A GCN rendszerek különbségei
A GCN architektúra lassan két évvel ezelőtti debütálása komoly hatással volt a piacra, hiszen egy alapjaiban új elvek szerint tervezett rendszerről hullt le a lepel, mely már inkább az általános számítások hatékonyságát helyezte előtérbe, de természetesen a grafikáról sem feledkezett meg. A GCN architektúrát részletesen elemeztük korábbi cikkünkben. Mára kiderült, hogy a fejlesztés meghatározza majd a következő évtizedet, hiszen az új generációs konzolok közül a Microsoft Xbox One és a Sony PlayStation 4 is erre a rendszerre épít. Ennek megfelelően senki sem számította arra, hogy az architektúra helyett valami újat húzna elő az AMD, de a technológia azért fejlődik, így a GCN is átesett a maga kis ráncfelvarrásán.
Manapság több helyen is megjelenik, hogy különböző GCN verziók vannak, ami önmagában igaz, de ezeket az AMD nem számokkal jelzi. Mielőtt az újításokat megvizsgálnánk, mindenképp tisztázni kell, hogy konkrétan milyen GCN rendszerek léteznek. A legegyszerűbb a GCN S.I.-vel (Southern Islands) kezdeni, ami az alapot képviseli, és a fent linkelt cikkben erről írtunk. A GCN S.I.-re épül a Cape Verde (Radeon HD 7750 és 7770), a Pitcairn (Radeon HD 7850, 7870 és R9 270X) valamint a Tahiti (Radeon HD 7950, 7970 és R9 280X) kódnevű cGPU is. Technikai értelemben ezek tartalmazzák az első verziójú utasításarchitektúrát és a szintén első verziójú ACE egységeket.
A következő lépcsőt a Bonaire (Radeon HD 7790 és R7 260X), az Oland (Radeon R7 240 és 250) és a Hainan (erre még nem épül dobozos termék) kódnevű cGPU képviseli, melyek vegyítik az új GCN C.I. (Sea Islands) utasításarchitektúrát az eredeti ACE egységekkel. Ez amolyan átmenet az igazi szintlépés és az első GCN fejlesztés között. A legmodernebb kategóriát az új GCN C.I. utasításarchitektúra és a továbbfejlesztett ACE egységek párosítása jelenti. Ide tartozik a Kabini és a Temash kódnevű SoC APU-k IGP-je, valamint az új generációs konzolokban található APU-k integrált grafikus vezérlője, és persze jelen cikkünk alanya, a Hawaii kódnevű cGPU is.

A fentieket mindenképp fontosnak tartottuk tisztázni, így remélhetőleg a jövőben egyszerűbben azonosítják be a felhasználók a különböző GCN architektúrákat. Az is kiderült, hogy az új GCN C.I. verzió társítható az eredeti ACE egységekkel, de ez egyébként fordítva nem igaz, tehát a továbbfejlesztett ACE egységek csak az újabb utasításarchitektúrával működnek. Már csak annyi kérdés lehet, hogy mi a különbség a GCN S.I. és az újabb C.I. között. Nos, a felújítás során számos változás érte a memóriacímzést. Többek között megjelent egy memóriafigyelő, mellyel a shader észlelheti, ha egy memóriaterülethez hozzáférés történt. Jelentősen javult a hardver debugolhatósága, mivel a debugger státuszbitekkel ruházhatja fel a wavefrontokat, így a kód egy része tetszőlegesen kihagyható vagy lefuttatható. Ez jelentősen leegyszerűsítheti a komplex programok debugolását, főleg akkor, ha alacsony szintű interfészen keresztül történik a hardver programozása. Mindezek mellett megjelent a rossz memóriacímre való hivatkozás detektálása és jelentése, illetve az úgynevezett unaligned (illesztetlen) memóriaelérés támogatása. Ezek a funkciók elsősorban az új generációs konzolok miatt kerültek be, mert az Xbox One és a PlayStation 4 APU-jaiban található IGP-ket a fejlesztők később assembly szinthez közel programozzák majd, tehát alapvetően fontos, hogy a hardverhez közeli programozás a lehető legegyszerűbb legyen.
Mindezek mellett a GCN C.I. utasításarchitektúrában bemutatkozik az eszköz egységes címzése is, amivel az adott kernel vagy shader az LDS-t (helyi adatmegosztás), a privát memóriát, a videomemóriát és a rendszermemóriát egyetlen címezhető lineáris memóriaként láthatja. Ehhez tartozik az új FLAT utasításformátum, és az összes utasítás elérhető vele. Ezek az utasítások nem használnak erőforráskonstanst, amely meghatározná egy felület alapvető címzését, vagyis az adott shadernek például nem kell tudnia, hogy egy pointer mely fizikai területre mutat. Ez is inkább egy konzolokhoz, illetve az integrációhoz tervezett funkció, de hasznos lehet a dedikált grafikus vezérlő szintjén is. Legfőbb előnye, hogy eléggé leegyszerűsíti az egyes függvényhívásokat, így a fejlesztők újszerűen kezdhetnek el gondolkodni, ami új algoritmusokhoz vezethet.
A GCN C.I. utasításarchitektúra szintén bevezeti a rendszermemória egységes címzését, amivel a grafikus vezérlő elérheti a koherens rendszermemóriát. Ennek nem sok haszna van egy VGA-ban, így ez is inkább az Xbox One és a PlayStation 4 APU-ján belül lesz lényeges funkció, hiszen erre építették mindkét konzolt. Fontos megjegyezni, hogy ez a rendszer megfelelő HSA-MMU mellett dolgozik teljes funkcionalitással, így PC-n majd a Kaveri APU IOMMU v2.5-ös egységével lesznek kihasználhatók a legfőbb előnyei.

A GCN architektúra sarkalatos pontjának számítanak még az ACE egységek, melyek úgymond opcionális részei a rendszernek, vagyis implementációjuk nem kötelező, tehát egy adott GPU működik nélkülük is, de olyan előnyt kínálnak, hogy az általános számítások felé haladó világban ezeket már nem lehet kihagyni. Az AMD azonban meglehetősen finoman állt hozzá az új irányokhoz, így a Cape Verde, a Bonaire, a Pitcairn és a Tahiti cGPU-k két ACE-t kaptak. Ezek a parancsprocesszorhoz szorosan kapcsolódtak, és az erőforrás allokációjával, a kontextusváltással és a feladat prioritásával kapcsolatban hoztak döntéseket. Természetesen az ACE out of order logikát alkalmazott az erőforrások mielőbbi felszabadítása érdekében. Egyszerűen összefoglalva elmondható, hogy minél több ACE egység van az adott lapkában, annál hatékonyabb a multiprocesszorok úgymond etetése. Viszont ennek az előnye igazából akkor jön ki, ha az adott program rengeteg általános számítási feladattal dolgozik, és azok különböző kontextusból származnak.
A továbbfejlesztett ACE egységet az AMD már elhelyezte a Kabini és a Temash kódnevű SoC APU-k IGP-jében, valamint az Xbox One és a PlayStation 4 APU-jában, de csak most, a Hawaii kódnevű lapka megjelenésével döntötte el a cég, hogy részletesen beszámol a változásokról. Az ACE alapvető funkciója nem változott, viszont számos újítást mutatott be.
Felzárkózás a konzolokhoz a Hawaii cGPU-val
Az új ACE egység elsődleges újítása, hogy egy parancslista helyett már nyolcat kezel, emellett a rendszer képes saját magának új munkát adni anélkül, hogy a processzor beavatkozására lenne szükség. Ezzel lényegében támogatható az OpenCL 2.0-ban érkező dinamikus parallelizmus funkció.

[+]
A felújított ACE egységek száma továbbra is meghatározható. Például a Kabini és a Temash kódnevű SoC APU-k IGP-je négyet, az Xbox One APU-jának IGP-je kettőt, míg a PlayStation 4 APU-jának IGP-je nyolc darabot kapott. Utóbbitól az új Hawaii kódnevű cGPU sem akart elmaradni, így ebbe a lapkába is nyolc új ACE egység került. Ezek továbbra is képesek egymással szinkronizálni, és kommunikálni a GDS (globális adatmegosztás) és az L2 gyorsítótáron keresztül. Az AMD a változásokkal még erősebben rálépett a compute irányra, aminek hála olyan grafikus processzorok készülnek, amelyek hatékony multitaszk feldolgozást tesznek lehetővé. Ennek manapság nincs látható jelentősége, hiszen a piacon kapható hardverek többsége nem elég jó ahhoz, hogy a fejlesztők építsenek az előbbi a képességekre, de az új generációs konzolok megjelenésével ez a felfogás megváltozik, így a PC-be is át kell menteni ezeket a funkciókat.
Újítások a Hawaii cGPU-ban
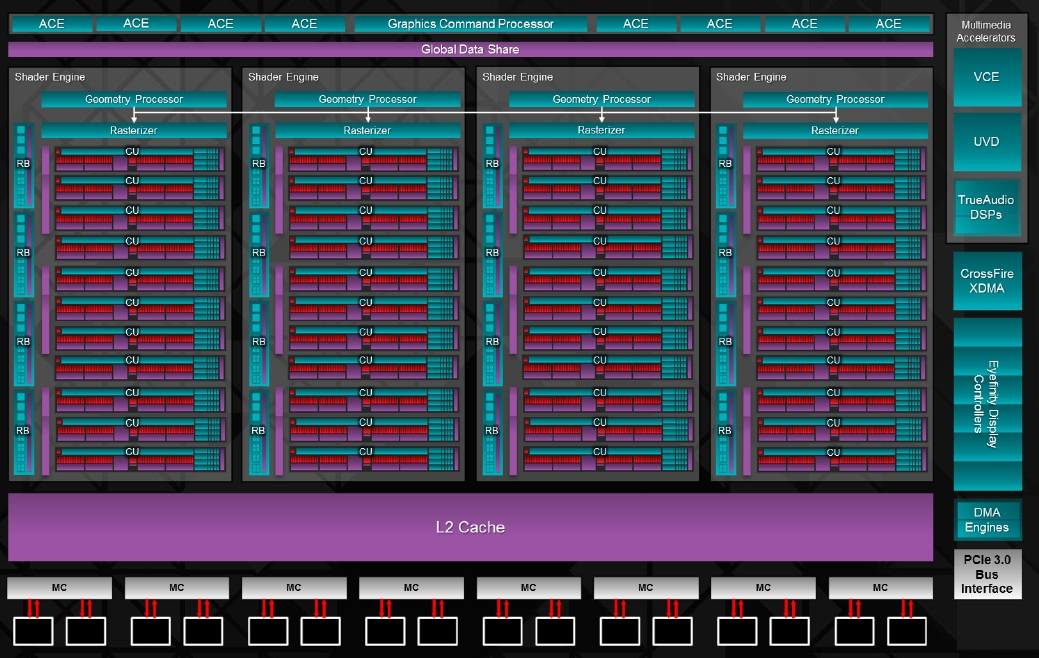
Most, hogy látható a GCN rendszerek közötti alapvető eltérés, rá lehet térni a Hawaii kódnevű cGPU vizsgálatára, mely gyakorlatilag a legmodernebb részegységekre épít, azaz konkrétan azokra, amelyeket az Xbox One és a PlayStation 4 konzolok APU-jainak IGP-je kapott. Az új lapka a TSMC 28 nm-es gyártástechnológiájával készül, kiterjedése pedig 438 mm², és ebbe a méretbe 6,2 milliárd tranzisztort sikerült bepasszírozni. A rendszer alapját továbbra is a CU, azaz a Compute Unit képzi, ami azonban a Tahiti cGPU-hoz képest változott egy picit. Radikális különbségekre persze nem kell gondolni, hiszen megmaradt az egy skalár feldolgozó, illetve négy darab, egymástól teljesen független, 16 utas, azaz 512 bites, multiprecíziós SIMD motor. Egy CU-n belül továbbra is 64 kB-os helyi adatmegosztás, vagy más néven Local Data Share (LDS) található, melyen a négy darab, egyenként 64 kB-os regiszterterülettel rendelkező SIMD motor osztozik. Az LDS mellett egy 16 kB-os adat gyorsítótár is elérhető, melyet a CU írhat és olvashat is.

[+]
Az előző bekezdésben már említett skalárfeldolgozó némileg különc a CU-n belül. Ez lényegében egy integer ALU, mely 4 kB-os dedikált regiszterterületet kapott. Észrevehető, hogy a korábbi CU dizájnban 8 kB dedikált regiszterterület állt rendelkezésre, vagyis az AMD itt jelentősen visszavett az elődökhöz képest. Ezt a cég azzal magyarázza, hogy még a 4 kB is bőven sok erre a célra, így nincs értelme a tranzisztorokat olyan helyen használni, ahol nem hoz gyorsulást. A textúrázást CU-nként továbbra is egy blokk oldja meg, mely négy darab, csak szűrt mintákkal visszatérő, Gather4-kompatibilis textúrázó csatornát rejt. Funkcionális újítás még a továbbfejlesztett MQSAD utasítás, mely jobb minőségben dolgozik, mint a korábbi lapkákban, illetve a rendszer pontosabban számolja a natív LOG és EXP operációkat.
Rendkívül érdekes extra még a CU-kon belül, hogy a rendszer mostantól használhatja az LDS-t a geometry shaderek adatainak lementésére. Erre az AMD korábban a GDS-t használta, illetve ez még most sem tilos, de a 64 kB-os helyi adatmegosztás továbbra is túlteljesíti a DirectCompute 5.0 igényét, hiszen ez a felület 32 kB-os tárat ír elő. Viszont a vállalat a GCN architektúra esetében az LDS-t virtualizálja, tehát a különböző feladatok egymás adatait nem bánthatják. Az új ötlettel drámaian lehet növelni az architektúra geometry shader kódokban leadott teljesítményét anélkül, hogy az kárt okozna más munkafolyamatoknak.
A lapka egészét tekintve már érdekesebb újítások vannak. Ahogy korábban említettük, nyolc darab ACE egység került a grafikus parancsprocesszor mellé. Előbbi csak compute, míg utóbbi compute és grafikus feladatokat képes feldolgozni. A rendszer része maradt a 64 kB-os globális adatmegosztás, vagy más néven Global Data Share (GDS), emellett megmaradt a két DMA motor, a VCE 1.0-s és az UVD 3.2-es egység, illetve bekerült a TrueAudio blokk, melyről cikkünkben részletesen írtunk.
A rendszer belső szervezése azonban egy picit megváltozott. Mostantól a hardver úgynevezett shader motorokra van felosztva. Ezeken belül számos CU tömb lehet, számos ROP-blokkal, viszont mindegyik motor alapvető eleme egy tesszellátor és egy raszter motor. Az új, tizedik generációs tesszellátor a Tahiti cGPU-ban bemutatott kilencedik generációs egységhez képest csak picit fejlődött, főleg a pufferelés területén. Lényegesebb újítás azonban, hogy a raszter motorok jelentős fejlődésen mentek keresztül. Egy ilyen egység órajelenként 16 pixelt képes feldolgozni, de ennél is fontosabb, hogy a teljes raszterizálási folyamat nagyobb gyorsítótárakkal dolgozhat, így jelentősen gyorsul majd a hardver azokban a szituációkban, ahol a háromszögek nem tesznek ki 16 pixelt. Információink szerint a felújítás hatására a csupán négy pixelt kitöltő háromszögek feldolgozása is rendkívül gyors lett, annak ellenére, hogy itt már a raszterizálás hatékonysága általánosan hátrányosnak tekinthető.
Korábban már többször is leírtuk, hogy a 2 x 2 pixeles tömbökön zajló leképzés miatt nem ideális, ha egy háromszög kisebb mint 16 pixel, mivel ez drámaian csökkenti a feldolgozás hatékonyságát minden hardveren. Ez alól az új Hawaii cGPU sem kivétel, csupán az történik, hogy a feldolgozás sebessége nem esik annyira vissza, mint a többi hardveren, de a hatékonyság akkor is radikális mértékben esik. Ennek megfelelően továbbra sem támogatjuk, hogy egy játékban 16 pixelnél kisebbek legyenek a háromszögek. Az viszont elmondható, hogy ha kisebbek, akkor az messze a Hawaii setup részének a legkedvezőbb. Úgy gondoljuk azonban, hogy a fejlesztők értik a tesszellálás lényegét, így pontosan tudják, hogy semmire sem mennek azzal, ha drámaian lecsökkentik a raszterizálás hatékonyságát, tehát az AMD fejlesztése nem nekik szól, hanem inkább az NVIDIA-nak. Ha a zöldek továbbra is igénylik a reálisan értékelhetőnél jobban tesszellált felületeket (legyen az akár sík vagy sem) a fejlesztőktől, akkor azzal mostantól a Hawaii cGPU-nak tesznek nagyon jót. Viszont kérdés, hogy átesünk-e a ló túloldalára, mivel az AMD is hozzáállhat úgy a kérdéshez, hogy a jövőben túltesszellálják a játékokat, hiszen ez mostantól nekik kedvez.
A shader motorokon belül három vagy négy CU rendeződhet egy tömbbe, és ezekhez tartozik egy 16 kB-os skalár és egy 32 kB-os utasítás gyorsítótár. Előbbit csak a skalárfeldolgozó éri el, és csak olvasható tárról van szó, ám utóbbi írható is, és a CU összes feldolgozója hasznosíthatja.
Mi van a Hawaii cGPU-ban?
Az újítások részletezése után ideje rátérni a számokra, és ezzel a lapka teljesítményére. A Hawaii kódnevű cGPU-ban összesen négy darab shader motor található, melyekben egy-egy tesszellátor és raszter motor dolgozik négy-négy ROP blokk és három-három CU tömb mellett. Utóbbi tömbök szempontjából kettőben 4 darab, míg egyben 3 CU található. Ezt összesítve a lapkába 4 tesszellátor és 4 raszter motor került 44 darab CU-val egyetemben, melyek felfoghatók 2816 darab shader részelemként is.
[+]
Egy shader motor setup része órajelenként egy háromszöget dolgoz fel, ami a teljes chipre nézve már négy háromszöget jelent, emellett a raszter motorok összesített teljesítménye órajelenként 64 pixel. Ehhez jól igazodik a cGPU-ban található 16 darab ROP blokk, ami összesen 64 blending és 256 Z mintavételező egységet eredményez. Mindegyik ROP blokk kapott egy 16 kB-os color és egy 4 kB-os depth gyorsítótárat, emellett a teljes lapkában található egy 1 MB-os L2 gyorsítótár, mely írható és olvasható is egyben, emellett koherens is, vagyis mindegyik CU azonos memóriaképet lát.
Az L2 gyorsítótár 16 darab 64 kB-os partícióra van felosztva, amelyek órajelenként 64 bájt adatot mozgatnak, vagyis a belső sávszélesség 1 TB/s. A nyolc darab 64 bites memóriacsatorna két-két darab 64 kB-os L2 partícióhoz kapcsolódik. A memóriabusz szélessége összesen 512 bites, és az AMD által ajánlott 5 GHz-es effektív órajelű GDDR5 memóriákkal társítva 320 GB/s lehet a memória-sávszélesség.
A Hawaii cGPU magórajelének meghatározása már sokkal nehezebb. Az AMD egy új PowerTune rendszerrel állt elő, melynek célja teljesen a hardverre bízni az órajel és a feszültség vezérlését. A szoftver azonban mostantól csak alapvető direktívákat adhat, mivel a vezérlést az SMU firmware végzi. A korábban bemutatott Bonaire cGPU már egy ilyen irány felé menetelt, amikor nyolcra növelte a DPM állapotok számát, de az új PowerTune már 255 különböző DPM állapotot ismer, melyek között 10 mikromásodpercenként képes váltani, ami rendkívül gyorsnak számít. Ez az egész radikális előrelépés a működés terültén, mivel 1,55 V-ig 255 különböző állapot van, és egy váltással 6,25 mV-os lépést tehet a hardver. Gyakorlatilag az üzemfeszültség, mint fogalom eltűnik, mivel a rendszer mindig a megfelelő feszültséget állítja be az adott órajelhez.

[+]
A magórajelet tekintve az alapvető érték 1 GHz. Ez azonban nem állandó paraméter, hanem sokkal inkább egy cél, amit a hardver mindig tartani szeretne. A meghatározott fogyasztási keret azonban nem biztos, hogy minden esetben elég ehhez, így a Hawaii cGPU terhelés mellett 800 MHz-ig visszaveheti a működési órajelet. A váltás az előbb felvázolt PowerTune szabályai szerint zajlik, vagyis a hardver csak egyenletesen válthat órajelet, amire a rendkívül gyors reakcióidő bőven lehetőséget ad. Mivel a PowerTune nagyon gyorsan működik, így a rendszer rendelkezik egy belső pufferrel, mely a váltásokat folyamatosan feljegyzi, az órajelet kiolvasó szenzor pedig egy átlagolt paramétert jelez vissza a felhasználónak.

[+]
A felújított PowerTune hatására a rendszer mindig a maximumot nyújtja. A Hawaii cGPU átlagosan mindössze 1 wattos hibahatárral dolgozik terhelés mellett, vagyis tökéletesen képes alkalmazkodni az adott számításigényhez. Ezzel a rendszer hűtése is sokkal kiszámíthatóbb, így minimalizálni lehet a ventilátor fordulatszámát, emellett az átlagosnál magasabb hőmérséklet célozható meg.

[+]
A Hawaii cGPU PowerTune funkciója a Catalyst vezérlőpult Overdrive menüjében paraméterezhető. A tuning mostantól százalékos szinten állítható be mind a memória, mind pedig a GPU órajelére vonatkozóan, emellett százalékosan megváltoztatható az áramfelvételi korlát is. Fontos, hogy a beállított paraméterek közül a magórajel a maximumot jelzi, vagyis ha a hardver úgy gondolja, hogy a grafikus processzor nem fogja bírni a terhelést, akkor saját magának beállít egy alacsonyabb órajelet. Ennek megfelelően nem feltétlenül a legmagasabb beállított százalék adja a legjobb eredményt, ezt tehát ki kell tapasztalni.
A hőmérséklet szintén megváltoztatható. Alapértelmezetten a VGA 95°C-ra van kalibrálva, de ez igény szerint 50°C-ig csökkenthető; ilyenkor a hardver a megcélzott értékhez állítja a fogyasztást és a hűtést. A ventilátor fordulatszáma nem állítható be fixen, de megadható egy maximális érték, aminél jobban nem pöröghet fel. Alapértelmezetten 40% a maximális fordulatszám. Az előbbi beállításokkal bárki teljesen személyre szabhatja a Radeon R9 290X jelzésű VGA-t, attól függően, hogy éppen milyen igényekkel rendelkezik. Ehhez azonban a kártyát úgynevezett "Uber" módba kell állítani a NYÁK-ra épített kapcsoló segítségével. A másik opció a csendes (Quiet) üzemmód, amit az AMD előre paraméterezett. Ez bizonyos mértékben lassabb működést eredményez az "Uber" módhoz képest, és aktiválásával nem használható a Catalyst Overdrive menüje sem, így nem tuningolható a termék. A PCI Express 3.0-s csatolóba illeszthető AMD Radeon R9 290X TDP limitje 250 watt, de terhelés nélkül nagyjából 20 wattal is beéri, ami a ZeroCore Power szolgáltatás aktiválódása mellet körülbelül 3 wattra csökken.
A Hawaii funkcionalitásban a többi GCN architektúrára épülő megoldást másolja, így támogatja a DirectX 11.2-es, az OpenGL 4.3-es és az OpenGL ES 3.0-s API-t, emellett kezeli a C++ AMP-t és az OpenCL 1.2-es felületet, valamint a Partially Resident Textures kiterjesztést, aminek hála elérhető a DirectX Tiled Resources funkciójának TIER_2 szintje. Később támogatni fogja az OpenGL 4.4 és a Mantle API-t, de ez igaz mindegyik GCN architektúrát használó hardverre. A Hawaii sajátja azonban, hogy az OpenCL 2.0 összes, VGA-ra vonatkozó tervezett funkciójának eleget tesz.
Az AMD Radeon R9 290X részletes ismeretében elmondható, hogy egyszeres pontosság mellett 5,6 TFLOPS-os számítási teljesítményre képes, emellett 4 milliárd háromszöget dolgoz fel másodpercenként. A pixel és texel kitöltési sebesség rendre 64 MPixel/s és 176 GTexel/s. Előbbi érték messze kimagaslik az aktuális mezőnyből, ami komolyabb felbontás alatt jöhet jól.
Új CrossFire
Az AMD a CrossFire technológiát is felújította, így a korábbi CrossFire hidas összeköttetést a PCI Express kapcsolaton keresztüli kommunikáció váltja fel. Ez főleg komolyabb felbontás mellett segít a skálázódás maximalizálásában.

[+]
A rendszer alapja mostantól a CrossFire XDMA blokk a lapkákon belül, ami feloldja a korábbi megoldás adatátviteli korlátját, így a fejlesztők több adat megosztásával operálhatnak az egymást követő képkockák esetében.
Az AMD Radeon R9 290X
Az R9 270X és az R7 260X kártyához hasonlóan az R9 290X-ből is az AMD referencia megvalósítása jutott el hozzánk elsőként. Természetesen ez most sem jelenti azt, hogy az AMD partnerei nem állhatnak elő más kialakítású megoldásokkal, de ezekre valószínűleg várnunk kell egy kicsit.

[+]
A referencia R9 290X első ránézésre eléggé hasonlít a korábban bemutatott R9 270X-re, csak némileg hosszabb annál. A kártya 278 milliméteres, így pontosan 9 milliméterrel nyúlik túl a GeForce GTX TITAN-on.

[+]
A kártya oldalán nem láthatunk különösebb díszítést, vagy esetlegesen pirosan világító Radeon feliratot. Szokás szerint itt kaptak helyet a tápcsatlakozók, melyek egy 6 és egy 8 tűs aljzatból tevődnek össze, melyeken keresztül 225 wattot vehet fel a kártya. Mindehhez hozzájöhet még további 75 watt a PCI Expressen keresztül, amivel együtt összesen 300 wattból gazdálkodhat az R9 290X.

[+]
A légáramlásért a HD 7990-nel ellentétben ebben a kategóriában továbbra is egyetlen ventilátor felel, mely a kártya végében kapott helyet. A hűvösebb levegő nagy része a légkavaró teteje felől kerül beszívásra, ugyanakkor a burkolatban három kisebb járatot is kialakítottak, de ezek szerintünk inkább díszítőelemként funkcionálnak.

[+]
A felhevült levegő a kártya elején távozik, melynek rácsozata a korábbi szériához képest plusz DVI csatlakozó miatt kissé megcsappant, ugyanakkor oldalt is kivágásra került egy rész, melyen keresztül viszont a levegő már a házba távozik, feltéve ha épp ezen a részen nem kapott rácsozatot a gép hátulja, ahol egyből tovább tud haladni. Az R9 290X a különféle kimenetek sorát egy normál méretű DisplayPort 1.2 HBR2 csatolóval nyitja, ami mellé került a 3 GHz-es HDMI 1.4a. Ahogy utaltunk rá, DVI-D típusú csatlakozóból kettő került a hátoldalra. Mindkettő dual-link, ugyanakkor analóg kijelzőt, illetve ezzel együtt D-Sub (VGA) átalakítót már egyikre sem csatlakoztathatunk. Ezen lehetőségek együttesével DisplayPort használata nélkül is van lehetőségünk három HDMI/DVI csatolású megjelenítő egyidejű, Eyefinity-ben való használatához, amit a DisplayPort közreműködésével még akár további hárommal egészíthetünk ki. A DDM Audio használata mellett minden kijelzőhöz külön nyolccsatornás hangfolyam rendelhető.

[+]
A műanyagburkolat eltávolítása után felbukkant a hűtés, ami egy méretes, rézalapú bordából és a már említett ventilátorból áll. A GDDR5 szabványú chipek és a tápellátás hőelvezetéséről most is egy vastag fémlap gondoskodik, mely a szükséges helyeken vékony hővezető párnákkal van felvértezve.

A 2816 számolóegység maximális órajele 1 GHz [+]
A borda alatt a NYÁK közepén trónol a Hawaii kódnevű cGPU, mely továbbra is 28 nm-en készül. A 438 mm²-es lapka 24%-kal nagyobb az előd Tahitinél, ugyanakkor az TITAN-on található, GK110 kódjelű, 551 mm²-es központi egységnél már számottevően kisebb. Utóbbi ellenére a Hawaii az AMD eddig piacra dobott legnagyobb méretű GPU-ja, amivel a híres-hírhedt R600 420 mm²-es értékét előzi meg. Érdekesség, hogy míg utóbbiba 720 millió tranzisztor került, addig a Hawaii kódnevű legifjabb rokona nem sokkal nagyobb területen, már lassan tízszer annyit, 6,2 milliárdot tartalmaz.

[+]
A GPU mellé 16 darab, egyenként 256 MB kapacitású, SKhynix gyártmányú GDDR5 chip került, ami kereken 4 GB memóriát jelent. A viszonylag nagy darabszámért a GPU-ban található 512 bites memóriavezérlő felel, melyhez hasonlóval a Radeon HD 2900 XT (R600) óta nem rukkolt elő az AMD. A H5GQ2H24AFR-R0C típusjelzésű chipek gyárilag 1500 MHz-es órajelre (effektív 6 GHz) képesek, de ezt a tervezők nem használták ki, így azok csak 1250 MHz-en ketyegnek. Az elérhető maximális sávszélesség miatt így sem lehet okunk különösebb panaszra, hisz mindent egybevéve nem kevesebb mint 320 GB/s-os értékre képes a rendszer.

[+]
A 6 fázist felvonultató tápellátás összeállítása nagyon hasonló a HD 7970-nél látotthoz. A koncepció most is minőségi (és viszonylag drága) elemekből épül fel, melynek egyik része az International Rectifier által gyártott, úgynevezett DirectFET, míg az azt követő tekercseket a CPL szállítja. A vezérlésért szintén egy az International Rectifier által gyártott részegység felel a 3567B jelzésű chip személyében.

[+]
A HD 6900-as kártyáknál felbukkant kétállású BIOS-kapcsoló most sem sem maradt le. Az R9 290X esetében itt a csendes ("Quiet"), illetve autós hasonlattal élve sport ("Uber") fokozatok között váltogathatunk, annak függvényében, hogy éppen mennyire zavar minket a hűtés zaja, illetve szükségünk van-e az elérhető legnagyobb számítási teljesítményre.

[+]
Tesztkonfig, specifikációk
| Videokártyák | AMD Radeon R9 290X 4096 MB (Catalyst 13.11 beta) ASUS Radeon HD 7990 6144 MB (Catalyst 13.11 beta) AMD Radeon R9 270X 2048 MB (Catalyst 13.11 beta) HIS IceQ X2 Radeon R9 280X 3072 MB (Catalyst 13.11 beta) AMD Radeon HD 7970 GHz Edition 3072 MB (Catalyst 13.11 beta) AMD Radeon HD 7970 3072 MB (Catalyst 13.11 beta) Sapphire Radeon HD 7950 3072 MB (Catalyst 13.11 beta) Sapphire Radeon HD 7870 2048 MB (Catalyst 13.11 beta) NVIDIA GeForce GTX TITAN 3072 MB (Geforce driver 331.40) NVIDIA GeForce GTX 780 3072 MB (Geforce driver 331.40) NVIDIA GeForce GTX 770 2048 MB (Geforce driver 331.40) NVIDIA GeForce GTX 760 2048 MB (Geforce driver 331.40) |
|---|---|
| Processzor | Core i7-3770K (3,60 GHz) – túlhajtva 4,3 GHz-en EIST / C1E / C-state kikapcsolva; Turbo Boost kikapcsolva |
| Alaplap | MSI Z77 MPOWER (BIOS: V17.5) – Intel Z77 chipset AHCI driver: Intel 11.5.0.1207 |
| Memória |
G.Skill RipjawsX 16 GB (4 x 4 GB) DDR3-1866 F3-14900CL9Q-16GBXL |
| Háttértárak | Intel SSD 320 160 GB SSDSA2CW160G310 (SATA 3 Gbps) Seagate Barracuda 7200.12 500 GB (SATA, 7200 rpm, 16 MB cache) |
| Tápegység | Seasonic Platinum Fanless 520 – 520 watt |
| Monitor | Samsung Syncmaster 305T Plus (30") |
| Operációs rendszer | Windows 7 Ultimate 64 bit |
Az új Radeon legfőbb ellenfeleit a kategóriának megfelelően válogattuk össze, így nem maradhatott ki a GeForce GTX TITAN és a GTX 780 sem. Házon belülről a HD 7970 GHz Edition, illetve R9 280X kártyák mellé még a két GPU-s HD 7990 is bekerült.

[+]
Csúcskategóriás kártyákról lévén szó most is úgy döntöttünk, hogy Intel Core i7-3770K processzorunk órajelét egy egészséges tuning keretein belül 4,3 GHz-re emeljük, ami mellé a 16 GB G.Skill márkájú memóriánk üzemi órajelét 1866 MHz-re srófoltuk fel. Ami a meghajtóprogramokat illeti, a Radeon kártyákat az AMD-től kapott 13.11-es beta driverrel teszteltük, míg a GeForce kártyák a tesztelés időpontjában legújabbnak számító 331.40-es beta driverrel zakatoltak különféle méréseink alatt.
A játékokat a tesztben szereplő kártyákban lapuló számítási teljesítmény miatt 1920x1200-as és 2560x1600-as felbontásban teszteltük. A képminőséget maximálisra vagy ahhoz nagyon közelire állítottuk. Az AMD és az NVIDIA meghajtóprogramjaiban mindent alapértelmezett beállításokon hagytunk, az anizotropikus szűrést, illetve az élsimítást pedig mindig az adott játékban aktiváltuk.
Játékok
- Battlefield 3 (DirectX 11) – motor: Frostbite 2.0 / műfaj: FPS
- BioShock Infinite (DirectX 11) – motor: Unreal Engine 3 / műfaj: FPS
- Company of Heroes 2 (DirectX 11) – motor: Essence Engine 3.0 / műfaj: stratégia
- Crysis 3 (DirectX 11) – motor: CryEngine 3 / műfaj: FPS
- DiRT Showdown (DirectX 11) – motor: EGO Engine / műfaj: autóverseny
- Hitman: Absolution (DirectX 11) – motor: Glacier 2 / műfaj: TPS
- Metro 2033 (DirectX 11) - motor: 4A Engine / műfaj: FPS
- Sleeping Dogs (DirectX 11) – motor: United Front Engine / műfaj: TPS/akció
- Tomb Raider (DirectX 11) – motor: Crystal Engine / műfaj: TPS/kaland
A mérésekhez eddig használt játékok palettáját megváltoztattuk kissé. Továbbra is fontosnak tartjuk, hogy viszonylag naprakész és/vagy népszerű címeket alkalmazzunk, így a közelmúltban az Anno 2070 helyét a Company of Heroes 2 vette át.
A könnyebb és pontosabb mérés, valamint összevetés érdekében a Sleeping Dogsnál a benchmark toolt használtuk, ahogyan a BioShock Infinite, Metro 2033, DiRT Showdown, Hitman: Absolution, valamint Company of Heroes 2 és Tomb Raider esetében is. A Battlefield 3-nál a Going Hunting című küldetés első perceit mértük le FRAPS-szel, míg a Crysis 3-nál a Canyon nevű pálya elején található demó jellegű részt mértük. Korábban észrevettük, hogy a Metro 2033 sajnos rendszerint hibásan méri a minimum fps-t, ezért itt is a FRAPS-et alkalmaztuk a lehető legpontosabb eredmények érdekében.
| VGA megnevezése | Radeon R9 290X |
Radeon HD 7970 G.E. |
Radeon R9 280X |
GeForce GTX TITAN |
GeForce GTX 780 |
|---|---|---|---|---|---|
| Kódnév | Hawaii XT | Tahiti XT | GK110 | ||
| Gyártástechnológia | 28 nm (TSMC) | ||||
| Mikroarchitektúra | GCN | Kepler | |||
| Tranzisztorok száma | 6,2 milliárd | 4,31 milliárd | 7,1 milliárd | ||
| GPU lapka mérete | 438 mm2 | 365 mm2 | 551 mm2 | ||
| GPU max. órajele | 1000 MHz | 1050 MHz | 1000 MHz | 876 MHz | 902 MHz |
| GPU/shader órajele üresjáratban | 300 MHz | 324 MHz | |||
| Shader processzorok típusa | multiprecíziós vektor | stream | |||
| Számolóegységek száma | 2816 | 2048 | 2688 | 2304 | |
| Textúrázók száma | 176 textúracímző és -szűrő |
128 textúracímző és -szűrő |
224 textúracímző és -szűrő |
192 textúracímző és -szűrő |
|
| ROP egységek száma | 16 blokk (64) | 8 blokk (32) | 12 blokk (48) | ||
| Memória mérete | 4096 MB | 3072 MB | 6144 MB | 3072 MB | |
| Memóriavezérlő | 512 bites hubvezérelt | 384 bites hubvezérelt | 384 bites crossbar | ||
| Memória órajele terhelve | 1250 MHz (GDDR5) | 1500 MHz (GDDR5) | 1502 MHz (GDDR5) | ||
| Üresjáratban | 150 MHz | 162 MHz | |||
| Max. memória-sávszélesség | 320 000 MB/s | 288 000 MB/s | 288 384 MB/s | ||
| Támogatott DirectX | 11.2 | 11 | |||
| Dedikált HD transzkódoló | VCE | NVENC | |||
| Videóanyagok lejátszásának hardveres támogatása | AVIVO HD (UVD 3.2) | Purevideo HD (VP4) | |||
| TDP | ~250 watt | ||||
Fogyasztás, hűtés, tuning
A fogyasztást egy konnektorba dugható, digitális VOLTCRAFT Energy Logger 4000 készülékkel vizsgáltuk. A grafikonon az egyes videokártyákkal kiegészített rendszerek fogyasztása látható alaplappal, processzorral, táppal és a többi alkatrésszel együtt, de természetesen a monitor nélkül. A méréseket a Metro 2033 benchmarkja alatt mértük, mely 1920x1200-as felbontásban került lefuttatásra. Játékkal terhelt mérés közben meglehetősen sűrűn és gyorsan ingadoznak az értékek, ezért ide egy olyan értéket próbáltunk regisztrálni, mely a legtöbbször villant fel az eszköz kijelzőjén, vagyis nem a csúcsértéket jegyeztük fel.
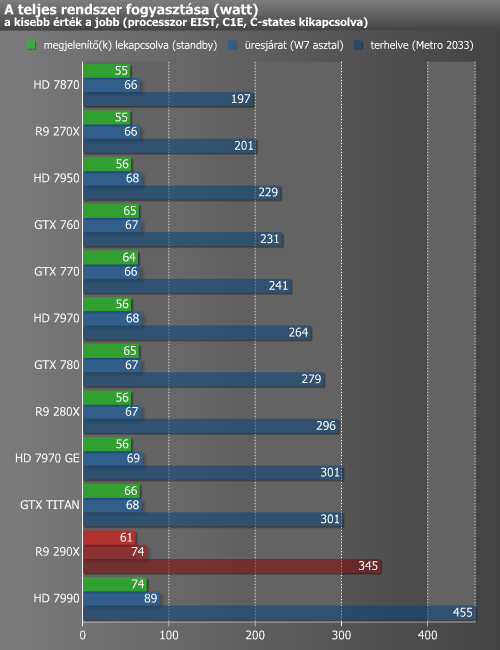
A grafikon jól szemlélteti, hogy az R9 290X meglehetősen nagy étvággyal rendelkezik. A közvetlen konkurens GTX TITAN-nál több mint 40 wattal fogyaszt többet. Ami még kissé furcsa, hogy a korábbi Radeon kártyákhoz képest az üresjárati értékek is magasabbak, bár az eltérés nem jelentős.

"Quiet" és "Uber" mód [+]
A hűtés teljesítményének vizsgálatát egy nagyjából 20 °C hőmérsékletű helyiségben végeztük, miközben a konfiguráció egy asztalon volt összeállítva. A korábban említett BIOS kapcsoló mindkét állásában megmértük a kártyát. A csendes(ebb) módban 40%-os fordulatszám föle nem engedi a légkavarót a vezérlés, így amikor a GPU hőmérséklete meghaladná a 95 Celsius-fokot, akkor az órajel csökken, hogy tartható legyen a hőmérsékleti célérték. Maximalista módban már 55% lehet a legmagasabb fordulatszám, ami nagyobb hűtést biztosít a GPU-nak, így csak ritkán, illetve kisebb mértékben esik a maximális 1 GHz alá a GPU órajele. A rögzített naplófájl alapján ekkor 49%-on (~2600 rpm) tetőzött a ventilátor tempója. Szerintünk csendes ("Quiet") módban még tűrhető a légkavaró által generált zaj, de "Uber" módban már kifejezetten nagy a zaj.
Az NVIDIA GeForce TITAN-ja ilyen szempontból jobb, mint az AMD referencia R9 290X-e, ugyanis az a gyári beállítások mellett csendesebb, mint az új Radeon. Fontos megjegyezni, hogy tapasztalataink alapján a kártya fogyasztását nem befolyásolta a kapcsoló állása, aminek valószínűleg az az oka, hogy a maximális GPU-hőmérsékletben, illetve áramfelvételben nincs eltérés a két mód között. Ennek kapcsán érdemes szem előtt tartani, hogy mindez a GPU-k fogyasztására is hatással van, ami nagyon leegyszerűsítve és röviden annyit tesz, hogy a lapka üzemi hőmérséklete önmaga áramfelvételére is hatással van, ugyanis a melegebb processzor többet fogyaszt.

A GPU órajele [+]
Azt is megnéztük, hogy a két módban miként változik a GPU órajele. Ehhez szintén a Metro 2033-at vettük elő, amit a hűtés tesztjéhez hasonlóan egymást követően nyolcszor futtattunk le. Jól látható, hogy 1/3-ad környékén, amikor a GPU hőmérséklete eléri a 95 Celsius-fokos határt, csendes módban elkezd csökkeni az órajel, hogy tartható legyen a legfeljebb 40%-os fordulatszám melletti maximális hőmérékleti célérték. Mindez azt is jelenti, hogy a hűtés jelentősége megnőtt, így a korábbiaknál többet számíthat annak minősége, hisz az egy bizonyos szintig már a teljesítménybe is beleszól. (A vízhűtést preferálók dörzsölhetik a tenyerüket, és kezdhetik feltörni a malacperselyt.)

A felújított OverDrive menü [+]
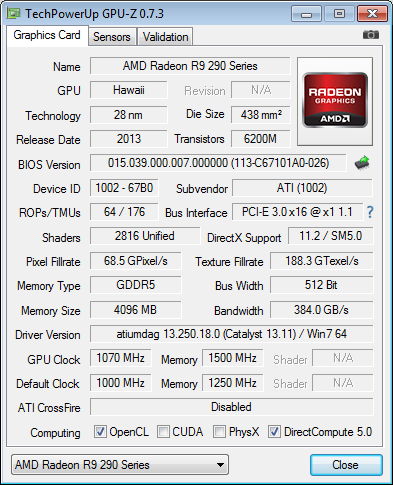
Végül természetesen a kártya túlhajtási lehetőségeire is vetettünk egy pillantást, melyhez csak a Catalyst, azaz az AMD saját szoftvere állt rendelkezésünkre, viszont annak a már megújult felülete. Nagyjából fél óra kisérletezgetés után 7%-ot tudunk emelni a GPU maximális órajelén, ami így 1070 MHz-lett. A memória kezesebb volt, így azon 20%-ot tudtunk emelni, ami frekvenciában 1500 MHz-et jelentett.
Az új OverDrive nem csak túlhajtás esetében jöhet jól, hisz meghatározott keretek között kártyánk GPU hőmérsékletét, illetve zajszintjét is kordában tarthatjuk vele. Sajnos egyelőre mindez csak az R9 290-es kártyák esetében fog működni, így az alsóbb régiókban való felbukkanása valószínűleg csak a következő Radeon generációval lesz esedékes.
Sleeping Dogs, DiRT: Showdown, CoH 2
A Radeon R9 290X-et mindkét módban megmértük, így a grafikonokon egy "U" betűvel ("Uber" mód), és egy "Q" betűvel ("Quiet" mód) jelölt variáns is látható.





Sleeping Dogs alatt mindkét módban megelőzte a TITAN-t az új Radeon, és ez a DiRT, illetve a Company of Heroes 2 alatt sem történt másképp.
Metro 2033, Crysis 3, Hitman: Absolution




A Metro újfent az R9 290X sikerért hozta, míg Crysis 3 alatt már szorossá vált a verseny. Itt már csak a sport fokozatba kapcsolt 290X hozta a TITAN tempóját, mely képkockára pontosan lemásolta a GeForce eredményét. A Hitman ismét a Radeonnak feküdt jobban.
BioShock, Battlefield 3, Tomb Raider



A Bioshock egyértelműen a GeForce-ok felségterülete, akárcsak a Battlefield 3. Bár a Tomb Raider alapvetően egy AMD által támogatott játék, ennek ellenére a TITAN ott tudott lenni az R9 290X nyakán.
ComputeMark, LuxMark
A tavalyi év során két általános számítási feladatokat tartalmazó benchmark is bekerült méréseink közé. Mivel félig-meddig szintetikus tesztekről van szó, túl messzemenő következtetéseket szerintünk nem érdemes levonni ezek eredményeiből.


A ComputeMark egyszerűbb DirectCompute shaderekkel operál, melyekkel főleg a játékok alatt lehet találkozni. Ezzel szemben a Luxmark az egyik legelterjedtebb benchmark a ray-tracing tesztelésére. A Kepler ezen a ponton nem sokat lépett előre a Fermihez képest, sőt. Valószínűleg a gyenge szereplésből a kezdetleges támogatás is kiveszi a részét, de az NVIDIA által alkalmazott gyorsítótár- és memóriahierarchia nem kedveli annyira a komplex számításokat, mint az AMD GCN architektúrája.
Összegzés

Az általunk alkalmazott tesztcsomag összesített eredményei alapján az új Radeon R9 290X gyorsabb, mint a GeForce GTX TITAN. Csendes(ebb) módban alig 1%, míg a gyárilag elérhető maximum tempóval 5% körüli az AMD előnye. Ez túlzással sem nevezhető soknak, így vásárlásnál valószínűleg nem ez fog dönteni. A házon belüli párharcban az új R9 290X körülbelül 32-34%-kal lépte túl a HD 7970 GHz Editiont és az ahhoz nagyon hasonló R9 280X-et.

A teljesítmény/fogyasztás mutatókat vizsgálva elmondhatjuk, hogy a Radeon R9 290X nem szerepel rosszul, bár a GK110 GPU-ra épülő GeForce-ok jobbak nála.
Az AMD új csúcskártyája, a Radeon R9 290X a közelmúltban debütált széria egyetlen, igazán új fejlesztésűnek nevezhető tagja. Mindez a kártyával együtt debütált Hawaii GPU-nak köszönhető, mely az AMD eddigi legnagyobb méretű és teljesítményű grafikus processzora. A 2816 darab, legfeljebb 1 GHz-en üzemelő számolóegység önmagáért beszél, akárcsak az 512 bites memóriavezérlő vagy az ahhoz kapcsolódó 4 GB memória. Bár jelen pillanatban az R9 290X tekinthető a leggyorsabb, egyetlen GPU-t alkalmazó grafikus kártyának, de összességében nem nagyon tudott meglépni a bő 25%-kal nagyobb alapterületű GPU-ra építkező GTX TITAN-tól, így ezen pozíciója véleményünk szerint nem nevezhető sziklaszilárdnak.

[+]
Ami a kártya felépítését illeti, szerintünk a hűtés, pontosabban annak zajszintje az új VGA gyenge pontja. Szinte biztosak vagyunk abban, hogy a későbbiekben néhány gyártó jobb hűtéssel ellátott R9 290X-szel fog előrukkolni, melyek talán nem csak csendesebb működést, de alacsonyabb GPU-hőmérsékletet is biztosítanak, hiszen ha valamikor, akkor most igazán lesz értelme ráfeküdni a hatékonyabb hűtésre. A fogyasztás magas, de szerintünk az ilyen és ehhez hasonló csúcskártyák célközönségének nagy részét ez már különösebben nem rázza meg. Szokás szerint a végére hagytuk az árazás kérdését, mely talán sokakban kompenzálja az esetleges negatívumokat. A GTX TITAN ára jelenleg 260-270 000 forint környékén mozog, ehhez képest az AMD a Radeon R9 290X-et jelentősen kedvezőbb áron, kalkulációink alapján körülbelül 155-160 000 forintos áron fogja kínálni. Ebből fakadóan az aktuálisan leggyorsabb, egyetlen GPU-val szerelt grafikus kártyát megcélzó vásárlóknak jelenleg egyértelműen a legújabb Radeont ajánljuk.

AMD Radeon R9 290X videokártya
Oliverda és Abu85
A tesztben szereplő AMD Radeon R9 290X grafikus kártyát az AMD biztosította. Az ASUS Radeon HD 7990-et a Ramiris Europe Kft.-től kaptuk kölcsön.




{kind=link}