Az NVIDIA előrelépése
A 2014-es év elején ismerkedhettünk meg testközelből az NVIDIA Maxwell névre keresztelt fejlesztésével, ami végeredményben a februárban megjelentetett, középkategóriás NVIDIA GeForce GTX 750 és 750 Ti személyében öltött testet, és nem is szerepelt rosszul a tesztünkben. A némi csúszással bemutatott (akkor) új architektúrára épülő fejlesztés már korábban kitűnt a sorból hatékony energiafelhasználásával és a hozzá párosuló teljesítménnyel, de az igazi csemege, a Maxwell felsőbb kategóriában való felbukkanása a második félév távoli ködös jövőjében körvonalazódott. Ezzel kapcsolatban viszont csak tippek voltak.

Bár az NVIDIA az idestova lassan egy éve bemutatott GeForce GTX 780 Ti révén még mindig birtokolja a lélektanilag fontos első helyet az egy GPU-val szerelt VGA-k között, az ütemezést tartva végre előrukkoltak a Maxwellre épülő VGA-k fenegyerekével, ami kiváló bizonyítéka annak, hogy mennyire nehéz a jövőbe látni a gyártástechnológiai iránnyal kapcsolatban. Februárban ugyanis még 20 nm-es gyártástechnológiáról szóltak a pletykák, most viszont kiderül, hogy a várakozásokkal ellentétben ezen a téren nem léptek előrébb, így az új fejlesztés továbbra is 28 nm-es alapokon nyugszik. Ez persze nem annyira nagy baj, hiszen ez otthonos terep az NVIDIA számára, másrészt a csíkszélesség csak egy kis szelete a tortának, hiszen – ahogy azt látni fogjuk – van még kipréselhető energia- és teljesítménytartalék a 28 nm-ben is.
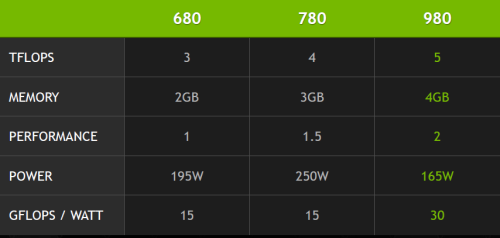
Mindezek fényében az NVIDIA receptje egyszerűen alakul a felsőházban: lépcsőzetesen növekvő számítási kapacitás és teljesítmény, több fedélzeti memória, mindez csökkentett fogyasztással fűszerezve, így az egyenlet végén nem is állhat más, mint a javuló hatékonysági mutató. A GM204 GPU többek között ezen az úton folytatja a GM107-tel korábban megkezdett utat, miközben tudását tekintve is fejlődött, amiről persze részletekbe menően beszámolunk a cikkünkben.

[+]
Ám mielőtt ezekkel az újításokkal megismerkednénk, az újdonsült GPU kapcsán mindenképp meg kell említeni, hogy az NVIDIA rögtön két kártyát is hoz a GM204-re alapozva. A csúcson a GeForce GTX 980 foglal helyet, illetve ezzel párhuzamosan a kisebbik modellel, a GTX 970 is megjelenik a kínálatban. Bár tesztünkben mi most csak az erősebb modellel kerültünk kapcsolatba, vessünk egy pillantást mindkét változatra! A fő eltérés a GTX 980 és 970 között a végrehajtóegységek számában, illetve a GPU-órajelben lesz, miközben a memóriabusz, valamint a memória mennyisége és órajele változatlan marad, akárcsak a portok típusai. Árban viszont jelentős eltérés lesz a két modell között: a GTX 980 hivatalos ára 179 000 forint, míg a GTX 970-é 105 000 forint lesz.
A Maxwell másodszor
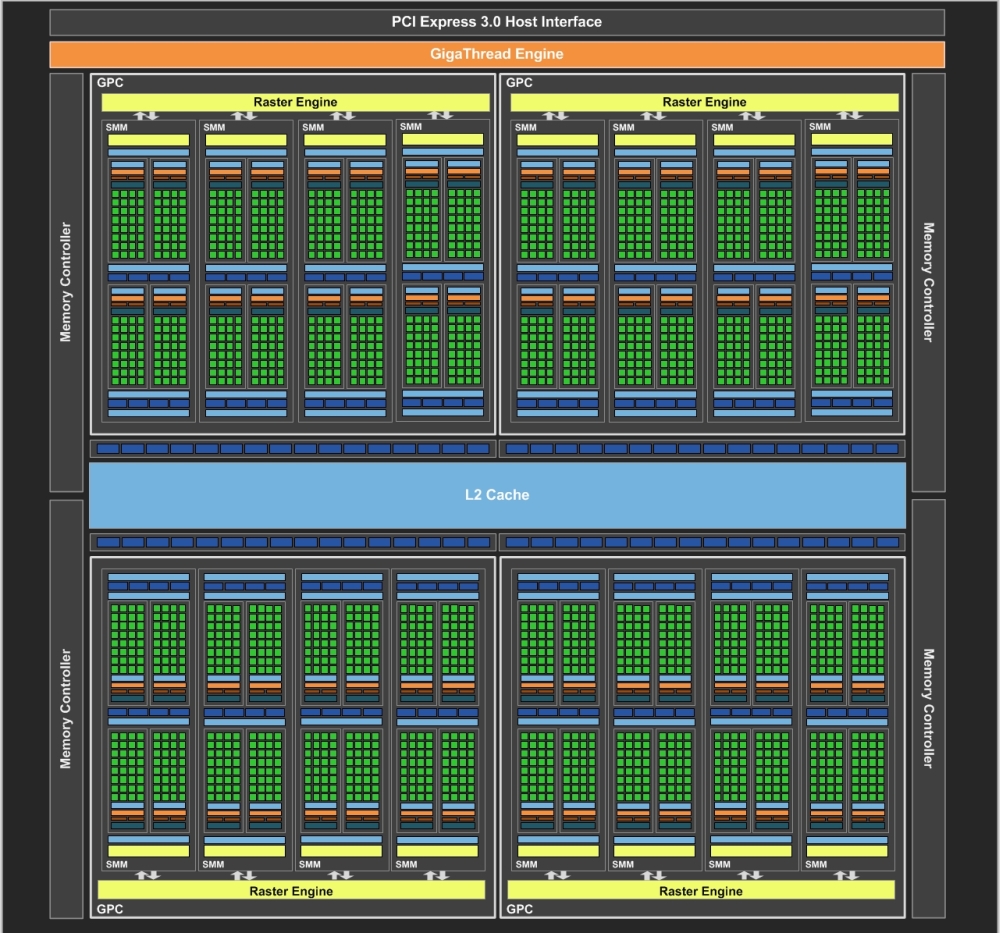
Természetesen az év elején bemutatott, eredeti Maxwell architektúrához képest a második generációs dizájn némileg változott, de az abszolút hatékony energiafelhasználás előtérben maradt. Az új GM204-es kódnevű lapka méretéhez képest nagyon jó fogyasztási mutatókkal rendelkezik. Nem meglepetés, hogy megmaradt a 28 nm-es gyártástechnológia, így az 5,2 milliárd tranzisztorból felépülő, 398 mm²-es chipbe 16 darab streaming multiprocesszort sikerült beépíteni, amit az NVIDIA a Maxwell esetében SMM-nek, azaz Maxwell streaming multiprocesszornak hív.
A GM204 [+]
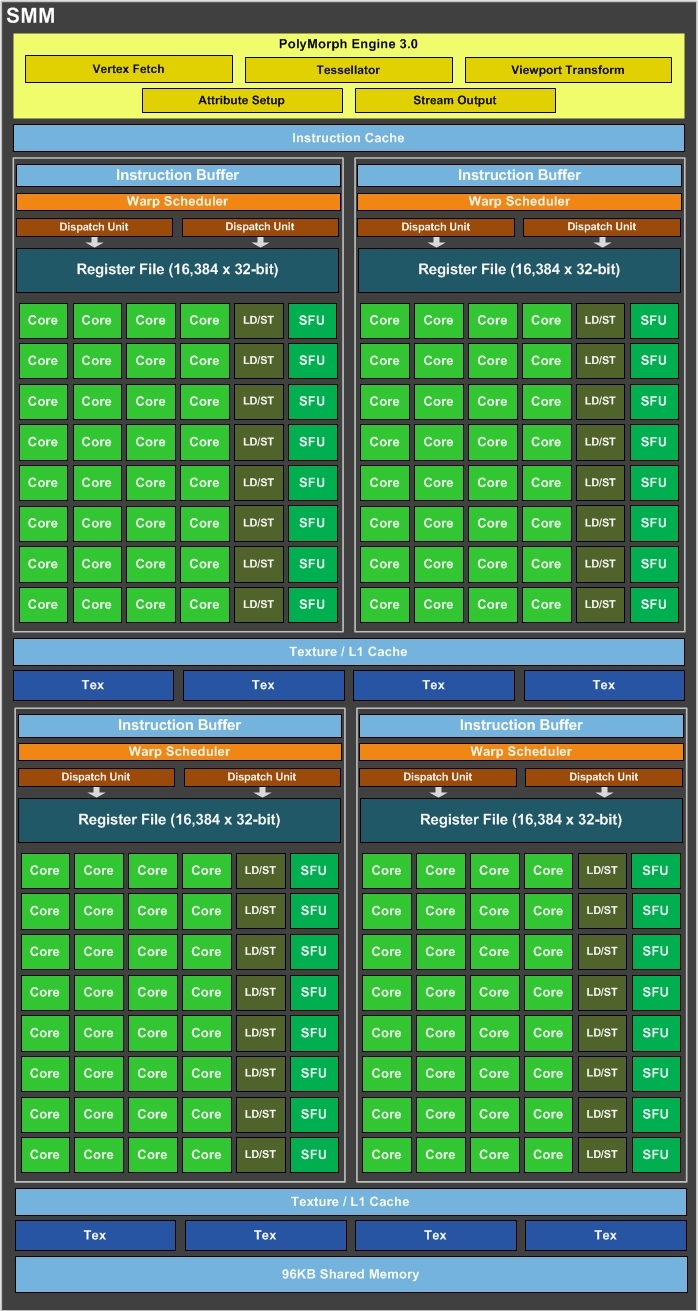
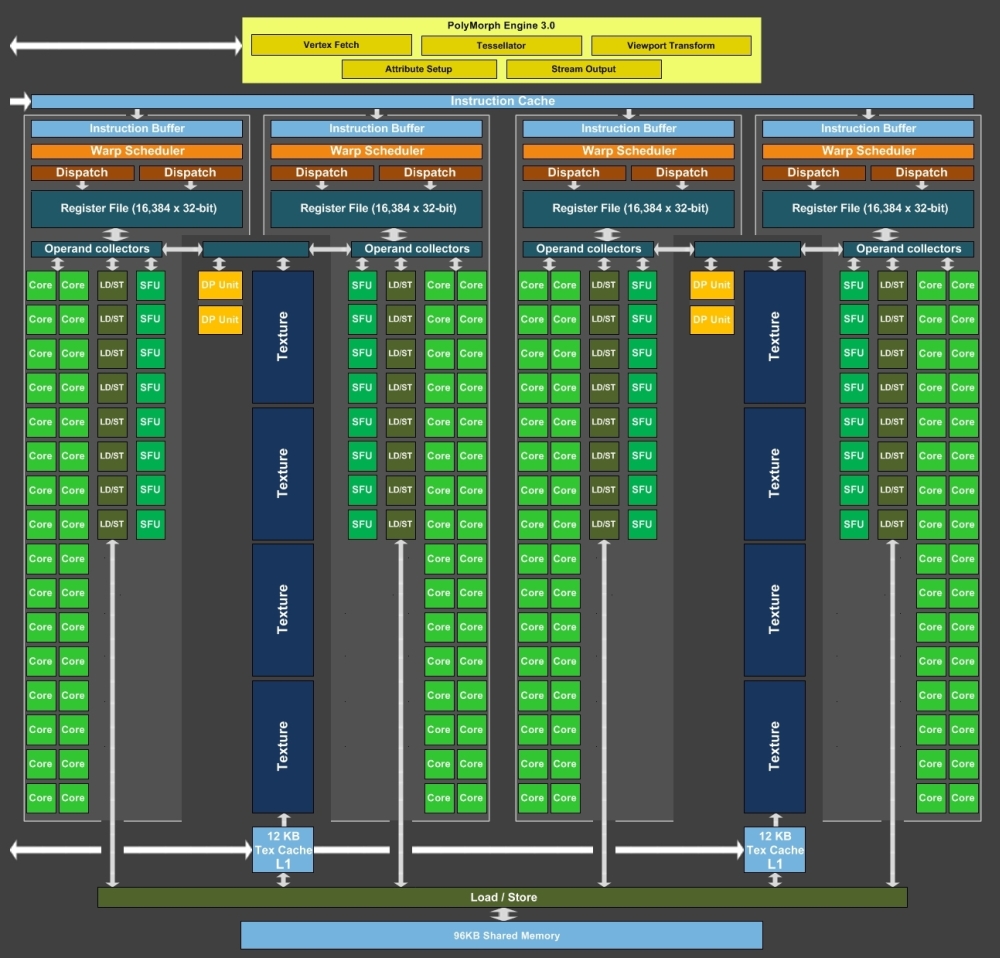
A streaming multiprocesszorok felépítése a GM107-ben ismert megoldáshoz képest alig változott. Ennek köszönhetően elmondható, hogy egy ilyen egységen belül négy nagyobb compute blokk került kialakításra, amelyek közös utasítás gyorsítótárat használnak. Mindegyik compute blokk rendelkezik egy utasítás pufferrel, ami nyilvánvalóan az utasítás gyorsítótárból szerzi be az aktuális munkához szükséges információkat. Az egész rendszer komplex ütemezést használ, ami részben a hardverben, részben a szoftverben valósul meg. A hardveres részért a már megszokott GigaThread motor felel, míg az ütemezés szoftveres oldala természetesen a driver fordítójának reszortja. Utóbbi alkalmazásával viszonylag sok energiát lehet spórolni.
Egy compute blokk két feladatirányító egységet (dispatch) és egy darab warp ütemezőt használ, amelyek 32 darab, úgynevezett CUDA magot etetnek, így az utasításszavak 2 darab, 16 utas feldolgozón hajtódnak végre párhuzamosan. Mindegyik CUDA mag rendelkezik egy IEEE754-2008-as szabványnak megfelelő, 32 bites lebegőpontos végrehajtóval, amelyek támogatják a MAD (Multiply-Add) és az FMA (Fused Multiply-Add) instrukciókat. Mindegyik compute blokkban közös regiszterterület található, amelynek kapacitása 64 kB. A compute blokkonon belül található még 8 darab, a speciális funkciókért felelő egység (SFU), amelyek a trigonometrikus és transzcendens utasítások mellett az interpoláció feladatát is elvégzik.
A GM204 a textúrázási képességek területén is a GM107-et másolja, így az egyes streaming multiprocesszorok két darab textúrázó blokkot tartalmaznak, amelyekben egyenként négy textúracímző és textúraszűrő található, és ezekhez csatornánként négy mintavételező tartozik. Egy textúrázó blokkot két compute blokk használ egyszerre. Ez hardveres szinten van bedrótozva, így mondható az, hogy az SMM két nagy feldolgozó tömbre oszlik, amelyek két compute és egy textúrázó blokkot tartalmaznak. Mindemellett a Maxwell esetében a textúrázáshoz való 12 kB-os gyorsítótár technikai értelemben továbbra is egy adatgyorsítótár marad, azaz természetesen tárolhat textúrainformációkat is, de számoláshoz szükséges adatokhoz is használható. Ennek hozománya, hogy ez a gyorsítótár nem csak olvasható, hanem írható is.
Az új SMM [+]
Eddig láthatóan nincs változás a GM107 és a GM204 SMM-jei között, ám nem maradtak módosítás nélkül, ugyanis az új verzióban az SMM modulok már 96 kB-os helyi adatmegosztással (Local Data Share) rendelkeznek, amelyen a négy darab compute blokk osztozik. Itt az NVIDIA továbbra is jelentős energiát takaríthat meg, hiszen technikai értelemben nem rendel direkt LDS-t az egyes compute blokkokhoz, tehát kevesebb tranzisztort is kell erre költeniük. Viszont a DirectCompute 5.0-s szabvány ezt a megoldást direkten nem támogatja, mivel a helyi adatmegosztáson egyszerre nem osztozhat több compute blokk, pontosabban fogalmazva több szálcsoport. A Maxwell a GM107 esetében ennek áthidalására egy trükköt használt, amivel a 64 kB-os helyi adatmegosztás többféleképpen volt működtethető. Alapértelmezett módban egy blokk maximum 48 kB-os részt kaphat, de ekkor maga a tár egy időegységben mindig csak az egyik compute blokkhoz tartozhat, míg a másik három compute blokknak olyan feladatot kell futtatni, ami nem igényli a helyi adatmegosztást, viszont a fennmaradt 16 kB-ot az említett három compute blokk feldolgozói közösen hasznosíthatják. Emellett, amint a tárkapacitás nagy részét birtokló compute blokkhoz tartozó feladat véget ért, a helyi adatmegosztást rögtön igénybe veheti egy másik compute blokk. Alternatív lehetőség a 32-32 kB-ra való felosztás, ami lényegében a DirectCompute 5.0 által előírt minimális kapacitás egy szálcsoporthoz. Ilyenkor már két compute blokk írhat a saját területébe, de a másik két compute blokk elől ez az erőforrás teljesen el lesz zárva.
Nyilván nem kedvező a számítások szempontjából, ha a négy compute blokkból egyszerre csak kettő írhat a saját területébe, bár a GM204 a 96 kB-os helyi adatmegosztást továbbra is leoszthatja két 48 kB-os részre is, ami továbbra is két compute blokkot működtet, viszont relatíve nagy tárral. Ugyanakkor alternatív lehetőség három darab 32 kB-os részre osztani az LDS-t, amivel a négyből már három compute blokk is befogható. Természetesen más compute felületeken a helyi adatmegosztás továbbra is sokkal rugalmasabban használható, hiszen a fenti működés főleg a DirectCompute 5.0-s szabvány limitációiból keletkezik.
Memóriahierarchia szempontjából a GM204 nem változott a GM107-hez képest, így az architektúra továbbra is a 2 MB kapacitású, megosztott L2 gyorsítótárat tartalmaz, amit mindegyik streaming multiprocesszor elérhet, és a CUDA magok írhatnak is bele. Ennek egy része most is a mozaikos optimalizálást segíti, amolyan lapkán belüli dedikált memóriaként.
Memóriavezérlő tekintetében az NVIDIA továbbra is maradt a crossbarnál. A GM204 256 bites szélességű buszt használ, ami 64 bites csatornákra van szétosztva. Egy-egy csatornához egy ROP-blokk tartozik. Utóbbiból összesen 4 darab van, ami 64 blending és 256 Z mintavételező egységet eredményez.
Az új SMM teljes vázlata [+]
Az NVIDIA a dupla pontosságot a GM204 esetében nagyjából úgy oldja meg, ahogy ezt teszi a GK110-es lapkában. Jelen esetben minden compute blokkhoz egy-egy darab speciális CUDA mag tartozik. Technikai értelemben ezek az SMM részei, viszont két-két speciális CUDA magon osztozik két-két compute blokk. Ennek következtében egy SMM-ben összesen négy dupla pontosságra tervezett mag található, ami a teljes lapkára nézve 64 feldolgozót eredményez. Ez azt jelenti, hogy a dupla pontossággal elérhető elméleti számítási tempó a szimpla pontosság mellett felmutatott elméleti sebesség 32-ed része.
A GM204 újításai
A Maxwell architektúra túlságosan nem változott a setup területén, a GM204 esetében az NVIDIA továbbra is egy raszteres és egy úgynevezett PolyMorph részre vágja a hagyományos értelemben vett setup motort. Az előbbi egységből négy található a lapkában, azaz egy raszter motor négy darab streaming multiprocesszor ellátásáról gondoskodik. Ezt a felállást a vállalat Graphics Processing Clusternek (GPC) szokta nevezni, és ez most sincs másképp. A raszter motor órajelenként 16 pixelt képes feldolgozni, ami természetesen a teljes lapkára nézve 64 pixelt jelent, és ez tökéletesen egyensúlyban van a 64 blending egységgel is, azaz a friss lapka ezen a ponton kiegyensúlyozott. Mindemellett a GM204 órajelenként négy háromszöget képes feldolgozni.
A streaming multiprocesszorokban található PolyMorph motor továbbra is a geometriával kapcsolatos munkálatokat végzi, és a korábbi rendszerekhez képest semmit sem változott a működése. Mivel 16 darab SMM található a GM204-ben, így értelemszerűen ez ugyanennyi PolyMorph motort eredményez. Ugyanakkor ez a részegység továbbfejlődött, de a módosítások leginkább az extrém tesszellálás melletti teljesítményt növelik, így a játékokban jellemzően alkalmazott minőségi szinteken nem történt előrelépés.
Memóriakímélés itt is!
Manapság éppen aktuális beszédtéma a grafikus vezérlők által használt színtömörítési megoldások helyzete. Ha kiejtjük azt, hogy Delta Color Compression, akkor valószínűleg mindenkinek a Tonga cGPU új technikája jut eszébe. De ahogy korábbi cikkünkben írtuk, minden gyártó minden új hardvere használ valamilyen színtömörítési megoldást a memória kímélésére, ezek között viszont van hatékonyságbeli eltérés. Ebbe a körbe természetesen beletartozik az NVIDIA is a nem meglepő módon Delta Color Compression névre keresztelt technikájával. Ez is veszteségmentes tömörítés, ami két szín közötti eltérésre épül, de azt ki kell emelni, hogy a megegyező elnevezés ellenére a használt algoritmus eltérő, ami nagyrészt a tömörítés hatékonyságában érhető tetten.
Óhatatlanul felmerülhet a kérdés, hogy ha efféle Delta Color Compression megoldásokat már korábban is használtak a hardverek, akkor miért csak most beszélnek róla a gyártók? Ennek igazából egyszerű a magyarázata. Veszteségmentes színtömörítést implementálni viszonylag egyszerű, de jól működő megoldást fejleszteni már nagyon nehéz. Amíg ezek a technikák nagyjából 5-10%-os megtakarítást értek el a memóriahasználaton, addig kétségtelenül hasznosak voltak, de nem volt kiugró a jelentőségük. Az ARM ugyanakkor bőszen reklámozta AFBC technikáját, mert az 20-25%-kal hatékonyabban használta a memóriát, ami már elég jó eredménynek számított, illetve az AMD is azért kezdte hangsúlyozni új Delta Color Compression technikáját, mert az 40-50%-kal hatékonyabban használja a memóriát, ami szintén jelentős előrelépés.

A rózsaszín kijelölés jelenti a tömöríthető információkat egy képkockán
Az NVIDIA sem maradt adós ezzel, így saját Delta Color Compression fejlesztésük a GM204-es GPU-ban 17-29%-kal hatékonyabb memóriahasználatot nyújt, és ez is egy komoly fejlesztés. Azt is fontos hangsúlyozni, hogy a színtömörítési megoldások hatékonyságának mérésére nincs egzakt tesztprogram. Minden érintett cég a saját, belső tesztjei alapján adja meg a százalékokat, és ezek a tesztek eltérnek, vagyis az adatok direkten nem összehasonlíthatók. A hangsúly viszont a javuláson van, ebből a szempontból ugyanis az új megoldások kétségtelenül fejlettebbek az elődöknél.
A titkos(ított) tudás
A GM204 egyik sarkalatos pontja a hardver tudása. Bár a GPU a Maxwell architektúrára épül, de annak egy továbbfejlesztett verziójára, tehát többet tud, mint a GM107-es opció vagy éppen a Kepler sorozatú megoldások. Az NVIDIA azonban ennél tovább még nem megy, így a GM204 tudása szó szerint titkos. A vállalat hivatalosan annyit közöl, hogy csak a DirectX 12 véglegesítésénél, vagyis nagyjából egy év múlva fogják megmondani, hogy a GM204 pontosan mit támogat a Microsoft új API-jából, illetve mit nem. Az NVIDIA szerint ennek az az oka, hogy még nincs véglegesítve az API specifikációja, és rengeteg opcionális funkció van terítéken, amelyek beépítéséről, vagy éppen a már beépített újítások kivágásról még ma is komoly tárgyalások folynak. Nyilván mindenki a saját érdekeit nézi, miközben a Microsoft a legjobb funkcionalitást akarja letenni az asztalra, így az ötletek kidolgozásra kerülnek, de arról igen sokáig vitáznak az érintettek, hogy ezeket érdemes-e beépíteni, akár kötelező vagy esetleg opcionális formában.
Bár ez korábban nem szokott gondot okozni, hiszen az igen terjedelmes, architektúrákra vonatkozó dokumentációkból nagyon sok információt ki lehet nyerni, de az NVIDIA az Intellel és az AMD-vel ellentétben nem dokumentálja hardvereit. Bár annyiban védhető az NVIDIA álláspontja, hogy a felhasználóknak erről nem kell tudniuk, ráadásul a vállalat szerint a GeForce Experience program egy gombnyomással elvégez minden beállítást a felhasználó helyett, ugyanakkor az architektúrák dokumentációja így is nagyon hasznos lenne, mert alapvetően rámutathatna arra, hogyan működik egy rendszer. A publikus dokumentációkban többek között részletezve van az erőforrás-kezelés működése, amit egyszerűen rá lehet illeszteni az adott API leírására, így kideríthetők az egyes puffer típusokra vonatkozó adatok, illetve az egyes műveleteknél támogatott formátumok. Az NVIDIA esetében az említett adatokat a dokumentációk hiányában csak megtippelni lehet, ennek megfelelően nem tudjuk részletesen elemezni, és ezzel továbbadni olvasóinknak az adott architektúra pontos tudását.
Egyedül az NVIDIA által elmondottakra támaszkodhatunk, és a vállalat annyit el is árult, hogy az új lapka támogatni fogja a már elérhető és az érkező GameWorks effekteket. Ezen a ponton persze akkor lepődtünk volna meg, ha ez nem így lenne. A tesztkártyán végzett diagnosztika alapján le lehet írni, hogy az OpenGL 4.5, az OpenCL 1.1, a legújabb CUDA és a C++ AMP kezelése megoldott. A DirectX 11.2 esetében is elérhető már a D3D_FEATURE_LEVEL_11_1 szint támogatása, ami a korábbi hardverekből hiányzott, de a compute effektek térnyerésével nagyon fontos lesz, hogy ne csak 8, hanem minimum 64 UAV-t (Unordered Access View) kezeljen a hardver a futószalag összes programozható lépcsőjén. Mindemellett az említett szint többi újítása is hasznos. A Tiled Resources funkció esetében a támogatás természetesen adott, ráadásul már a TIER_2.
Annyit azért megjegyzünk, hogy a DirectX 12 bekötési modellje tartalmaz egy TIER_2 szintet, ami jelenleg egyetlen hardverre sem illik rá, tehát elvi alapokon abszolút logikátlan volt megalkotni. Ugyanakkor erős a gyanúnk, hogy a GM204 ezt a szintet támogatja. Ezt arra alapozzuk, hogy valamiért a TIER_2 szint megszületett, tehát ha a ma ismert hardverek közül egyik sem illeszthető rá, akkor valószínű, hogy a jövőben érkezik (vagy akár meg is érkezett) egy olyan lapka, amely ezt fogja használni. Mindemellett az NVIDIA Kepler és a GM107-ben alkalmazott Maxwell architektúra a 64 UAV-n kívül minden más követelményt teljesített. Például az SRV-k és a mintavételezők száma shader lépcsőnként 220-on, ami átszámítva 1 048 576. Feltételezhető, hogy ettől az NVIDIA a GM204 esetében sem tért el, hiszen a felújított Maxwell architektúra az előd alapjaira építkezik. Ezek után ugyan nem állíthatjuk biztosra, de minden jel arra utal, hogy a GM204 tudása megegyezik a DirectX 12 bekötési modelljének TIER_2 szintjével.
A GM204 extrái
Az előbbi oldalt kiegészítve a GM204-ben van pár olyan érdekes képesség, amelyet érdemes szemügyre venni. Ezeket ömlesztve tálaljuk, de persze a magyarázat nem marad el! Az NVIDIA leginkább az FMAA-t (multi-frame sampled anti-aliasing) emelte ki, mint olyan újdonságot, amelyet csak az új hardver támogat. Ez tulajdonképpen egyfajta temporális MSAA. A technika működéséről részletes leírást adtunk a fenti linkben, de a temporális tényező fontos, mivel az MSAA alkalmazása során a mintavételi pontok minden egyes képkocka minden egyes pixeljén pontosan ugyanott helyezkednek el.
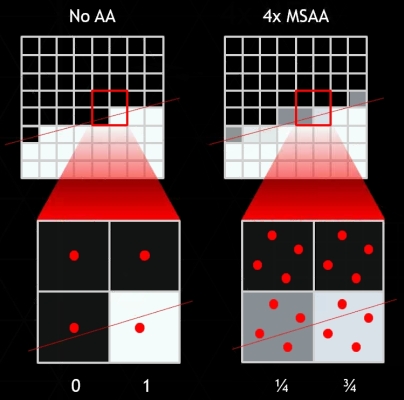
Általános az a nézet, hogy a négymintás MSAA ad úgymond elfogadható eredményt, mivel a négy darab mintavételi pont nagyrészt lefedik az adott pixelt. Ez jól látható a fenti képen is. A két darab mintavételi pont már nem olyan hatékony, mert a négymintás opcióhoz képest a pixeleken belüli legfelső és legalsó pontot lehet használni. Az MFAA tulajdonképpen egy olyan kétmintás MSAA megoldás, ami az egyes szomszédos pixeleken máshol végez mintavételezést, de nagyon fontos, hogy az egymás után következő képkockák esetében ugyanannak a pixelnek a mintavételezése módosul. Innen a temporális jelző és az alábbi kép jól szemlélteti a működést.
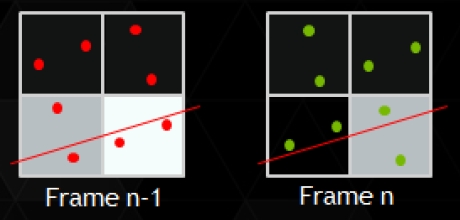
Az MFAA előnye, hogy a kétmintás MSAA teljesítményigényével rendelkezik, de annál jobb munkát végez, noha képminősége nem éri el a négymintás MSAA-t – de nem is ez volt a cél. Hátránya, hogy temporálisan nem stabil, ami azt jelenti, hogy ha a kamera nem mozdul, akkor minden egymás után következő képkocka eredménye valamekkora mértékben eltér.
Az MFAA a GM204-es GPU-ra épülő VGA-kon aktiválható a driveren belül. Mivel ez a technika az MSAA-hoz kapcsolódik, így csak olyan játékban működik, amely az MSAA-t teljes mértékben támogatja.
Az NVIDIA az élsimítás mellett kiemelte a VXGI effektet, ami a voxel global illumination rövidítése. A globális illumináció a mai játékokban általánosan alkalmazott megoldás, de a ma jellemzően használt implementációk nem adnak elég jó eredmény – főleg a legtöbb videojáték-motorban használt Enlighten technológia, amely tulajdonképpen egy hamis hatást kelt, noha kétségtelen, hogy számításigénye elenyésző.
Ugyanakkor a modernebb motorokban megtalálható light propagation volumes és virtual point lights egész korrekt működést kínál jó teljesítmény mellett, de az igazán korszerű koncepció a voxel cone tracing. Utóbbi régóta létezik, de a PC-s alkalmazására tett kísérletek rendre kudarcot vallottak. Egyedül a Sony jutott el a tényleges használatáig, de ezt is csak a PlayStation 4-en oldották meg. Mindenesetre a The Tomorrow Children egész jó alapot ad arra, hogy a rendszer működését megérthessük, hiszen az alábbi cikkünkben beszámoltunk a technikáról, illetve egy videóban is megtekinthető a hatása.
Az NVIDIA most kidolgozta a saját effektjét, és ez nem meglepő módon azokra a problémákra reagál, amelyek ellehetetlenítették a voxel cone tracing PC-s használatát. A legnagyobb probléma az SVO, azaz sparse voxel octree adatstruktúra, ami nagyon sok memóriát igényel, illetve rendkívül rosszul kezelhető és skálázható egy grafikus vezérlőn belül. Nem véletlen egyébként, hogy a The Tomorrow Children sem ezt használja, hanem inkább kaszkád 3D-s textúrázást implementál PRT technikán keresztül.
Az NVIDIA is jól látta, hogy a gyorsítóstruktúra a kulcsa az egésznek, így kidolgoztak egy új megoldást, ami a jelenet voxelizálását gyorsítja fel. Utóbbival az a gond, hogy a megfelelő eredmény érdekében több nézőpontból kell elvégezni, ami egyszerű megközelítéssel azt is jelenti, hogy ugyanannak a jelenetnek a geometriáját többször kell kirajzolni. Manapság azonban a geometry shader használatával ez megúszható, de sok hardveren ez sem gyors megoldás, hiszen nem mindegyik architektúra van kigyúrva a komolyabb geometriai manipulációkra.



A VXGI az Unreal Engine 4-ben [+]
A GM204 egy harmadik megoldást kínál, amely lényegében egy bitmaszkot eredményez a vertex shaderek kimenetein, így az adott háromszög szimplán lemásolható az összes nézőpontnak megfelelően. Ennek használatával anélkül megoldható a voxelizálás, hogy többször kellene kirajzolni a geometriát vagy esetleg geometry shadert kellene használni. Ezt a vállalat viewport multicast néven emlegeti. Az elvi működés tekintetében a koncepció nagyon hasonlít az AMD két és fél éve bemutatott viewport indexing technikához.
A voxel cone tracing esetében szintén fontos tényező a konzervatív raszterizáció, ami arra szolgál, hogy a raszterizálás a mostani kötött formánál jobb irányíthatóságot kapjon. Mint ismeretes, a normál raszterizálás esetében a háromszög akkor fedi az adott pixelt, ha a mintavételi pont fedi azt. A konzervatív raszterizáció esetében lehetőség van arra, hogy a háromszög akkor is fedje a pixelt, ha annak csak egy nagyon apró része nyúlik bele a pixelbe. Ez a voxelizálás során is lényeges, mert a voxelizált tartalomnál az eredeti háromszög adatait jól kell visszaadnia. Természetesen a konzervatív raszterizáció megoldható pixel shaderrel is, de a hardveres támogatáshoz képest lassabban.
A voxel cone tracinghez a többi számítás már nem túl megterhelő, ezeket szimplán, fixfunkciós hardverek nélkül is meg lehet oldani. A GM204 az NVIDIA mérései szerint háromszorosára gyorsult az voxelizálásra vonatkozó fázisban, amikor a fixfunkciós hardver és a konzervatív raszterizálás aktív volt.
A VXGI effekt a GameWorks csomag része lesz. A Maxwell fentebb említett, viewport multicasthoz szükséges fixfunkciós motorja más formában nem lesz hozzáférhető a fejlesztők számára, de az NVIDIA az esetleges jó ötletekre igény esetén készíthet effekteket. Annyi kiderül még, hogy az Unreal Engine 4-be beépítik a VXGI effektet a GameWorks csomaggal együtt, de más videojáték-motorra vonatkozó támogatásról nem esett szó.
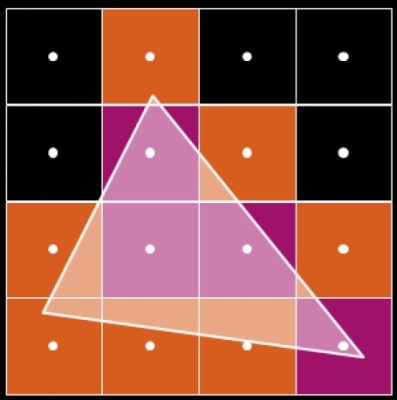
A háromszög lefedése normál (lila) és kozervatív (narancssárga) raszterizálással
A konzervatív raszterizálás egyébként a DirectX 12 API-nak is a része lesz, illetve a GM204 másik újítása a raster order view, ami az Intel PixelSync technológiájának konkrét másolata, és szintén része a DirectX 12-nek.
A konzervatív raszterizálás és a raster order view esetében az NVIDIA a DirectX 12-re vár, de lesz egy alternatív elérhetőség is a DirectX 11 új kiegészítésével, amely később érkezik meg.
A raster order view esetében fontos kiemelni, hogy bármennyire is a PixelSync másolata, az utóbbi technológiához tartozó kiterjesztésekkel készült kódok nem futnak rajta, tehát ezeket újra kell majd írni.
A multimédia és a szoftverek
A GM204 nehezebben emészthető részei után a könnyedebb adatok következnek. Multimédiás szempontból megújul az NVENC nevű hardveres blokk, amit a Kepler vezetett be. Az új rendszer mostantól a H.264-es videók transzkódolása mellett a HEVC-vel is megbirkózik.
A GM204-re épülő GeForce GTX 970 és 980 esetében a kijelzőkezelés alapjaiban nem sokat változik, továbbra is maximum négy megjelenítő köthető rájuk, de az új VGA-k a szokásos dual-link DVI mellett három DisplayPort 1.2-es aljzatot is kínálnak, illetve nagy újítás a HDMI 2.0-s interfész támogatása.
A multimédiás rész ezzel le is zárható, de van egy érdekes szoftveres újítás is, ami a Dynamic Super Resolution névre hallgat. Itt a szoftverest mindenképp ki kell hangsúlyozni, mert bár most még csak a GM204-en működik, de később általánosan engedélyezve lesz.

Tulajdonképpen egy túlmintavételezésről van szó, amely nem ismeretlen dolog, és nem egy szoftver van, amellyel megoldható ma is a használata, de az NVIDIA a driverbe egy egyszerűbb koncepciót épített, amelyet csak be kell kapcsolni, és működik bármiféle segédprogram nélkül. A koncepcióval el lehet érni, hogy egy Full HD-s kijelzőre a játék akár 4K-s felbontásban legyen leképezve, majd az extra adatokkal rendelkező képkockát a driver leskálázza Full HD-re. Ennek hatása hasonló az SSAA nevű élsimítási eljáráshoz, amely az NVIDIA meghajtóiban nem lelhető fel, így a vállalat helyette a Dynamic Super Resolutiont biztosította.
VR Direct, a virtuális valósághoz
Szoftverek szempontjából az NVIDIA a VR Direct nevű csomagot is készíti, amely publikus formában még nem érhető el, de nyilván nem kell ecsetelni, hogy a következő évben megkezdődik a virtuális valóság forradalma. Ehhez azonban nem elég pusztán a megfelelő hardvereket biztosítani, mert a ma használt, szabványos grafikus API-k, mint például a DirectX 11 által kínál működés egyszerűen túl nagy késleltetést jelent a virtuális valóság jó működéséhez.

A grafikus meghajtó optimalizálása [+]
Ez nem újdonság, hiszen a virtuális valósággal foglalkozó cégek már korábban is felhívták arra a problémára a figyelmet, hogy túl nagy a késleltetés szoftverben. Bár ennek egy része nem üthető ki, de a grafikus meghajtó és a DirectX 11 legalább 10 ezredmásodpercet vesz ki a késleltetésből, amit egyébként el lehet tüntetni, ha a grafikus meghajtó úgy van beállítva, hogy maximum egy képkockára gyűjtse előre össze az API parancsokat. Ez bizonyos esetekben változatlan sebességet jelent, de lassulás is előfordulhat a képszámítás során.
Az NVIDIA szerint az MFAA-val szintén lehet javítani a sebességet, ami természetesen csökkenti a késleltetést. Ez logikus, hiszen a hardver kevesebbet számol, persze rosszabb is lesz a képminőség a négymintás MSAA-hoz képest.
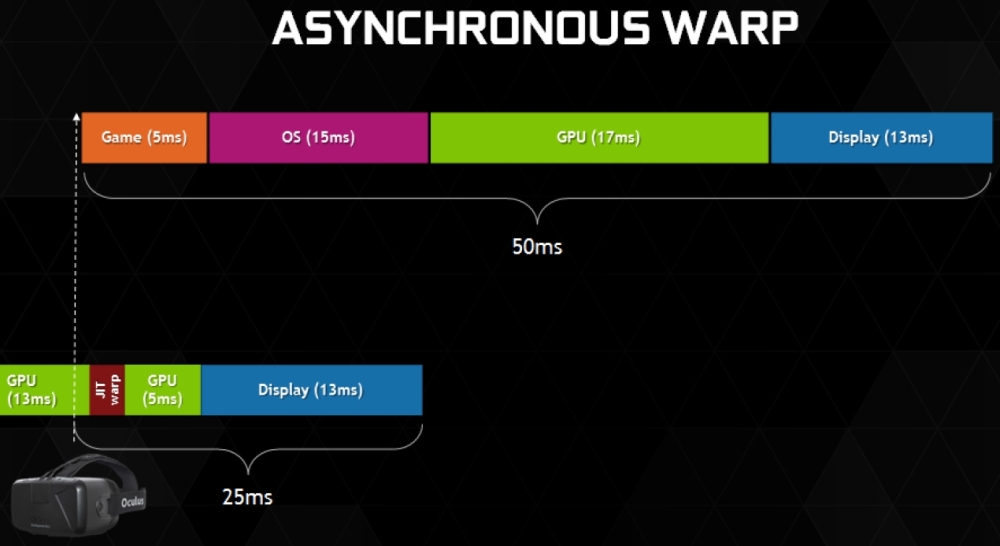
Asynchronous warp [+]
A legérdekesebb koncepció a késleltetés további csökkentésére az asynchronous warp. Ez már egy kevésbé triviális megoldás, mivel arról van szó, hogy a rendszer megpróbálja elkerülni az egyes képkockák teljes újraszámolását. Ez jelen pillanatban még egy elvileg működőképes koncepció, de vannak igen erős buktatói is. Alapvetően itt a grafikus meghajtó eltérő módon vezérli a hardvert, így az adott képkocka számításával kapcsolatban minden részinformációt megpróbál megtartani, ezután a következő képkockát nem az új jelenetből számolja, hanem az előző jelenetre vonatkozó, korábban elmentett adatokat hasznosítja újra, csak éppen a bemeneti adatként kapott fejmozgást figyelembe véve más kameranézettel.
Ezzel a késleltetés drámai mértékben lecsökken, viszont nincs új jelenet felépítve, tehát a tartalom szintjén nem történik változás. Ugyanakkor a jelenetszámítás sem pihen, ez a háttérben megtörténik, és ekkor az új adatok alapján keletkezik egy ténylegesen új adatokra épülő képkocka. Majd ez a folyamat kezdődik elölről. Bár ez erős trükközés, vagyis két jelenet számítása között hamis adatokra épülő képkocka keletkezik, de a folyamatosság megőrzése fontosabb az agynak, és a mai elavult grafikus API-kon ezt csak efféle trükkökkel lehet biztosítani.
A VR Direct egyébként megoldja az SLI problémáját is. A csomag tartalmaz egy alapvető technikát arra vonatkozóan, hogy a két GPU megléte esetén az egyik a bal, míg a másik a jobb szem számára szükséges képet számolja. Ennek a megoldásnak a támogatásához alapvető követelményeknek kell megfelelni a videojáték-motoron belül, hogy a grafikus meghajtó képes legyen két GPU-ra leosztani a munkát.
Az SLI támogatása egyébként eleve kiemelten fontos a virtuális valóság szempontjából, mivel a számításigény igen nagy lesz, tehát jórészt két GPU-val lehet majd elérni értékelhető sebességet. Erre a fejlesztőknek akkor is figyelniük kell, ha a DirectX 11 nem biztosít direkt kontrollt a több GPU-s konfigurációk működtetésére. A koncepció nagyjából ugyanaz, mint a normál SLI esetén: kontroll lehetősége nélkül magát a szoftvert kell addig optimalizálni, amíg a grafikus meghajtóba épített SLI mód hatékonyan működik.
Az NVIDIA GeForce GTX 980
Szerkesztőségünk az NVIDIA GeForce GTX 980 referencia kiadását kapta meg tesztre, így a tartozékokról és egyebekről nem tudunk szót ejteni, hiszen a dobozban a kártyán kívül más kiegészítő nem lapult.

[+]
Akik korábban láttak már GTX Titan, GTX 780 Ti vagy GTX 780 jelzésű vezérlőt a GeForce családból, nos azok számára csak kevés újdonságot tudunk mondani a dizájnról, a hűtésről és a felépítésről, ugyanis a GTX 980 is szakasztott úgy néz ki, mint GTX 780 Ti. Azért ezt a verziót emelnénk ki a fent említett hármasból, mert apróbb különbségek akadnak, mint például a GPU egészséges hőháztartásáért felelős hűtőborda, ami ezúttal is feketében pompázik, és továbbra is látszódik az ablakocska alatt.


[+]
A hűtés részeként funkcionáló burkolat nem csak fémes hatású, hanem nagy része valóban fém, és ez igaz a kártyát teljesen takaró hátlapra is, de még a ventilátor közepére is applikáltak e nemes anyagból; ami pedig csavarnak néz ki, az nem dísz, hanem valóban csavar. A többi testvérhez hasonlóan tehát a GTX 980 is minőségi hatást kelt, és még azoknak is kedveznek, akik kedvelik a bling-bling faktort, hiszen a zölden világító GeForce GTX felirat most is megtalálható a kártya oldalán, de igény szerint az innen jövő fényártól meg is szabadulhatunk.


[+]
Visszatérve a csavarokhoz, a kártya szétszedése nem sétagalopp, rengeteg kötőelemet használt a gyártó, amitől megszabadulni nem két perc, de ezután viszonylag könnyen atomjaira robbantható a hűtés egy alapos portalanításhoz, újrapasztázáshoz. Természetesen a függőleges alumíniumlamellák alatt most is egy méretes réztalp kapott helyet, amibe három hővezető csövet integráltak a jobb hatások érdekében. Emellett a hátoldalon egy kis lecsavarozható ablakot találunk, amivel tovább növelhető a kártya körüli légáramlat, miközben a hátlap előnyeiről sem kell lemondani.


[+]
A VGA-t lecsupaszítva és a hővezető pasztát letakarítva figyelmünk elsőként most is a GPU-ra terelődött.

[+]
A 28 nm-es gyártástechnológián készülő GM204-es kódjelű lapka területe 398 mm², ami kisebb, mint a 780-asokban alkalmazott 551 mm² GK110 vagy a 438 mm²-es AMD Hawaii, viszont nagyobb 294 mm²-es GK104-nél. A kisebb méret természetesen mindig jól jön, ha a fogyasztásról vagy a gyártási költségekről esik szó. A chip alapórajele 1126 MHz, ami GPU Boost segítségével 1216 MHz-ig skálázódhat.

A 256 bites memóriabuszon 4 GB-nyi GDDR5 memória kapcsolódik, aminek órajele 1750 MHz, azaz effektív 7 GHz, így az elérhető sávszélesség 224 GB/s. A K4G41325FC-HC28 típusú, 1,5 voltos feszültségen üzemelő, 4 gigabites chipeket a Samsung szállítja, ezekből nyolc darab található a GPU köré csoportosulva.

[+]
A referencia vezérlő 4+1 tápellátást kapott, de ezúttal OnSemi FET-ekkel, így ez a rész eltér az elődöktől; ugyanettől a gyártótól származik a PWM-vezérlő is, az NCP81174. Szemmel láthatóan van még tartalék a kártyában további fázisok alkalmazásának érdekében, amit minden bizonnyal a tuningra gyúró partnerek ki is fognak használni.

[+]
A vezérlő érdekes fele még a hátlapi panel, amire egészen újfajta formavilágú szellőzőket vágtak. De nem ez az, ami igazán érdekes, hanem a csatlakozók, amelyeket alaposan megvariáltak a GTX 780-hoz képest. DVI-ból (ami jelen esetben dual-link DVI-I típust jelent) csupán egyetlen darab került a kártyára, a többi helyet a DisplayPort 1.2 és HDMI 2.0 oltárán áldozták fel: előbbiből három, utóbbiból egy darabot kapunk. Ami a többmonitoros felhasználást illeti, összesen négy kijelző (amelyek lehetnek akár 4K felbontásúak is MST módban) egyidejű meghajtására van lehetőség, a legnagyobb felbontás pedig 5120x3200 képpontnál tetőzik 60 hertzes frissítés mellett, hála az új HDMI-szabványnak.
Tesztkonfig, fogyasztás, specifikációk
| Videokártyák | NVIDIA GeForce GTX 980 4096 MB (GeForce driver 344.07) NVIDIA GeForce GTX 780 Ti 3072 MB (GeForce driver 344.07) NVIDIA GeForce GTX 780 3072 MB (GeForce driver 344.07) AMD Radeon R9 290X 4096 MB (Catalyst 14.7 RC3 beta) AMD Radeon R9 290 4096 MB (Catalyst 14.7 RC3 beta) |
|---|---|
| Processzor | Core i7-3770K (3,60 GHz) – túlhajtva 4,3 GHz-en EIST / C1E / C-state kikapcsolva; Turbo Boost kikapcsolva |
| Alaplap | MSI Z77 MPOWER (BIOS: V17.5) – Intel Z77 chipset AHCI driver: Intel 11.5.0.1207 |
| Memória |
G.Skill RipjawsX 16 GB (4 x 4 GB) DDR3-1866 F3-14900CL9Q-16GBXL |
| Háttértárak | Intel SSD 320 160 GB SSDSA2CW160G310 (SATA 3 Gbps) Seagate Barracuda 7200.12 500 GB (SATA, 7200 rpm, 16 MB cache) |
| Tápegység | Seasonic Platinum Fanless 520 – 520 watt |
| Monitor | Acer B326HUL (30") |
| Operációs rendszer | Windows 8.1 64 bit |
Az új GeForce legfőbb ellenfeleit a kategóriának megfelelően válogattuk össze, így a Radeon R9 290X és 290, míg házon belülről a GeForce GTX 780 Ti és a GTX 780 állított neki ellenfelet, tehát ezek teljesítményére voltunk kíváncsiak.
Csúcskategóriás kártyákról lévén szó most is úgy döntöttünk, hogy Intel Core i7-3770K processzorunk órajelét egy egészséges tuning keretein belül 4,3 GHz-re emeljük, ami mellé a 16 GB G.Skill márkájú memóriánk üzemi órajelét 1866 MHz-re srófoltuk fel. Ami a meghajtóprogramokat illeti, a Radeon kártyákat az AMD oldaláról letölthető legfrissebb 14.7 RC3 beta driverrel teszteltük, míg az NVIDIA kártyájához a cégtől kapott 344.07-es drivert telepítettük fel.
A játékokat a tesztben szereplő kártyákban lapuló számítási teljesítmény miatt 1920x1080-as (Full HD) és 2560x1440-es (WQHD) felbontásban teszteltük. A képminőséget játéktól függetlenül maximálisra állítottuk. A meghajtóprogramban mindent alapértelmezett beállításokon hagytunk, az anizotropikus szűrést, illetve az élsimítást pedig mindig az adott játékban aktiváltuk.
Játékok
- Battlefield 4 (DirectX 11.1) – motor: Frostbite 3 / műfaj: FPS
- Batman: Arkham Origins (DirectX 11) – motor: Unreal Engine 3 / műfaj: TPS
- Company of Heroes 2 (DirectX 11) – motor: Essence Engine 3.0 / műfaj: stratégia
- Crysis 3 (DirectX 11) – motor: CryEngine 3 / műfaj: FPS
- GRID 2 (DirectX 11) – motor: EGO Engine 3.0 / műfaj: autóverseny
- Hitman: Absolution (DirectX 11) – motor: Glacier 2 / műfaj: TPS
- Metro: Last Light (DirectX 11) – motor: 4A Engine / műfaj: FPS
- Thief (DirectX 11) – motor: Unreal Engine 3 / műfaj: FPS/akció
- Tomb Raider (DirectX 11) – motor: Crystal Engine / műfaj: TPS/kaland
A mérésekhez használt játékok palettáját nemrégiben megváltoztattuk, így ezt az új rendszert használjuk most is. Továbbra is fontosnak tartjuk, hogy viszonylag naprakész és/vagy népszerű címeket alkalmazzunk, ezért az elődöt a Battlefield 4 váltotta, a Bioshock helyét a Batman: Arkham Origins vette át, míg a DiRT Showdown-t a GRID 2-re cseréltük le, illetve a Metróból is az újabb rész került a pakkba. Végül, de nem utolsósorban pedig a Sleeping Dogs helyére a legújabb Thief epizódot pakoltuk be.
A könnyebb és pontosabb mérés, valamint összevetés érdekében a Thiefnél a beépített benchmark toolt használtuk, ahogyan a Batman, Metro, GRID 2, Hitman: Absolution, Company of Heroes 2, valamint a Tomb Raider esetében is. A Battlefield 4-nél az első küldetés víz alatti perceit mértük le FRAPS-szel, míg a Crysis 3-nál a Canyon nevű pálya elején található demó jellegű részt mértük.
A grafikonokat a minimum képkockák értékei alapján rendeztük csökkenő sorrendbe, ahol a mindenkori nagyobbik felbontás az elsődleges szempont.
A fogyasztást konnektorba dugható, digitális VOLTCRAFT Energy Logger 4000 készülékkel vizsgáltuk. A grafikonon az egyes videokártyákkal kiegészített rendszerek fogyasztása látható alaplappal, processzorral, táppal és a többi alkatrésszel együtt, de természetesen a monitor nélkül. A méréseket a Metro 2033 benchmarkja alatt végeztük, mely 1920x1200-as felbontásban került lefuttatásra. Játékkal terhelt mérés közben meglehetősen sűrűn és gyorsan ingadozik a fogyasztás, ezért ide egy olyan értéket próbáltunk regisztrálni, ami a legtöbbször villant fel az eszköz kijelzőjén, vagyis nem a csúcsértéket jegyeztük fel. Az újabb játékok bekerülése mellett még egy kisebb változás, hogy mostantól a hardveres DXVA dekódolás alatti fogyasztást is regisztráljuk, és az így összegyűjtött eredmények bekerülnek a szokásos grafikonba.
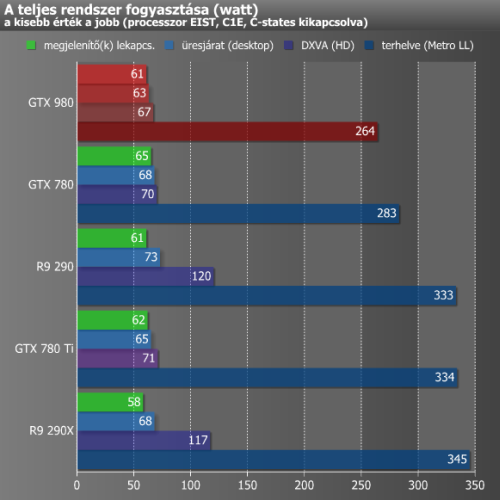
Kétségkívül a Maxwell egyik nagy előnye az energiatakarékosság, de erre számítani lehetett a megadott 165 wattos TDP alapján, és a két darab 6-tűs PCI Express tápcsatlakozó is előrevetítette, hogy viszonylag takarékos megoldásra számíthatunk. Méréseink is ezt igazolják, a teljes konfiguráció teljesítményfelvétele terhelés alatt a GTX 780-nal szerelt masina alatt maradt jócskán, valamint üresjáratban és videolejátszás során is a konkurens megoldások közelében vagy alatta produkált.
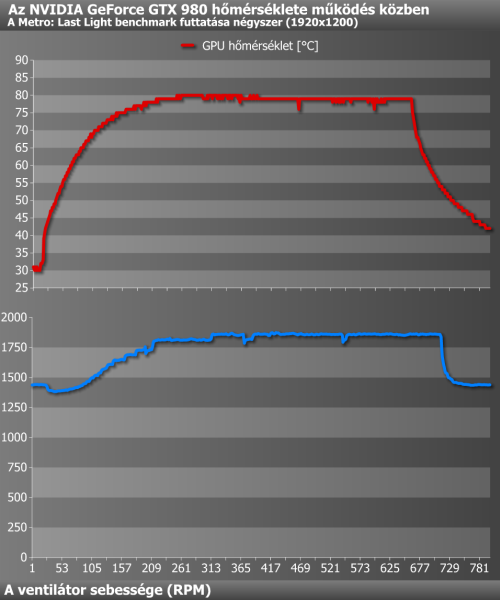
Terhelés nélkül a ventilátor a vártnál magasabb fordulatszámon pörgött, de erről csak a GPU-Z méréseiből értesültünk, mert a ventilátor ennek ellenére szinte zajtalanul teszi a dolgát, így a nagyjából 20 °C hőmérsékletű helyiségben a GPU hőmérséklete alig érte el a 30 °C-ot. Terhelésre a légkavaró nem reagál idegesen, azonnali felpörgéssel, hanem a hőmérséklet emelkedésével párhuzamosan emeli a fordulatszámot, de csak annyira, hogy a központi egység éppen ne érje el 80 °C-ot. Ehhez nagyjából 1800 körüli percenkénti fordulatra volt szüksége tesztalanyunknak, tehát kategóriájához mérten relatíve csendes marad működés közben is.
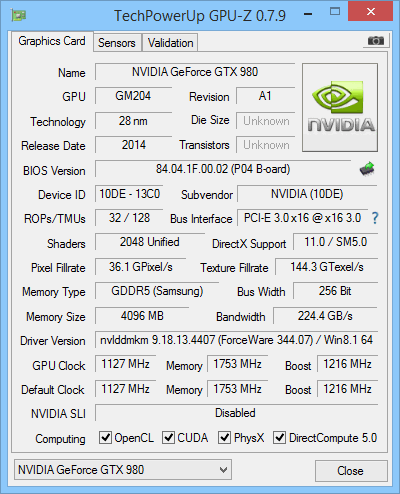
A túlhajtást ezúttal hanyagoltuk, de nem végleg, a tuningolt verziók érkezésével majd erre a képességre is fényt derítünk. Az alábbi táblázatban viszont összefoglaltuk a GeForce GTX 980 és a mérésekhez használt konkurens vezérlők tudását:
| VGA megnevezése | Radeon R9 290X |
Radeon R9 290 |
GeForce GTX 980 | GeForce GTX 780 Ti |
GeForce GTX 780 |
|---|---|---|---|---|---|
| Kódnév | Hawaii | GM204 | GK110 | ||
| Gyártástechnológia | 28 nm (TSMC) | ||||
| Mikroarchitektúra | GCN | Maxwell | Kepler | ||
| Tranzisztorok száma | 6,2 milliárd | 5,2 milliárd | 7,1 milliárd | ||
| GPU-lapka mérete | 438 mm2 | 398 mm2 | 551 mm2 | ||
| GPU/turbo max. órajele | 1000 MHz | 947 MHz | 1126/1216 MHz | 876/926 MHz | 863/902 MHz |
| GPU/shader órajele üresjáratban | 300 MHz | 324 MHz | |||
| Shader processzorok típusa | multiprecíziós vektor | stream | |||
| Számolóegységek száma | 2816 | 2560 | 2048 | 2688 | 2304 |
| Textúrázók száma | 176 textúracímző és -szűrő |
160 textúracímző és -szűrő |
128 textúracímző és -szűrő |
224 textúracímző és -szűrő |
192 textúracímző és -szűrő |
| ROP egységek száma | 16 blokk (64) | 4 blokk (64) | 12 blokk (48) | ||
| Memória mérete | 4096 MB | 4096 MB | 3072 MB | ||
| Memóriavezérlő | 512 bites hubvezérelt | 256 bites crossbar | 384 bites crossbar | ||
| Memória órajele terhelve | 1250 MHz (GDDR5) | 1750 MHz (GDDR5) | 1750 MHz (GDDR5) | ||
| Üresjáratban | 150 MHz | 162 MHz | |||
| Max. memória-sávszélesség | 320 000 MB/s | 224 000 MB/s | 336 000 MB/s | ||
| Támogatott DirectX | 11.2 | 11 | |||
| Dedikált HD transzkódoló | VCE | NVENC | |||
| Videóanyagok lejátszásának hardveres támogatása | AVIVO HD (UVD 3.2) | Purevideo HD (VP4) | |||
| TDP | ~250 watt | ~165 watt | ~250 watt | ||
Hitman: Absolution, Grid 2, Company of Heroes 2
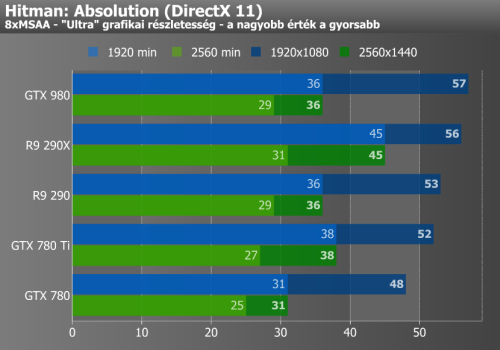
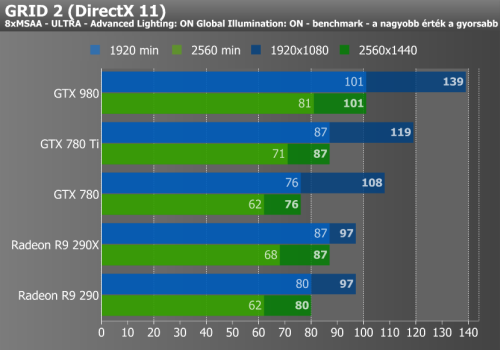
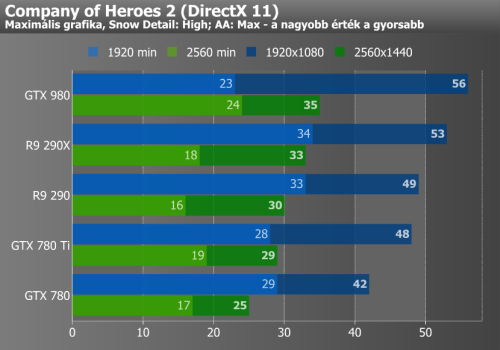
Az első három mérésről általánosságban elmondható, hogy a GTX 980 a favorit, bár nagy felbontásra kapcsolva a Company of Heroes 2-nél a Radon R9 290X-nek sikerül tartania a lépést, a Hitmannél pedig meg is előznie az NVIDIA üdvöskéjét. Grid 2-ben viszont a GTX 980 megint elhúz a mezőnytől.
Metro: Last Light, Crysis 3, Thief
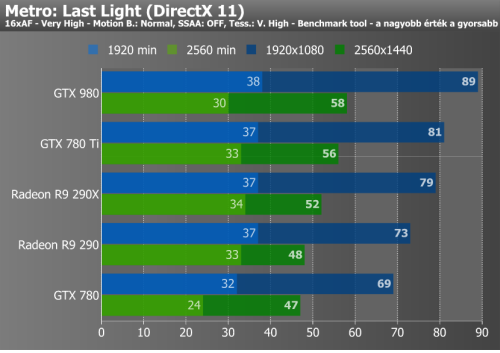
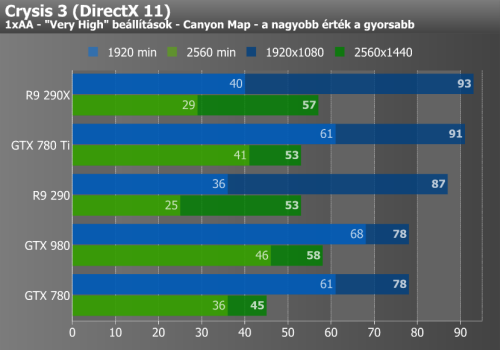

Full HD felbontásban az NVIDIA kártyája több helyen megszerzi az elsőséget, sőt nagy felbontásban sincs oka szégyenkezésre, bár a Metróban a minimum fps-ek több helyen a várt szint és a konkurensek alatt maradnak. Ahol egyértelműen nem termett babér 1920x1080 pixeles felbontásban a GTX 980-nak, az a Crysis 3, ahol az utolsó előtti helyen kullog, de fordul a kocka és az első helyre katapultál, amint WQHD-ba kapcsolunk.
Batman, Battlefield 4, Tomb Raider


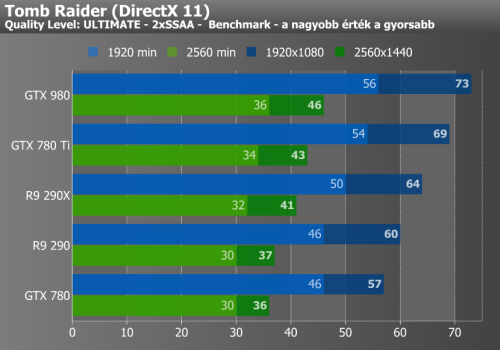
Az utolsó hármasfogatban megint az NVIDIA, vagyis a GTX 980 előnye rajzolódik ki. Egyedül Battlefield 4 alatt csökken az ereje a nagyobb felbontásban, így némi optimalizálás még ráfér a driverre.
ComputeMark, LuxMark
A tavalyi év során két általános számítási feladatokat tartalmazó benchmark is bekerült méréseink közé. Mivel félig-meddig szintetikus tesztekről van szó, így túl messzemenő következtetéseket szerintünk nem érdemes levonni ezek eredményeiből.
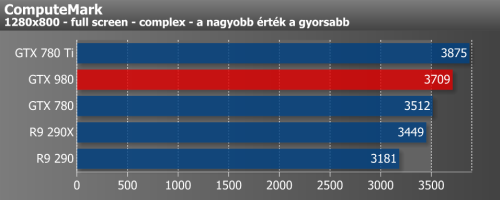
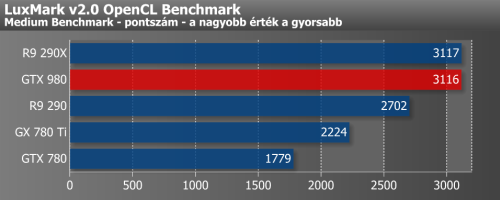
ComputeMark egyszerűbb DirectCompute shaderekkel operál, melyekkel főleg a játékok alatt lehet találkozni. Ezzel szemben a Luxmark az egyik legelterjedtebb benchmark a ray-tracing tesztelésére. A ComputeMark eddig is feküdt az NVIDIA korábbi GeForce kártyájának, a GTX 780 Ti-nek, és erre most a GTX 980 sem tudott kontrázni. Ellenben LuxMark alatt már korántsem volt fényes az NVIDIA korábbi teljesítménye, ami úgy tűnik, a Maxwellel változhat, hiszen a Radeon R9 290X-szel azonos szinten teljesített.
Összegzés
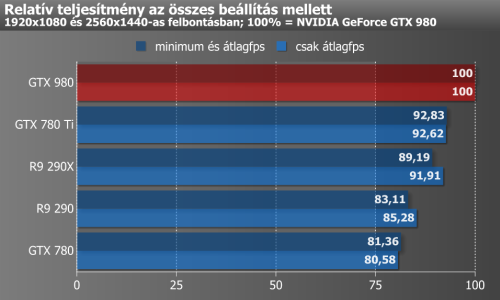
A zöldeknek a GeForce GTX 780 Ti-vel, noha csak nagyjából két százalék körüli előnnyel, de már korábban sikerült átvenniük a vezetést az egy GPU-val dolgozó kártyák között. Ez a különbség most sem változott számottevő mértékben, a korábbi tesztekhez viszonyított enyhe eltérés pedig betudható a meghajtóprogramok fejlődésének. Ám ezt az előnyt a GTX 980-nak sikerült felbontástól függően 8-11%-ra növelnie a konkurens AMD Radeon R9 290X-szel szemben, ami persze még mindig nem mondható tetemes előnynek, de biztosítja az NVIDIA elsőségét – legalábbis egy időre.
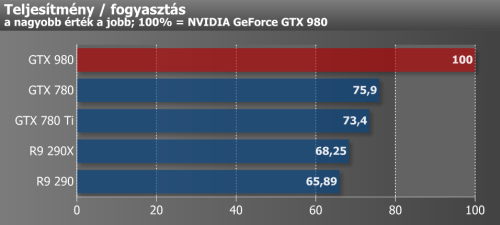
Amire viszont az NVIDIA joggal büszke lehet, az a Maxwellből kipréselt teljesítmény adott fogyasztás mellett, ahol messze-messze a legjobb teljesítményt nyújtotta a GTX 980, közel 25 százalékot verve a második helyezett GTX 780-ra. Korábbi tesztünkben ez a modell még alulmarad a GTX 780 Ti-vel szemben ugyanebben a mérkőzésben, ám tesztprogramjaink teljes lecserélése kedvezett a kisebbik Keplernek, így már meg tudta előzni a Ti változatot. Az AMD-vel összehasonlítva a különbség meghaladja a 30 százalékot, így egyértelműen elmondható, hogy az NVIDIA a hatékonyságot tekintve alapos munkát végzett.

[+]
A legfontosabb kérdés, hogy megéri-e az NVIDIA legújabb kártyáját, a GeForce GTX 980-at megvásárolni? Ha csak a teljesítményt nézzük, a válasz egyértelműen igen, hiszen a piac jelenleg leggyorsabb egy GPU-s vezérlőjét tették le az asztalra, ami árával és teljesítményével egyértelműen kiüti a nyeregből a hasonló áron kínált, de most már lassabb GTX 780 Ti-t. Emellett olyan érvek szólnak még mellette, mint a relatíve alacsony fogyasztás és halk hűtő, na és persze a HDMI 2.0-s kimenet, amelyeket a már felsorolt pozitívumokkal párosítva a GTX 980-at egyértelműen az ajánlott vételek közé repíti.
Házon belül tehát egyértelműen jó választás a GTX 980 mellett dönteni, de a másik sarokban ott van az AMD Radeon R9 290X, ami a GTX 980-hoz képest nem új fejlesztés, ám teljesítményben csupán 10 százalékkal marad el tőle, miközben az árcéduláján majd 40 000 forinttal kisebb összeg fityeg, amiért valószínűleg sokan bevállalják ezt a csekélynek mondható teljesítményveszteséget. Tény viszont, hogy szolgáltatását (és most gondolunk itt a HDMI 2.0-n kívül például a G-Sync-re is) és fogyasztását tekintve a Radeon elmarad a zöldek üdvöskéjétől, ami bizonyos eseteken a GTX 980 felé billentheti a virtuális mérleg nyelvét.

NVIDIA GeForce GTX 980 videokártya
Apró megjegyzés, hogy az NVIDIA a termék startjával párhuzamosan egy Game24 konferenciát rendez, amelyet a linkelt oldalon élőben lehet követni.
Daywalker és Abu85
A NVIDIA GeForce GTX 980 VGA-t az NVIDIA biztosította.


