Egy kis történelem
Azon szerencsések közé tartozunk, akik első kézből értesülhettek az új Pentium 4-es processzorról, és élőben szemlélhették meg az ominózus bejelentést. Persze kénytelenek vagyunk rögtön visszavenni a lelkesedésből, ugyanis akkora mázlink már nem volt, hogy hetekkel ezelőtt elkezdhessük tesztelni az immáron asztali CPU-k családjában is HyperThreading támogatással felvértezett P4 3.06 GHz-es processzort. Marad tehát az elmélet, de hisszük, hogy a különböző szintetikus teszteknél sokkal többet ér, ha tudjuk és értjük, hogy mit is tud az Intel új zászlóshajója. Többszálúság tehát, rogyásig:
Hirdetés
Mit jelent a Hyperthreading?
Az utóbbi évtizedben a processzorok teljesítményét az órajel növelésén kívül architekturális fejlesztésekkel is próbálták növelni a processzorgyártók, nem kevés sikerrel, gondoljunk itt például a szuperskalár feldolgozásra, a branch predictionre (programelágazások eredményét megjósoló egység), a soron kívüli végrehajtásra vagy az egyre fejlődő cache-technológiára. Ezen megoldások mindegyike persze jelentősen megnöveli a processzorba épített tranzisztorok számát, a magméretet, és így a fogyasztást is. A fő probléma az, hogy a teljesítmény növekedése nem áll egyenes arányban a komplexitás növekedésével, mint ahogy azt az alábbi ábra is mutatja.
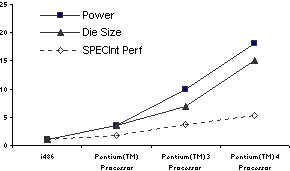
A teljesítményfelvétel, a magméret és a számítási teljesítmény változása
Emiatt a klasszikus processzortervezési elvektől el kell térni, és erre próbál egy megoldást adni az Intel - asztali processzoroknál - új megoldása, a Hyperthreading. Tudjuk ugyanis, hogy a szerverekbe és munkaállomásokba szánt XEON család esetében a többszálú végrehajtás jóideje elérhető, egyedül az asztali CPU-knál nem volt ez engedélyezve. Eddig.
A processzorok egyik teljesítménynövelő eszköze a szuperskalár architektúra, azaz kevésbé szépen nevezve az utasítások végrehajtásának párhuzamossága (ILP ? Instruction Level Parallelism) volt - ebbe a kategóriába tartozik például az Athlon 3 db ALU egysége. Ezzel a probléma az, hogy például az egész számmal végzett műveletek sorrendje nehezen megjósolható, tehát megfelelő hatásfokkal nehezen párhuzamosítható. A mai operációs rendszerek és programok azonban már nem csak az utasítások szintjén hajtanak végre több párhuzamos műveletet. Több, egymás mellett futó programszálból áll az, amivel játszunk, szöveget szerkesztünk, filmet nézünk vagy épp netezünk. Ezen szálak párhuzamos feldolgozásához (TLP ? Thread Level Parallelism) szükséges erőforrás-megosztás könnyen megoldható, ha például többprocesszoros rendszereket használunk. A szálak lehetnek azonos vagy különböző alkalmazás szálai, és az operációs rendszer szintjén végrehajtandó szálak is. Jelenleg ez a technológia a processzorokban az időosztásos többszálúságként (TSM ? time-slice multithreading) van jelen, amikor is egy szálon dolgozik a CPU, majd fix idő múlva vagy eseményvezérelten vált egy másik szálra. Ez persze több kihasználatlan ciklust is eredményez a váltások közti "üresjáratokban", azonban elég jól hasznosíthatók a RAM késleltetési idők (amikor egy szálnak várnia kell a memória-hozzáférésre), mivel közben lehetőség nyílik más szálak végrehajtására.
Természetesen ennél jobb a valódi többszálúság, azaz amikor egy végrehajtó egység megszakítás nélkül tud egy threaddel "foglalkozni". A multiprocesszoros rendszerekkel eddig is nagy teljesítményt lehetett elérni ebben a tekintetben, az elterjedésüknek az egyik korlátja az volt, hogy a chipek teljesítménye olyan gyorsan növekedett, hogy mire olcsóvá váltak volna a duál vagy többprocesszoros rendszerek, addigra mindig megjelent az új típus, amelynek sebessége már megközelítette a két vagy több CPU-ból álló eszközökét. Mára azonban a hűtőteljesítmény- és magméretbeli korlátok miatt újra érdemes lett gondolkozni több, párhuzamos processzor alkalmazásán. A Hyperthreading filozófiája szerint hajtsunk végre egy magon több szálat, párhuzamosan!
A cikk még nem ért véget, kérlek, lapozz!




