- Az NVIDIA szerint a partnereik prémium AI PC-ket kínálnak
- Két Zen 5-ös dizájnjának mintáit is szállítja már az AMD
- A Colorful "fagyosan kompakt" alkatrészekkel megy elébe a nyárnak
- A Keychron ismét egy űr betöltését vállalta magára az egerek szegmensében
- Az átlagnál vaskosabb ventilátorok kandikáltak ki a Corsair vitorlája mögül
- Milyen billentyűzetet vegyek?
- 3D nyomtatás
- Kihívás a középkategóriában: teszten a Radeon RX 7600 XT
- NVIDIA GeForce RTX 4080 /4080S / 4090 (AD103 / 102)
- Fujifilm X
- OLED TV topic
- NVIDIA GeForce RTX 3080 / 3090 / Ti (GA102)
- Bambu Lab X1/X1C, P1P-P1S és A1 mini tulajok
- Raspberry Pi
- AMD vs. INTEL vs. NVIDIA
Hirdetés
-


Nyár végén jön az idei THQ Nordic Digital Showcase
gp Az új bejelentések mellett újabb részleteket kapunk a Gothic Remake-ről és a Titan Quest II-ről is.
-


Eleglide C1 - a középérték
ma Szintet lépett az Eleglide, az egyébként egész korrekt M2 után a C1 sokkal komfortosabb közlekedésre alkalmas.
-


Toyota Corolla Touring Sport 2.0 teszt és az autóipar
lo Némi autóipari kitekintés után egy középkategóriás autót mutatok be, ami az észszerűség műhelyében készül.






-

PROHARDVER!
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-

Balala2007
tag
válasz
 #95904256
#1353
üzenetére
#95904256
#1353
üzenetére
Instruction latency meresre az EVEREST nem jo? (Jobbclick alul a statusz soron --> CPU Debug --> Instruction Latency Dump). Nez egy par spec. esetet is, es viszonylag pontosnak is. Ez itt pl. egy Yonah:
Ui: hoppa, ez igy eleg csunyan nez ki, inkabb kiveszem, de az EVEREST-ben megtekintheto
[Szerkesztve]AIDA64.com
-
#1600
Balala2007
tag
Balala2007
tag
AMD SSE5: (3 operandusos fpu muveletek, fused-multiply add stb.)
http://developer.amd.com/assets/sse5_43479_BDAPMU_3-00_8-27-07.pdfAIDA64.com
-
#2088
Balala2007
tag
dezz
#2044
Balala2007
tag
Nyugodtan megbizhatsz a CPUZ latency ertekekben, ezt mint EVEREST fejleszto mondom.
Ugyanazt a lancolt listas merest vegzi mind a ketto, (illetve ha akosf progijat is beleszamolom, akkor mind a harom.) Az a gond, hogy a memlatency erteke eleg sok mindentol fugg, emiatt a teljes kepet nem lehet 1db skalar ertekkel jellemezni. Szamit az alignment; az irany, hogy novekvo, csokkeno vagy kovetkezetlenul ugral a cimek kozott; a hasznalt memoriaterulet merete, hogy belefer-e valamelyik cache-be; illetve leginkabb az ugras merete, (ez a ''stride'') azaz mekkora tavolsag van 2 cim kozott.
Ezen parameterek alapjan lehet a latency matrixokat szerkeszteni, amit az EVEREST is meg tud tenni a developer verzioban. Ime egy pelda: [link], illetve ugyanerrol a geprol a CPUZ dumpja: [link] Latszik, hogy a CPUZ a backward linkelt listat hasznalja (felteszem azert, hogy egy-ket korabbi prefetchert atverjen, amik csak novekvo cimek eseten tudtak eloreolvasni), es annak egy reszmatrixat irja ki, a techreport pedig ebbol a matrixbol onkenyesen kivette a 8MiB blokkmeretu 512 byte stride-os erteket.
Az EVEREST az elorefele lancolt, 16MiB blokk, 1024 byte-os stride-os erteket irja ki a GUI-n.
Mind a ketto ''igazi'' ertek, csak mas parameterekkel futott a meres.AIDA64.com
-
-
#2112
Balala2007
tag
dezz
#2099
Balala2007
tag
CPUZ:
Ennek a miertjeit vszeg Frank Delattre tudja megvalaszolni. Egyebkent a CPUZ egy matrixot ad outputnak, amibol a t. cikkirok/olvasok izles szerint mazsolaznak.
Mi azert valasztottuk a forward/1024/16MiB-et, mert egy jo kozeperteknek tunt. Ugy altalaban gyakrabban szokas elorefele irkalni a memoriaban, 1024 byte-os stride-nal mar nem zavar be a cacheline merete es prefetchek sem szoktak ennyire elore olvasni, viszont meg page-ek kozott sem kell ugralni, a 16MiB meg tul van a legtobb cache mereten, viszont az oregebb konfigokon is eldocog.
[Szerkesztve]AIDA64.com
-
Balala2007
tag
válasz
#95904256
#1369
üzenetére
Kicsit bovulni fog az EVEREST InstLat a kovetkezo release-ben,
itt egy Barcelona dump peldakentEgy kis InstLat dump gyujtemeny
[ Szerkesztve ]
AIDA64.com
-
Balala2007
tag
válasz
#95904256
#2300
üzenetére
Gratula, szep munka, be is linkeltem a hasonlo projektek koze.[link]
Kulonosen az x87 resz tetszik, az nagyon otletes.Ugroutasitasos teszt nem veletlenul nincs az EVEREST-ben, es nem is valoszinu, hogy lesz. Sajna az EIP-t modosito utasitasok kesleltetesei direktben nem tesztelhetok ilyen ismetlodo lancolassal, emiatt egyaltalan nem tudok egyeterteni a peldaid ertekeivel.
A miertekrol szivesen kommunikalnek, de tartok tole, ez mar erosen off topik lenne itt. Egy uj topikot is megerne a dolog, ha gondolod, itt a PH!-n, vagy akar a lavalys forumban.[link]
AIDA64.com
-
#3032
Balala2007
tag
Balala2007
tag
-
#3331
Balala2007
tag
dezz
#3329
Balala2007
tag
nem értem ezen a 2. képen a Penrynek SSE4-ből eredő 2x-es gyorsulását.
Elvileg a PHMINPOSUW tehet rola.
AIDA64.com
-
Balala2007
tag
válasz
#95904256
#3338
üzenetére
A Visual Studio 2008-hoz jaro MASM 9.xx tud SSE4A-t, SSE4.1-et, SSE4.2-t, LZCNT-t, POPCNT-ot, legalabbis x64 alatt. x86-on nem mennek a gpr-ekre vonatkozo utasitasok, CRC32, LZCNT, POPCNT. (vagy legalabbis nem talaltam meg ki, hogyan lehet bekapcsolni ezeket.) A tobbi assemblert sajna nem ismerem.

AIDA64.com
-
#4111
Balala2007
tag
fLeSs
#4105
Balala2007
tag
Prime csak x87-et használ
Sztem ahhoz kepest tul sok a mulpd a kodban.
A PerfMonitor szerint hasznalja is oket, legalabbis azon a K8-on, amin megneztem. Nem kevered a SuperPi-vel?AIDA64.com
-
#4591
Balala2007
tag
Oliverda
#4589
-
#4593
Balala2007
tag
Oliverda
#4592
Balala2007
tag
válasz
 Oliverda
#4592
üzenetére
Oliverda
#4592
üzenetére
312 CVTSD2SS and CVTPD2PS Instructions May Not Round to Zero
Description
The Convert Scalar Double-Precision Floating Point to Scalar Single-Precision Floating Point (CVTSD2SS) and Convert Packed Double-Precision Floating Point to Packed Single-Precision Floating Point (CVTPD2PS) instructions do not round to zero when the Flush to Zero and Underflow Mask bits (MXCSR bits 15 and 11) are set to 1b and the double-precision operand is less than the smallest single-precision normal number.Potential Effect on System
The conversion result will yield the smallest single-precision normalized number rather than zero. It is not expected that this will result in any anomalous software behavior since enabling flush to zero provides less precise results.
Suggested Workaround
NoneFix Planned
NoAIDA64.com
-
#4647
Balala2007
tag
Balala2007
tag
A Barcelonahoz kepest "csak" a 45 nano es a 6MB L3 valtozott, semmi ISA bovules, vagy mas komolyabb belepiszkalas. Ugy latszik arra valamiert nagyon vigyaz az AMD, hogy a freq ki ne tudodjon vhogy.
[ Szerkesztve ]
AIDA64.com
-
#4648
Balala2007
tag
Balala2007
tag
AIDA64.com
-
Balala2007
tag
válasz
#95904256
#4651
üzenetére
32 helyett 48 utas lesz a 6MB L3. Tekintve, hogy mennyi tervezesi eroforrasuk van es milyen keves ido telt el a 65 es a 45 nanos verzio kozott, tartok tole, hogy ez nemhogy gyorsulast, hanem inkabb valamekkora L3 latency novekedest fog a gyakorlatban jelenteni per clock alapon.
AIDA64.com
-
Balala2007
tag
-
Balala2007
tag
válasz
#95904256
#4861
üzenetére
Tudtommal van 256 bites HADD az AVX-ben.
VHADDPD (VEX.256 encoded version)
DEST[63:0] <- SRC1[127:64] + SRC1[63:0]
DEST[127:64] <- SRC2[127:64] + SRC2[63:0]
DEST[191:128] <- SRC1[255:192] + SRC1[191:128]
DEST[255:192] <- SRC2[255:192] + SRC2[191:128]VDPPD-bol viszont tenyleg nincs 256 bites
AIDA64.com
-
Balala2007
tag
válasz
 shabbarulez
#4860
üzenetére
shabbarulez
#4860
üzenetére
AVX vs. SSE5 ahogy en most latom
(szigoruan elso benyomasok, lehetnek benne sulyos felreertesek, raadasul erosen szubjektiv is)
- SSE5 nem definial uj architekturalis allapotot, a meglevo 8 ill. 16 SSE regisztert hasznalja, nem kell hozza a meglevo OS-eket patchelni. Az AVX nagyobb regiszterteret hasznal (YMM regiszterek) ezek mentesehez bele kell piszkalni az OS-ekbe. Ez a 256 bites regiszterek nyilvanvalo hatranya. A helyzet analog az SSE vs. 3DNow! helyzettel kb. 10 evvel ezelott.
- SSE5 ortogonalis, azaz a regiszterek teljesen egyenranguak, minden mindenhol hasznalhato. Az x86 egyik fo baja amugy is a dedikalt regiszterhasznalat, marmint bizonyos muveletek kotelezoen megadott a regisztereket hasznalnak (pl. full MUL eseten eredmeny mindig rAX:rDX-ben, stb.) Ez egy rakas plusz mozgatast igenyel a kodban. Az SSE1,2,3, SSSE3 ugyan ortogonalis, de az SSE4 mar nem, abban az xmm0-nak kiemelt szerepe van. Az AMD cuccai ebben sokkal jobbak, az SSE5, a 3DNow! es a TFP (Technical Floating Point, piacra nem kerult, de az opkodok megtekintenthetok itt: http://www.sandpile.org/ia32/opc_k3d.htm) 100% ortogonalisak.
- Az AVX a boviteseket a 2 vagy 3 byte-os VEX prefixszel vezeti be, helyettesitve az SSE ill. REX prefixeket, emiatt az atlagos AVX utasitasok vszeg hosszabbak lehetnek az SSE5-os megfeleloiknel. Nem lepodnek meg, ha legkesobb a Sandy Bridge-ben a 16 byte-os Ifetch ablak 32 byte-ra novekedne.
- Az AVX onmagaban csak az alap float es double tipusokra vonatkozik. Egyreszt kiszelesednek a regiszterek 128-rol 256 bitre, masreszt lehetoseg nyilik 3 operandusos muveletekre. SSE1,2,3,SSSE3,SSE4.1 lebegopontos muveletei 2 operandusosak, az egyik forrast az eredmeny mindig felulirja. src,dst->dst helyett src1,src2->dst, ez mar nagyon kellett.
- Az AVX nem foglalkozik egesz tipusokkal 256 biten.
- Az SSE5 komoly egesz tipus tamogatassal rendelkezik. Rendre byte, word, dword, qword-re is ki vannak dolgozva a horizontal ADD/SUB, MADD, shift, rotalas muveletek, nagyon elegans es teljesen szimmetrikus.
- Az SSE5 permutalo utasitasai sztem kulon tapsot erdemelnek. Pl. a PPERM egymagaban tobbet tud, mint az osszes Inteles MOV/PACK/UNPCK. Ehhez kepest az Intel megoldasa enyhen szolva trehany.
- Az AVX csak az egyik a most bejelentett 4 fele fuggetlen Inteles utasitaskeszlet bovites kozul. A Nehalemekben ezekbol meg egy sem lesz benne, a Westmere-ben lesz HW AES tamogatas, a tobbi egyelore kerdojeles.
- Az AVX nem tartalmazza az igazan nagy ujitast, az FMA-t (fused multiply-add). Ez egy utasitasban egyesiti a szorzast es az azt koveto osszeadast, mikozben az utasitas latency tipikusan nem nagyobb a sima szorzasnal. Az Intel az SSE4.1 probalkozott valamit a DPPS/DPPD-vel, de az a gyakorlatban nem mutat igazi elonyt, az csak valamilyen mikrokodos varazslas.
- Az Intel az AVX-tol fuggetlenul definialta a sajat 4 operandusos FMA supportjat az YMM regiszterekre. Az egyelore nem vilagos, hogy mikor kerul implementalasra.
- Az Intel FMA-ban van kevert ADDSUB ill. SUBADD-os verzio is, azaz az FFT butterfly muvelete 1 utasitasra egyszerusodhet.
- Az SSE5 tartalmaz egy olyan FMA supportot, aminek az a hatranya van az Intelehez kepest, hogy csak virtualisan 4 operandusos. Az dst = op1 * op2 + op3 muvelethez teljes megvalositasban 4 fuggetlen regiszter kellene, az SSE5-ben viszont a dst sajna az egyik az op1, op2, op3 kozul.Tomoren: sztem az SSE5 a maga korlatai kozott atlathatobb, szimmetrikusabb, kovetkezetesebb (es talan konnyebben hasznalhatobb is lenne), mint a (sztem szokasosnak mondhato) Inteles takolas, de nem hinnem, hogy valaha is piacra kerul.
Az AMD sztem a "koszonjuk a reszvetelt" fazisban van, mert a jovendobeli sikereihez nem csak onmagaban kellene jol teljesitnie, hanem az Intelnek is rosszul.AIDA64.com
-
Balala2007
tag
válasz
 Balala2007
#4880
üzenetére
Balala2007
#4880
üzenetére
Nem tudom mennyire uj info, de itt vegre megirtak, hogy a Shanghaiban semmi architekturalis ujitas nem lesz a 6MB L3-on kivul. Semmi SSSE3, semmi SSE5, felesleges remenykedni. Vszeg az L3 latency-nek sem fog jot tenni a nagyobb meret es a nagyobb (32 vs. 48) asszociativitas. A magasabb freq-ban meg lehet remenykedni.
![;]](//cdn.rios.hu/dl/s/v1.gif)
AIDA64.com
-
Balala2007
tag
válasz
Balala2007
#4880
üzenetére
Ebben a pdf-ben szemleletesebb leiras talalhato az AVX-rol. Az is kiderul belole, hogy a VEX prefix nem csak a REX-et es SSE-t csereli le, hanem az escape-et is (0Fh), igy igazabol nem novekszik az atlagos utasitashossz, 2 byte-os VEX-nel meg me'g nehany esetben rovidulhet is. Meg egy elony az SSE5-tel szemben...
AIDA64.com
-
Balala2007
tag
válasz
#95904256
#4951
üzenetére
Előbb kipróbáltam ezt a cache-miss dolgot egy Phenom-on és egy Wolfdale-en is. Mindkettő képes volt arra hogy amíg a cache-miss miatt bejön a RAM-ból a dolog addig több száz utasítást ( add, xor, inc, fld, fstp, ... ) végrehajtsanak, így a több száz utasítással és azok nélkül is ugyanannyi volt a futásidő.
En is kiprobaltam egy Phenomon, es nekem az jott ki, hogy a reordering az csak ROB-nyi uop kozott mukodik. Az ellenkezoje meglepett volna, hiszen a retirement is in-order minden esetben.
#define BUFFER_SIZE 16 * 1024 * 1024
#define STRIDE 1024
#define READS 10000000
__declspec(naked) void __fastcall Walk(DWORD *raddr, DWORD repeat) {
__asm {
startWalk:
mov ecx, [ecx]
dec edx
jnz startWalk
ret
}
}
__declspec(naked) void __fastcall Walk2(DWORD *raddr, DWORD repeat) {
__asm {
startWalk2:
mov ecx, [ecx]
nop
....
nop
dec edx
jnz startWalk2
ret
}
}
void _tmain(int argc, _TCHAR* argv[])
{
double start, end;
DWORD *buff = NULL;
buff = (DWORD *)VirtualAlloc(NULL, BUFFER_SIZE, MEM_COMMIT, PAGE_READWRITE);
int index = 0;
for (index = 0; index < (BUFFER_SIZE / sizeof(DWORD)) - (STRIDE / sizeof(DWORD)); index += STRIDE / sizeof(DWORD))
buff[index] = (DWORD)&buff[index + STRIDE / sizeof(DWORD)];
buff[index] = (DWORD)&buff[0];
Walk(buff, READS);
start = (double)__rdtsc();
Walk(buff, READS);
end = (double)__rdtsc();
printf("Clocks:%f\n", (end - start) / (double)(READS));
start = (double)__rdtsc();
Walk2(buff, READS);
end = (double)__rdtsc();
printf("Clocks:%f\n", (end - start) / (double)(READS));
return;
}Ez a szokasos lancolt listas memoriaolvasgatast csinalja 2 verzioban. A masodiknal a futasido megegyezik az elsovel (nalam 145 clock-ra jon ki 1024byte-os stride-dal), amig csak 66db nop-ot szurok be. Ez stimmel is, mert 66 nop + 3 uop + 1 fetch bubble az 72 uop. A 67. nop utan erdekes modon elkezd lassulni, pedig a 145 clock alatt meg boven lenne ideje nop-okat apritani, de hat nem tud az in-order retirement miatt.
[ Szerkesztve ]
AIDA64.com
-
Balala2007
tag
válasz
 Andre1234
#5183
üzenetére
Andre1234
#5183
üzenetére
az 5 éves k8.Kiöregedő architektúrát eladják sempronnak.
Meg Family 11h-nak... (= K11
 )
)[ Szerkesztve ]
AIDA64.com
-
#5190
Balala2007
tag
dezz
#5188
Balala2007
tag
Hmm, azt kötve hiszem.
Teljesen biztos. Itt vannak CPUID dumpok, latszik, hogy a "K11" feature-ok megegyeznek a K8-eval. Van Shanghai meg Deneb dump is, ezek alapjan semmi arch. valtozas nem lesz a nagyobb L3-on kivul a 65 nanosokhoz kepest, semmi SSSE3, SSE4, vagy SSE5. A freq. persze vszeg magasabb lesz, itt peldaloznak egy allitolagos 4GHz-re beallitott C1-es ketyerevel, de nem hinnem, hogy ez a kozeleben lenne a hivatalos orajeleknek.
AIDA64.com
-
#5631
Balala2007
tag
Balala2007
tag
-
#5951
Balala2007
tag
leviske
#5947
Balala2007
tag
válasz
 leviske
#5947
üzenetére
leviske
#5947
üzenetére
Ezt az AMD SimNow doksijabol vagtam ki:
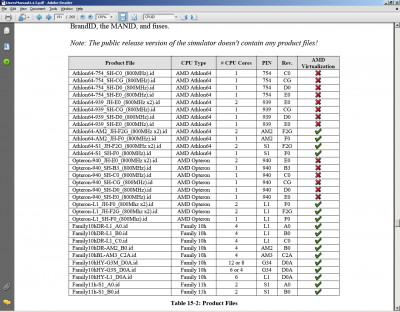
Ugy tunik a tobb magon tul ez "csak" egy ujabb K10 revizio (D) lesz.AIDA64.com
-
#6018
Balala2007
tag
Balala2007
tag
Az AMD kiadott egy uj utasitaskeszlet-bovitmeny doksit:http://support.amd.com/us/Processor_TechDocs/43479.pdf Az SSE5-ot ezen a heten XOP-nak, FMA4-nek es CVT16-nak hivjak.



[ Szerkesztve ]
AIDA64.com
-
Balala2007
tag
válasz
 zsolt320i
#6403
üzenetére
zsolt320i
#6403
üzenetére
Mennyit lehet tudni a Sandy-ról?
Ez egy hivatalos vazlat, latszik, hogy a 6 portbol 5db 256 bit szeles.
A Bulldozerrol tudtommal a legkonkretabbakat Dresdenboy blogjaban irjak, kar, hogy ezek tobbnyire csak talalgatasok a keves hivatalos adatbol tovabbgondolva.
Meg nagyon sok adat hianyzik, es az utasitaskeszlet specifikaciok is tobb korben valtoztak, de sztem az idezett sorokban olyasmire gondoltak, hogy amig a Bulldozeren egy clk alatt lekuldheto egyvfmaddsubpd ymm0, ymm1, ymm2, [yword]
addig a SB- a fenti vazlat alapjan elkepzelheto, hogy csucsertekben lemegy akar ez is:
vmulpd ymm0, ymm1, ymm2
vaddpd ymm3, ymm4, ymm5
vandpd ymm6, ymm7, ymm8
vmovapd ymm9, [yword]
vmovapd [xword], xmm11(Latszolag meg egy plusz vmovapd ymm10, [yword] is beleferne az VE-k szempontjabol, de az L1D bandwidth csak 48 byte. A Bulldozer ezen parametere -- tudtommal -- meg nem ismert, de nagyon sok mulhat rajta.)
Bonyolitja a dolgot, hogy a csucsertekek kihasznalasahoz uj kodot kell gyartani. (Kerdes, hogy ha valaki elkezd AVX-re fejleszteni, akkor megelegszik-e ezzel, vagy egy lendulettel megcsinalja mondjuk az FMA4 verziot is...) Aztan kevesnek tunhet az 1 FMA4 az 5 AVX ellen, de sok olyan kodot el tudok kepzelni, ahol FMUL+FADD latency kritikus, es ott a Bulldozer tarolhat az FMA4-gyel.[ Szerkesztve ]
AIDA64.com
-
#6413
Balala2007
tag
Oliverda
#6409
Balala2007
tag
válasz
Oliverda
#6409
üzenetére
Az AMD sajat compilerenek, az Open64-nek a forrasa igazi kincsesbanya, rengeteg minden kiderul belole a Bulldozerrel kapcsolatban Pl. a CPUID family erteke 21 Az L1D latency marad 3 clk (ez a legbizonytalanabb info, mert kerdojelesen szerepel), a legtobb integer marad 1 clk, az egyszeru float/double muveletek 4->6 clk, (FMA4 is 6clk!, DIV/SQRT hasonlo aranyban lassulnak), viszont ha memoriaoperandust hasznal, akkor +2clk helyett +5 clk a K10-hez kepest. Az integer SIMD maradt 2 clk, es SIMD regiszterek kozotti MOV-ok 0-ra csokkennek, egy EBO nevu valaminek koszonhetoen. Dresdenboy blogjanak talalgatasa szerint ez a "Extended Block Optimizer (EBO)"-nek a roviditese, ami egy eleg bonyolult elofeldogozonak nez ki.
[ Szerkesztve ]
AIDA64.com
-
#8180
Balala2007
tag
Abu85
#8177
Balala2007
tag
A B0 revízióban nem lehet írni az L2 és L3 gyorsítótárba.
De lehet, a 0 eredmeny csak amiatt van, mert az az AIDA meg nincs rendesen felkeszitve a Bulldozerre, nem veletlenul jelenik meg az a "not fully optimized" warning.
(Az AIDA64 azt a strategiat koveti az altala meg nem ismert prociknal, hogy megprobalja a hozza legkozelebb eso korabbi proci rutinjat futtatni, jelen Bulldozer esetben a K10-es rutinokat. Ezek 3DNow prefetch utasitasokat hasznalnak, de mivel a Bulldozerben mar nincs 3DNow, a 345-os bench build skippeli ezeket, ezert lesznek 0 eredmenyek. Sajnos hibasan, mivel csak a prefetch utasitasok a 3DNow-bol tovabbra is tamogatottak, csak ezt a B345 nem jol kezeli le.) A BDZ L1D es L2 cache-ei write through-ak (tkpen csak a read-eket gyorsitjak), ugyhogy write-ban nem fognak hasitani.[ Szerkesztve ]
AIDA64.com
-
#8196
Balala2007
tag
Abu85
#8183
Balala2007
tag
Azt tudom, hogy a Bulldozer L1D es L2-i write through-ak. Az AMD régóta ezt a megközelítést alkalmazza a procijainál.
Utoljara az Am486-ban volt write through cache az AMD procikban, az Intelekben is csak a P4 L1D-nek hasznaltak a 486-osok ota, azota minden mindenhol write back. Sztem kevered az exclusivitassal.
AIDA64.com
-
Balala2007
tag
válasz
Oliverda
#13424
üzenetére
Turbo/C1E/CPB/stb. letiltva, 1 szalon, Bytes/clk:
AMD 610F01 INTC 306A8 INTC 306C3
L1D 31.867 B/c 31.975 B/c 63.897 B/c
L2 15.930 B/c 17.877 B/c 29.309 B/c
Write
L1D 5.858 B/c 15.994 B/c 31.976 B/c
L2 5.605 B/c 10.663 B/c 10.142 B/c
Copy
L1D 11.802 B/c 31.974 B/c 63.903 B/c
L2 9.683 B/c 15.876 B/c 15.915 B/c[ Szerkesztve ]
AIDA64.com
-
#13971
Balala2007
tag
Balala2007
tag
Ha valakit erdekelnek a low-level Kaveri ugyek, akkor ime a publikus BKDG.
(Bar meg kell jegyeznem kapasbol 2 dolgot is kiszurtam benne, amit, hat, khm... nem tudok megerositeni.)AIDA64.com
-
Balala2007
tag
válasz
 letepem
#14043
üzenetére
letepem
#14043
üzenetére
Esetleg van valami doksi az AVX-ről,
Intel AVX512 (+ SHA + MPX + Broadwell uj utasitasok stb.) doksi ez lesz implementalva a Sky Lake - Sunset Lake - Cannon Lake ...(desktop/server) illetve Knights Landing - Knights Hill ... (MIC) cuccokban
Intel SDE-vel lehet tesztelni/debugolni mar most az AVX512 kodok helyesseget
A nasm 2.11-gyel lehet mar AVX512 asm kodot forditani
[ Szerkesztve ]
AIDA64.com
-
#14066
Balala2007
tag
dezz
#14048
Balala2007
tag
Mikor is jön az AVX-512? 2015 elején, közepén, végén?
min(release_date(KNL),release_date(Skylake)) <>=? release_date(Carrizo_AVX2)
Mennyien veszik a fáradtságot AVX assembly programozásra manapság?
Mindenhol, ahol nem fejlesztesi, hanem futasidore optimalizalnak.Pl.:
- x264/ffmpeg/libav/VLC komplex (AVX2);
- Google VP9 (AVX2, VP8 meg csak SSE41-ig jutott);
- x265 (AVX2);
- GIMPS/Prime95 (27.7-tol, 2012 majustol van AVX);
- GMPLib 5.2 (Ez csak most fog kijonni, de felhasznalja a Mathematica es a Maple is);
- FFTW (3.3.3 ota AVX)
- y-cruncher (tudtommal ez mostani pi-comp csucstarto, 2011 ota van benne AVX);
- nyomokban feltunik mar a PovRay-ben is, az FMA4-gyel egyutt;
- A Kribi3D is hasznal AVX2-t mar tavaly szeptembertol. Mivel nem publikus a forrasa, biztosat nem lehet tudni, de a megjelenes sebessegebol es a futasido kritikussagat itelve ez is asm alapu lehet.
- minden mas projekt eselyes lehet, aminek van SSEn asm resze, es forditoja kepes AVX kodot gyartani.Eleg keves az SSE->AVX assembly valtashoz a tanulnivalo, par Intel pdf atnezesevel a lenyeg 90%-at meg lehet erteni. Ugy altalaban azt lehet varni, hogy ahol volt SSEn codepath, ott idovel lesz AVXn is.
[ Szerkesztve ]
AIDA64.com
-
#14077
Balala2007
tag
dezz
#14074
Balala2007
tag
Ez mit jelent?
A 3 kozul pontosan az egyik lesz, de meg nem tudom melyik
Remélhetőleg előbb-utóbb a GPGPU-zásba is belekezdenek a fejlesztőik
A Kribi3D definicio szerint csak CPU-val foglalkozik, a y-cruncher fejlesztoje konkretan kizarta dolgot, a tobbit nem tudom.
Hacsak nem az Intel szponzorálja őket a háttérben.
Ennek semmi koze az Intelhez. Vannak olyan problemaosztalyok, amikre a GPU alkalmatlan. Vegul is csak egy koprocesszor, nem varhato, hogy altalaban hatekony legyen mindenre.
[ Szerkesztve ]
AIDA64.com
-
#14467
Balala2007
tag
Fiery
#14463
Balala2007
tag
-
#14602
Balala2007
tag
Balala2007
tag
-
Balala2007
tag
válasz
Balala2007
#14602
üzenetére
Nocsak:
+ { "CPU_ZNVER1_FLAGS",
"Cpu186|Cpu286|Cpu386|Cpu486|Cpu586|Cpu686|CpuSYSCALL|CpuRdtscp
|Cpu387|Cpu687|CpuFISTTP|CpuNop|CpuMMX|CpuSSE|CpuSSE2|CpuSSE3
|CpuSSE4a|CpuABM|CpuLM|CpuFMA|CpuFMA4|CpuBMI|CpuF16C|
CpuCX16|CpuClflush|CpuSSSE3|CpuSVME|CpuSSE4_1|CpuSSE4_2
|CpuAES|CpuAVX|CpuPCLMUL|CpuLZCNT|CpuPRFCHW|CpuXsave|
CpuXsaveopt|CpuFSGSBase|CpuAVX2|CpuMovbe|CpuBMI2|CpuRdRnd|
CpuADX|CpuRdSeed|CpuSMAP|CpuSHA|CpuXSAVEC|CpuXSAVES|
CpuClflushOpt|CpuCLZERO"[ Szerkesztve ]
AIDA64.com
-
#14695
Balala2007
tag
Balala2007
tag
AIDA64.com
-
#14703
Balala2007
tag
Z10N
#14702
Balala2007
tag
-
#14796
Balala2007
tag
Balala2007
tag
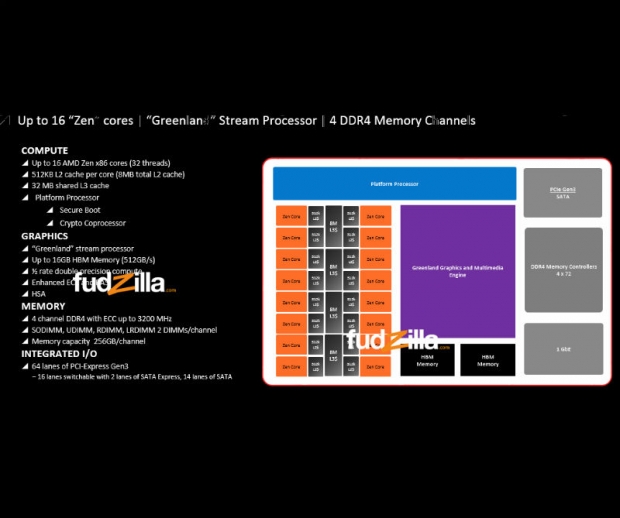
<allitolag>
- 2 socketes verzio
- max 140W TDP
- 4x MCM, azaz 4 die 1 socketre integralva. Ez megmagyarazna a 4x8MB L3-at
</allitolag>AIDA64.com










![;]](http://cdn.rios.hu/dl/s/v1.gif)
 )
)













Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.

- BestBuy ruhás topik
- Milyen billentyűzetet vegyek?
- 3D nyomtatás
- D1Rect: Nagy "hülyétkapokazapróktól" topik
- Kihívás a középkategóriában: teszten a Radeon RX 7600 XT
- NVIDIA GeForce RTX 4080 /4080S / 4090 (AD103 / 102)
- Microsoft Excel topic
- Fujifilm X
- Renault, Dacia topik
- OLED TV topic
- További aktív témák...
