Visszatérés a Fermihez
Az NVIDIA a tegnapi napon bemutatta a Tesla P100 jelzésű gyorsítót, amelyről az alábbi hírben írtunk, és ígéretet tettünk arra, hogy később elemezzük magát a lapkát is. Bár a vállalat már a nyitóelőadáskor közzé tett egy részletesebb leírást a fejlesztésről, de az elemzéshez mindenképpen meg akartuk várni az NVIDIA erre kihegyezett prezentációját, hogy jobb képet kapjunk arról, milyen technikai alapokra épül az újítás.

A GP100 [+]
A Pascal architektúra tulajdonképpen nem tekinthető alapvető reformnak, csupán az elődnek számító Maxwell architektúra és a Fermi örökségének egybegyúrásáról van szó. Ez viszont nagyon alapos, így nem csak apróbb kiegészítésekről beszélhetünk, hanem a rendszer alapvető működését befolyásoló módosítások történtek, amelyek az NVIDIA elmondása szerint a compute hatékonyság növelését célozzák meg. A GP100 kódnevű lapka esetében alapvető újdonság a 16 nm-es gyártástechnológia, így a 15,3 milliárd tranzisztorból felépülő, 610 mm²-es chipbe 60 darab streaming multiprocesszort sikerült beépíteni, amit az NVIDIA ezúttal szimplán SM-nek jelöl (bár bizonyos előadásokon az SMP tűnt fel), ami hivatalosan a Pascal streaming multiprocesszor rövidítése.
A streaming multiprocesszorok felépítése a második generációs Maxwell architektúrában ismert megoldáshoz képest jelentősen megváltozott. Ennek köszönhetően elmondható, hogy egy ilyen egységen belül már nem négy, hanem csak kettő nagyobb compute blokk került kialakításra, amelyek közös utasítás gyorsítótárat használnak. Mindegyik compute blokk rendelkezik egy utasítás pufferrel, ami nyilvánvalóan az utasítás gyorsítótárból szerzi be az aktuális munkához szükséges információkat. Az egész rendszer komplex ütemezést használ, amely a Kepler és a Maxwell architektúrával ellentétben már nagyrészt hardveres, így a szoftveres ütemezés mértéke jelentősen redukálva lett. A hardveres részért továbbra is GigaThread motor felel, ami jelentős átdolgozásra került a korábbi architektúrákhoz képest.
A változások nagyon egyszerűen értelmezhetők, mivel a streaming multiprocesszorokon belüli compute blokkok csökkentése, az ütemezés nagyrészt hardveressé tétele, ezen belül is a szoftveres ütemezés mértékének redukálása mind arra szolgál, hogy a lapka compute hatékonysága nőjön. Ebből a szempontból a Pascal visszatérés a Fermi koncepciójához. Utóbbinak nagyon egyszerű oka van, ugyanis az NVIDIA a Fermi után azért emelte ki folyamatosan a jó compute hatékonysághoz szükséges hardverelemeket, hogy csökkenjen a fogyasztás. A FinFET tranzisztorokkal azonban ez pusztán a gyártástechnológia oldaláról is hozható, így az amúgy eléggé fontos, jó compute hatékonyságot biztosító hardverelemek végre visszakerülhetnek, persze már megújult formában.
A compute blokkokra rátérve egy ilyen egységben két feladatirányító (dispatch) és egy warp ütemező található, amelyek 32 darab, úgynevezett CUDA magot etetnek, így az utasításszavak 2 darab, 16 utas feldolgozón hajtódnak végre párhuzamosan. Mindegyik CUDA mag rendelkezik egy IEEE754-2008-as szabványnak megfelelő, 32 bites lebegőpontos végrehajtóval, amelyek támogatják a MAD (Multiply-Add) és az FMA (Fused Multiply-Add) instrukciókat. Ráadásul ezek az új CUDA magok olyan 32 bites ALU-kat használnak, amelyek nem egy, hanem két darab 16 bites lebegőpontos operációt is képesek végrehajtani. Ez itt az a fő újítás, ami a gépi tanuláshoz szükséges, mivel így a felezett pontosságú tempó kétszerese lehet a szimpla pontosságú teljesítménynek. A compute blokkonon belül található még 8 darab speciális funkciókért felelő egység (SFU), amelyek a trigonometrikus és transzcendens utasítások mellett az interpoláció feladatát is elvégzik, továbbá a blokkok része még 16 darab dedikált FP64-es CUDA mag, amelyek nyilván a dupla pontosság végrehajtásáért felelnek.

Az új SM
A compute blokkokban fontos változás még a közös regiszterterület növekedése, aminek kapacitása már 128 kB lesz. Utoljára a Fermi rendelkezett ennyi regiszterrel 32 darab shader processzorra levetítve, így az NVIDIA ezen a ponton is lépdel visszafelé az alaparchitektúra irányába. Itt megint az a változás történik, amiről fentebb írtunk az ütemezés kapcsán. Az új gyártástechnológiával már nem szükséges olyan kompromisszumokat kötni, amelyekre a vállalat a Kepler és a Maxwell architektúrában kényszerült, így visszatérhet az az eredeti dizájn, amit a mérnökök a Fermivel álmodtak meg, és ez szintén növeli a compute hatékonyságot.
A GP100 a textúrázási képességek területén nem újít igazán. Az egyes streaming multiprocesszorok egy darab textúrázó blokkot tartalmaznak, amelyet két compute blokk használ egyszerre. Ehhez a textúrázó blokkhoz tartozik egy ismeretlen kapacitású írható és olvasható L1 gyorsítótár, amelyet természetesen a CUDA magok is használhatnak. Az NVIDIA arra nem tért ki, hogy a GP100 textúrázócsatornái képesek-e szűrt mintákkal visszatérni, vagy csupán mintavételezők vannak benne. Ez azért lenne fontos adat, mert utóbbi tényező fennállása mellett a GP100 csakis egy szerverekbe szánt termék lehet, míg előbbi esetben jó lenne más piacokra is. Hasonlóan titkolózik a vállalat azzal kapcsolatban is, hogy a GP100 rendelkezik-e egyáltalán setup motorokkal, illetve ROP blokkokkal. Nyilván ezek hiánya is azt jelentené, hogy a rendszer csak egy szerverekbe való gyorsító.
A Pascal architektúra némileg módosít a helyi adatmegosztáson is. Az új shader multiprocesszor mostantól 64 kB-os helyi adatmegosztással (Local Data Share) rendelkezik, vagyis egy compute blokkra 32 kB-nyi terület jut. Ez többek között a DirectX API DirectCompute specifikációi szempontjából lesz fontos változás, ugyanis a Maxwell architektúra esetében problémát jelentett, hogy a négy compute blokkra nem jutott akkora helyi adatmegosztás, amely minden compute blokknak biztosított volna egy 32 kB-os területet. Ilyen formában a Maxwell itt is compute teljesítményt vesztett, mivel nem mindig lehetett aktív a shader multiprocesszoron belül az összes compute blokk. A Pascal architektúra esetében azonban az NVIDIA orvosolta ezt a problémát, így ezen a területen is előrelépés történt.
Az NVIDIA ugyan nem részletezte mélységeiben, de lényeges újítás még, hogy a Pascal esetében a preempció a korábbi architektúrákhoz képest finomabb szemcsézettségű lesz. Arról nincs adat, hogy ez egészen konkrétan mit jelent, de az már biztos, hogy a korábbi rajzolási szintű preempciót egy új modell váltja fel. Ennek részleteiről azonban a vállalat még nem szeretne beszélni. Megújulnak a GMU-k, azaz a Grid Management Unitok is, így a Pascal jobb Hyper-Q képességekkel fog rendelkezni, mint a Maxwell. Sajnos a konkrétumokat a cég itt sem fejtette ki, de nagyon valószínű, hogy az új GMU-k már támogatni fogják az erőforrás-korlátozást, ami az aszinkron compute szempontjából nagyon hasznos lesz.
A HBM adja a cukormázt
A memórián is változtat az NVIDIA, mivel az ilyen szörnyetegekhez már komoly memória-sávszélesség szükséges, emiatt a vállalat a HBM memóriaszabvány második generációs verzióját veti be. A GP100 meglehetősen méretes interposerére négy darab, egyenként 4 GB-os, azaz összesen 16 GB HBM memória kerül. Ezek a GPU négy darab memóriavezérlőjéhez egyenként 1024 bites buszon keresztül kapcsolódnak. A változás miatt az NVIDIA átdolgozta a memóriavezérlést igazodva a HBM igényeihez, illetve a lapka kapott még 4 MB L2 gyorsítótárat is.
Amolyan extrának számít, de a szerverek területén nagyon fontos lesz az NVLINK, mely összeköttetés a GP100-on belül HUB által lesz vezérelve. Maga a lapka négy darab NVLINK interfészt kezel, vagyis minden GPU-hoz négy további GPU köthető. Egy NVLINK interfész egy irányba 20 GB/s-os adatátviteli teljesítményt kínál. A GP100-hoz alkalmazható topológiától függően az összteljesítmény elérheti a 160 GB/s-ot, de ez nagyban függ a konfiguráció formájától, így általánosítani nem lehet.
A GP100-akat kétféleképpen lehet beépíteni a szerverekbe. Egyrészt használhatók olyan processzorok, amelyek minimum x16-os PCI Express 3.0-s vezérlővel rendelkeznek. Ilyenkor egy processzorra a megfelelő PCI Express átkapcsolóval akár két GP100 is köthető, de a szerverprocesszorok esetében azért jellemzően jóval több PCI Express 3.0-s csatorna is használható. Az NVIDIA a megfelelő NVLINK topológia miatt processzoronként maximum négy GP100 lapkát enged meg.
Alternatív, de egyben sokkal jobb lehetőség, ha a GP100 nem csak PCI Express 3.0-s interfészen kapcsolódik a processzorhoz, hanem közvetlenül NVLINK-en is. Ilyenre lesz lehetőség, méghozzá az IBM OpenPOWER konzorciumának hála. Érkezni fog ugyanis legalább egy Power8 architektúrát használó processzor, amelyen belül található két NVLINK is. Egy ilyen processzorhoz két GP100-as GPU kapcsolható két x16-os PCI Express 3.0-s és két NVLINK interfészen keresztül. Kétutas szerver esetén ez máris négy GP100-at jelent, amelyek természetesen összeköthetők az NVLINK által. Ezt a topológiát az alábbi ábra szemlélteti.
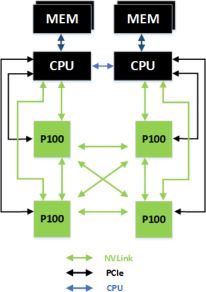
Ennek a modellnek egy hatalmas járulékos előnye az egységes virtuális memória támogatása, az NVIDIA ugyanis a Pascal architektúrát úgy tervezte, hogy közvetlenül támogassa az IBM Power8 címzési modelljét, illetve a processzorarchitektúra által használt lapméretet. Ilyen formában egy GP100-as GPU képes direkten az IBM Power8 processzorhoz kapcsolt teljes rendszermemóriába írni, vagyis elkerülhetők a sok bonyodalmat okozó adatmásolások.
A tényleges termékre rátérve a Tesla P100 nem teljes értékű GP100-at használ, mivel a lehetséges 60 shader multiprocesszorból csak 56 lesz aktív. Ez nem akkora probléma, mivel nyilván a gyártás során keletkeznek selejtek, amelyek a hibás területek letiltásával eladhatóvá vállnak. Évek óta alkalmazott és jól működő modell ez, különösen egy új gyártástechnológia bevezetésénél.
56 darab SM-mel számolva a 300 wattos TDP fogyasztási osztályba sorolt Tesla P100-ban összesen 3584 darab CUDA mag lesz, amelyeket 1792 darab FP64-es feldolgozó egészít ki. A textúrázó csatornák száma összesen 224, míg a teljes memóriabusz 4096 bites. Az NVIDIA a magórajel szempontjából 1328 MHz-es paramétert tervez, míg a GPU Boost órajel 1480 MHz is lehet. Utóbbi értékkel számolva jönnek ki az 5,3 TFLOPS-os, 10,6 TFLOPS-os és 21,2 TFLOPS-os elméleti teljesítményadatok 64 bites, 32 bites és 16 bites lebegőpontos számítások mellett. A valósághoz egyébként közelebb állna az alapórajellel való számítás, mivel a GPU Boost csak bizonyos feltételek mellett teljesül. Emiatt ezeket az értéket is kiszámoltuk, így a Tesla P100 ilyen formában rendre 4,8 TFLOPS-ot, 9,5 TFLOPS-ot és 19 TFLOPS-ot tud. Az NVIDIA megadta a memória effektív órajelét is, amely 1,4 GHz lesz, így a memória-sávszélesség 720 GB/s. Mindemellett az ECC is támogatott.

A Tesla GP100 egyébként gépi tanulásban teljesít igazán jól, ami nem akkora meglepetés, ha figyelembe vesszük, hogy az NVIDIA konkrétan ide tervezte. A gyorsulást nem csak maga a grafikus vezérlő, hanem az egész rendszer biztosítja, kiemelve az NVLINK-et, és ilyen formában nyolc GT100 akár 12-szer gyorsabb lehet négy GM200-as GPU-nál. Ez lesz a rendszer fő előnye, de persze a dupla pontosság melletti teljesítmény is hasznos lesz más területeken.
Abu85







