg energia takarítható meg. Mindez teljesen dinamikusan történik, vagyis akár a program futtatása közben is megtehető, és erről teljes egészében a hardver dönt a felhasználó tudta nélkül. Az elérési időt az átméretezés nem módosítja, így ez a technika szimplán a fogyasztást csökkenti, de ezen a ponton tényleg sokat lehet nyerni. Az L3 gyorsítótár esetében sokan problémásnak tekintik a lassú elérést, de az AMD ezen nem javított. Mark Papermaster szerint az L3 gyorsítótár viszonylag lassú elérési ideje a szerverek piacán nem jelent gondot, mivel ezek a munkafolyamatok jellemzően nem túl érzékenyek erre, az asztali és a mobil PC-k szegmensébe kerülő, Steamroller modult használó lapkákból pedig úgyis hiányozni fog ez a tár.
A GlobalFoundries 28 nm-es gyártástechnológiáján készülő, Kaveri kódnevű APU-ba kerülő Steamroller modul felületes bemutatása után Mark Papermaster beszélt a jövőbeli processzortervezésről, mely alapvetően különbözik majd a mostanitól. Az előadáson elhangzott, hogy az ATI felvásárlásának egyik fő oka a processzortervezés magas szintű automatizálása. A GPU-k esetében ez a forma régóta jelen van, és nagyon fontos részét képzi a dizájn kialakításának. Ezt az AMD az ATI bekebelezésével is továbbvitte, illetve az eszközöket folyamatosan fejlesztik, de CPU-knál nem igazán alkalmazták még.

AMD High Density Library [+]
Az AMD a GPU-k tervezéséhez használt HDL (High Density Library) bevetésével demonstrálta, hogy mennyit jelent a dizájn kialakításának magas szintű automatizálása. A fenti kép felső részén a Bulldozer modul 128 bites FMAC egysége látható, ami 32 nm-es gyártástechnológiával készül. Az alsó részen ugyanez az egység található megegyező gyártástechnológiával, de már a HDL-t bevetve. Utóbbinak hála az egység mérete és fogyasztása 30%-kal csökkent. Ezek egymástól függnek, hiszen, ha csökken a méret, akkor csökken az órajelfa vezetékezése, ami összességében a fogyasztás csökkenéséhez vezet. A HDL hátránya, hogy a kézi dizájnokhoz képest alacsonyabb órajel-frekvenciával működhetnek az így kialakított egységek, de az AMD szerint ez így is megéri, mivel az órajelet korlátozzák a fizika törvényei, emellett a mobil irányt figyelembe véve ma már jobban számít az operációnként nyerhető 15-30%-os fogyasztáscsökkenés.
A HDL processzormagoknál, illetve -moduloknál való bevetéséről még nem beszélt a cég, de a Steamroller esetében biztos nem lesz alkalmazva, később azonban erősen épít majd rá az AMD.


